# MIT License# Copyright (c) 2025 Mahtab Syed# https://www.linkedin.com/in/mahtabsyed/"""
实战代码示例 - 迭代 2
- 以 LangChain 和 OpenAI API 展示目标设定与监控模式:
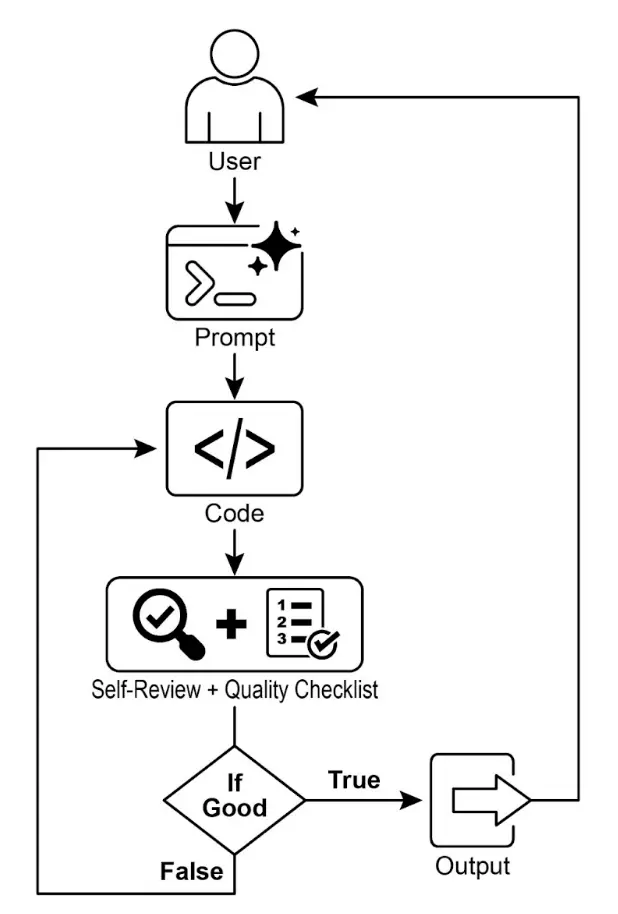
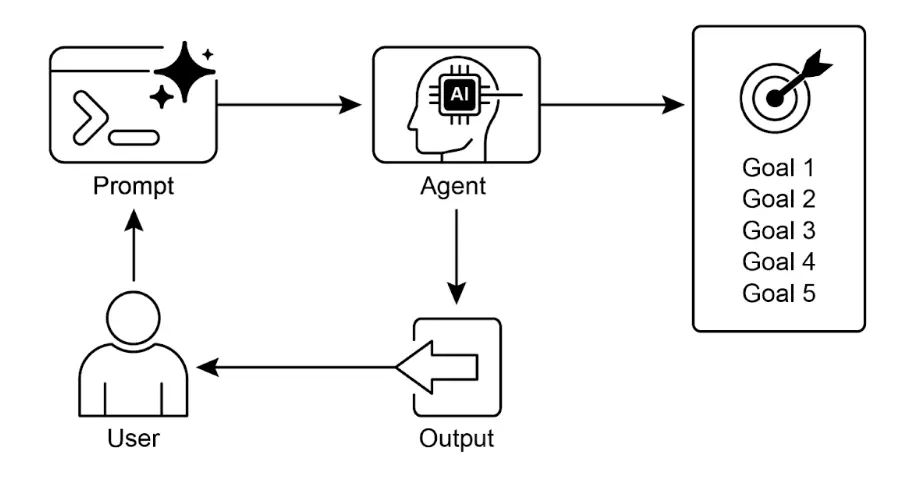
目标:构建一个 AI 智能体,能根据指定目标为用例编写代码:
- 接收编程问题(用例)作为输入。
- 接收目标列表(如“简单”、“已测试”、“处理边界情况”)作为输入。
- 使用 LLM(如 GPT-4o)生成并优化 Python 代码,直到目标达成(最多 5 次迭代,可自定义)。
- 判断目标是否达成时,LLM 仅返回 True 或 False,便于停止迭代。
- 最终将代码保存为 .py 文件,文件名简洁,带头部注释。
"""importosimportrandomimportrefrompathlibimportPathfromlangchain_openaiimportChatOpenAIfromdotenvimportload_dotenv,find_dotenv# 🔐 Load environment variables_=load_dotenv(find_dotenv())OPENAI_API_KEY=os.getenv("OPENAI_API_KEY")ifnotOPENAI_API_KEY:raiseEnvironmentError("❌ Please set the OPENAI_API_KEY environment variable.")# ✅ Initialize OpenAI modelprint("📡 Initializing OpenAI LLM (gpt-4o)...")llm=ChatOpenAI(model="gpt-4o",# If you dont have access to got-4o use other OpenAI LLMstemperature=0.3,openai_api_key=OPENAI_API_KEY,)# --- Utility Functions ---defgenerate_prompt(use_case:str,goals:list[str],previous_code:str="",feedback:str="")->str:print("📝 Constructing prompt for code generation...")base_prompt=f"""
You are an AI coding agent. Your job is to write Python code based on the following use case:
Use Case: {use_case}Your goals are:
{chr(10).join(f"- {g.strip()}"forgingoals)}"""ifprevious_code:print("🔄 Adding previous code to the prompt for refinement.")base_prompt+=f"\nPreviously generated code:\n{previous_code}"iffeedback:print("📋 Including feedback for revision.")base_prompt+=f"\nFeedback on previous version:\n{feedback}\n"base_prompt+="\nPlease return only the revised Python code. Do not include comments or explanations outside the code."returnbase_promptdefget_code_feedback(code:str,goals:list[str])->str:print("🔍 Evaluating code against the goals...")feedback_prompt=f"""
You are a Python code reviewer. A code snippet is shown below. Based on the following goals:
{chr(10).join(f"- {g.strip()}"forgingoals)}Please critique this code and identify if the goals are met. Mention if improvements are needed for clarity, simplicity, correctness, edge case handling, or test coverage.
Code:
{code}"""returnllm.invoke(feedback_prompt)defgoals_met(feedback_text:str,goals:list[str])->bool:"""
Uses the LLM to evaluate whether the goals have been met based on the feedback text.
Returns True or False (parsed from LLM output).
"""review_prompt=f"""
You are an AI reviewer.
Here are the goals:
{chr(10).join(f"- {g.strip()}"forgingoals)}Here is the feedback on the code:
\"\"\"{feedback_text}\"\"\"Based on the feedback above, have the goals been met?
Respond with only one word: True or False.
"""response=llm.invoke(review_prompt).content.strip().lower()returnresponse=="true"defclean_code_block(code:str)->str:lines=code.strip().splitlines()iflinesandlines[0].strip().startswith("```"):lines=lines[1:]iflinesandlines[-1].strip()=="```":lines=lines[:-1]return"\n".join(lines).strip()defadd_comment_header(code:str,use_case:str)->str:comment=f"# This Python program implements the following use case:\n# {use_case.strip()}\n"returncomment+"\n"+codedefto_snake_case(text:str)->str:text=re.sub(r"[^a-zA-Z0-9 ]","",text)returnre.sub(r"\s+","_",text.strip().lower())defsave_code_to_file(code:str,use_case:str)->str:print("💾 Saving final code to file...")summary_prompt=(f"Summarize the following use case into a single lowercase word or phrase, "f"no more than 10 characters, suitable for a Python filename:\n\n{use_case}")raw_summary=llm.invoke(summary_prompt).content.strip()short_name=re.sub(r"[^a-zA-Z0-9_]","",raw_summary.replace(" ","_").lower())[:10]random_suffix=str(random.randint(1000,9999))filename=f"{short_name}_{random_suffix}.py"filepath=Path.cwd()/filenamewithopen(filepath,"w")asf:f.write(code)print(f"✅ Code saved to: {filepath}")returnstr(filepath)# --- Main Agent Function ---defrun_code_agent(use_case:str,goals_input:str,max_iterations:int=5)->str:goals=[g.strip()forgingoals_input.split(",")]print(f"\n🎯 Use Case: {use_case}")print("🎯 Goals:")forgingoals:print(f" - {g}")previous_code=""feedback=""foriinrange(max_iterations):print(f"\n=== 🔁 Iteration {i+1} of {max_iterations} ===")prompt=generate_prompt(use_case,goals,previous_code,feedbackifisinstance(feedback,str)elsefeedback.content)print("🚧 Generating code...")code_response=llm.invoke(prompt)raw_code=code_response.content.strip()code=clean_code_block(raw_code)print("\n🧾 Generated Code:\n"+"-"*50+f"\n{code}\n"+"-"*50)print("\n📤 Submitting code for feedback review...")feedback=get_code_feedback(code,goals)feedback_text=feedback.content.strip()print("\n📥 Feedback Received:\n"+"-"*50+f"\n{feedback_text}\n"+"-"*50)ifgoals_met(feedback_text,goals):print("✅ LLM confirms goals are met. Stopping iteration.")breakprint("🛠️ Goals not fully met. Preparing for next iteration...")previous_code=codefinal_code=add_comment_header(code,use_case)returnsave_code_to_file(final_code,use_case)# --- CLI Test Run ---if__name__=="__main__":print("\n🧠 Welcome to the AI Code Generation Agent")# Example 1use_case_input="Write code to find BinaryGap of a given positive integer"goals_input="Code simple to understand, Functionally correct, Handles comprehensive edge cases, Takes positive integer input only, prints the results with few examples"run_code_agent(use_case_input,goals_input)# Example 2# use_case_input = "Write code to count the number of files in current directory and all its nested sub directories, and print the total count"# goals_input = (# "Code simple to understand, Functionally correct, Handles comprehensive edge cases, Ignore recommendations for performance, Ignore recommendations for test suite use like unittest or pytest"# )# run_code_agent(use_case_input, goals_input)# Example 3# use_case_input = "Write code which takes a command line input of a word doc or docx file and opens it and counts the number of words, and characters in it and prints all"# goals_input = "Code simple to understand, Functionally correct, Handles edge cases"# run_code_agent(use_case_input, goals_input)
本章聚焦于目标设定与监控这一关键范式,阐述了其如何将智能体从被动响应系统转变为主动、目标驱动的实体。强调了明确、可衡量目标和严格监控流程的重要性,并通过实际应用展示了该范式在客户服务、机器人等领域支持可靠自主运行的能力。代码示例则展示了如何在结构化框架下实现这些原则,通过智能体指令和状态管理引导和评估目标达成。为智能体赋予制定和监督目标的能力,是迈向真正智能、可问责 AI 系统的基础。