第 9 章:AI 评估
AI 评估是降低应用不确定性、提升系统性能与信任的关键环节,贯穿 AI 生命周期,助力企业实现高质量智能化落地。
基于评估降低 AI 应用的不确定性
AI 应用的非确定性和幻觉问题,要求我们建立系统性的评估体系。阿里云 CIO 蒋林泉在 2025 AIcon 全球人工智能开发与应用大会提出 RIDE 方法论,其中 Execute 阶段强调评估系统的重要性。大模型时代,评测没有标准答案,评估成为落地的瓶颈和“品味”的体现。
从确定性到不确定性
传统软件研发依赖测试保障输入输出的确定性,准确率需接近 100%。而 AI 应用本质上是概率性系统,行为非确定、上下文相关,输出不可预测。模型发布速度快、投资巨大,传统 QA 流程难以应对数据驱动、自适应系统的挑战。评估成为 AI 应用全生命周期的持续性、战略性要务。
幻觉和不确定性的根因
AI 应用的非确定性源于其概率性架构和训练方法。模型基于统计模式预测下一个词,创造力与不可靠性并存,易产生“幻觉”——听起来合理但实际错误的输出。
幻觉和不确定性根因包括:
- 数据缺陷:模型知识受限于训练数据,数据不完整或有偏见会被继承和放大,无法提供训练外信息。
- 架构与建模:Transformer 架构和训练过程鼓励模型在信息不足时“猜测”,过拟合和注意力机制失效也会引入不确定性。
- 错位与不确定性:模型知识正确但与用户指令不对齐,导致输出偏差。即使高置信度下也可能产生幻觉,难以检测。
AI 评估的重要性
系统性评估是 AI 治理的基石,支撑风险识别、流程验证与模型持续优化,防止偏见、幻觉或失效决策带来损失。尤其在高风险领域,缺乏本地化评估可能导致严重后果。
评估是构建信任的核心机制,负责任 AI 实践(公平性、透明度、可解释性、问责制)需通过可度量评估实现。严格评估直接转化为竞争优势,助力企业加速创新、控制成本、提升市场竞争力。
AI 的非确定性催生了评估经济,评估成为持续工程实践,标志着 AI 原生时代质量保障的新范式。
AI 评估体系
建立清晰的分类框架是理解和应用 AI 评估的前提。AI 评估由多种目标、方法和场景构成,涵盖基础二分法、静态与动态评估、多范式全景等。
评估方法的基础二分法
AI 评估可从对象(内在/外在)和执行者(自动化/人工)两个维度理解。
- 内在评估:孤立评估模型输出的固有质量,如流畅性、连贯性、语法、事实准确性。优势是细致洞察模型能力,缺点是难以反映真实应用效用。
- 外在评估:衡量模型在特定下游任务或应用中的表现,如提升办公效率。优势是反映真实场景性能,缺点是依赖特定任务,泛化能力有限。
- 自动化评估:利用 BLEU、ROUGE 等指标或 LLM-as-a-judge 自动打分,优势是高可扩展性、低成本和一致性,难以捕捉主观和复杂上下文。
- 人工评估:依赖人类评估员判断,适合主观维度,是“黄金标准”,但成本高、难以规模化,易受主观影响。最佳策略通常是自动化与人工评估结合。
从静态到动态评估的演进
随着模型能力提升,静态评估方法局限性凸显,推动向动态评估演进。
- 静态基准:如 GLUE、SuperGLUE、MMLU,推动技术进步,但易被模型记忆或饱和,难以反映真实能力差异。
- 动态评估:模拟真实场景复杂性,通过变量变化、意外输入和演进上下文测试系统。包括基于模拟的测试、实时对抗性基准、程序化生成等,考察模型泛化、适应性和稳健性。
现代 AI 评估的多范式全景
当前 AI 评估领域由多个并存、甚至相互隔离的研究范式构成,主要包括:
- 基准测试范式:通过标准化数据集和指标排序比较,推动技术进步。
- Evals 范式:关注安全性和潜在危害,采用对抗性测试和红队演练。
- 心理测量学范式:评估 AI 系统内在潜变量,解释模型表现差异。
- 人机交互范式:关注可用性、用户满意度、人机协同效率和信任度。
- 形式化方法范式:用数学和逻辑工具对系统属性提供可证明保证,适用于安全攸关系统。
- 社会技术范式:分析 AI 系统对社会结构的影响,关注公平、就业和权力动态。
选择评估范式是战略优先级和风险偏好的体现。综合性元框架(如 HELM、NIST AI 风险管理框架)推动多指标、跨领域评估,避免单一维度缺陷,标志着 AI 评估学科走向成熟。
构建一个整体性的评估体系
一个强大而全面的 AI 评估体系是负责任创新的基石,贯穿 AI 生命周期,系统性验证模型性能、稳健性、公平性和合规性。综合行业最佳实践,完整评估体系应包含以下 8 个核心组件:
- 性能指标
- 稳健性与泛化测试
- 偏见与公平性评估
- 可解释性
- 合规性与伦理考量
- 持续监控与模型漂移检测
- 决策框架
- 自动化与人在回路
基于 LLM 的自动化评估
随着生成式 AI 能力提升,传统评估方法已难以满足需求,LLM-as-a-Judge 范式应运而生。
传统指标的局限性
BLEU、ROUGE 等传统指标基于词汇重叠,难以捕捉语义、风格、创造力等细微差别。人工评估虽为“黄金标准”,但成本高、周期长、主观性强,难以适应快速迭代。业界亟需兼具理解力、可扩展性和成本效益的新方法。
LLM-as-a-Judge 范式介绍
LLM-as-a-judge 利用强大 LLM 作为裁判,对模型输出评分、排序或选择,结合自动化可扩展性与人工评估细致性。
基本流程为:向裁判 LLM 提供模型输出、原始输入和评分指南,生成分数或判断。核心应用场景包括数据标注、实时验证和模型优化反馈,将主观偏好转化为结构化、可量化的评估函数。
LLM 裁判的评估模式
- 逐点评估:独立评估单个输出,给出绝对分数,可有参考或无参考。
- 成对比较:同时比较两个输出,判断优劣或等同,更符合人类认知,结果更稳定。
控制 LLM 裁判的负面影响
LLM 裁判引入自身偏见和局限性,需识别和缓解以保证评估公正性。
- 系统性偏见:包括位置偏见、冗长偏见、自我偏好偏见、情绪与语气偏见、评分粒度有限等。分数反映裁判模型偏好,需评估评估者本身。
- 递归依赖:LLM 裁判能力受限,无法评估比自身更强的模型,形成递归依赖。前沿领域需依赖人类专家和红队演练。
提升裁判可靠性的缓解策略
- 提示工程技术:如思维链、少样本提示、清晰评分指南,提升判断一致性。
- 结构化缓解措施:如交换位置、基于参考评分、约束输出格式,减少偏见。
- 基于模型的解决方案:如微调裁判模型、使用陪审团机制,提升稳健性。
- 高质量数据集:构建标准答案和 Bad Case 集合,持续优化评估流程。
自动化评估落地实践
搭建评估系统的痛点
实际落地评估系统面临数据采集、LLM Judger 准确性、Ground Truth 获取、领域指标定义、评估成本、数据预处理、可行动洞察等痛点。
评估系统的不同 Level
下表总结了评估系统能力的 5 个等级,从固定模板到智能 Agentic 评估,能力逐步提升。
| 能力项 | level 0.5 | level 1 | level 2 | level 3 | level 4 |
|---|---|---|---|---|---|
| 固定评估模板 | ✓ | ||||
| 人工指定 Ground Truth 到 Prompt | ✓ | ||||
| 支持预处理评估内容和后处理评估结果 | ✓ | ||||
| 支持自定义评估 | ✓ | ||||
| 支持回测 | ✓ | ||||
| 生成特定指标评估模板 | ✓ | ||||
| 文本聚类去重与黄金指标生成 | ✓ | ||||
| 支持合成 Ground Truth | ✓ | ||||
| Agentic Eval 智能评估 | ✓ |
- 固定评估模板:最简单,无法扩展。
- Ground Truth:标准答案是 Benchmark 基础。
- 预处理和后处理:支持脏数据处理、内容抽取、Trace 聚合、分数分布和趋势分析。
- 支持自定义评估和回测:满足多场景需求,监控模型迭代。
- 生成评估模板和合成 Ground Truth:提升效率,降低人工成本。
- Agentic 评估:自动理解数据、合成 Ground Truth、生成评估任务和报告。
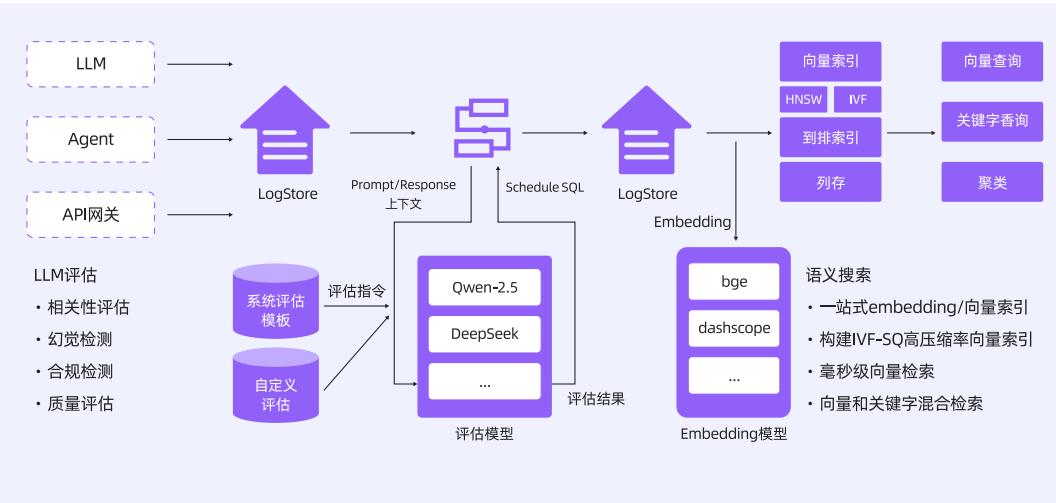
云原生评估系统
云原生评估系统一站式集成数据采集、存储、评估、语义检索能力,解决数据孤岛和评估落地痛点。
- 数据采集:兼容 OpenTelemetry 协议,支持无侵入探针和高性能采集器。
- 在线数据预处理:基于 SQL/SPL 实现提取、去重、关联等操作。
- 实时评估:评估算子集成先进大模型,提升评估能力。
- 评估模板建设:内置多种模板,支持自定义和 MetaStore 管理。
- 语义搜索与聚类:精准筛选和聚类分析评估结果,发现高频 Pattern 和离群点。
下图展示了云原生评估系统架构:
评估任务与明细
- 创建评估任务:选择模板、语言、类型、任务名称、过滤语句等。
- 评估任务类型:包括通用场景、语义评估、RAG 评估、Agent 评估、工具使用评估。
- 评估明细:展示 TraceID、SpanID、评分、解释等,可与原始数据关联。
- 评分分布:通过可观测大盘展示分数分布和任务质量。
通用场景评估任务
下表为通用场景评估任务及评分标准:
| 序号 | 评估任务 | 0 分 | 1 分 |
|---|---|---|---|
| 1 | 准确度 | 完全不准确 | 完全准确 |
| 2 | 计算器正确性 | 完全不正确 | 完全正确 |
| 3 | 简洁性 | 完全不简洁 | 完全简洁 |
| 4 | 包含代码 | 包含代码 | 不包含代码 |
| 5 | 包含个人身份信息 | 包含个人身份信息 | 不包含个人身份信息 |
| 6 | 上下文相关性 | 完全不相关 | 完全相关 |
| 7 | 禁忌词 | 包含禁忌词 | 不包含禁忌词 |
| 8 | 幻觉 | 存在幻觉 | 完全没有幻觉 |
| 9 | 仇恨言论 | 包含仇恨言论 | 不包含仇恨言论 |
| 10 | 有用性 | 完全无用 | 非常有用 |
| 11 | 语言检测器 | 无法检测语言 | 准确检测语言 |
| 12 | 开源 | 开源 | 非开源 |
| 13 | 问题与 Python 相关 | 与 Python 相关 | 与 Python 无关 |
| 14 | 毒性 | 有毒性 | 无毒性 |
语义评估任务
语义评估包括实体信息抽取、格式信息提取、重点词汇抽取、数值信息抽取、抽象信息抽取、用户意图识别、文本摘要、情绪分类、主题分类、角色分类、语言分类、生成相关问题等。
RAG 评估任务
| 序号 | 评估任务 | 0 分 | 1 分 |
|---|---|---|---|
| 1 | RAG 召回语料和问题的相关性 | 完全不相关 | 完全相关 |
| 2 | RAG 召回语料和答案的相关性 | 完全不相关 | 完全相关 |
| 3 | RAG 语料是否存在重复 | 完全重复 | 完全不重复 |
| 4 | RAG 语料的多样性 | 多样性最差 | 多样性最好 |
Agent 评估任务
| 序号 | 评估任务 | 0 分 | 1 分 |
|---|---|---|---|
| 1 | Agent 指令是否清晰 | 不清晰 | 清晰 |
| 2 | Agent 规划是否有错误 | 存在错误 | 正确 |
| 3 | Agent 任务是否复杂 | 复杂 | 不复杂 |
| 4 | Agent 执行路径是否存在错误 | 有错误 | 无错误 |
| 5 | Agent 是否最终达到了目标 | 未达到目标 | 达到了目标 |
| 6 | Agent 执行路径是否简洁 | 不简洁 | 简洁 |
工具使用评估任务
| 序号 | 评估任务 | 0 分 | 1 分 |
|---|---|---|---|
| 1 | 规划是否调用了工具 | 否 | 是 |
| 2 | 遇到错误参数时,是否修正了错误的参数 | 未修正错误 | 修正了错误 |
| 3 | 工具调用的正确性 | 错误 | 正确 |
| 4 | 工具参数是否有错误 | 有错误 | 无错误 |
| 5 | 工具调用效率 | 效率较低 | 效率较高 |
| 6 | 工具是否合适 | 不合适 | 合适 |
总结
AI 评估是降低应用不确定性、提升系统性能与信任的核心环节。现代评估体系涵盖多范式、多维度,自动化与人工结合,贯穿 AI 生命周期。LLM-as-a-judge 等新范式提升了评估效率和可扩展性,但需警惕系统性偏见和能力上限。云原生评估系统集成数据采集、预处理、评估和后处理,为企业构建高质量、可持续的智能应用提供坚实基础。
参考文献
- HELM: Holistic Evaluation of Language Models - crfm.stanford.edu
- NIST AI 风险管理框架 - nist.gov
- 阿里云云原生可观测解决方案 - aliyun.com
- OpenTelemetry 官网 - opentelemetry.io
- Higress 社区文档 - github.com