第 19 章:评估与监控
本章探讨了智能体系统性评估自身性能、监控目标进展以及检测运行异常的方法。第十一章介绍了目标设定与监控,第十七章讨论了推理机制,而本章则聚焦于智能体有效性、效率及合规性的持续(通常是外部)测量,包括指标定义、反馈回路建立和报告系统实现,确保智能体在实际环境中的表现符合预期(见图 1)。
实践应用与用例
常见应用场景包括:
- 生产环境性能追踪:持续监控智能体在实际部署中的准确率、延迟和资源消耗(如客服机器人解决率、响应时间)。
- A/B 测试优化:并行比较不同版本或策略的智能体表现,寻找最优方案(如物流智能体尝试两种规划算法)。
- 合规与安全审计:自动生成审计报告,跟踪智能体对伦理、法规和安全协议的遵守情况,可由人工或其他智能体验证,发现问题时生成 KPI 或触发告警。
- 企业系统治理:在企业级智能体 AI 管理中,需要一种新的控制工具——AI“合同”,动态约定目标、规则和控制措施。
- 漂移检测:监控智能体输出的相关性或准确性,检测因输入数据分布或环境变化导致的性能下降(概念漂移)。
- 异常行为检测:识别智能体异常或意外行为,可能表明错误、攻击或不良新行为出现。
- 学习进度评估:对具备学习能力的智能体,跟踪其学习曲线、技能提升或在不同任务/数据集上的泛化能力。
实操代码示例
开发智能体的评估框架是一项复杂工作,涉及模型性能、用户交互、伦理影响及社会效应等多方面因素。实际落地时,可聚焦于关键用例,提升智能体的效率与效果。
智能体响应评估:这是评估智能体输出质量与准确性的核心流程,关注其是否能针对输入提供相关、正确、逻辑严密、公正且准确的信息。评估指标包括事实正确性、流畅度、语法精度及是否符合用户意图。
| |
上述 Python 函数通过去除首尾空格并忽略大小写,严格比较智能体输出与期望结果,完全一致则返回 1.0,否则为 0.0。这种方法无法识别语义等价(如例子中的两句话),仅适用于简单场景。实际评估需用更高级的 NLP 技术,如字符串相似度(Levenshtein 距离、Jaccard 相似度)、关键词分析、语义相似度(嵌入模型余弦相似度)、LLM 评审(后文介绍)及 RAG 相关指标(如真实性、相关性)。
延迟监控:智能体响应延迟在实时或交互场景中至关重要。监控处理请求到输出的耗时,过高延迟会影响用户体验和智能体效果。实际应用建议将延迟数据记录到持久化存储,如结构化日志(JSON)、时序数据库(InfluxDB、Prometheus)、数据仓库(Snowflake、BigQuery、PostgreSQL)或可观测性平台(Datadog、Splunk、Grafana Cloud)。
LLM 交互 Token 用量追踪:对于 LLM 驱动的智能体,追踪 Token 用量有助于成本管理和资源优化。LLM 计费通常按输入/输出 Token 数量,监控 Token 用量可优化提示词设计和响应生成。
| |
上述 Python 类 LLMInteractionMonitor 用于追踪 LLM 交互的 Token 用量,实际应用需结合 LLM API 的 Token 计数器。累计输入/输出 Token 总数,有助于成本管控和优化。
LLM 评审“有用性”自定义指标:评估智能体“有用性”等主观指标,可采用 LLM 作为评审者(LLM-as-a-Judge),根据预设标准自动化、规模化地进行定性评估。此方法利用 LLM 的语言理解能力,超越简单关键词匹配或规则判断,适合自动化主观质量评估。
| |
上述代码定义了 LLMJudgeForLegalSurvey 类,利用 Gemini 模型和详细评审标准自动评估法律调查问题,输出包括总分、理由、各项详细反馈、关注点和建议。支持自动化主观质量评估,适用于大规模问卷或内容审核。
在总结前,下面对多种评估方法进行对比:
| 评估方法 | 优势 | 劣势 |
|---|---|---|
| 人工评估 | 能捕捉细微行为 | 难以规模化,成本高,主观性强 |
| LLM 评审 | 一致、高效、可扩展 | 可能忽略中间步骤,受限于 LLM 能力 |
| 自动化指标 | 可扩展、高效、客观 | 难以全面覆盖智能体能力 |
智能体轨迹评估
智能体轨迹评估至关重要,传统软件测试仅能判断通过/失败,而智能体行为具有概率性,需定性分析最终输出及决策过程。多智能体系统评估更具挑战性,因其不断变化,需开发超越个体性能的协作与沟通指标,并适应动态环境。
轨迹评估包括决策质量、推理过程和最终结果。自动化评估对原型开发尤为重要。分析轨迹和工具使用时,需比较智能体实际步骤与理想路径,包括工具选择、策略和任务效率。例如,客服智能体理想轨迹为确定意图、调用数据库工具、审核结果并生成报告。实际行为与理想轨迹可用精确匹配、顺序匹配、任意顺序匹配、查准率、查全率、单工具使用等方法对比,具体指标选择取决于场景需求。
智能体评估主要有两种方式:测试文件和 evalset 文件。测试文件(JSON 格式)用于单次简单交互或会话,适合开发阶段单元测试,关注快速执行和简单会话。每个测试文件包含一个会话,含多轮用户 - 智能体交互,包括用户请求、工具使用轨迹、智能体中间响应和最终回复。可按文件夹组织,并用 test_config.json 定义评估标准。Evalset 文件用于复杂多轮会话和集成测试,包含多个 eval,每个 eval 代表一个会话,含多轮交互、工具调用和参考答案。例如,用户先问“你能做什么?”,再要求“掷两次十面骰并判断 9 是否为质数”,定义工具调用和最终回复。
多智能体评估:复杂 AI 系统如同团队项目,需评估每个智能体的分工和整体协作:
- 智能体是否有效协作?如“机票预订智能体”是否能正确将日期和目的地传递给“酒店预订智能体”,避免预订错误。
- 是否制定并遵循合理计划?如先订机票再订酒店,若酒店智能体提前订房则偏离计划,或智能体陷入某一步无法前进。
- 是否为任务选择了合适智能体?如查询天气应由“天气智能体”而非“通用知识智能体”回答。
- 增加新智能体是否提升整体性能?如新增“餐厅预订智能体”后,是否提升效率或引发冲突。
从智能体到高级“承包商”
近期提出(Agent Companion, gulli 等)将智能体从概率性、易出错系统升级为更确定、可问责的“承包商”,适用于复杂高风险场景(见图 2)。
传统智能体仅依赖简短指令,适合演示但在生产环境易因歧义失败。“承包商”模型通过正式合同建立用户与 AI 的严密关系,合同详细规定任务、交付物、数据源、范围、成本和时限,结果可客观验证。
第一支柱是正式合同,作为任务唯一真相来源,远超简单提示。例如,财务分析合同要求“生成 20 页 PDF 报告,分析 2025 年 Q1 欧洲市场销售,含 5 个数据可视化、与 2024 年 Q1 对比及供应链风险评估”,明确交付物、规范、数据源和时限。
第二支柱是动态协商与反馈,合同不是静态命令,而是对话起点。承包商智能体可分析条款并协商,如要求使用无法访问的数据源时,智能体可反馈“指定数据库不可用,请提供凭证或批准使用公开数据库,可能影响数据粒度”,提前解决歧义和风险,确保最终结果符合用户真实需求。
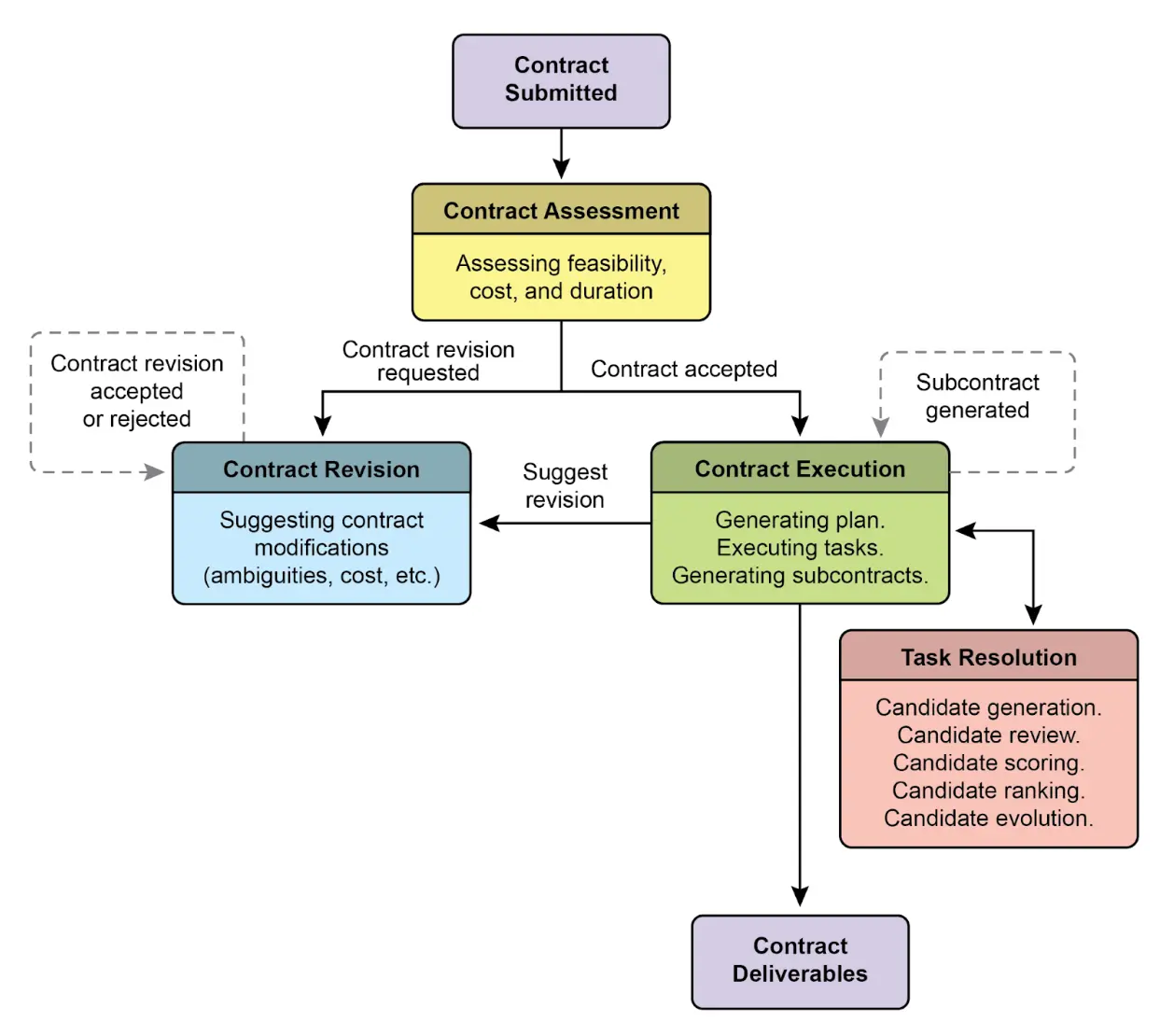
第三支柱是质量导向的迭代执行,承包商优先保证正确性和质量。以代码生成合同为例,智能体会生成多种算法方案,编译并运行合同定义的单元测试,按性能、安全性和可读性评分,仅提交全部通过的版本。自我验证和改进循环是建立信任的关键。
第四支柱是分层分解与子合同,复杂任务由主承包商智能体分解为多个子任务,生成独立子合同,如“开发电商移动应用”可分解为“设计 UI/UX”、“开发认证模块”、“创建产品数据库”、“集成支付网关”,每个子合同有独立交付物和规范,可分配给专用Agent。结构化分解让系统能高效组织和扩展,推动 AI 从工具向自主可靠的解决方案转变。
最终,承包商框架通过正式规范、协商和可验证执行,将 AI 从易变助手升级为可问责系统,适用于关键领域。
Google ADK 框架
最后介绍一个支持评估的实际框架:Google 的 ADK(见图 3)。智能体评估可通过三种方式进行:Web UI(adk web)用于交互式评估和数据集生成,pytest 集成用于测试流水线,命令行(adk eval)适合自动化评估和常规构建验证。
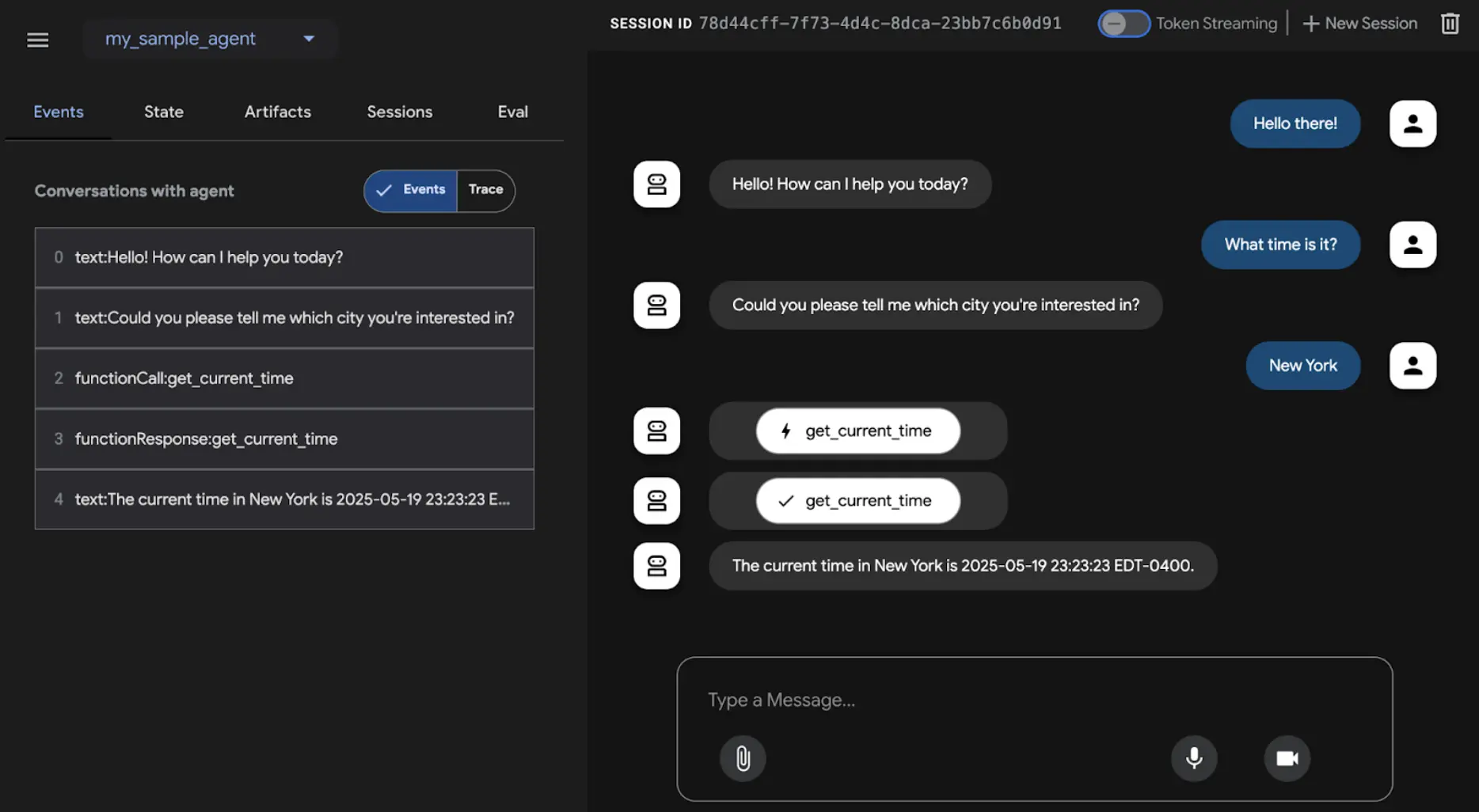
Web UI 支持交互式会话创建和保存,展示评估状态。Pytest 集成可通过 AgentEvaluator.evaluate 调用智能体模块和测试文件,实现集成测试。
命令行支持自动化评估,指定智能体模块和 evalset 文件,可选配置文件或详细结果输出。可通过逗号分隔指定 evalset 中的具体 eval。
一图速览
是什么:智能体系统和 LLM 在复杂动态环境中运行,性能可能随时间下降。其概率性和非确定性特性使传统测试难以保障可靠性。多智能体系统和环境不断变化,需开发适应性测试方法和协作指标。部署后可能出现数据漂移、异常交互、工具调用和目标偏离,需持续评估智能体的有效性、效率和合规性。
为什么:标准化评估与监控框架能系统性地保障智能体持续性能,包括准确率、延迟、资源消耗(如 LLM Token 用量)等指标,以及分析轨迹和主观质量(如有用性)。通过反馈回路和报告系统,实现持续改进、A/B 测试和异常检测,确保智能体始终符合目标。
经验法则:当智能体部署在生产环境、需实时性能和可靠性时采用本模式;需系统比较不同版本或模型以驱动优化时使用;在合规、安全和伦理要求高的领域也适用;当智能体性能可能因数据或环境变化而下降(漂移),或需评估复杂行为(轨迹、主观输出)时也推荐使用。
视觉总结
关键要点
- 智能体评估超越传统测试,需持续衡量其在实际环境中的有效性、效率和合规性。
- 典型应用包括生产环境性能追踪、A/B 测试、合规审计、漂移和异常检测。
- 基础评估关注响应准确性,实际场景需延迟监控、LLM Token 用量等更复杂指标。
- 轨迹评估关注智能体行为序列,将实际步骤与理想路径对比,发现错误和低效。
- ADK 提供结构化评估方法,支持单元测试(测试文件)和集成测试(evalset 文件),均定义预期行为。
- 评估可通过 Web UI 交互测试、pytest 集成 CI/CD、命令行自动化执行。
- 为提升 AI 在复杂高风险任务中的可靠性,需从简单提示转向正式“合同”,明确定义可验证交付物和范围,支持协商、分解和自我验证,将智能体转变为可问责系统。
总结
综上,有效评估智能体需超越简单准确率检查,采用持续、多维度的动态环境性能评估,包括延迟、资源消耗等实际指标,以及轨迹分析和主观质量评估(如有用性)。LLM 评审等创新方法日益重要,Google ADK 等框架为单元和集成测试提供结构化工具。多智能体系统评估重点转向协作与整体表现。
为保障关键应用可靠性,智能体范式正从简单提示驱动转向正式合同绑定的高级“承包商”,通过明确定义、协商、分解和自我验证,满足高质量标准。此结构化方法让智能体从不可预测工具升级为可问责系统,推动 AI 在关键领域的可信部署。
参考文献
本章引用的主要资源与研究文章如下:
- ADK Web - github.com
- ADK 评估文档 - google.github.io
- LLM 智能体评估综述 - arxiv.org
- Agent-as-a-Judge:智能体评估 Agent - arxiv.org
- Agent Companion (Gulli 等) - kaggle.com
测验:评估与监控
基于第 19 章:评估与监控,检验智能体评估方法和监控策略的理解