第 18 章:护栏与安全模式
护栏(Guardrails),也称为安全模式,是确保智能体安全、合规、按预期运行的关键机制,尤其是在智能体日益自主并集成到关键系统中的情况下。它们作为保护层,引导智能体的行为和输出,防止有害、偏见、无关或其他不良响应。护栏可在多个阶段实施,包括输入验证/清洗(过滤恶意内容)、输出过滤/后处理(分析生成结果是否有毒或偏见)、行为约束(提示级)、工具使用限制、外部内容审核 API,以及“人类介入”机制(Human-in-the-Loop)。
护栏的主要目标不是限制智能体能力,而是确保其运行稳健、可信且有益。它们既是安全措施,也是行为引导,对于构建负责任的 AI 系统、降低风险、维护用户信任至关重要,确保行为可预测、安全、合规,防止被操纵并维护伦理与法律标准。没有护栏,AI 系统可能变得不可控、不可预测,甚至带来危险。为进一步降低风险,可以采用计算资源消耗较低的模型作为快速额外防线,对主模型的输入或输出进行预筛查,检测是否有政策违规。
实践应用与场景
护栏广泛应用于各类智能体系统:
- 客服聊天机器人:防止生成冒犯性语言、错误或有害建议(如医疗、法律)、或跑题回复。护栏可检测有毒输入并指示机器人拒绝或转交人工处理。
- 内容生成系统:确保生成的文章、营销文案或创意内容符合规范、法律和伦理标准,避免仇恨言论、虚假信息或不良内容。可通过后处理过滤器标记并删除问题短语。
- 教育助教/辅导员:防止智能体提供错误答案、传播偏见观点或参与不当对话,通常涉及内容过滤和遵循预设课程。
- 法律研究助手:防止智能体提供明确法律建议或替代持证律师,仅引导用户咨询专业人士。
- 招聘与人力资源工具:通过过滤歧视性语言或标准,确保公平,防止偏见。
- 社交媒体内容审核:自动识别并标记包含仇恨言论、虚假信息或暴力内容的帖子。
- 科研助手:防止智能体伪造研究数据或得出无依据结论,强调实证验证和同行评审。
在这些场景中,护栏作为防御机制,保护用户、组织及 AI 系统声誉。
实战代码 CrewAI 示例
以下是 CrewAI 的护栏实现示例。使用 CrewAI 构建护栏需多层防御,流程包括输入清洗与验证(如内容审核 API 检测不当提示、Pydantic 校验结构化输入),限制智能体处理敏感话题。
监控与可观测性对于合规至关重要,包括记录所有行为、工具调用、输入输出,便于调试和审计,并收集延迟、成功率、错误等指标,实现可追溯性。
错误处理与弹性同样重要。需预判故障并优雅处理,如使用 try-except 块、指数退避重试逻辑,并提供清晰错误信息。关键决策或护栏检测到问题时,可集成人工介入流程,人工审核输出或干预智能体流程。
智能体配置也是护栏的一环。定义角色、目标、背景故事可引导行为,采用专用智能体而非通用型,保持聚焦。实际操作如管理 LLM 上下文窗口、设置速率限制,防止 API 超限。安全管理 API 密钥、保护敏感数据、对抗训练等高级安全措施可增强模型对抗恶意攻击的能力。
以下代码展示如何用 CrewAI 增加安全层,通过专用智能体和任务、特定提示词及 Pydantic 护栏,筛查用户输入,防止主 AI 处理有问题内容。
| |
该 Python 代码构建了一个内容政策执行机制,核心是预筛查用户输入,确保其符合严格的安全与相关性政策,才允许主 AI 处理。
SAFETY_GUARDRAIL_PROMPT 是一组详细的 LLM 指令,定义了“AI 内容政策执行者”角色,列举了多项关键政策,包括指令绕过(Jailbreaking)、禁止内容(如仇恨言论、危险行为、色情、辱骂)、无关话题(如政治、宗教、学术作弊)、品牌与竞争信息。提示词明确给出合规输入示例,并要求输出严格遵循 JSON 格式,包括 compliance_status、evaluation_summary 和 triggered_policies。
为确保 LLM 输出结构正确,定义了 Pydantic 模型 PolicyEvaluation,并配套 validate_policy_evaluation 函数作为技术护栏,解析 LLM 输出、处理 markdown 格式、校验数据结构和内容合法性,若校验失败则返回错误,否则返回合规结果。
CrewAI 框架下,创建了 policy_enforcer_agent Agent,专注于政策执行,配置为不可委托、非冗余,使用快速、低成本模型(如 gemini/gemini-2.0-flash),温度设为 0 保证严格遵循政策。
任务 evaluate_input_task 动态嵌入 SAFETY_GUARDRAIL_PROMPT 和用户输入,要求输出符合 PolicyEvaluation 模型,并指定 validate_policy_evaluation 作为护栏。
这些组件组装为 Crew,采用顺序执行流程。
run_guardrail_crew 函数封装了执行逻辑,输入用户字符串,调用 crew.kickoff,获取最终校验结果,根据 compliance_status 返回合规性、摘要和触发政策列表,并包含异常处理。
主程序块演示了多组测试用例,涵盖合规与违规输入,逐一调用 run_guardrail_crew 并格式化输出结果,清晰展示输入、合规状态、摘要、触发政策及建议操作(放行或阻止)。
Vertex AI 实战代码示例
Google Cloud 的 Vertex AI 提供多层安全机制,包括身份与授权、输入输出过滤、工具安全控制、内置 Gemini 安全特性(内容过滤、系统指令)、模型与工具调用回调校验。
关键安全实践包括:用轻量模型(如 Gemini Flash Lite)做额外防线、隔离代码执行环境、严格评估与监控智能体行为、限制智能体活动在安全网络边界(如 VPC Service Controls)。实施前需针对智能体功能、领域和部署环境做详细风险评估。技术护栏之外,所有模型生成内容在展示前都应清洗,防止恶意代码在浏览器执行。
以下代码展示了工具调用前的参数校验回调:
| |
该代码定义了智能体和工具执行前的校验回调。validate_tool_params 函数在工具调用前执行,校验参数中的 user_id 是否与会话状态一致,若不一致则阻止工具执行并返回错误,否则允许继续。最后实例化了 root_agent Agent,指定模型、指令,并分配了校验回调,确保所有工具调用都经过安全校验。
需要强调的是,护栏可通过多种方式实现,既有基于模式的简单允许/拒绝列表,也有基于提示词的复杂护栏。
LLM(如 Gemini)可驱动强大的提示词安全措施,如回调,帮助防范内容安全、智能体偏离、品牌安全等风险,尤其适合筛查用户和工具输入。
例如,LLM 可被指令为安全护栏,有效防止 Jailbreak(绕过安全限制的攻击性提示),避免 AI 生成本应拒绝的有害内容、恶意代码或冒犯性信息。
(提示词示例略,详见英文原文)
工程化可靠智能体
构建可靠智能体需遵循传统软件工程的严谨原则。即使确定性代码也会有 bug 和不可预测行为,因此容错、状态管理和测试至关重要。智能体应视为复杂系统,更需这些成熟工程方法。
检查点与回滚模式是典型案例。自主智能体管理复杂状态,易偏离预期,检查点机制类似数据库事务的提交与回滚,是容错设计的核心。每个检查点是已验证状态,回滚则是故障恢复机制,成为主动测试与质量保障策略的一部分。
但健壮智能体架构远不止一种模式,还需多项软件工程原则:
- 模块化与关注点分离:单一大智能体难以调试,最佳实践是设计多个专用智能体或工具协作。例如,一个负责数据检索,一个负责分析,一个负责用户沟通。模块化提升并行处理能力、敏捷性和故障隔离,便于独立优化、升级和调试,系统更易扩展、健壮、可维护。
- 结构化日志实现可观测性:可靠系统必须可理解。智能体需深度可观测,记录完整“思考链路”——调用了哪些工具、收到哪些数据、下一步决策及信心分数,便于调试和性能优化。
- 最小权限原则:安全至上。智能体只应获得完成任务所需的最小权限。例如,只能访问新闻 API,而不能读取私有文件或其他系统,极大降低潜在错误或恶意攻击的影响范围。
集成这些核心原则——容错、模块化、可观测性、严格安全——可将智能体从“能用”提升为“工程级”,确保其操作不仅高效,还具备健壮性、可审计性和可信度,达到高标准的软件工程要求。
一图速览
是什么:随着智能体和 LLM 越来越自主,若无约束,可能带来不可预测风险,生成有害、偏见、伦理或事实错误内容,造成现实损害。系统易受 Jailbreak 等对抗攻击,绕过安全协议。无护栏,智能体可能行为失控,失去用户信任,带来法律和声誉风险。
为什么:护栏/安全模式为智能体系统风险管理提供标准化解决方案,是多层防御机制,确保智能体安全、合规、目标一致。可在输入验证、输出过滤、行为约束、工具限制、人类介入等环节实施,最终目标不是限制智能体,而是引导其行为,确保可信、可预测、有益。
经验法则:只要智能体输出可能影响用户、系统或业务声誉,都应实施护栏。对于面向用户的自主智能体(如聊天机器人)、内容生成平台、处理敏感信息的系统(金融、医疗、法律等),护栏至关重要。用于执行伦理规范、防止虚假信息、保护品牌安全、确保法律合规。
视觉摘要
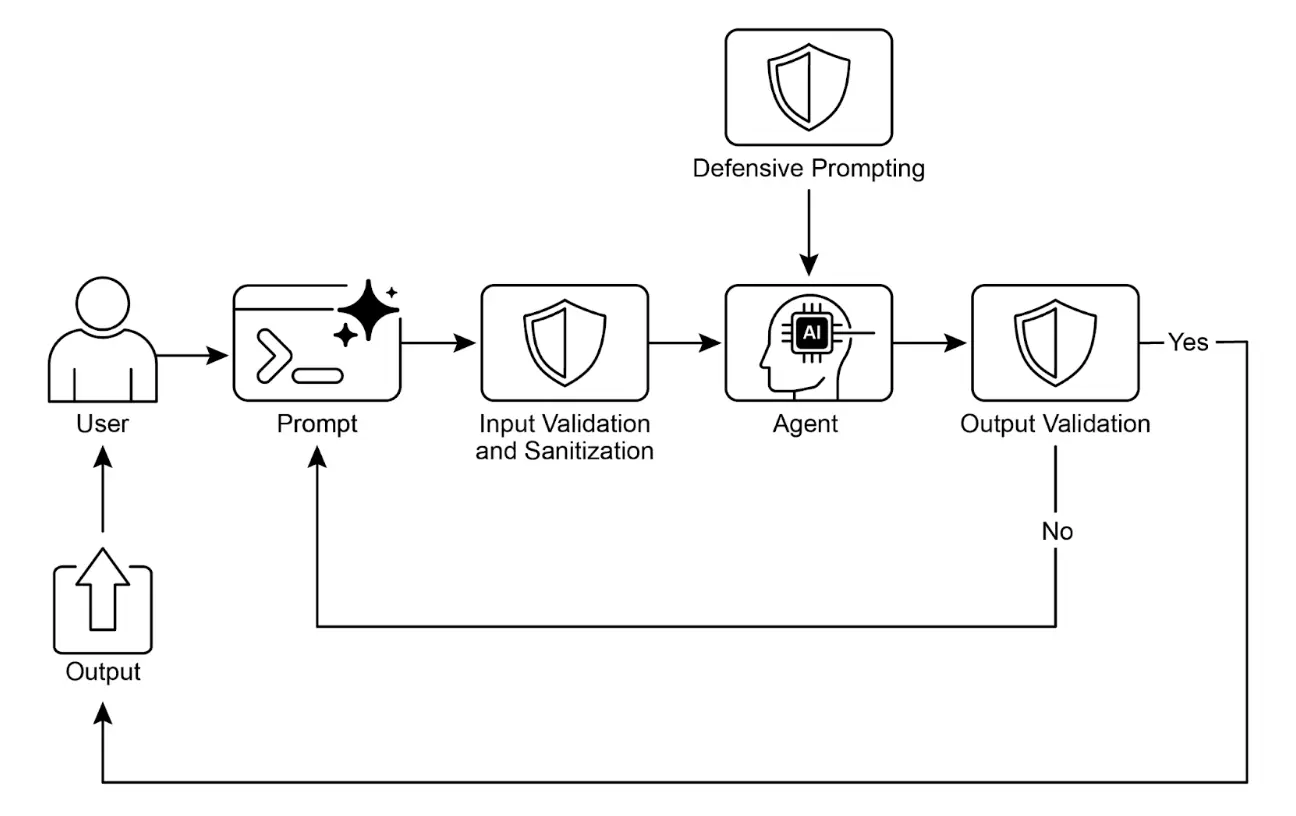
关键要点
- 护栏是构建负责任、合规、安全智能体的基础,防止有害、偏见或跑题输出。
- 可在输入验证、输出过滤、行为约束、工具限制、外部审核等环节实施。
- 多种护栏技术组合最为稳健。
- 护栏需持续监控、评估和优化,适应风险和用户变化。
- 有效护栏对维护用户信任和智能
- 构建可靠、工程级智能体的最佳方式,是将其视为复杂软件系统,应用传统系统几十年来成熟的工程实践,如容错设计、状态管理和全面测试。
总结
有效护栏的实施是负责任 AI 开发的核心承诺,超越技术层面。战略性应用安全模式可让开发者构建既稳健高效、又可信有益的智能体。多层防御机制,集成输入验证到人工介入,能抵御意外或有害输出。护栏需持续评估和化,适应挑战,确保智能体系统长期合规。最终,精心设计的护栏让 AI 能安全、高效地服务于人类需求。
参考文献
测验:护栏与安全模式
基于第 18 章:护栏与安全模式,检验关键概念与应用场景理解