HAMi used to save cards in the cluster. Now it decides how good a desktop AI workstation feels.
An Old Friend Mentions a Name
A few days ago an old friend came by to chat. We used to run the cloud-native community scene together back home, so we go way back. She recently joined a company called Olares, and somewhere in the conversation she dropped this: their project had integrated HAMi.
I run the HAMi community day to day, so whenever I hear someone using it for something, I want to take a closer look. I went and dug through the Olares repo and website, and my first reaction was, huh, this is actually interesting.
Isn’t this exactly the kind of local AI workstation I’d been eyeing forever but never pulled the trigger on? I wrote in My Personal AI Stack that for someone like me who mainly works with my head, subscribing to models beats maintaining a high-end GPU. But how far can “one machine running the full AI stack” really go, and who has actually built it, I’ve wanted to see with my own eyes.
What Is This Thing, Really
Olares isn’t a “NAS with a GPU bolted on,” and it isn’t a “mini PC with Ollama installed.” It’s more like a personal cloud built on Kubernetes: local models, apps, identity, remote access, dev environment, storage, even GPU governance, all packed into one machine as a desktop cloud OS.
HAMi isn’t filler here. It’s the layer that turns “one card” into “a resource pool you can share, isolate, and schedule.”
How It Differs from the AI Mini-PC Crowd
There’s no shortage of things calling themselves AI workstations, but most are just beefier mini PCs. Olares is different. It’s genuinely designed as a cloud.
The company positions this machine outright as a 24/7 personal AI cloud, not a PC you sit in front of. That single framing explains almost everything that follows: why it has to use Kubernetes, why it cares so much about network traversal and remote access, why GPU governance suddenly matters here.
Two other details tell you a lot: it supports Thunderbolt 5 external eGPUs, and two machines can cluster up. In other words, it was never a sealed box. It starts as a single node and grows upward.
Stuffing a Whole Cloud Runtime into One Box
Architecturally, what Olares does is compress an entire cloud runtime into a single machine: auth and authorization, app lifecycle, tunnels and traversal, secrets, observability middleware, not a layer skipped.
This isn’t “a few AI apps preinstalled.” It’s a complete cloud runtime stuffed into a desktop device.
The diagram below is my own re-drawn layering based on its public docs, with the HAMi layer pulled out explicitly because it’s the point of this whole piece.

One Detail That Caught My Eye
One thing jumped out while I was reading: Olares’s docs haven’t kept up with its own product.
Its 2025 architecture page still says nvshare, noting that GPUs are limited to one card per node. But flip through the release notes and 1.12 already integrates the HAMi scheduler, with exclusive, time-slicing, and memory-slicing modes all there; 1.12.2 adds multi-GPU; 1.12.5 supports DGX Spark outright and rolls automatic scheduling across all three modes.
The product is outrunning its docs. That alone tells you something: it’s shifting from a “personal cloud OS” toward a “local AI cloud OS.” That’s also why I wanted to write a whole piece on it.
What HAMi Actually Does in There
HAMi is a CNCF Sandbox project, positioned as a heterogeneous AI compute virtualization middleware. On the path there’s a Webhook, a scheduler, a Device Plugin, and HAMi-core handling in-container resource control. I summed it up in one line in Kubernetes Is Becoming the GPU Control Plane of the AI Era: it turns GPU slicing from “a hardware capability” into “a control-plane capability.”
On Olares, that’s the real thing behind the GPU mode toggle in settings. On the surface it’s a UI option; underneath, it’s a policy switch on the resource plane.
The most critical piece is almost certainly HAMi-core, which in one sentence: intercepts CUDA calls inside the container and does memory virtualization, compute throttling, and utilization monitoring. It doesn’t slice with hardware. It manages with software.
The diagram below puts that injection path and the three GPU modes side by side.

The evidence lines up too. In Olares’s GitHub issues you can see HAMi’s libvgpu.so crashing under WSL2, the discussion mentions it getting injected into every process via /etc/ld.so.preload, and the Olares team itself says this implementation “drew heavy inspiration” from the HAMi project.
One thing I should be clear about, though: whether Olares uses upstream HAMi-core directly or maintains a forked version, there’s no single official answer in public. I won’t fill that in for them.
The three modes make sense in order. Full-card exclusive is for heavy loads; time-slicing lets lightweight services take turns, and Olares even swaps inactive models into memory first, with roughly 5% switching overhead; memory-slicing cuts the memory into fixed quotas so multiple apps run together. On something like DGX Spark, where CPU and GPU share memory, it defaults to memory-slicing because there’s no traditional memory paging in and out to begin with.
Why This Matters for HAMi
HAMi used to live mostly in big clusters: multi-tenant, inference serving, mixed training-and-inference, heterogeneous cards. NIO running it for sharing across 80 nodes and 600 cards is the textbook example. That line is well-trodden.
What feels new about Olares is that it moves the same problem onto a single machine.

What you actually run at once on Olares is never just one Ollama: a local model, a chat UI, a research agent, an image or video pipeline, plus a pile of OCR, speech-to-text, and automation tools. In a scenario like that, without a GPU scheduling layer, the GPU always degenerates into “whoever starts first grabs it.”
So for HAMi this matters. It goes from “a tool that saves cards for platform engineers” to “something that directly decides whether an ordinary user has a good time.” In the cluster it manages utilization and cost; on Olares it manages concurrent experience, model switching, and whether this machine is actually pleasant to use. HAMi doesn’t only talk to platform engineers anymore.
Where Edge AI Goes from Here
My sense is, edge AI won’t settle at “a stronger local model box.” It’ll grow into a full stack of “control plane plus model plane plus application plane.”
NVIDIA pushing DGX Spark and RTX Spark onto the desktop has already moved the story from “run models locally” to “run agents locally.” Olares’s CUDA-plus-x86 is one path, DGX Spark’s unified memory is another, and below that there’s the DIY mini-PC-plus-eGPU route you assemble yourself. Interestingly, Olares lists eGPU and dual-node as supported paths itself, so the line between appliance and DIY isn’t that sharp.
But my guess is, the one that breaks out won’t be the one with the most ferocious specs. It’ll be the one that fuses resource governance, dev experience, app ecosystem, security, and remote access into one closed loop. If desktop AI workstations really become a category, what people compete on isn’t GPU and memory, it’s the control plane.
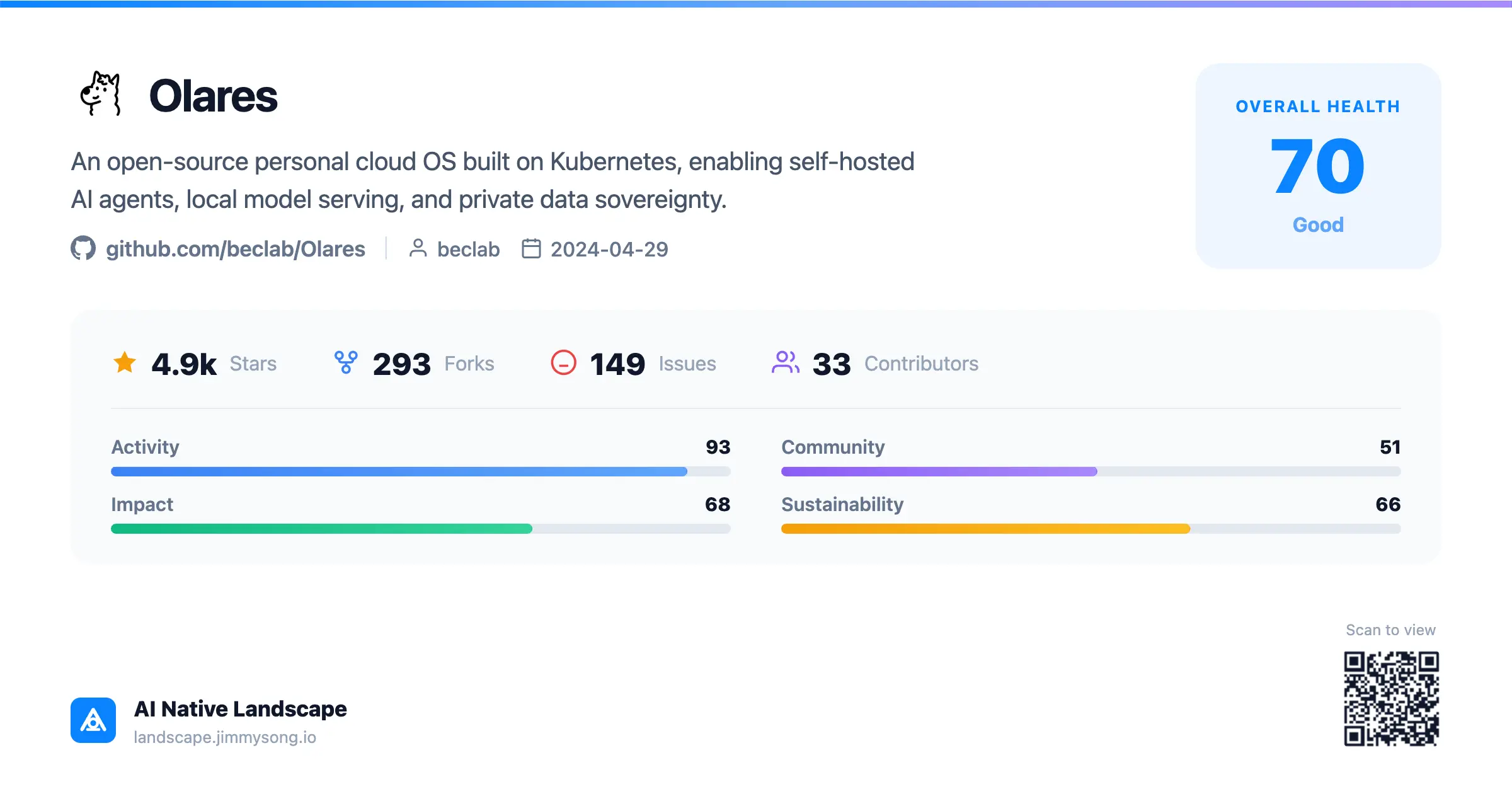
I went ahead and added Olares to the AI Native Landscape I maintain, so I can keep watching how it grows.
Conclusion
In one line: Olares is a desktop AI OS with Kubernetes at its core, and HAMi is the layer that turns its single-machine GPU into a shareable, isolatable, schedulable resource pool.
From cluster to desktop, HAMi’s story is expanding from “saving cards” to “making edge AI usable.” If desktop AI workstations become a real category, what people compete on is the control plane, not single-card performance.
