图像分类
概述
在我们开启嵌入式机器学习(TinyML)学习之旅时,计算机视觉(CV)与人工智能(AI)对生活的深远影响已不可忽视。这两大领域相互交织,从自动驾驶、机器人到医疗健康与安防监控,持续重塑着机器的感知与能力边界。
当前,我们正处于人工智能(AI)革命的浪潮中。正如 Gartner 所言,边缘 AI(Edge AI) 已具备极高的影响力,并且已经到来!

在技术雷达的“靶心”位置正是 边缘计算机视觉。谈及视觉领域的机器学习(ML)应用,最先想到的便是图像分类,这也是 ML 领域的“Hello World”项目!
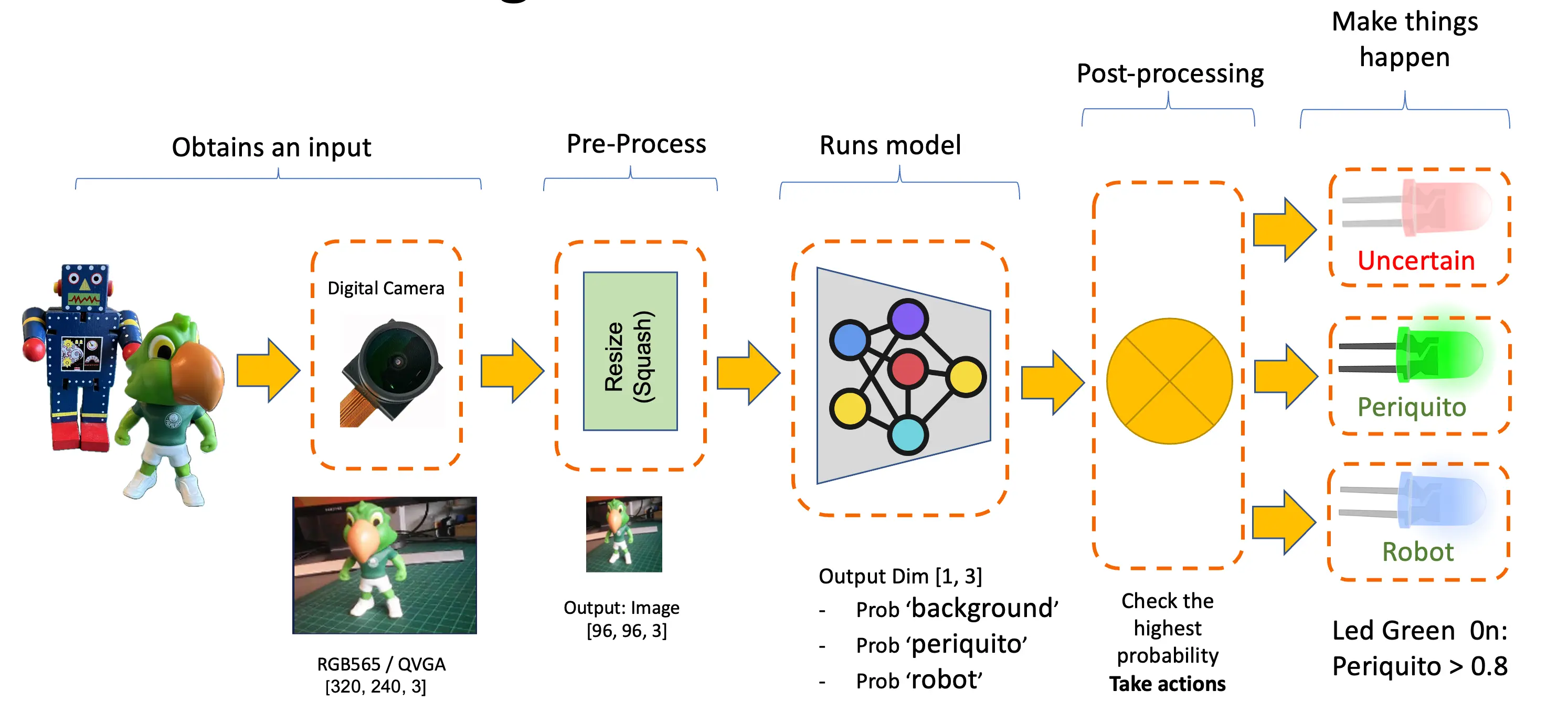
本实验将带你实践一个基于卷积神经网络(CNN)的计算机视觉项目,实现实时图像分类。我们将借助 TensorFlow 强大的生态系统,采用预训练的 MobileNet 模型,并针对边缘设备进行适配优化。重点在于让模型在资源受限的硬件上高效运行,同时保证准确率。
我们会用到量化(quantization)、剪枝(pruning)等模型优化技术,降低计算负载。完成本教程后,你将获得一个可在 Arduino Nicla Vision 板卡等低功耗嵌入式系统上实时分类图像的原型系统。
计算机视觉简介
计算机视觉的核心在于让机器能够理解和决策来自现实世界的视觉数据,模拟人类视觉系统的能力。而人工智能则是更广泛的领域,涵盖机器学习、自然语言处理、机器人等多种技术。当 AI 算法与计算机视觉结合时,系统对视觉信息的理解、解释和反应能力将大幅提升。
在嵌入式设备上应用计算机视觉,最常见的场景就是图像分类与目标检测。

这两类模型都可以在如 Arduino Nicla Vision 这样的小型设备上实现,并应用于实际项目。本章聚焦于图像分类。
图像分类项目目标
任何机器学习项目的第一步都是明确目标。本项目旨在检测并分类一张图片中的两种特定物体。我们选择了两个小玩具:一个机器人和一只巴西鹦鹉(Periquito),同时还会采集背景图片(即不含这两种物体的场景)。

数据采集
明确项目目标后,最关键的步骤就是采集数据集。采集图片可以通过以下方式:
- Web Serial Camera 工具
- Edge Impulse Studio
- OpenMV IDE
- 智能手机
本项目采用 OpenMV IDE 进行数据采集。
使用 OpenMV IDE 采集数据集
首先,在电脑上新建一个用于保存数据的文件夹,例如“data”。然后在 OpenMV IDE 中,依次点击 Tools > Dataset Editor,选择 New Dataset 开始采集:
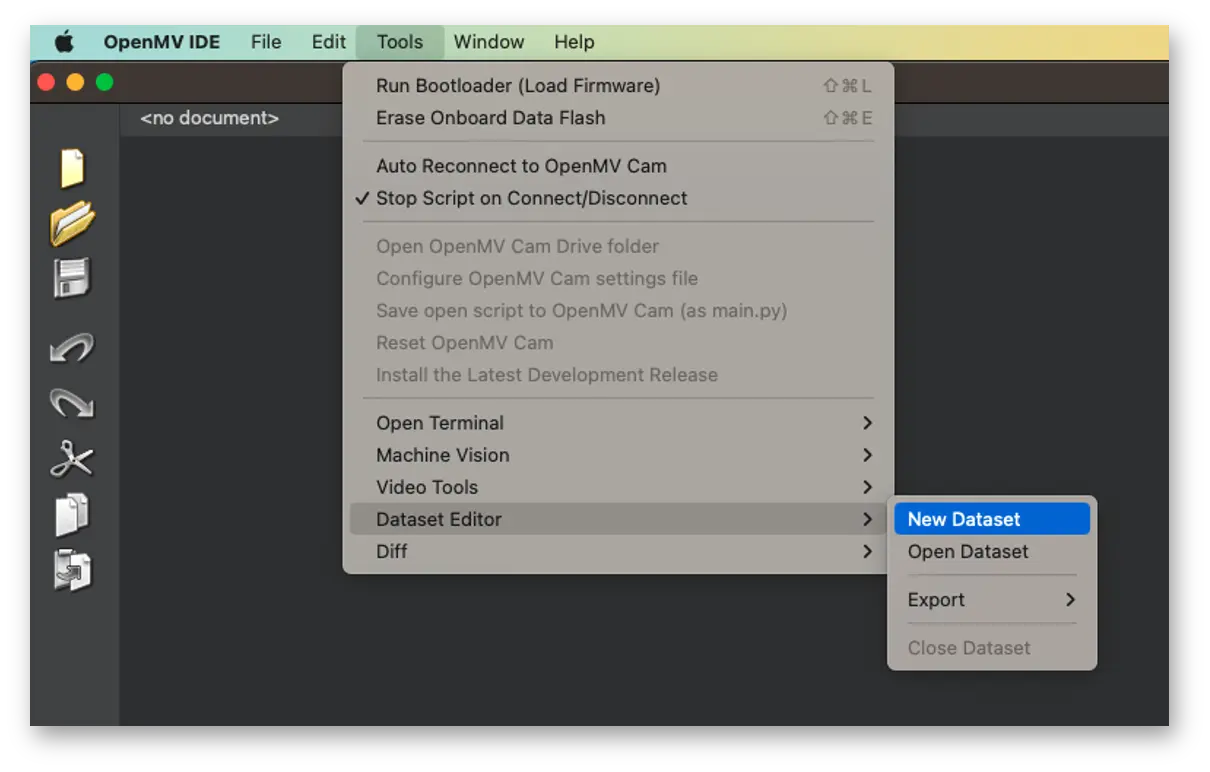
IDE 会提示选择数据保存路径,选择刚刚创建的“data”文件夹。此时左侧面板会出现新的图标。

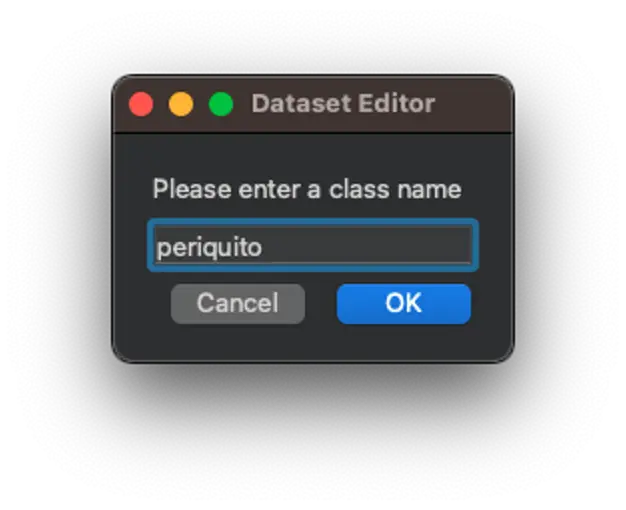
点击上方图标(1),输入第一个类别名称,如“periquito”:
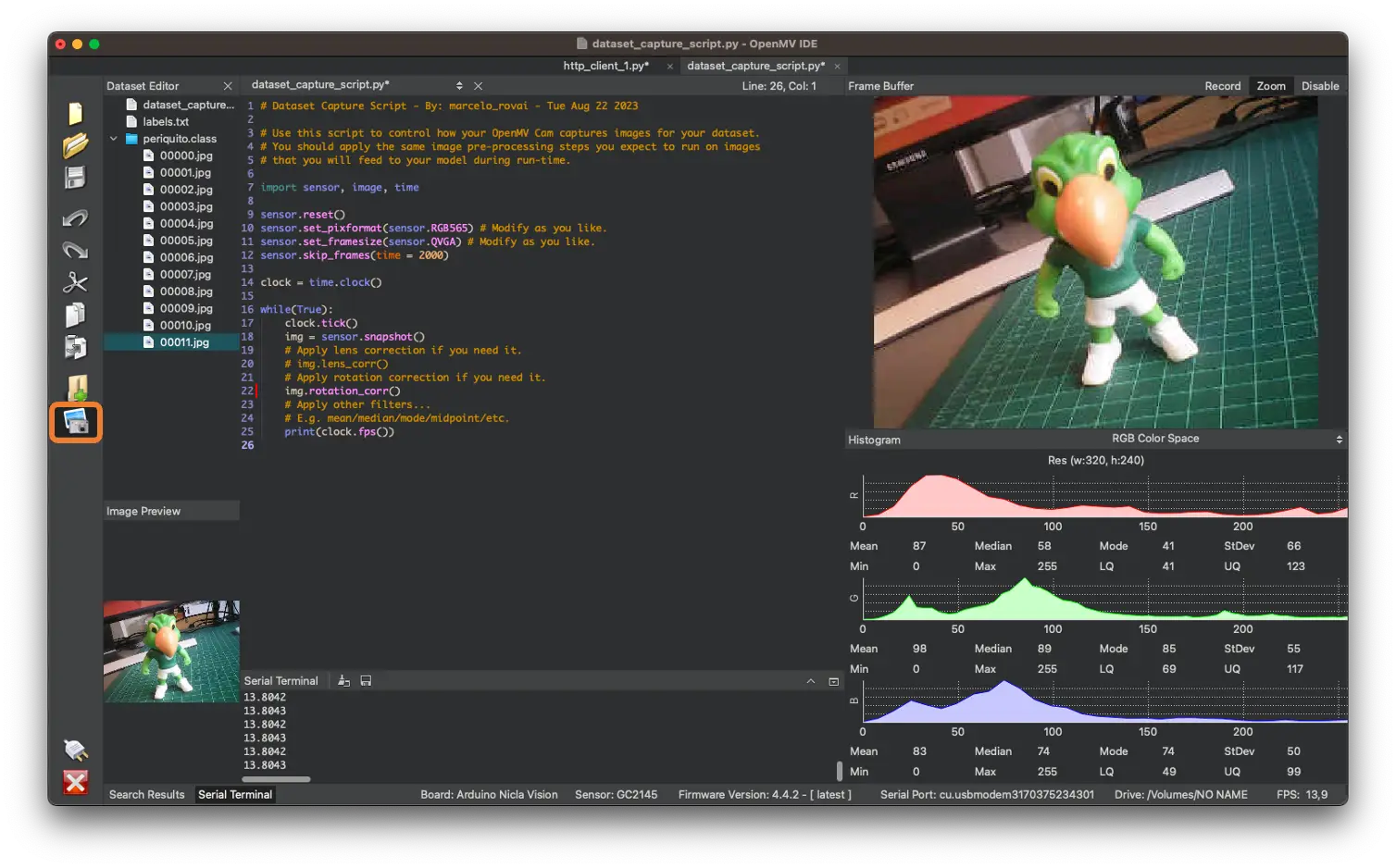
运行 dataset_capture_script.py,点击相机图标(2)即可开始采集图片:
对其他类别重复上述操作。
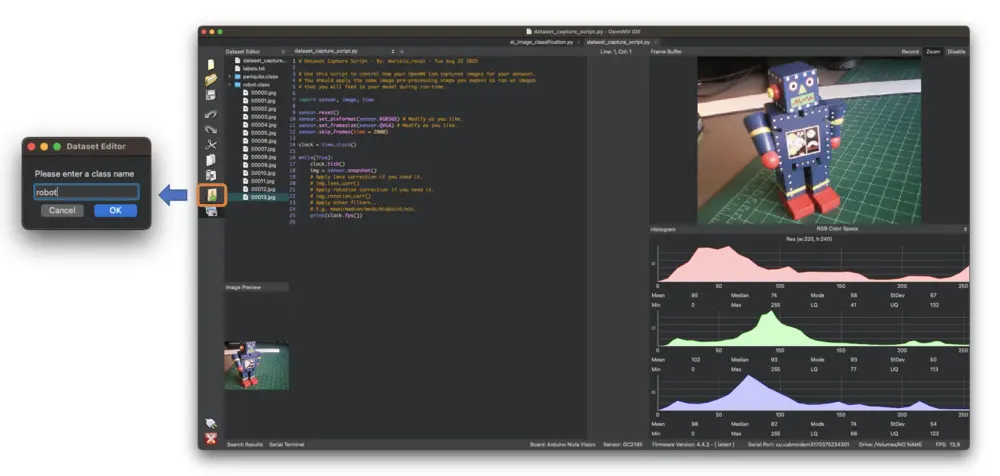
建议每个类别采集 50~60 张图片,尽量涵盖不同角度、背景和光照条件。
采集的图片为 QVGA 尺寸 $320\times 240$,采用 RGB565 色彩格式。
采集完成后,关闭 Tools > Dataset Editor。
最终,我们会得到包含 periquito、robot 和 background 三个类别的数据集。
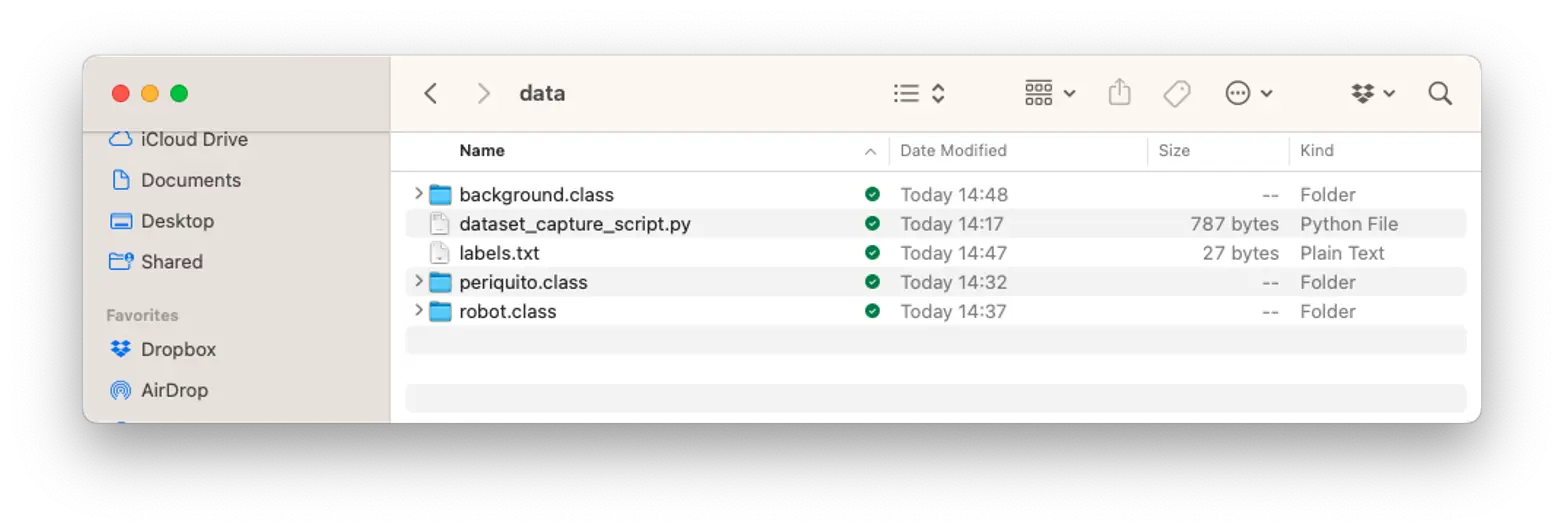
接下来,回到 Edge Impulse Studio,将数据集上传到已创建的项目中。
使用 Edge Impulse Studio 训练模型
我们将利用 Edge Impulse Studio 训练模型。登录账号并新建项目:
你也可以克隆类似项目: NICLA-Vision_Image_Classification 。
数据集处理
在 EI Studio(下称 Studio)中,主要分为四步:数据集、Impulse 设计、测试和部署(本例为 NiclaV 板卡)。
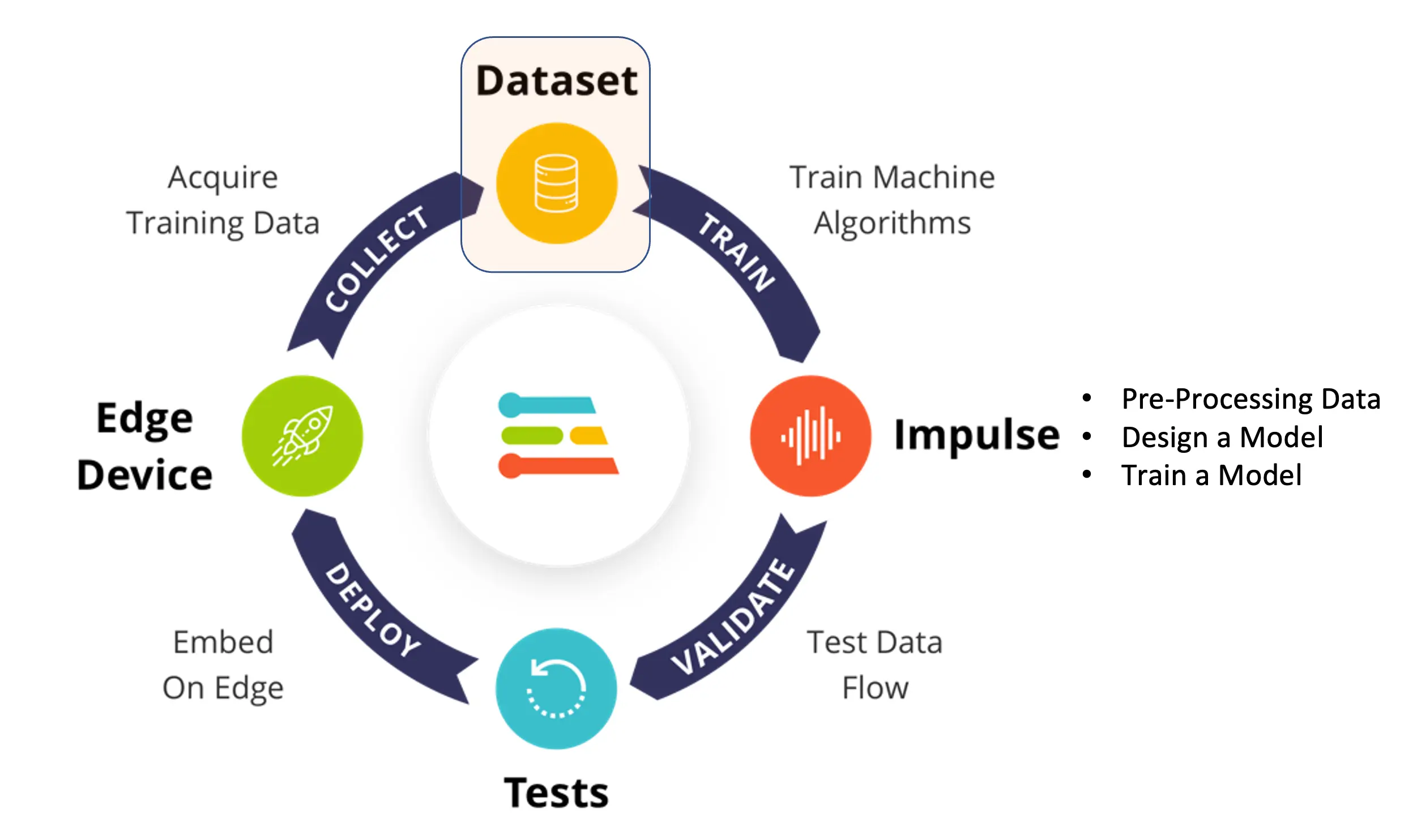
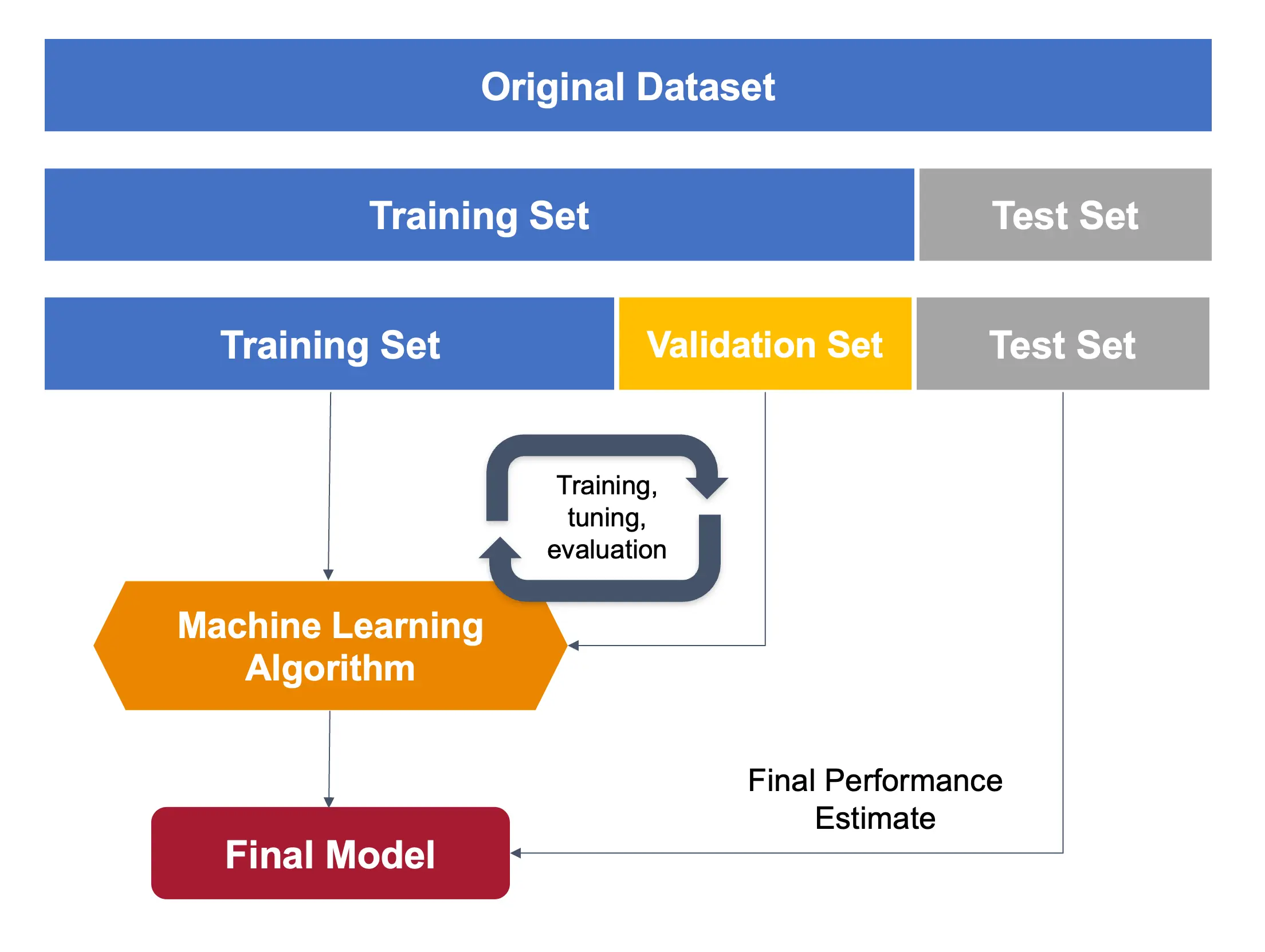
关于数据集,需注意:我们用 OpenMV IDE 采集的原始数据集会被自动划分为 训练集、验证集 和 测试集。测试集从一开始就分离出来,仅在训练后用于测试。验证集则在训练过程中使用。
Studio 会自动从训练数据中划分一部分作为验证集
在 Studio 的 Data acquisition 标签页,点击 UPLOAD DATA 区域,上传各类别的图片:
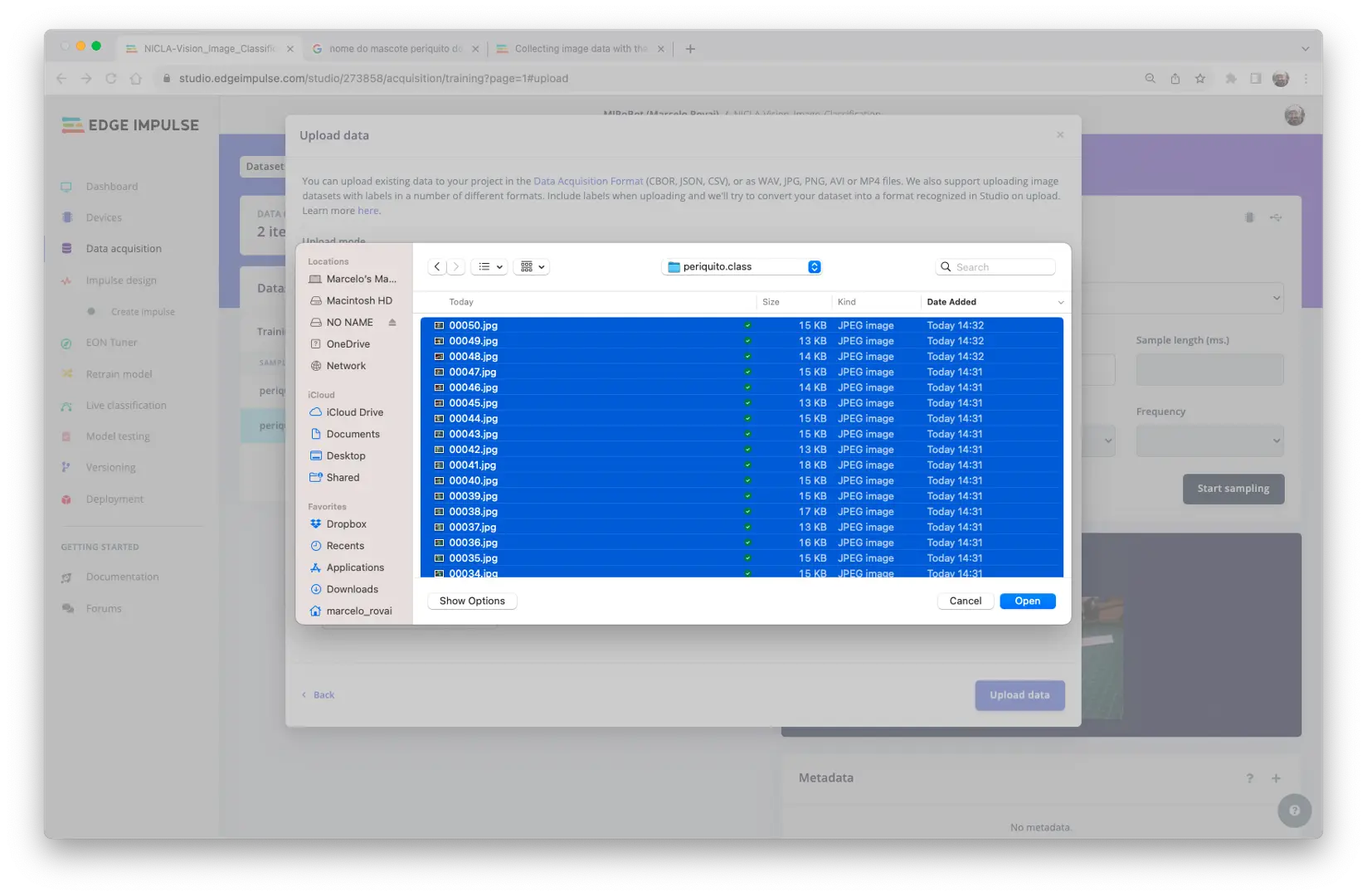
数据集的划分(训练/测试)可交由 Studio 自动完成,并为每类数据选择标签:
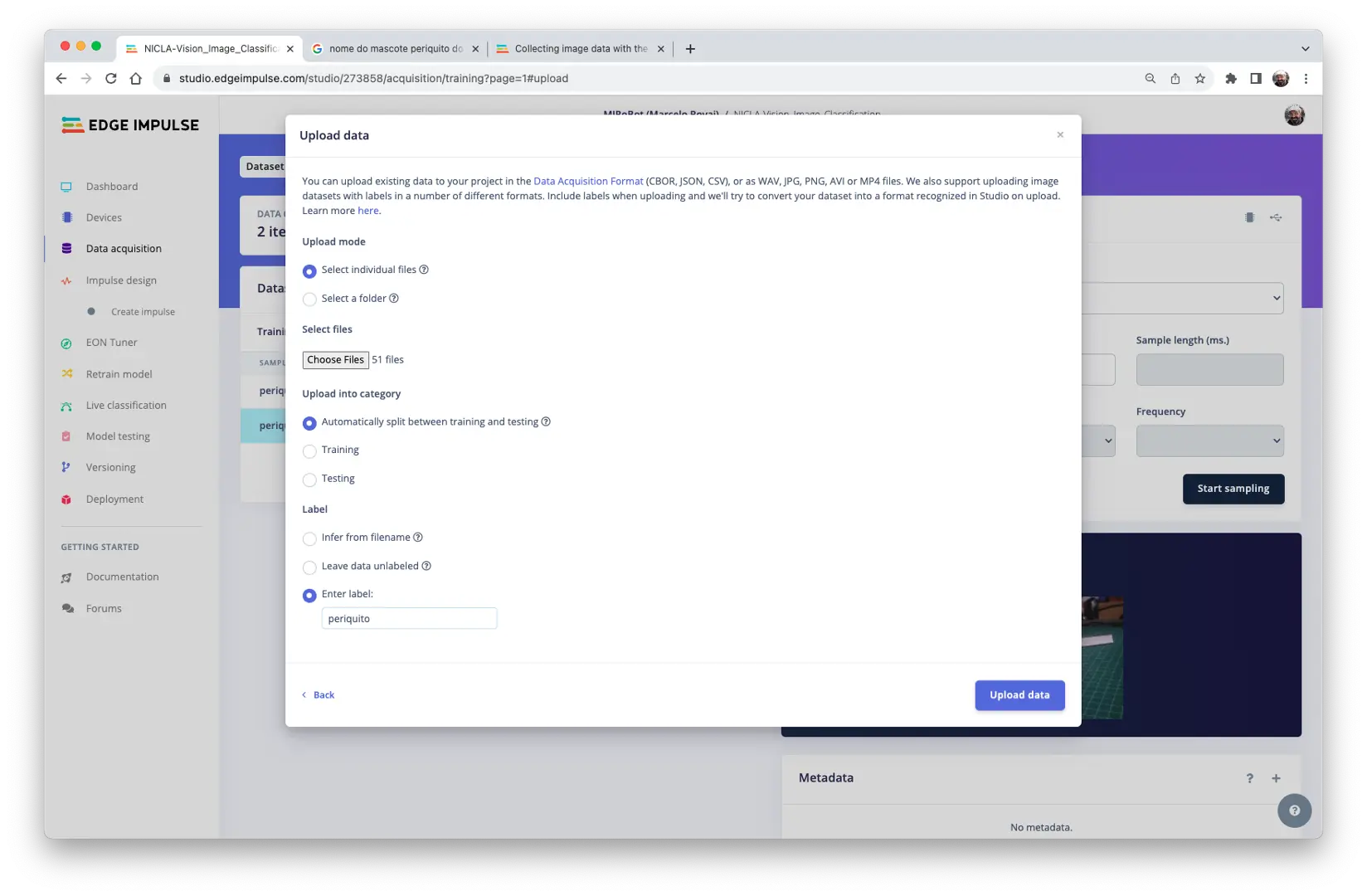
对三类数据重复上传操作。
支持选择整个文件夹,一次性上传所有图片。
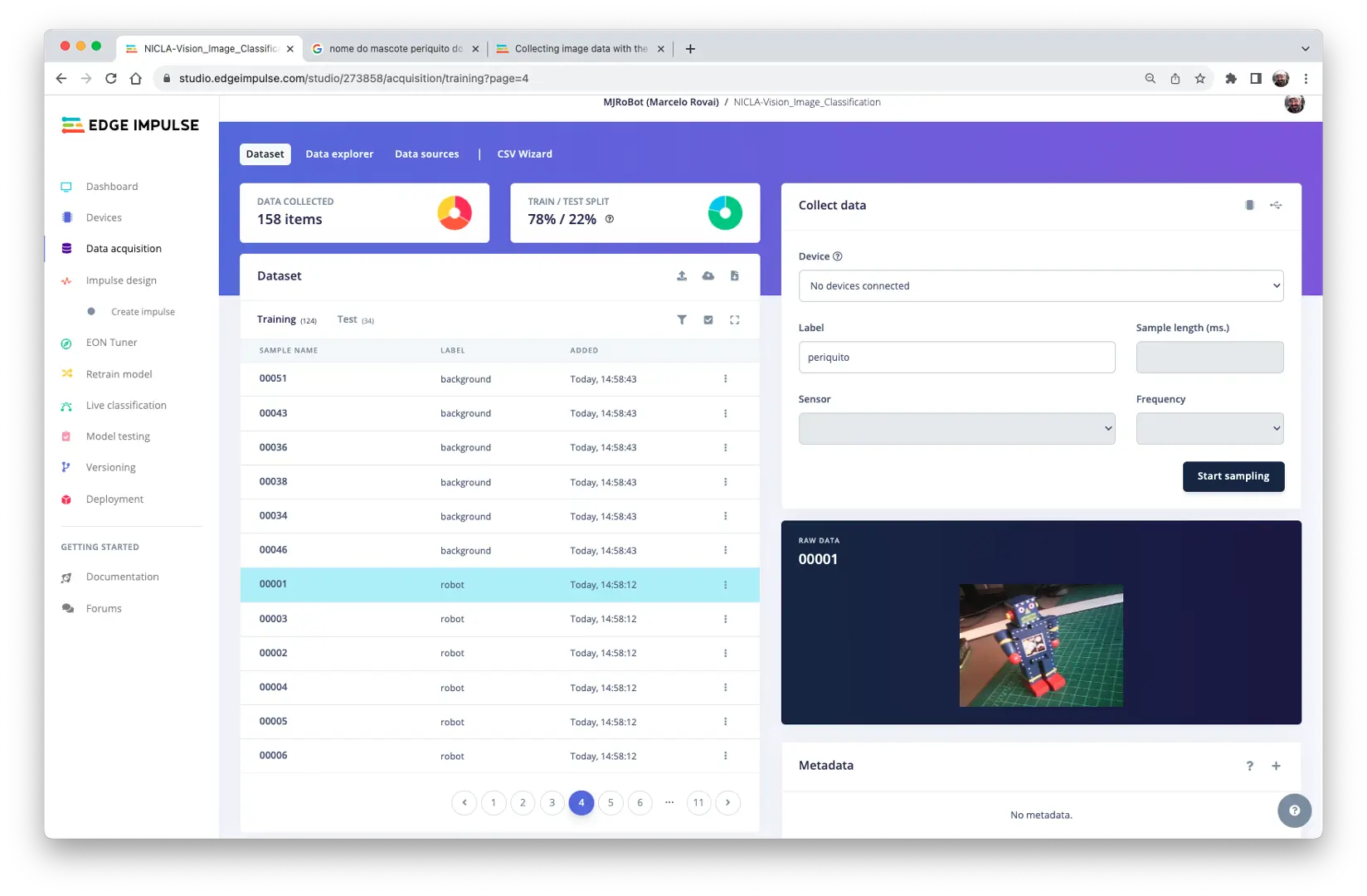
上传完成后,可在 Studio 中查看“原始数据”:
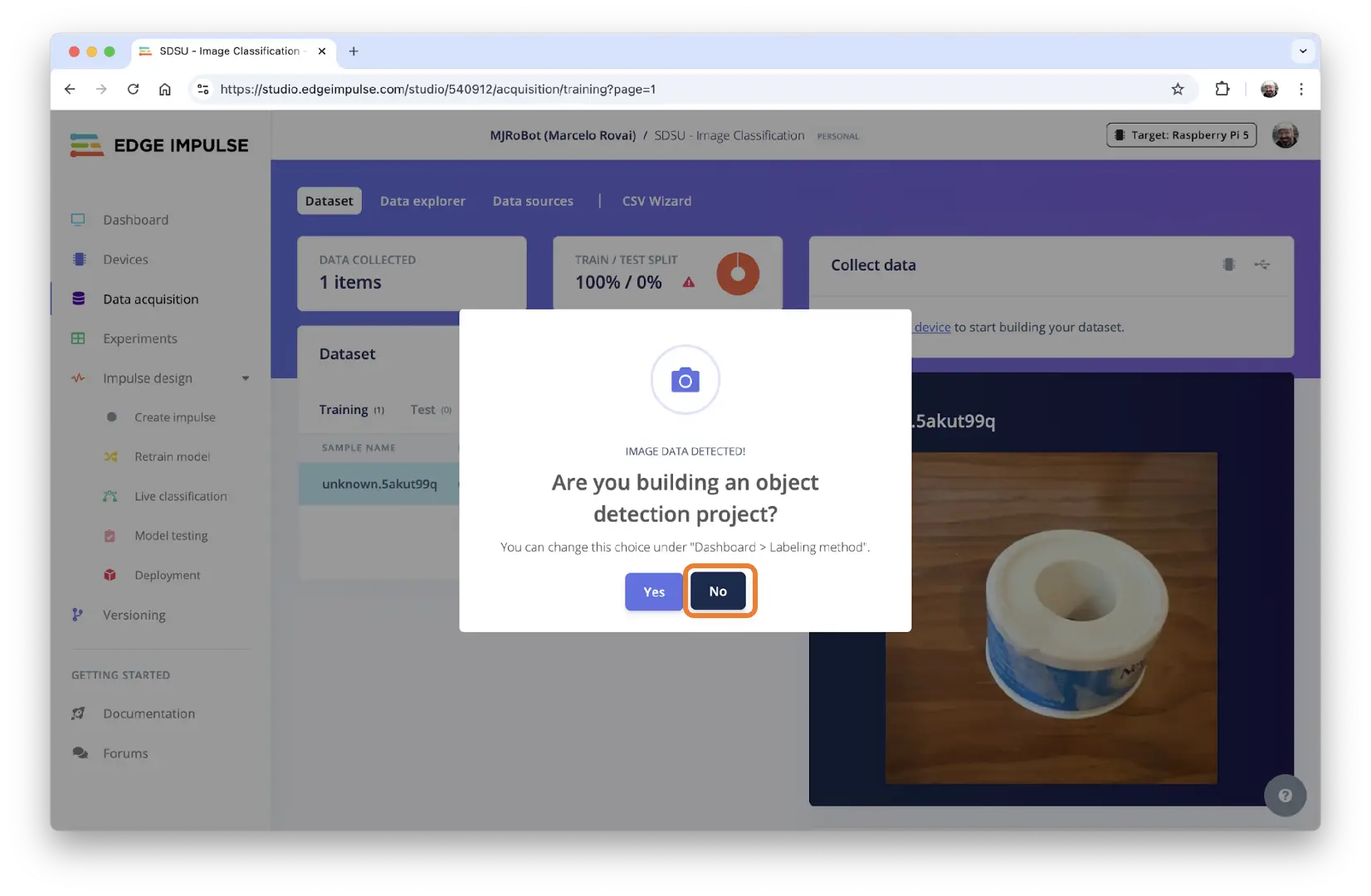
上传过程中,可能弹出窗口询问是否为目标检测项目,选择 [NO]。
如需更改,可在 Dashboard 区域设置为 One label per data item(图像分类):
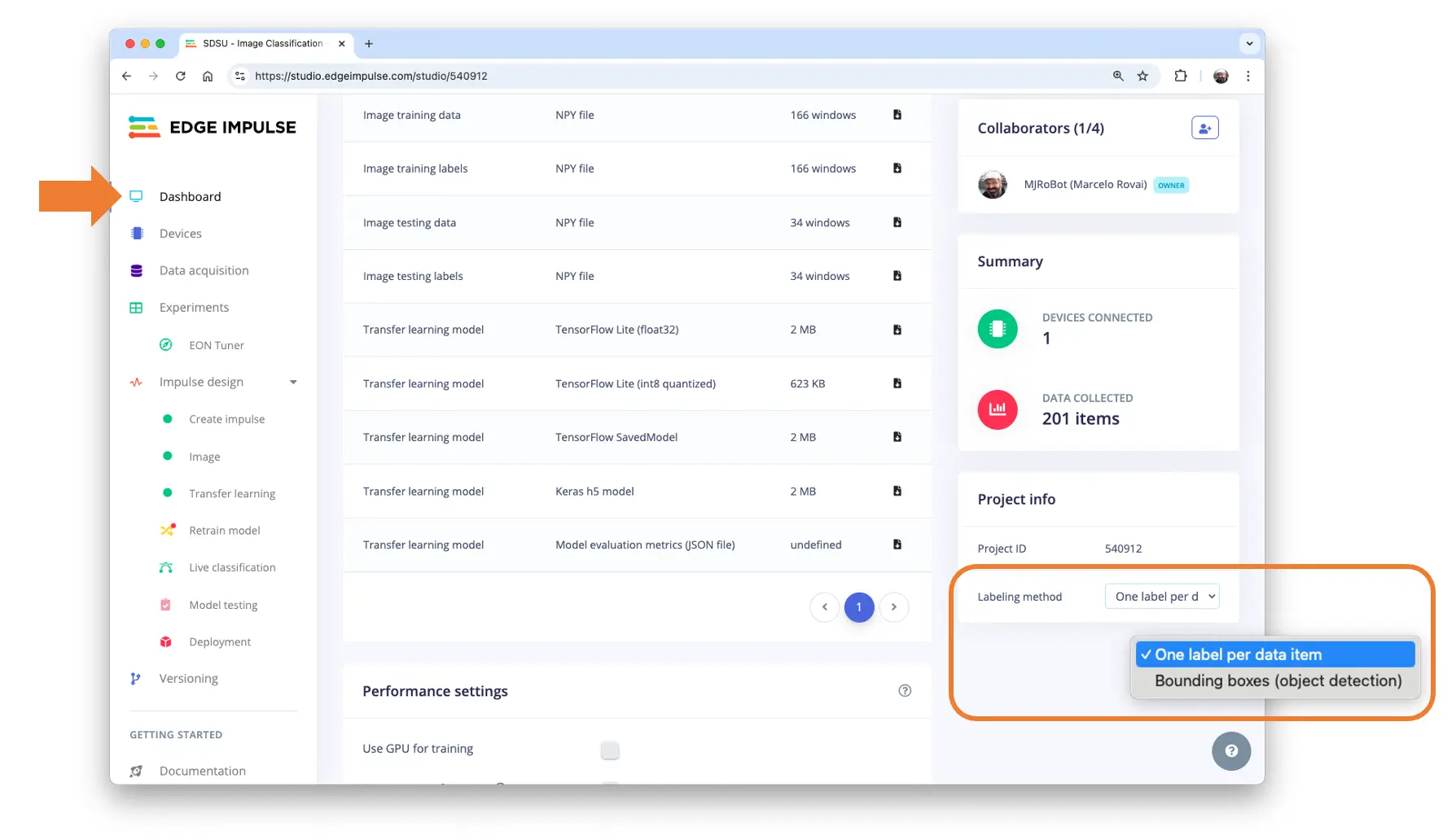
Studio 还支持数据浏览、清理和标签修改。对于本项目,数据已准备就绪。
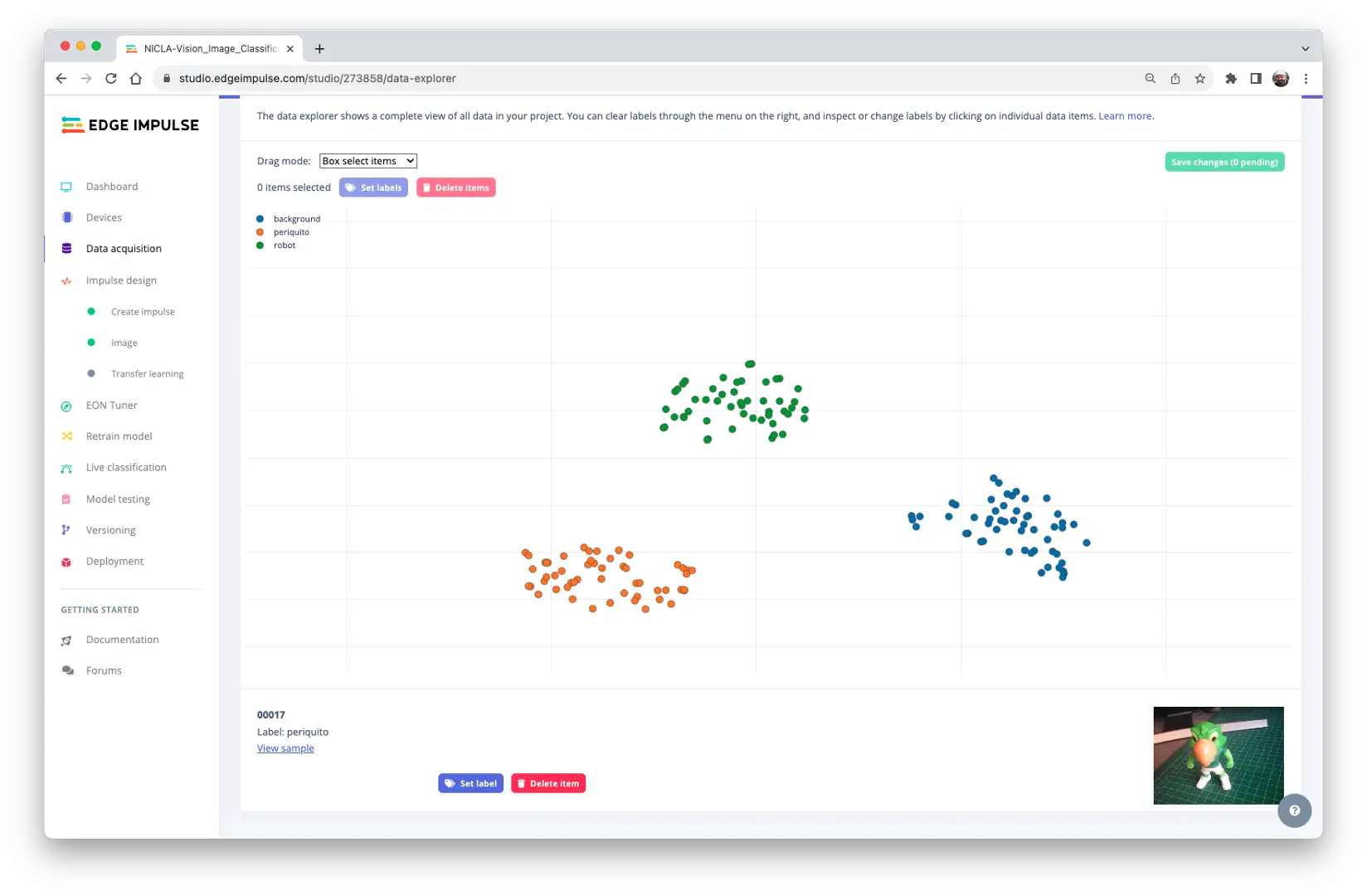
Impulse 设计
本阶段需完成以下两步:
- 数据预处理:包括图片尺寸调整、色彩深度(RGB 或灰度)选择
- 模型选择:本项目采用
Transfer Learning (Images),即在预训练 MobileNet V2 基础上微调,适合小型数据集(如本例约 150 张图片)
基于 MobileNet 的迁移学习(Transfer Learning)极大简化了模型训练流程,尤其适合资源受限环境和标注数据有限的项目。MobileNet 以轻量级著称,已在大规模数据集(如 ImageNet)上学习到丰富特征。
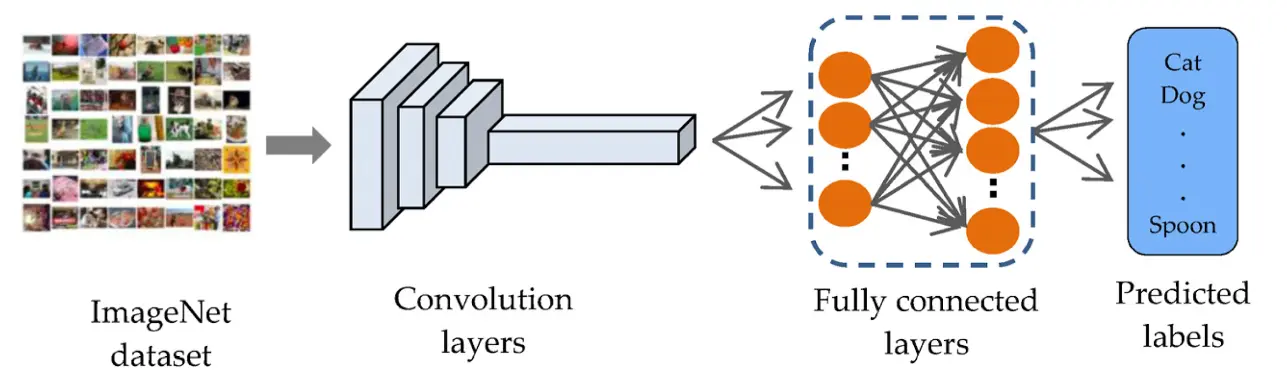
借助这些预训练特征,即使数据量较小,也能训练出高准确率的新模型,且计算资源消耗较低。
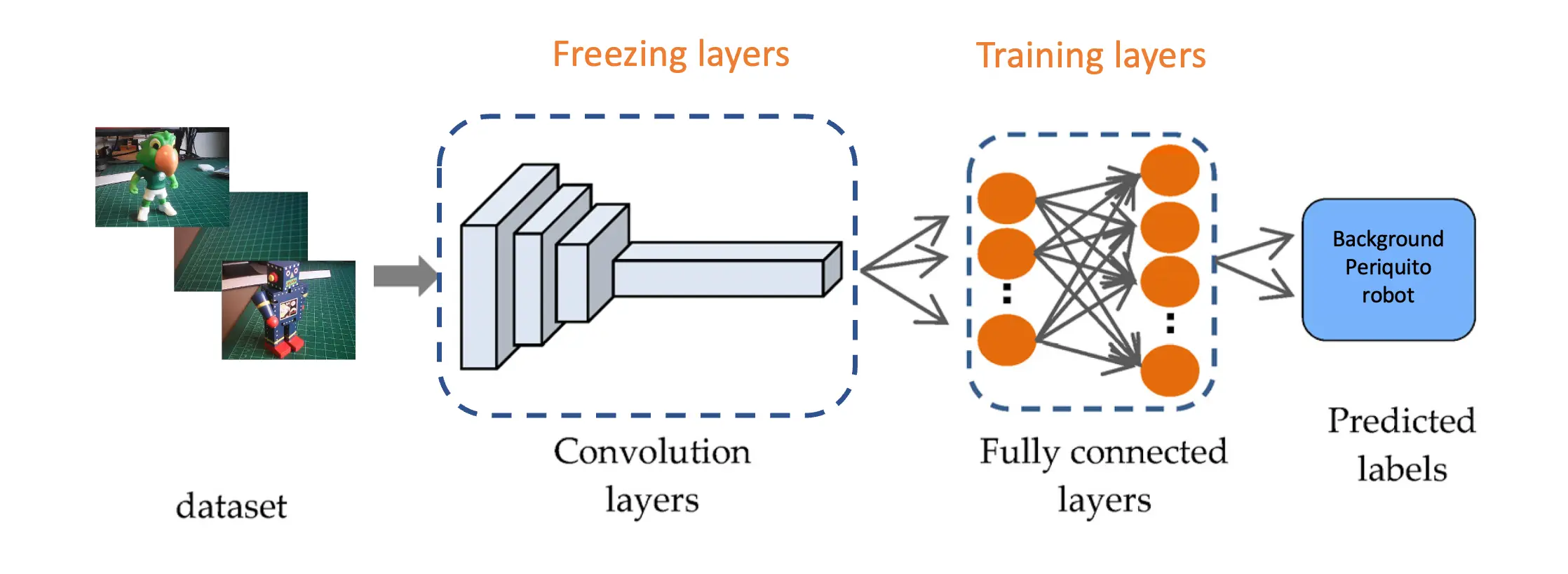
这种方法显著缩短训练时间、降低计算成本,非常适合嵌入式设备上的快速原型开发与部署。
在 Impulse Design 标签页,创建 impulse,设置图片尺寸为 96x96,选择 Image 和 Transfer Learning 模块,保存设置。
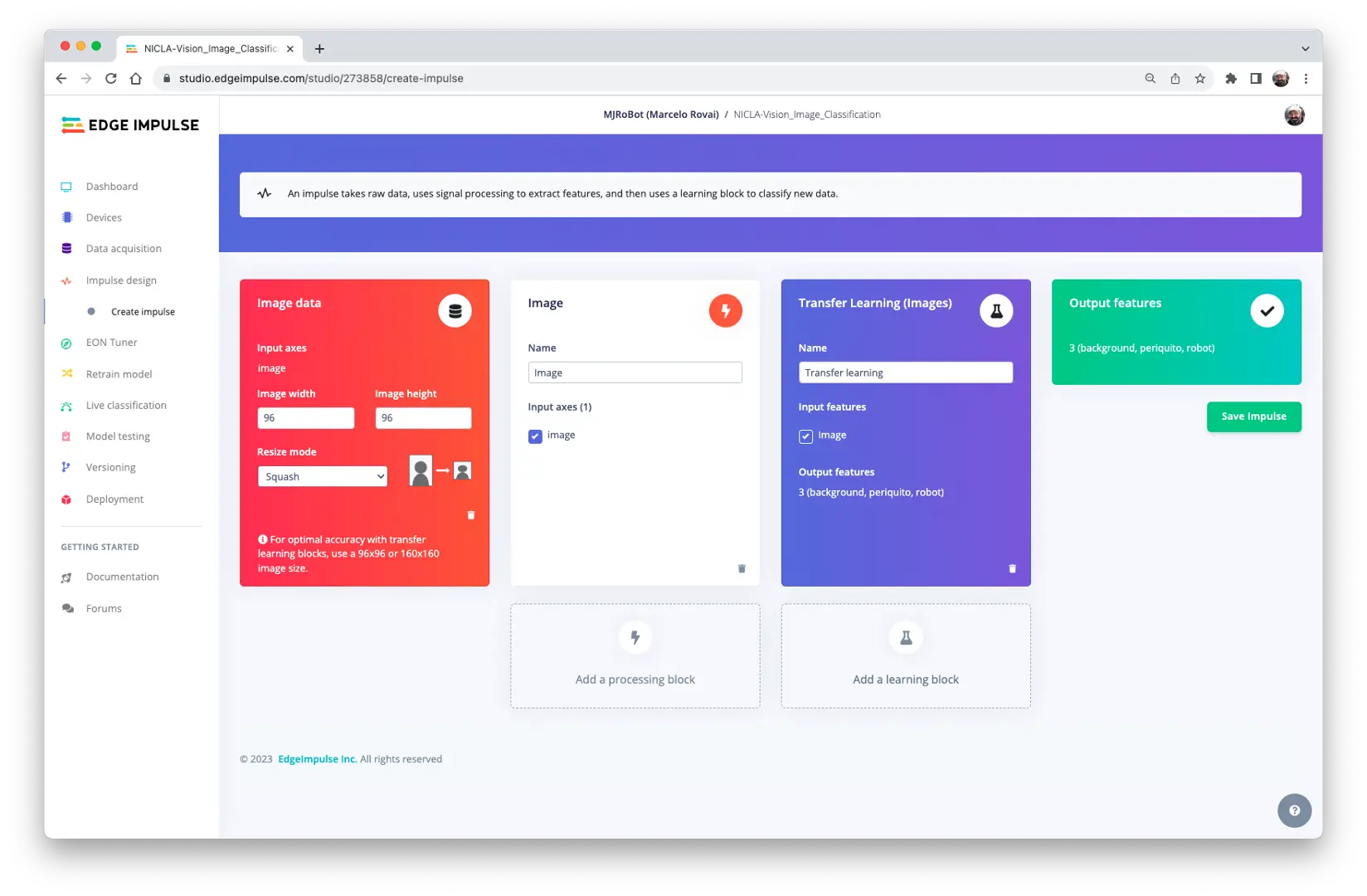
图片预处理
所有输入的 QVGA/RGB565 图片将被转换为 27,640 个特征($96\times 96\times 3$)。
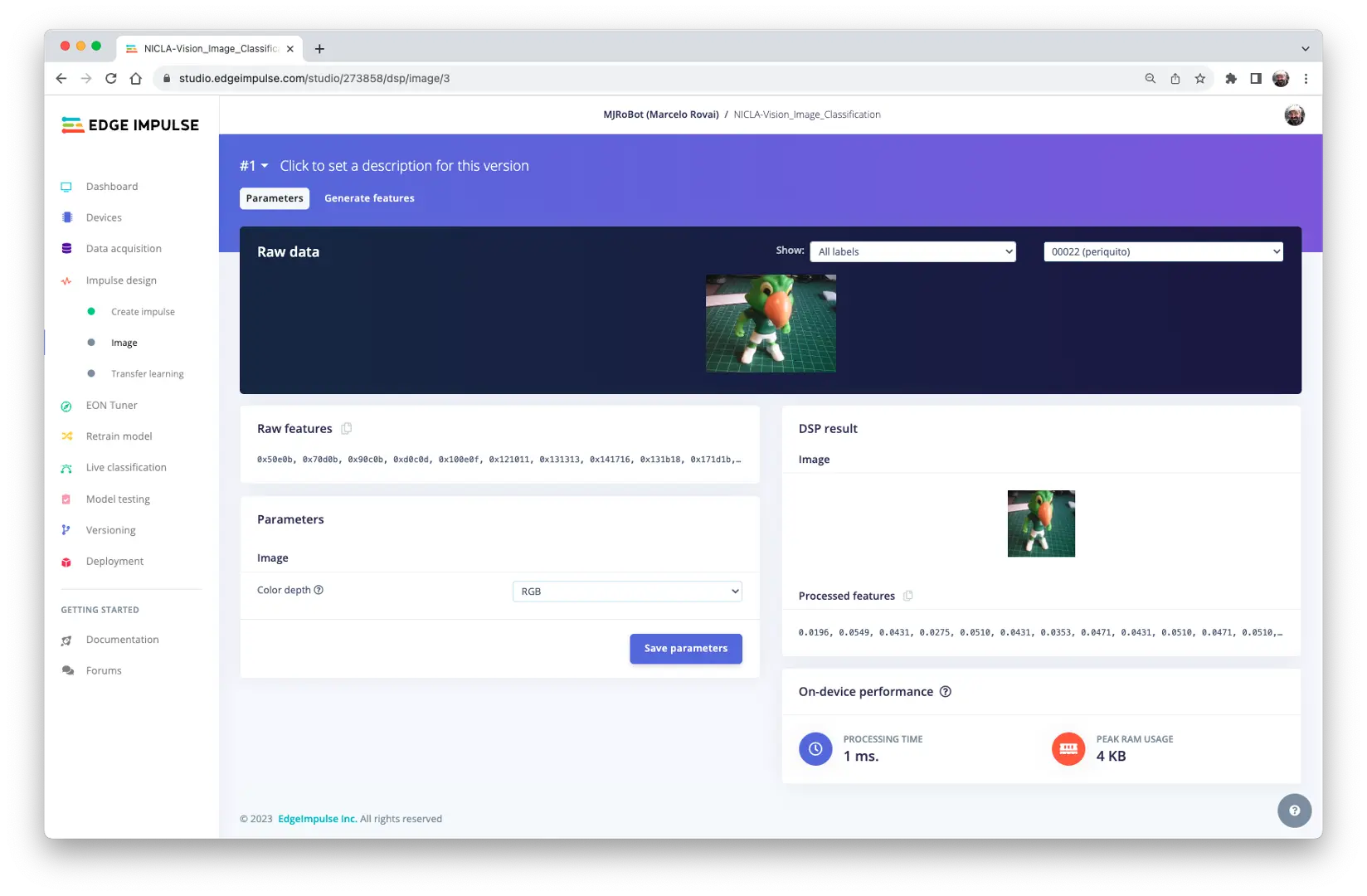
点击 [Save parameters] 并生成全部特征:
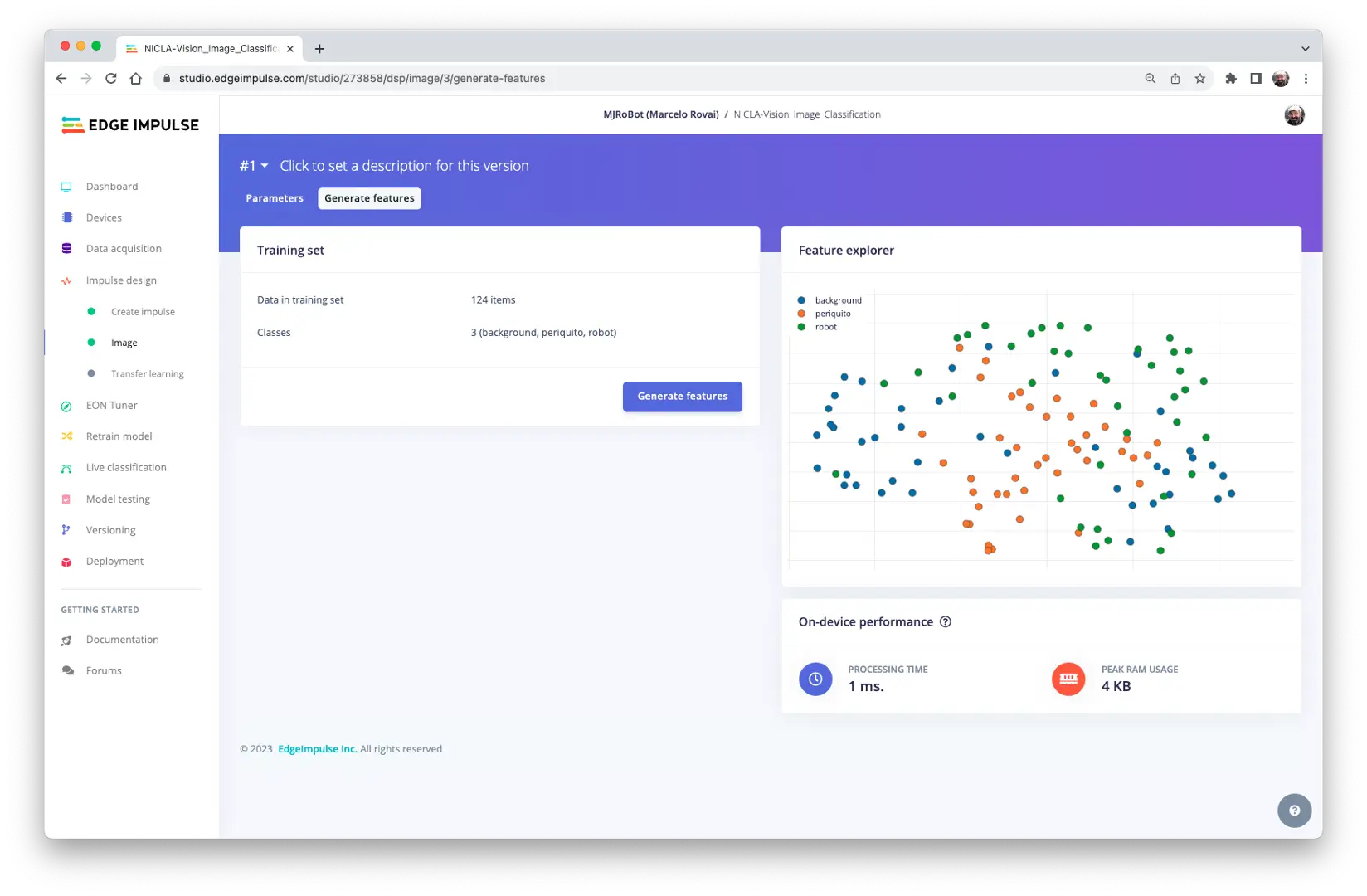
模型设计
2007 年,Google 推出 MobileNetV1 ,专为移动端设计的通用视觉神经网络,支持分类、检测等任务。MobileNet 以小巧、低延迟、低功耗著称,并可根据实际需求调整模型规模。2018 年,Google 又发布了 MobileNetV2: Inverted Residuals and Linear Bottlenecks 。
MobileNet V1 与 V2 都面向移动与嵌入式视觉应用,但 V2 在结构复杂度和性能上更进一步。两者均采用深度可分离卷积以降低计算量,V2 还引入了倒残差块(Inverted Residual Block)和线性瓶颈(Linear Bottleneck),在提升性能的同时进一步减少参数量。此外,V2 在中间扩展层采用非线性激活,而瓶颈层则用线性激活,以保留关键信息。MobileNet V2 以更高的准确率和效率优化了架构,本项目将采用该模型。
尽管 MobileNet 本身已非常小巧且低延迟,但某些场景仍需更小更快的模型。MobileNet 引入了宽度因子 $\alpha$(width multiplier),可在各层均匀缩减网络规模。
Edge Impulse Studio 支持 MobileNetV1($96\times 96$)和 V2($96\times 96$ 或 $160\times 160$),并可选择多种 $\alpha$(0.05~1.0)。例如,V2 + $160\times 160$ + $\alpha=1.0$ 可获得最高准确率,但需约 1.3MB RAM 和 2.6MB ROM,延迟也更高。极致小型化可选 V1 + $\alpha=0.10$,仅需约 53.2K RAM 和 101K ROM。
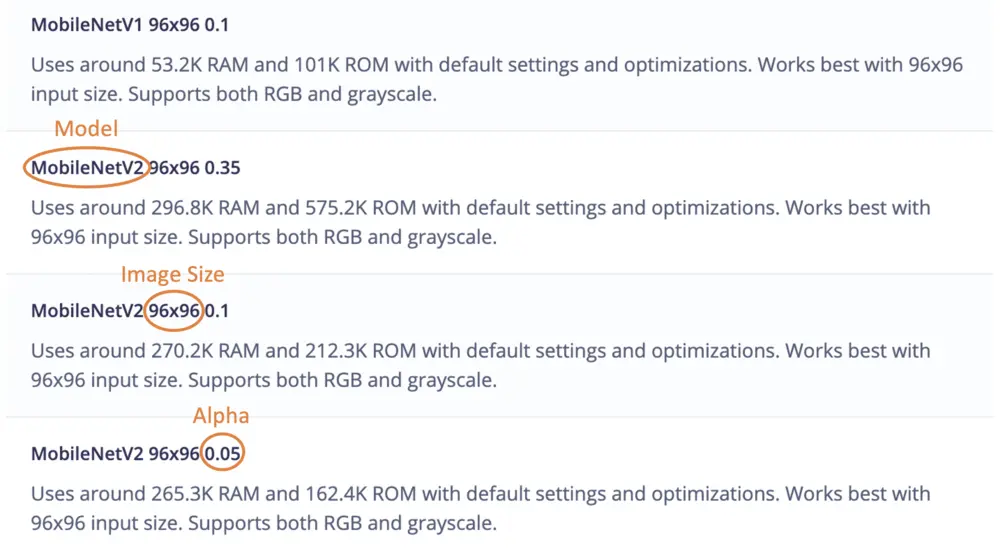
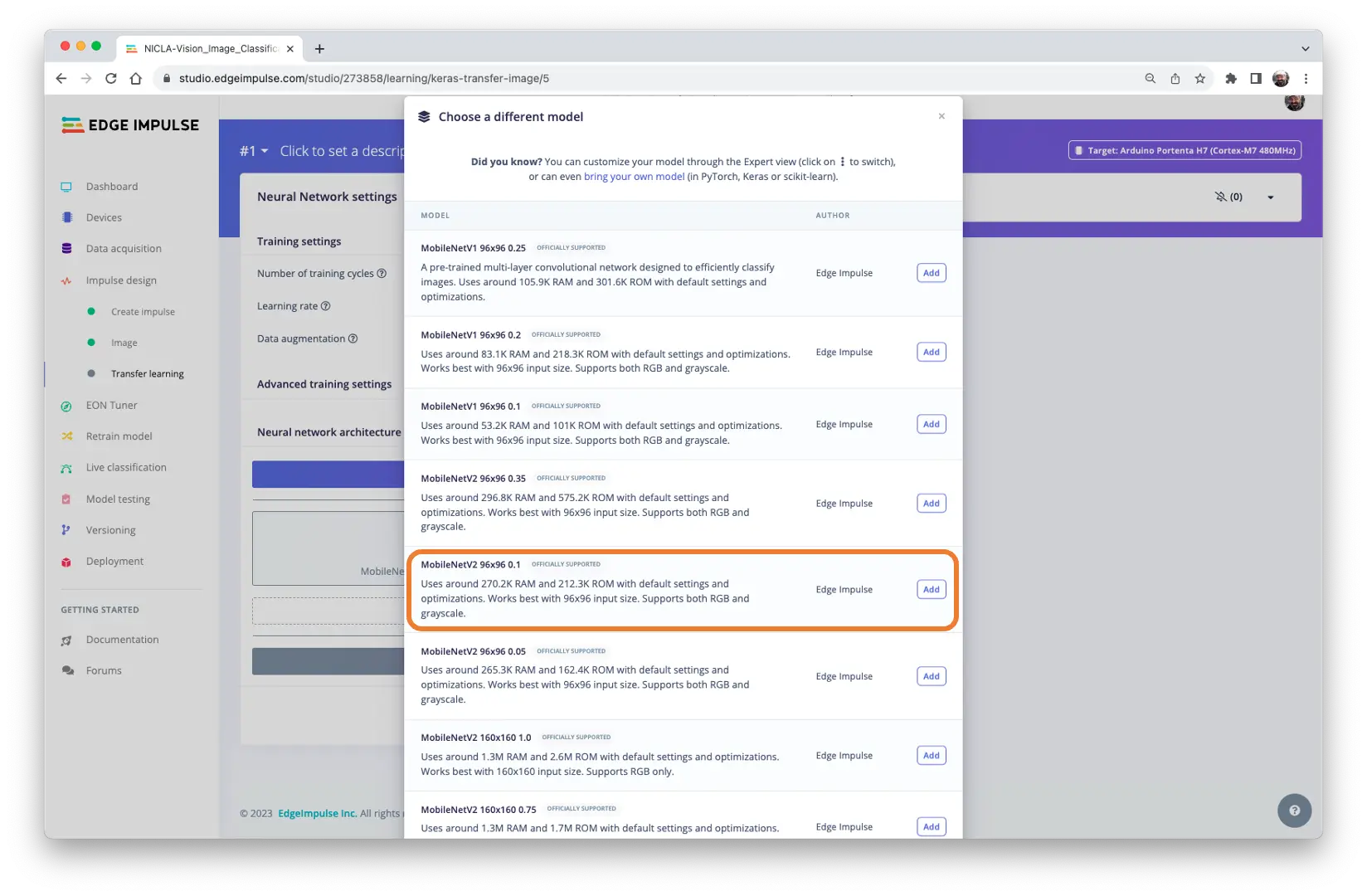
本项目选用 MobileNetV2 96x96 0.1(或 0.05),预计占用 265.3KB RAM,适合 1MB SRAM 的 Nicla Vision。可在 Transfer Learning 标签页选择该模型:
模型训练
深度学习中常用的提升技巧之一是数据增强(Data Augmentation)。通过对训练数据进行随机变换(如翻转、裁剪、旋转等),可生成更多样本,提升模型泛化能力。
以下为 Edge Impulse 实现的数据增强策略示例:
# 实现数据增强策略
def augment_image(image, label):
# 随机水平翻转图片
image = tf.image.random_flip_left_right(image)
# 放大图片后随机裁剪回原尺寸
resize_factor = random.uniform(1, 1.2)
new_height = math.floor(resize_factor * INPUT_SHAPE[0])
new_width = math.floor(resize_factor * INPUT_SHAPE[1])
image = tf.image.resize_with_crop_or_pad(image, new_height,
new_width)
image = tf.image.random_crop(image, size=INPUT_SHAPE)
# 随机调整亮度
image = tf.image.random_brightness(image, max_delta=0.2)
return image, label
训练过程中引入这些变化,有助于防止模型“死记硬背”训练集表面特征,更好地学习数据的深层规律。
最终模型输出层包含 12 个神经元,并采用 15% dropout 防止过拟合。训练结果如下:
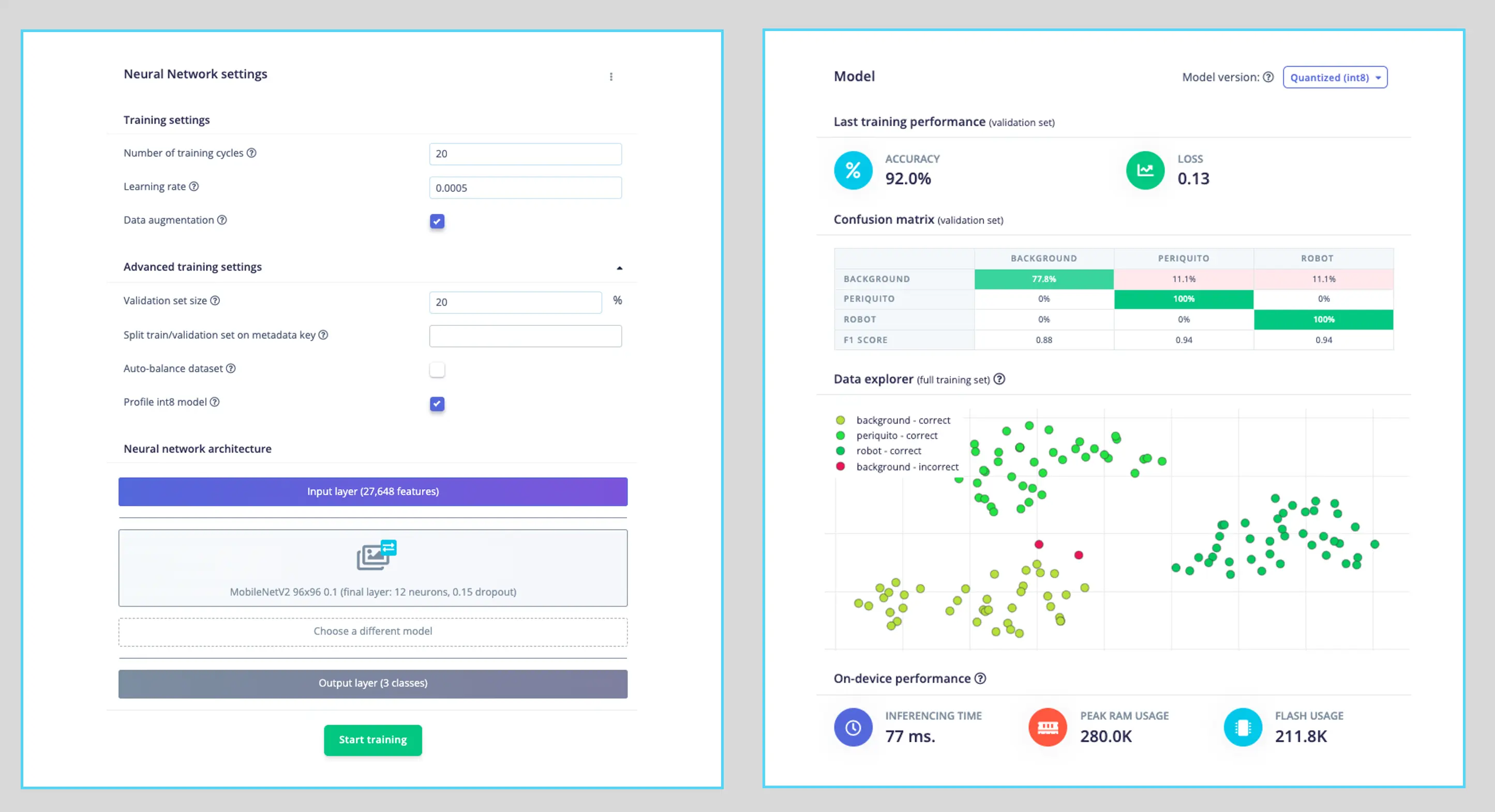
结果非常理想,推理延迟约 77ms,预计可实现约 13 帧/秒。
模型测试
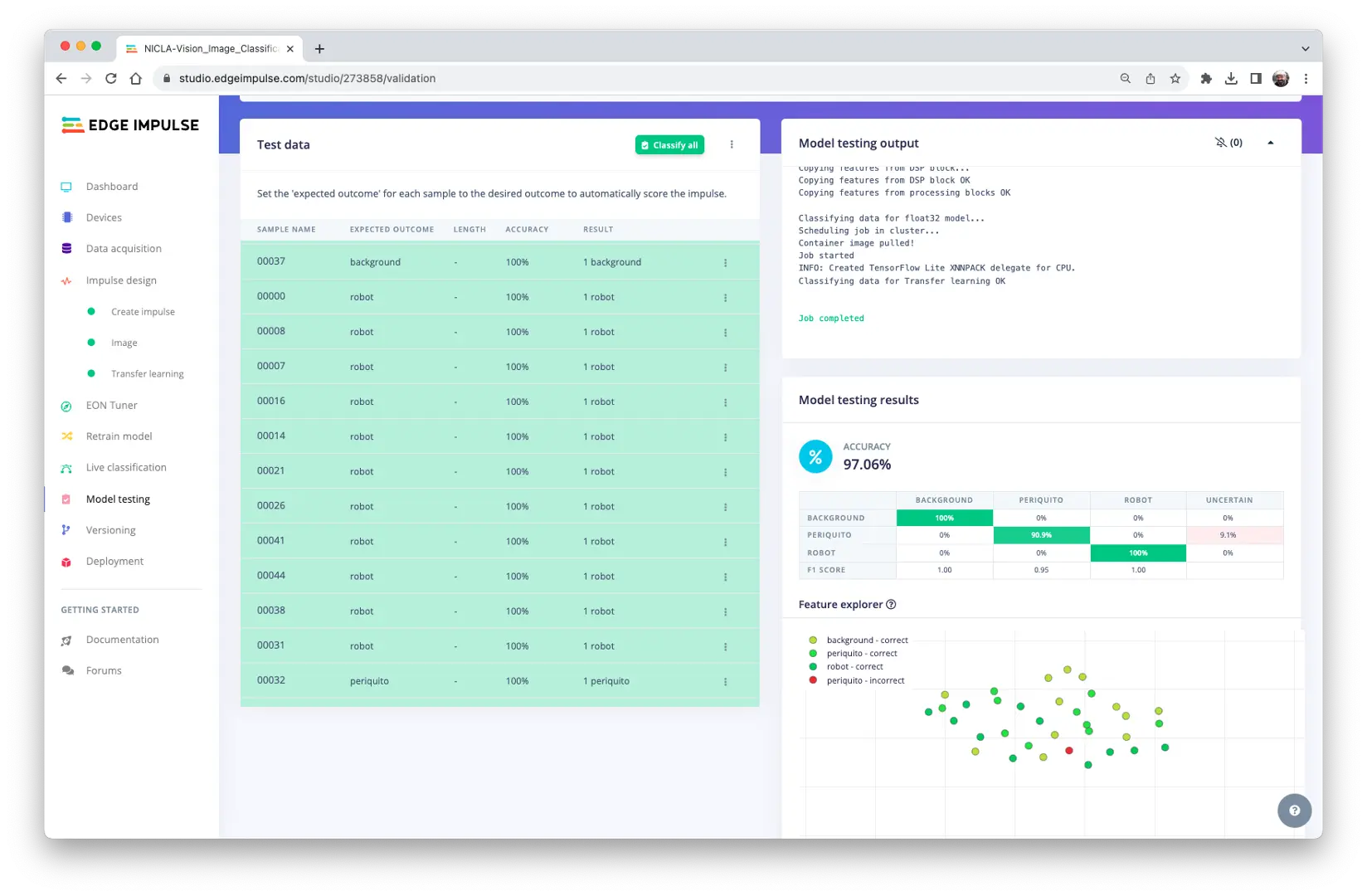
此时,可用项目初始预留的测试集对训练好的模型进行测试:
测试结果同样优秀。
部署模型
此时可将训练好的模型以固件(FW)形式部署,并通过 OpenMV IDE 运行 MicroPython 脚本,或导出为 C/C++ 或 Arduino 库。
Arduino 库部署
首先,将模型部署为 Arduino 库:
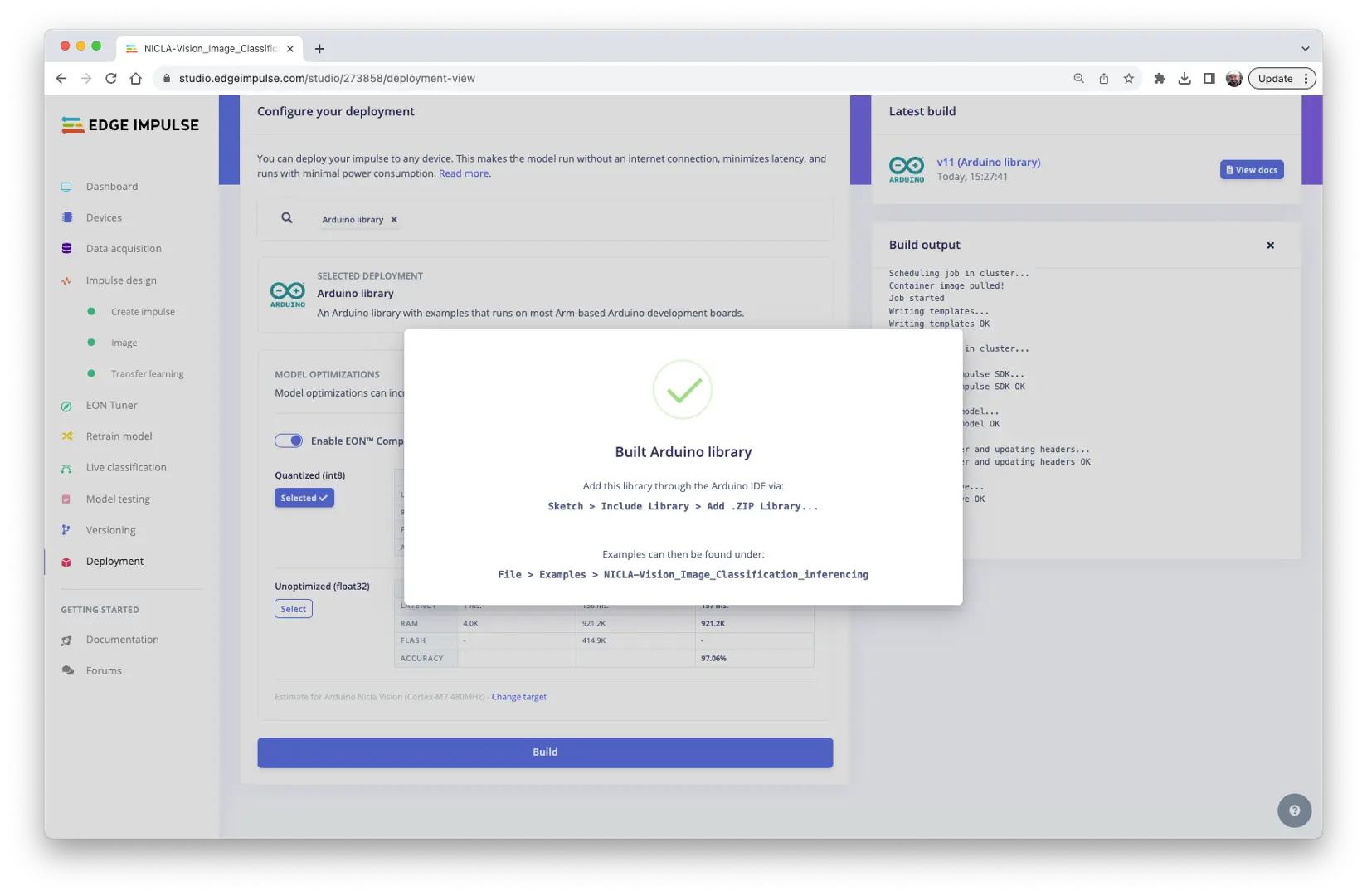
在 Arduino IDE 中安装 .zip 库,并运行库自带的 nicla_vision_camera.ino 示例。
注意:Arduino Nicla Vision 默认为 M7 核心分配 512KB RAM,M4 地址空间另有 244KB。本项目将分配调整为 288KB,以确保模型可正常运行(
malloc_addblock((void*)0x30000000, 288 * 1024);)。
实际测得延迟约 86ms。

可观看推理演示视频:https://youtu.be/bZPZZJblU-o
OpenMV 部署
模型也可部署为 OpenMV 专用库或固件(FW)。选择固件方式,Edge Impulse Studio 会生成优化后的模型、库和推理框架。下面以固件部署为例:
在 Deploy Tab 选择 OpenMV Firmware,点击 [Build]。
下载后解压 ZIP 文件:
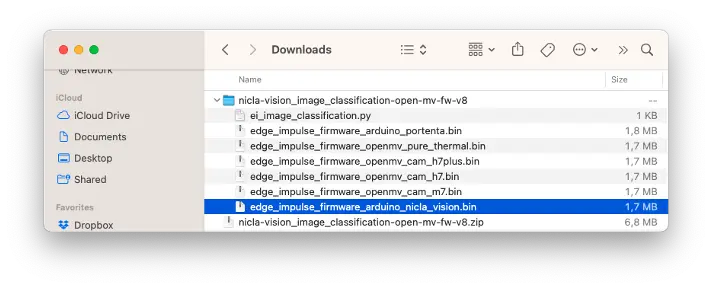
用 OpenMV IDE 的 Bootloader 工具将固件烧录到开发板(1):
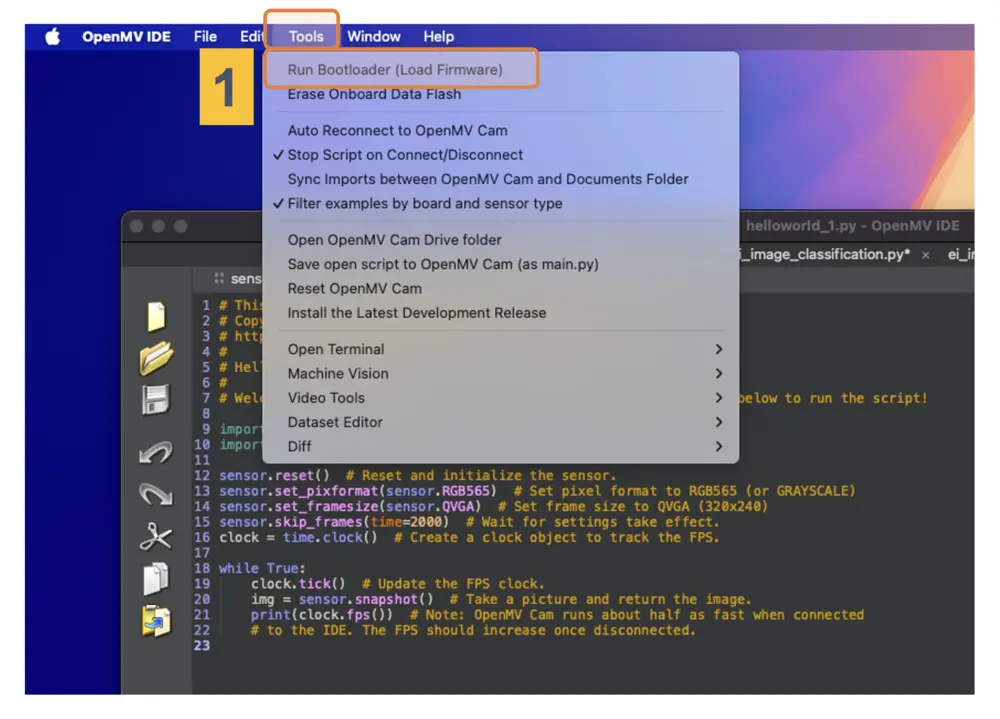
选择对应的 .bin 文件(Nicla-Vision 专用):
烧录完成后点击 OK:
如提示固件过期,请勿升级,选择 [NO]。

打开 Studio 下载的 ei_image_classification.py 脚本和 .bin 文件。
运行脚本,将摄像头对准待分类物体,推理结果会显示在串口终端。
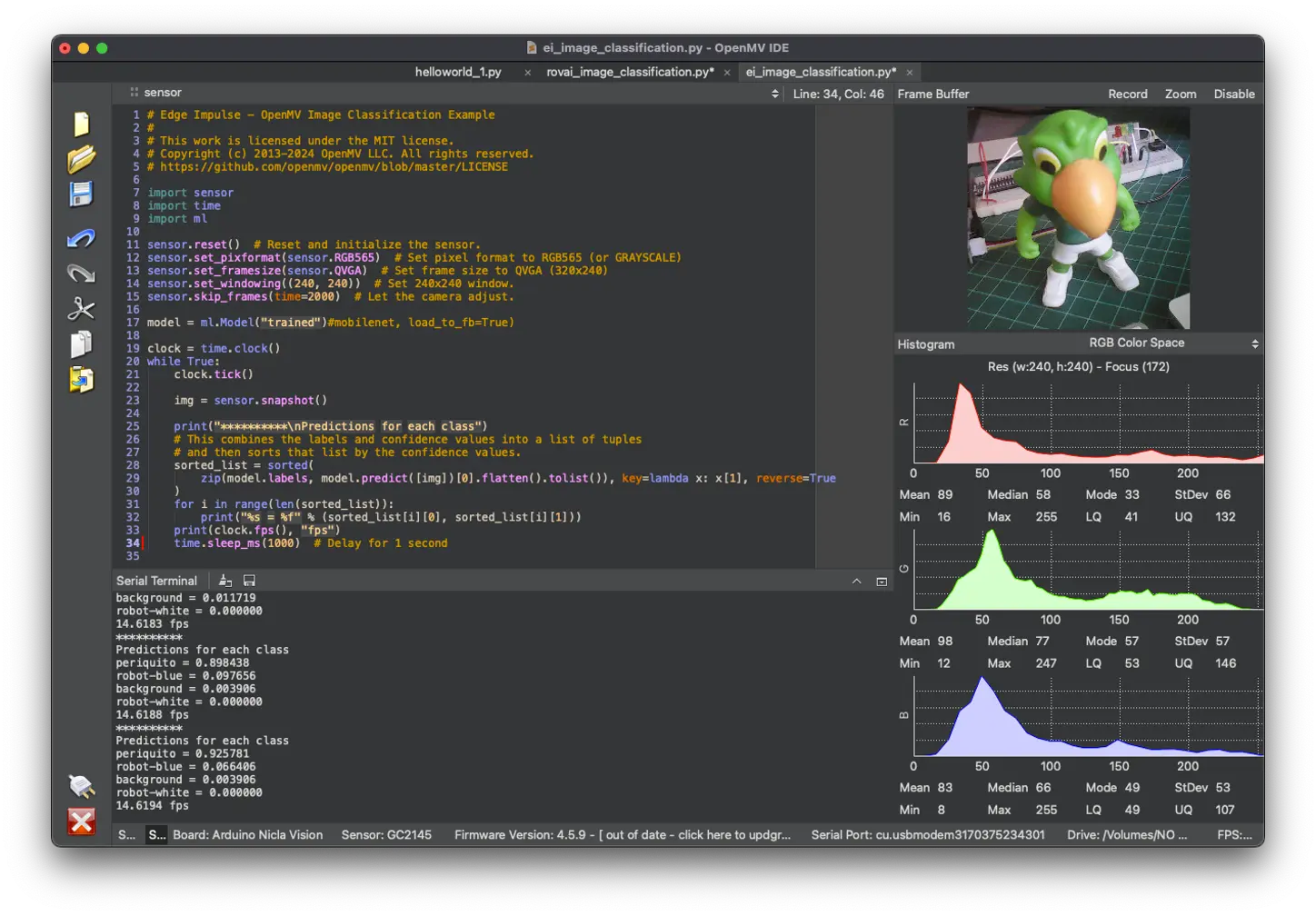
如结果难以阅读,可在代码中加入延时:
import time
while True:
...
time.sleep_ms(200) # 延时 0.2 秒
增加标签显示
可修改 Edge Impulse 提供的代码,使推理结果直接显示在 OpenMV IDE 的图像窗口。可 从 GitHub 下载代码 ,或按如下方式修改:
# Marcelo Rovai - NICLA Vision - 图像分类
# 基于 Edge Impulse - OpenMV 图像分类示例
# @24March25
import sensor
import time
import ml
sensor.reset() # 传感器初始化
sensor.set_pixformat(sensor.RGB565) # 设置像素格式
sensor.set_framesize(sensor.QVGA) # 设置帧尺寸
sensor.set_windowing((240, 240)) # 设置窗口
sensor.skip_frames(time=2000) # 等待相机调整
model = ml.Model("trained") # 加载模型
clock = time.clock()
while True:
clock.tick()
img = sensor.snapshot()
fps = clock.fps()
lat = clock.avg()
print("**********\nPrediction:")
# 按置信度排序
sorted_list = sorted(
zip(model.labels, model.predict([img])[0].flatten().tolist()),
key=lambda x: x[1], reverse=True
)
# 只输出概率最高的类别
max_val = sorted_list[0][1]
max_lbl = sorted_list[0][0]
if max_val < 0.5:
max_lbl = 'uncertain'
print("{} with a prob of {:.2f}".format(max_lbl, max_val))
print("FPS: {:.2f} fps ==> latency: {:.0f} ms".format(fps, lat))
# 在图像窗口绘制标签
img.draw_string(
10, 10,
max_lbl + "\n{:.2f}".format(max_val),
mono_space = False,
scale=3
)
time.sleep_ms(500) # 延时 0.5 秒
运行效果如下:
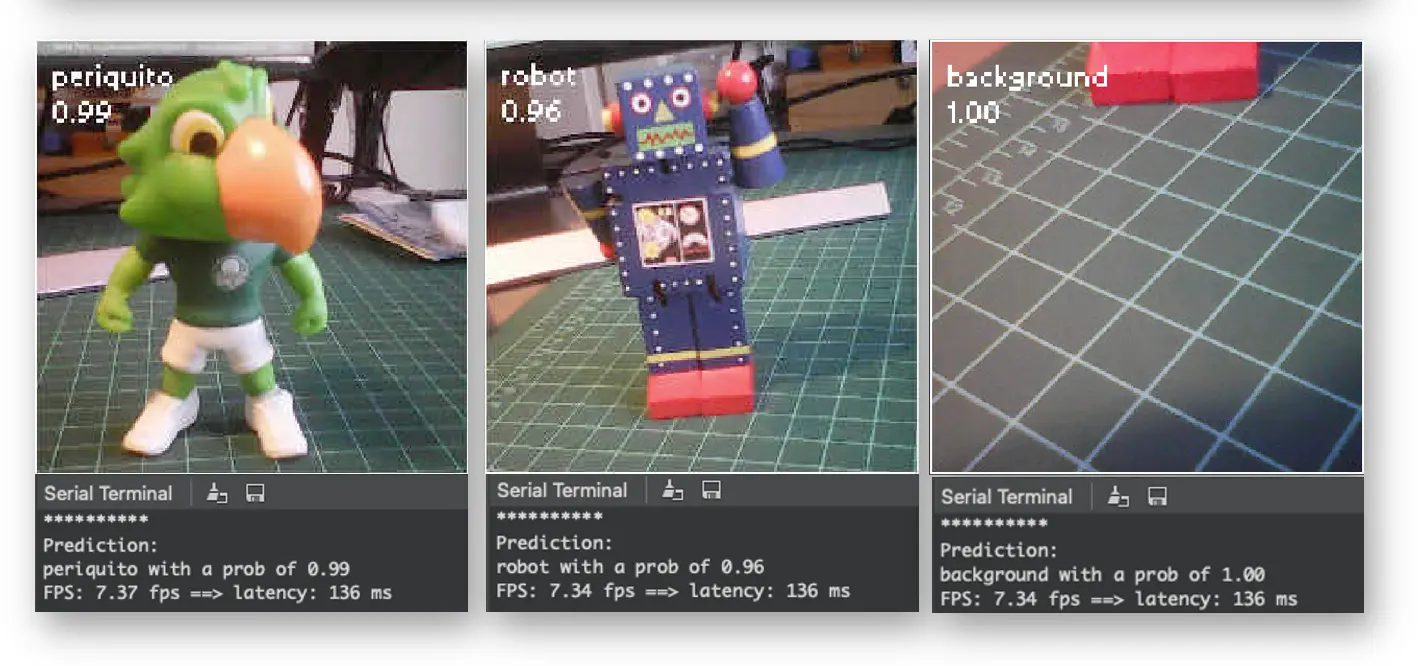
注意:此时延迟(136ms)约为 Arduino IDE 的两倍,因为 IDE 作为接口增加了额外耗时。如果仅在推理前启动计时,延迟可降至约 70ms。
NiclaV 连接 IDE 时运行速度约为断开时的一半,断开后帧率会提升。
LED 后处理
嵌入式机器学习的目标是让设备持续推理并直接对物理世界做出响应,而非仅在电脑上显示结果。为模拟此场景,我们将为每个推理结果点亮不同的 LED。
可 从 GitHub 下载代码 ,或在前述代码基础上增加 LED 控制:
# Marcelo Rovai - NICLA Vision - 图像分类与 LED 指示
# 基于 Edge Impulse - OpenMV 图像分类示例
# @24Aug23
import sensor, time, ml
from machine import LED
ledRed = LED("LED_RED")
ledGre = LED("LED_GREEN")
ledBlu = LED("LED_BLUE")
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((240, 240))
sensor.skip_frames(time=2000)
model = ml.Model("trained")
ledRed.off()
ledGre.off()
ledBlu.off()
clock = time.clock()
def setLEDs(max_lbl):
if max_lbl == 'uncertain':
ledRed.on()
ledGre.off()
ledBlu.off()
if max_lbl == 'periquito':
ledRed.off()
ledGre.on()
ledBlu.off()
if max_lbl == 'robot':
ledRed.off()
ledGre.off()
ledBlu.on()
if max_lbl == 'background':
ledRed.off()
ledGre.off()
ledBlu.off()
while True:
img = sensor.snapshot()
clock.tick()
fps = clock.fps()
lat = clock.avg()
print("**********\nPrediction:")
sorted_list = sorted(
zip(model.labels, model.predict([img])[0].flatten().tolist()),
key=lambda x: x[1], reverse=True
)
max_val = sorted_list[0][1]
max_lbl = sorted_list[0][0]
if max_val < 0.5:
max_lbl = 'uncertain'
print("{} with a prob of {:.2f}".format(max_lbl, max_val))
print("FPS: {:.2f} fps ==> latency: {:.0f} ms".format(fps, lat))
img.draw_string(
10, 10,
max_lbl + "\n{:.2f}".format(max_val),
mono_space = False,
scale=3
)
setLEDs(max_lbl)
time.sleep_ms(200) # 延时 0.2 秒
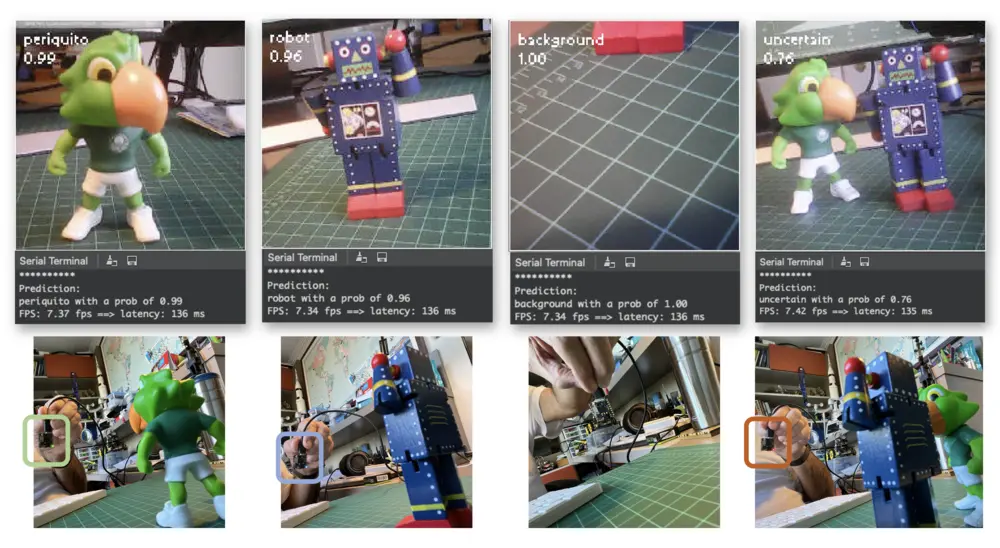
现在,每当某一类别得分超过 0.8 时,对应 LED 会被点亮:
- 红灯亮:不确定(无类别得分超过 0.8)
- 绿灯亮:Periquito > 0.8
- 蓝灯亮:Robot > 0.8
- 全灭:Background > 0.8
实际效果如下:
细节展示:

图像分类(非官方)基准测试
常见的嵌入式机器学习(TinyML)开发板包括 ESP32 CAM、Seeed XIAO ESP32S3 Sense、Arduino Nicla Vision 和 Arduino Portenta,均适用于低功耗计算机视觉应用。
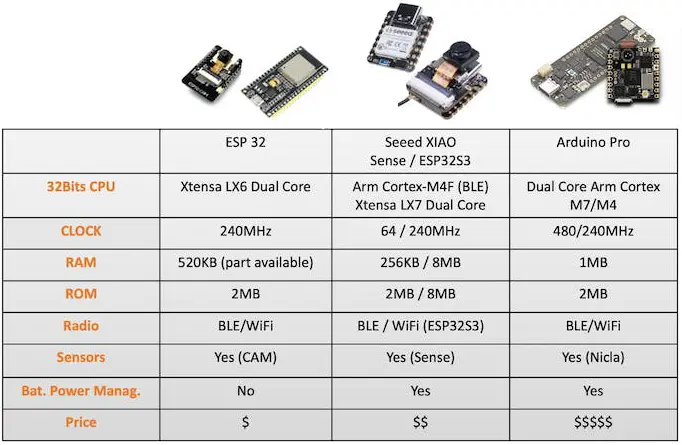
本项目训练的模型也在 ESP-CAM、XIAO 和 Portenta 上部署(Portenta 需用灰度图像重新训练以兼容其摄像头)。下图为各板卡以 Arduino 库方式部署后的效果:

总结
最后需要强调,计算机视觉远不止图像分类。你还可以围绕视觉开发多种边缘机器学习项目,例如:
- 自动驾驶:融合传感器、激光雷达与视觉算法,实现导航与决策
- 医疗健康:通过 MRI、X 光、CT 图像自动诊断疾病
- 零售:自动结算系统,识别商品并完成结账
- 安防监控:人脸识别、异常检测、实时目标跟踪
- 增强现实:目标检测与分类,实现虚实结合的信息叠加
- 工业自动化:产品外观检测、预测性维护、机器人/无人机导航
- 农业:无人机作物监测、自动采摘
- 自然语言处理:图像描述、视觉问答
- 手势识别:游戏、手语翻译、人机交互
- 内容推荐:电商中的基于图片的推荐系统