Horizontal Pod Autoscaling
HPA(Horizontal Pod Autoscaler)让 Kubernetes 集群中的 Pod 数量能够根据负载自动扩缩容,实现资源的弹性管理,是自动化运维的核心能力之一。
应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,让 service 中的 Pod 个数自动调整呢?这就有赖于 Horizontal Pod Autoscaling 了,顾名思义,使 Pod 水平自动缩放。
HPA 是最能体现 Kubernetes 相比传统运维价值的功能之一,不再需要手动扩容,真正实现了自动化运维,还可以基于自定义指标进行扩缩容。
概述
HPA 属于 Kubernetes 中的 autoscaling SIG(Special Interest Group),其下有两个主要特性:
- Arbitrary/Custom Metrics in the Horizontal Pod Autoscaler#117
- Monitoring Pipeline Metrics HPA API #118
版本演进
Kubernetes HPA 的功能随着版本不断演进,主要里程碑如下:
- Kubernetes 1.2:引入 HPA 机制
- Kubernetes 1.6:从 kubelet 获取指标转为通过 API server、Heapster 或 kube-aggregator 获取
- Kubernetes 1.6+:支持自定义指标
- 现在:推荐使用
autoscaling/v2API
架构原理
Horizontal Pod Autoscaling 仅适用于 Deployment 和 ReplicaSet,由 API server 和 controller 共同实现。
下图展示了 HPA 的整体架构:
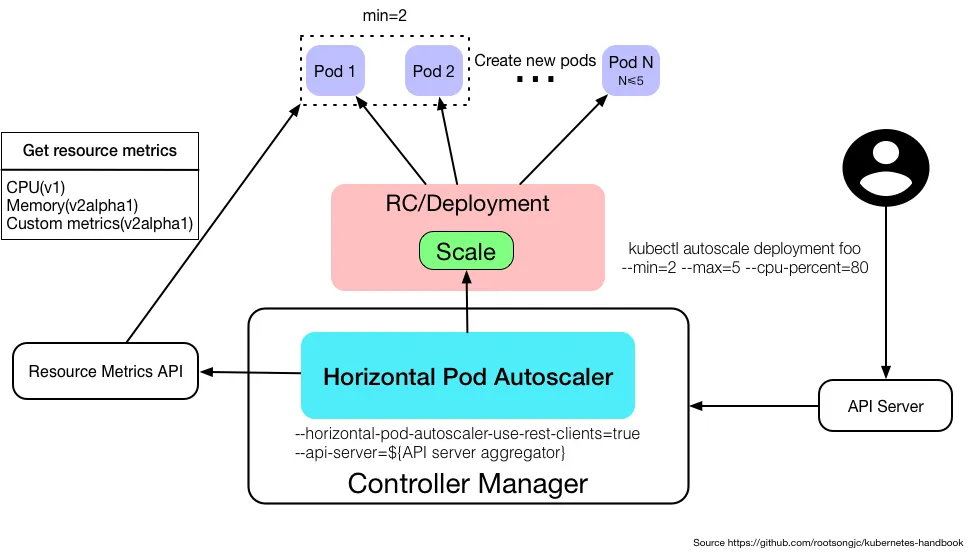
工作机制
HPA 通过控制循环实现自动扩缩容,循环周期由 controller manager 的 --horizontal-pod-autoscaler-sync-period 参数指定(默认 30 秒)。
每个周期内,controller manager 会执行以下步骤:
- 查询指标:从 resource metric API 或自定义 metric API 获取指标。
- 计算利用率:
- Resource metrics:计算与容器 resource request 的百分比。
- 自定义 metrics:使用原始值进行比较。
- Object metrics:获取单个对象的指标与目标值比较。
- 计算副本数:基于所有指标计算新的副本数,取最大值。
- 执行扩缩容:通过 Scale 子资源调整副本数。
支持的指标类型
Kubernetes HPA 支持多种指标类型,具体如下:
API 版本对比
下表对比了不同 API 版本下 HPA 支持的指标类型。
| API 版本 | 支持的指标 |
|---|---|
| autoscaling/v1 | CPU 利用率 |
| autoscaling/v2 | CPU、内存、自定义指标、多指标组合 |
指标获取方式
HPA 控制器可通过以下两种方式获取指标:
- 直接 Heapster 访问:通过 API 服务器的服务代理查询 Heapster。
- REST 客户端访问:通过 metrics API 获取指标。
基本使用
在实际运维中,HPA 的使用非常灵活,支持命令行和 YAML 配置两种方式。
kubectl 命令
以下是常用的 HPA 管理命令:
# 基本管理命令
kubectl create hpa
kubectl get hpa
kubectl describe hpa
kubectl delete hpa
# 快速创建 HPA
kubectl autoscale deployment nginx --min=2 --max=10 --cpu-percent=80
命令参数说明
kubectl autoscale 命令的参数说明如下:
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags]
示例:为 Deployment foo 创建 autoscaler,CPU 利用率达到 80% 时扩缩容,副本数在 2-5 之间:
kubectl autoscale deployment foo --min=2 --max=5 --cpu-percent=80
YAML 配置示例
通过 YAML 文件可以更灵活地配置 HPA,支持多指标扩缩容。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- ✅ 支持:HPA 绑定到 Deployment,支持滚动更新
- ❌ 不支持:HPA 直接绑定到 ReplicationController 进行滚动更新
原因:滚动更新会创建新的 ReplicationController,HPA 不会自动绑定到新的 RC。
自定义指标配置
HPA 支持基于自定义指标的扩缩容,需满足一定的前提条件。
前提条件
要使用自定义指标,需完成如下配置:
Controller Manager 配置:
--horizontal-pod-autoscaler-use-rest-clients=true --master=http://API_SERVER_ADDRESS:8080API Server 配置(Kubernetes 1.7+):
--requestheader-client-ca-file=/etc/kubernetes/ssl/ca.pem --requestheader-allowed-names=aggregator --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --proxy-client-cert-file=/etc/kubernetes/ssl/kubernetes.pem --proxy-client-key-file=/etc/kubernetes/ssl/kubernetes-key.pem
APIService 配置
创建自定义指标 API 服务的 YAML 示例:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta2.custom-metrics.metrics.k8s.io
spec:
insecureSkipTLSVerify: true
group: custom-metrics.metrics.k8s.io
groupPriorityMinimum: 1000
versionPriority: 5
service:
name: custom-metrics-apiserver
namespace: custom-metrics
version: v1beta2
Prometheus 集成
通过 Prometheus Operator 可以实现自定义指标的采集与暴露。
部署 Prometheus Operator:
kubectl apply -f prometheus-operator.yaml验证自定义指标 API:
kubectl get --raw="/apis/custom-metrics.metrics.k8s.io/v1beta2" | jq .自定义指标 HPA 示例:
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: nginx-custom-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: nginx minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metric: name: http_requests_per_second target: type: AverageValue averageValue: "100" - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: "10k"
多指标支持
Kubernetes 1.6 及以上版本支持基于多个指标的扩缩容。
- HPA 会根据每个指标分别计算所需副本数
- 取所有指标计算结果中的最大值作为最终扩缩容结果
- 需确保所有指标都满足要求
指标类型说明
下表总结了 HPA 支持的指标类型及其用途。
| 指标类型 | 描述 | 用途 |
|---|---|---|
| Resource | CPU、内存等资源指标 | 基础资源监控 |
| Pods | Pod 级别的自定义指标 | 应用特定指标 |
| Object | Kubernetes 对象指标 | 外部资源监控 |
| External | 外部系统指标 | 云服务指标 |
最佳实践
在实际生产环境中,建议遵循以下最佳实践:
资源请求设置
合理设置 Pod 的资源请求和限制,有助于 HPA 精确扩缩容。
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
合理的扩缩容参数
通过配置 behavior 字段,可以优化扩缩容的平滑性,避免频繁波动。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 50
periodSeconds: 60
监控和告警
- 监控 HPA 状态和扩缩容事件
- 设置合理的告警阈值
- 定期检查指标的准确性
故障排除
在使用 HPA 过程中,常见问题及排查方法如下:
常见问题
HPA 不生效
- 检查 Pod 是否设置了 resource requests
- 验证 metrics-server 是否正常运行
- 确认 HPA 配置正确
自定义指标无法获取
- 检查自定义指标 API 是否注册
- 验证 APIService 配置
- 确认指标数据源正常
频繁扩缩容
- 调整
stabilizationWindowSeconds - 优化指标阈值设置
- 检查应用负载模式
- 调整
调试命令
以下命令可用于排查 HPA 相关问题:
# 查看 HPA 状态
kubectl describe hpa <hpa-name>
# 查看 HPA 事件
kubectl get events --field-selector involvedObject.kind=HorizontalPodAutoscaler
# 查看可用指标
kubectl get --raw "/apis/metrics.k8s.io/v1/nodes" | jq .
kubectl get --raw "/apis/custom-metrics.metrics.k8s.io/v1beta2" | jq .
总结
HPA 是 Kubernetes 自动化运维的核心能力之一,能够根据多种指标实现 Pod 的自动扩缩容。通过合理配置资源请求、自定义指标和扩缩容策略,可以显著提升集群资源利用率和应用弹性。实际生产中,建议结合监控和告警体系,持续优化 HPA 策略,确保系统稳定高效运行。
参考资料
- HPA 官方文档 - kubernetes.io
- HPA Walkthrough - kubernetes.io
- 自定义指标开发 - github.com
- Kubernetes autoscaling based on custom metrics - medium.com