关键词检测(KWS)
概述
在前面的 图像分类 和 目标检测 应用中,我们已经体验了 Nicla Vision 板卡的强大能力。现在,我们将目光转向语音激活应用,实践一个关键词检测(KWS)项目。
正如 音频分类特征工程 实践教程中介绍的,关键词检测(KWS)已集成到许多语音识别系统中,使设备能够响应特定词语或短语。这项技术不仅支撑了 Google Assistant、Amazon Alexa 等流行设备,也完全可以在小型、低功耗设备上实现。本教程将带你在配备数字麦克风的 Nicla Vision 开发板上,利用 TinyML 实现 KWS 系统。
我们的模型将识别可唤醒设备或触发特定动作的关键词,实现真正的语音激活控制。
语音助手是如何工作的?
如前所述,市面上的语音助手(如 Google Home、Amazon Echo-Dot)只有在被特定关键词唤醒时才会响应用户,比如前者的“Hey Google”和后者的“Alexa”。
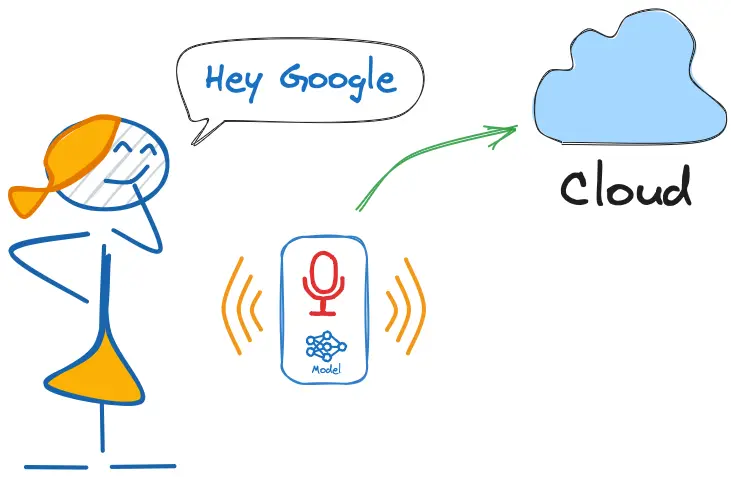
换句话说,语音命令的识别基于多级模型或级联检测(Cascade Detection)。
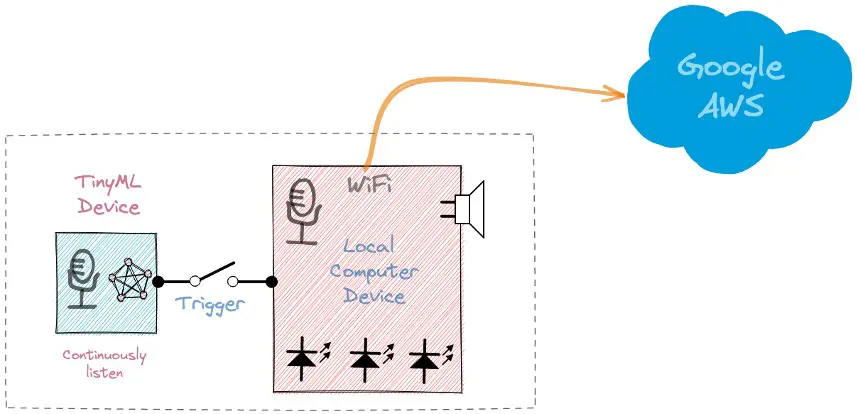
第一阶段:Echo Dot 或 Google Home 内部的小型微处理器持续监听,等待关键词出现,使用 TinyML 模型在本地进行检测(KWS 应用)。
第二阶段:只有当第一阶段的 KWS 应用检测到关键词后,数据才会被发送到云端,由更大的模型进一步处理。
下方视频展示了在树莓派(第二阶段)上编程 Google Assistant,并用 Arduino Nano 33 BLE 作为 TinyML 设备(第一阶段)的例子。
想深入了解上述 Google Assistant 项目,请参考教程: 从零构建智能语音助手 。
本 KWS 项目聚焦于第一阶段(KWS 或关键词检测),我们将使用带数字麦克风的 Nicla Vision 进行关键词检测。
KWS 实践项目
下图展示了最终 KWS 应用在推理阶段的工作流程:
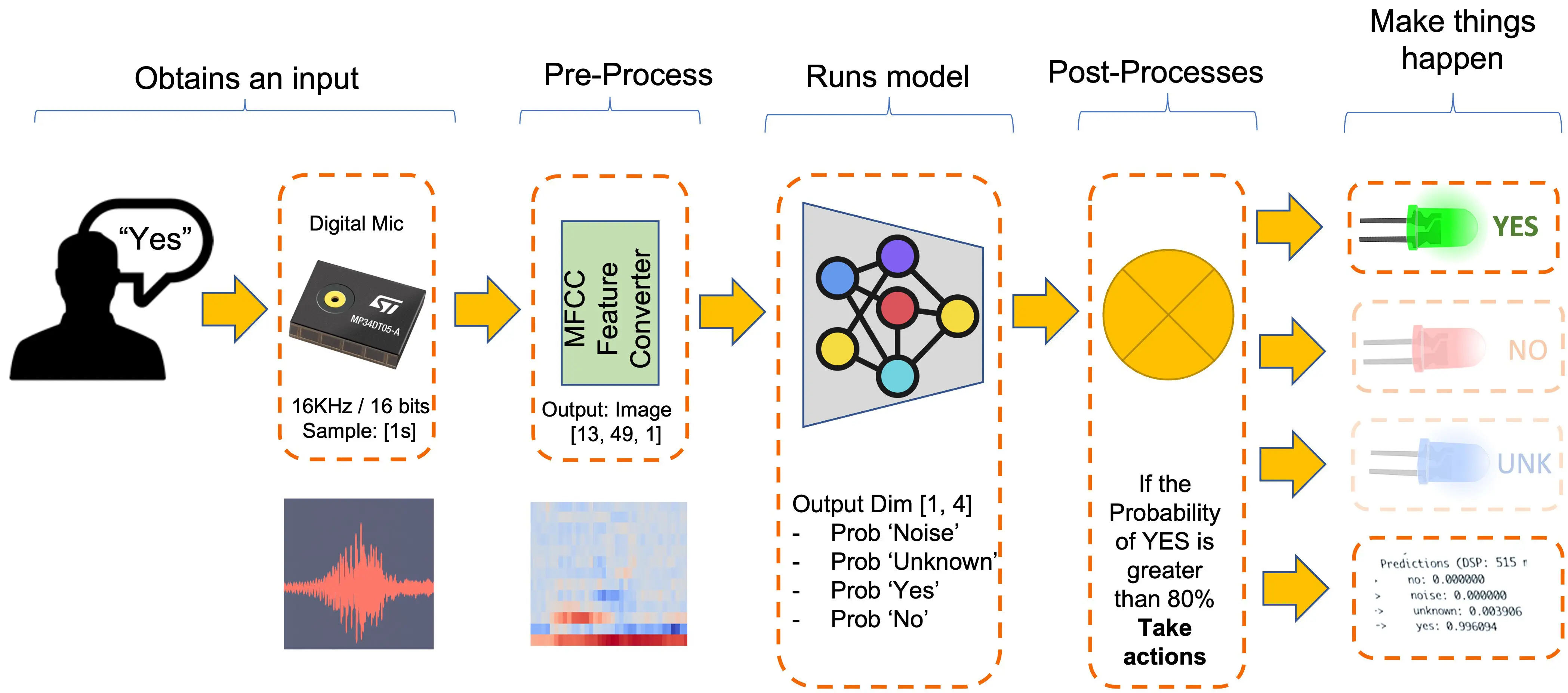
我们的 KWS 应用将识别四类声音:
- YES(关键词 1)
- NO(关键词 2)
- NOISE(仅有背景噪声,无语音)
- UNKNOWN(除 YES 和 NO 外的其他词)
在实际项目中,建议除了关键词外,还包含“噪声”(或背景)和“未知”类别。
机器学习工作流
KWS 应用的核心是其模型。因此,我们需要用特定关键词、噪声和其他词(“未知”)来训练模型:
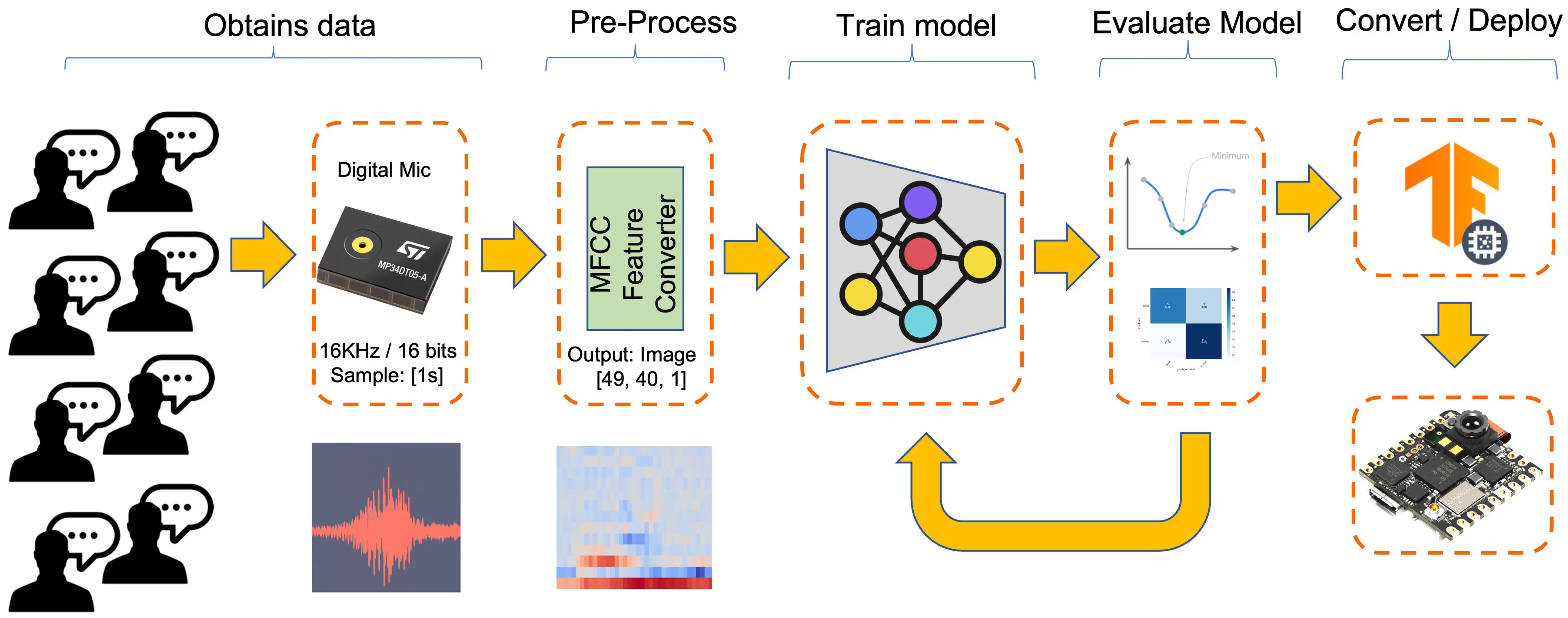
数据集
任何机器学习流程的关键在于数据集。确定关键词后(本例为 YES 和 NO),我们可以利用 Pete Warden 开发的数据集 “Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition” 。该数据集包含 35 个关键词(每类 1000+ 样本),如 yes、no、stop、go 等。以 yes 和 no 为例,每类可获得约 1500 个样本。
你可以从 Edge Studio 下载该数据集的精简版( 关键词检测预置数据集 ),其中包含本项目所需的四类样本:yes、no、noise、background。操作步骤如下:
- 下载 关键词数据集
- 解压到本地任意位置
上传数据集到 Edge Impulse Studio
在 Edge Impulse Studio(EIS)新建项目,在 Data Acquisition 区域选择 Upload Existing Data 工具,选择要上传的文件:
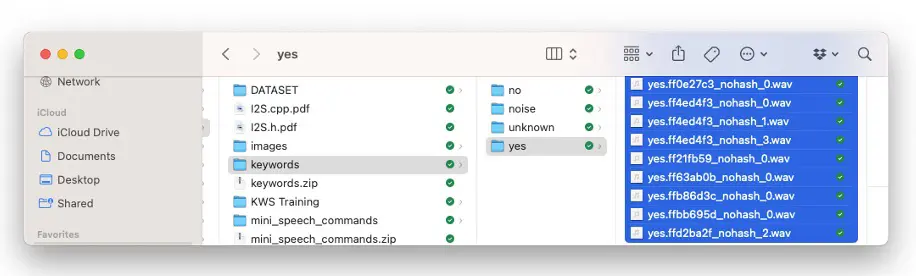
定义标签,选择 Automatically split between train and test,点击 Upload data 上传到 EIS。对所有类别重复此操作。
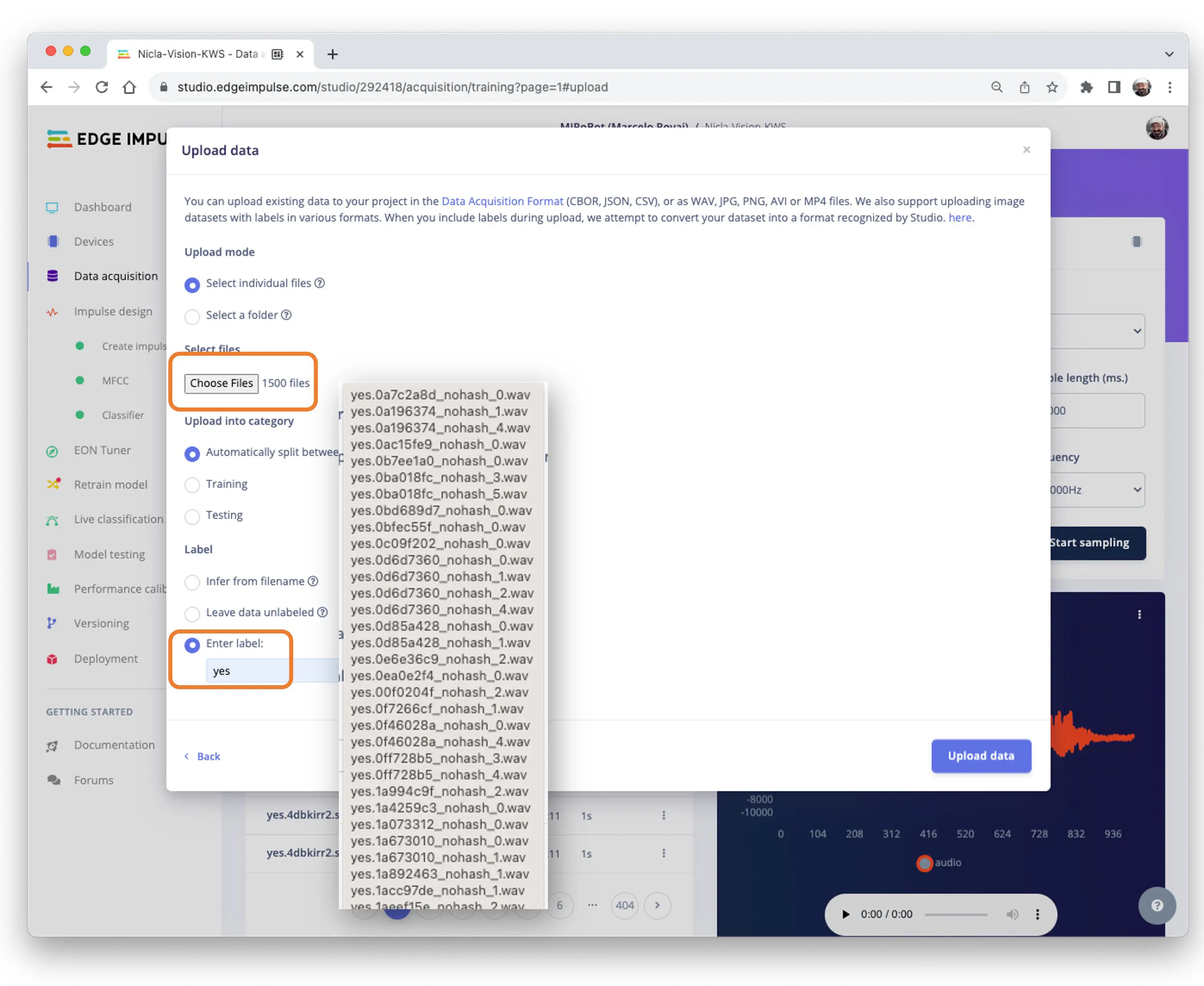
上传后,数据集会出现在 Data acquisition 区域。约 6000 个样本(每类 1500 个),自动分为训练集(4800)和测试集(1200)。
采集额外音频数据
尽管 Pete 的数据集已很丰富,建议还是采集一些自己的语音样本。对于加速度计等传感器,建议用同类型设备采集数据。对于声音,这不是必须,因为我们实际分类的是音频数据。
声音与音频的关键区别在于能量类型。声音是介质中的机械扰动(纵波),引起压力变化;音频则是代表声音的电信号(模拟或数字)。
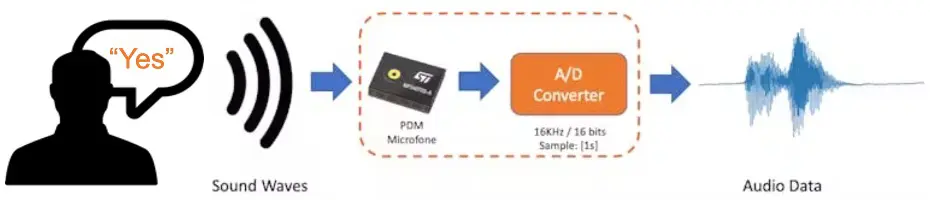
当我们发出关键词时,声波需被麦克风采样为音频数据,采样率为 16 KHz,采样位宽为 16 位。
只要设备能生成 16 KHz/16 位音频数据即可,包括 NiclaV、电脑或手机。
使用 NiclaV 和 Edge Impulse Studio
如 Nicla Vision 设置 章节所述,EIS 官方支持 Nicla Vision,便于采集其传感器(包括麦克风)数据。请新建 EIS 项目并连接 Nicla,步骤如下:
- 下载最新版 EIS 固件 并解压
- 在电脑上打开 zip 文件,选择对应操作系统的上传工具
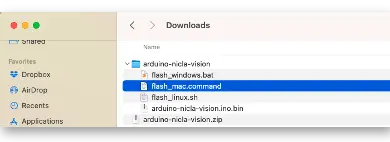
- 按两次复位键,将 NiclaV 置于 Boot 模式
- 运行对应批处理脚本,将 arduino-nicla-vision.bin 上传到开发板
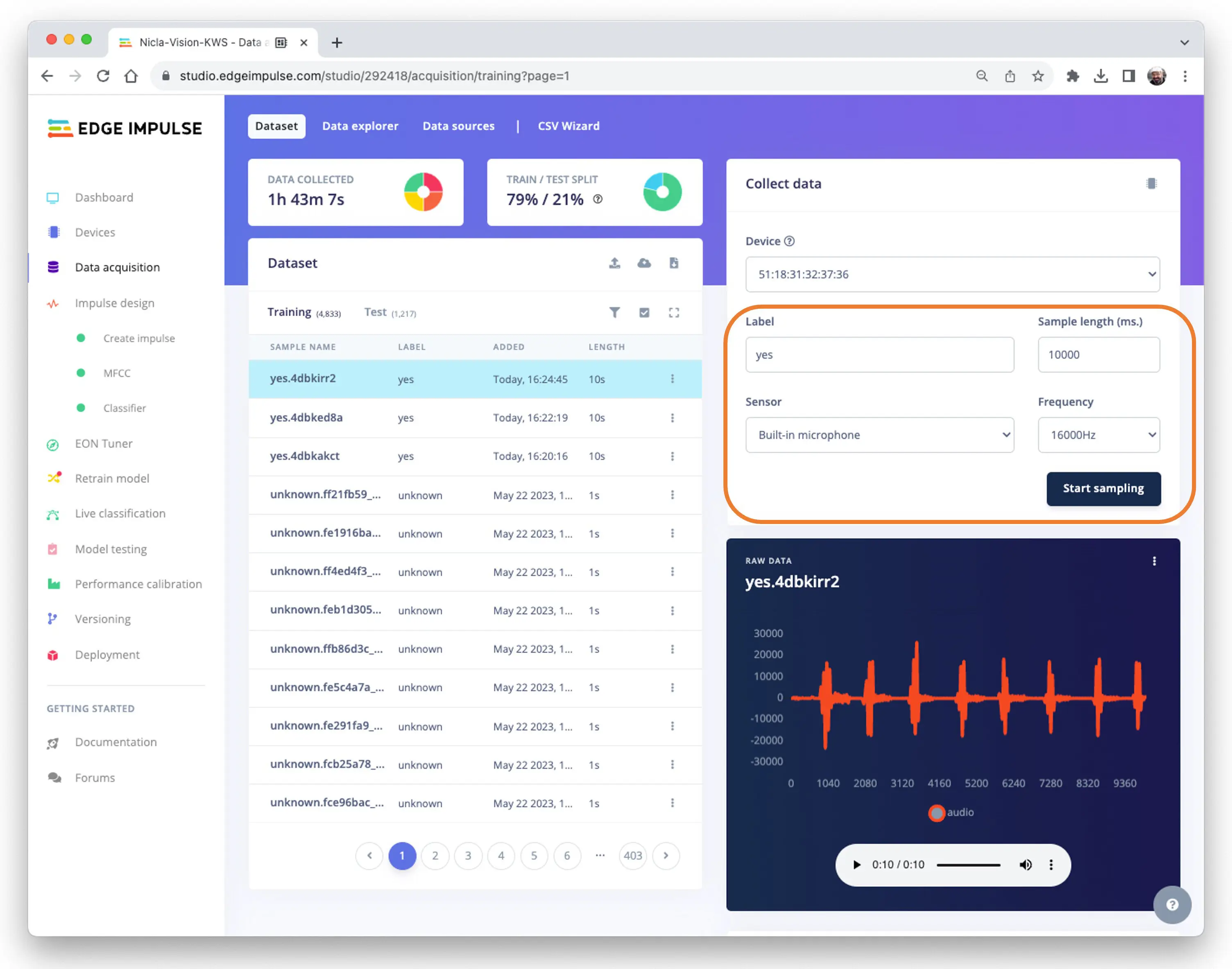
进入 EIS 项目,在 Data Acquisition 标签页选择 WebUSB,弹窗中选择 Nicla is paired 并点击 [Connect]。
在 Collect Data 区域选择 Built-in microphone,设置 label(如 yes)、采样频率 [16000Hz]、采样时长(如 [10s]),点击 Start sampling。
Pete 数据集样本长度为 1s,录制样本为 10s,需拆分为 1s 样本。点击样本名后的“三点”,选择 Split sample。
弹出分割工具窗口:
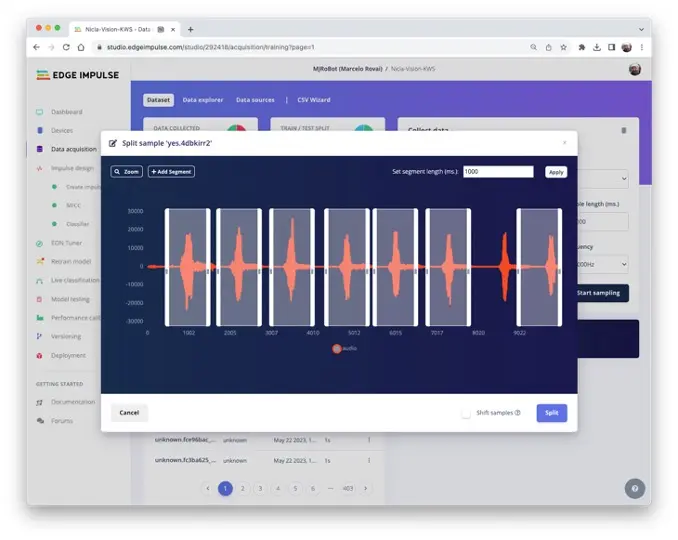
在工具中将数据分割为 1 秒(1000 ms)片段,如有需要可增删片段。对所有新样本重复此操作。
使用手机和 EI Studio
也可用电脑或手机采集音频,采样率 16 KHz,位宽 16 位。
在 Devices 页面扫码,手机浏览器打开数据采集应用,选择 Collecting Audio,设置 Label、采集时长和 Category。
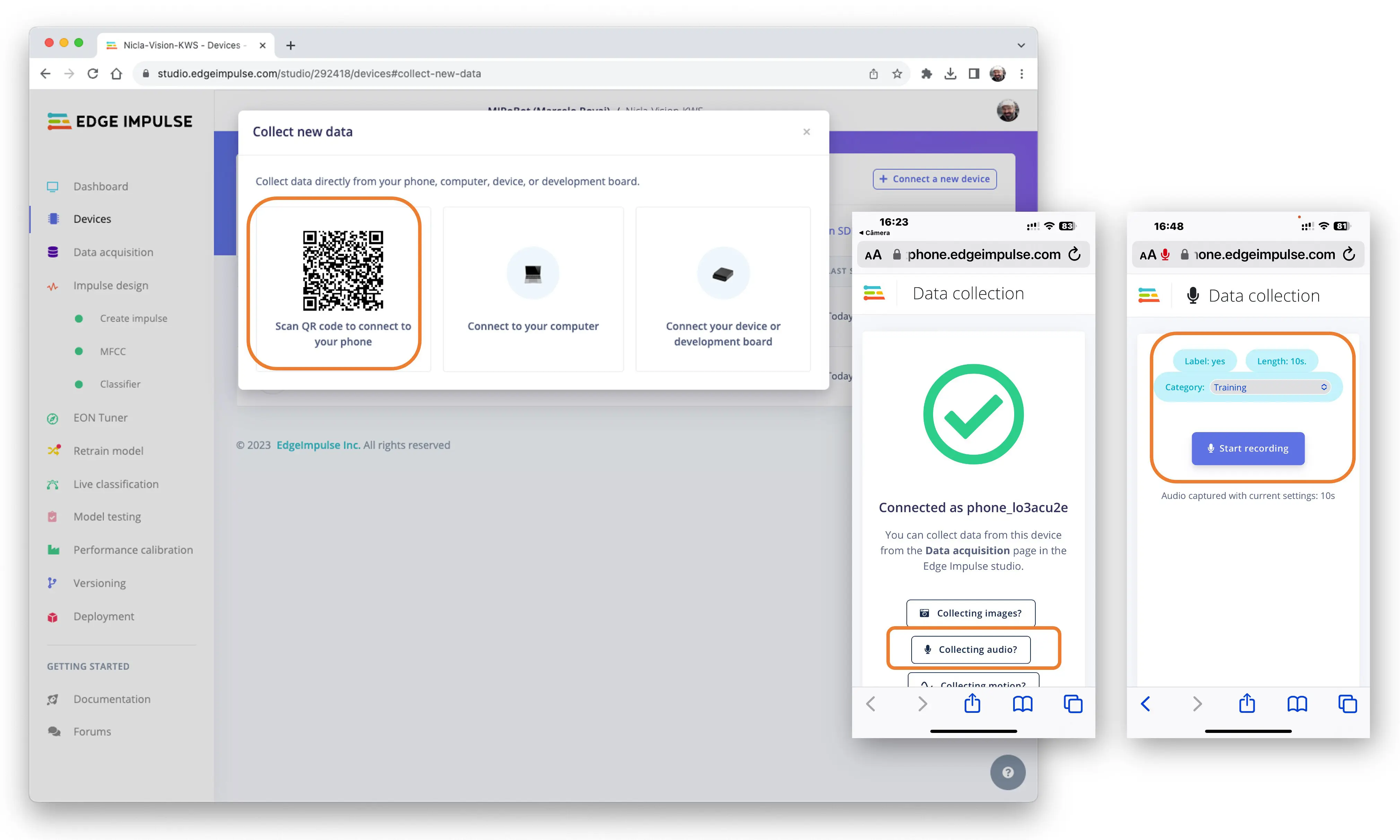
操作流程与 NiclaV 类似。
任何支持 16 KHz/16 位采样的录音软件(如 Audacity )均可用于音频采集。
创建 Impulse(预处理与模型定义)
Impulse 指将原始数据通过信号处理提取特征,再用学习模块对新数据进行分类的流程。
Impulse 设计
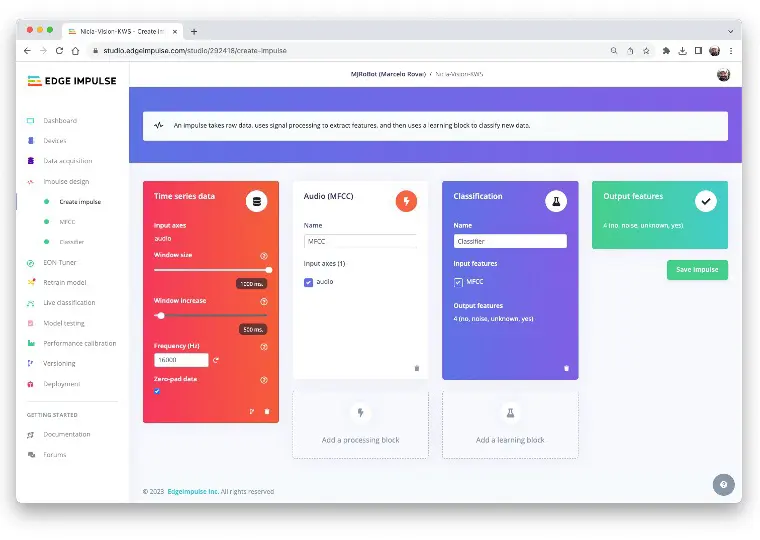
首先,以 1 秒窗口采集数据,进行数据增强,并以 500 ms 步长滑动窗口。注意启用 zero-pad 选项,确保不足 1 秒的样本用零填充,避免噪声和异常。
每个 1 秒音频样本需预处理并转换为图像(如 $13\times 49\times 1$)。如 音频分类特征工程 实践所述,我们采用 Audio (MFCC),即用
Mel 频率倒谱系数
提取音频特征,适合语音场景。
接着选择 Classification 模块,基于卷积神经网络(CNN)从零构建模型。
也可选用
Transfer Learning (Keyword Spotting)模块,微调预训练 KWS 模型,适合小型关键词数据集。
预处理(MFCC)
下一步是生成用于训练的特征:
可保留默认参数,也可用 DSP 的 Autotune parameters 自动调参。
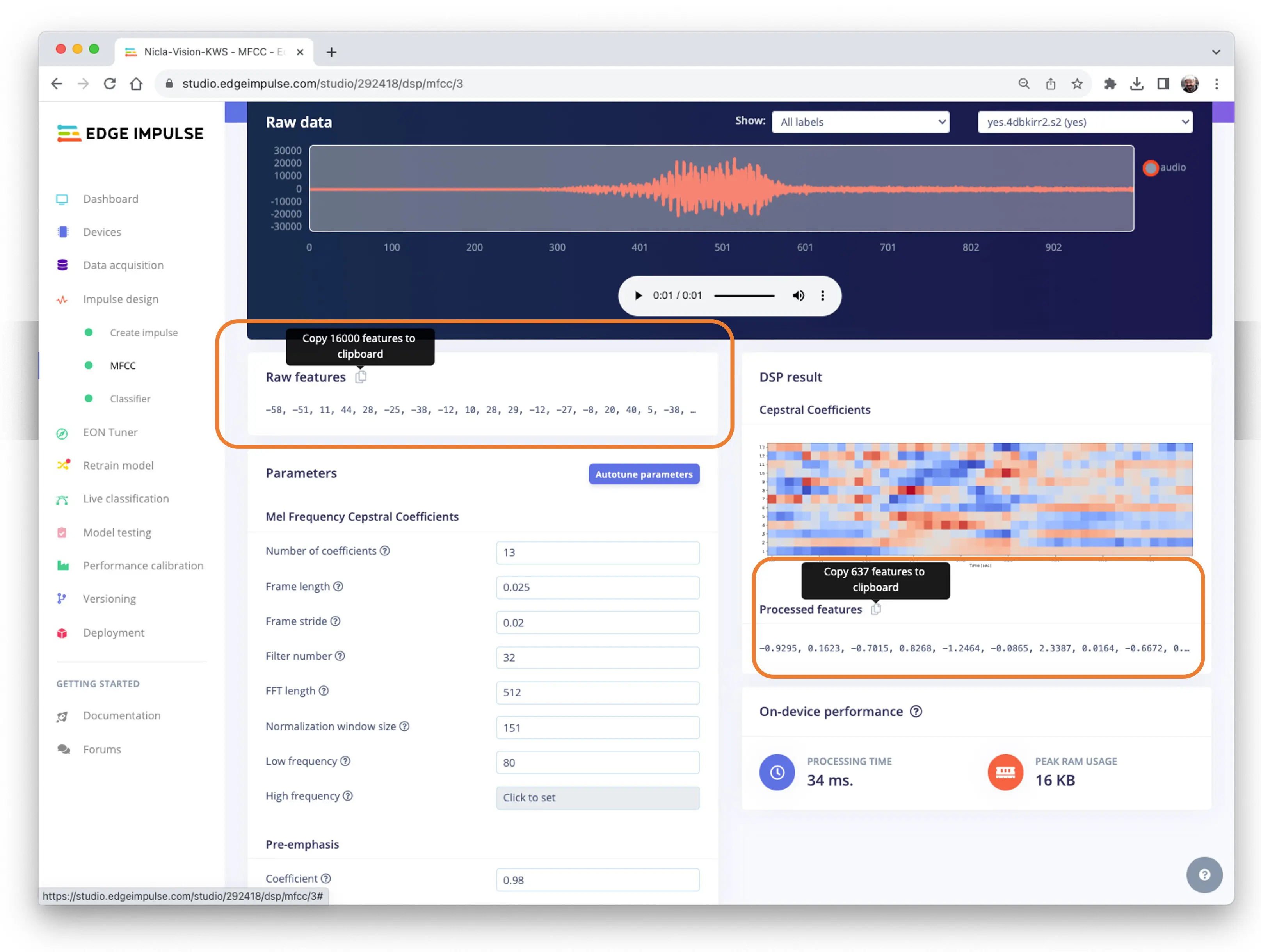
将 1 秒、16 KHz 采样的原始音频(16,000 点)用 MFCC 处理,得到 637 个特征($13\times 49$)。
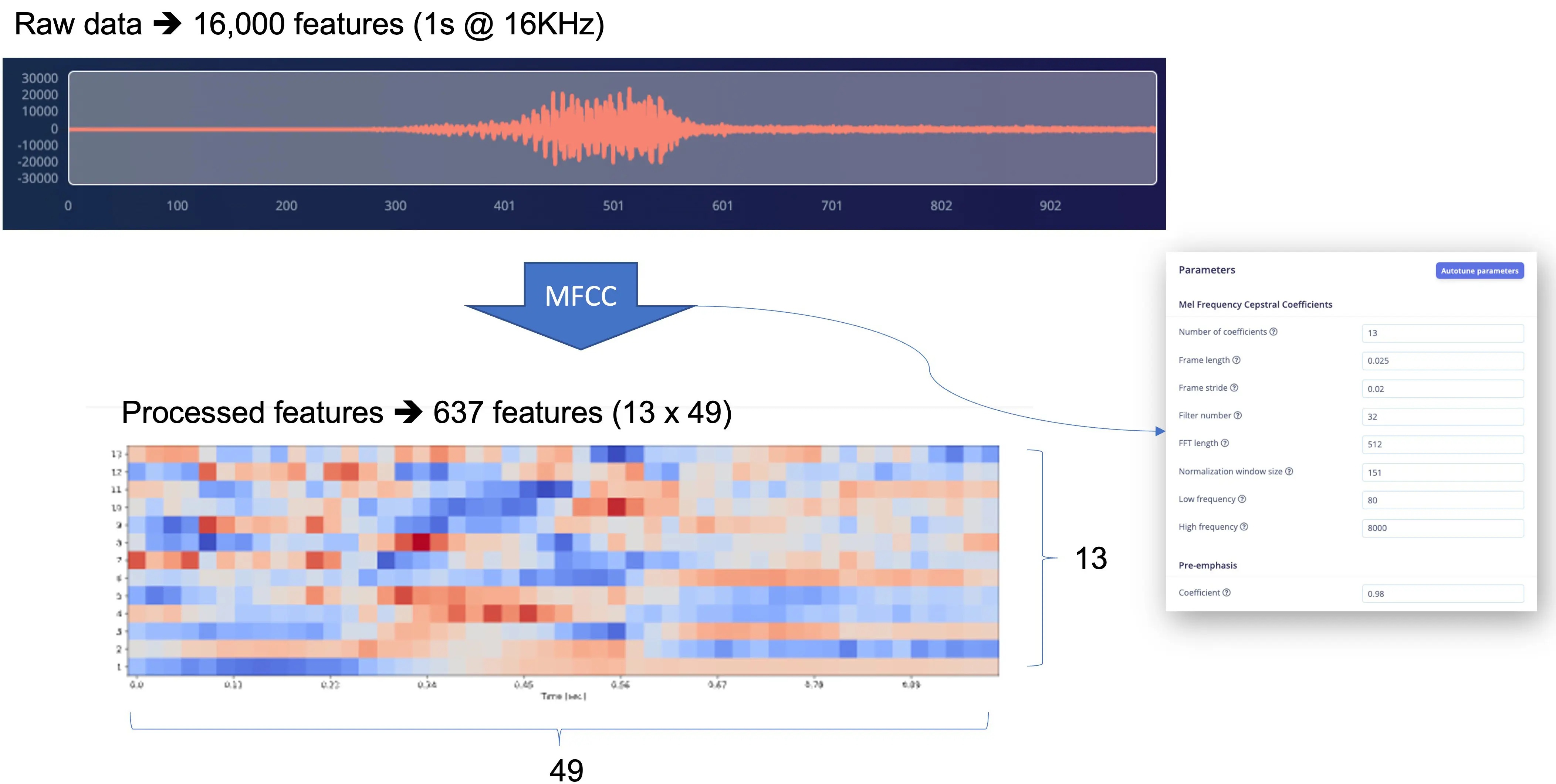
结果显示,预处理仅占用 16 KB 内存,延迟 34 ms,非常优秀。例如在 Arduino Nano(Cortex-M4f @ 64 MHz)上,预处理需约 480 ms。参数如 FFT length [512] 会显著影响延迟。
保存参数后,进入 Generated features 标签页,实际生成特征。用
UMAP
进行降维,Feature explorer 可视化特征分布。
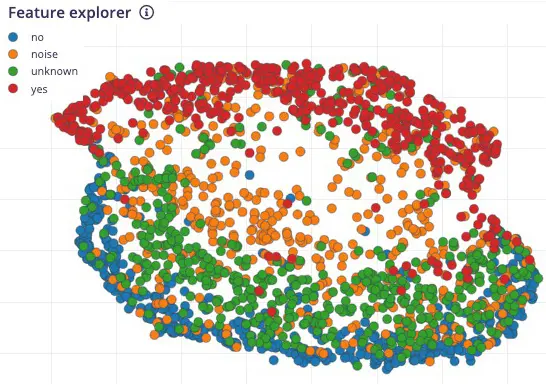
结果显示 yes(红色)与 no(蓝色)特征分布明显分离,unknown 更靠近 no,提示 no 更易出现误判。
深入理解
想深入了解原始声音的预处理,可参考 音频分类特征工程 章节。可下载本 notebook 或 在 Colab 打开 体验 MFCC 特征生成。
模型设计与训练
我们采用简单的卷积神经网络(CNN)模型,分别测试 1D 和 2D 卷积。基本结构为两组卷积 + 池化(分别为 8 和 16 个滤波器),1D dropout 为 0.25,2D 为 0.5。最后一层 Flatten 后有 4 个神经元,对应四个类别:
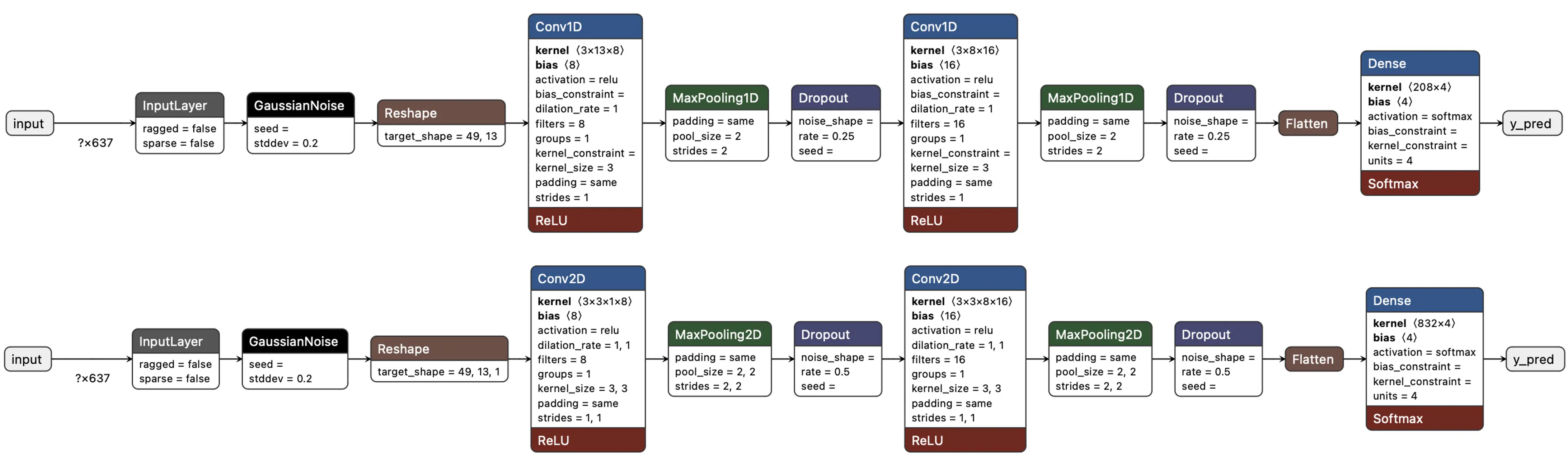
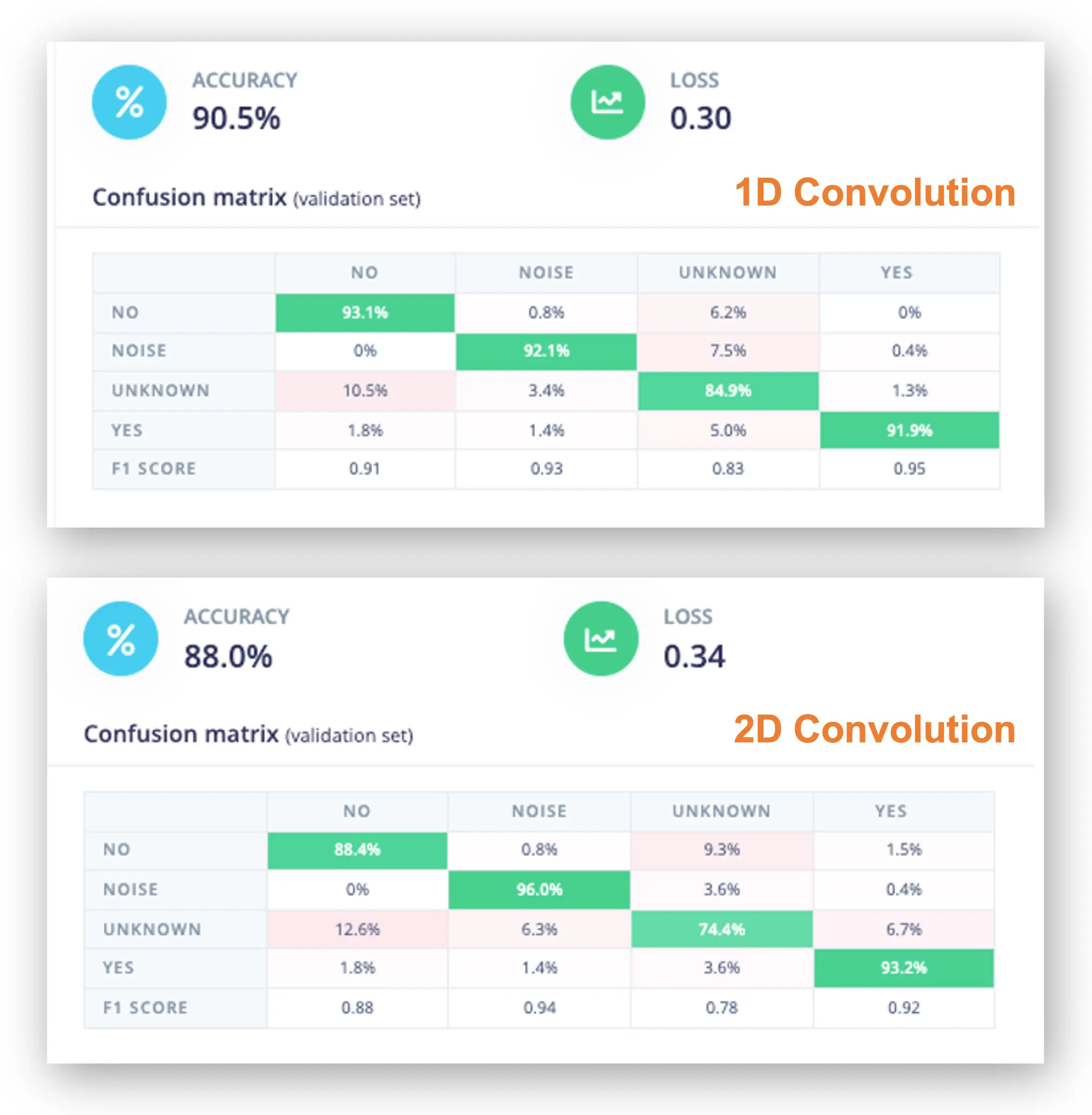
超参数设置:学习率 0.005,训练 100 轮,采用 SpecAugment 数据增强。1D 和 2D 架构同参对比,1D 准确率更高(90.5% vs 88%),因此采用 1D。
1D 卷积参数更少,更适合资源受限环境。
1D 混淆矩阵显示,YES 的 F1 分数为 95%,NO 为 91%。这与特征可视化结果一致(no 与 unknown 距离近)。如需提升效果,可分析错误样本。
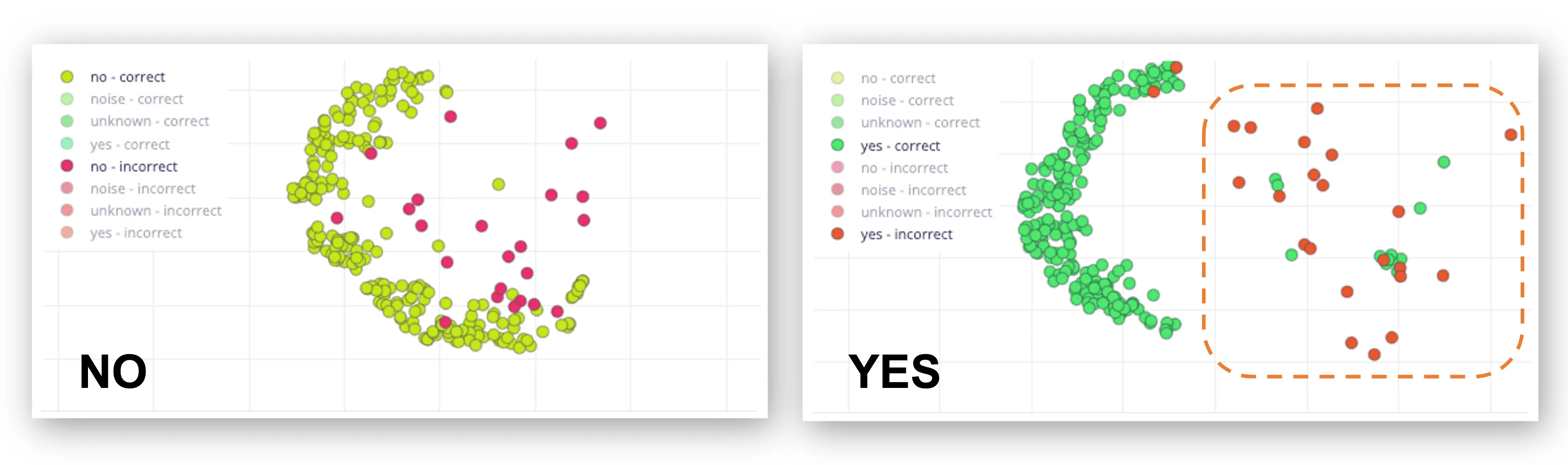
可试听错误样本,如 YES 多为发音类似“yeh”。可采集更多样本后重新训练。
深入理解
想了解底层细节,可在 Dashboard 标签页下载预处理数据集(MFCC training data),并用本
Jupyter Notebook
或
Colab 版本
分析训练过程,如逐轮准确率:
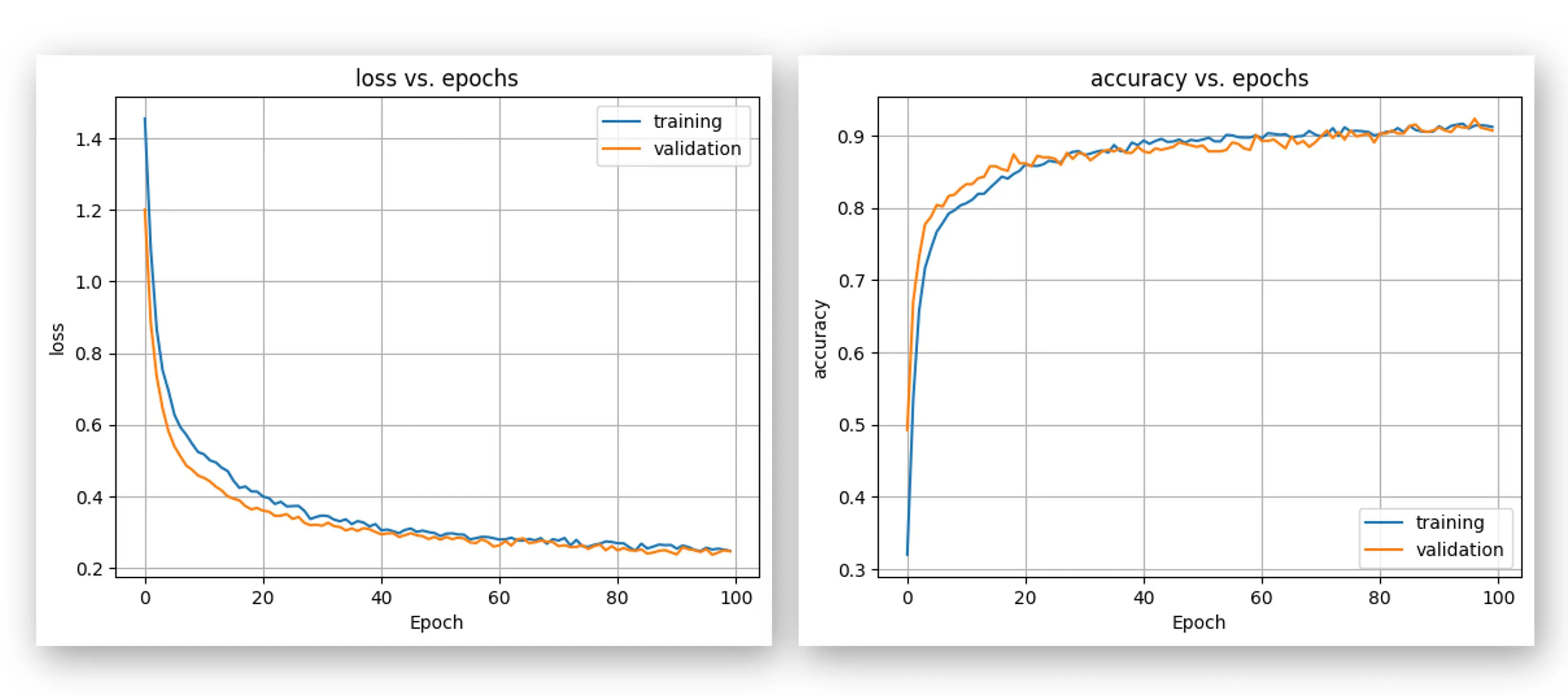
测试
用预留测试集测试模型,准确率约 76%。
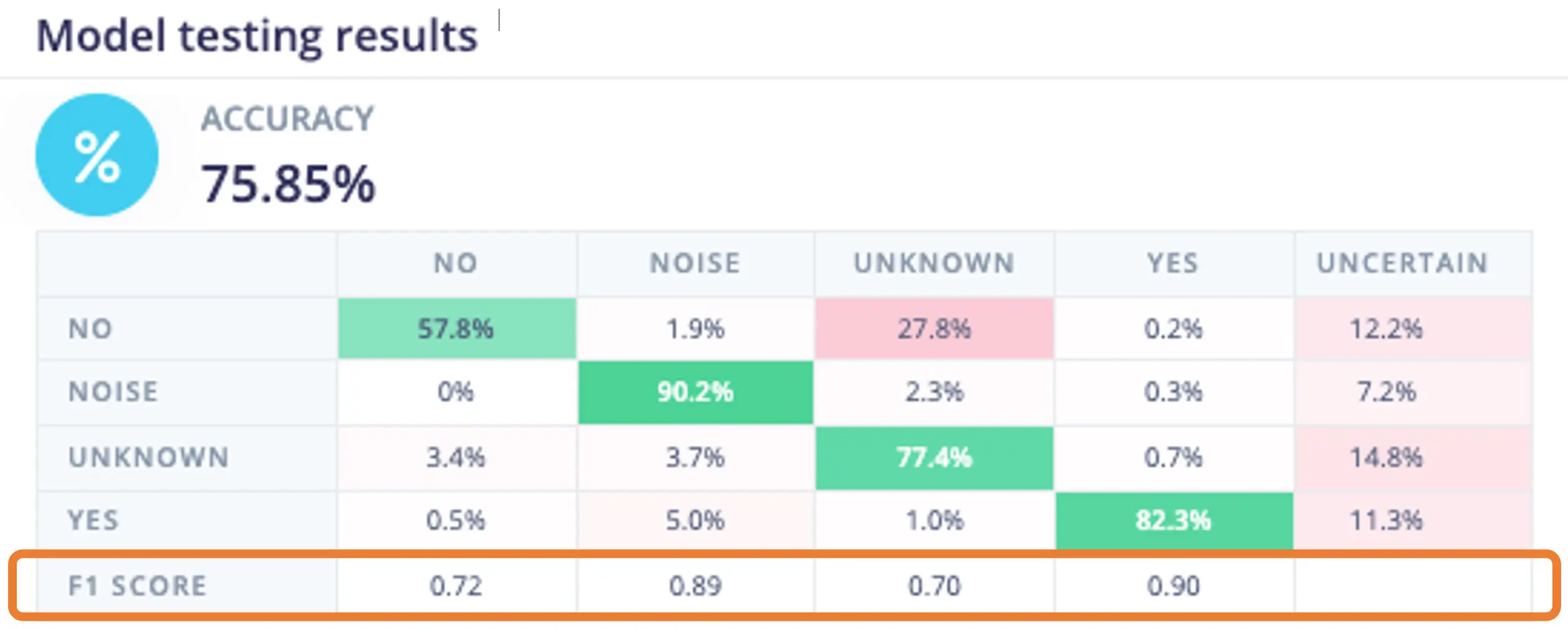
F1 分数显示 YES 达 0.90,非常理想,NO 为 0.72,UNKNOWN 为 0.70。可将误判样本加入训练集后再次训练以提升效果。
实时分类
可进入下一步,也可用 NiclaV 或手机采集实时样本,测试模型部署前的效果。
部署与推理
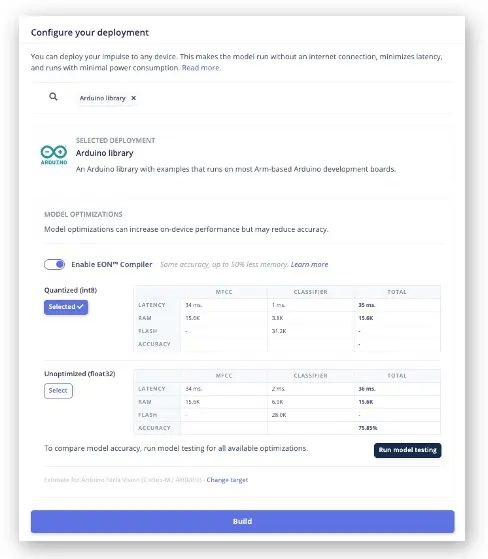
EIS 会打包所需库、预处理函数和训练模型,下载到本地。在 Deployment 区域选择 Arduino Library,底部选择 Quantized (Int8),点击 Build。
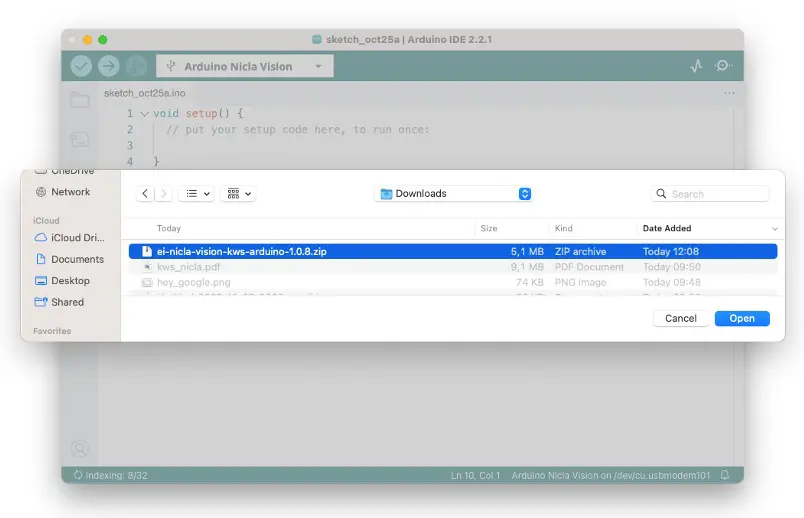
点击 Build 后会下载 zip 文件。在 Arduino IDE 的 Sketch 菜单选择 Add .ZIP Library,导入下载的 zip 文件:
现在可以完全脱离 EIS 进行推理测试。使用部署库自带的 NiclaV 示例代码。
在 Arduino IDE 的 File/Examples 菜单,找到项目,选择 nicla-vision/nicla-vision_microphone(或 nicla-vision_microphone_continuous)
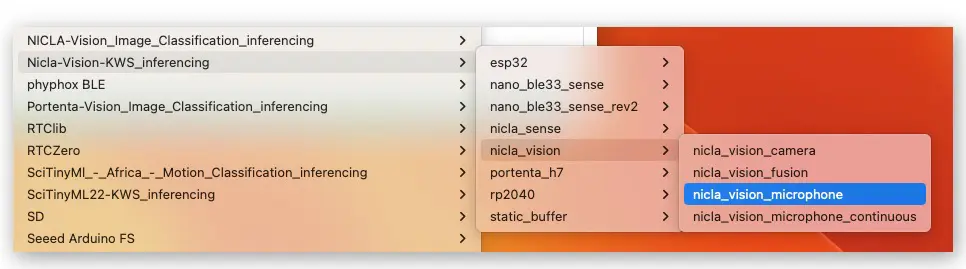
按两次复位键进入 boot 模式,上传代码,进行实际推理测试:

后处理
模型已能检测关键词,接下来修改代码,实现 NiclaV 脱机(电池、充电宝或独立 5V 供电)时的 LED 指示:
- 检测到 YES,点亮绿灯
- 检测到 NO,点亮红灯
- 检测到 UNKNOWN,点亮蓝灯
- 检测到噪声(无关键词),所有灯灭
以 nicla-vision_microphone_continuous 示例为例,初始化 LED:
// ...existing code...
void setup()
{
// ...existing code...
// Arduino NiclaV 板载 RGB LED 引脚
pinMode(LEDR, OUTPUT);
pinMode(LEDG, OUTPUT);
pinMode(LEDB, OUTPUT);
// 默认关闭所有 LED(低电平点亮,高电平熄灭)
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, HIGH);
// ...existing code...
}
添加 turn_off_leds() 函数关闭所有 LED:
/*
* @brief turn_off_leds - 关闭所有 RGB LED
*/
void turn_off_leds(){
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, HIGH);
}
添加 turn_on_leds() 按分类结果点亮对应 LED:
/*
* @brief turn_on_leds - 按分类结果点亮 RGB LED
* @param[in] pred_index
* no: [0] ==> 红灯亮
* noise: [1] ==> 全灭
* unknown: [2] ==> 蓝灯亮
* yes: [3] ==> 绿灯亮
*/
void turn_on_leds(int pred_index) {
switch (pred_index)
{
case 0:
turn_off_leds();
digitalWrite(LEDR, LOW);
break;
case 1:
turn_off_leds();
break;
case 2:
turn_off_leds();
digitalWrite(LEDB, LOW);
break;
case 3:
turn_off_leds();
digitalWrite(LEDG, LOW);
break;
}
}
在 loop() 的 // print the predictions 部分修改如下:
// ...existing code...
if (++print_results >= (EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW)) {
// 打印推理结果
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
int pred_index = 0;
float pred_value = 0;
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
if (result.classification[ix].value > pred_value){
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
ei_printf(" PREDICTION: ==> %s with probability %.2f\n",
result.classification[pred_index].label, pred_value);
turn_on_leds(pred_index);
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
print_results = 0;
}
// ...existing code...
完整代码见 项目 GitHub 。
上传代码,实际测试推理效果。检测到 YES 时绿灯亮,NO 时红灯亮,其他词蓝灯亮,噪声时全灭。类似方式也可用于触发外部设备执行动作。
总结
本教程相关 notebook 和代码可在 GitHub 获取。
最后补充,声音分类不仅限于语音,还可用于以下 TinyML 场景:
- 安防(破玻璃、枪声检测)
- 工业(异常检测)
- 医疗(鼾声、咳嗽、肺部疾病)
- 自然(蜂群监控、昆虫声音、反偷猎)
参考资源
- Google Speech Commands 数据集子集
- KWS MFCC 分析 Colab Notebook
- KWS_CNN_training Colab Notebook
- Arduino 后处理代码
- Edge Impulse 项目