目标检测
概述
本章承接 Nicla Vision 上的图像分类内容,进一步探索目标检测。

在深入目标检测之前,我们先对比一下图像分类与目标检测的区别。
目标检测与图像分类的区别
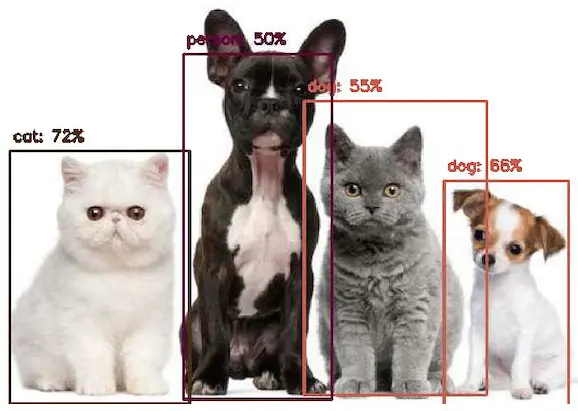
图像分类模型的主要任务是输出图片中最可能出现的物体类别列表。例如,识别刚吃完饭的虎斑猫:

但如果猫跳到酒杯旁边,模型依然只会识别出图片中占主导地位的虎斑猫:

如果图片中没有明显的主导类别呢?

模型会错误地将上图识别为“ashcan”(垃圾桶),可能是因为颜色的原因。
上述示例均使用 MobileNet 模型,训练数据集为 ImageNet。
要解决上述问题,我们需要另一类模型,不仅能识别多个类别,还要知道这些物体在图片中的位置。
这类模型通常更复杂、更大。例如,MobileNetV2 SSD FPN-Lite 320x320(COCO 数据集),可在一张图片中定位最多 10 个物体,并输出每个物体的边界框。下图为该模型在树莓派上的推理结果:
这些目标检测模型(如 MobileNet SSD 或 YOLO)通常体积较大(数 MB),适合树莓派等设备,但不适合 RAM 小于 1MB 的嵌入式设备。
FOMO:嵌入式目标检测创新方案
Edge Impulse 于 2022 年推出了 FOMO(Faster Objects, More Objects) ,为嵌入式设备带来了全新的目标检测方案。不仅支持 Nicla Vision(Cortex M7),还支持 Cortex M4F(Arduino Nano33、OpenMV M4 系列)和 ESP32(ESP-CAM、XIAO ESP32S3 Sense)等设备。
本实验将实践 FOMO 目标检测,不深入模型原理,想了解更多可参考 FOMO 官方公告 。
目标检测项目目标
所有机器学习项目都需明确目标。假设我们在工厂,需要对轮子和特殊盒子进行分拣和计数。

换句话说,我们要实现多标签分类,每张图片可能包含三类:
- 背景(无物体)
- 盒子
- 轮子
下图为部分未标注的样本图片,用于检测物体(轮子和盒子):

我们关注图片中有哪些物体、它们的位置(质心)以及数量。FOMO 不检测物体尺寸(不像 MobileNet SSD 或 YOLO 输出边界框),只输出质心坐标。
本项目将用 Nicla Vision 采集图片并推理,使用 Edge Impulse Studio 开发 ML 项目。在 Studio 开始目标检测项目前,先用包含目标物体的图片创建原始数据集(未标注)。
数据采集
采集图片可选:
- Web Serial Camera 工具
- Edge Impulse Studio
- OpenMV IDE
- 智能手机
本项目采用 OpenMV IDE。
使用 OpenMV IDE 采集数据集
首先在电脑新建数据保存文件夹(如“data”)。在 OpenMV IDE 依次点击 Tools > Dataset Editor,选择 New Dataset 开始采集:
Edge Impulse 建议物体大小相近且不重叠,便于模型学习。在工厂场景下,摄像头固定,距离一致,满足要求。我们也会尝试不同大小和位置,观察效果。
不需为每类图片单独建文件夹,因为每张图片可能有多个标签。
连接 Nicla Vision 到 OpenMV IDE,运行 dataset_capture_script.py,点击 Capture Image 按钮开始采集:
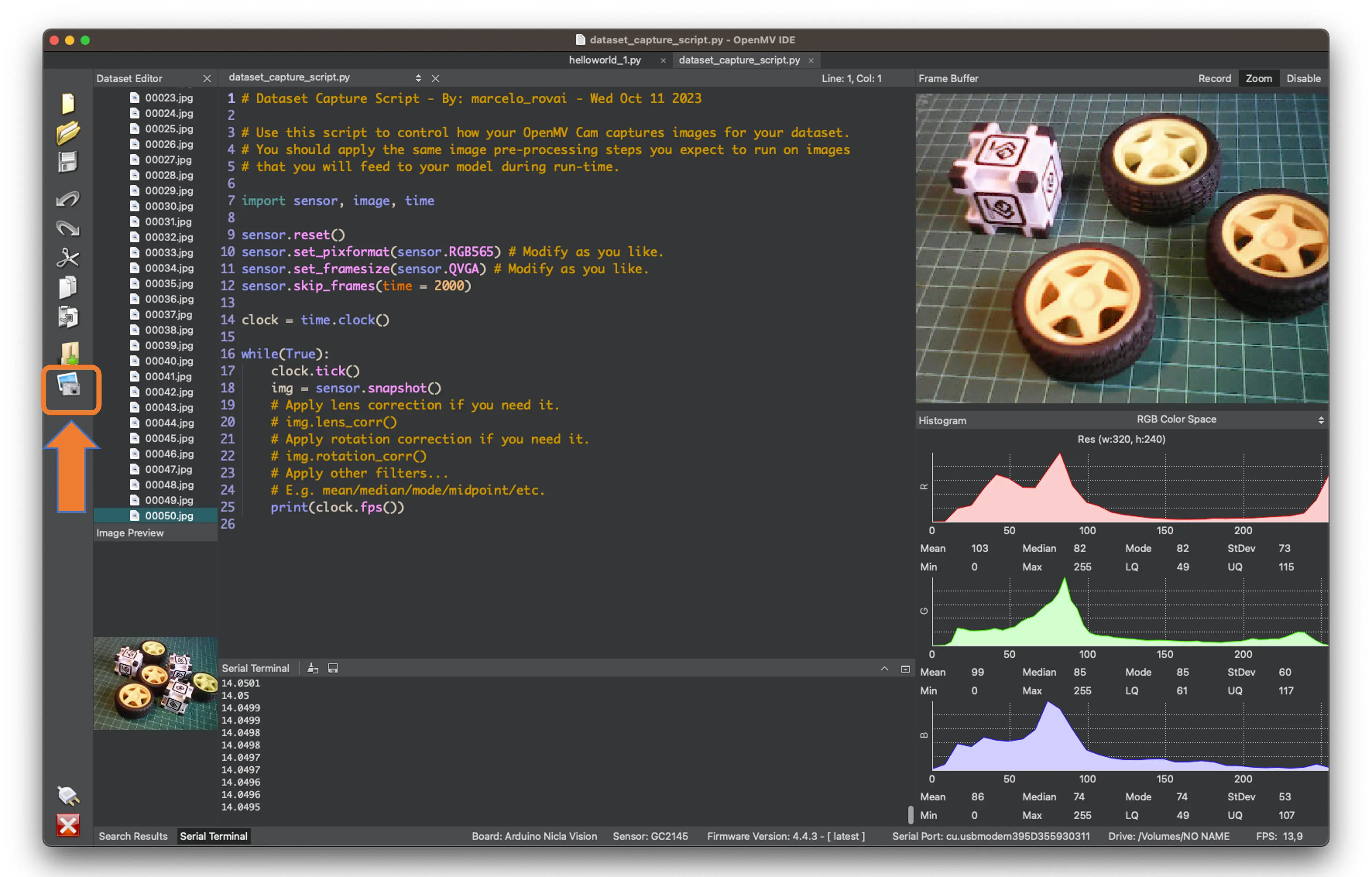
建议采集约 50 张图片,混合不同物体和数量,尽量涵盖不同角度、背景和光照。
图片为 QVGA 尺寸 $320\times 240$,RGB565 色彩格式。
采集完成后,关闭 Tools > Dataset Editor。
Edge Impulse Studio
项目设置
访问 Edge Impulse Studio ,登录或注册新账号,新建项目。
可克隆本实验项目: NICLA_Vision_Object_Detection 。
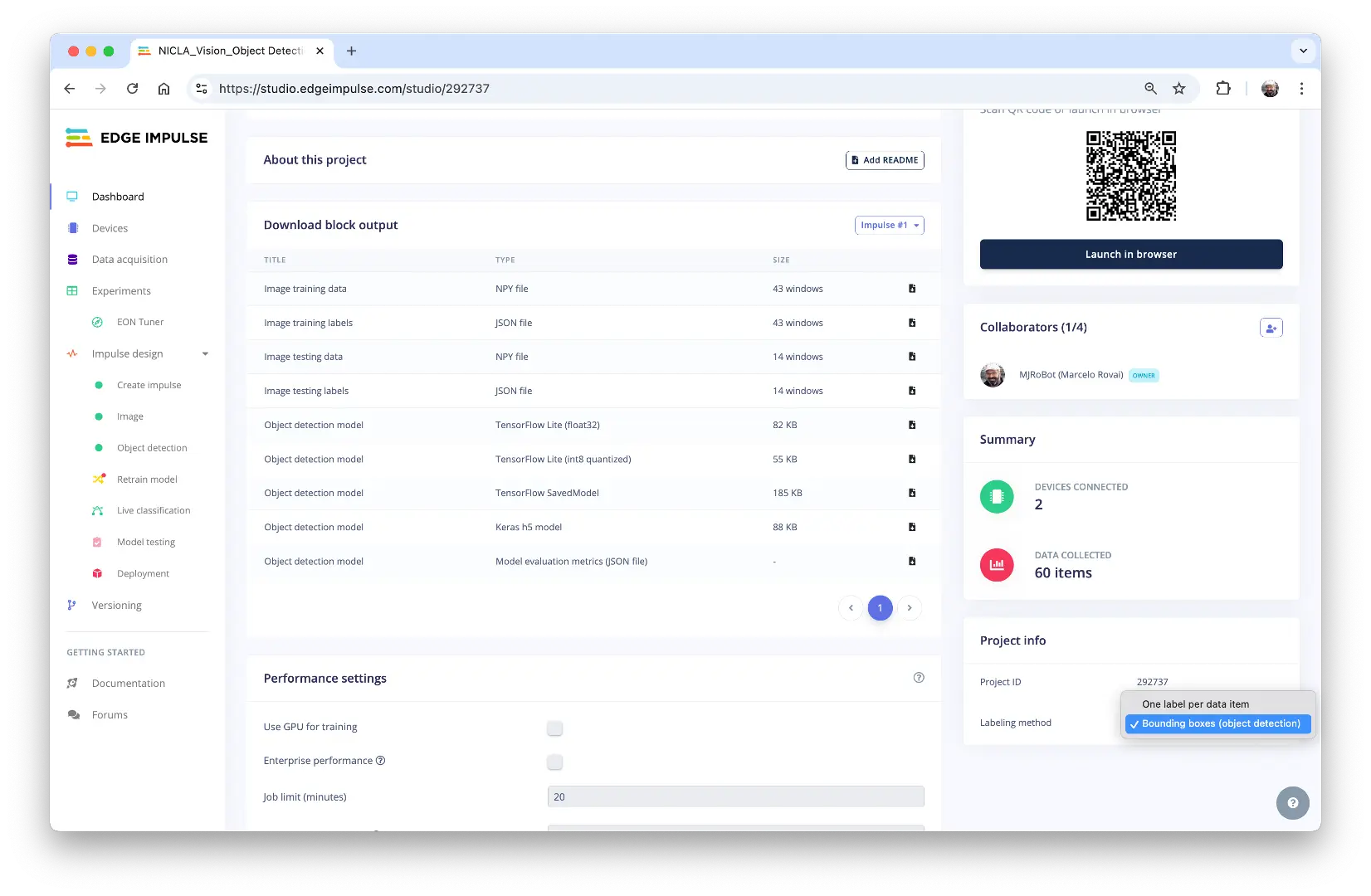
在项目 Dashboard,进入 Project info,选择 Bounding boxes (object detection),右上角选择 Target 为 Arduino Nicla Vision (Cortex-M7)。
上传未标注数据
在 Studio 的 Data acquisition 标签页,UPLOAD DATA 区域上传采集的图片。
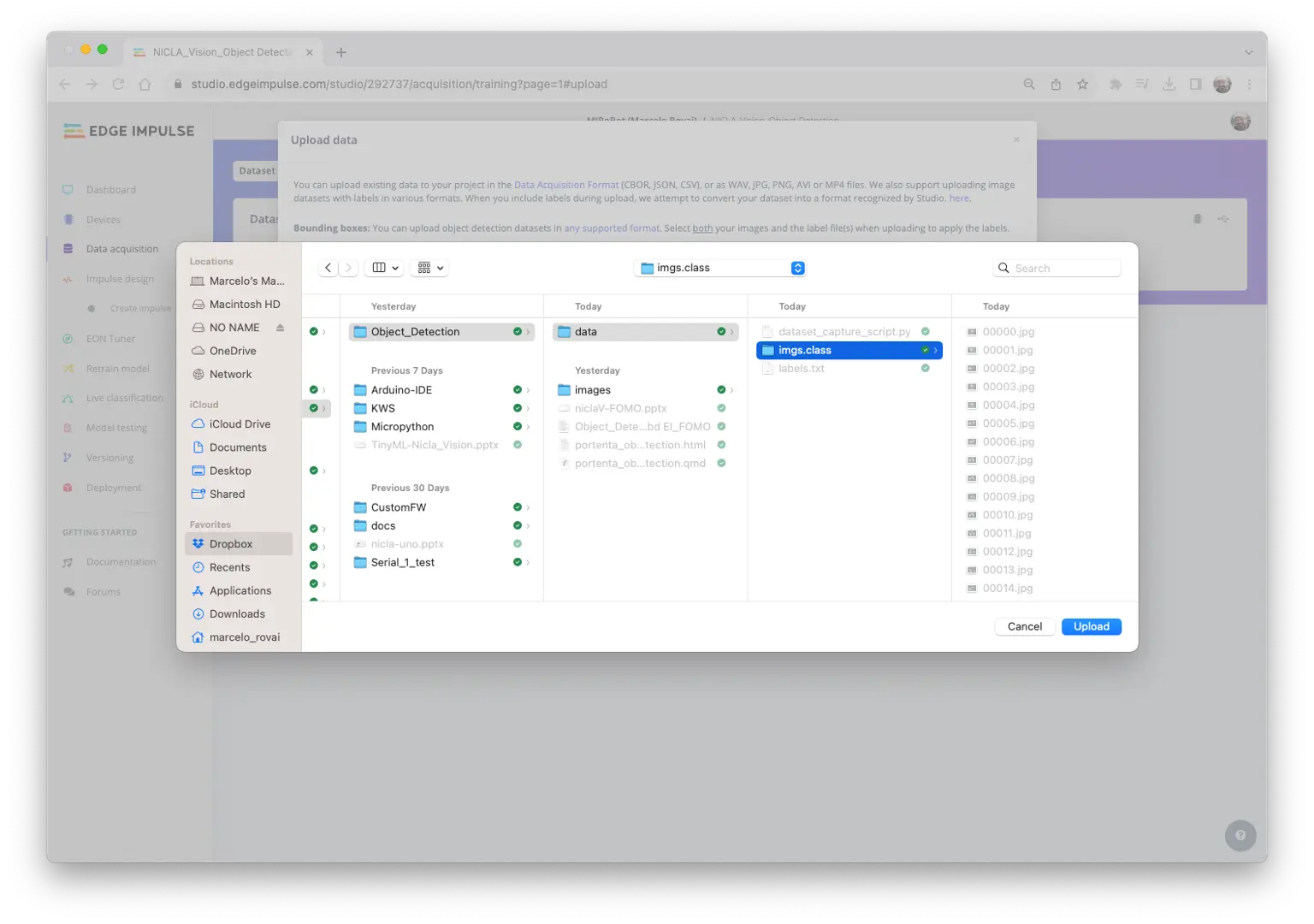
可让 Studio 自动划分训练/测试集,也可手动分配。
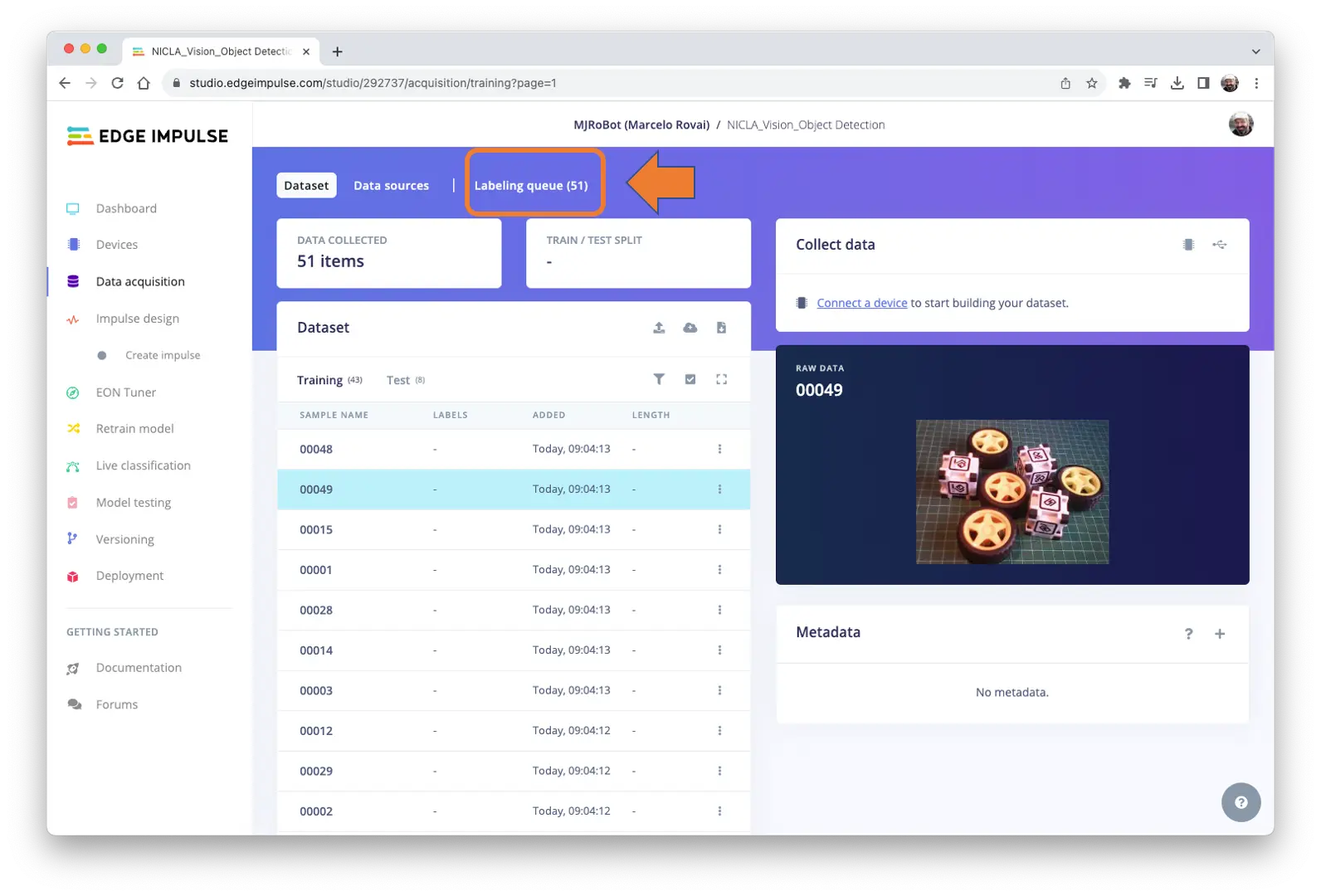
所有未标注图片(51 张)已上传,但需标注后才能用于训练。Studio 提供标注工具,点击 Labeling queue (51) 进入。
Edge Impulse Studio(免费版)支持两种 AI 辅助标注方式:
- 使用 yolov5
- 帧间目标跟踪
企业版支持 自动标注功能 。
常见物体可用 YOLOv5(COCO 数据集)预训练模型自动标注。但本项目物体不在 COCO 数据集内,需选择 tracking objects,即手动标注一帧后自动跟踪,部分图片可自动标注(但并非全部准确)。
若已有带边界框的标注数据集,可用 EI uploader 导入。
标注数据集
从第一张未标注图片开始,用鼠标框选物体并添加标签,点击 Save labels 进入下一张。
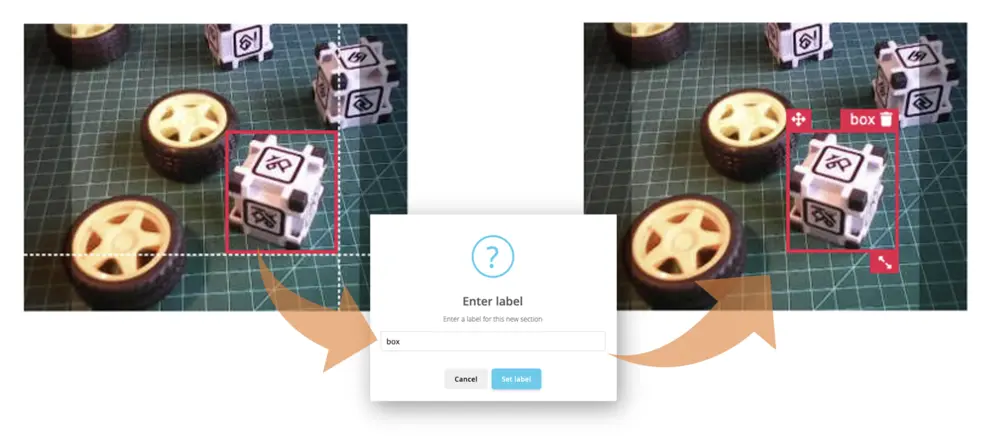
重复操作直到队列为空。最终所有图片都应正确标注,如下所示:

在 Data acquisition 标签页复查标注样本,如有错误可通过三点菜单编辑:
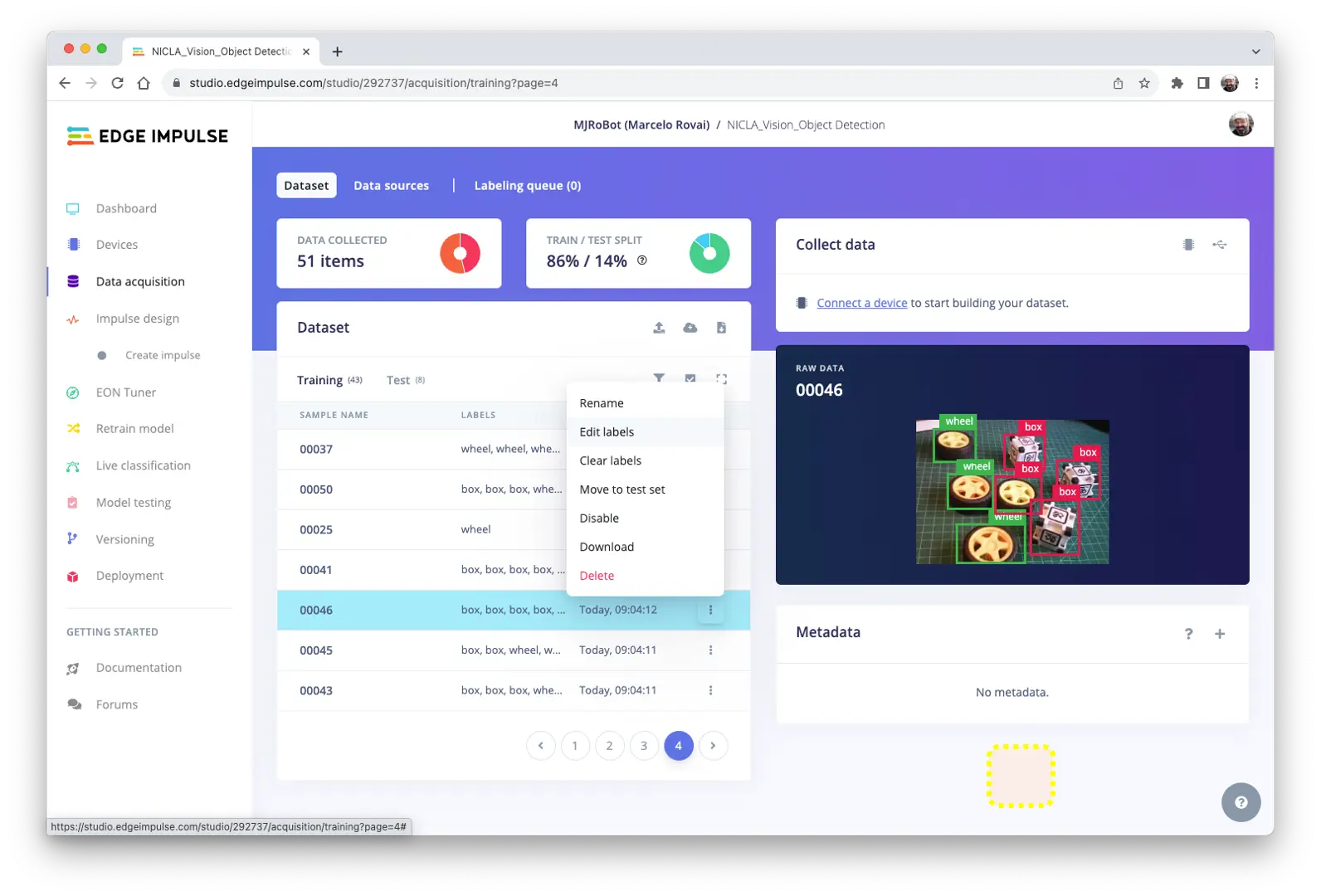
可替换错误标签,修正数据集。

Impulse 设计
本阶段需完成:
- 预处理:将图片从
320 x 240缩放为96 x 96,保持方形(不裁剪),并转为灰度图。 - 模型设计:选择“Object Detection”。
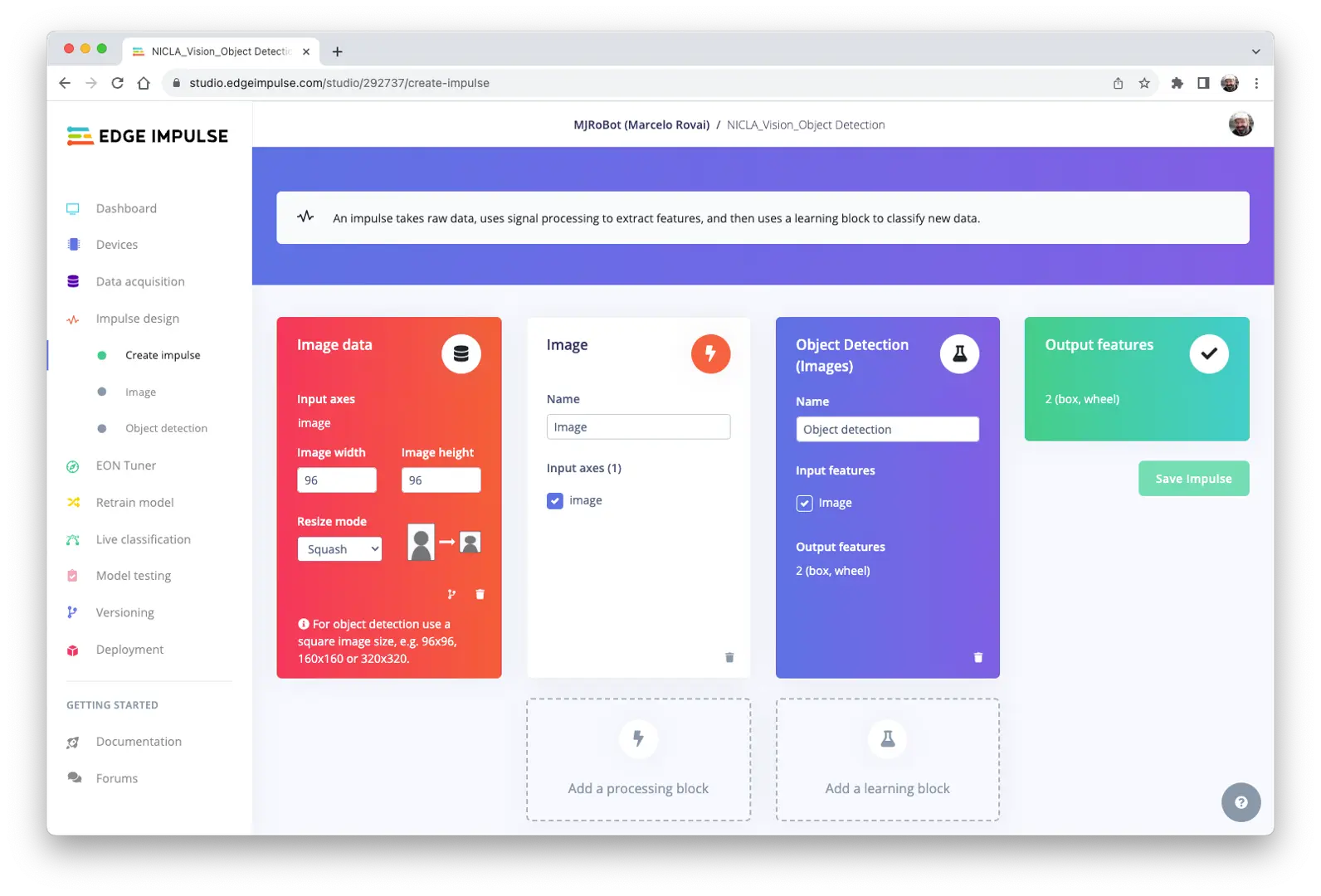
预处理数据集
选择 Color depth 为 Grayscale,适合 FOMO 模型,保存参数。
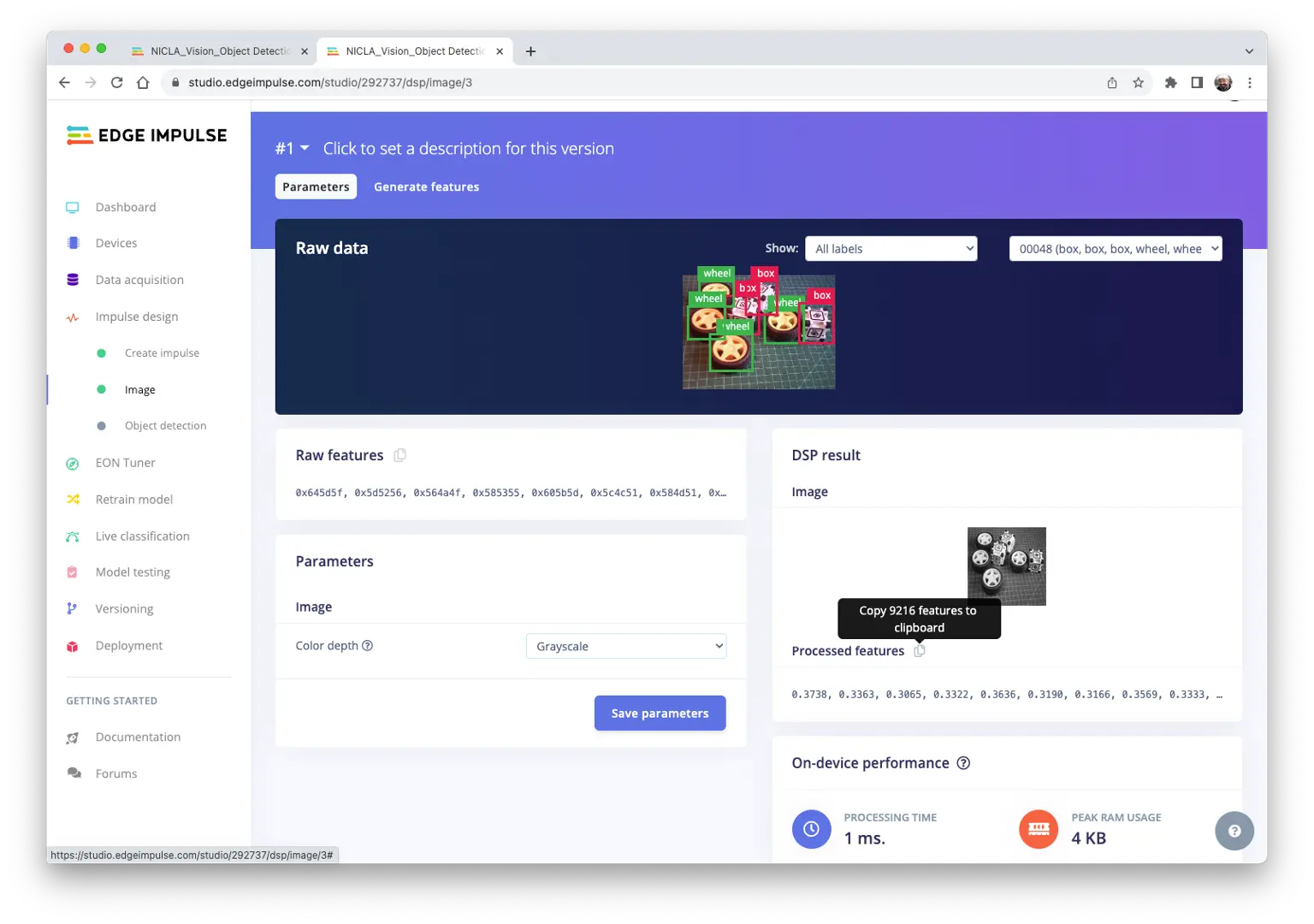
Studio 自动进入 Generate features,所有样本将被预处理,生成 $96\times 96\times 1$ 的图片(9216 个特征)。
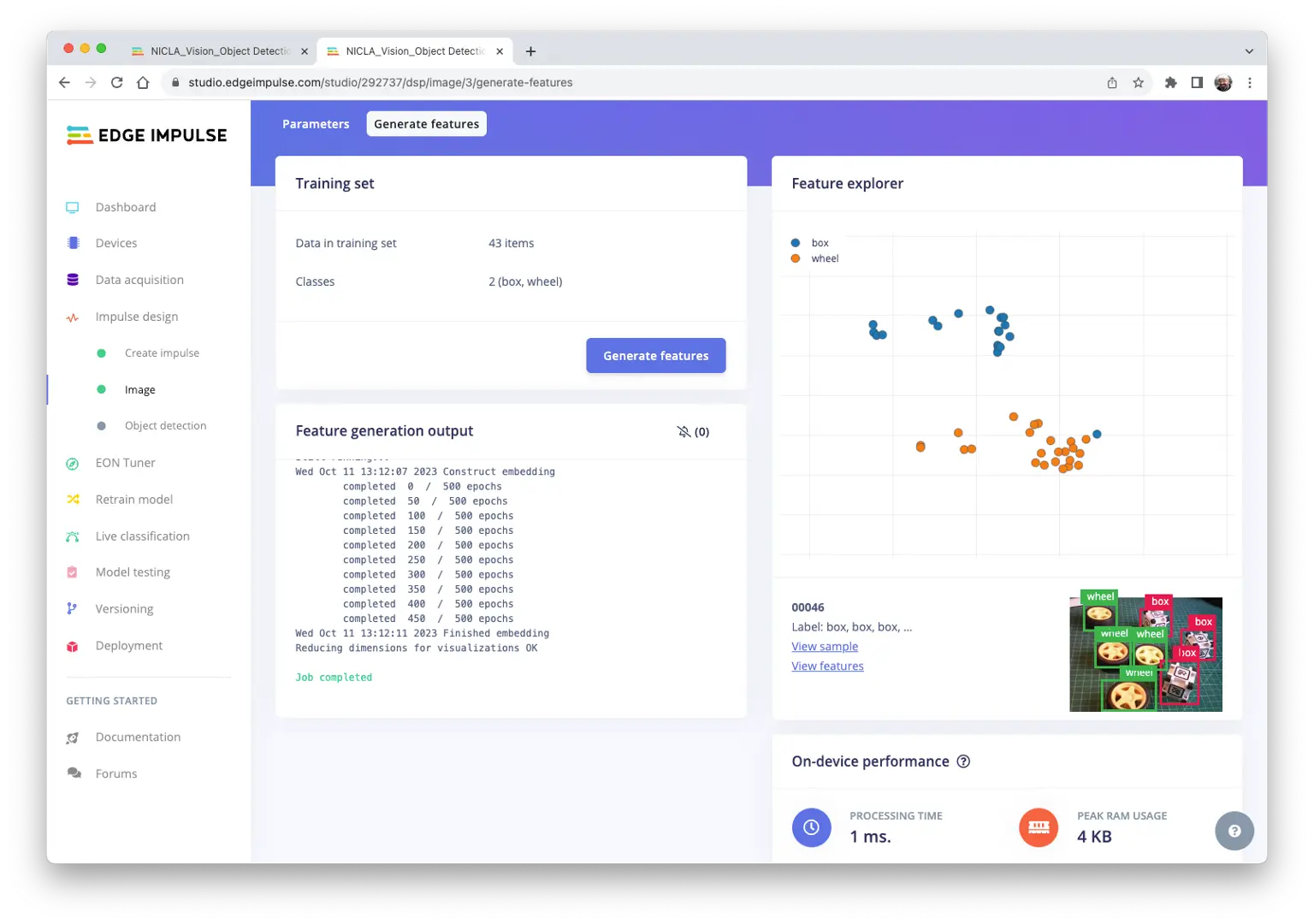
特征可视化显示样本分布良好。
有一张样本(46)似乎位置异常,点击确认标签无误。
模型设计、训练与测试
本项目采用基于 MobileNetV2(alpha 0.35)的 FOMO 目标检测模型,将图片粗略分割为背景与目标物体(盒子、轮子)网格。
FOMO 是创新的目标检测模型,能耗和内存消耗比传统模型(Mobilenet SSD、YOLOv5)低 30 倍,可在小于 200 KB RAM 的微控制器上运行。其原理是只输出物体质心坐标,不输出边界框。
FOMO 工作原理
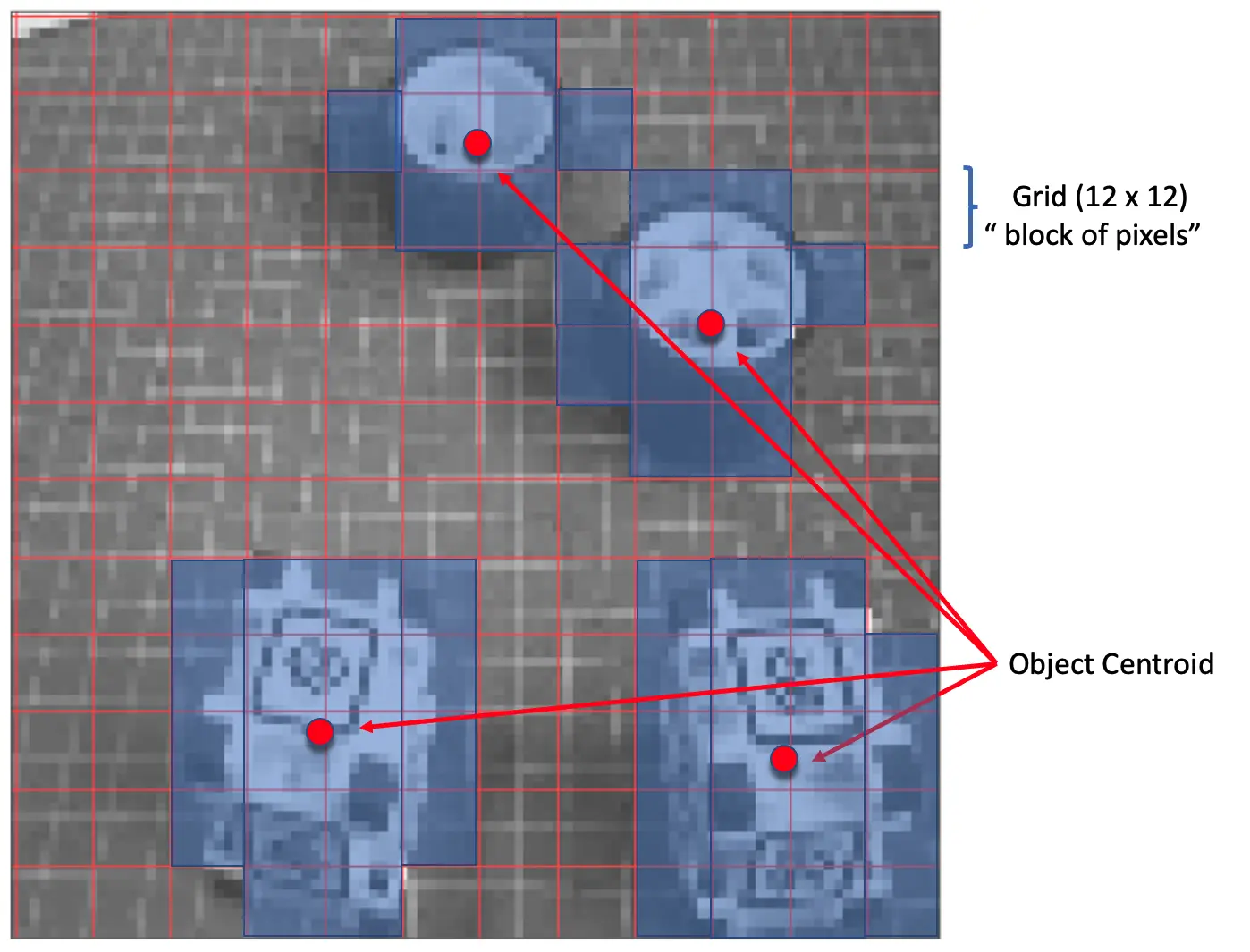
FOMO 将灰度图按 8 像素分块,输入为 96x96 时,网格为 $12\times 12$。每个像素块用分类器判断是否包含目标物体,最终输出概率最高的区域(无物体则为背景)。最终输出为各物体质心的坐标。
训练时选择预训练模型 FOMO (Faster Objects, More Objects) MobileNetV2 0.35,约占用 250 KB RAM 和 80 KB ROM,适合 1MB RAM/ROM 的板卡。
训练超参数:
- 轮数:60
- 批量:32
- 学习率:0.001
训练时 20% 数据集用于验证,80% 用于训练并进行数据增强(随机翻转、缩放、亮度变化、裁剪),提升泛化能力。
最终模型 F1 分数约 91%(验证集)、93%(测试集)。
FOMO 自动为原有的盒子和轮子标签添加了第三类背景。
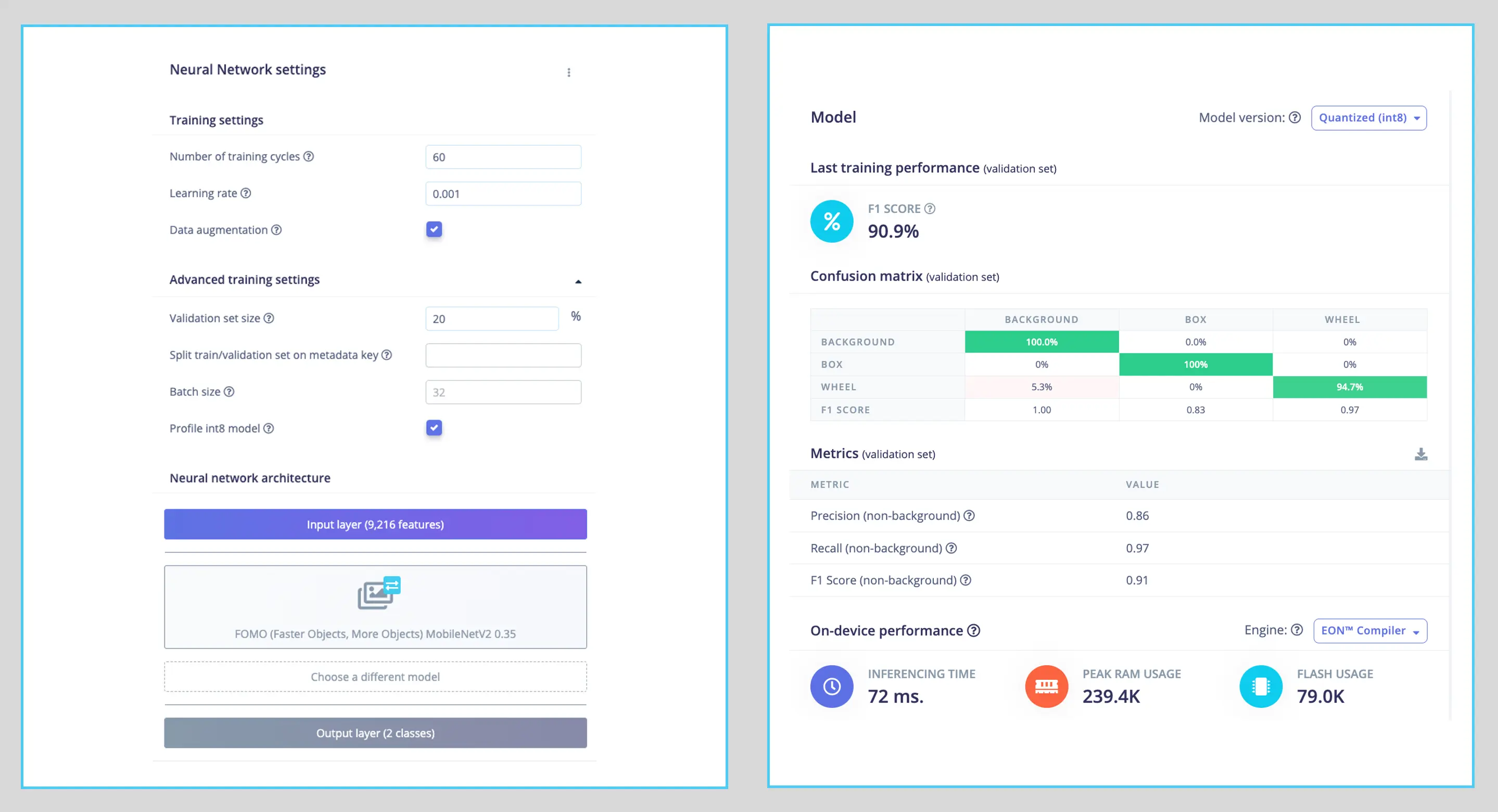
目标检测任务通常不以准确率为主要 评估指标 ,而以 F1 分数等衡量。FOMO 只输出质心,无边界框,因此更适合用 F1 分数评价。
“实时分类”测试模型
Edge Impulse 官方支持 Nicla Vision,可直接连接 Studio 进行实时测试:
- 下载 最新 EI 固件 并解压
- 打开 zip,选择对应操作系统的上传工具
- 按两次复位键进入 Boot 模式
- 运行批处理脚本上传
arduino-nicla-vision.bin
在 EI Studio 的 Live classification 区域,用 webUSB 连接 Nicla Vision:
连接后可用 Nicla 采集图片,实时用训练模型推理:
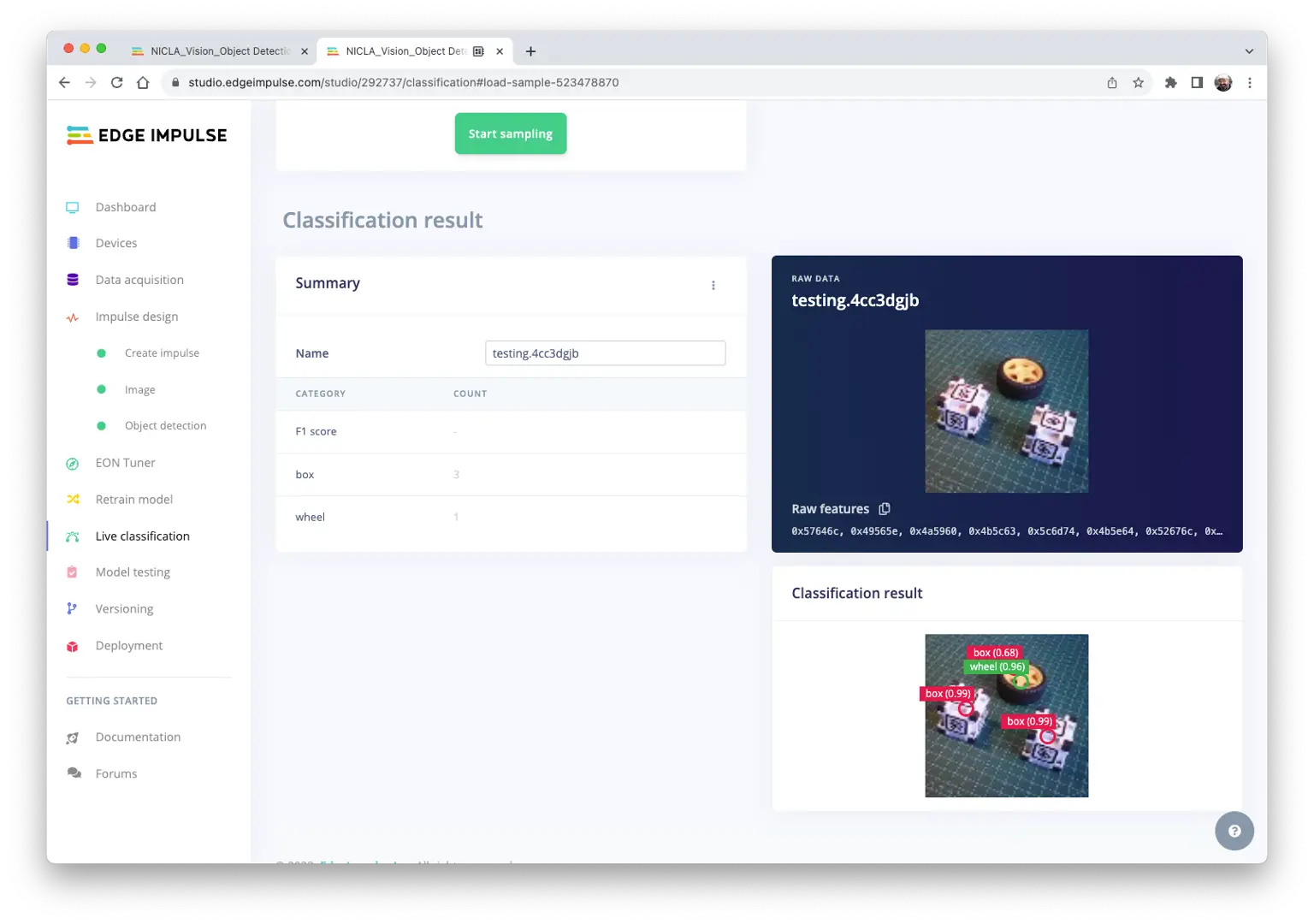
注意模型可能有误报/漏报,可通过设置 Confidence Threshold(在三点菜单中)调整,建议设为 0.8 以上。
部署模型
在 Deploy Tab 选择 OpenMV Firmware,点击 [Build]。
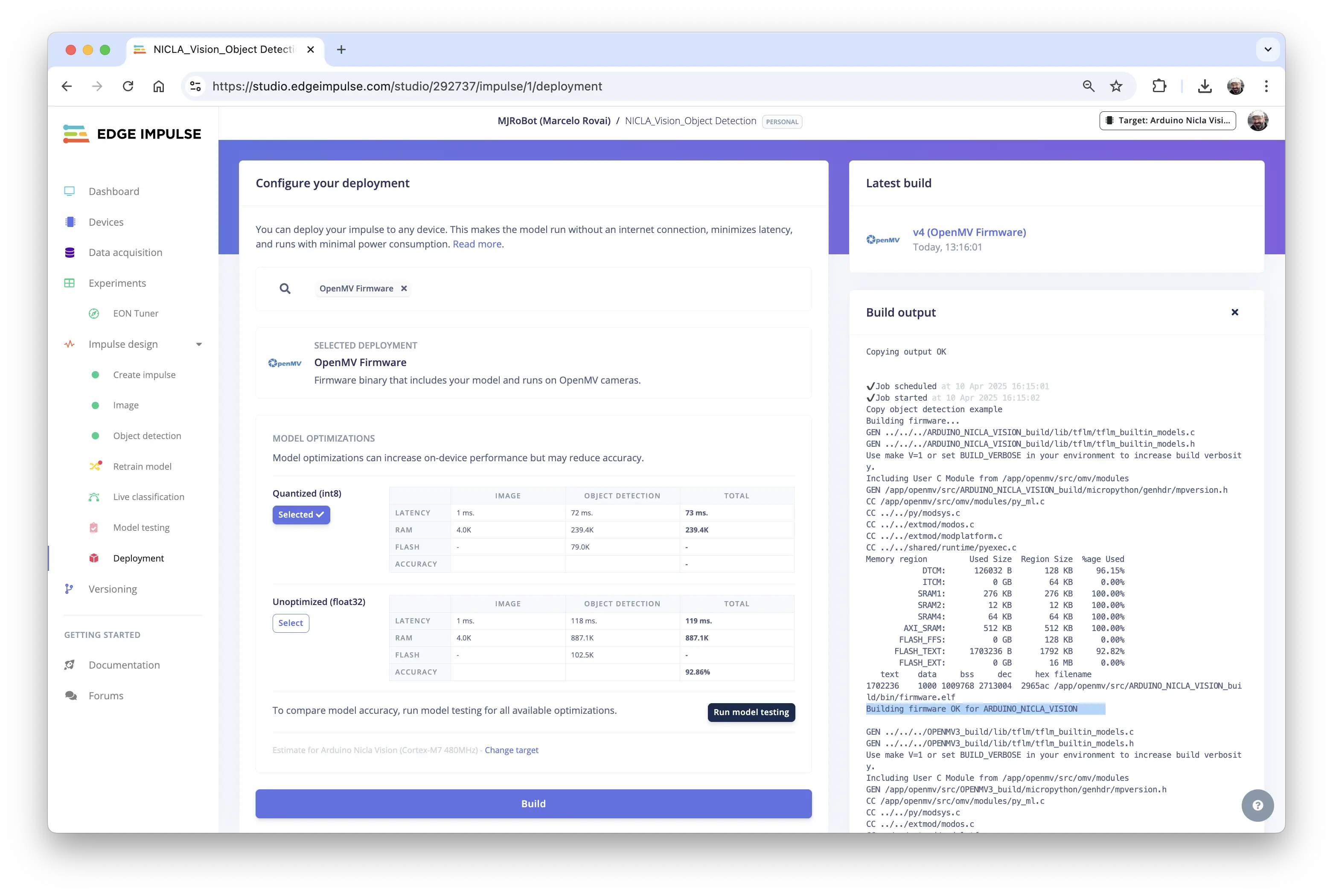
再次用 OpenMV IDE 连接 Nicla 时,选择 Load a specific firmware,或通过 Tools > Runs Boatloader (Load Firmware) 手动加载。

解压 Studio 下载的 ZIP 文件:
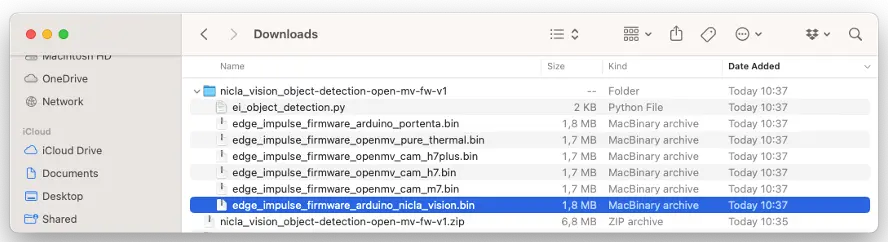
将 .bin 文件烧录到开发板:
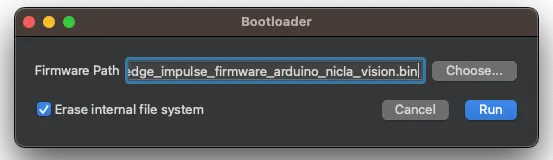
烧录完成后弹窗提示,点击 OK,打开 Studio 下载的 ei_object_detection.py 脚本。
如弹窗提示固件过期,点击
[NO]跳过升级。
运行脚本前可调整部分参数。窗口定义可保持 $240\times 240$,摄像头采集 QVGA/RGB,图片会被固件自动预处理。
import sensor
import time
import ml
from ml.utils import NMS
import math
import image
sensor.reset() # 传感器初始化
sensor.set_pixformat(sensor.RGB565) # 设置像素格式
sensor.set_framesize(sensor.QVGA) # 设置帧尺寸
sensor.skip_frames(time=2000) # 等待相机调整
可调整最小置信度(如 0.8),减少误报/漏报:
min_confidence = 0.8
如需更好对比,可调整质心圆圈颜色:
threshold_list = [(math.ceil(min_confidence * 255), 255)]
# 加载内置模型
model = ml.Model("trained")
print(model)
# 可选:从文件系统加载模型
# model = ml.Model('<object_detection_modelwork>.tflite', load_to_fb=True)
# labels = [line.rstrip('\n') for line in open("labels.txt")]
colors = [
(255, 255, 0), # background: yellow(未用)
( 0, 255, 0), # cube: green
(255, 0, 0), # wheel: red
( 0, 0, 255), # 未用
(255, 0, 255), # 未用
( 0, 255, 255), # 未用
(255, 255, 255), # 未用
]
其余代码保持不变:
# FOMO outputs an image per class where each pixel in the
# image is the centroid of the trained object. So, we will
# get those output images and then run find_blobs() on them
# to extract the centroids. We will also run get_stats() on
# the detected blobs to determine their score.
# The Non-Max-Supression (NMS) object then filters out
# overlapping detections and maps their position in the
# output image back to the original input image. The
# function then returns a list per class which each contain
# a list of (rect, score) tuples representing the detected
# objects.
def fomo_post_process(model, inputs, outputs):
n, oh, ow, oc = model.output_shape[0]
nms = NMS(ow, oh, inputs[0].roi)
for i in range(oc):
img = image.Image(outputs[0][0, :, :, i] * 255)
blobs = img.find_blobs(
threshold_list,
x_stride=1,
area_threshold=1,
pixels_threshold=1,
)
for b in blobs:
rect = b.rect()
x, y, w, h = rect
score = (
img.get_statistics(
thresholds=threshold_list, roi=rect
).l_mean()
/ 255.0
)
nms.add_bounding_box(x, y, x + w, y + h, score, i)
return nms.get_bounding_boxes()
clock = time.clock()
while True:
clock.tick()
img = sensor.snapshot()
for i, detection_list in enumerate(
model.predict([img], callback=fomo_post_process)
):
if i == 0:
continue # background class
if len(detection_list) == 0:
continue # no detections for this class?
print("********** %s **********" % model.labels[i])
for (x, y, w, h), score in detection_list:
center_x = math.floor(x + (w / 2))
center_y = math.floor(y + (h / 2))
print(f"x {center_x}\ty {center_y}\tscore {score}")
img.draw_circle((center_x, center_y, 12), color=colors[i])
print(clock.fps(), "fps", end="\n")
点击 绿色播放按钮 运行代码:
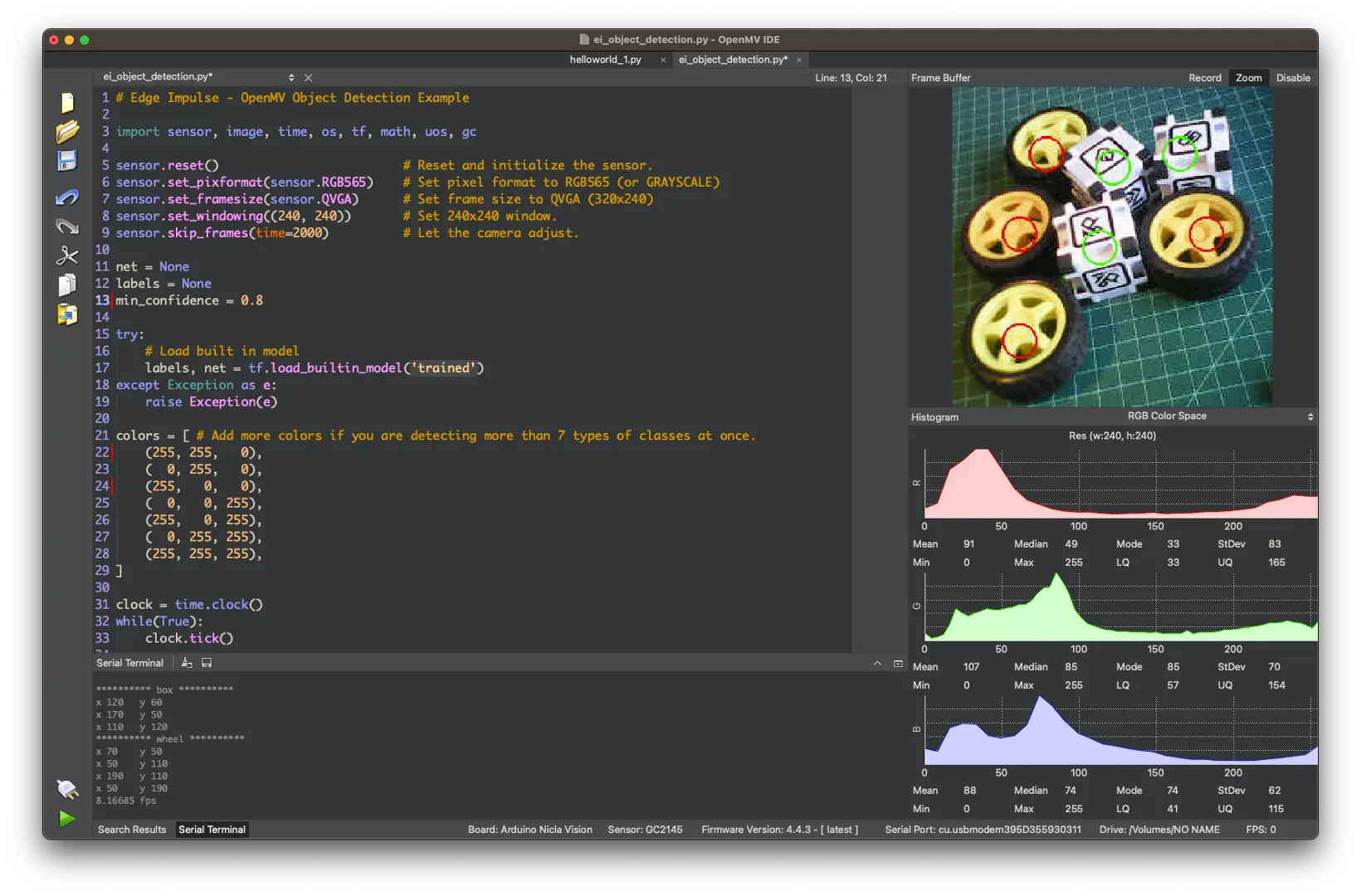
摄像头画面中,物体质心用 12 像素圆圈标记(不同类别颜色不同)。串口终端显示检测到的标签及其在窗口 $(240\times 240)$ 的位置。
坐标原点在左上角。

帧率约 8 fps,与图像分类项目相近。FOMO 基于 CNN 构建,效率高于 SSD MobileNet 或 YOLO。例如,树莓派 4 上运行 MobileNetV2 SSD FPN-Lite $320\times 320$,延迟约为本项目的 5 倍(约 1.5 fps)。
推理演示视频:https://youtu.be/JbpoqRp3BbM
总结
FOMO 是图像处理领域的重要突破,正如 Louis Moreau 和 Mat Kelcey 在 2022 年发布时所说:
FOMO 是一项突破性算法,首次将实时目标检测、追踪和计数带到微控制器平台。
在嵌入式设备上探索目标检测(尤其是计数)有广阔应用前景,如蜜蜂计数等项目。
