It has been six years since Kubernetes was open-sourced. The cloud-native era has arrived, and I’ve been following the cloud-native field for over four years. Recently, I’ve been thinking about the future direction of cloud-native and wrote this article as the opening to the “Cloud-Native Applications White Paper.” For more introductions to cloud-native applications, please refer to the white paper.
Key Points
- Cloud-native infrastructure has passed the 野蛮 growth period and is moving toward unified application standards.
- Kubernetes primitives cannot completely describe the cloud-native application ecosystem, and there’s serious coupling between development and operations functionality in resource configuration.
- Operators have expanded the Kubernetes ecosystem but also led to fragmentation of cloud-native applications, urgently needing a unified application definition standard.
- OAM essentially separates development and operations concerns in cloud-native application definition, further abstracts resource objects, simplifies complexity, and encompasses everything.
- “Post-Kubernetes era” refers to the period after Kubernetes has become the infrastructure layer standard, where the cloud-native ecosystem’s focus is shifting to the application layer. The hot Service Mesh in recent years is a powerful exploration in this process, and the era of Kubernetes-based cloud-native application architecture is about to arrive.
Kubernetes has become the established platform for cloud-native applications. This article takes Kubernetes as the default platform, including the layered model of cloud-native applications.
Different Development Stages of Cloud Native
Since its open-sourcing, Kubernetes has gone through nearly six years (open-sourced in June 2014). It can be said that Kubernetes’s birth opened the entire cloud-native era. I roughly divide cloud-native development into the following periods.
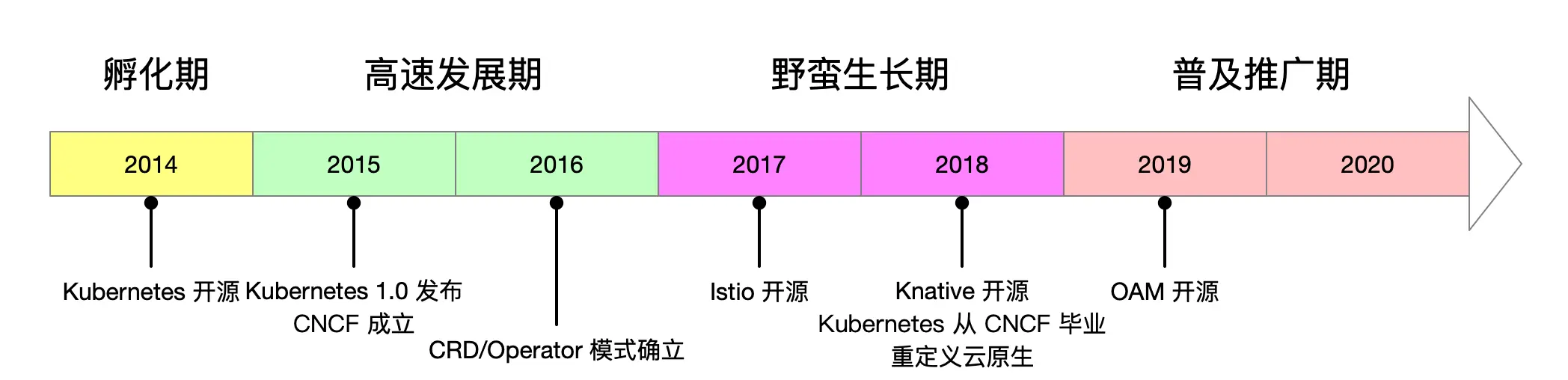
Stage 1: Incubation (2014)
In 2014, Google open-sourced Kubernetes. Before that, in 2013, Docker was open-sourced, DevOps and microservices had become very popular, and the concept of cloud-native was just emerging. After open-sourcing Kubernetes, Google united other vendors to establish CNCF and contributed Kubernetes as a founding project to CNCF. CNCF became the driving force behind cloud-native, starting to promote Kubernetes.
Stage 2: Rapid Development (2015 - 2016)
During these years, Kubernetes maintained rapid development and in 2017 defeated Docker Swarm and Mesos, establishing its leadership position among container orchestration tools. The birth of CRD and Operator patterns greatly enhanced Kubernetes’s extensibility and promoted the prosperity of the surrounding ecosystem.
Stage 3: Wild Growth (2017 - 2018)
After 2016, cloud-native basically defaulted to running on the Kubernetes platform. In 2017 and 2018, Google-led Istio and Knative were successively open-sourced. These open-source projects extensively used Kubernetes’s Operators for extension. When Istio was first released, it had over 50 CRD definitions. Istio claims to be microservices in the post-Kubernetes era. Its appearance made cloud-native service-centric (application-centric) for the first time. Knative is Google’s attempt in the serverless field based on Kubernetes. In 2018, Kubernetes officially graduated from CNCF, and Prometheus and Envoy also successively graduated from CNCF. CNCF also amended its charter in 2018, redefining cloud-native from the original three elements: “application containerization; microservice-oriented architecture; applications support container orchestration scheduling” to “cloud-native technologies help organizations build and run scalable applications in new dynamic environments such as public clouds, private clouds, and hybrid clouds. Representative cloud-native technologies include containers, service meshes, microservices, immutable infrastructure, and declarative APIs.” That year, I wrote two year-end summaries and outlooks on Kubernetes and cloud-native development, see 2017 and 2018 predictions and summaries.
Stage 4: Popularization and Promotion (2019 - Present)
After several years of development, Kubernetes has achieved large-scale application, and the concept of cloud-native has taken root. Kubernetes is known as the operating system of cloud-native. The ecology based on the Operator model has flourished. Integrating Kubernetes and cloud infrastructure, separating development and operations concerns. From Kubernetes to Service Mesh (microservices in the post-Kubernetes era), to Kubernetes-based serverless, all are developing rapidly. OAM was born, aiming to define cloud-native application standards.
[Note: Due to length constraints, this is a partial translation focusing on the key concepts and introduction.]
