第 12 章:云原生数据:打破数据整体
本章围绕云原生数据管理,系统梳理了缓存、事件驱动架构和事件溯源等关键模式,帮助读者理解如何构建自治性强、弹性高的数据系统,并逐步打破传统数据单体架构。
本章要点
- 为什么每个微服务都需要一个缓存
- 如何通过事件来增加本地数据存储/缓存
- 在事件驱动系统中如何使用消息传递
- 消息传递和事件之间的区别
- 事件日志和事件源
云原生数据的特性与挑战
还记得第一章中对云原生的定义吗?我们将现代软件的高层需求归纳为四个特性:冗余、可适应、模块化和动态可扩展(见下图 12.1)。这些特性不仅适用于服务,也同样适用于数据层。
以冗余为例,现代云原生数据服务已在多节点设计中深入引入冗余机制,并采用如 Paxos、领导者/跟随者等模式来保证一致性和可用性。
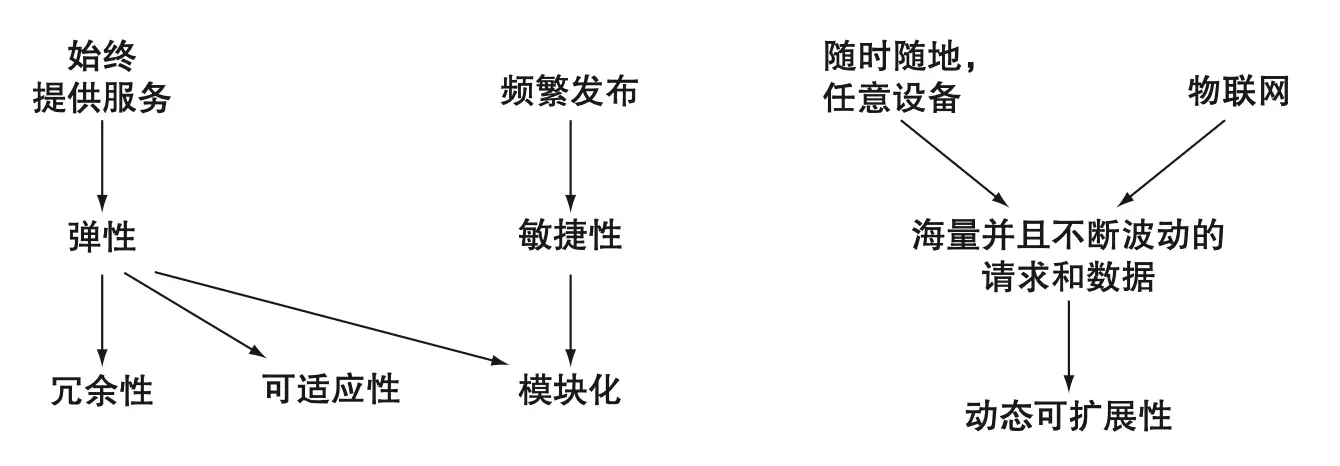
对于可伸缩性,传统数据库多采用垂直扩展,而现代数据库(如 Cassandra、MongoDB、Couchbase)则以水平扩展为核心设计。随着数据量增加,可通过增加节点实现集群扩展。
虽然我们可以深入探讨所有特性,但本章重点关注模块化。微服务架构的核心是将单体应用拆分为多个自治服务,但如果背后仍然是单体数据库,自治性就大打折扣。
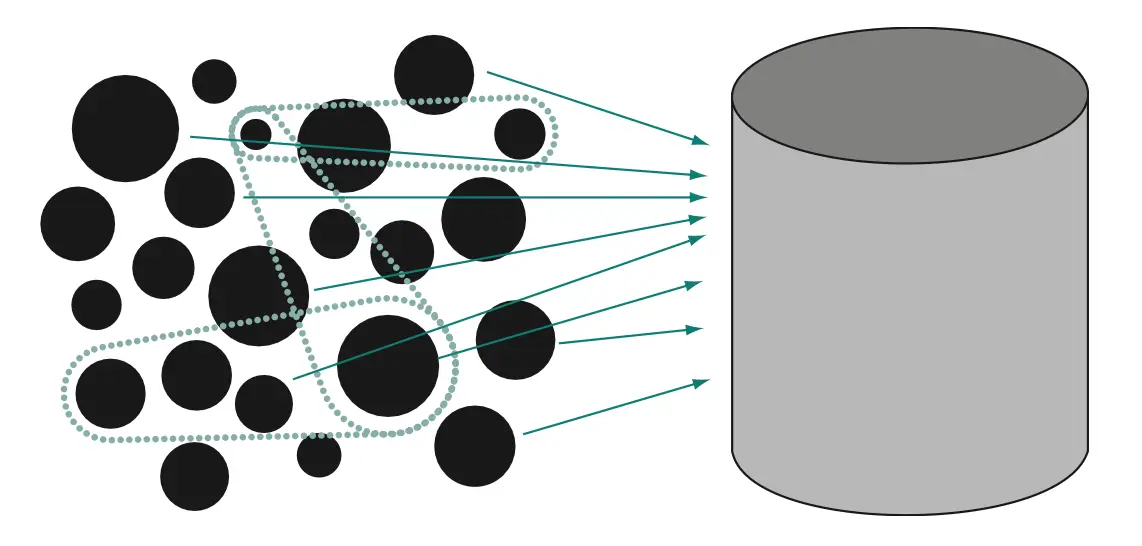
共享数据库带来传递依赖和并发访问瓶颈,微服务的自治性受限。因此,打破数据单体是云原生架构的关键目标。
缓存:提升自治性与弹性
为什么每个微服务都需要缓存
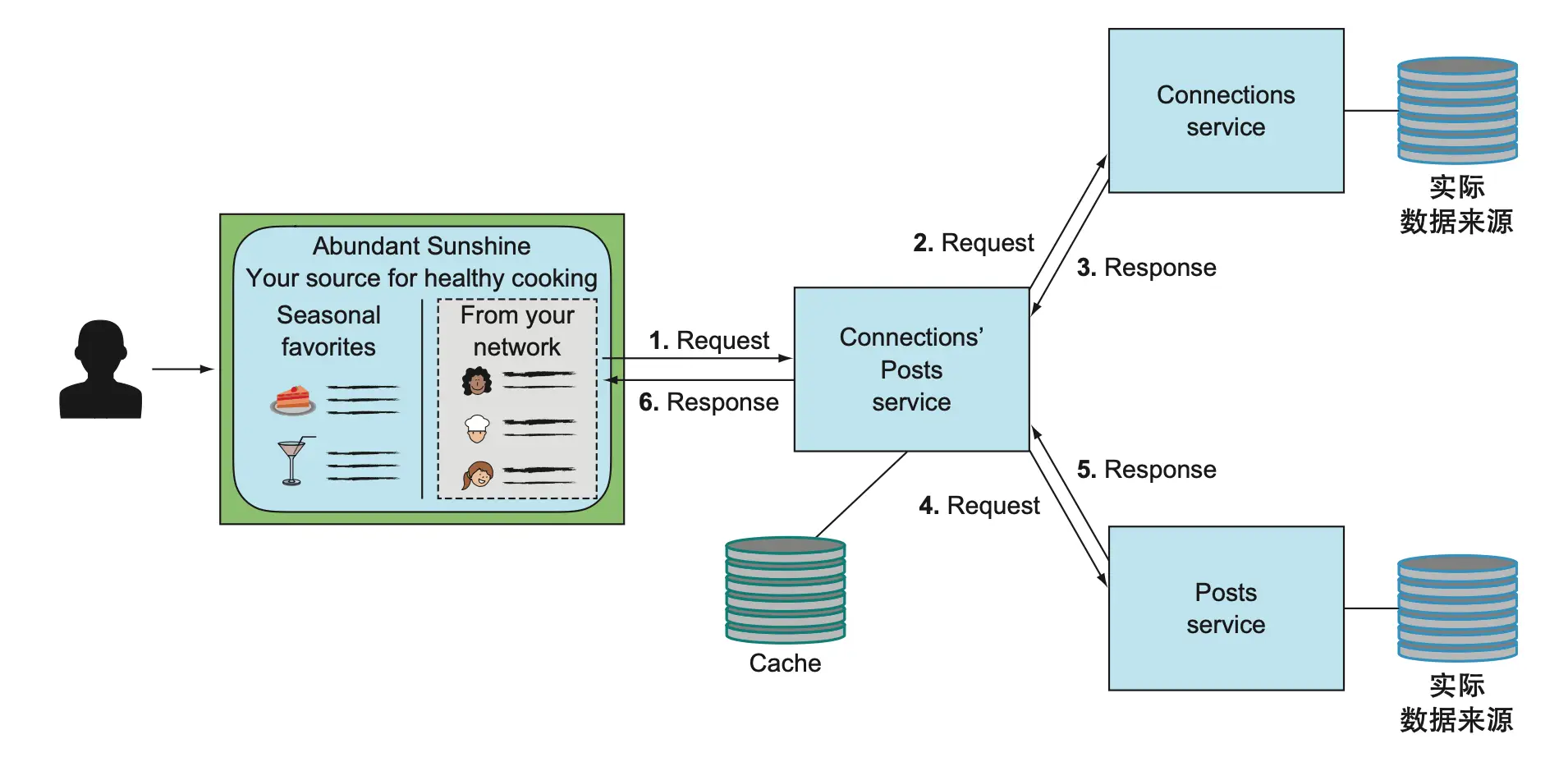
让我们从未使用缓存的设计说起。下图展示了相关帖子服务聚合关系服务和帖子服务内容的场景,采用传统请求/响应协议。
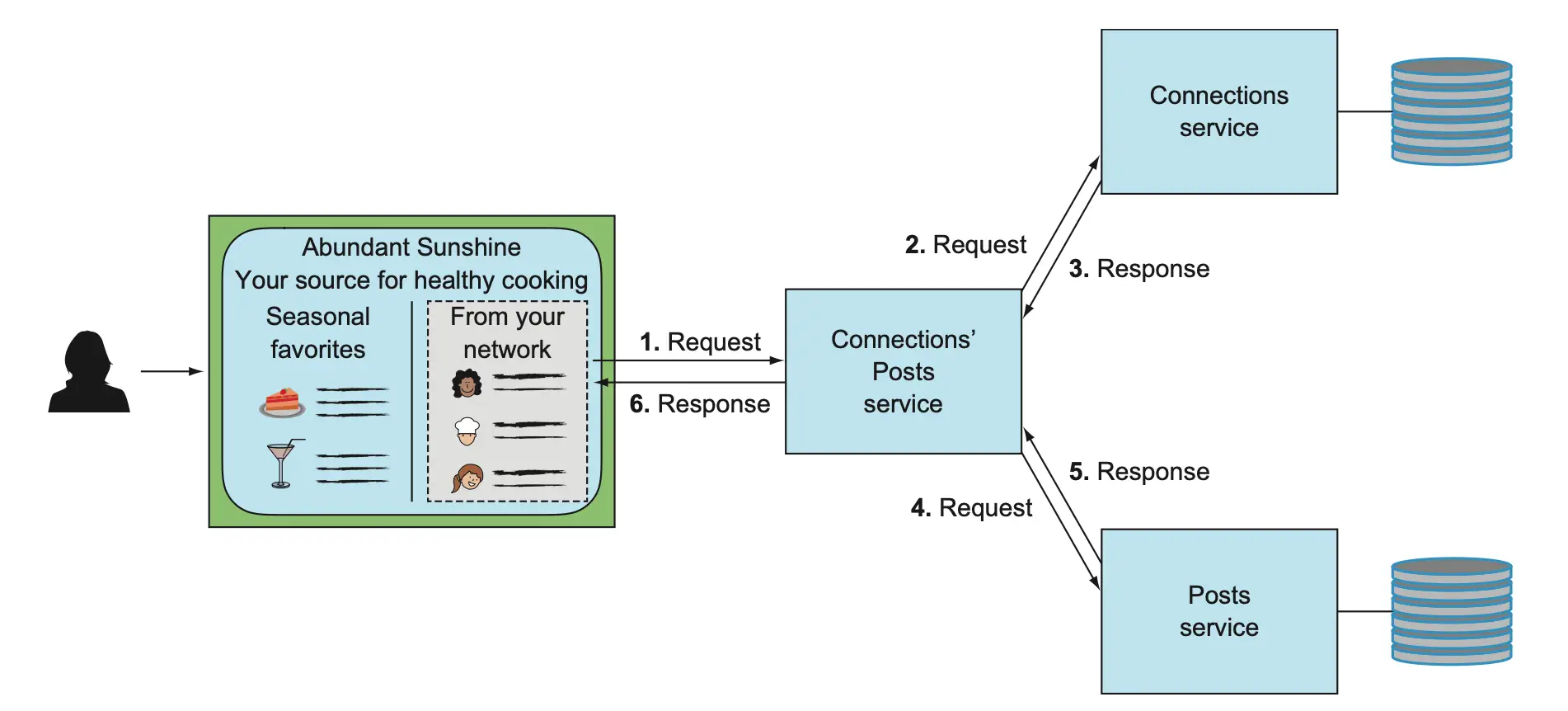
在遇到局部故障时,聚合服务的弹性能力有限。下图显示,只要下游服务不可用,聚合服务就无法生成结果。
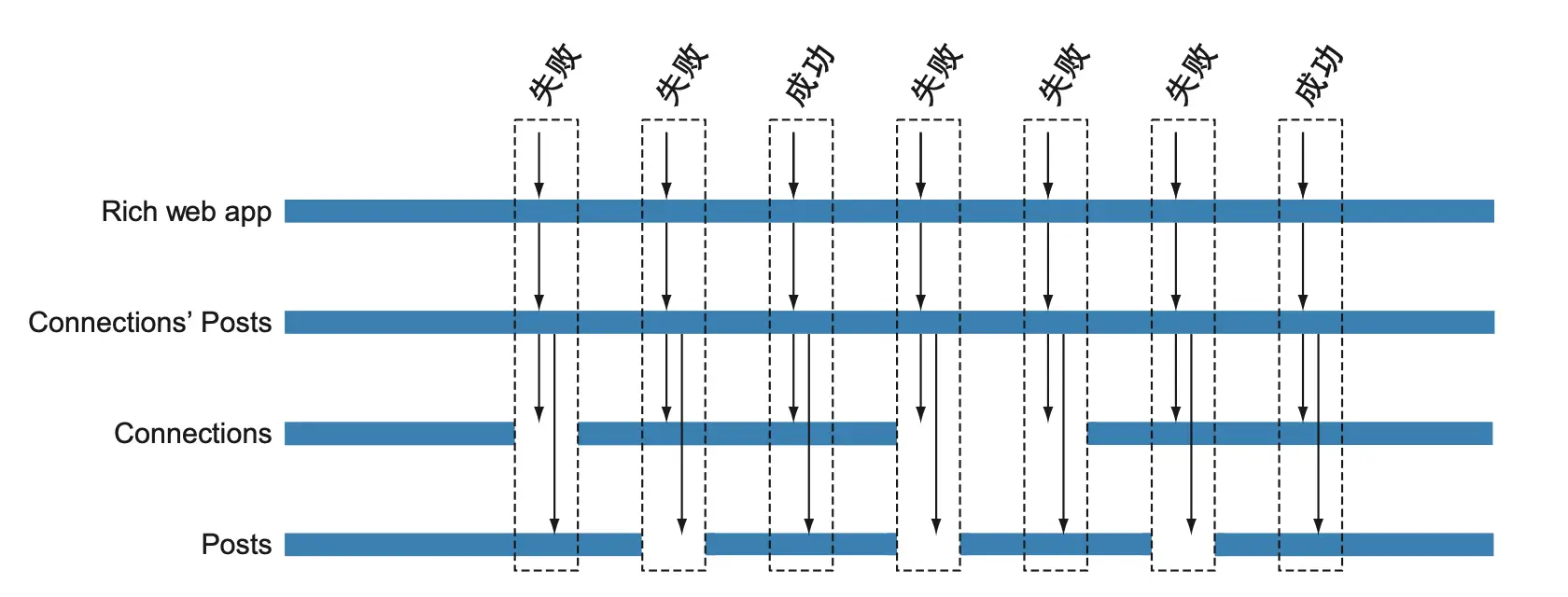
引入缓存后,相关帖子服务可在本地存储下游服务的数据副本,提升自治性和弹性。缓存可采用旁路缓存或透读缓存协议,具体实现方式可根据业务需求选择。
事件驱动:主动推送数据变更
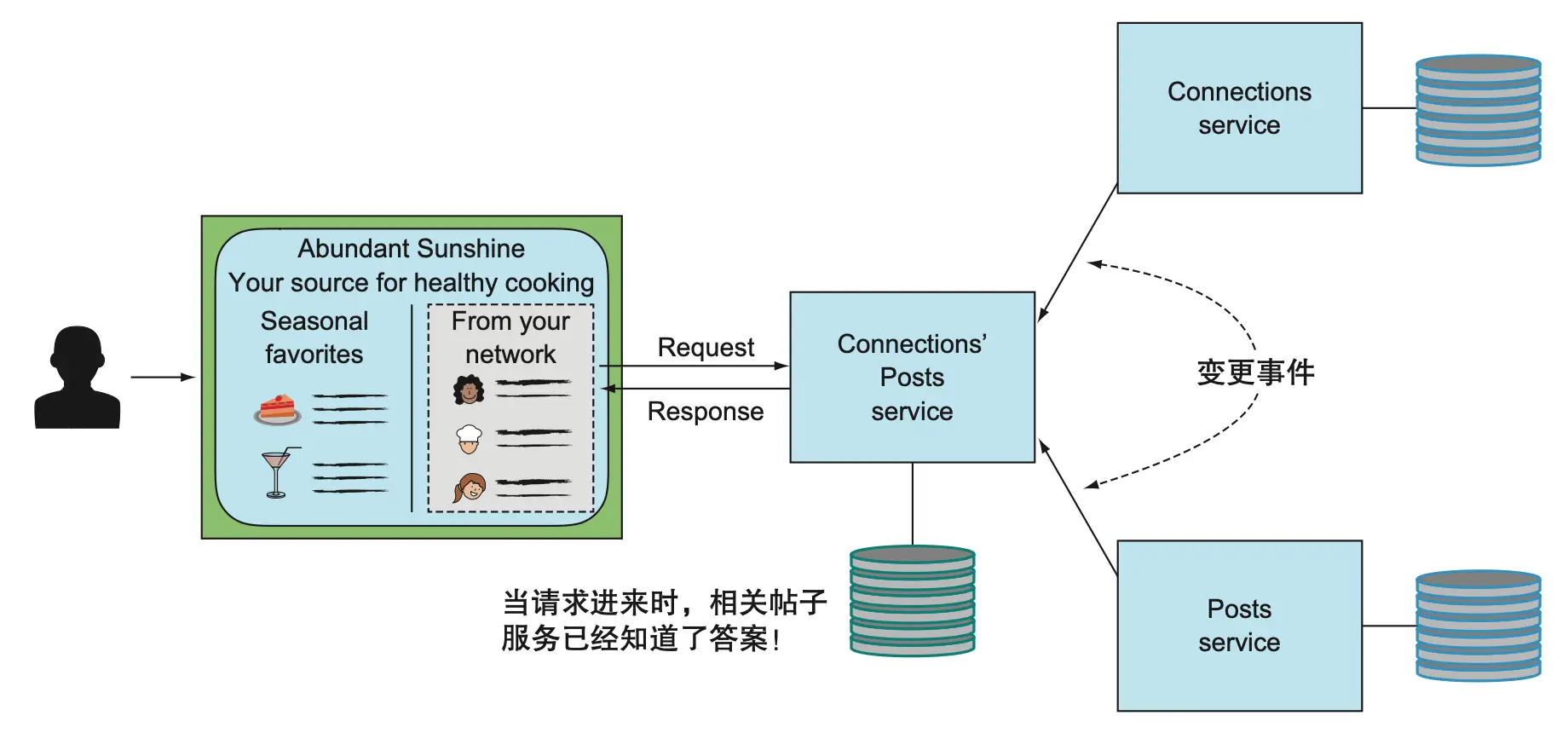
从请求/响应到事件驱动
事件驱动架构通过下游服务广播变更事件,相关服务可实时更新本地存储,无需担心缓存过期问题。
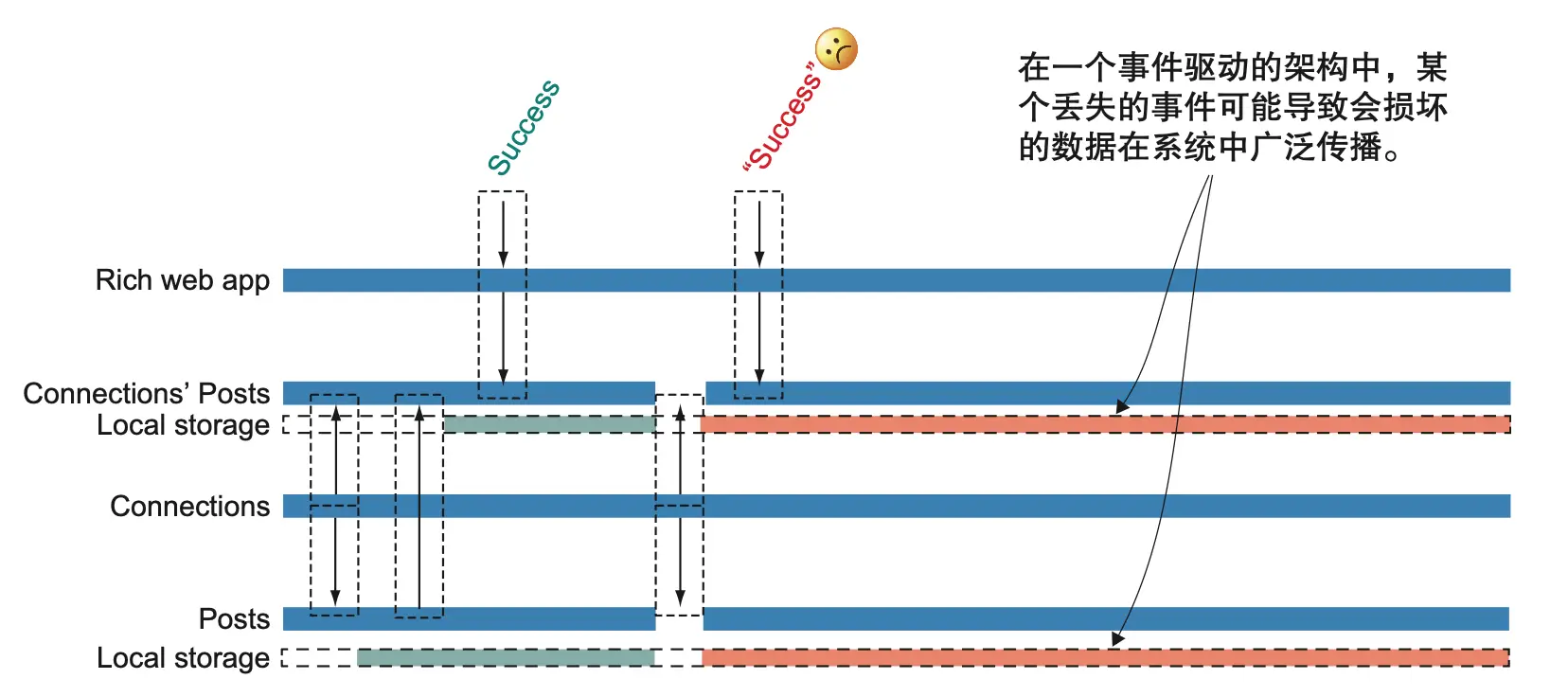
事件驱动提升了自治性,但如果事件丢失,可能导致本地存储数据不一致,错误结果“成功”返回。
事件日志:解耦与持久化
引入事件日志
为保证事件可靠传递,需引入异步消息系统(如 Kafka),让事件生产者与消费者完全解耦。事件日志可持久保存事件,直到所有相关方消费完毕。
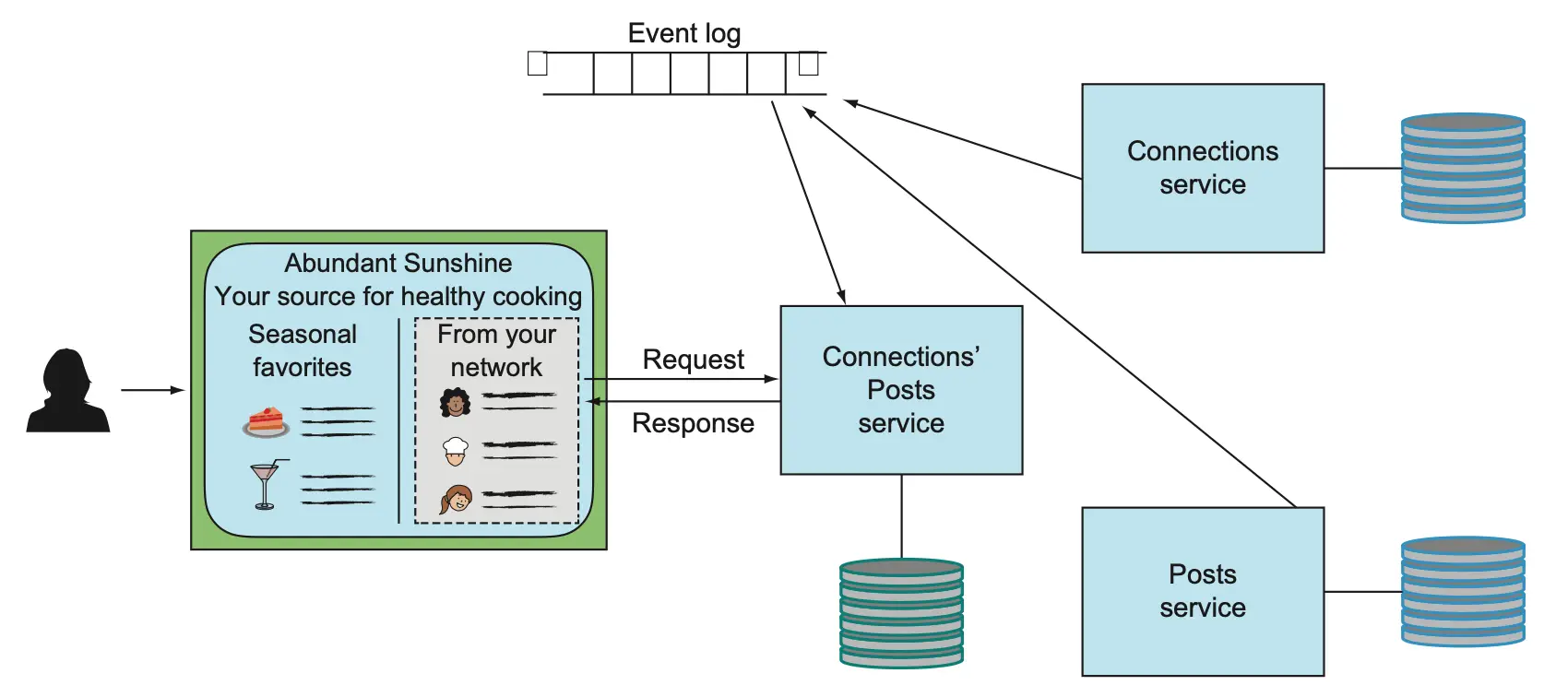
事件日志的消费模式支持多种场景,消费者可根据自身需求管理游标,实现弹性恢复和数据重建。
实际案例:事件驱动微服务架构
本章示例基于事件日志实现服务解耦。以用户创建为例,写控制器将新用户存入数据库,并向事件日志发送变更事件。事件消费者订阅相关主题,处理事件并更新本地存储。
示例代码可参考 Spring Kafka 的生产者和消费者实现,具体细节可根据实际业务调整。
事件处理程序需保证幂等性,避免重复消费导致数据异常。实际部署可采用 Kubernetes 集群,结合 MySQL、Kafka 等组件,支持服务弹性伸缩和自治运维。
主题与队列:消息系统基础
队列保证消息只被一个订阅者消费,主题则可被多个订阅者同时消费。Kafka 通过 topic 和 groupId 实现灵活的消息分发和消费模式,支持微服务架构下的多实例部署。
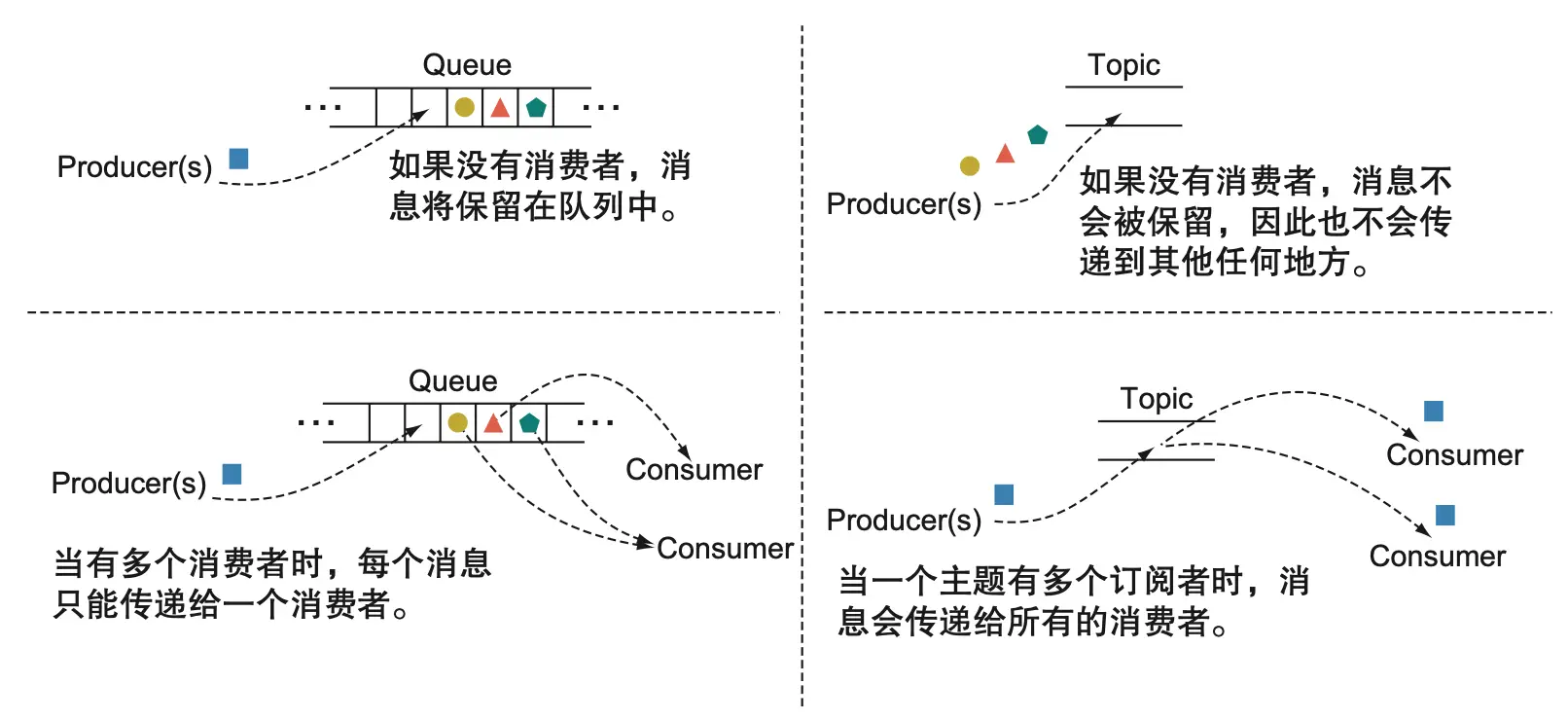
事件日志主题可持久保存事件,支持新消费者随时重放历史事件,提升系统弹性和可扩展性。
事件载荷与结构管理
事件载荷应完整描述变更内容,避免依赖外部数据源。事件结构需由生产者定义并版本化,供所有相关方访问和适配。可参考 Confluent Schema Registry 等工具实现结构管理。
幂等性:分布式系统的关键保障
事件消费者应尽可能实现幂等操作,保证多次处理同一事件结果一致,提升系统健壮性和容错能力。
事件溯源:数据的唯一真实来源
事件溯源模式将事件日志作为唯一真实来源,所有服务的本地存储仅为事件的投射结果。写控制器只负责写入事件日志,事件处理程序负责从日志投射数据,读控制器根据投射数据返回结果。
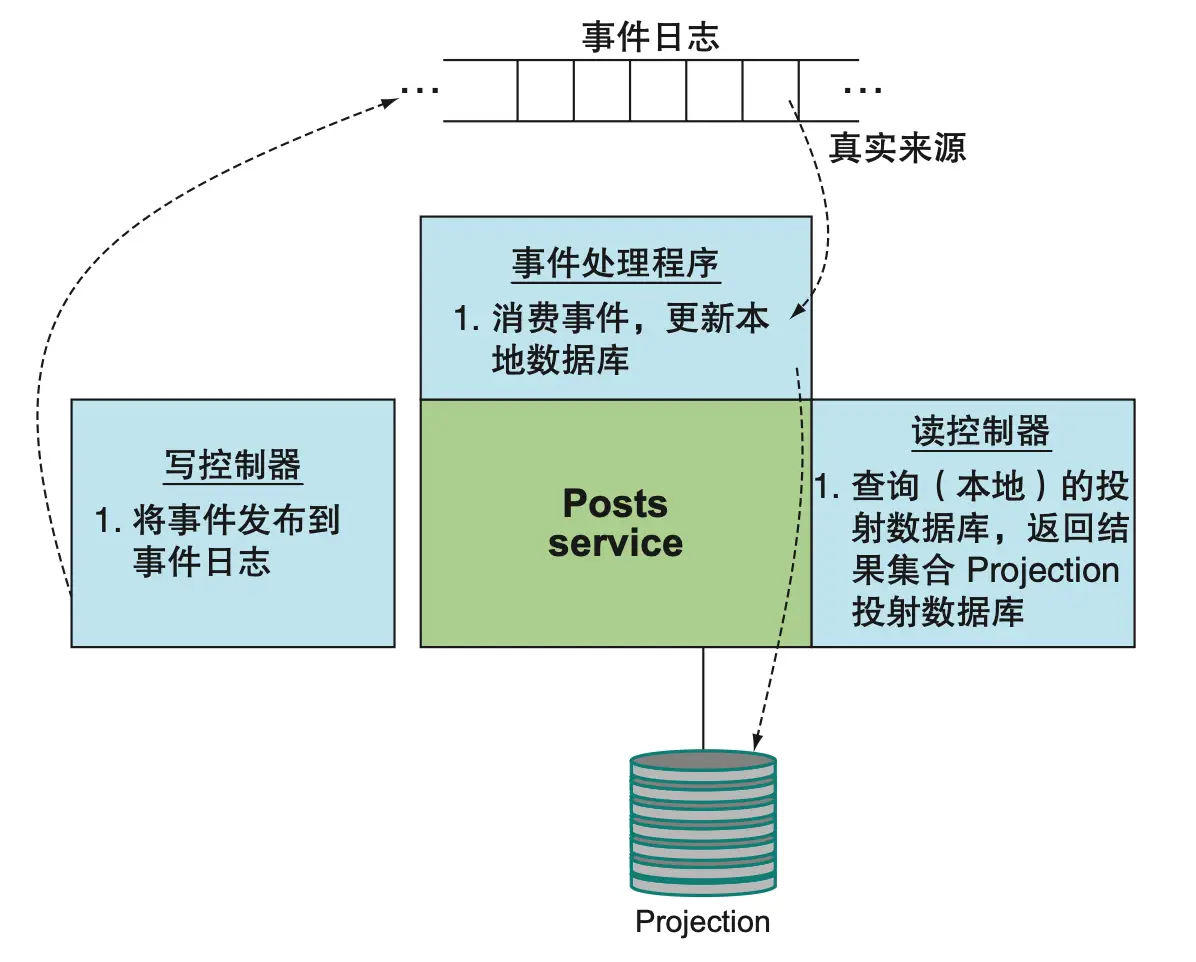
实践建议与扩展话题
- 事件日志分区与扩展
- 事件排序与一致性保障
- 事件结构演进与兼容性
- 投射数据快照与恢复
推荐阅读 Martin Kleppmann 的《设计数据密集型应用程序》,深入了解事件溯源与数据架构设计。
总结
- 微服务拥有独立数据库显著提升自治性和弹性。
- 缓存适用于静态数据,事件驱动更适合频繁变更场景。
- 事件日志实现服务彻底解耦和数据一致性。
- 事件溯源让系统具备高度自治和弹性,支持分布式环境下的数据一致性与恢复。
参考文献
- Designing Data Intensive Applications - oreilly.com
- Apache Kafka 官方文档 - kafka.apache.org
- Confluent Schema Registry - confluent.io