I recently implemented instant search using Fuse and the entire site’s structured data (only 2MB after compression) exported from Hugo, and also set up a quick search URL at https://jimmysong.io/search/?q=keyword, customizing the result display page. This showcases the power of open source, allowing for personal customization anywhere.
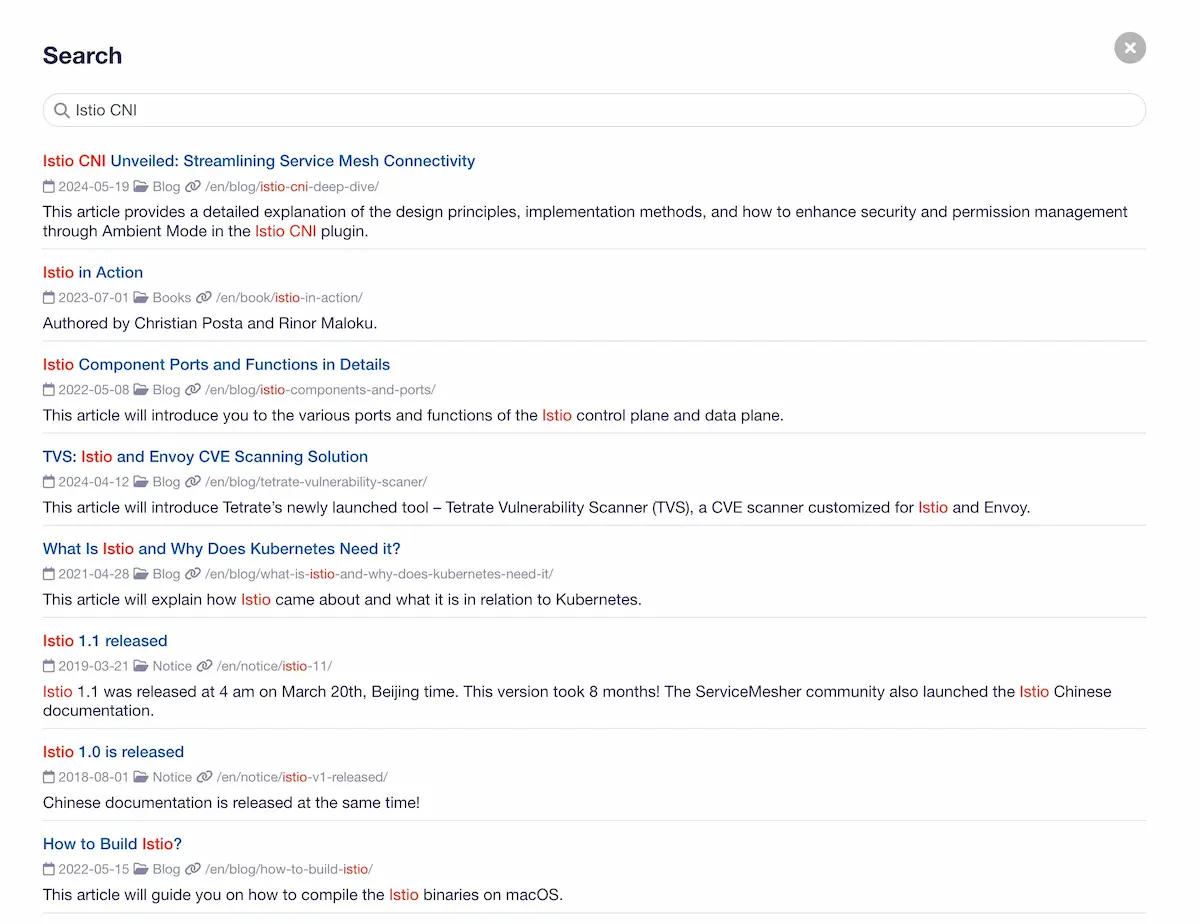
Overview
Below, I will share how to add instant search functionality to your Hugo website. The main steps are as follows:
- Export structured data from the Hugo site
- Build search JavaScript code using the Fuse library
- Add a frontend search template
- Automate the update of website structured data
- Further optimization
Tip
Readers can refer to the search implementation in the hugo-blox-builder project, here is some reference code:
- Frontend code: search.html
- Search implementation: wowchemy-search.js
- Styles: _search.scss
1. Export Hugo Website’s Structured Data
First, you need to create a JSON file for your Hugo site, which will contain essential metadata of all pages such as titles, descriptions, and links. This can be achieved by adding a custom output format in your Hugo configuration file (usually config.toml or config.yaml):
[outputs]
home = ["HTML", "RSS", "JSON"]
[outputFormats.JSON]
mediaType = "application/json"
baseName = "index"
isPlainText = falseThen, in your content template (like layouts/_default/list.json.json), define the JSON structure to be output:
{
"data": [
{{ range .Pages }}
{
"title": "{{ .Title }}",
"url": "{{ .Permalink }}",
"summary": "{{ .Summary }}"
}
{{ if not (eq .Next nil) }},{{ end }}
{{ end }}
]
}This will generate an index.json file for your entire site, containing the basic information of all pages. Of course, you may not want to export all pages of your site; you can customize the export of specific sections or different types of pages using Hugo’s syntax.
2. Build Search JavaScript Code Using Fuse Library
Next, use the Fuse.js library to implement the front-end instant search functionality. First, include the Fuse.js library file in your website. You can load it from a CDN like jsDelivr:
<script src="https://cdn.jsdelivr.net/npm/fuse.js/dist/fuse.min.js"></script>Then, in your JavaScript file, load and parse the index.json file and perform the search using Fuse.js:
fetch('/index.json')
.then(response => response.json())
.then(data => {
const fuse = new Fuse(data.data, {
keys: ['title', 'summary'],
includeScore: true
});
document.getElementById('search-input').addEventListener('input', function (e) {
const results = fuse.search(e.target.value);
displayResults(results);
});
});
function displayResults(results) {
const searchResults = document.getElementById('search-results');
searchResults.innerHTML = '';
results.forEach(result => {
const elem = document.createElement('div');
elem.innerHTML = `<a href="${result.item.url}">${result.item.title}</a>`;
searchResults.appendChild(elem);
});
}The specific implementation can be referenced from wowchemy-search.js.
3. Add Frontend Search Template
Add a search box
and results display area to your website:
<input type="text" id="search-input" placeholder="Enter search term">
<div id="search-results"></div>Additionally, you can add shortcut keys, usually ⌘/CTRL + K, to quickly open the search page.
The specific implementation can be referenced from this frontend template.
4. Automate Updating Website Structured Data
To ensure real-time search results, you can automate the Hugo website’s build and deployment process through GitHub Actions or other CI/CD tools, ensuring the index.json file is always up-to-date.
Create a .github/workflows/hugo_build.yml file, defining the automation process:
name: Build and Deploy
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Set up Hugo
uses: peaceiris/actions-hugo@v2
with:
hugo-version: 'latest'
- name: Build
run: hugo --minify
- name: Deploy
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./publicAdditionally, if your website supports multiple languages, you can generate index.json files for each language and load the corresponding index file on different language pages.
5. Further Optimization
- Cache Optimization: Set a reasonable cache policy for the
index.jsonto reduce server load and improve response speed. If you are using GitHub Pages as a static site, you can ignore this step. - Data Compression: Compress your
index.jsonfile. You can choose to export part of the website’s data, such as certain sections, truncate the content, or compress the file into gz format, then decompress it on the front end after loading, reducing network data transfer. - Search Result Highlighting: Add highlighting for keywords in the search results to improve user experience.
- Advanced Search Options: Allow users to filter searches by specific fields (like authors, categories).
- Network Optimization: Asynchronously load the JavaScript file used for searching,
By following these steps, you can effectively add a highly efficient and customizable instant search feature to your Hugo website.
Conclusion
This article introduces how to add instant search functionality to a Hugo website, and provides suggestions for further optimizing the search feature, including cache optimization, search result highlighting, and advanced search options. This not only showcases the powerful customization capabilities of open source technology but also enables website users to find needed information faster and more accurately.
