第 8 章:AI 可观测性
AI 可观测性是保障 AI 应用性能、安全与可靠性的基础能力,通过全链路追踪和全栈观测,开发者能够高效定位问题、优化成本并提升系统稳定性。
AI 可观测的挑战与应对方案
随着 AI 应用的广泛部署和复杂性提升,深入洞察其内部行为变得尤为重要。AI 可观测性应运而生,通过方法论和工具,帮助开发者监控性能、调试问题,并提升内容输出的可用性、安全性与可靠性。
什么是 AI 可观测
AI 可观测性是一系列让工程师全面洞察基于大语言模型(LLM)应用的实践与工具。它不仅追踪系统性能,更深入探究模型“在做什么”以及“为什么这么做”。这种全面的方法对于确保 AI 应用的健康、性能和安全至关重要。借助可观测工具,团队可以观测响应质量、延迟、异常行为等,及时发现和修复问题。
AI 应用具有非确定性,即便相同提示在不同运行中也可能产生不同输出。没有可观测能力,幻觉、虚假等严重问题难以定位。优秀的可观测工具会记录每一次提示与响应、追踪使用模式并标记异常,为工程师提供宝贵洞察,优化性能并修复安全风险。
可观测 vs. 监控:从“是什么”到“为什么”
在 AI 应用背景下,区分“可观测”与“监控”非常重要。
监控:关注“什么”
监控聚焦于“发生了什么”,追踪关键性能指标(KPIs)和系统健康状况,如 API 响应时间、错误率、请求吞吐量和 Token 使用量等。一旦指标超出阈值,监控工具会发出警报,帮助工程师迅速响应。监控回答的问题是:“AI 应用当前是否有问题?”可观测性:探究“为什么”
可观测性深入挖掘指标背后的“为什么”。它将性能指标与日志、事件和链路信息(Trace)关联,支持每一次请求的全链路追溯,包括工具调用、Prompt、数据库/API 调用及最终输出。可观测工具为排查和定位问题根因提供丰富上下文。例如,监控只显示“错误率上升”,可观测则揭示具体原因,如 RAG 请求召回错误导致模型输出不准确。
总结来说,监控告诉你“出问题了”,可观测帮助你理解“为什么出问题以及如何修复”。两者缺一不可,监控提供早期预警,可观测提供深度诊断。
AI 可观测应对的核心挑战
AI 应用面临一系列传统软件没有的独特挑战,主要包括:
- 性能与可靠性问题:大模型资源密集,延迟峰值和瓶颈常见。可观测性将所有组件数据关联,帮助精确定位延迟根源,简化复杂系统调试。
- 成本问题:大模型服务按 Token 计费,若无控制成本易飙升。可观测工具追踪每个请求的 Token 数、总用量等,异常高峰时及时预警,帮助优化和限制成本。
- 质量问题:大模型输出可能继承偏见、产生幻觉或不当内容。可观测通过自动评估工具检测输入输出的准确性和安全性,及时发现并处理风险。
AI 可观测解决方案的关键能力
为应对上述挑战,高效的 AI 可观测解决方案应具备以下能力:
- 端到端全链路追踪:采集日志和链路信息,可视化展示请求在整个 AI 应用中的执行路径,支持历史对话灵活查询与筛选。
- 全栈可观测:覆盖应用、AI 网关、推理引擎等维度,观测响应延迟、吞吐量、Token 消耗、错误率和资源使用等,指标异常时触发警报。
- 自动化评估功能:引入评估 Agent,对输入输出进行自动化评估,检测幻觉、不一致或答案质量下降等问题,集成评估模板便于快速检测。
后续章节将详细介绍端到端链路追踪、全栈可观测和自动化评估的实现与实践。
端到端全链路追踪
一个典型的 LLM 应用架构包含用户终端、认证模块、会话管理、对话服务、大模型路由、流程编排等。模型推理应用还可能对接不同大模型服务、外部工具、向量数据库和缓存等。
为应对链路复杂性,保障 SLA 和用户体验,需要具备如下可观测能力:
- 标准化数据语义规范(如 LLM Trace/Metrics 领域语义,记录 Input、Output、Prompt、Token、TTFT、TPOT 等)。
- 低成本高质量数据采集(如 OpenTelemetry Agent 实现无侵入采集)。
- 端到端全链路追踪(基于 OpenTelemetry W3C 协议,实现用户终端、AI 网关、模型应用、外部工具、模型服务的全链路 Trace 串联)。
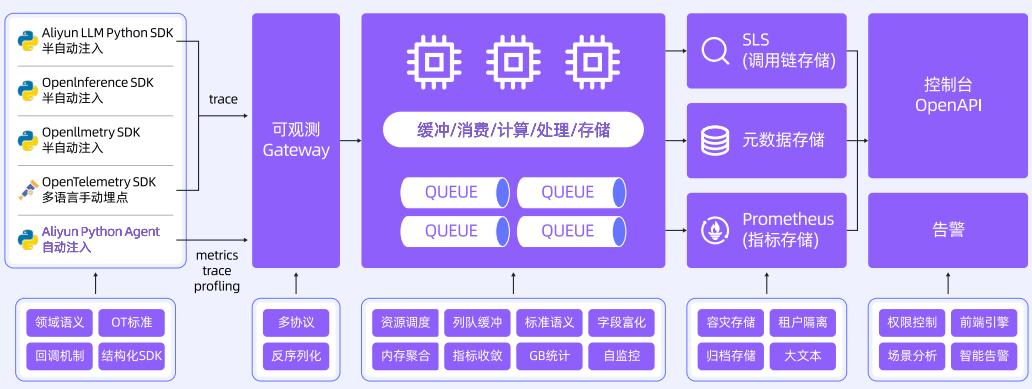
下图展示了端到端全链路追踪的典型架构:
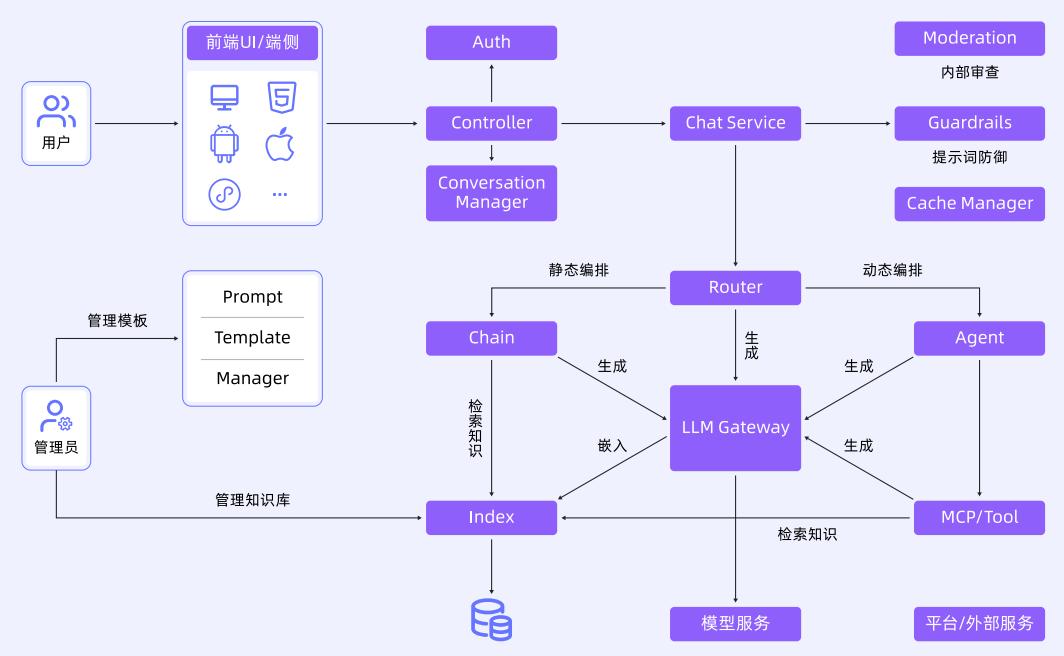
端到端全链路追踪的实现方式
基于 OpenTelemetry 标准,通过 Trace 领域化语义增强、低成本高质量数据采集、标准化协议透传等,实现从用户终端到模型推理层的完整调用链路追踪。
领域化 Trace 语义:以会话串联用户交互过程,Trace 承载全链路交互节点,定义标准化操作语义和存储,如 Input、Output、Prompt、Token、TTFT、TPOT 等字段,便于性能和成本分析。
多语言兼容与采集:兼容 OpenTelemetry Python/Java/Go Agent 等多客户端接入,增强大模型领域语义规范与数据采集,自动采集 LLM 调用参数、Token 数、TTFT/TPOT 等指标。
标准化协议透传:兼容 OpenTelemetry W3C 协议,实现跨语言、跨组件链路透传。
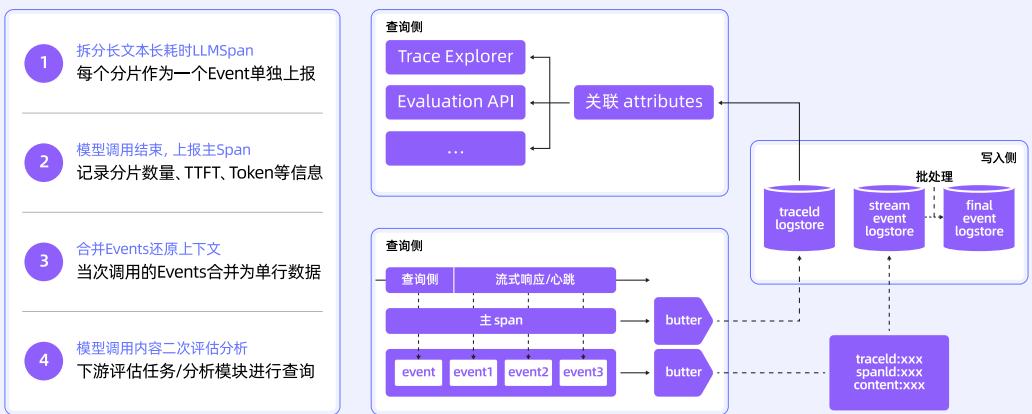
相关技术架构和采集流程如下图所示:
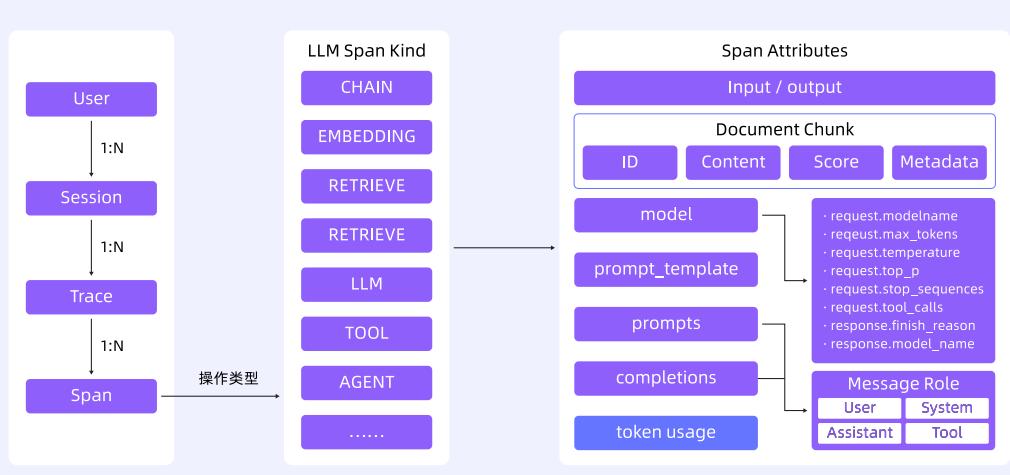
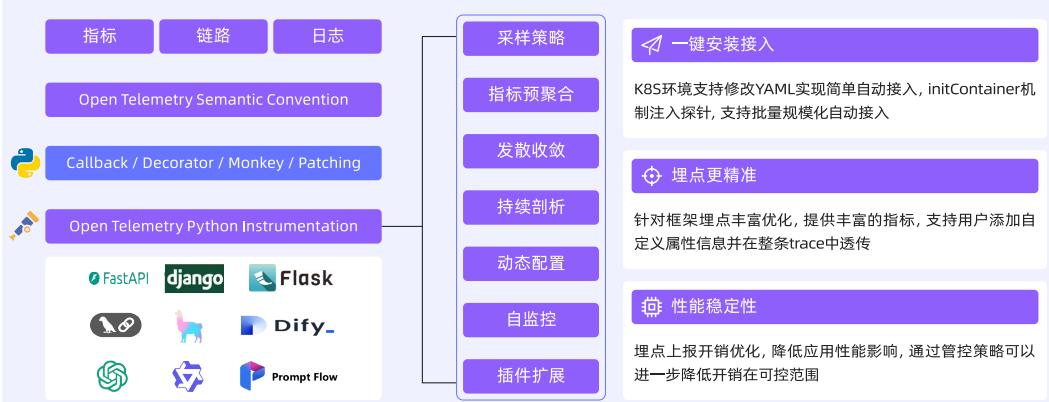
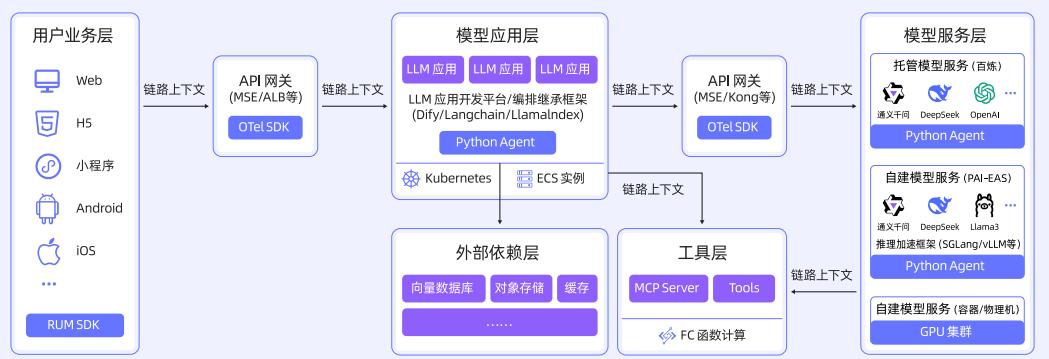
核心技术路径
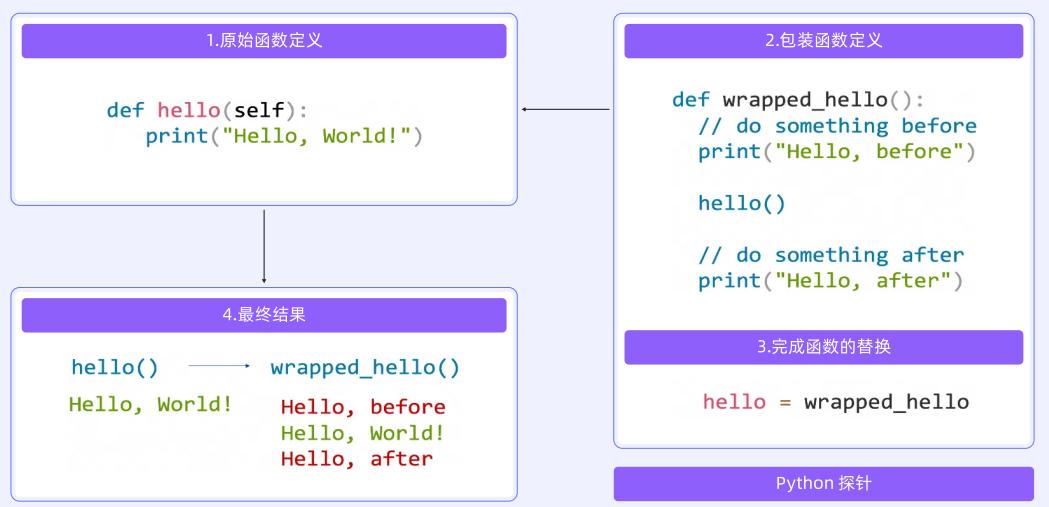
链路插桩技术:Python 采用 MonkeyPatch 装饰器实现无侵入埋点,支持 LlamaIndex/Dify/LangChain 等主流框架。Java 通过字节码增强拦截 SpringBoot 应用,Go 通过编译时插桩自动埋点。其他语言通过 OpenTelemetry 框架支持。
链路采集与加工:统一数据处理链路,开放可观测数据标准,线性化处理架构,支持 Trace 直连上报和日志转 Trace。流式场景采用客户端分段采集 + 服务端合并还原,拆分长 Span 为 Event 分片,合并还原完整上下文。
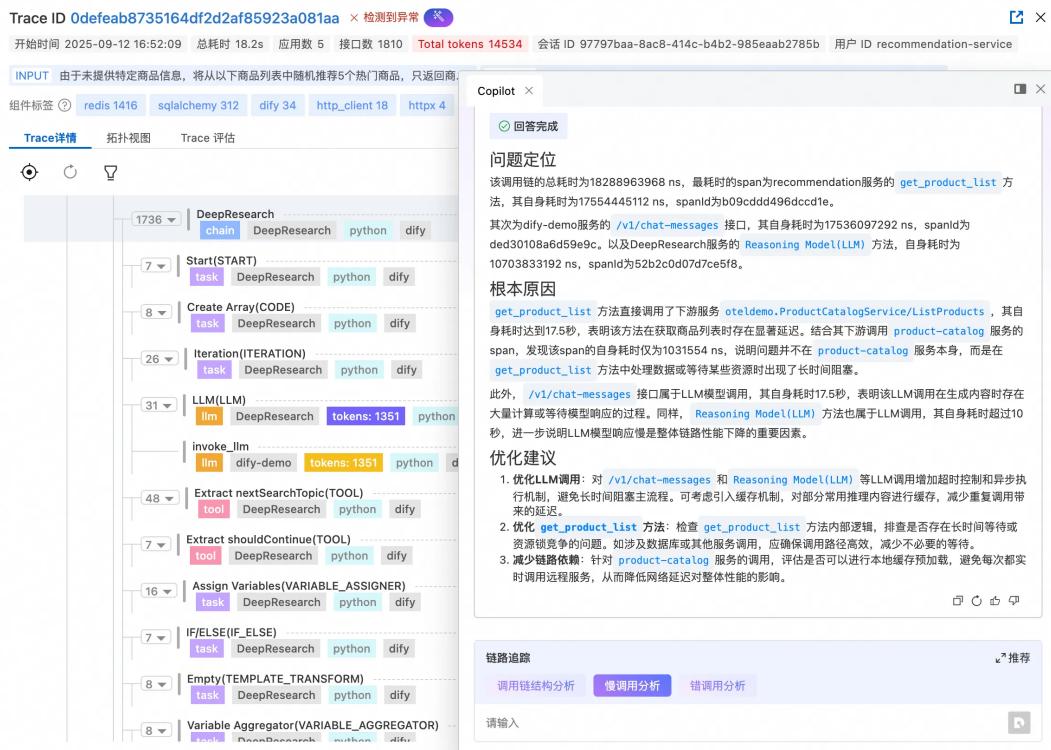
Trace 查询与分析:通过 TraceID 串联用户请求路径,展示 LLM 调用输入/输出、Prompt 模板、模型参数等,支持按状态、耗时、Span 类型筛选,并可基于大模型实现智能诊断。
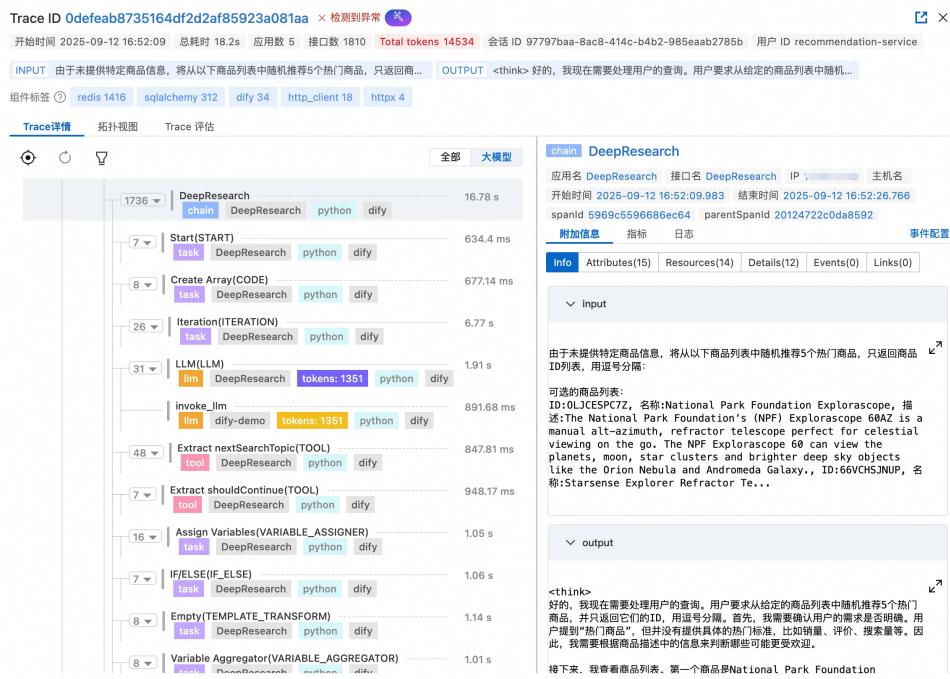
相关流程和界面如下图所示:
全栈可观测:应用可观测
端到端全链路追踪为全栈可观测奠定基础。以下从应用、AI 网关、推理引擎三个维度,分享全栈可观测的场景、能力和实践。
AI 原生应用开发的痛点
开发智能体与 MCP 应用时,常见痛点包括:
- 工具选择盲区:Agent 选择不合适工具,缺乏可视化分析手段。
- 错误排查困难:参数错误难以快速定位根因。
- Token 消耗黑洞:多轮交互易产生大量 Token 消耗,缺乏实时成本监控。
- 循环调用陷阱:Agent 可能陷入工具循环调用,难以及时发现和中断。
AI 原生应用可观测需要具备哪些能力
AI 应用接入全链路可观测,应具备以下能力:
- 零代码接入,开箱即用的监控能力。
- 可视化工具选择过程,深度集成 MCP 协议。
- 精准故障定位,链路信息快速锁定问题根源。
- Token 成本分析,精确监控和成本关联。
- 端到端链路追踪,完整展示调用链路,快速定位异常模式。
场景演示架构
下图展示了智能日志分析助手的架构,演示如何监控基于 LangChain 的 Agent 及其调用的 MCP 服务器。
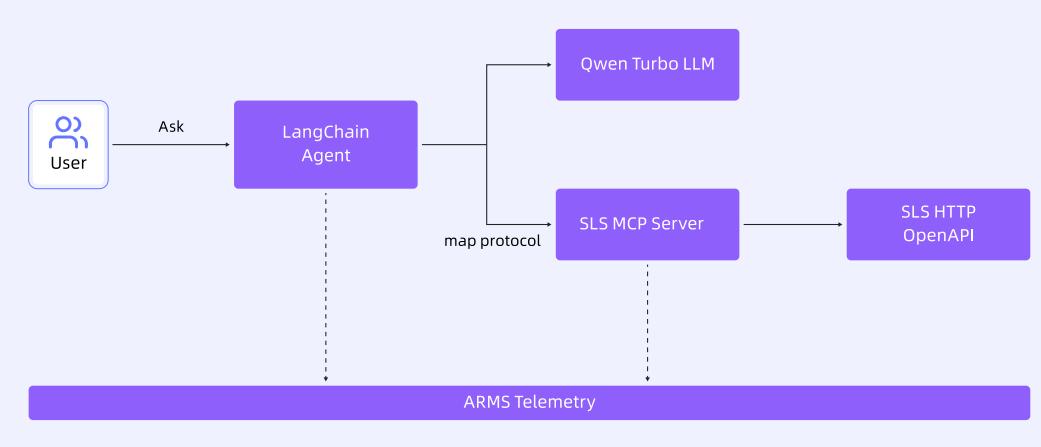
场景演示
启动 SLS MCP 服务器,在本地启动阿里云可观测 MCP 服务器。

图 11: 启动 SLS MCP 服务器 启动 LangChain Agent 程序,创建 Agent 并向其提问,Agent 使用 SLS MCP 服务处理日志分析请求。
Agent 观测:在可观测平台(如阿里云 ARMS)查看 LangGraph 的 Span 列表,分析调用次数、输入输出、Token 消耗等。
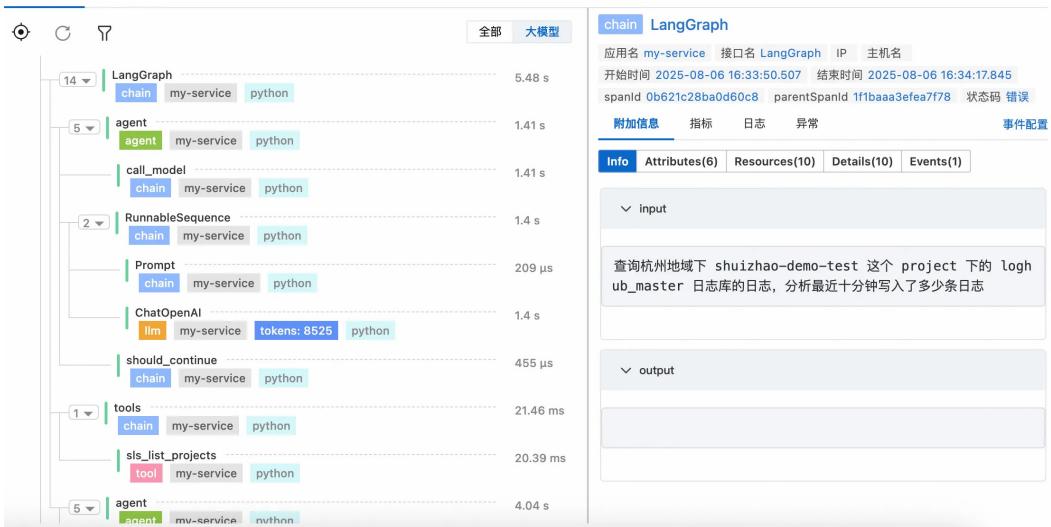
图 12: Agent 观测界面 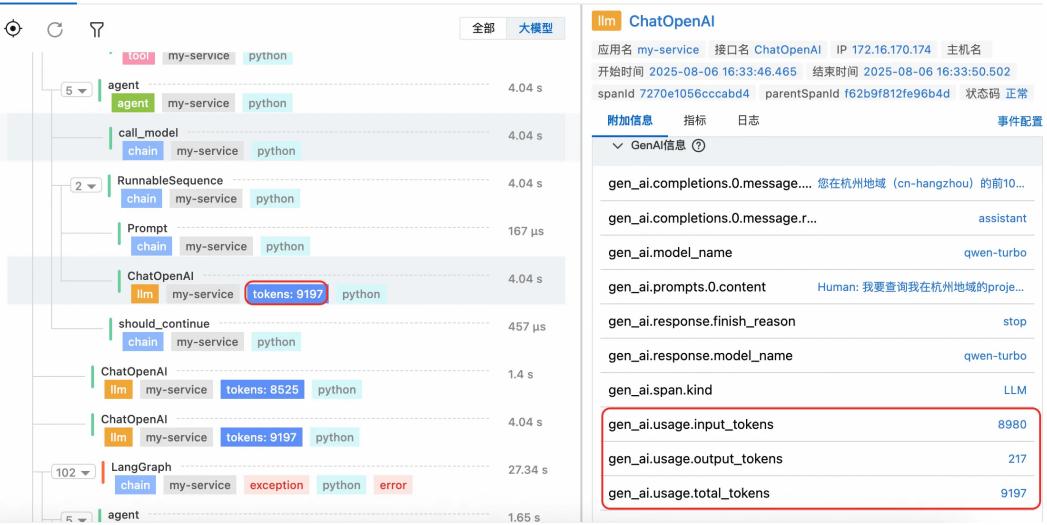
图 13: Token 消耗分析 MCP 观测:监控 MCP 调用链路,分析完整调用过程、服务地址、协议、参数、返回体大小等。
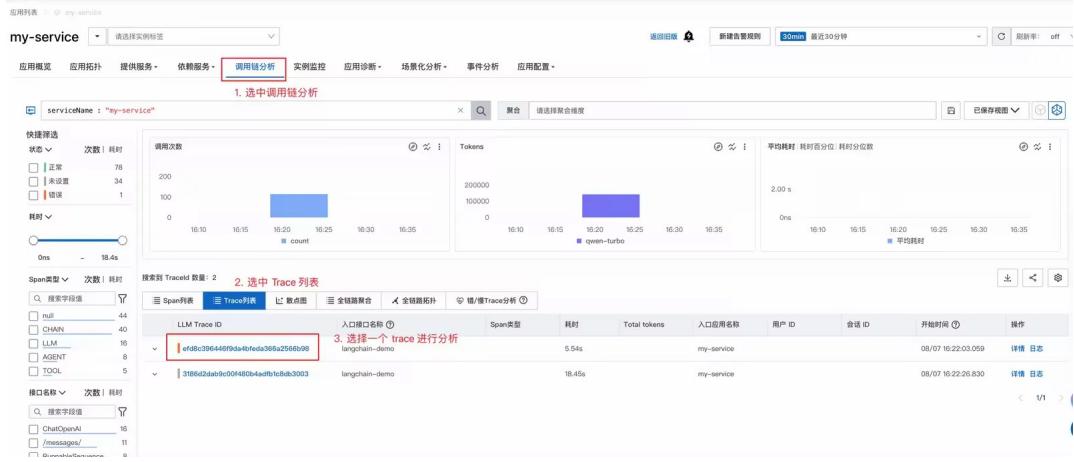
图 14: MCP 调用链路分析 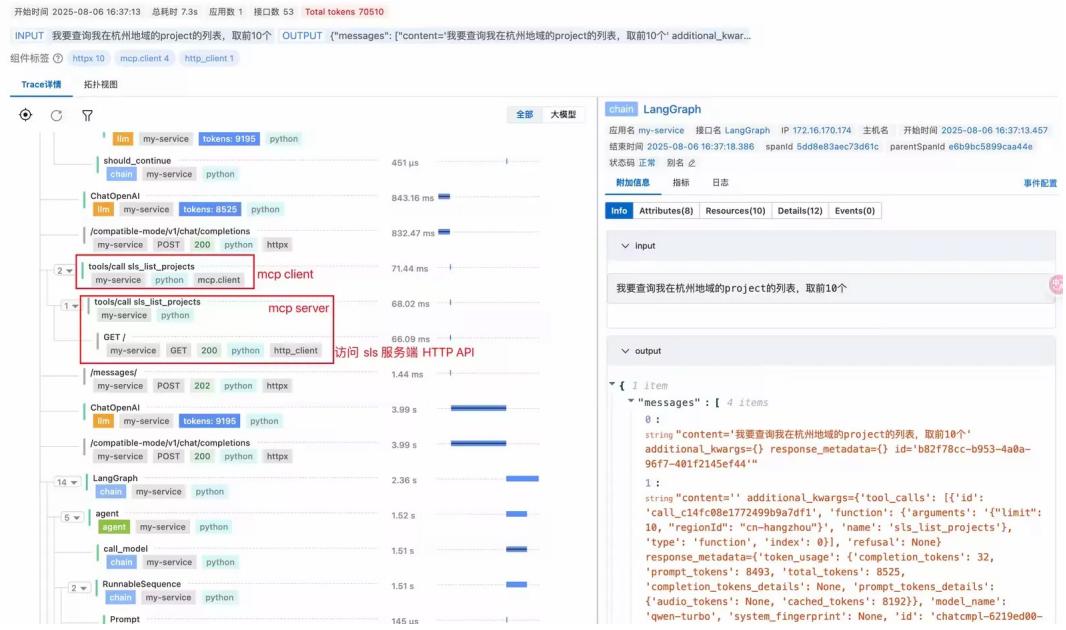
图 15: MCP 详细信息
本节展示了通过常见智能体框架搭建 AI 原生应用遇到的典型问题,以及可观测工具如何解决,最后通过 LangChain Agent 调用本地 MCP Server 的例子,展示了全流程全栈监控。
全栈可观测:AI 网关可观测
AI 网关作为统一接入与治理中枢,承载模型路由、鉴权、限流、缓存等关键能力,其运行状态直接影响 AI 应用质量与效率。构建围绕 AI 网关的可观测体系,实现对请求流量、资源消耗、安全风险与治理策略的全面监控,是保障 AI 能力可靠输出的核心基础。
观测场景:AI 组件的多维可观测需求
AI 组件的可观测性涵盖性能、资源、安全、成本、治理等多个层面。以下从 5 个典型场景揭示企业在使用 AI 网关过程中的可观测需求。
- 性能与稳定性监控:采集 QPS、请求成功率、响应时间、流式与非流式请求分布等指标,支持实时监控和告警。
- 资源消耗与成本分析:统计每个 API、消费者、模型的 Token 消耗,结合缓存命中率评估成本节省效果。
- 安全与合规审计:记录内容安全拦截日志、风险类型统计、风险消费者统计,满足合规要求。
- 治理策略执行追踪:记录限流、缓存命中、Fallback 执行路径等,验证治理策略实际效果。
- 多租户与权限治理:支持消费者身份识别、指标统计、异常检测,实现资源配额和行为审计。
观测实践:基于 AI 网关的可观测体系构建
观测数据采集:AI 网关作为统一入口,采集指标(如 QPS、RT、Token 消耗)和日志(请求上下文、Prompt、Response、状态码、模型名、消费者 ID、缓存命中等)。
可视化监控:构建多维度、分层级、可下钻的仪表盘,顶层展示全局关键指标,下层按实例、API、消费者等维度展开。

图 16: AI 网关可观测仪表盘 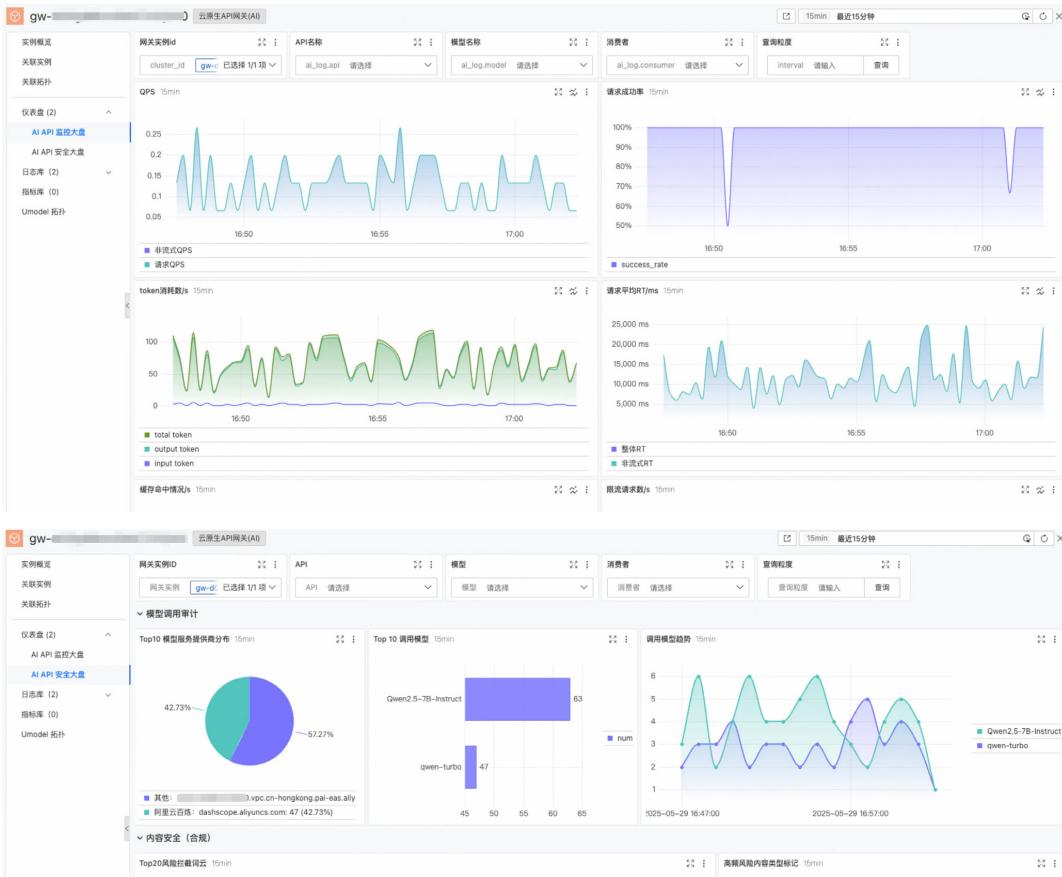
图 17: 多维聚合分析 深度分析:通过日志查询和 SQL 分析,灵活检索失败请求、缓存命中影响、风险来源等,挖掘隐藏模式与异常。
智能告警与自动化响应:基于关键指标设置告警规则,联动自动化脚本进行初步处置。
成本优化与治理闭环:定期生成资源使用报告,制定优化策略,形成“监控→分析→优化→再监控”的治理闭环。
AI 网关作为可观测体系核心载体,正在重新定义企业对 AI 服务的管理方式。
全栈可观测:推理引擎可观测
LLM 推理引擎(如 vLLM、SGLang)是 AI 服务基础架构的关键组件,负责优化 LLM 性能、管理硬件资源、提供分布式能力等。推理引擎的可观测性对于监控性能、检测问题和优化系统至关重要。
推理引擎需要观测什么
以 vLLM 为例,其整体架构如下图所示:
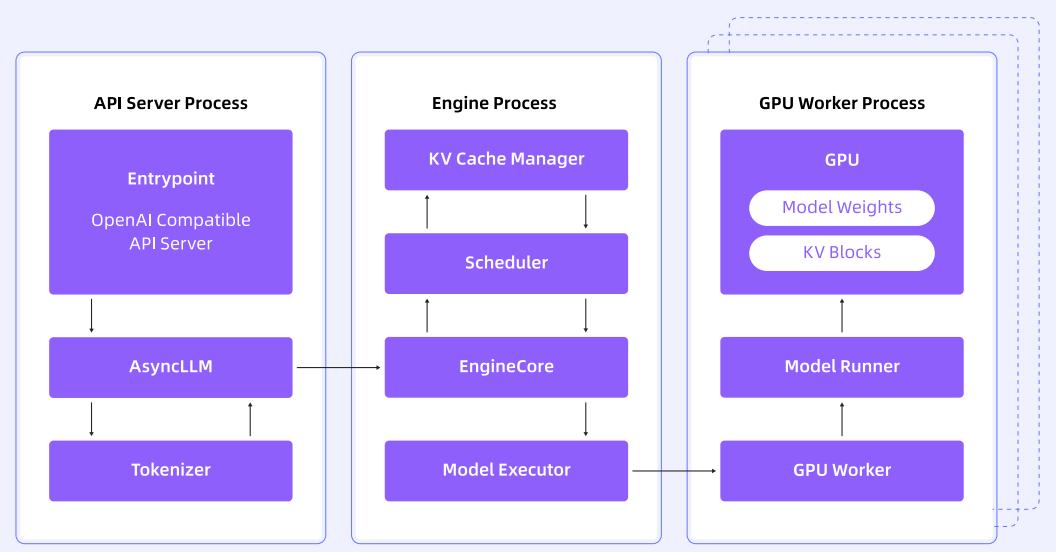
图片来源: Life of an inference request (vLLM V1): How LLMs are served efficiently at scale
vLLM 由 API Server、Engine、GPU Worker 组成,分别负责 HTTP 服务、KV Cache 管理与调度、GPU 推理等。每个组件在请求生命周期中协同工作,实现高性能服务。
推理引擎常见可观测项如下表所示:
表格说明:推理引擎各组件常见可观测项及含义。
| 组件 | 观测项 | 含义 | 示例 |
|---|---|---|---|
| API Server | 路径 | 请求的路径 | /v1/completions |
| 状态码 | 请求处理状态 | 200/400 | |
| 客户端 | 客户端类别 | Chrome/HTTP Client | |
| 耗时 | 请求处理时间 | 1s | |
| 模型输入输出 | 提示词 | 用户输入 | 杭州哪里好玩? |
| 响应方式 | 是否流式发送 | Stream/None Stream | |
| 模型名称 | LLM 名称 | Qwen/Qwen2.5-0.5B | |
| 最大 Token 数 | 生成 Token 上限 | 1000 | |
| 温度 | 控制生成随机性 | 0/0.5/0.9 | |
| Top-K | 保留概率最高 K 个词 | 3/5 | |
| Top-P | 概率累积阈值 | 0.5/0.9 | |
| N | 返回建议答案数量 | 1/3 | |
| 推理过程 | E2E 时间 | 推理总时间 | 1s |
| 首 Token 时间 | 生成第一个 Token 时间 | 1s | |
| Prefill 时间 | Prefill 阶段耗时 | 1s | |
| Decode 时间 | Decode 阶段耗时 | 1s | |
| 等待时间 | 调度器等待时间 | 1s | |
| Token 间隔时间 | 输出 Token 间隔 | 1s | |
| 推理引擎状态 | 运行中请求数 | 正在推理的请求数 | 2 |
| 等待请求数 | 等待调度的请求数 | 2 | |
| 被抢占请求数 | 被调度出 GPU 的请求数 | 5 | |
| KV Cache 使用率 | KV Cache 使用率 | 90% | |
| 总提示词 Token 数 | 所有请求提示词 Token 总数 | 1000 | |
| 总生成 Token 数 | 所有请求生成 Token 总数 | 1000 | |
| 处理成功的请求数 | 已成功处理请求数 | 1000 |
推理引擎可观测的实践
首 Token 时间(TTFT)对客户体验影响较大。TTFT 受提示词长度、并发排队、KV Cache 使用率等多因素影响。优化建议包括:
- 提高 GPU 显存分配,降低 KV Cache 使用率。
- 增加显卡提升并发处理能力。
- 优化提示词长度,提升响应速度。
- 升级推理引擎版本,获得结构和调度优化。
结合分布式调用链系统,开发人员可深入洞察延迟问题,准确定位性能瓶颈,持续优化 AI 应用性能。
总结
AI 可观测性是保障 AI 应用高效、安全、稳定运行的核心能力。通过端到端全链路追踪、全栈可观测和自动化评估,开发者能够高效定位问题、优化成本、提升系统可靠性。未来,AI 可观测体系将持续演进,助力企业构建智能化、可治理的 AI 应用基础设施。
参考文献
- OpenTelemetry 官网 - opentelemetry.io
- Higress 社区文档 - github.com
- vLLM 项目主页 - github.com
- 阿里云应用实时监控服务 ARMS - aliyun.com