第 7 章:AI 应用运行时
AI 应用运行时正经历从云原生到 AI 原生的深刻变革,Serverless 架构和会话式运行时成为智能体与模型高效、安全、弹性运行的关键基石。
AI 应用运行时的演进趋势
AI 应用运行时的演进,体现了计算范式的持续变革。每一次范式跃迁,都是为了解决前一时代的矛盾,释放新的生产力。
从云原生到 AI 原生
信息技术的发展史,是一部计算范式不断演进的历史。从大型机时代的集中式计算,到客户端 - 服务器架构的分布式计算,再到云原生时代的微服务和容器化,每一次变革都推动了生产力的提升。
云原生时代的核心是应用。围绕应用,业界构建了以 Kubernetes 为标准的容器编排系统、无服务器计算(Serverless/FaaS)、CI/CD、可观测性和服务治理体系。这些技术的目标是将单体应用拆解为更小、更独立、更具弹性的微服务,并高效部署、扩展和管理。
然而,随着大模型(LLM)的崛起,出现了全新的计算实体——自主智能体(Autonomous Agent)。Agent 的行为不再由确定性代码驱动,而是由目标和模型共同决定,具备自主规划、推理、决策和工具调用能力。AI 软件工程师 Agent 的工作流,变成了动态、长周期、充满不确定性的“思考 - 行动”循环。
这种转变促使我们重新审视云原生基础设施。传统虚拟机和容器因资源占用高、启动慢、闲置成本高,难以满足 Agent 对极致弹性和成本效益的需求。Serverless 架构也难以承载需要长时上下文和复杂交互的 Agent。AI 应用亟需原生的运行时基础设施。
Agentic AI 应用的典型场景
为更好理解 AI 原生应用需求,以下以企业落地场景为例,拆解典型应用的业务行为。
- 交互式智能内容创作助手:支持多轮对话、上下文记忆、模型自托管、异构任务流和流式响应。
- 个性化 AI 客服:事件驱动、企业数据整合、实时在线。
- 通用 Agent 平台与 AIGC 创意应用:Agent 智能体生成代码,代码执行验证,支持部署与分享,脉冲式流量和大文件处理。
这些场景共同特征是会话式、工具增强、事件驱动、异构算力和极致弹性。
AI 原生应用运行时的核心能力
AI 应用的共同需求,要求运行时具备以下核心能力:
- 面向会话的状态管理与安全隔离:为每个 Agent 会话提供完全隔离且状态持久的运行时,采用硬件虚拟化(如 MicroVM)确保安全边界。
- 大规模实时弹性与精益成本管理:支持毫秒级启动和弹性扩缩容,按真实工作量计费,区分 Active/Idle 状态,降低闲置成本。
- 异构算力与标准化工具连接能力:支持 CPU/GPU/XPU 等异构资源池化调度,原生支持 MCP、A2A 等协议,具备异步处理和平台级错误处理能力。
下图展示了 AI 原生应用运行时的核心能力:
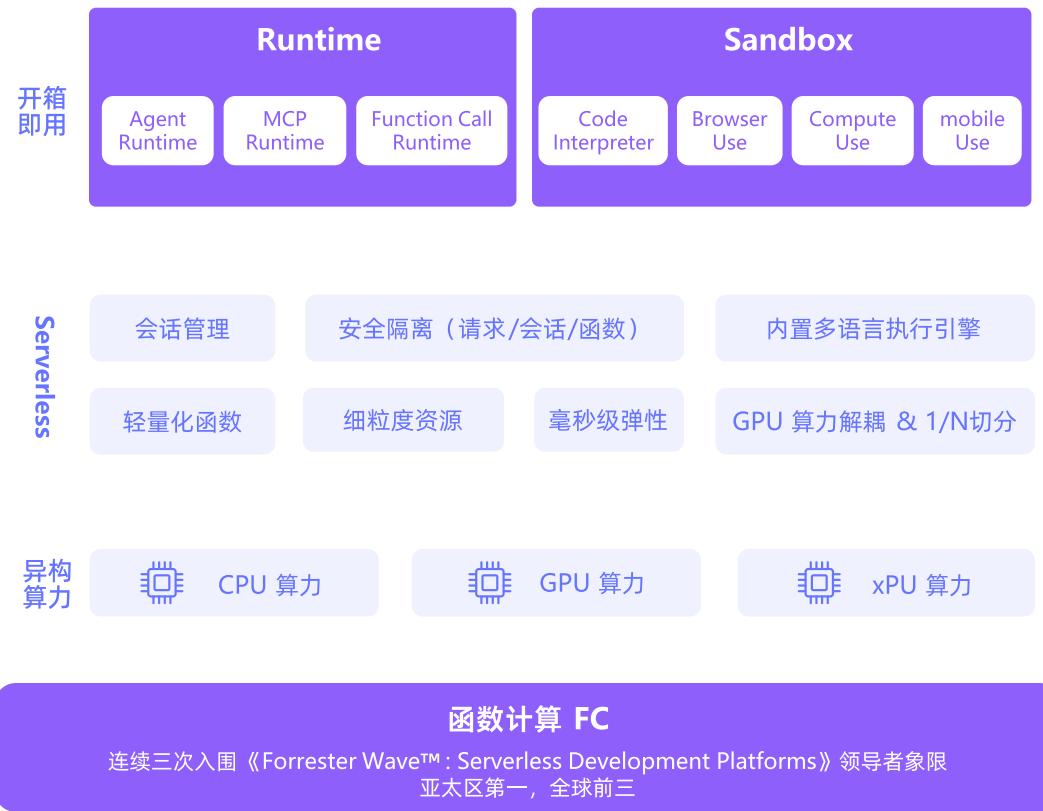
模型运行时
模型是 AI 应用的核心基石。企业在模型部署上面临 MaaS 与自托管两种路径权衡。Serverless 运行时成为模型的最优解。
企业模型使用的核心痛点
- 资源浪费:如景区 AI 生图,流量波动大,传统方案需预留峰值 GPU,导致高闲置成本。
- 冷启动延迟:如儿童阅读 App,长尾模型冷启动慢,影响用户体验。
- 定制化困境:如智能家居企业,模型部署与迭代周期长,创新受限。
Serverless 模型运行时以无服务器理念重塑 AI 生产关系,开发者专注创新,企业破解算力困局,产业实现规模化普及。
Serverless 模型运行时的核心能力
- 异构算力和 1/N 卡切分:GPU 虚拟化将单卡切分为多个独立单元,提升利用率,降低成本。
- 负载感知调度和毫秒级闲置唤醒:实时监测负载,优先分配活跃实例,利用 CRIU 技术实现毫秒级恢复。
- 集成加速框架和开发工具链:预集成 vLLM、SGLang、TensorRT-LLM 等加速框架,提供 DevPod、在线 IDE、自动化部署等工具。
三层能力协同,极大提升吞吐量、降低成本,加速模型托管工业化。
Serverless 模型运行时——AI 大脑的终极载体
Serverless 模型运行时通过异构算力、智能调度和开发范式升级,让企业实现“所想即所得”的模型服务,无需担忧算力锁,专注智能创新。
智能体运行时
AI 应用形态的持续演进
- 请求 - 响应模式:无状态事务性任务,适合 Serverless/FaaS 架构。
- 对话模式:有状态协作式 Agent 应用,会话上下文贯穿交互生命周期,会话及状态管理成为架构核心。
Agent 运行时的核心架构目标
- 围绕会话请求和资源调度模型,维持长时运行的状态延续:以会话为原子单元,支持状态持久化和弹性扩展,实现逻辑生命周期与物理资源解耦。
- 实现面向 Active-Idle 资源管理,解决长时运行的成本困境:动态挂载/卸载昂贵计算资源,始终保持廉价状态资源在线。
现有架构支撑 Agent 运行时对比分析
下表对比了主流有状态 Serverless 架构模式的性能、成本和复杂性:
表格说明:对比三种主流有状态 Serverless 架构模式的状态范围、弹性效率、容错性、性能、开发复杂度、成本模型和理想场景。
| 技术方案 | 状态范围 | 弹性效率 | 系统容错性 | 业务性能 | 开发复杂度 | 成本模型 | 理想场景 |
|---|---|---|---|---|---|---|---|
| 状态外置适配无服务器架构 | 请求级,外部持久化 | 极高 | 高 | 中 | 中 | 按请求付费 + 状态存储 | 状态需求简单、对延迟不敏感 |
| 传统尽力会话亲和 | 会话级,内存中(脆弱) | 低 | 低 | 高 | 高 | 按请求付费(需预置实例) | 迁移需要粘性会话的遗留应用 |
| 平台原生状态抽象 | 实体级,平台持久化 | 高 | 高 | 中 | 低 | 按操作/状态存储付费 | 事件溯源、复杂工作流编排 |
分析与建议:业务状态外置适合简单场景,传统会话亲和为过渡方案,平台原生状态抽象适合复杂工作流和可靠状态管理。
为 AI 原生的“会话式”Serverless 运行时
阿里云和 AWS 等云厂商已原生支持会话管理和隔离,动态分配专用实例,支持会话生命周期管理、优雅升级与灰度发布、匹配运行特征的成本模型,实现“一个会话,一个独立运行时”的架构。
工具与云沙箱
AlAgent 与工具:从概念到能力
AI 工具已从简单 API 调用演变为需要复杂运行时的执行环境。下表总结了 Agent 常用工具类型及其运行时需求。
表格说明:列举常见 AI 工具类型、描述及核心运行时需求。
| 工具 | 描述 | 核心运行时需求 |
|---|---|---|
| MCP (模型上下文协议) | 实现互操作性,允许 LLM 通过结构化 API 动态理解并调用外部工具。 | 稳健的 API 服务与运行时紧密集成,具备弹性能力 |
| File Search (文件搜索/检索) | 在私有文档库中执行语义检索,实现 RAG。 | 高效向量检索服务,上下文缓存 |
| Image Generation (图像生成) | 文生图和程序化图像处理,将自然语言转为视觉内容。 | 高性能计算、异构算力 |
| Code Interpreter (代码解释器) | 提供有状态、沙箱化的多语言执行环境,支持复杂计算和程序化任务。 | 强隔离与安全、持久化会话、科学计算环境 |
| Browser Use (浏览器使用) | 编程方式控制 Web 浏览器实例,执行网页自动化任务。 | 强隔离、会话管理、可观测性与人机协同 |
| Computer Use (计算机使用) | 视觉代理与 GUI 交互,实现端到端自动化。 | 强隔离、完整操作系统、会话管理、可观测性 |
| Mobile Use (移动端使用) | 赋予操作系统语义理解和跨应用操作能力。 | 专用、持久化运行时,支持会话管理 |
复杂工具如代码解释器、浏览器和计算机使用,需有状态、沙箱化环境。AI Sandbox 提供安全保障,是 Agent 商业化的基础设施。
复杂工具运行时的核心诉求
Agent 的出现,对底层的运行时环境提出了三大根本性的、前所未有的技术挑战。这些挑战解释了为何传统基础设施无法高效、安全地支持复杂的 AI 工具运行时。
隔离与安全(Isolation & Security):这是首要且不容妥协的要求。执行由 LLM 动态生成且不可信的代码,引入了巨大的安全漏洞,例如沙箱逃逸、代码注入和权限提升等。传统的软件沙箱技术在应对这种动态、复杂且可能具有对抗性的 AI 工作负载时,正变得力不从心,漏洞频发证明了其不足。Agent 对运行时隔离性的要求达到了前所未有的高度。
状态管理与成本(State Management & Cost):Agent 的工作模式是对话式和持续性的,这需要每个沙箱都拥有一个持久的、有状态的会话来维持上下文、记忆和交互环境。这种特性与传统无状态的 FaaS(函数即服务)设计产生了根本性冲突。若为每一个潜在的用户会话都预置一个长期运行的虚拟机(VM),将导致惊人的闲置资源成本和巨大的运维负担。
可扩展性与运维(Scalability & Operations):Agent 应用的流量往往是突发且不可预测的。基础设施必须能够瞬时、动态地扩展以应对峰值,并在空闲时迅速缩减以节约成本。然而,从零开始构建并维护一个既安全隔离又具备弹性伸缩能力的沙箱环境,需要极其专业的 DevOps 知识和大量的人力投入,这对大多数开发团队而言都是一个难以逾越的障碍。
上述挑战共同指向一个结论:Agent 的兴起催生了一种独特的云工作负载类型,它不完全符合传统 FaaS 的模式,也对现有的 FaaS 平台在状态管理和隔离性上提出更高的要求,使其兼具虚拟机级的强隔离、状态化管理与 Serverless 的极致弹性与经济性。
Serverless 作为 Al Sandbox 的理想基座
Serverless 平台通过底层架构演进,成为 AI Sandbox 的理想基座:
- 计算隔离:硬件级与内核级双重保障,MicroVM 安全容器实现端到端隔离。
- 会话管理:原生支持有状态应用,强会话亲和、物理隔离和管理接口。
- 存储隔离:快照技术实现本地临时存储极速恢复,会话级存储亲和和多租户安全实践保障数据隔离。
- 极致存储性能:支持高性能存储盘动态挂载,满足高 I/O 需求。
AI 应用运行时的降本路线
AI 应用计费方式的演进,反映了 Serverless 产品形态与用户价值的深度对齐。
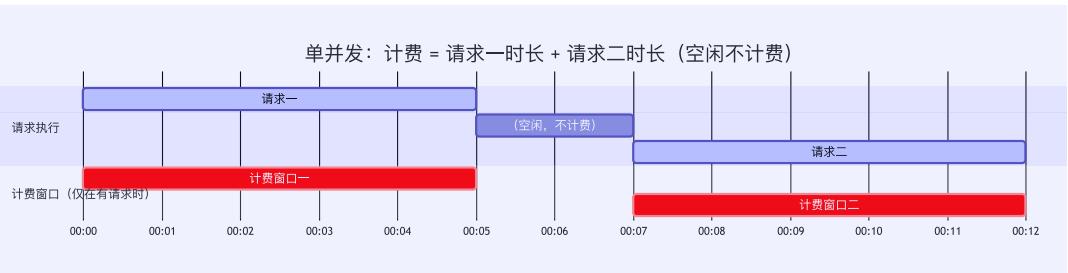
阶段一:从资源租用到按请求计费
Serverless 函数计算的最大突破是按请求计费,用户只为实际调用付费,无需承担闲置成本。
下图展示了按请求计费模式的技术支撑:
阶段二:多并发 + 毫秒级计费
为适配 Web 应用,Serverless 支持多并发和 1ms 计费粒度,按活跃区间计费,降低成本。
下图展示了多并发和毫秒级计费的演进:
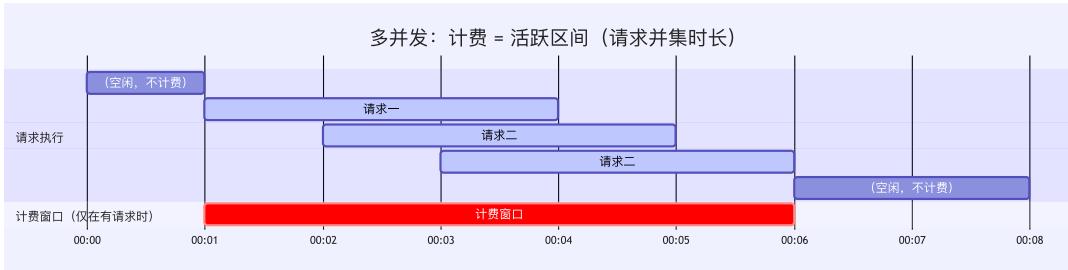
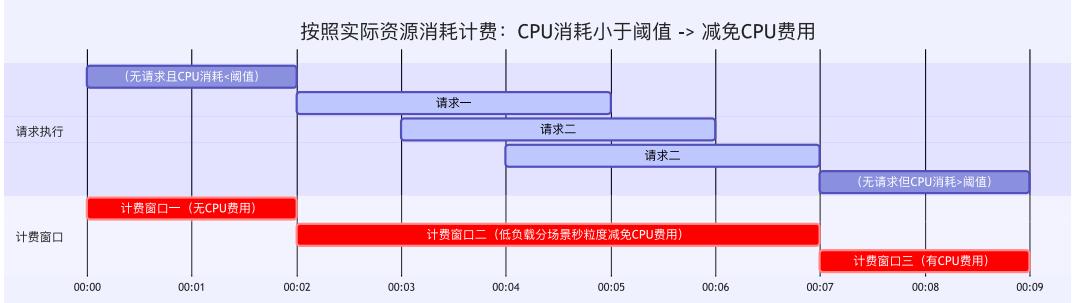
阶段三:按实际资源消耗计费——AI 时代的价值计费
AI 应用长会话、强交互、低延迟,需按实际资源消耗动态区分活跃/闲置,低负载减免 CPU 费用,支持后台任务持续运行。
下图展示了按资源消耗分层计费的演进:
函数计算的演化方向
阿里云函数计算计费方式经历三个阶段:
- 按请求计费:降低门槛,只为调用付费。
- 活跃区间计费:扩展场景,适配 Web/API 应用。
- 按资源消耗计费:贴近价值,适配 AI 长会话与强交互负载。
Serverless 让开发者专注业务逻辑,云厂商自动完成资源管理与调度,实现“计算即服务,按价值付费”。
总结
AI 应用运行时正从云原生向 AI 原生演进,Serverless 架构和会话式运行时成为智能体和模型高效、安全、弹性运行的关键。通过异构算力、智能调度、状态管理和成本优化,企业能够专注创新,释放 AI 生产力。未来,AI 原生运行时将持续推动智能应用和 Agent 生态的繁荣。
参考文献
- Higress 官网 - hgress.ai
- 阿里云内容安全文档 - aliyun.com
- Sequoia Capital - AI Ascent 2025
- Higress 社区文档 - github.com/alibaba/higress