Service
Service 是 Kubernetes 微服务架构中实现稳定服务发现与流量调度的基础设施,合理设计可极大提升系统的可用性与可维护性。
Service 概述
在 Kubernetes 集群中,Pod 具有生命周期性,IP 地址并不总是稳定可靠。通过 ReplicaSet 或 Deployment 等控制器可以动态地创建和销毁 Pod。对于需要为其他 Pod 提供服务的一组后端 Pod,前端应用如何发现并连接这些后端 Pod,是微服务架构中的关键问题。
Kubernetes Service(服务)定义了一种抽象,将一组功能相同的 Pod 逻辑分组,并通过标签选择器(Label Selector)实现流量路由。Service 能够为后端 Pod 提供统一的访问入口,解耦前后端依赖,提升系统弹性。
例如,一个图像处理服务运行了多个副本,前端应用无需关心具体调用哪个 Pod,Service 负责将请求分发到后端所有可用副本。Pod 的变更(如重启、扩缩容)不会影响客户端访问,Service 抽象实现了这种解耦。
对于集群内应用,Kubernetes 提供 Endpoints API 自动更新后端地址。对于集群外访问,Service 通过虚拟 IP(VIP)实现统一入口,自动路由到后端 Pod。
定义 Service
Service 是 Kubernetes 的 REST 对象,可通过 YAML/JSON 配置并提交到 API Server 创建。
以下为典型 Service 配置示例:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
该 Service 会将流量转发到所有带有 app=MyApp 标签的 Pod 的 9376 端口,并分配一个集群内部 IP(Cluster IP)。Service 的选择器持续评估,自动更新同名 Endpoints 对象。
targetPort 可为数字或字符串(引用容器端口名),便于后端升级时端口变更而不影响客户端调用。Service 支持 TCP、UDP、SCTP 协议,默认 TCP。
无选择器的 Service
Service 也可用于代理集群外部服务或特殊场景(如跨 Namespace、混合部署),此时无需 selector:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
需手动创建 Endpoints:
apiVersion: v1
kind: Endpoints
metadata:
name: my-service
subsets:
- addresses:
- ip: 1.2.3.4
ports:
- port: 9376
Endpoint IP 不能为回环、链路本地或多播地址。
Service 类型
Kubernetes 支持多种 ServiceType,满足不同访问需求。
| 类型 | 说明 | 典型场景 |
|---|---|---|
| ClusterIP | 仅集群内可访问(默认) | 内部微服务通信 |
| NodePort | 每个 Node 分配静态端口,外部可通过 <NodeIP>:<NodePort> 访问 | 开发测试、简单暴露 |
| LoadBalancer | 云厂商负载均衡器,自动分配外部 IP | 生产级外部访问 |
| ExternalName | 通过 CNAME 指向外部 DNS 名称 | 代理外部服务 |
ClusterIP
仅集群内部可访问,适合微服务间通信。
NodePort
每个 Node 分配静态端口,外部可通过 <NodeIP>:<NodePort> 访问。端口范围默认 30000-32767。
LoadBalancer
云平台自动创建负载均衡器,分配外部 IP,适合生产环境暴露服务。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
ExternalName
通过 CNAME 方式代理外部服务,无需代理流量。
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
ExternalName 不能直接解析为 IP,推荐用于 DNS 名称代理。
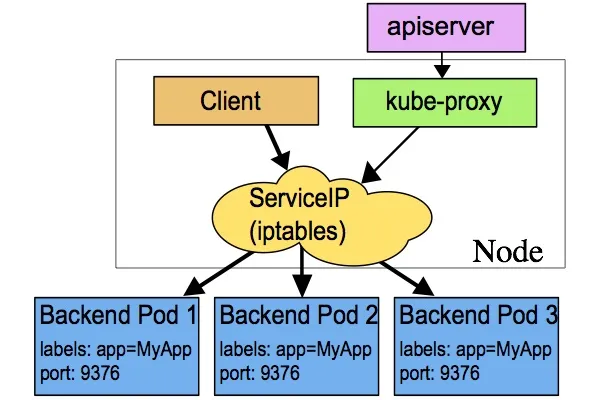
Service 代理模式
每个 Node 运行 kube-proxy,负责实现 Service 虚拟 IP(VIP)代理。
iptables 代理模式
kube-proxy 监控 Service/Endpoints 变化,自动生成 iptables 规则,将流量重定向到后端 Pod。支持基于客户端 IP 的会话亲和性(service.spec.sessionAffinity: ClientIP)。
IPVS 代理模式
基于内核 IPVS,性能优于 iptables,支持多种负载均衡算法(轮询、最少连接、哈希等),适合大规模集群。
多端口 Service
Service 支持暴露多个端口,需为每个端口命名,避免歧义。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
自定义 ClusterIP
可通过 spec.clusterIP 指定自定义集群 IP,需在 --service-cluster-ip-range 范围内。若无效,API Server 返回 422 错误。
服务发现机制
Kubernetes 支持环境变量和 DNS 两种服务发现方式。
环境变量
Pod 启动时,kubelet 为每个 Service 注入环境变量(如 REDIS_MASTER_SERVICE_HOST)。需注意 Service 必须先于 Pod 创建。
DNS
推荐方式。集群内 DNS 服务器为每个 Service 创建 DNS 记录,支持 A 记录和 SRV 记录。跨 Namespace 需使用全限定名(如 my-service.my-ns)。
Headless Service
如无需负载均衡和 VIP,可将 spec.clusterIP 设为 "None",实现 Headless Service。此时 DNS 直接返回所有后端 Pod 的 IP,适合自注册、状态同步等场景。
- 有选择器:DNS 返回 Pod IP 列表
- 无选择器:需手动创建 Endpoints
外部 IP 与 externalIPs
Service 可通过 externalIPs 字段暴露外部 IP,需由集群管理员保证路由可达。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
externalIPs:
- 80.11.12.10
虚拟 IP 实现与冲突避免
Kubernetes 为每个 Service 分配唯一 VIP,避免端口冲突。VIP 通过 iptables 或 IPVS 规则实现,客户端访问 VIP 时自动转发到后端 Pod。
API 对象与参考
Service 是 Kubernetes 顶级 REST 资源,详细字段见 Service API 对象。
总结
Kubernetes Service 通过标签选择器、虚拟 IP、灵活的代理和服务发现机制,实现了微服务架构下的高可用、可扩展和易维护的服务访问。建议结合实际场景选择合适的 Service 类型和发现方式,提升系统健壮性。