第 9 章:数据管理
本章系统梳理了云原生应用中的数据建模、Spring Data 多种数据源集成、微服务数据隔离与缓存等关键实践,帮助开发者构建高可扩展性和高可维护性的分布式数据架构。
数据建模与领域驱动设计
良好的数据模型是软件业务需求的核心表达。领域驱动设计(DDD)强调通过领域模型(如图 9-1)明确业务概念、边界和关系,促进开发团队与业务专家的沟通,降低后期变更成本。
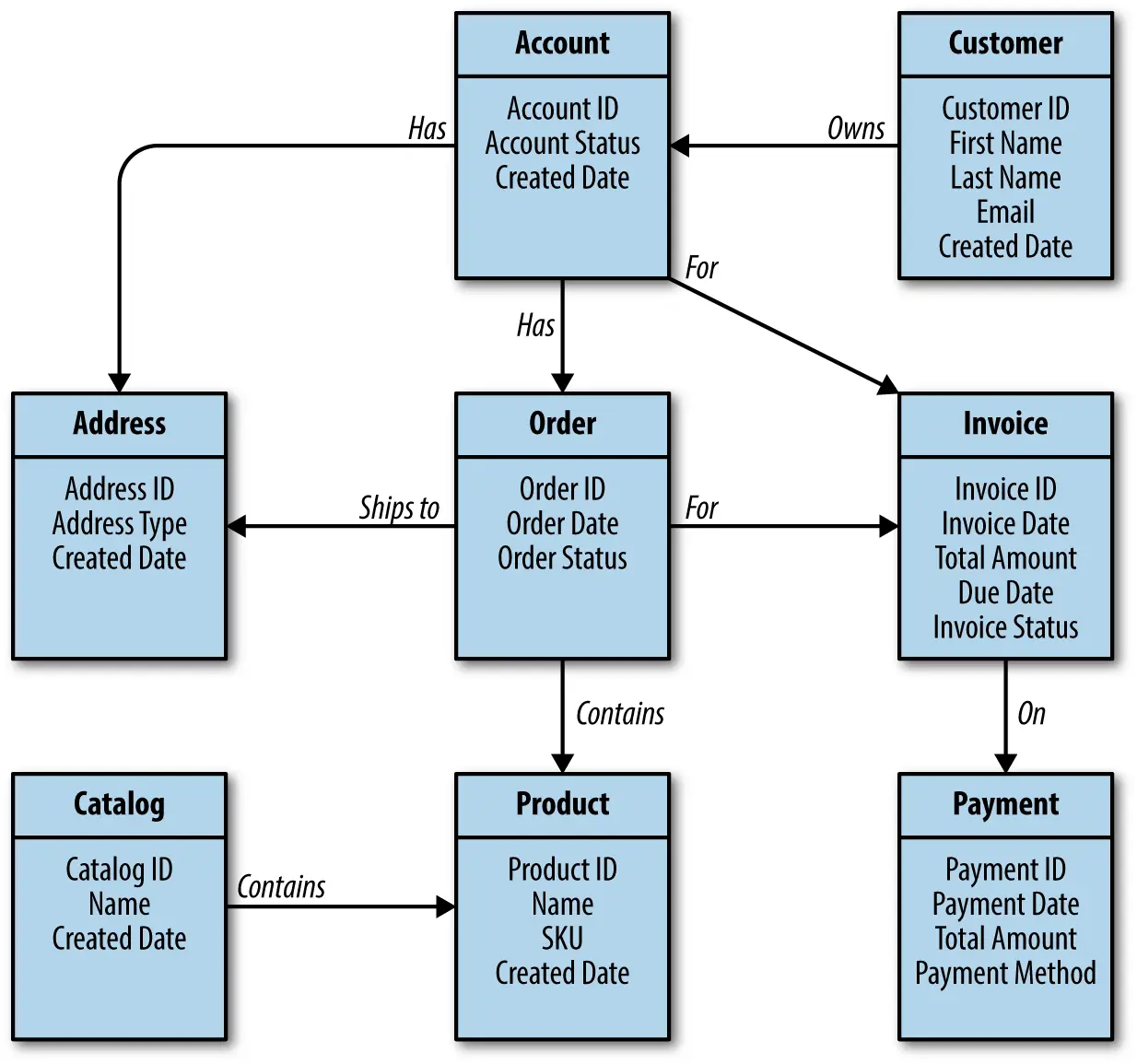
领域模型的清晰划分有助于微服务架构下的有界上下文设计,避免概念混淆和技术债务。
关系数据库与 NoSQL 简述
关系数据库(RDBMS)长期主导事务型数据存储,强调一致性和结构化查询。NoSQL 数据库则提供多样化的数据模型(文档、键值、图等),适合微服务的多样需求和异构持久化(Polyglot Persistence)场景。
Spring Data 生态与数据访问模式
Spring Data 提供统一的数据访问抽象,支持主流 RDBMS 和 NoSQL 数据库(JPA、MongoDB、Neo4j、Redis 等)。核心模式包括:
- 领域类(Entity/Document/Node):映射业务对象
- 存储库(Repository):定义数据访问接口,Spring Data 自动实现
- 包结构:建议以有界上下文为单位组织领域类和存储库,便于微服务拆分和演进
Spring Data 基础用法
以 User 实体为例,定义领域类和存储库:
public class User {
private Long id;
private String firstName;
private String lastName;
private String email;
// getter/setter
}
public interface UserRepository extends CrudRepository<User, Long> { }
Spring Data 自动实现接口,无需手写 SQL 或数据访问逻辑。
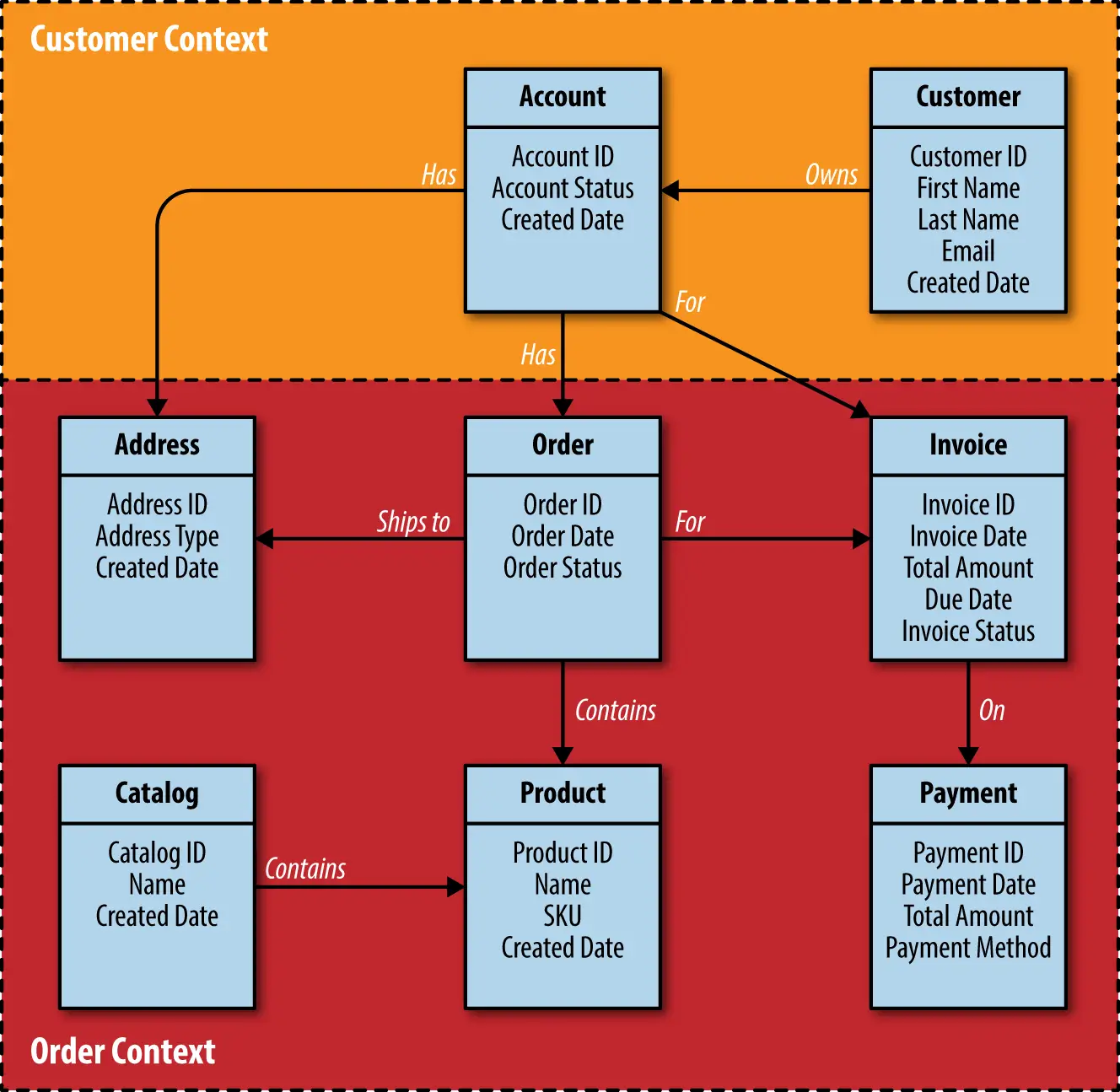
包结构与有界上下文
建议将领域类和存储库按有界上下文分包,便于后续微服务拆分。例如:
demo.customer:Customer 相关实体与仓库demo.order:Order 相关实体与仓库
Spring Data 支持的存储库类型
下表展示了常见 Spring Data 存储库类型及其适用场景。
| 存储库类型 | 项目 | 说明 |
|---|---|---|
| Repository | Data Commons | 核心抽象,基础接口 |
| CrudRepository | Data Commons | 增删改查基础操作 |
| PagingAndSortingRepository | Data Commons | 支持分页与排序 |
| JpaRepository | Data JPA | JPA/RDBMS 扩展,支持更多 JPA 特性 |
| MongoRepository | Data MongoDB | MongoDB 文档操作 |
| CouchbaseRepository | Data Couchbase | Couchbase 文档操作 |
JDBC 与 JPA 数据访问
Spring Boot 自动配置 DataSource、JDBC、JPA,支持多种数据库。推荐将敏感信息外部化配置。JdbcTemplate 简化了 SQL 操作,JPA 提供 ORM 支持,开发者可专注于领域模型。
@Component
class JdbcCommandLineRunner implements CommandLineRunner {
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public void run(String... args) {
// 创建表、插入数据、查询映射为对象
}
}
Spring Data JPA 实践:Account Service
以 Cloud Native Clothing 的 Account Service 为例,使用 JPA 实现 Account、Customer、Address、CreditCard 等实体及其关系,支持审计(@CreatedDate、@LastModifiedDate),并通过 Repository 管理数据访问。
- 配置多环境数据源(MySQL/H2),通过 profile 切换
- 使用 @Entity、@OneToMany、@OneToOne 等注解建模关系
- 通过 @EnableJpaAuditing 启用审计
Spring Data MongoDB 实践:Order Service
Order Service 使用 MongoDB 存储订单、发票、产品等文档,适合聚合存储和灵活结构。
- @Document 注解定义文档类
- 支持嵌套对象、列表、状态枚举
- 通过 Repository 实现自定义查询
- 使用 AbstractMongoEventListener 实现审计
Spring Data Neo4j 实践:Inventory Service
Inventory Service 采用 Neo4j 图数据库,适合建模复杂关系(如仓库、产品、目录、发货等)。
- @NodeEntity 注解定义节点
- @Relationship 注解定义节点间关系
- 使用 GraphRepository/PagingAndSortingRepository 管理节点
- 支持 Cypher 查询和高效图遍历
Spring Data Redis 实践:缓存与高性能
Redis 作为高性能缓存,Spring Data Redis 支持注解驱动缓存(@Cacheable、@CachePut、@CacheEvict),提升微服务性能与可用性。
- 配置 @EnableCaching,自动集成 RedisTemplate
- 结合主数据源(如 MySQL)实现读写分离与缓存一致性
- 注意缓存命名空间与 TTL 设置,避免数据冲突
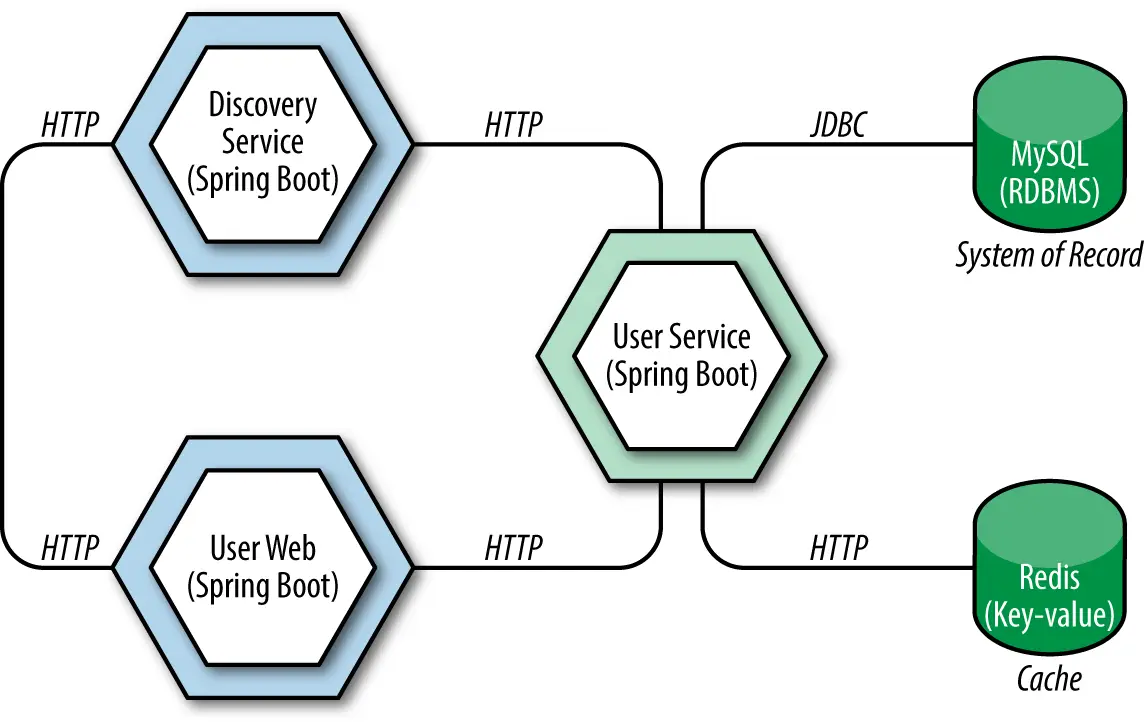
典型微服务数据架构案例
以 Cloud Native Clothing 在线商店为例,Account Service(JPA-MySQL)、Order Service(MongoDB)、Inventory Service(Neo4j)分别管理不同有界上下文的数据,实现数据隔离与多样化持久化。
总结
本章系统梳理了云原生应用中的数据建模、Spring Data 多数据源集成、微服务数据隔离与缓存等关键实践。通过合理的数据架构设计与 Spring Data 生态集成,开发者可实现高可扩展性、高可维护性和高性能的分布式数据管理,为云原生微服务系统的持续演进奠定坚实基础。