使用 SGLang 实现结构化输出与函数调用能力
结构化输出和函数调用,是让大模型真正“可控”的关键一步。
SGLang 是一个用于定义和执行生成式 AI 工作流的领域特定语言(DSL),旨在简化复杂生成任务的编排与管理。通过 SGLang,用户可以以声明式方式描述多步骤的生成流程,集成不同的模型和工具,实现自动化的内容生成、数据处理和交互式应用。
SGLang 名称的含义
本节介绍 SGLang(Structured Generation Language)名称背后的设计理念。
- Structured(结构化):强调对大模型输出进行格式约束和结构化处理,比如生成严格的 JSON、XML 等数据结构,而不是仅仅输出自由文本。这有助于后续自动解析和程序化调用,提升生成内容的可用性和可靠性。
- Generation(生成):指的是生成式 AI 的内容生产能力,包括文本、数据、代码等多种类型的自动化生成。
- Language(语言):说明它是一种领域特定语言(DSL),用于描述和编排生成式 AI 的工作流和逻辑流程。
因此,SGLang 既是一个用于定义生成任务的 DSL,也是一个支持结构化输出和函数调用的大模型服务框架。它让开发者能够以声明式方式,灵活控制模型的输出格式和交互逻辑,简化复杂的 AI 应用开发流程。
背景原理与核心概念
SGLang(Structured Generation Language)是一款开源的大模型服务框架,注重高速推理和可控生成能力。与 vLLM 偏重后台优化不同,SGLang 采用“后端 Runtime + 前端 DSL”的协同设计,使开发者可以用高级接口操控模型输出格式、逻辑流程等。
其核心特色包括:支持高效的推理引擎(RadixAttention 快速 Attention 计算、零开销 CPU 调度、连续动态批处理等)以及结构化输出和工具调用能力。
结构化输出指引导或约束 LLM 按照特定格式生成内容(如严格的 JSON、XML 结构等),减少解析自由文本的麻烦。函数/工具调用则是近来 LLM 应用的热门功能:模型能根据用户请求,输出结构化的数据以调用预定义的函数或 API,从而实现查询数据库、获取实时信息等操作。
SGLang 在这两方面提供了原生支持——模型可通过产出特定的 JSON 片段来表示函数名和参数,SGLang 的解析器会将其提取并独立返回,从而让外部程序调用相应函数。这一机制类似于 OpenAI 的 Function Calling,但在开源模型上实现了类似能力。
值得注意的是,SGLang 目前主要优化支持 GPU 后端,在多 GPU 大模型部署上有显著优势。然而对于只有 CPU 的 Mac 环境,SGLang 尚未提供直接的高效后端。官方文档指出,SGLang 后端目前要求 NVIDIA GPU(计算能力 7.5 及以上)以发挥性能。如果没有兼容 GPU,可以退而求其次,利用 SGLang 的前端语言特性搭配其他后端,例如 OpenAI 云 API 或本地 OpenAI 兼容服务。换句话说,我们可以在 Mac 上通过安装“SGLang OpenAI 后端支持”模块,将 SGLang 作为一个客户端,调用远端的 OpenAI 接口或本地 vLLM 服务,从而利用 SGLang 的结构化输出/函数调用能力。
SGLang 架构
下图展示了 SGLang 的整体架构,帮助理解其分层设计和各模块的作用。

SGLang 的分层架构如下:
应用/脚本层(App)
- 你写的 Python 代码:用装饰器(
@sgl.function)和算子(sgl.gen等)把对话步骤、分支、循环、工具调用组织起来。 - 作用:把“Prompt 工程 + 业务流程”变成可维护的程序化编排,而不是到处散落的字符串。
SGLang 前端编排层(Frontend)
- Prompt 管理:统一管理 system/user/assistant 消息、模板填充、few-shot 等。
- 上下文/会话态:把中间变量、工具返回结果塞回上下文,供后续轮次使用。
- 受控生成控制器:这是 SGLang 的杀手锏——你可以给出 JSON Schema/正则/EBNF,SGLang 在解码时实时约束,确保输出严格合法(不是“软提示”)。
- 函数/工具调用解析:模型生成函数名 + 参数(结构化格式),框架自动解析并执行你注册的函数,把工具结果再注入上下文,进入下一轮。
推理运行时(Runtime)
- 请求调度/连续批处理:把不同长度、不同到达时间的请求动态合并成批次,提高吞吐。
- KV Cache/上下文管理:跨请求/多轮对话共享和复用 KV,减少重复计算。
- 执行器:负责解码循环、并发控制、流式输出;这里会配合后端的特性发挥性能(GPU 时收益更明显)。
后端(Backends)
- OpenAI 兼容 API:可以指向云端(官方/第三方)或本地(如 LM Studio、vLLM 起的 /v1 服务)。
- Transformers:快速原型、离线 CPU 体验。
- vLLM/其他引擎:大规模服务时的首选,吃满 GPU,Paged KV/Continuous Batching 等优化在此层发挥。
输出层(Output)
- 后处理:对模型输出做 JSON 校验、补齐、解包工具调用结果;出错时可回退/重试。
- 结构化响应:不仅有文本,还可以带函数执行结果、思路片段、元数据(token 数、耗时等),便于接入你的上层应用。
安装与运行步骤(macOS)
本节介绍如何在无 GPU 环境下安装和运行 SGLang。
安装:针对无 GPU 环境,官方建议安装精简版的 SGLang OpenAI 后端支持包。可通过 pip 一键安装:
pip install "sglang[openai]"
上述命令会安装 SGLang 及其依赖,并跳过 GPU 相关的组件。如果将来在 Linux 服务器或配备 GPU 的环境使用,可改为安装完整版(如 pip install "sglang[all]")或从源码安装最新版本。
运行:在 Mac 上没有 GPU,无法直接用 SGLang 加载本地模型执行。但是我们可以采取两种方式来体验其功能:
- 连接 OpenAI 云服务:将 OpenAI 的 API 当作后端,让 SGLang 负责发送请求和解析输出。这需要有 OpenAI API 密钥,但实现最简单。
- 连接本地兼容服务:使用本地部署的大模型服务作为后端。SGLang 前端会将请求发送到该本地服务,从而实现纯离线推理和结构控制。
我们将使用 LM Studio 部署本地大模型,访问
LM Studio
下载应用并在 App 中选择 qwen/qwen3-4b-2507,该模型只有 2.28GB,完全可以在本地运行,支持中文,并可以快速响应。
示例调用
本节通过代码示例演示 SGLang 的结构化输出能力。
| |
在上面的示例中,sglang_example.py 展示了如何用 SGLang 的 Python API 定义结构化输出函数。我们通过 @sgl.function 装饰器定义了 get_capital_and_population,在函数体内先用系统指令要求模型只输出 JSON,然后用用户指令提出问题,最后通过 sgl.gen 并传入 json_schema 参数,强制模型输出符合指定 JSON Schema 的内容。
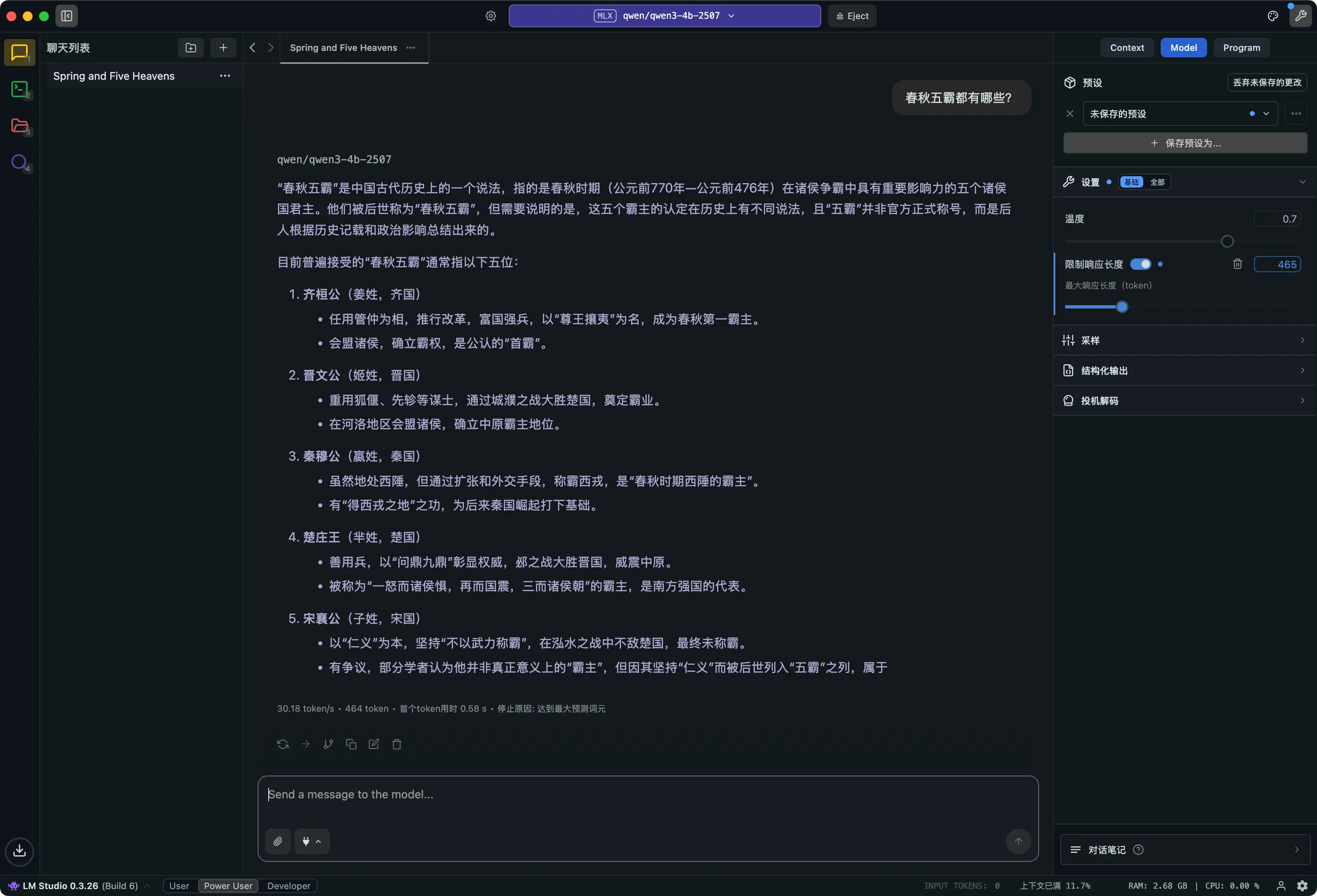
SGLang 会自动在解码阶段应用该约束,确保模型输出严格符合 JSON 格式,并自动解析为 Python 字典(如 {"name": "布加勒斯特", "population": 1883425})。开发者无需手动正则或字符串处理,直接获得结构化数据,极大提升了生成式 AI 在数据处理和接口集成场景下的可靠性与开发效率。
在 LM Studio 中运行上述代码,得到的结果类似:
{
"name": "布加勒斯特",
"population": 1883425
}
你可以在 LM Studio 的界面中看到模型的回答,并且 SGLang 已经将其解析为结构化的 JSON 对象。
SGLang 的函数工具调用本质上也是结构化输出的一种特殊情况。通常我们会在提示模板中引导模型以预定 JSON 格式输出函数名和参数。当模型生成出这个 JSON 后,SGLang 的 Tool Parser 会将其从回答中剥离出来,作为独立的工具调用结果返回。
例如用户问“今天北京的天气如何?”,我们可以设计让模型输出:{"function": "get_weather", "args": {"location": "北京"}}。SGLang 解析后可以直接调用 get_weather 函数,并最终返回函数结果给用户,实现自动工具使用。在 OpenAI 的函数调用基础上,SGLang 针对不同模型(如 DeepSeek 系列)做了专门适配,提升了成功率。
要点总结
- SGLang 简介:LMSYS 团队开源的高性能大模型服务框架,兼具后端高性能和前端灵活编程能力。支持多种模型(如 LLaMA、Qwen、DeepSeek 等)的推理,并提供丰富的 API 来控制模型行为。
- 结构化输出优势:SGLang 允许开发者指定 JSON Schema、正则表达式、EBNF 文法等约束,对模型生成结果进行硬约束。模型输出会被限制在符合格式的范围内,大幅降低了后续解析的难度和出错率。这对于需要模型返回 JSON 以供程序处理的情景(如数据库查询结果、表格数据生成)尤其重要。在 SGLang 中,这通过“受控解码”实现,内部使用了如 XGrammar 等高速语法约束库。
- 函数调用能力:SGLang 原生支持工具调用(Function Calling)。模型可以用结构化内容表示要调用的函数名和参数,SGLang 可以自动解析并触发相应函数执行。这一能力使 LLM 从纯文本回答扩展为具备动作能力,可访问外部知识库或服务,实现“Think-And-Act”范式。在实际应用中,这意味着可以用开源模型构建类似 ChatGPT Plugins 的功能,比如查询天气、查数据库、执行计算等。
- 性能和并发:SGLang 在 GPU 上表现出色,针对多 GPU/多机场景有诸多优化(如流水线并行、Expert Parallel 等)。同时它引入了零开销调度、连续批处理等机制,使高并发请求下仍能保持较低延迟。在 CPU 上虽然目前缺乏专门优化,但其架构保证了前端逻辑的轻量,足以在 Mac 等设备上跑小规模示例。
- 使用限制:目前 SGLang 完整功能需要较新款 GPU 支持。在无 GPU 环境下主要作为一个 OpenAI 兼容的客户端使用,通过调用云端或本地其他服务来间接实现推理。这一点在面向客户选型时需明确:小规模离线原型可以用 SGLang+OpenAI API 组合,但大规模部署最好在云上使用 GPU 以发挥 SGLang 最大性能。
- 典型应用场景:当客户需要高可靠结构化输出(例如法规摘要需要 JSON 格式)或工具调用能力(如智能客服需查询数据库),SGLang 非常契合需求。它可以保证模型回答格式正确率,减少二次解析开销。同时结合其前端 DSL,还能编排复杂对话流程,对于需要多轮交互的应用提供了便利。
总结
本文系统介绍了 SGLang 的结构化输出与函数调用能力,详细解析了其架构、原理、安装运行方式及典型应用场景。SGLang 通过 DSL 编排和受控生成机制,让大模型输出真正“可控”,极大提升了生成式 AI 在实际业务中的可靠性和集成效率。对于需要高质量结构化数据和自动工具调用的场景,SGLang 是开源生态中极具竞争力的选择。未来,随着其后端和前端能力的持续演进,SGLang 有望成为生成式 AI 应用开发的主流基础设施之一。