第 7 章:AI 框架
目标
为什么机器学习框架是决定生产级 AI 系统可扩展性、开发速度和架构灵活性的关键抽象层?
机器学习框架作为理论与实践的桥梁,将抽象的数学思想转化为高效可执行的代码,并为硬件加速、分布式计算和模型部署提供标准化接口。如果没有框架,每个 ML 项目都需重复实现诸如自动微分、并行计算等核心操作,大规模开发将变得极其低效且成本高昂。框架的抽象层带来了两大能力:一是通过预优化实现加速开发,二是实现硬件的可移植性(支持 CPU、GPU 及专用加速器)。框架选择是系统工程中最重要的决策之一,直接影响架构约束、性能表现和部署灵活性,贯穿整个开发生命周期。
学习目标
- 梳理 ML 框架从数值计算库到深度学习平台再到专用部署工具的演进历程
- 解析现代框架中计算图、自动微分和张量操作的架构与实现
- 通过对比静态与动态执行模型,分析其在开发灵活性、调试能力和生产优化上的权衡
- 探讨主流框架的设计哲学(如研究优先、生产优先、函数式编程)及其对系统架构的影响
- 通过系统评估模型需求、硬件约束和部署场景,制定框架选择标准
- 在多种框架下实现等价的机器学习操作,展示抽象层的差异
- 针对云、边缘、移动和微控制器等场景,设计框架选型策略
- 批判常见的框架选型误区,评估其对系统性能与可维护性的影响
框架抽象与必要性
将底层计算原语转化为机器学习系统,是现代计算机科学最具挑战性的工程之一。本章在上一章数据管道基础上,深入探讨支撑高效 ML 算法实现的软件基础设施。虽然机器学习的数学基础(线性代数、优化算法、梯度计算)已非常成熟,但在生产系统中高效落地,必须依赖软件抽象,将理论与实际工程约束相结合。
现代 ML 算法的计算复杂度凸显了抽象层的必要性。训练一个主流语言模型,需在分布式硬件上协调数十亿次浮点运算,涉及内存层级、通信协议和数值精度管理。每个算法环节(如前向传播、反向传播)都需拆解为可映射到异构处理单元的基本操作,同时保证数值稳定性和可复现性。若仅依赖底层原语实现,绝大多数组织都难以承担大规模 ML 的开发成本。
具体实现难度一目了然:手动实现一个三层 MLP 的反向传播,需数百行复杂的微积分与矩阵运算代码,而现代框架只需一句 loss.backward()。框架不仅让机器学习变得“简单”,更让现代深度学习成为可能——它们管理了梯度计算、硬件优化和分布式执行的复杂性。
机器学习框架是连接高层算法描述与底层计算实现的核心软件基础设施。它们解决了 ML 计算的抽象难题:在保证算法表达力的同时,实现跨硬件的高效计算。通过标准化的计算图、自动微分引擎和优化算子库,框架让研究者和工程师专注于算法创新,而无需关心底层实现细节。这一抽象层极大加速了 ML 的科研突破和工业落地。
框架定义
机器学习框架(ML Framework) 是一种 软件平台,为设计、训练和部署机器学习模型提供 工具与抽象。它连接 用户应用 与 基础设施,通过计算图和算子实现 算法表达力,通过工作流编排覆盖 ML 生命周期,通过调度与编译器实现 硬件优化,支持分布式与边缘系统的 可扩展性,并具备高度 可扩展性 和 可扩展性。ML 框架通过标准化开发与部署流程,成为现代机器学习系统的基础。
机器学习框架的演进轨迹,反映了 AI 领域从实验研究到工业规模部署的成熟过程。早期框架主要关注数学运算的高效表达,着重优化线性代数原语和梯度计算。现代平台则涵盖了完整的 ML 开发生命周期,集成了数据预处理、分布式训练、模型版本管理和生产部署等功能。这种架构演进体现了业界对可持续 ML 系统的工程化需求——不仅要算法高效,还要兼顾可扩展性、可靠性、可维护性和可复现性。
框架架构设计的每一个决策,都会深刻影响基于其构建的 ML 系统的特性和能力。计算图表示、内存管理、并行策略和硬件抽象层的选择,直接决定了系统性能、可扩展性和部署灵活性。这些架构约束会贯穿开发的每个阶段,从原型到生产优化,决定了算法创新的实际落地边界。
本章将机器学习框架视为软件工程产物和现代 AI 系统的使能器,系统分析其架构原理、设计权衡及在 ML 基础设施生态中的作用。通过框架演进、架构模式和实现策略的深入剖析,帮助读者建立科学的框架选型能力,并在生产级 ML 系统设计与实现中高效利用这些抽象。
历史发展脉络
要理解现代框架为何具备如此强大的能力,需回顾它们如何从简单数学库演变为今日的平台。ML 框架的演进,正是 AI 与计算能力发展的缩影,主要受三大因素驱动:模型复杂度提升、数据集规模扩大、硬件架构多样化。
这些驱动力塑造了框架发展的不同阶段,既反映了技术进步,也体现了 AI 社区需求的变化。本节将梳理框架从早期数值计算库到现代深度学习平台的演变过程。这一历程承接了 第 1 章:绪论 的 AI 发展历史背景,展示了软件基础设施如何让 ML 理论突破变为现实。
框架发展时间线
ML 框架的发展,建立在数十年计算库的基础之上。从 BLAS、LAPACK 等底层构件,到 TensorFlow、PyTorch、JAX 等现代框架,这一历程是不断提升抽象层级、让 ML 更易用更强大的过程。
通过梳理这些基础技术的关系,可以清晰看到 ML 发展脉络。参考图 1,可追溯数值计算库如何为现代 ML 奠定基础。BLAS、LAPACK 的数学底座,催生了更易用的 NumPy、SciPy,最终成就了深度学习框架。

这一进步过程,展示了框架如何通过渐进式创新,基于前人的基础不断提升计算可达性。
数学计算基础设施
现代 ML 框架的基础,始于矩阵运算这一核心计算层。机器学习的主要计算是矩阵 - 矩阵和矩阵 - 向量乘法,因为神经网络通过线性变换1处理多维数据。1979 年开发的基础线性代数子程序( BLAS )2,为 ML 提供了关键的矩阵运算底座。这些底层操作的组合与执行,支撑了神经网络和其他 ML 模型的复杂计算。
在 BLAS 基础上,1992 年推出了线性代数包( LAPACK )3,扩展了矩阵分解、特征值问题和线性系统求解等高级运算。这种由基础矩阵运算逐层构建复杂操作的模式,成为 ML 框架的典型特征。
优化的线性代数运算,为更高层抽象奠定了基础。2006 年推出的 NumPy ,在 Numeric 和 Numarray 基础上,成为 Python 数值计算的主力包。NumPy 引入了多维数组对象和基础数学函数,高效对接 BLAS、LAPACK 运算,让开发者能用高层数组操作,享受底层优化性能。
随后 SciPy 在 2008 年稳定发布,进一步扩展了 NumPy 的优化、线性代数和信号处理等专用函数。这种从基础矩阵运算到数值计算的分层架构,为后续 ML 框架奠定了蓝图。
早期机器学习平台发展
下一个阶段,是从通用数值计算到领域专用 ML 工具的跃迁。数值库向专用 ML 框架转变,标志着抽象层级的提升。虽然底层计算仍是矩阵运算,但框架开始将这些操作封装为更高层的 ML 原语。1993 年新西兰怀卡托大学推出 Weka [Witten 2002],是最早的 ML 框架之一,将矩阵运算抽象为数据挖掘任务,但受限于 Java 实现和小规模计算。
2007 年出现的
Scikit-learn
,在 NumPy、SciPy 基础上实现了 ML 算法的高层抽象。比如,原本需要一系列矩阵乘法和梯度计算的逻辑回归模型,在框架中只需调用 fit() 方法。隐藏复杂矩阵运算、提供简洁 API 的抽象模式,成为现代 ML 框架的标志。
蒙特利尔大学开发的 Theano 4,2007 年问世,带来了两大革命性概念:计算图5和 GPU 加速 [Al 2016]。计算图将数学运算表示为有向图,节点是矩阵操作,数据在节点间流动。这种图式表达让自动微分和矩阵运算优化成为可能,更重要的是能自动将运算分配到 GPU,大幅加速矩阵计算。
另一条发展线是 2002 年 NYU 推出的 Torch7 (PyTorch 的 Lua 前身),采用即时执行(eager execution6),为神经网络实现提供了灵活接口。
Torch 的设计哲学——兼顾开发体验与高性能,影响了后来的 PyTorch。其架构展示了如何在高层抽象与底层矩阵运算间取得平衡,为深度学习复杂性提升奠定了关键思想。
深度学习平台创新
深度学习的兴起带来了前所未有的计算需求,暴露了既有框架的局限。深度学习革命要求框架在矩阵运算处理上做出重大变革,主要原因有三:计算规模巨大、梯度计算复杂、分布式处理需求强烈。传统框架难以应对训练深度神经网络所需的数十亿次矩阵运算。
这一计算挑战,催生了学术界的创新,彻底改变了框架发展。蒙特利尔大学的 Theano ,2007 年发布,奠定了现代框架的核心概念 [Bergstra 2010]。它引入了计算图、自动微分和 GPU 加速,展示了如何组织和优化复杂神经网络计算。
2013 年 UC Berkeley 推出的 Caffe ,通过卷积操作的专用实现推动了计算机视觉任务的发展。卷积本质上是特定模式的矩阵乘法,Caffe 针对视觉网络优化了这些操作,证明了专用矩阵运算能极大提升特定架构的性能。
工业界的突破来自 Google 的 TensorFlow 7,2015 年发布,将矩阵运算视为分布式计算问题 [Dean 2012]。它将所有计算(从单次矩阵乘法到整个神经网络)表示为静态计算图8,可在多设备间拆分。这一模式让模型规模突破极限,通过集群和专用硬件分布矩阵运算。静态图虽然限制了灵活性,但能通过算子融合9和内存规划10等技术,极大优化矩阵运算。
深度学习框架生态持续多元化,不同组织针对特定计算挑战推出新架构。微软的 CNTK 2016 年进入市场,专注语音识别和自然语言处理 [Seide 2016],强调分布式系统的可扩展性和序列模型的高效计算。
同时,Facebook 的 PyTorch 11 也在 2016 年发布,采用动态计算图,可在运行时修改 [Paszke 2019]。动态图虽然牺牲部分优化机会,但极大简化了调试和模型分析,成为研究者的首选。PyTorch 的成功证明,动态可变的计算结构对科研同样重要。
亚马逊的 MXNet 则聚焦内存效率和多硬件可扩展性,采用静态与动态图混合模式,兼顾开发灵活性和底层矩阵运算优化。
随着深度学习应用多样化,专用和高层抽象工具不断涌现。 Keras 2015 年发布,提供统一接口,可运行于多种底层框架之上 [Chollet 2015],强调用户体验与底层计算能力的结合。
Google 的 JAX 12 2018 年推出,将函数式编程引入深度学习计算,带来全新模型开发模式 [JAX 2018]。 FastAI 基于 PyTorch,封装常用深度学习模式,让高级技术更易用 [Howard 2020]。这些高层框架证明,抽象不仅能简化开发,还能保留底层性能优势。
硬件驱动的框架架构演进
框架的演进与计算硬件进步密不可分,软件能力与硬件创新形成动态互动。硬件发展极大改变了框架对矩阵运算的实现与优化方式。2007 年 NVIDIA 推出 CUDA 平台 [^fn-cuda],让 GPU 能用于通用计算 [Nickolls 2008],对框架设计产生了革命性影响。GPU 擅长并行矩阵运算,能将深度学习计算速度提升数十倍。CPU 通常顺序处理矩阵元素,而 GPU 可同时处理数千个元素,框架必须优化计算调度以充分利用 GPU。
现代 GPU 架构在 ML 工作负载下展现出量化效率优势。NVIDIA A100 GPU 在 FP16 精度下可达 312 TFLOPS 张量运算,内存带宽 1.6 TB/s,而典型 CPU 仅 1-2 TFLOPS、带宽 50-100 GB/s。框架需设计计算图,最大化 GPU 利用率,确保足够的计算强度(FLOPS/字节)以饱和带宽。
内存带宽优化在 GPU 加速场景尤为关键。内存带宽与计算比(字节/FLOP)决定操作是计算瓶颈还是内存瓶颈。大尺寸矩阵乘法(N×N,N>1024)计算强度高,能充分利用 GPU;而逐元素操作如激活函数常受内存瓶颈影响,性能仅为峰值的 10-20%。框架通过算子融合,将多个内存瓶颈操作合并为单一内核,减少内存传输。
专用硬件加速器的出现进一步推动了框架设计革新。Google 的 TPU 13,2016 年部署,专为张量运算设计,是深度学习计算的核心。TPU 采用脉动阵列14架构,极大提升了矩阵乘法和卷积效率。框架如 TensorFlow 针对 TPU 开发了专用编译策略,将高层操作直接映射为 TPU 指令,跳过传统 CPU 优化。
TPU 架构在能效上有显著优势。TPU v4 芯片 BF16 计算达 275 TFLOPS,内存带宽 1.2 TB/s,功耗 200W,能效 1.375 TFLOPS/W,比同代 GPU 在大矩阵运算上高 3-5 倍。但 TPU 仅对稠密矩阵运算优化,稀疏计算或复杂控制流效率较低。框架需设计计算图,最大化稠密矩阵操作,减少芯片内外数据移动。
移动硬件加速器如 Apple Neural Engine (2017) 和高通 NPU,为框架设计带来新约束与机遇。这些设备强调能效而非计算速度,框架需开发量化和算子融合新策略。移动框架如 TensorFlow Lite(现更名为 LiteRT )和 PyTorch Mobile ,需在模型精度与能耗间权衡,推动了矩阵运算调度与执行创新。
移动加速器凸显混合精度计算对能效的关键作用。Apple A17 Pro 芯片的 Neural Engine INT8 性能 35 TOPS,功耗约 5W,能效 7.2 TOPS/W,比同芯片 FP32 计算高 10-15 倍。框架需自动混合精度策略,按操作选择最优精度,兼顾能耗与精度。
稀疏计算框架解决了移动硬件的内存带宽瓶颈。结构化稀疏网络可减少 50-90% 内存流量,直接提升能效(内存访问能耗是算术操作的 10-100 倍)。如 Neural Magic 的 SparseML 自动生成稀疏模型,兼顾精度与硬件稀疏支持。高通 NPU SDK 支持 2:4 结构稀疏算子,每 4 个权重有 2 个为零,速度提升 1.5-2 倍,精度损失极小。
定制 ASIC15 的出现进一步丰富了硬件生态。Graphcore、Cerebras、SambaNova 等公司开发了各具特色的矩阵计算架构,框架需采用更灵活的中间表示16,实现针对目标硬件的优化,同时保持高层接口一致。
可重构硬件的出现又带来新复杂性与机遇。FPGA(现场可编程门阵列)让框架能针对特定矩阵运算模式生成优化电路。框架需开发 JIT 编译策略,按模型需求生成最优硬件配置。
硬件驱动的框架演进,要求框架设计不断适应新计算能力。梳理了从数值库到硬件创新驱动的平台演变后,接下来将深入理解现代框架管理计算复杂性的核心概念——计算图、执行模型和系统架构,这些是所有框架能力的基础。
基础概念
现代机器学习框架通过四大层次集成运作:基础层、数据处理层、开发者接口层、执行与抽象层。各层协同,为模型开发与部署提供结构化、高效的基础,如图 2 所示。

基础层通过计算图建立框架结构。计算图采用有向无环图(DAG),支持自动微分与优化。通过组织操作与数据依赖,计算图让框架能分布任务、在多种硬件平台高效执行。
数据处理层管理 ML 工作流所需的数值数据与参数。核心数据结构如张量,支持高维数组、优化内存与设备分配。内存管理与数据移动策略,确保在硬件资源有限或多样化环境下高效执行。
开发者接口层为用户提供工具与抽象。编程模型分为命令式与符号式,命令式灵活易调试,符号式则优先性能与部署效率。执行模型决定计算是即时(eager)还是预优化静态图。
最底层的执行与抽象层,将高层表示转化为高效硬件可执行操作。涵盖从基础线性代数到复杂神经网络层的核心算子,针对多种硬件平台优化。还包括动态资源分配与内存管理机制,保障训练与推理的可扩展性能。
四层通过精心设计的接口与依赖协作,形成兼顾易用性与性能的整体系统。理解这些层次的关联,是高效利用 ML 框架的关键。每层在实验、优化、部署中都扮演着独立又互补的角色。掌握这些概念,能科学决策资源利用、扩展策略及框架适用性。
我们从计算图开始,因为它是所有框架能力的结构基础。该抽象为自动微分、优化和硬件加速提供数学表示,是现代框架区别于简单数值库的核心。
计算图
计算图是框架将直观模型描述转化为高效硬件执行的核心抽象。它组织数学操作及其依赖,实现自动优化、并行化和硬件专用化。
计算图基础
计算图作为 ML 框架的关键抽象,解决了深度学习模型日益复杂带来的执行难题。随着模型规模和复杂度提升,跨硬件高效执行成为必需。计算图将高层模型描述转化为底层硬件执行,以有向无环图(DAG)17表示 ML 模型,节点为操作,边为数据流。DAG 抽象支持自动微分和跨硬件优化。
例如,节点可表示矩阵乘法,输入为两个矩阵(或张量),输出为一个矩阵(或张量)。如图 3 所示,DAG 计算 $z = x \times y$,各变量为数值。

实际 ML 模型远比此例复杂。见图 4,计算图结构涉及卷积、激活、池化、归一化等层的互联,执行前可优化。图中还展示了系统级交互,如内存管理和设备分配,静态图模式支持完整的预执行分析与资源分配。

层与张量
现代 ML 框架通过层与张量两大抽象实现神经网络计算。层是执行卷积、池化、全连接等操作的计算单元,每层有权重、偏置等内部状态,训练时不断更新。数据在层间流动,以张量形式存在,张量是不可变的数学对象,承载和传递数值。
层与张量的关系,类似传统编程中的操作与数据。层定义如何将输入张量转为输出张量,类似函数的输入输出。但层还需在训练中维护和更新参数。例如卷积层不仅定义卷积操作,还学习并存储最优卷积核。
框架自动化图构建极大提升了开发体验。开发者只需写 tf.keras.layers.Conv2D,框架自动构建卷积操作、参数管理和数据流的图节点,无需关心底层实现。
神经网络构建
计算图的威力远不止于基础层操作。激活函数是引入非线性的关键,成为图中的节点。ReLU、sigmoid、tanh 等函数对层输出张量进行变换,框架提供优化实现,开发者可自由试验不同非线性,无需关心底层细节。
现代框架进一步模块化,提供预配置的完整模型架构(如 ResNet、MobileNet),开发者可定制层结构,利用预训练权重实现迁移学习。
系统层面影响
基于前述计算图抽象,框架能在执行前分析和优化整个计算。显式的数据依赖表示支持自动微分和梯度优化。
更重要的是,图结构带来执行灵活性。相同模型定义可在不同硬件平台高效运行,框架自动处理操作映射、内存优化和并行执行。图结构还支持模型序列化,便于模型保存、共享和跨环境部署。
这些系统优势,使计算图远超简单的可视化工具。神经网络结构图仅用于架构展示,而计算图是底层数学操作和数据依赖的精确表示,是将直观模型设计转化为高效执行的关键。理解这一表示,能洞察框架如何将高层模型描述转化为硬件优化实现,让现代深度学习成为可能。
需区分计算图与神经网络结构图(如 MLP 节点与层),后者仅用于架构可视化,前者则是实现和训练网络所需的底层数学与数据依赖表示。
计算图的表达能力对框架设计和性能有深远影响。从系统角度看,计算图带来自动微分、数据依赖分析、并行潜力和硬件优化等关键能力。但计算图的威力,取决于其执行方式——这也是静态与动态图执行模型的根本区别。
预定义计算结构
静态计算图(TensorFlow 早期版本首创)采用“先定义后执行”模式。开发者需在执行前完整指定计算图结构。这一架构选择对系统性能和开发流程影响深远,后文将详细分析。
静态计算图将操作定义与执行彻底分离。定义阶段,所有数学操作、变量和数据流连接都显式声明并加入图结构。此时仅构建计算的完整规格,不做实际计算。框架内部生成所有操作及依赖的表示,待后续执行。
预定义结构带来强大系统优化能力。框架可分析完整结构,发现算子融合机会,消除冗余中间结果,内存流量可降 3-10 倍。内存需求可提前精确计算和优化,分配策略高效。静态图支持如 XLA[^fn-xla](加速线性代数)等编译框架,进行激进优化。图重写可消除大量冗余操作,硬件专用内核生成带来显著加速。这种抽象虽优雅,但对可表达计算有根本约束:静态图以牺牲控制流和动态计算灵活性换取性能。一旦验证,计算可多次高效复用,行为和性能高度可控。
下图展示了静态图的两阶段流程:先构建和优化完整计算图,再在执行阶段让数据流经图结构产生结果。这种分离让框架能在执行前充分分析和优化整个计算。

运行时自适应计算结构
动态计算图(PyTorch 推广)采用“定义即运行”模式。图结构在执行时构建,模型定义和调试更灵活。与静态图预分配内存不同,动态图在操作执行时分配内存,长时间任务易出现内存碎片。动态图以牺牲效率换取控制流表达灵活性,限制了编译器优化空间。无法在执行前分析完整计算,难以实现静态图的算子融合和图重写优化。
如图 6 所示,每步操作定义、执行、完成后再定义下一步。与静态图需预定义所有操作形成鲜明对比。操作定义即刻执行,结果可用于后续操作或调试。如此循环,直至所有操作完成。

动态图在需条件执行或动态控制流场景(如变长序列处理、复杂分支逻辑)表现优异。开发阶段可即时反馈,便于发现和修复计算流程问题。与命令式编程模式天然契合,开发者可在运行时检查和修改计算。研究开发阶段,动态图极大提升迭代速度和调试体验。
框架架构权衡
静态与动态计算图的架构差异,对 ML 系统设计和执行有多重影响。涵盖内存管理、设备利用、执行优化和调试等方面,决定系统效率和可扩展性。重点分析内存管理和设备分配,优化技术详见 第 8 章:AI 训练 ,便于后续深入理解优化与容错等复杂主题。
内存管理
计算图执行时需内存管理。静态图因结构预定义,可在执行前精确规划内存,框架能提前计算需求、优化分配、通过内存复用降低开销。结构化分配保证性能稳定,尤其适合资源受限环境(如移动、Tiny ML)。大模型需高效处理内存带宽(小模型 100GB/s,大语言模型数十亿参数超 1TB/s),内存规划对吞吐至关重要。
动态图则在操作执行时动态分配内存,灵活应对控制流和变长输入,但易导致内存开销高和碎片化。开发阶段,动态图便于快速迭代和调试,生产部署则需额外优化。内存带宽利用率低于 50% 时,碎片和访问模式不佳会显著影响性能。
设备分配
设备分配即将操作分派到 CPU、GPU、TPU 等硬件资源。静态图可在执行前详细分析,框架能将计算密集型操作映射到最优设备,最小化通信开销。适合专用硬件优化,性能提升显著。
动态图则在运行时分配设备,可自适应硬件状态或负载变化。但因缺乏完整图结构,难以充分优化设备利用,大规模或分布式场景易出现效率瓶颈。
更广泛影响
静态与动态图的权衡远超内存和设备。见表 1,架构影响优化潜力、调试能力、可扩展性和部署复杂度。更广泛影响详见 第 8 章:AI 训练 (训练流程)和 第 11 章:AI 加速 (系统优化)。
混合方案旨在开发阶段提供动态图灵活性,生产环境实现静态图性能优化。选型需结合项目需求,权衡开发速度、生产性能和系统复杂度。
| 方面 | 静态图 | 动态图 |
|---|---|---|
| 内存管理 | 精确分配规划,优化内存使用 | 灵活但分配效率较低 |
| 优化潜力 | 可全局优化计算图 | 仅能局部优化,受限于运行时 |
| 硬件利用 | 可生成高度优化的硬件专用代码 | 可能牺牲硬件专用优化 |
| 开发体验 | 需提前规划,调试难度大 | 调试更便捷,迭代速度快 |
| 调试流程 | 框架专用工具,堆栈追踪不连贯 | 标准 Python 调试(pdb、print、inspect) |
| 错误报告 | 执行时错误与定义脱节 | 堆栈追踪直指具体代码行 |
| 科研速度 | 迭代慢,需先定义后运行 | 快速原型和模型实验 |
| 运行时灵活性 | 计算结构固定 | 可自适应运行时条件 |
| 生产性能 | 大规模下性能更优 | 图构建有额外开销 |
| 与遗留代码集成 | 定义与执行分离较多 | 与命令式代码自然集成 |
| 内存开销 | 规划分配,开销低 | 动态分配,开销高 |
| 部署复杂度 | 结构固定,部署简单 | 需额外运行时支持 |
表 1:图计算模式:静态图预定义全部计算,便于优化;动态图运行时构建,灵活应对变长输入和控制流。两者影响执行效率和开发调试体验。
基于图的梯度计算实现
计算图不仅是执行计划,更是实现反向自动微分的核心数据结构。理解这一点,能洞察框架如何高效计算复杂神经网络的梯度。
前向传播时,框架构建计算图,每个节点代表操作,存储结果及梯度计算所需信息。该图不仅是可视化工具,而是实际内存中的数据结构。调用 loss.backward() 时,框架按图的逆拓扑顺序反向遍历,系统应用链式法则。
关键在于图结构编码了链式法则所需的全部依赖关系。图中每条边代表偏导数,反向遍历自动按链式法则组合偏导。前向构建计算历史,反向遍历即为累积梯度的图遍历算法。
这一设计让自动微分能扩展到百万参数网络,复杂度与操作数线性相关,而非变量数指数增长。图结构保证每次梯度计算只执行一次,共享子计算通过依赖跟踪自动处理。
自动微分
ML 框架需解决核心计算难题:高效、准确地计算复杂数学操作链的导数。这一能力让神经网络能通过梯度调整数百万参数,提升模型性能 [Baydin 2018]。
代码清单 1 展示了这一挑战的简单计算。
代码清单 1:自动微分:高效计算复杂函数梯度,是优化神经网络参数的关键。
def f(x):
a = x * x # 平方
b = sin(x) # 正弦
return a * b # 乘积
自动微分将函数分解为基本操作,逐步计算导数。以本例为例,AD 分三步:
- 计算
a = x * x(平方) - 计算
b = sin(x)(正弦) - 计算最终乘积
a * b
每步 AD 都有基本导数规则:
- 平方:
d(x²)/dx = 2x - 正弦:
d(sin(x))/dx = cos(x) - 乘积:
d(uv)/dx = u(dv/dx) + v(du/dx)
AD 跟踪操作组合,系统应用链式法则,精确计算整个计算的导数。PyTorch、TensorFlow 等框架实现后,能自动计算任意神经网络结构的梯度,是后续 第 8 章:AI 训练 训练算法和优化技术的基础。理解 AD 如何分解和跟踪计算,是后续深入其数学原理、系统架构和性能优化的前提。
前向与反向模式微分
自动微分有两大实现方式,各自效率、内存和适用场景不同。本节分析前向模式和反向模式 AD 的数学基础、实现结构、性能特性及在 ML 框架中的集成模式。
前向模式
前向模式 AD 在原始计算同时计算导数,跟踪输入变化如何影响输出。承接 第 7 章:AI 框架 的基础,前向模式类似手工求导,直观易懂。
见代码清单 2,展示前向模式工作原理。
代码清单 2:前向模式自动微分:在函数计算同时用乘积法则计算导数,展示输入变化如何影响输出。
def f(x): # 同时计算值和导数
# 步骤 1:x -> x²
a = x * x # 值:x²
da = 2 * x # 导数:2x
# 步骤 2:x -> sin(x)
b = sin(x) # 值:sin(x)
db = cos(x) # 导数:cos(x)
# 步骤 3:乘积法则
result = a * b # 值:x² * sin(x)
dresult = a * db + b * da # 导数:x²*cos(x) + sin(x)*2x
return result, dresult
前向模式通过“对偶数”同时跟踪数值和导数。代码清单 3 展示 x = 2.0 时的数值计算:
代码清单 3:前向模式:同时计算值和导数,展示如何跟踪结果及变化率。
x = 2.0 # 初始值
dx = 1.0 # 跟踪对 x 的导数
# 步骤 1:x²
a = 4.0 # (2.0)²
da = 4.0 # 2 * 2.0
# 步骤 2:sin(x)
b = 0.909 # sin(2.0)
db = -0.416 # cos(2.0)
# 最终结果
result = 3.637 # 4.0 * 0.909
dresult = 2.805 # 4.0 * (-0.416) + 0.909 * 4.0
实现结构
前向模式 AD 结构化计算,始终同时跟踪值和导数。见代码清单 4,每步操作都显式跟踪中间结果。
代码清单 4:前向模式 AD 结构:每步同时跟踪值和导数,突出前向模式自动微分的计算结构。
def f(x):
a = x * x
b = sin(x)
return a * b
框架执行前向模式时,每步都携带数值和导数信息。见代码清单 5:
代码清单 5:对偶跟踪:每步同时跟踪值和导数,展示前向模式自动微分的实际工作方式。
# 概念上,每步跟踪 (值,导数)
x = (2.0, 1.0) # 输入值及其导数
a = (4.0, 4.0) # x² 及其导数 2x
b = (0.909, -0.416) # sin(x) 及其导数 cos(x)
result = (3.637, 2.805) # 最终值和导数
前向传播导数信息由框架自动完成:1. 每个值都带导数信息 2. 每个操作都能处理值和导数 3. 信息随计算前向传播
这一模式与计算流程天然一致,适合单输入多输出场景,导数信息与数值同步前进。
性能特性
前向模式 AD 性能有独特模式,框架会据此选用不同 AD 策略。
前向模式每步都计算一次导数。单输入变量时,计算量约为原运算两倍。复杂度与操作数线性相关,适合简单计算。
但神经网络层如矩阵乘法,若需对所有权重求导,前向模式需对每个参数重复计算,可能成千上万次。前向模式效率取决于需导数的输入变量数。
前向模式内存需求较低,只需存储原值、单个导数和临时结果,复杂度不随计算复杂度增长。适合嵌入式、实时和内存带宽受限场景。
计算量随输入变量增长,内存消耗恒定,决定了框架选型权衡。前向模式适合少输入多输出场景,简单实现和资源可控性优于多次计算。
应用场景
前向模式 AD 虽非训练神经网络的主力,但在现代 ML 框架中有重要作用。其优势在于分析输入微小变化对网络行为的影响。数据科学家需分析模型为何做出某些预测,可能需研究单像素或特征变化对输出影响,见代码清单 6。
代码清单 6:敏感性分析:输入图像微小变化通过前向模式 AD 影响神经网络预测,便于调试和提升稳健性。
def analyze_image_sensitivity(model, image):
# 前向模式跟踪单像素变化
layer1 = relu(W1 @ image + b1)
layer2 = relu(W2 @ layer1 + b2)
predictions = softmax(W3 @ layer2 + b3)
return predictions
每层操作,前向模式同时跟踪值和导数,便于分析输入扰动如何影响最终预测。
神经网络解释也是重要应用。研究者生成显著性图或归因分数时,需计算每个输入对输出的影响,见代码清单 7。
代码清单 7:前向模式 AD:高效计算特征重要性,跟踪输入扰动对网络输出的影响。
def compute_feature_importance(model, input_features):
# 跟踪每个输入特征对输出的影响
hidden = tanh(W1 @ input_features + b1)
logits = W2 @ hidden + b2
# 前向模式高效计算 d(logits)/d(input)
return logits
理解这些应用,解释了为何 ML 框架保留前向模式能力。反向模式主导模型训练,前向模式则为特定分析任务提供优雅解决方案。
反向模式
反向模式自动微分是现代神经网络训练的计算核心。训练时,输出为标量(损失函数),需对数百万参数(权重)求导,反向模式对此极为高效。
代码清单 8 展示了反向模式结构。
代码清单 8:反向模式自动微分基础示例
def f(x):
a = x * x # 第一步:平方
b = sin(x) # 第二步:正弦
c = a * b # 第三步:乘积
return c
在此函数中,x 通过两条路径影响最终结果 c:一条是平方(a = x²),一条是正弦(b = sin(x))。求导时需同时考虑两条路径。
先做前向计算,见代码清单 9。
代码清单 9:前向传播:计算中间值,贡献最终输出。
x = 2.0 # 输入值
a = 4.0 # x * x = 2.0 * 2.0 = 4.0
b = 0.909 # sin(2.0) ≈ 0.909
c = 3.637 # a * b = 4.0 * 0.909 ≈ 3.637
接着反向传播,见代码清单 10,梯度从输出开始计算。
代码清单 10:反向传播:通过多条路径计算梯度,更新模型参数。此说明直接告知读者反向传播用于参数更新,是 ML 模型训练的核心。
#| eval: false
dc/dc = 1.0 # 输出对自身的导数为 1
# 乘法 c = a * b 的反向
dc/da = b # ∂(a*b)/∂a = b = 0.909
dc/db = a # ∂(a*b)/∂b = a = 4.0
# x 的两条路径贡献
# 路径 1:x -> x² -> c 贡献:2x * dc/da
# 路径 2:x -> sin(x) -> c 贡献:cos(x) * dc/db
dc/dx = (2 * x * dc/da) + (cos(x) * dc/db)
= (2 * 2.0 * 0.909) + (cos(2.0) * 4.0)
= 3.636 + (-0.416 * 4.0)
= 2.805
反向模式的优势在于,新增依赖路径时,前向模式需多次计算,反向模式只需一次反向遍历。神经网络中,每个权重都可能通过多条路径影响损失,反向模式能高效处理。
实现结构
反向模式在机器学习框架中的实现,需精心设计计算与内存管理。前向模式只需扩展每步计算,反向模式需记录前向过程以支持反向遍历。现代框架通过计算图和自动梯度累积18实现。
扩展前例为小型神经网络,见代码清单 11。
代码清单 11:反向模式:神经网络通过反向遍历层计算梯度。
def simple_network(x, w1, w2):
# 前向传播
hidden = x * w1 # 第一层乘法
activated = max(0, hidden) # ReLU 激活
output = activated * w2 # 第二层乘法
return output # 最终输出(未加损失)
前向传播时,框架不仅计算数值,还构建操作图并跟踪中间结果,见代码清单 12。
代码清单 12:前向传播:通过线性和非线性变换计算中间状态,生成最终输出。训练流程:将数据集分为训练、验证和测试集,确保模型稳健性和无偏评估。
x = 1.0
w1 = 2.0
w2 = 3.0
hidden = 2.0 # x * w1 = 1.0 * 2.0
activated = 2.0 # max(0, 2.0) = 2.0
output = 6.0 # activated * w2 = 2.0 * 3.0
代码清单 13 展示反向传播梯度计算步骤。
代码清单 13:反向传播:计算神经网络权重梯度,突出梯度如何反向传播更新参数。
d_output = 1.0 # 输出的导数
d_w2 = activated # d_output * d(output)/d_w2
# = 1.0 * 2.0 = 2.0
d_activated = w2 # d_output * d(output)/d_activated
# = 1.0 * 3.0 = 3.0
# ReLU 梯度:输入 > 0 时为 1,否则为 0
d_hidden = d_activated * (1 if hidden > 0 else 0)
# 3.0 * 1 = 3.0
d_w1 = x * d_hidden # 1.0 * 3.0 = 3.0
d_x = w1 * d_hidden # 2.0 * 3.0 = 6.0
本例说明实现要点:1. 框架需跟踪操作依赖 2. 中间值需为反向传播保留 3. 梯度按前向计算的逆拓扑顺序计算 4. 每步操作需有前向与反向实现
内存管理策略
反向模式实现的关键挑战之一是内存管理。与前向模式可随计算丢弃中间值不同,反向模式需保留前向结果以支持反向梯度计算。
代码清单 14 扩展神经网络例子,突出反向传播需保留中间激活。
代码清单 14:反向模式内存管理:训练时需存储中间值以支持反向传播梯度计算。
def deep_network(x, w1, w2, w3):
# 前向传播 - 必须存储中间结果
hidden1 = x * w1
activated1 = max(0, hidden1) # 反向需用
hidden2 = activated1 * w2
activated2 = max(0, hidden2) # 反向需用
output = activated2 * w3
return output
每个反向传播需用的中间值都要保留,直到反向遍历完成。网络越深,内存需求线性增长。典型深度网络处理一批图像时,激活存储可达数 GB。
框架采用多种策略优化内存。代码清单 15 展示一种方法。
代码清单 15:内存管理策略:训练涉及多层变换,需优化内存。检查点机制允许中间值在训练过程中释放,降低内存使用,同时通过说明:代码强调深度学习系统在内存管理与模型复杂度间的权衡。
def training_step(model, input_batch):
# 策略 1:检查点机制
with checkpoint_scope():
hidden1 = activation(layer1(input_batch))
# 框架可在此释放部分内存
hidden2 = activation(layer2(hidden1))
# 更精细的内存管理
output = layer3(hidden2)
# 策略 2:梯度累积
loss = compute_loss(output)
# 反向传播时优化内存
loss.backward()
现代框架自动平衡内存与计算速度。部分内存密集操作可在反向传播时重算中间值,而非全部存储。大规模训练场景下,内存与计算的权衡尤为重要。
优化技术
在机器学习框架中,反向模式自动微分采用了多种关键优化技术,以提升训练效率。对于大规模神经网络而言,这些优化对于突破计算和内存瓶颈至关重要。
现代框架实现了梯度检查点技术19,通过在计算与内存之间做权衡,显著降低内存消耗。下方代码清单 16 展示了网络的简化前向过程。
代码清单 16:前向传播:神经网络通过多层变换处理输入,最终输出结果,体现了深度学习架构的层次性。
def deep_network(input_tensor):
# 典型深度网络计算流程
layer1 = large_dense_layer(input_tensor)
activation1 = relu(layer1)
layer2 = large_dense_layer(activation1)
activation2 = relu(layer2)
# ... 更多层
output = final_layer(activation_n)
return output
框架并非保存所有中间激活值,而是选择性地在反向传播时重算部分值。代码清单 17 展示了框架如何实现内存节省,通常只保存每隔几层的激活。
代码清单 17:检查点机制:通过选择性保存中间激活值,降低前向过程的内存消耗。框架在存储与计算效率之间做平衡,优化模型训练。
# 检查点机制的概念表示
checkpoint1 = save_for_backward(activation1)
# 其他激活可在反向时重算
checkpoint2 = save_for_backward(activation4)
# 框架在存储与重算之间权衡
另一项关键优化是算子融合20。框架将常见的连续数学操作合并为单一运算,如矩阵乘法后接偏置加法,可融合为一个操作,减少内存传输并提升硬件利用率。
反向传播本身也可通过重排序计算以最大化硬件效率。例如卷积层的梯度计算,框架会实现专用的反向操作,充分利用现代硬件能力,而非直接翻译数学定义。
这些优化协同作用,使得大规模神经网络训练变得可行。没有这些技术,许多现代架构的训练成本将高得难以承受,无论是内存还是计算时间。
框架中的自动微分实现
将自动微分集成到机器学习框架,需要在灵活性、性能和易用性之间做系统性权衡。PyTorch、TensorFlow 等现代框架通过高级 API 暴露自动微分能力,底层则实现了复杂的机制。
框架通过多种接口向用户呈现自动微分。PyTorch 的典型用法见代码清单 18。
代码清单 18:自动微分接口:PyTorch 在神经网络执行时自动跟踪操作,实现高效反向传播。训练过程需精细管理梯度和模型参数,自动微分对性能至关重要。
# PyTorch 风格自动微分
def neural_network(x):
# 框架自动跟踪操作
layer1 = nn.Linear(784, 256)
layer2 = nn.Linear(256, 10)
# 每步操作自动跟踪
hidden = torch.relu(layer1(x))
output = layer2(hidden)
return output
# 训练循环展示自动微分集成
for batch_x, batch_y in data_loader:
optimizer.zero_grad() # 清除旧梯度
output = neural_network(batch_x)
loss = loss_function(output, batch_y)
# 框架自动处理所有微分机制
loss.backward() # 自动反向传播
optimizer.step() # 参数更新
表面上代码很简洁,实际上框架需:
- 跟踪前向过程所有操作
- 构建并维护计算图
- 管理中间值内存
- 高效调度梯度计算
- 与硬件加速器对接
这种集成远不止基础训练。框架还需支持高阶梯度(如二阶导数)和混合精度训练。代码清单 19 展示了二阶梯度的计算。
代码清单 19:高阶梯度:二阶梯度揭示参数变化对一阶梯度的影响,是高级优化技术的基础。
# 计算高阶梯度
with torch.set_grad_enabled(True):
# 一阶梯度
output = model(input)
grad_output = torch.autograd.grad(output, model.parameters())
# 二阶梯度
grad2_output = torch.autograd.grad(
grad_output, model.parameters()
)
系统工程突破
自动微分的数学基础早已确立,但在 ML 框架中的工程实现是重大的系统工程突破。理解这一点,有助于认识自动微分为何推动了深度学习革命。
在自动化系统出现前,梯度计算需手动推导并编码每个操作的梯度。即使是简单的全连接层,也要分别写前向和反向函数,跟踪中间值,确保几十步操作的数学正确。架构复杂后,如卷积、注意力机制或自定义操作,手工实现极易出错且耗时巨大。
自动微分的突破不在于数学创新,而在于软件工程。现代框架需处理内存管理、操作调度、数值稳定性和跨硬件优化,同时保证数学正确性。比如一次矩阵乘法,梯度计算因输入需求、张量形状、硬件能力和内存约束而异,自动微分系统能自动处理这些差异,让研究者专注于模型架构而非梯度实现。
更重要的是,自动微分系统让架构创新成为可能。像 Transformer 这样的现代架构,涉及数百个复杂依赖操作。手工推导和调试这些组件的梯度,需数月时间。自动微分系统能高效、正确地计算所有梯度,让新架构快速试验和迭代。
系统视角解释了深度学习为何在框架成熟后加速发展:不是数学变了,而是软件工程让数学得以大规模应用。前述计算图提供了基础设施,自动微分系统则赋予了智能,能高效遍历计算图。
梯度计算中的内存管理
自动微分的内存需求,源于一个基本要求:反向传播时,必须记住前向过程发生了什么。这个看似简单的要求,给 ML 框架带来了有趣挑战。传统程序可随用即弃中间结果,AD 系统则需完整保留计算历史。
代码清单 20 展示了神经网络前向过程的内存需求。
代码清单 20:前向传播:神经网络顺序计算并存储中间结果,为反向传播准确计算梯度做准备。
def neural_network(x):
# 每步操作都需保留结果
a = layer1(x) # 反向需用
b = relu(a) # 需保留 relu 输入
c = layer2(b) # 反向需用
return c
每次网络处理数据,操作不仅产生输出,还带来内存负担。layer1 的乘法需记住输入,反向时计算梯度要用。即使简单的 relu,也需跟踪哪些输入为负,才能正确反向传播。网络越深,内存需求越大,见代码清单 21。
代码清单 21:内存累积:深度神经网络每层都需保留反向传播所需信息,网络越深,内存需求越大。
# 更深的网络,内存需求逐层累积
hidden1 = large_matrix_multiply(input, weights1)
activated1 = relu(hidden1)
hidden2 = large_matrix_multiply(activated1, weights2)
activated2 = relu(hidden2)
output = large_matrix_multiply(activated2, weights3)
现代框架自动管理这些内存。它们跟踪每个中间值的生命周期,确保梯度计算所需时仍在内存中。训练大模型时,内存管理与数值计算同样重要。框架会在中间值不再需要时及时释放内存,保证内存使用虽大但尽量高效。
生产系统集成挑战
自动微分集成到 ML 框架,带来重要的系统层面考量,影响框架设计和训练性能。大规模神经网络训练时,这些考量尤为突出。
代码清单 22 展示了典型训练循环的系统交互。
代码清单 22:训练流程:ML 工作流将数据集分为训练、验证和测试集,确保模型开发的稳健性和无偏评估。
def train_epoch(model, data_loader):
for batch_x, batch_y in data_loader:
# 数据在 CPU 与加速器间移动
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
# 前向传播构建计算图
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
# 反向传播计算梯度
loss.backward()
optimizer.step()
optimizer.zero_grad()
这个简单循环背后,隐藏着复杂的系统交互。AD 系统需与内存分配器、设备管理器、操作调度器和优化器协同。每次梯度计算都可能触发设备间数据移动、内存分配和加速器内核调度。
代码清单 23 展示了现代硬件加速器上的 AD 操作调度。
代码清单 23:并行计算:神经网络中的操作可并行执行,需同步结果以高效组合。Via The code
def parallel_network(x):
# 这些操作可并行执行
branch1 = conv_layer1(x)
branch2 = conv_layer2(x)
# 合并前需同步
combined = branch1 + branch2
return final_layer(combined)
AD 系统不仅需跟踪梯度计算依赖,还要优化硬件利用率。它需判断哪些梯度计算可并行,哪些需等待。依赖跟踪贯穿前向和反向过程,形成复杂的调度问题。
现代框架在保证用户接口简洁的同时,自动处理这些系统层面问题。底层会做复杂的操作调度、内存分配和数据移动决策,同时确保通过计算图正确计算梯度。
这些系统层面的考量,体现了现代框架自动化处理的工程复杂性,让开发者能专注于模型设计而非底层实现细节。
框架特定的微分策略
虽然自动微分原理在各框架间一致,但具体实现方式差异很大,直接影响科研工作流和开发体验。理解这些差异,有助于开发者选型并解释实际性能表现。
PyTorch 的动态图自动微分系统
PyTorch 通过动态 tape 机制实现自动微分,在执行时构建计算图。这种方式直接支持前述动态图的科研工作流和调试能力。
代码清单 24 展示了 PyTorch 的梯度跟踪,前向执行时自动构建 tape。
代码清单 24:PyTorch Autograd 实现:前向过程动态构建 tape,支持透明梯度计算和即时调试。
import torch
# PyTorch 在执行时构建计算图
x = torch.tensor(2.0, requires_grad=True)
y = torch.tensor(3.0, requires_grad=True)
# 每步操作加入动态 tape
z = x * y # 创建 MulBackward 节点
w = z + x # 创建 AddBackward 节点
loss = w**2 # 创建 PowBackward 节点
# 计算图在前向结束后才存在
print(f"Computation graph: {loss.grad_fn}")
# 输出:<PowBackward0 object>
# 反向传播遍历动态构建的图
loss.backward()
print(f"dx/dloss = {x.grad}") # 可即时获取梯度
print(f"dy/dloss = {y.grad}")
PyTorch 的动态机制对科研工作流有多重优势。无需预定义计算图,支持自然的 Python 控制流(如条件、循环)。反向传播后梯度立即可用,便于交互式调试和实验。
动态 tape 机制也天然支持变长计算。代码清单 25 展示了 PyTorch 如何适应运行时决定的计算图。
代码清单 25:动态长度计算:PyTorch 的 autograd 能自然处理变长计算模式,支持根据输入特性自适应模型结构。
def dynamic_model(x, condition):
# 计算图结构随运行时条件变化
hidden = torch.relu(torch.mm(x, weights1))
if condition > 0.5: # 运行时决定图结构
# 更复杂的计算路径
hidden = torch.relu(torch.mm(hidden, weights2))
hidden = torch.relu(torch.mm(hidden, weights3))
output = torch.mm(hidden, final_weights)
return output
# 不同调用生成不同计算图
result1 = dynamic_model(input_data, 0.3) # 较短图
result2 = dynamic_model(input_data, 0.7) # 较长图
# 两者都能正确反向传播
这种灵活性带来一定的内存和计算开销。PyTorch 必须在反向传播完成前保留整个计算图,且梯度计算无法利用全局优化。
TensorFlow 的静态图优化
TensorFlow 传统自动微分采用静态图分析,实现激进优化。虽然 TensorFlow 2.x 默认即时执行,理解静态图有助于把握灵活性与优化的权衡。
代码清单 26 展示了 TensorFlow 静态图微分,分离了图构建与执行。
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# 图定义阶段 - 不实际计算
x = tf.placeholder(tf.float32, shape=())
y = tf.placeholder(tf.float32, shape=())
# 符号式定义计算
z = x * y
w = z + x
loss = w**2
# 图构建时符号化梯度计算
gradients = tf.gradients(loss, [x, y])
# 执行阶段 - 实际计算
with tf.Session() as sess:
# 同一图可高效多次执行
for step in range(1000):
grad_vals, loss_val = sess.run(
[gradients, loss], feed_dict={x: 2.0, y: 3.0}
)
# 编译内核优化执行
静态图方式支持强大的优化,动态系统无法实现。TensorFlow 可分析完整梯度计算图,应用算子融合、内存布局优化和并行调度。大模型可提升 2-3 倍性能。
静态图也便于高效重复执行。编译后同一图可多批次处理,生产环境下极为高效。
但该方式调试复杂,灵活性有限。TensorFlow 现代版本通过 eager 执行和 tf.function 编译兼顾两者。
JAX 的函数式微分
JAX 采用函数式编程和程序变换实现自动微分,体现了其函数式哲学,详见后续框架对比章节。
代码清单 27 展示了 JAX 的变换式微分。
代码清单 27:JAX 函数式微分:程序变换支持前向和反向微分,数学透明且易组合。
import jax
import jax.numpy as jnp
# 纯函数定义
def compute_loss(params, x, y):
z = x * params["w1"] + y * params["w2"]
return z**2
# JAX 变换函数而非跟踪操作
grad_fn = jax.grad(compute_loss) # 返回梯度函数
value_and_grad_fn = jax.value_and_grad(compute_loss)
# 多种微分模式
forward_grad_fn = jax.jacfwd(compute_loss) # 前向模式
reverse_grad_fn = jax.jacrev(compute_loss) # 反向模式
# 变换可自然组合
batched_grad_fn = jax.vmap(grad_fn) # 向量化梯度
jit_grad_fn = jax.jit(grad_fn) # 编译梯度
# 不可变参数执行
params = {"w1": 2.0, "w2": 3.0}
gradients = grad_fn(params, 1.0, 2.0)
print(f"Gradients: {gradients}")
JAX 的函数式方法有独特优势。相同函数可变换为不同微分模式、执行模式和优化策略。前向、反向微分同样易用,可按问题特性选最优。
变换式方法支持强大的组合模式。代码清单 28 展示了多重变换的组合。
# 组合多重变换
def model_step(params, batch_x, batch_y):
predictions = model_forward(params, batch_x)
return compute_loss(predictions, batch_y)
# 通过组合构建复杂训练函数
batch_grad_fn = jax.vmap(jax.grad(model_step), in_axes=(None, 0, 0))
compiled_batch_grad_fn = jax.jit(batch_grad_fn)
parallel_batch_grad_fn = jax.pmap(compiled_batch_grad_fn)
# 结果:向量化、编译、并行化的梯度函数
# 仅通过函数变换实现
函数式方法要求不可变数据结构和纯函数,但支持数学推理和程序变换,状态式系统难以实现。
科研生产力与创新加速
这些实现差异直接影响科研效率和开发流程。PyTorch 的动态机制加速实验和调试,但生产部署需优化。TensorFlow 静态图性能优异,但开发流程更结构化。JAX 的函数式变换支持强大数学抽象,但需函数式编程习惯。
理解这些权衡,有助于研究者按需求选型,并解释开发与部署过程中的性能表现。动态灵活性、静态优化和函数式变换的选择,取决于项目优先级:快速实验、生产性能或数学优雅。
自动微分系统设计原则
自动微分系统将导数的数学概念转化为高效实现。通过前向和反向模式分析,框架在数学精度与计算效率间做平衡,支撑现代神经网络训练。
AD 系统的实现揭示了 ML 框架的关键设计模式。代码清单 29 展示了其中一种模式。
代码清单 29:AD 机制:框架跟踪操作,实现高效反向传播。示例强调跟踪中间计算对有效梯度计算的重要性,是 ML 系统自动微分的核心。
def computation(x, w):
# 框架跟踪操作
hidden = x * w # 反向需存储
output = relu(hidden) # 跟踪激活模式
return output
这一简单计算体现了几个基本概念:
- 跟踪操作以便求导
- 管理中间值内存
- 系统协调高效执行
如代码清单 30 所示,现代框架在简洁接口背后抽象了这些复杂性,同时保证高性能。
代码清单 30:最简 API:通过跟踪前向计算和高效梯度计算,简化自动微分,助力模型优化。
loss = model(input) # 前向跟踪计算
loss.backward() # 高效反向模式 AD
optimizer.step() # 利用已计算的梯度
自动微分系统的高效性,源于对多重需求的精细平衡。既要保留足够计算历史以保证梯度准确,又要控制内存消耗;既要高效调度操作,又要保证正确性;既要灵活,又要优化性能。
理解这些系统,对框架开发者和实践者都至关重要。开发者需实现高效 AD 以支撑现代深度学习,实践者则需理解 AD 的能力与约束,指导模型设计与训练。
自动微分为基于梯度的学习提供了计算基础,其实际实现高度依赖框架对数据的组织与操作方式。接下来将讨论支撑高效计算和内存管理的数据结构,这些结构不仅要支持 AD,还要为多样化硬件平台提供高效访问模式。
框架架构的未来方向
自动微分系统为神经网络训练提供了计算基础,但并非孤立运行。它们需要高效的数据表示和操作方式。接下来将讨论 ML 框架用于组织和处理信息的数据结构。
回顾前述数值处理示例(代码清单 31)。
代码清单 31:层级变换:神经网络通过顺序操作处理输入,权重和激活函数共同影响最终预测。数值在神经网络计算中流动,突出权重乘法和激活函数的作用。Via Data Flow: The code
def neural_network(x):
hidden = w1 * x # x 的具体类型?
activated = relu(hidden) # hidden 如何存储?
output = w2 * activated # 乘法类型?
return output
这些操作看似简单,实则引发重要问题。框架如何表示这些值?如何组织数据以高效计算和自动微分?如何结构化数据以充分利用现代硬件?
下一节将探讨框架如何通过专用数据结构(尤其是张量)回答这些问题,这些结构是现代 ML 计算的基础构件。
数据结构
机器学习框架通过专用数据结构扩展计算图,将高层计算与实际实现连接起来。这些结构有两个核心作用:一是作为 ML 模型数值数据的容器,二是管理数据在不同内存空间和设备间的存储与移动。
计算图定义了操作的逻辑流程,数据结构则决定了操作如何在内存中访问和处理数据。既要为模型计算组织数值,又要处理内存管理和设备分配的复杂性,框架才能将数学运算高效映射到多样化计算平台。
ML 框架的有效性高度依赖底层数据组织。理论可用数学公式表达,但实际实现需精心设计数据组织、存储和操作方式。现代模型训练和推理需处理海量数据,高效的数据访问和内存利用对多硬件平台至关重要。
框架的数据结构需在三方面表现优异。首先是高性能,支持快速数据访问和高效内存利用,优化缓存布局和内存层级间的数据传输。其次是灵活性,适应多种模型架构和训练方式,支持不同数据类型和精度。第三是为开发者提供清晰直观的接口,底层自动处理复杂的内存管理和设备分配。
这些数据结构是数学与工程的桥梁。ML 运算如矩阵乘法、卷积、激活函数,决定了数据组织的基本要求。结构需保证数值精度和稳定性,同时支持常见操作和自动梯度计算,还要应对现实计算约束,如有限内存带宽、硬件能力差异和分布式需求。
数据结构设计的优劣,直接影响框架能力。设计不当会导致内存浪费,限制模型规模和批次能力,或成为性能瓶颈,甚至让编程易错。设计合理则能自动优化内存和计算、支持硬件扩展、并为开发者提供高效接口,助力新技术快速落地。
通过具体数据结构分析,可见框架如何通过设计和优化应对这些挑战。这对 ML 系统开发者至关重要,无论是新模型开发、现有模型优化,还是框架能力扩展。分析从张量抽象开始,这是现代 ML 框架的基础构件,随后探讨参数管理、数据集处理和执行控制等专用结构。
张量
ML 框架以张量为核心处理和存储数值数据。神经网络的每一步计算,从输入数据处理到模型权重更新,都是在张量上进行。训练批次、卷积网络的激活图、反向传播的参数梯度,均以张量形式存在。统一的张量表示,让框架能实现一致的数据操作接口,并针对不同硬件架构优化运算。
张量结构与维度
张量是将标量、向量、矩阵推广到更高维度的数学对象。维度形成自然层级:标量是零维张量,向量是一维,矩阵是二维。更高维张量通过嵌套结构扩展,如图 7 所示,三维张量可视为矩阵堆叠。因此,向量和矩阵是张量的特殊情况(1D、2D)。

三维张量:高阶张量通过嵌套结构扩展标量、向量和矩阵的概念。图中三维张量为矩阵堆叠,能表达复杂多维数据关系。高于二维的张量是图像处理、自然语言处理等领域表达多维数据的基础。

在 ML 框架中,张量不仅有数学定义,还需满足现代系统的实际需求。数学张量是多维数组,具备变换属性,机器学习则要求高效计算。框架需在数学精度与计算性能间做权衡。
框架张量结合了数值数据数组和计算元数据。维度结构(shape)从简单向量、矩阵到高维数组,能表达如图像批次、序列模型等复杂数据。维度信息对操作校验和优化至关重要,如矩阵乘法需 shape 元数据验证兼容性并决定最优计算路径。
内存布局是张量设计的难点。张量抽象为多维数据,但物理内存是线性的。stride 模式解决了多维索引与线性地址的映射问题。stride 影响张量操作的内存访问模式和性能。图 5 用 2×3 张量展示了行主序和列主序布局及 stride 计算。
![图 9: <strong>张量内存布局</strong>:2×3 张量可按行主序(C 风格)或列主序(Fortran 风格)存储。stride 定义每维移动时需跳过的元素数,便于框架计算 tensor[i,j] 的地址:base_address + i×stride[0] + j×stride[1]。布局选择显著影响缓存性能和计算效率。](/f78c7471ad0993e352f904eed876286c79655e7c.svg)
理解这些内存布局模式对框架性能优化至关重要。行主序(NumPy、PyTorch)按行存储,行操作缓存友好;列主序(部分 BLAS 库)按列存储,优化列操作。stride 编码了布局信息:2×3 张量行主序,下一行需跳过 3 个元素(stride[0]=3),下一列跳过 1 个(stride[1]=1)。
stride 与硬件内存层级对齐,可最大化缓存效率和带宽利用,最优布局能实现理论带宽的 80-90%(现代 GPU 通常 100-500GB/s),而不佳布局仅能利用 20-30%。
类型系统与精度
张量实现通过类型系统控制数值精度和内存消耗。ML 标准为 32 位浮点(float32),兼顾精度与效率。现代框架支持多种数值类型:整数用于索引和嵌入,16 位浮点适合移动端高效部署,8 位整数用于专用硬件快速推理。
数值类型影响模型行为和计算效率。训练通常需 float32 保证梯度稳定,推理可用低精度(int8、甚至 int4),降低内存和提升速度。混合精度训练则用 float32 累加关键值,大部分计算用低精度,兼顾性能和精度。
不同类型间转换需谨慎管理。不同类型张量操作需显式转换规则,保证数值正确。转换有计算成本,也可能损失精度。框架提供类型转换能力,但需开发者保证跨操作的数值精度。
设备与内存管理
异构计算的兴起,改变了 ML 框架对张量操作的管理。现代框架需在 CPU、GPU、TPU 等多种加速器间无缝运行,每种设备计算能力和内存特性不同。张量需高效在设备间移动,保证计算一致性。
设备分配直接影响计算性能和内存利用。张量在设备间移动有延迟和带宽成本。多设备张量副本可加速计算,但增加总内存消耗,需精细管理副本一致性。框架需实现复杂的内存管理系统,跟踪张量位置,协调数据移动,权衡这些因素。
内存管理系统动态跟踪设备内存,优化数据传输。当操作需不同设备上的张量时,框架要么移动数据,要么调整计算分布。决策过程与计算图执行和操作调度深度集成。设备内存压力、数据传输成本和计算负载都影响分配。现代系统需优化 PCIe Gen4(CPU-GPU 通信 32GB/s)、NVLink(GPU-GPU 600GB/s)、网络互联(跨节点 10-100Gbps)等带宽。
设备分配与内存管理不仅是数据移动。框架需预判未来计算需求,高效预取数据,管理多设备碎片化,处理内存超载。需内存管理系统与操作调度器紧密协作,尤其在多设备并行或分布式训练场景。高效预取策略可通过计算与数据移动重叠,隐藏延迟,即使单次传输仅达峰值带宽的 10-20%,也能保持持续吞吐。
领域专用数据组织
张量虽是 ML 框架的基础,但并非唯一结构。框架还依赖一系列专用数据结构,满足数据处理、参数管理和执行协调等需求,保障从原始数据到硬件优化执行的全流程高效顺畅。
数据集结构
数据集结构负责将原始输入数据转化为适合 ML 计算的格式。它们将多样数据源与模型所需张量抽象自动连接,实现数据读取、解析和预处理自动化。
数据集结构需高效利用内存,应对远超内存容量的输入数据。例如训练大规模图像数据集时,结构需从磁盘加载图片,解码为张量格式,实时做归一化和增强。框架实现数据流、缓存和洗牌机制,保证预处理批次稳定供给,无瓶颈。
数据集结构设计直接影响训练性能。设计不当会造成 GPU 或加速器数据吞吐瓶颈。优化结构可利用 CPU 多核、磁盘 IO 和内存传输并行,满载加速器。现代训练管道需实现 1-10GB/s 数据加载速率,匹配 GPU 计算能力,需优化存储 IO 和预处理流程。框架通过并行加载、批次预取和高效数据格式(如优化格式可将加载开销从 80% 降至 10% 以下)实现。
分布式训练场景下,数据集结构还需协调节点间数据分配,保证每个 worker 处理不同数据子集,洗牌等操作一致,避免重复计算,支持多设备多机扩展。
参数结构
参数结构存储 ML 模型的数值参数,包括神经网络层的权重、偏置,以及批归一化统计量、优化器状态等辅助数据。与数据集不同,参数在训练和推理全程持久存在。
参数结构需兼顾高效存储与快速访问。例如卷积神经网络需为滤波器、全连接层和归一化层分配参数,各自有独特形状和内存对齐需求。框架将参数组织为紧凑结构,最小化内存消耗,支持高效读写。
分布式训练时,参数结构需高效管理多设备内存 [Li 2014]。框架可在 GPU 间复制参数并在 CPU 保持主副本,实现一致性和低延迟梯度更新。参数结构常用内存共享技术减少重复,如梯度和优化器状态原地存储节省内存。参数同步通信成本巨大,如 7B 参数模型在 8 GPU 间同步需传输约 28GB 梯度(FP32),25Gbps 网络下需 9 秒以上,故框架实现梯度压缩和高效通信(如 ring all-reduce)。
参数结构还需适应多种精度需求。训练多用 32 位浮点,推理和大规模训练则用 16 位甚至 8 位。框架实现类型转换和混合精度管理,兼顾优化和数值准确性。
执行结构
执行结构协调计算在硬件上的执行,保证操作高效且符合设备约束。它们与计算图紧密协作,决定数据流动和中间结果内存分配。
执行结构主要负责内存管理。训练或推理时,中间计算如激活图或梯度会消耗大量内存。执行结构动态分配和释放内存缓冲,避免碎片化,最大化硬件利用。例如深度网络可复用激活图内存,降低整体内存占用。
执行结构还负责操作调度,保证计算顺序和硬件利用最优。在 GPU 上,可重叠计算与数据传输,隐藏延迟提升吞吐。多设备运行时,需同步依赖计算,保证一致性无延迟。
分布式训练更复杂,执行结构需管理多节点数据和计算,包括计算图分区、梯度同步和数据重分配。高效执行结构能最小化通信开销,实现硬件线性扩展。图 10 展示了分布式训练如何在加速器网格上多维并行,提升吞吐。

编程与执行模型
开发者“编写”代码的方式(编程模型)与框架“执行”代码的方式(执行模型)密切相关。理解这一关系,有助于把握不同框架的设计权衡,以及这些决策如何影响开发体验和系统性能。统一视角揭示了编程范式如何直接映射到执行策略,形成框架特性,影响调试流程和生产优化。
ML 框架主要有三种编程与执行范式:命令式编程配合即时执行、符号式编程配合图执行,以及混合 JIT 编译。三者在开发灵活性与系统优化能力间各有侧重。
声明式模型定义与优化执行
符号式编程涉及先构建抽象计算表达,再执行。该范式直接对应图执行,框架在执行前构建完整计算图。符号式编程与图执行的紧密结合,带来强大优化机会,但要求开发者以完整计算流程为思维方式。
符号式编程中,变量和操作以符号表示,表达式直到显式执行才被计算,框架可在运行前分析和优化计算图。
代码清单 32 展示了符号式编程示例。
代码清单 32:符号计算:符号表达式先构建不立即计算,便于优化后再执行。
# 构建表达式但不立即计算
weights = tf.Variable(tf.random.normal([784, 10]))
input = tf.placeholder(tf.float32, [None, 784])
output = tf.matmul(input, weights)
# 独立的执行阶段
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
result = sess.run(output, feed_dict={input: data})
该方式让框架能对整个计算做全局优化,适合部署场景。静态图可序列化、跨环境执行,提升可移植性。预定义图也便于高效并行执行。但调试较难,错误多在执行时暴露,动态修改图结构也较繁琐。
交互式开发与即时执行
命令式编程采用传统方式,操作遇到即执行。该范式直接对应即时执行,操作在调用时立即计算。命令式编程与即时执行的结合,形成动态计算图,灵活性高但优化空间有限。
此范式下,计算随代码执行,类似大多数通用编程语言。代码清单 33 展示了即时执行示例。
代码清单 33:命令式执行:每步操作在代码运行时立即计算,动态计算图逐步推进。
# 每步表达式立即计算
weights = torch.randn(784, 10)
input = torch.randn(32, 784)
output = input @ weights # Computation occurs now
即时执行模式直观,符合常见编程习惯,易用性高。错误可在执行时立即发现和修复,调试简单。动态图可随时调整,适合变结构任务,如强化学习或序列建模。但运行时动态构建图有计算开销,框架难以全局优化。
即时执行适合研究、交互开发和快速原型。数据科学家和研究者能快速迭代,立即看到结果。许多现代 ML 框架(如 TensorFlow 2.x 和 PyTorch)默认采用即时执行,因其对开发者友好。
性能与开发效率权衡
符号式与命令式编程模型的选择,显著影响框架对系统特性如内存管理和优化策略的处理。
性能考量
符号式编程让框架能预先分析完整计算图,实现高效内存分配,如中间结果复用。全局视角支持高级优化,如算子融合、自动微分和硬件专用内核选择,生产环境性能极佳。
命令式编程则需运行时决策内存和优化,操作即刻执行,无法全局分析。虽牺牲部分性能,但开发灵活性和即时反馈更强。编程模型选择还影响开发体验,尤其是模型开发和调试。
开发与调试
符号式编程要求开发者以完整计算图思考,调试需额外步骤,如 TensorFlow 1.x 需用 session 和 feed_dict 检查中间结果,开发流程较慢。
命令式编程调试更直接,操作即刻执行,开发者可随时检查张量值和形状,便于实验和问题定位,适合快速原型和迭代开发。
权衡管理
项目需求决定编程模型选择。符号式适合性能和优化要求高的生产部署,命令式则适合科研和开发灵活性需求。
运行时编译的自适应优化
现代框架认识到编程范式选择不必二选一。混合方案通过 JIT 编译结合两者优势,开发者可用命令式风格编写,框架自动将高频代码路径编译为优化静态图,生产部署性能更优。
JIT 编译是编程与执行模型的现代融合。开发者用自然命令式代码开发和调试,框架可自动将关键路径转为优化静态图,兼顾开发体验和执行性能。
典型混合方案如 TensorFlow 的 tf.function 装饰器,将命令式 Python 函数编译为优化图执行;PyTorch 的 torch.jit.script 可将动态模型编译为静态图;JAX 的 jit 变换自动实现图编译和优化。
这些混合方案表明现代框架已超越传统符号式与命令式分野,编程模型与执行模型可解耦,实现开发效率与系统性能兼得。
执行模型技术实现
明确三大编程 - 执行范式后,可分析其实现特性和性能影响。每种范式在内存管理、优化能力和开发流程上有特定权衡,直接影响系统性能和开发效率。
即时执行
即时执行是最直接、最易理解的执行范式。操作在代码调用时立即执行,类似传统命令式编程语言,开发者熟悉。
代码清单 34 展示了即时执行,操作即刻计算。
代码清单 34:即时执行:操作在代码调用时立即计算,开发体验更直观灵活。
import tensorflow as tf
x = tf.constant([[1.0, 2.0], [3.0, 4.0]])
y = tf.constant([[1, 2], [3, 4]])
z = tf.matmul(x, y)
print(z)
在这段代码中,每行顺序执行。创建张量 x 和 y 时,它们立即在内存中实例化。矩阵乘法 tf.matmul(x, y) 立刻计算,结果存入 z。打印 z 时,立即看到计算结果。
即时执行提供多重优势。反馈及时,便于开发者轻松检查中间值,调试直观。代码结构灵活,计算图可随执行变化,适合动态任务。
但即时执行也有权衡。操作即刻执行,框架难以全局优化,复杂模型或大数据集性能不如优化范式。
即时执行特别适合科研、交互开发和快速原型。数据科学家和研究者能快速试验,立即见效。许多现代 ML 框架(如 TensorFlow 2.x 和 PyTorch)默认采用即时执行,因其开发者友好。
图执行
图执行(静态图执行)采用不同方式。开发者先定义完整计算图,再分步执行。
代码清单 35 展示了 TensorFlow 1.x 风格的图执行。
代码清单 35:图执行:先定义计算图,再用 session 执行,突出 TensorFlow 1.x 的定义与执行分离。
import tensorflow.compat.v1 as tf
tf.disable_eager_execution()
# 定义计算图
x = tf.placeholder(tf.float32, shape=(2, 2))
y = tf.placeholder(tf.float32, shape=(2, 2))
z = tf.matmul(x, y)
# 执行计算图
with tf.Session() as sess:
result = sess.run(
z,
feed_dict={x: [[1.0, 2.0], [3.0, 4.0]], y: [[1, 2], [3, 4]]},
)
print(result)
在这段代码中,我们先定义计算结构。placeholder 操作创建输入数据的计算图节点,tf.matmul 创建表示矩阵乘法的节点。定义阶段不实际计算。
计算在创建会话并调用 sess.run() 时执行。这时提供实际输入数据,框架拥有完整图,可在执行前优化。
图执行的优势在于,框架可预见全部计算,进行全局优化,复杂模型性能更优。定义后,图可轻松保存并跨环境部署,适合高效重复执行。
但图执行也有权衡。开发者需以图构建为思维方式,调试较难,错误多在执行时暴露,动态计算实现复杂。
图执行适合生产环境,性能和部署一致性要求高,常用于大规模分布式训练和高吞吐推理场景。
动态代码生成与优化
JIT 编译是即时执行与图执行的折中。该范式结合即时执行的灵活性与图优化的性能。
代码清单 36 展示了 PyTorch 的 JIT 编译用法。
代码清单 36:PyTorch JIT 编译:编译脚本函数以高效复用,展示即时编译如何在 ML 工作流中兼顾灵活性与性能。
import torch
@torch.jit.script
def compute(x, y):
return torch.matmul(x, y)
x = torch.randn(2, 2)
y = torch.randn(2, 2)
# 首次调用编译函数
result = compute(x, y)
print(result)
# 后续调用用优化版本
result = compute(x, y)
print(result)
在这段代码中,我们定义了一个 compute 函数,并用 @torch.jit.script 装饰。这个装饰器告诉 PyTorch 用 JIT 编译器编译这个函数。首次调用 compute 时,PyTorch 分析这个函数,进行优化并生成高效的机器代码。这个编译过程在函数执行前完成,故称“即时编译”。
后续对 compute 的调用将使用优化版本,特别是对于复杂操作或重复调用,性能提升显著。
JIT 编译兼顾开发灵活性和运行性能。开发者可用自然命令式代码,关键部分自动优化。
这种方法的优势在于,它保持了即时执行的即时反馈和直观调试,同时为计算密集型的关键部分提供了性能提升。JIT 编译还可以根据实际使用的特定数据类型和形状来调整优化,可能比静态图编译出更高效的代码。
然而,JIT 编译也有其局限性。首次执行编译的开销可能导致初次调用变慢。一些复杂的 Python 结构可能无法被 JIT 编译,需要开发者了解哪些代码可以被有效优化。
JIT 编译在需要开发灵活性和性能的场景中非常有用,尤其是在研究快速迭代和生产大规模训练时。许多现代 ML 框架都集成了 JIT 编译,以提供开发者友好的同时又能实现性能优化,如表 2 所示。该平衡体现在学习曲线和运行时行为,既有即时反馈又有性能提升。表格突出 JIT 编译如何弥合命令式编程的易用性与图执行的性能,尤其在内存使用和优化范围上。
| 方面 | 即时执行 | 图执行 | JIT 编译 |
|---|---|---|---|
| 方式 | 操作遇到即计算 | 先构建完整计算计划再执行 | 运行时分析代码,生成优化版本 |
| 内存使用 | 计算过程中保留所有中间结果 | 全局规划数据流优化内存 | 根据实际执行模式自适应内存使用 |
| 优化范围 | 仅限局部操作模式 | 全局优化整个计算链 | 结合运行时分析和定向优化 |
| 调试方式 | 计算任意点可检查值 | 需在图中设置监控点 | 初始运行原始行为,后续优化 |
| 速度与灵活性 | 灵活性优先于速度 | 性能优先于灵活性 | 平衡灵活性与性能 |
分布式执行
随着机器学习模型规模和复杂度不断提升,单设备训练已难以满足需求。大模型需要巨大的计算能力和内存,而海量数据集则要求高效的多机处理。为应对这些挑战,现代 AI 框架内置了分布式执行支持,可将计算任务分散到多块 GPU、TPU 或分布式集群上。通过抽象并行执行的复杂性,这些框架让开发者能够高效扩展机器学习工作负载,同时保持易用性。
分布式执行的核心策略有两种:数据并行21和模型并行22。数据并行让多台设备在不同数据子集上训练同一个模型副本,实现更快收敛且不增加单设备内存需求。模型并行则将模型结构拆分到多台设备上,使超大模型能够突破单设备内存限制。模型并行有多种变体,详见后续 第 8 章:AI 训练 章节。无论哪种方式,这两类分布式策略都是高效训练现代机器学习模型的基础。随着模型规模扩展到 第 9 章:高效 AI 所述的级别,分布式执行的实现也需依赖 第 11 章:AI 加速 介绍的硬件加速技术。
数据并行
数据并行是分布式训练中最常用的方法,可让机器学习模型在多台设备间高效扩展。每个计算设备保存一份相同的模型副本,但处理独立的训练数据子集,如图 11 所示。每轮训练后,各设备计算的梯度会同步,统一更新模型参数,保证所有副本一致。这样,模型可并行学习更大数据集,而单设备内存需求不变。

数据并行将训练数据分配到多台设备,模型副本一致,实现大数据集的高效加速。AI 框架内置了数据分发、梯度同步和性能优化机制。PyTorch 的 DistributedDataParallel (DDP) 自动管理多 GPU/节点训练,TensorFlow 提供 tf.distribute.MirroredStrategy 实现多 GPU 梯度同步,JAX 的 pmap() 可在多加速器间并行执行并优化通信。框架自动处理梯度聚合,超大模型同步梯度时需 10-100Gbps 网络带宽。例如,1750 亿参数模型在 1024 GPU 间同步梯度(FP32)每步需通信约 700GB,需高效算法实现近线性扩展。
这些框架自动处理同步与通信,让分布式训练对研究者和工程师都易于使用,无需手动管理底层并行细节。实现方式虽有差异,但目标一致:让多设备高效训练,无需用户手动并行化。
模型并行
数据并行适用于大多数 ML 任务,但部分模型过大,无法装入单设备内存。模型并行通过将模型结构拆分到多台设备上,解决这一限制。与数据并行每台设备保存完整模型不同,模型并行将层、张量或特定操作分配到不同硬件,如下图所示(图 12)。这样可训练超大模型,突破单设备内存瓶颈。

模型并行通过将模型不同部分分配到多台设备,解决内存瓶颈,支持超大模型训练。AI 框架提供结构化 API 简化模型并行,屏蔽分区和通信复杂性。PyTorch 支持流水线并行(torch.distributed.pipeline.sync),让不同 GPU 处理模型的连续层,保证高效执行流。TensorFlow 的 TPUStrategy 可自动将大模型分配到 TPU 核心,优化高带宽互联。DeepSpeed、Megatron-LM 等框架扩展 PyTorch,实现高级模型分片技术,如张量并行,将模型权重拆分到多设备,降低内存开销。张量并行通常需 100-400GB/s 设备间带宽,流水线并行则因激活传输频率低,带宽需求仅 10-50Gbps。
模型并行有多种变体,适合不同架构和硬件。具体权衡和应用详见 第 8 章:AI 训练 ,图 7 展示了并行策略对比。无论采用哪种方式,AI 框架都需高效管理分区、调度计算和优化通信,确保超大模型可扩展训练。

核心操作体系
机器学习框架采用三层操作体系,将高层模型描述转化为高效硬件计算。图 8 展示了硬件抽象操作管理计算平台复杂性,基础数值操作实现数学计算,系统级操作协调资源与执行。

硬件抽象操作
硬件抽象操作是底层基础,屏蔽平台细节,保证高效计算。该层负责计算内核管理、内存系统抽象和多平台执行控制。
计算内核管理
计算内核管理负责为不同硬件架构选择和调度最优数学操作实现。需维护多种核心操作实现和复杂调度逻辑。例如,矩阵乘法可用现代 CPU 的 AVX-512 指令、NVIDIA GPU 的 cuBLAS ,或 AI 加速器专用指令。内核管理器需根据输入规模、数据布局和硬件能力选择实现,并处理无专用实现时的回退路径。
内存系统抽象
内存系统抽象管理数据在复杂内存层级中的流动。需处理多种内存类型(注册、锁定、统一)及其访问模式。数据布局常需在硬件偏好格式间转换,如行主序与列主序、交错与平面图像格式。内存系统还需管理对齐要求(CPU 通常 4 字节,部分加速器 128 字节),并处理多执行单元访问同一数据时的缓存一致性。
执行控制
执行控制操作协调多执行单元和内存空间的计算。包括管理执行队列、事件依赖和异步操作。现代硬件支持多执行流并行,如 GPU 独立流或 CPU 线程池。执行控制器需管理这些流、同步点和依赖顺序,并提供硬件故障的错误处理和恢复机制。
基础数值操作
在硬件抽象层之上,框架实现基础数值操作,兼顾数学精度与计算效率。通用矩阵乘法(GEMM)是 ML 计算的主力,遵循 C = $\alpha$AB + $\beta$C,其中 A、B、C 为矩阵,$\alpha$、$\beta$为缩放因子。
GEMM 实现需多种优化技术,如分块提升缓存效率(将矩阵分为适合缓存的小块)、循环展开提升指令并行度、针对不同矩阵形状和稀疏模式的专用实现。例如,全连接层用常规稠密 GEMM,卷积层则用专用 GEMM 变体,利用输入局部性。
除 GEMM 外,框架还需高效实现 BLAS 操作,如向量加法(AXPY)、矩阵 - 向量乘法(GEMV)、各类归减操作。AXPY 通常受内存带宽限制,GEMV 需平衡内存访问与计算效率。
元素级操作也是关键,包括基础算术(加、乘)和超越函数(指数、对数、三角函数)。虽然概念简单,但可通过向量化和算子融合显著优化。例如,多步元素级操作可融合为单一内核,降低内存带宽需求。激活函数和归一化层常处理大量数据,效率至关重要。
现代框架还需支持多种数值精度。训练多用 32 位浮点保证稳定性,推理可用 16 位甚至 8 位低精度。框架需在多种格式下高效实现,同时保证精度。
系统级操作
系统级操作在计算图和硬件抽象基础上,管理整体计算流程和资源利用,包括操作调度、内存管理和资源优化。
操作调度利用前述计算图结构,决定执行顺序。静态图可提前分析全部依赖,动态图则需运行时处理。调度器还需支持条件操作和循环等动态控制流。
内存管理实现复杂的资源分配和释放策略。不同数据类型需不同管理方式。模型参数需全程持久,可能需专用内存类型。中间结果生命周期由操作图限定,如激活值仅反向传播时需用。内存管理器用引用计数自动清理、内存池减少分配开销、工作区管理临时缓冲。还需处理长时间训练中的内存碎片。
资源优化整合调度和内存决策,最大化系统性能。关键优化如梯度检查点,部分中间结果丢弃并在反向时重算,用计算换内存。优化器还需管理并发执行流,平衡负载并保证依赖。多实现操作时,需根据运行时条件选择最优算法,如根据矩阵形状和系统负载选择乘法策略。
这些操作层级基于 第 7 章:AI 框架 介绍的计算图,实现高效执行并屏蔽实现复杂性。层级间互动决定系统性能,也为后续 第 10 章:模型优化 和 第 11 章:AI 加速 的高级优化技术奠定基础。
在梳理了框架核心能力后,接下来将探讨这些能力如何通过开发接口和架构设计,转化为实际开发体验。框架架构决定了底层计算如何通过 API 和抽象层暴露给开发者,实现易用性与性能的平衡。
框架架构
基础概念提供了计算能力,实际框架使用则依赖架构接口将这些能力高效暴露给开发者。框架架构将前述能力(计算图、执行模型、优化操作)组织为结构化层级,服务于不同开发流程。理解这些架构选择,有助于开发者高效利用框架并按需选型。
API 与抽象层
ML 框架的 API 层是开发者与框架能力的主要接口。该层需在易用性、灵活性和高性能之间做平衡。
现代框架 API 实现多层抽象以满足不同需求。底层 API 直接暴露张量操作和计算图构建,支持自定义复杂计算,如代码清单 37 所示。
代码清单 37:手动张量操作:用 PyTorch 底层 API 实现自定义计算,展示复杂变换的灵活性。
import torch
# 手动张量操作
x = torch.randn(2, 3)
w = torch.randn(3, 4)
b = torch.randn(4)
y = torch.matmul(x, w) + b
# 手动梯度计算
y.backward(torch.ones_like(y))
在此基础上,框架提供更高层 API,将常见模式封装为可复用组件。神经网络层即为典型,如卷积、全连接层等高层抽象,开发者无需手动操作张量,见代码清单 38。
代码清单 38:中层抽象:用层级组件构建神经网络,高层模型建立在基础张量操作之上,实现高效开发。
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3, 64, kernel_size=3)
self.fc = nn.Linear(64, 10)
def forward(self, x):
x = self.conv(x)
x = torch.relu(x)
x = self.fc(x)
return x
最高层则实现完整工作流自动化。代码清单 39 展示了 Keras 的高层模型定义,自动化训练流程。
代码清单 39:高层模型定义:用 Keras 定义卷积神经网络,层级堆叠实现特征提取和分类。训练流程:自动化训练,编译模型、指定优化器和损失函数,批量训练。
from tensorflow import keras
model = keras.Sequential(
[
keras.layers.Conv2D(
64, 3, activation="relu", input_shape=(32, 32, 3)
),
keras.layers.Flatten(),
keras.layers.Dense(10),
]
)
# 自动化训练流程
model.compile(
optimizer="adam", loss="sparse_categorical_crossentropy"
)
model.fit(train_data, train_labels, epochs=10)
API 层级体现了框架设计的基本权衡。底层 API 灵活度高但需专业知识,高层 API 提升开发效率但限制实现选择。框架需在不同抽象层间提供清晰路径,支持开发者按需混用。
这些 API 层级是开发者与框架能力的接口,但只是完整开发体验的一部分。完整体验还依赖于围绕核心框架的工具、库和资源生态,覆盖整个机器学习生命周期。
框架生态系统
ML 框架将核心能力组织为多个组件,协同提供完整开发与部署环境。这些组件形成抽象层级,使框架既适合高层模型开发,也能高效底层执行。理解组件间互动,有助于开发者选型和高效使用,尤其是在支持完整 ML 生命周期(从数据预处理 第 6 章:数据工程 到训练 第 8 章:AI 训练 再到部署 第 13 章:机器学习运维 )。这种生态系统模式将 第 3 章:深度学习基础 的理论基础与 第 2 章:机器学习系统 的生产需求连接起来。
核心库
每个 ML 框架的核心是基础库,构成所有其他组件的基础。这些库实现了张量操作等基本构件,是数值计算的主力。为性能优化,常用底层语言和硬件专用优化,实现如矩阵乘法等神经网络核心运算。
这些计算原语支持更高级能力。核心库实现自动微分,能高效计算复杂函数的梯度,是神经网络优化的基础。实现涉及复杂的图操作和符号计算,屏蔽了梯度计算的底层复杂性。
在此基础上,核心库还提供预实现的神经网络层,如多种网络层类型。开发者可直接复用这些组件,专注于高层模型设计,无需重复底层实现。优化算法也常内置,进一步简化开发流程。
这些能力集成形成了完整开发环境。代码清单 40 展示了实际应用场景。
代码清单 40:训练流程:ML 工作流将数据集分为训练、验证和测试集,确保模型开发稳健性和无偏评估。
import torch
import torch.nn as nn
# 创建简单神经网络
model = nn.Sequential(nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 1))
# 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 前向、损失计算与反向传播
x = torch.randn(32, 10)
y = torch.randn(32, 1)
y_pred = model(x)
loss = loss_fn(y_pred, y)
loss.backward()
optimizer.step()
该示例展示了核心库如何为模型创建、损失计算和优化提供高层抽象,底层细节自动处理。组件无缝集成,体现了核心库作为框架生态基础的作用。
扩展与插件
核心库提供基础功能,现代 ML 框架的强大在于可扩展性。扩展和插件拓展了框架能力,满足专业需求并吸收最新研究进展。领域专用库如计算机视觉、自然语言处理,提供预训练模型、专用数据增强和任务层。
性能优化也是扩展的重要方向。硬件加速插件让框架利用 GPU、TPU 等专用硬件,极大提升计算速度,并支持不同硬件后端的无缝切换,是现代 ML 工作流可扩展性和灵活性的关键。
随着模型和数据规模增长,分布式计算扩展也变得重要。这些工具支持多设备、多机训练,自动处理数据并行、模型并行和节点间同步,是大规模 ML 问题的必备。
为支持研发过程,框架还集成了可视化和实验追踪扩展。可视化工具实时展示训练过程和模型行为,支持交互式调试。实验追踪扩展帮助管理复杂的研究流程,系统记录和对比不同模型配置和超参数。
集成开发与调试环境
除了核心框架和扩展,开发工具生态进一步提升了框架的实用性和普及度。交互式开发环境如 Jupyter notebook 已成为 ML 工作流标配,支持快速原型开发和代码、文档、输出一体化。许多框架为这些环境提供专用扩展,提升开发体验。
ML 系统的复杂性需要专用开发支持。调试和性能分析工具解决了模型开发的独特挑战。专用调试器可检查训练和推理过程中的模型内部状态,性能分析工具识别执行瓶颈,指导优化。这些工具对高效可靠的 ML 系统开发至关重要。
项目复杂度提升后,版本控制集成变得重要。支持模型权重、超参数和训练数据的版本管理,有助于迭代开发和协作,保证可复现性。
最后,部署工具简化了从开发到生产的过渡。包括模型压缩、格式转换和与服务基础设施集成,帮助模型从实验环境顺利进入实际应用。
系统集成
从开发环境到生产部署,ML 框架需应对系统集成挑战。系统集成关注 ML 框架在实际环境中的落地,涵盖与更广泛软件和硬件生态的集成难题和考量。
硬件集成
高效硬件集成对优化 ML 模型性能至关重要。现代框架需适应从高性能 GPU 集群到资源受限边缘设备的多样计算环境。
首先是加速计算平台。GPU 加速方面,TensorFlow 和 PyTorch 支持 NVIDIA CUDA 平台,实现训练和推理的显著加速。TensorFlow 对 Google TPU 也有原生支持,进一步提升特定任务性能。
分布式计算场景下,框架需高效管理多设备和多节点,通过高级协调抽象实现。数据并行需模型副本间 all-reduce 通信,框架实现 ring all-reduce 算法,通信复杂度 O(N),高带宽互联(如 InfiniBand 100-400Gbps)可达理论带宽的 85-95%。模型并行需分区间点对点通信,前后向同步,带宽不足时通信开销可达总训练时间的 20-40%。大规模训练必然遇到故障:Google 报告 TPU pod 训练每几小时就有内存、硬件或网络故障。现代框架通过弹性训练和检查点机制应对,支持动态集群扩展和定期保存模型状态。Horovod23 和 DeepSpeed 等框架抽象了分布式训练复杂性,优化通信模式,保证高带宽利用率。
边缘部署方面,框架提供轻量化版本,优化移动和物联网设备。TensorFlow Lite、PyTorch Mobile 提供模型压缩和优化工具,保证在资源有限、功耗受限设备上的高效执行。
框架基础设施依赖
ML 框架集成到现有软件栈面临独特挑战和机遇。数据处理管道接口是关键,框架常与 Apache Spark、Beam 等大数据工具对接,实现数据流与训练环境的无缝连接。
容器技术如 Docker 已成为 ML 工作流标配,保证开发与生产环境一致性。Kubernetes 是 ML 工作负载编排的主流选择,支持复杂部署的可扩展性和可管理性。
框架还需与数据库、消息队列和 Web 服务等企业系统集成。例如 TensorFlow Serving 提供高性能推理服务,易于嵌入微服务架构。
生产环境集成要求
ML 模型生产部署需多方面考量。模型服务策略需兼顾性能、可扩展性和资源效率,涵盖批量预测和实时推理。
生产扩展常用横向扩展推理服务器、预测缓存和多版本负载均衡。TensorFlow Serving、TorchServe 提供内建扩展解决方案。
监控和日志对生产 ML 系统至关重要,包括性能指标、概念漂移检测和输入输出审计。Prometheus、Grafana 常与 ML 服务系统集成,提供全面监控。
端到端 ML 流程管理
端到端 ML 管道管理需协调数据准备、模型训练、部署和监控各环节。MLOps 实践将 DevOps 原则引入 ML 工作流。
CI/CD 已被适配到 ML 流程,实现模型测试、验证和自动部署。Jenkins、GitLab CI 可扩展为 ML 专用流水线,构建健壮的自动化流程。
自动化模型重训练和更新也是关键,需系统自动用新数据重训、评估并无缝更新生产模型。Kubeflow 等框架可自动化这些流程。图 9 展示了 DAG(有向无环图)任务编排,自动化数据处理和训练。
ML 资产版本控制(数据、模型结构、超参数)对可复现和协作至关重要。DVC、MLflow 等工具专为 ML 版本管理设计。

主流框架平台分析
在梳理了核心概念、架构和生态组件后,接下来分析这些原则在实际框架中的落地。ML 框架架构复杂,业界涌现多种框架,但只有少数成为标准。本节分析主流框架,探讨其设计哲学如何转化为实际开发工具。
TensorFlow 生态系统
TensorFlow 由 Google Brain 团队开发,2015 年 11 月 9 日开源,采用数据流图实现数值计算,广泛用于各类 ML 应用。
TensorFlow 体现了面向生产的设计哲学。作为训练与推理框架,内置了从模型创建、训练到部署的全流程功能,如图 16 所示。随着发展,TensorFlow 生态已扩展为多种“变体”,支持不同平台 ML 应用。
- TensorFlow Core :主包,开发者主要使用,支持模型定义、训练和部署,内含高层 API tf.keras 。
- TensorFlow Lite :面向移动、嵌入和边缘设备的轻量部署,支持模型压缩和预训练模型优化。
- TensorFlow Lite Micro :面向微控制器,极低资源需求,无需操作系统或动态内存,仅用数 KB 内存。
- TensorFlow.js :JavaScript 库,支持浏览器和 Node.js 端训练与部署,支持模型格式转换。
- TensorFlow Edge Devices (Coral) :Google 边缘硬件平台,支持 Edge TPU 加速。
- TensorFlow Federated (TFF) :支持分布式数据的联邦学习,无需数据集中化即可训练模型。
- TensorFlow Graphics :支持 3D 形状和点云等图形任务的深度学习库。
- TensorFlow Hub :可复用模型组件库,支持迁移学习和模型组合。
- TensorFlow Serving :生产环境推理和部署框架,支持模型版本管理和动态更新。
- TensorFlow Extended (TFX) :生产级 ML 流程平台,涵盖数据验证、预处理、训练、验证和服务。

生产级部署
实际生产系统证明框架选择直接影响系统性能。优化常带来 4-10 倍延迟降低和 2-5 倍成本节省,包括量化、算子融合和硬件加速。
但这些优化需大量工程投入,定制算子实现、验证和性能调优通常需 4-12 周。框架选择是系统工程决策,远超 API 偏好,影响整个优化和部署流程。
详细生产部署案例、优化技术和量化权衡见 第 13 章:机器学习运维 ,系统性分析运维约束和部署策略。
PyTorch
与 TensorFlow 的生产优先不同,PyTorch 由 Facebook AI Research 开发,在学术界和研究领域广受欢迎。其设计哲学强调易用性、灵活性和动态计算,契合科研和实验的迭代需求。
PyTorch 的研究优先体现在动态图系统。与 TensorFlow 静态图不同,PyTorch 在执行时动态构建计算图(define-by-run),模型设计直观,调试方便,支持标准 Python 控制流。动态图支持变长输入和复杂结构,执行和检查即时。
PyTorch 与其他框架共享基础抽象,如张量为核心数据结构,CUDA 集成支持 GPU 加速。autograd 系统自动跟踪操作,实现梯度优化。
JAX
JAX 由 Google Research 开发,定位于高性能数值计算和前沿 ML 研究。与 TensorFlow 静态图和 PyTorch 动态执行不同,JAX 核心是函数式编程和变换组合。
JAX 兼容 NumPy,自动微分和即时编译,科学 Python 开发者易于上手,且具备强大优化能力。JAX 可微分原生 Python/NumPy 函数,支持循环、分支和递归,向量化和 JIT 编译能力突出。
JAX 编译策略比 TensorFlow 更依赖 XLA,优化 Python 代码到多种硬件。函数式编程采用纯函数和不可变数据,代码可预测且易于优化。JAX 的变换(grad、vmap、pmap)支持自动微分、向量化和并行,功能强大,区别于命令式框架。
平台性能量化分析
表 3 对 TensorFlow、PyTorch、JAX 三大框架做简要对比。三者虽目标相似,但设计哲学和技术实现有本质差异。
| 方面 | TensorFlow | PyTorch | JAX |
|---|---|---|---|
| 图类型 | 静态(1.x),动态(2.x) | 动态 | 函数式变换 |
| 编程模型 | 命令式(2.x),符号式(1.x) | 命令式 | 函数式 |
| 核心数据结构 | 张量(可变) | 张量(可变) | 数组(不可变) |
| 执行模式 | 即时(2.x 默认)、图执行 | 即时 | 即时编译 |
| 自动微分 | 反向模式 | 反向模式 | 前向与反向模式 |
| 硬件加速 | CPU、GPU、TPU | CPU、GPU | CPU、GPU、TPU |
| 编译优化 | XLA:3-10 倍加速 | TorchScript:2 倍 | XLA:3-10 倍加速 |
| 内存效率 | GPU 利用率 85% | GPU 利用率 82% | GPU 利用率 91% |
| 分布式扩展性 | 1024 GPU 效率 92% | 效率 88% | 1024 GPU 效率 95% |
这些架构差异体现在编程范式和 API 设计。下例展示同一简单神经网络(10 输入到 1 输出线性层)在三大框架下的实现,揭示设计哲学。
框架对比:Hello World
下方展示同一简单神经网络在主流框架下的语法差异:
# PyTorch - 动态、Python 风格 import torch.nn as nn class SimpleNet(nn.Module): def __init__(self): super().__init__() self.fc = nn.Linear(10, 1) def forward(self, x): return self.fc(x) # TensorFlow/Keras - 高层 API import tensorflow as tf model = tf.keras.Sequential( [tf.keras.layers.Dense(1, input_shape=(10,))] ) # JAX - 函数式 import jax.numpy as jnp from jax import random def simple_net(params, x): return jnp.dot(x, params["w"]) + params["b"] key = random.PRNGKey(0) params = { "w": random.normal(key, (10, 1)), "b": random.normal(key, (1,)), }
PyTorch 采用面向对象设计,显式继承 nn.Module,结构与执行分离,动态图支持灵活控制流和调试。
TensorFlow/Keras 用声明式编程,层级组合,Sequential API 自动管理连接、权重初始化和前向流程,兼容即时执行和生产优化。
JAX 强调函数式和不可变数据24,参数显式传递,模型函数无状态25,支持自动向量化26、即时编译27和自动微分,函数纯粹28,便于数学推理和安全变换。
框架设计哲学
ML 框架不仅有技术规格,更体现了设计哲学,反映开发者优先级和应用场景。理解这些哲学,有助于开发者按需选型,影响开发效率和系统性能。
研究优先:PyTorch
PyTorch 体现了研究优先哲学,重视开发体验和实验灵活性,优先即时执行、原生 Python 控制流和计算细节暴露,便于快速原型和调试,学术界采用广泛。
可扩展与生产优化:TensorFlow
TensorFlow 优先生产部署和可扩展性,体现 Google 大规模 ML 系统经验。强调静态图优化(XLA 编译),通过算子融合和硬件专用代码提升性能。内置生产工具(Serving、TFX),支持分布式部署和服务。高层抽象如 Keras 优先可靠性,API 演进注重兼容和稳定。
数学变换与可组合性:JAX
JAX 采用函数式哲学,强调数学纯粹和程序变换。不可变数组和纯函数支持自动向量化(vmap)、并行(pmap)、微分(grad),无隐藏状态。JAX 提供通用变换,分离计算与执行策略,兼容 NumPy,函数式约束带来强大优化能力。
框架哲学与项目需求匹配
哲学差异决定实际选型。探索性研究团队适合 PyTorch,生产部署和扩展优先可选 TensorFlow,算法开发和数学推理可选 JAX。
理解哲学有助于预判框架能力和未来演进。PyTorch 将持续优化开发体验,TensorFlow 注重生产工具和扩展,JAX 专注程序变换和数学优化。
框架哲学选择影响项目开发路径,从代码结构到调试到部署。团队按优先级和工作方式选型,通常比单纯技术规格更能保证长期成功。
部署环境专用框架
除主流框架哲学外,ML 框架已针对不同计算环境深度定制。随着应用扩展到边缘、移动和微控制器,专用框架需求愈发突出。
这种多样化源于部署异构性。框架专用化即针对特定环境优化性能、效率和功能。不同平台资源、功耗和场景差异巨大,专用化至关重要。
专用化带来碎片化挑战,业界通过标准化应对。ONNX29 成为主流模型格式,实现框架间互操作。
标准化满足实际工作流需求。ONNX 提供框架无关的模型结构和参数描述,支持多硬件运行时,无需手动转换或重实现。
实际应用中,ONNX 支持重要生产流程。例如,研究团队用 PyTorch 动态图训练模型,导出 ONNX 后用 TensorFlow Serving 部署。也可转为 ONNX 在边缘设备用 ONNX Runtime 执行。图 11 展示了互操作性,随着生态扩展愈发重要。组织常需在不同阶段利用各框架优势。
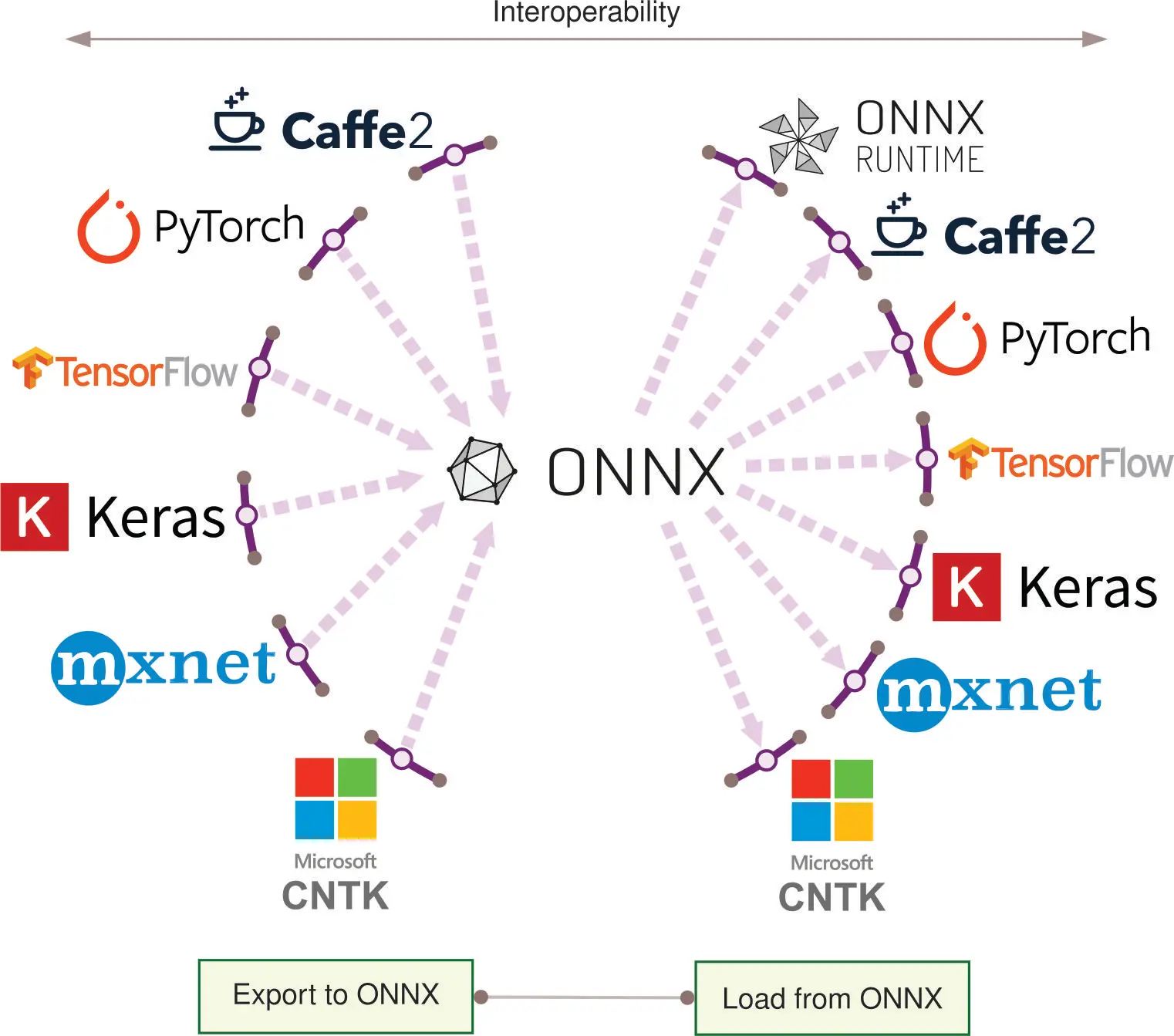
多样化的部署目标决定了机器学习框架在不同环境下的专用化策略。机器学习的部署环境深刻影响了框架的设计与演进。云端机器学习环境依赖高性能服务器,拥有丰富的计算资源,适合复杂的运算任务。边缘侧机器学习则运行在计算能力中等的设备上,通常以实时处理为优先。移动端机器学习需适应智能手机和平板等设备的性能差异和能耗约束。TinyML 则面向极度受限的微控制器等设备,这类硬件资源极为有限。
这些环境约束推动了各自独特的架构决策。每种环境都带来独特挑战,直接影响框架的设计取舍。云端框架强调可扩展性与分布式计算;边缘框架聚焦低延迟推理与对多样硬件的适配;移动端框架注重能效与对设备特性的集成;TinyML 框架则极致优化资源以适应极端受限的环境。
本节将系统梳理主流机器学习框架如何针对上述环境进行适配,剖析其应对各类挑战的技术手段与设计选择,突出不同领域框架专用化的权衡与优化。
分布式计算平台优化
云端环境拥有最丰富的计算资源,使得框架可以优先考虑可扩展性和复杂优化,而不必过度受限于资源。云端机器学习框架是一类高度复杂的软件基础设施,专为利用云环境的海量算力而设计。它们主要在三个方面实现专用化:分布式计算架构、大规模数据与模型管理、以及与云原生服务的深度集成。
首先,分布式计算是云端 ML 框架的核心专长。这类框架实现了先进的任务划分与多机/多 GPU 协同机制,支持在大规模数据集上训练超大模型。例如,TensorFlow 和 PyTorch 作为云端主流框架,都具备强大的分布式训练能力。TensorFlow 1.x 采用静态计算图,天然适合分布式执行;PyTorch 则以动态图为特色,支持更灵活的分布式训练策略。
其次,云端框架针对超大规模数据和模型进行了优化。它们的数据结构设计充分考虑了单机难以承载的规模。例如,TensorFlow 和 PyTorch 均以可变 Tensor 作为核心数据结构,便于高效地对大数据集进行原地操作。JAX 作为新兴框架,则采用不可变数组,结合函数式编程理念,在分布式场景下带来新的优化空间。
第三,云端框架与云原生服务的集成能力极强。它们支持自动资源扩展、无缝访问云存储、集成云端监控与日志系统等。例如,TensorFlow 2.x 和 PyTorch 默认采用动态图执行模式,便于与云服务集成和调试。JAX 的 JIT 编译则能针对特定硬件自动优化计算流程,提升云端性能。
硬件加速是云端 ML 框架的重要特性。主流框架均支持 CPU 和 GPU,TensorFlow 与 JAX 还原生支持 Google TPU。 NVIDIA TensorRT 是专为 GPU 推理优化的工具,具备层融合、精度校准、内核自动调优等高级功能,可极大提升 NVIDIA GPU 上的推理吞吐量。这些硬件加速选项让云端框架能充分发挥多样算力资源的优势。
34 TensorRT:NVIDIA 推出的推理优化库,专为深度学习应用最大化吞吐量、最小化延迟而设计。通过层融合、精度校准和内核自动调优等技术,实现 2-5 倍推理加速,是 NVIDIA 硬件生产部署的关键工具。
自动微分能力在云端尤为重要,因为大规模模型参数众多,训练复杂。TensorFlow 和 PyTorch 主要采用反向模式自动微分,JAX 同时支持正向与反向微分,在某些大规模优化场景下更具优势。
这些专用化能力让云端 ML 框架能够充分利用云基础设施的可扩展性和算力,但也带来了部署和运维的复杂性,通常需要专业知识才能发挥其全部潜力。云端框架的可扩展性和集成能力,使其非常适合大规模科研项目、企业级 ML 应用及需要海量算力的场景。
本地处理与低延迟优化
从资源充裕的云端转向边缘部署,框架设计面临全新约束。边缘 ML 框架专为边缘计算环境设计,强调靠近数据源、低延迟和有限算力。典型代表有 TensorFlow Lite 和 Edge Impulse 。这类框架主要应对三大挑战:实时推理优化、异构硬件适配、资源受限下的高效运行。这些挑战与第 9 章“高效 AI”中的技术密切相关,也需要第 11 章“AI 加速”所述的硬件加速策略。
实时推理优化是边缘 ML 框架的核心特性。不同框架采用不同的执行模式和计算图类型。例如,TensorFlow Lite 采用静态计算图以优化推理性能,而 PyTorch Mobile 则保留动态图能力,提升模型结构灵活性但牺牲部分性能。静态与动态图的选择,体现了边缘框架在优化潜力与模型灵灵活性之间的权衡。
异构硬件适配对边缘部署至关重要。边缘 ML 框架在继承云端硬件加速能力的基础上,更关注边缘专用硬件。例如,TensorFlow Lite 支持移动 GPU 和 Edge TPU 加速, ARM Compute Library 针对 ARM 处理器深度优化。这通常涉及自定义算子实现和底层硬件专用优化。
资源受限下的高效运行也是边缘框架专用化的重要方面。许多边缘框架采用量化张量作为主要数据结构,用低精度(如 8 位整型)代替 32 位浮点数,显著降低内存和计算需求。这些量化技术及剪枝、知识蒸馏等优化方法将在第 10 章“模型优化”详细介绍。自动微分能力在边缘框架中通常被简化或移除,以减小模型体积、提升推理速度。
边缘 ML 框架还常集成模型版本管理与在线更新功能,便于无中断部署新模型。有些框架支持有限的端侧学习,使模型能在本地数据上自适应,同时保护数据隐私。相关技术将在 第 14 章“端侧学习” 和第 15 章“安全与隐私”中深入探讨。
边缘 ML 框架的这些专用化能力,使其能在资源受限环境下实现高性能推理,拓展了 AI 在弱云连接或强实时需求场景下的应用空间。但要高效利用这些框架,需充分考虑目标硬件规格和应用需求,在模型精度与资源利用之间取得平衡。
资源受限设备优化
移动端环境在边缘计算基础上引入了更多约束,尤其是能效和用户体验。移动 ML 框架专为智能手机和平板等设备上的模型部署与推理设计,代表有 TensorFlow Lite 和 Apple Core ML 。这类框架主要应对计算资源有限、功耗受限和硬件多样性等挑战,专注于端上推理优化、能效提升和与移动硬件/传感器的集成。
移动 ML 框架的端上推理优化,通常需在计算图类型和执行模式间权衡。例如,TensorFlow Lite 采用静态计算图以提升推理性能,而 PyTorch Mobile 保持动态图灵活性但牺牲部分效率。静态与动态图的选择,直接影响模型在多变移动环境下的适应性与优化空间。
移动端框架在数据结构上也高度优化,追求内存与计算效率。与云端框架常用的可变 Tensor 不同,移动端更倾向于专用数据结构,如量化张量(8 位整型等),以适应设备 RAM 和算力的限制。
能效是移动端框架设计的核心考量。与云端常用的动态图执行不同,移动端多采用基于计算图的执行模式以节省能耗。例如,Apple Core ML 采用编译模型方式,将 ML 模型转为 iOS 设备可高效执行的格式,兼顾性能与能耗。
移动 ML 框架还需深度集成移动专用硬件与传感器。它们在继承云端加速能力的基础上,重点支持移动 GPU、NPU 等专用处理器。例如,TensorFlow Lite 可调用手机 GPU/神经网络单元加速,Qualcomm Neural Processing SDK 则专为 Snapdragon SoC 的 AI 加速器优化。这类硬件专用优化通常涉及自定义算子和底层适配。
自动微分能力在移动端通常被极大简化或移除,以减小模型体积、提升推理速度。模型训练和更新多在云端完成,移动端仅负责高效推理。
移动 ML 框架还常集成模型热更新与版本管理,便于在不更新 App 的情况下部署新模型。有些框架支持有限的端上学习,使模型能根据用户行为或环境变化自适应,同时保护隐私。相关技术将在第 14 章“端侧学习”与第 15 章“安全与隐私”详细介绍。
移动 ML 框架的专用化能力,使复杂 ML 模型能在资源受限的移动设备上高效运行,拓展了 AI 在移动场景下的应用空间(如实时图像/语音识别、个性化体验等)。但要高效利用这些框架,需充分考虑目标设备能力、用户体验和隐私等多重因素,在模型性能与资源利用之间取得最佳平衡。
微控制器与嵌入式系统实现
在资源受限的极端场景下,TinyML 框架推动了极限计算的边界。TinyML 框架专为微控制器和低功耗嵌入式系统上的模型部署而设计,应对极低算力、内存和能耗的挑战。其专用化主要体现在极致模型压缩、极端受限环境下的优化,以及对微控制器架构的深度集成。
TinyML 框架在模型压缩上将量化技术推向极致。移动端常用 8 位量化,TinyML 则进一步采用 4 位、2 位甚至 1 位(二值化)参数表示。例如,TensorFlow Lite Micro 就是此类极致压缩的代表,能将模型压缩到仅几 KB 内存。
TinyML 框架的执行模型高度专用化。与云端/移动端的动态图或 JIT 编译不同,TinyML 几乎只采用静态、极致优化的计算图。JAX 等框架的 JIT 编译在 TinyML 场景下因内存受限难以实现,通常采用预编译(AOT)生成针对设备的高效代码。
内存管理在 TinyML 框架中极为严苛。边缘/移动端尚可动态分配内存,TinyML 框架如 uTensor 则多采用静态内存分配,避免运行时开销和碎片。这要求在编译期精确规划内存布局,与云端的灵活管理形成鲜明对比。
硬件集成方面,TinyML 框架高度适配微控制器指令集。与云端通用 GPU、移动端 NPU 支持不同,TinyML 框架常针对特定微控制器优化。例如,ARM CMSIS-NN 提供 Cortex-M 系列专用神经网络内核,常被集成进 TinyML 框架。
自动微分在 TinyML 框架中基本缺失,几乎只关注推理,所有训练与模型更新均在设备外完成,极端受限的算力难以支持端上学习。
TinyML 框架还极度重视功耗管理,集成了如占空比控制、超低功耗唤醒等特性,使得“永远在线”传感应用能在纽扣电池上运行数年。
TinyML 框架的极致专用化,使得 AI 能在以往难以企及的场景落地,如智能尘埃传感器、植入式医疗设备等。但这种专用化也带来模型复杂度和精度的显著牺牲,需在 ML 能力与硬件极限之间谨慎权衡。
性能与资源优化平台
除部署场景专用化外,现代机器学习框架越来越多地将“高效”作为一等设计原则。高效导向型框架将计算效率、内存优化和能耗作为核心约束,而非事后优化。这类框架应对 AI 在资源受限环境下实际部署的需求,算法设计从一开始就受限于资源约束。
传统框架常将效率优化视为开发后的附加步骤,而高效导向型框架则将量化、剪枝、压缩等优化手段深度集成进开发流程,使开发者能在训练和部署阶段同步考虑资源约束。这种“效率优先”理念,使得许多传统框架难以落地的场景成为可能。
随着 AI 应用向资源受限场景扩展,生产系统对模型提出了更高的效率要求:推理延迟需低于 10ms、内存占用需适配 GPU 容量、能耗需延长电池寿命、计算成本需降低云端开销。这些约束与科研环境有本质区别,对框架提出了全新要求。
模型体积与计算量缩减技术
高效导向型框架在计算图设计上天然支持压缩感知。与传统框架仅对算子逐步优化不同,这类框架在整个计算流程中都优化压缩表示,从数据结构到执行引擎全链路支持。
神经网络压缩需框架支持专用数据类型与操作。量化感知训练要求框架能在训练时模拟低精度运算,同时保持全精度梯度以保证优化稳定性。Intel Neural Compressor 就是典型代表,能将 INT8 量化无缝集成进 PyTorch 和 TensorFlow 流程,通过插入“伪量化”操作,让模型在训练阶段适应量化约束,最大限度保留精度。
结构化剪枝需框架高效支持稀疏张量操作,包括专用存储格式(如压缩稀疏行)、稀疏矩阵高效运算和运行时稀疏调度。Apache TVM 展现了先进的稀疏张量编译能力,能为不同硬件自动生成高效稀疏运算代码。
知识蒸馏流程也是高效框架的重要能力。这类框架需支持教师 - 学生模型的协同训练,管理多模型并行带来的计算开销,并提供自定义蒸馏损失的 API。Hugging Face Optimum 就集成了完整的蒸馏流程,自动配置多种模型架构的教师 - 学生训练,极大简化了高效优化的工程难度。
硬件 - 框架协同性能调优
高效导向型框架强调软硬件协同优化,将框架架构与硬件能力深度耦合。相比通用硬件加速,这类框架在算法设计阶段就考虑硬件约束,针对目标硬件定制优化策略。
混合精度训练框架是软硬件协同的典型。NVIDIA PyTorch 的 AMP 能自动识别可用 FP16 运算的算子,同时对关键路径保持 FP32 精度,兼顾训练速度(在现代 GPU 上可提升 1.5-2 倍)与数值稳定性。这需要框架调度与硬件能力的深度集成。
稀疏计算框架进一步利用硬件稀疏性支持。例如,NVIDIA A100 GPU 集成了专用稀疏矩阵乘单元,支持 2:4 结构化稀疏(50% 零元素特定模式),几乎无性能损失。Neural Magic SparseML 等框架可自动训练符合硬件稀疏模式的模型,实现显著加速且无精度损失。
编译型框架则代表了最高级别的软硬件协同。Apache TVM、MLIR 提供领域专用语言,能表达硬件专用优化。它们自动分析计算图,为特定硬件生成最优内核,充分利用内存层次、指令集和并行能力,性能常超越手工优化。
生产部署性能需求
高效导向型框架通过系统化资源管理和性能优化,解决生产部署中的实际挑战。生产环境对推理延迟、内存占用和能耗有严格约束,与科研环境大相径庭。
推理优化框架如 NVIDIA TensorRT、ONNX Runtime 提供完整生产部署工具链。TensorRT 采用层融合、精度校准、内存优化等激进手段,推理速度可提升 3-7 倍,且精度损失可控。
内存优化是生产部署的关键。DeepSpeed、FairScale 等框架通过高级内存管理技术,使超大模型能在标准 GPU 上训练和推理。DeepSpeed ZeRO 优化器将优化器状态、梯度和参数分布到多设备,内存占用比传统并行方式降低 4-8 倍,使百亿参数模型在常规硬件上可训练。
能耗感知框架日益重要。功耗直接影响云端部署成本和移动端续航。NVIDIA Triton Inference Server 支持能耗感知调度,可动态调整推理批量和频率,兼顾能耗与吞吐。
系统化性能评估方法
高效导向型框架的评估需多维度指标,兼顾精度、性能与资源消耗。传统 ML 评估侧重精度,高效评估则需关注计算效率(FLOPS、推理加速)、内存效率(峰值占用、带宽利用)、能效(功耗、单次推理能耗)、部署效率(模型体积、部署复杂度)等。
定量对比需标准化基准。MLPerf Inference 提供了跨框架、跨硬件的标准推理性能基准,涵盖延迟、吞吐、能耗等多维度,便于直接对比框架效率。
性能分析工具如 NVIDIA Nsight Systems、Intel VTune 能深入剖析框架执行瓶颈,识别内存带宽、计算瓶颈和优化空间。这些工具与高效框架集成,为开发者提供可操作的性能提升建议。
高效导向型框架的演进,标志着 ML 系统设计范式的转变——从一开始就以资源约束为核心,推动 AI 在资源受限环境下的实际落地,同时保留现代 ML 框架的灵活性与表达力。
系统化框架选择流程
选择合适的机器学习框架需系统评估技术需求与运维约束。决策过程涵盖多个相互关联因素:技术能力(支持的操作、执行模型、硬件目标)、运维要求(部署约束、性能需求、可扩展性)和组织因素(团队经验、开发时间表、维护资源)。
框架选择遵循结构化方法,考虑三个主要维度:模型需求确定框架需支持的操作和架构,软件依赖定义操作系统和运行时要求,硬件约束建立内存和处理能力限制。这些技术考量需与实际因素平衡,如团队经验、学习曲线、社区支持和长期维护承诺。
决策过程还需考虑 第 2 章:机器学习系统 中概述的更广泛系统架构原则,并与 第 13 章:机器学习运维 中详细的部署模式保持一致。不同部署场景往往偏好不同框架架构:云训练需高吞吐和分布式能力,边缘推理优先考虑低延迟和最小资源使用,移动部署在性能与电池约束间平衡,嵌入式系统则优化内存占用和实时执行。
以 TensorFlow 生态为例,展示框架选择中权衡的广度:TensorFlow、TensorFlow Lite 和 TensorFlow Lite Micro。虽然以 TensorFlow 为案例,选择方法同样适用于 PyTorch、ONNX、JAX 等框架。
表 4 概述 TensorFlow 各变体间的主要差异。每种变体在计算能力和资源需求间存在明显权衡,体现在支持的操作、二进制大小和集成要求上。
| TensorFlow | TensorFlow Lite | TensorFlow Lite for Microcontrollers | |
|---|---|---|---|
| 训练 | 是 | 否 | 否 |
| 推理 | 是(但边缘设备上低效) | 是(且高效) | 是(且更高效) |
| 操作数量 | ~1400 | ~130 | ~50 |
| 量化工具支持 | 否 | 是 | 是 |
工程师在选择框架时主要分析三个方面:
- 模型需求确定框架需支持的操作和架构
- 软件依赖定义操作系统和运行时要求
- 硬件约束建立内存和处理能力限制
这种系统化分析帮助工程师选择与特定部署需求和组织环境相符的框架。以 TensorFlow 变体为例,探讨每个选择维度如何影响框架选择和系统能力。
模型需求
模型架构能力在 TensorFlow 各变体间差异显著,功能与效率间存在明显权衡。表 4 从训练能力、推理效率、操作支持和量化特性四个维度量化了这些差异。
静态图与动态图的权衡
图构建方式是框架间的关键区别。静态图(TensorFlow 1.x)需在执行前定义完整计算,类似编译后运行程序;动态图(PyTorch、TensorFlow 2.x 即时模式)则在执行时构建计算图,类似解释型语言。这影响调试难易(动态图支持标准 Python 调试)、优化机会(静态图可更激进优化)和部署复杂性(静态图简化部署但需前期设计)。TensorFlow 支持约 1400 种操作,支持训练和推理。但如表 4 所示,其推理能力在边缘设备上低效。TensorFlow Lite 将操作数量减少至约 130 种,同时提升推理效率。它取消了训练支持,但增加了原生量化工具。TensorFlow Lite Micro 进一步将操作集缩减至约 50 种,通过这些限制实现更高推理效率。与 TensorFlow Lite 类似,它也包含原生量化支持,但移除了训练能力。
操作集的逐步缩减,使得在资源受限设备上部署成为可能。TensorFlow Lite 和 TensorFlow Lite Micro 的原生量化功能,提供了在完整 TensorFlow 框架中缺失的优化能力。这些优化技术在选择特定部署场景的框架时,需与 第 6 章:数据工程 中讨论的数据管道需求一并考虑。
软件依赖
表 5 揭示了区分 TensorFlow 各变体的三个关键软件因素:操作系统要求、内存管理能力和加速器支持。这些差异反映了每个变体针对特定部署环境的优化。
| TensorFlow | TensorFlow Lite | TensorFlow Lite for Microcontrollers | |
|---|---|---|---|
| 需要操作系统 | 是 | 是 | 否 |
| 模型内存映射 | 否 | 是 | 是 |
| 加速器委派 | 是 | 是 | 否 |
操作系统依赖是变体间的根本区别。TensorFlow 和 TensorFlow Lite 需要操作系统,而 TensorFlow Lite Micro 无需操作系统即可运行。这使得 TensorFlow Lite Micro 能够减少内存开销和启动时间,但仍可与 FreeRTOS、Zephyr 和 Mbed OS 等实时操作系统集成。
内存管理能力也是变体间的区别。TensorFlow Lite 和 TensorFlow Lite Micro 支持模型内存映射,允许直接从闪存访问模型,无需加载到 RAM 中。TensorFlow 不支持此功能,反映其在内存资源丰富环境中的设计初衷。内存映射在向资源受限设备部署时变得愈发重要。
加速器委派能力进一步区分了变体。TensorFlow 和 TensorFlow Lite 都支持委派给加速器,优化计算分配。TensorFlow Lite Micro 则不支持此功能,考虑到嵌入式系统中专用加速器的有限可用性。这一设计选择保持了框架的最小占用,同时与典型嵌入式硬件配置相匹配。
硬件约束
表 6 概述了 TensorFlow 各变体在硬件优化上的差异:随着目标设备资源限制加剧,二进制大小和内存占用逐渐降低,支持从服务器到微控制器的多种部署。
| TensorFlow | TensorFlow Lite | TensorFlow Lite for Microcontrollers | |
|---|---|---|---|
| 基础二进制大小 | ~3-5 MB(因平台和构建配置而异) | 100 KB | ~10 KB |
| 基础内存占用 | ~5+ MB(最低运行时开销) | 300 KB | 20 KB |
| 优化架构 | X86、TPU、GPU | Arm Cortex A、x86 | Arm Cortex M、DSP、MCU |
如表 6 所示,二进制大小在各变体间大幅减少:从 TensorFlow 的 3+ MB 降至 TensorFlow Lite 的 100 KB,再到 TensorFlow Lite Micro 的 10 KB,反映了特性减少和优化。
内存占用也呈现类似的减少模式。TensorFlow 基础内存需求约 5 MB,TensorFlow Lite 为 300 KB,而 TensorFlow Lite Micro 进一步降至 20 KB,适应高度受限设备。
处理器架构支持与每个变体的目标部署环境一致。TensorFlow 支持 x86 处理器及 TPU、GPU 等加速器,满足数据中心高性能计算需求,如 第 11 章:AI 加速 所述。TensorFlow Lite 针对移动和边缘处理器,支持 Arm Cortex-A 和 x86 架构。TensorFlow Lite Micro 专注于微控制器部署,支持 Arm Cortex-M 核心、DSP 和各种 MCU(如 STM32、NXP Kinetis 和 Microchip AVR)。硬件加速策略和架构见 第 11 章:AI 加速 。
生产就绪评估因素
嵌入式系统框架选择超出技术规格,还需考虑模型架构、硬件要求和软件依赖的综合因素。额外因素影响开发效率、维护需求和部署成功率。框架迁移面临重大挑战,包括向后兼容性中断、版本间自定义算子迁移和生产停机风险。迁移问题详见 第 13 章:机器学习运维 ,包括迁移计划、测试程序和回滚策略。这些因素需系统评估,确保框架选择最优。
性能优化
嵌入式系统中的性能不仅包括计算速度,还包括多个指标。框架评估需量化各效率维度的权衡:
推理延迟决定系统响应和实时处理能力。移动应用典型目标为图像分类 10-50ms,关键词识别 1-5ms,工业控制应用需亚毫秒级响应。TensorFlow Lite 在移动 CPU 上对比 TensorFlow 推理延迟降低 2-5 倍,TensorRT 等专用框架在 NVIDIA 硬件上可达 10-20 倍加速。
内存利用影响静态存储需求和运行时效率。框架内存开销差异大:TensorFlow 基础需 5+ MB,TensorFlow Lite 约 300KB,TensorFlow Lite Micro 约 20KB。模型内存占用同样遵循此模式:如 TensorFlow 中的 MobileNetV2 模型约 14MB,TensorFlow Lite 量化后仅 3.4MB,减少 4 倍以上,精度保持 95% 以上。
功耗直接影响电池寿命和散热管理。量化后的 INT8 推理较 FP32 运算节能 4-8 倍。Apple Neural Engine 对 INT8 运算的 TOPS/W 效率可达 7.2,相比之下,CPU 上 FP32 计算仅为 0.1-0.5 TOPS/W。稀疏计算在框架支持结构化稀疏时可提供额外 2-3 倍的能量节省。
以 FLOPS 衡量的计算效率提供标准化性能对比。现代移动框架在高端智能手机处理器上可达 10-50 GFLOPS,Google Edge TPU 在 2W 功率预算内提供 4 TOPS(INT8)。优化技术如算子融合可将 FLOPS 利用率从 10-20% 提升至 60-80%。
部署可扩展性
可扩展性需求涵盖技术能力和运维考量。框架支持需覆盖部署规模和场景:
设备扩展实现从微控制器到更强大嵌入式处理器的一致部署。操作扩展支持从开发原型到生产部署的过渡。版本管理便于跨设备模型更新和维护。框架需在这些扩展维度保持一致的性能特征。
TensorFlow 生态系统展示了框架设计如何平衡不同部署场景的竞争需求。通过该案例(分析模型需求、软件依赖和硬件约束及运维因素),探讨如何评估任何框架生态。
开发支持与长期可持续性评估
框架选择不仅仅是技术能力的对比,更关乎其生态系统对长期可持续性和开发效率的影响。一个框架所依托的社区和生态,直接决定了其演进速度、支持质量以及集成能力。理解这些生态动态,有助于预测框架的可持续性和项目全生命周期的开发生产力。
开发者资源与知识共享网络
社区活跃度影响着开发和部署的诸多实际环节。活跃的社区意味着更快的 bug 修复、更完善的文档和更广泛的硬件支持。社区规模和参与度(如 GitHub 活动、Stack Overflow 问题量、会议活跃度)是衡量框架生命力和前景的重要指标。
PyTorch 的学术社区推动了研究型特性的快速创新,带来了丰富的新架构和实验技术的支持。其社区氛围促成了优质的教育资源、可复现性工具和前沿特性的开发。但在生产工具方面,PyTorch 早期相对滞后,近年来通过 PyTorch Lightning、TorchServe 等项目逐步补齐了运维短板。
TensorFlow 的企业社区则更注重生产级工具和可扩展部署方案,形成了完善的服务基础设施、监控工具和企业集成能力。其生态包括 TensorFlow Extended (TFX) 生产流水线、TensorBoard 可视化、TensorFlow Model Analysis 等专业工具。
JAX 的函数式编程社区专注于数学严谨性和程序变换能力,形成了强大的研究工具和优雅的数学抽象,但对不熟悉函数式编程的开发者有一定学习门槛。
支撑性基础设施与第三方兼容性
框架的实际价值往往取决于其生态工具,而非核心能力本身。这些工具决定了开发效率、调试体验和部署灵活性。
Hugging Face 已成为 NLP 领域事实标准,提供统一 API,兼容 PyTorch、TensorFlow、JAX 后端。高质量预训练模型和微调工具极大加速了项目开发。TensorFlow Hub、PyTorch Hub 提供官方模型仓库,但第三方集合往往涵盖更广泛的新架构。
PyTorch Lightning 抽象了 PyTorch 训练流程的样板代码,兼顾研究灵活性和结构化训练,弥补了 PyTorch 在训练工作流上的不足。Weights & Biases、MLflow 等工具支持多框架实验追踪,实现统一的工作流管理。TensorBoard 已发展为跨框架可视化工具,但与 TensorFlow 集成最为紧密。
TensorFlow Serving、TorchServe 提供生产级模型服务,但功能和运维特性差异明显。ONNX Runtime 作为框架无关的推理方案,提升了部署灵活性,但可能牺牲部分框架特定优化。云服务(如 AWS SageMaker、Google AI Platform、Azure ML)通常对主流框架有原生集成,也支持容器化部署兼容其他框架。
框架专用优化工具可带来显著性能提升,但也可能造成供应商锁定。TensorFlow 的 XLA 编译器、PyTorch 的 TorchScript 提供原生优化路径,Apache TVM 等工具则支持跨框架优化。选择专用还是通用优化工具,直接影响性能与部署灵活性的平衡。
长期技术投资考量
长期框架决策需关注生态演进和可持续性。框架流行度可能因技术创新、社区活力或公司战略变化而快速转移。组织应从贡献者多样性(避免单一公司依赖)、资金稳定性、路线图透明度和兼容性承诺等多维度评估生态健康。
生态视角还影响团队招聘与能力建设。框架选择决定了可用人才池、培训成本和知识传承能力。团队需考虑所选框架是否契合本地人才、教育体系和行业招聘趋势。
与现有组织工具和流程的集成能力也是关键生态考量。框架与 CI/CD、部署流水线、监控系统、安全工具的兼容性,直接影响运维成本。有些框架与特定云平台或企业软件栈集成更自然,带来运维优势或供应商依赖。
深度生态集成可提升开发效率,但团队也需关注迁移路径和跨框架兼容性。采用 ONNX 等标准化模型格式、保持数据管道框架无关、记录框架特定定制,有助于未来平滑迁移。
生态视角提醒我们,选择框架不仅是选一个软件库,更是加入一个社区、承诺于一个不断演进的技术生态。理解这些更广泛的影响,有助于团队做出长期可持续且具备竞争力的框架决策。
框架性能的系统化评估
系统化评估框架效率需多维度指标,全面反映准确率、性能与资源消耗的权衡。传统机器学习评估侧重准确率,但生产部署更需关注计算效率、内存利用、能耗和运维约束。
框架效率评估主要涵盖四大维度,反映实际部署需求。计算效率衡量框架对硬件资源的利用率(如 FLOPS 利用率、内核效率、并行化能力);内存效率关注峰值内存占用和带宽利用,决定资源受限设备的适用性;能效评估功耗特性,移动和绿色计算场景尤为关键;部署效率则关注模型体积、初始化时间和集成复杂度等运维特性。
多维量化性能分析
标准化对比需在典型工作负载和硬件配置下,量化各主流框架的效率。下表以 ResNet-50 在代表性硬件(服务器端 NVIDIA A100 GPU,移动端 ARM Cortex-A78)上的推理为例,系统对比主流框架在各效率维度的表现。所有测试均保证准确率在基线 1% 以内,硬件利用率为典型操作下的理论峰值百分比。
| 框架 | 推理延迟 (ms) | 内存占用 (MB) | 能耗 (mJ/次) | 模型体积压缩 | 硬件利用率 (%) |
|---|---|---|---|---|---|
| TensorFlow | 45 | 2,100 | 850 | 无 | 35 |
| TensorFlow Lite | 12 | 180 | 120 | 4 倍(量化) | 65 |
| TensorFlow Lite Micro | 8 | 32 | 45 | 8 倍(剪枝 + 量化) | 75 |
| PyTorch | 52 | 1,800 | 920 | 无 | 32 |
| PyTorch Mobile | 18 | 220 | 180 | 3 倍(量化) | 58 |
| ONNX Runtime | 15 | 340 | 210 | 2 倍(优化) | 72 |
| TensorRT | 3 | 450 | 65 | 2 倍(精度优化) | 88 |
| Apache TVM | 6 | 280 | 95 | 3 倍(编译优化) | 82 |
标准化基准测试方法
系统化评估需采用标准化基准测试,覆盖多样部署场景。评测方法包括典型模型(如视觉任务 ResNet-50、语言任务 BERT-Base、移动端 MobileNetV2)、标准数据集(ImageNet、GLUE)和统一硬件(服务器端 NVIDIA A100、移动端 ARM Cortex-A78)。
性能分析通过工具测量框架开销、内核效率和资源利用模式。内存分析包括峰值分配、带宽利用和垃圾回收开销。能耗通过硬件级监控(如 NVIDIA-SMI、移动端专用功耗仪)测量推理和训练过程的实际能耗。
准确率保持验证确保效率优化不会显著损失模型质量。量化训练需验证 INT8 模型准确率下降小于 1%;剪枝需验证稀疏模型在压缩比下保持目标精度;知识蒸馏需确认压缩模型能力不低于教师模型。
真实运维性能考量
框架效率评估还需关注实际部署中的运维约束。延迟分析包括冷启动(初始化时间)、热身(性能稳定过程)和稳态推理速度。内存分析涵盖静态需求(框架二进制体积、模型存储)和动态模式(峰值分配、碎片化、回收效率)。
可扩展性评估关注生产负载下的表现,如并发请求处理、批量推理效率、多模型实例资源共享。集成测试验证框架与生产基础设施(容器部署、服务网格、监控系统、可观测性工具)的兼容性。
可靠性评估关注长时间运行下的稳定性、错误处理和恢复机制。性能一致性分析则关注执行时间波动、内存使用稳定性和高负载下的热特性。
结构化框架选型流程
系统化框架选型需结构化评估,平衡效率指标、运维需求和组织约束。决策流程包括技术能力(操作支持、硬件加速、优化特性)、运维需求(部署灵活性、监控集成、维护成本)和组织因素(团队经验、开发效率、生态兼容性)。
效率需求需明确准确率与性能的权衡、资源约束(内存、功耗、延迟)和关键优化特性(量化、剪枝、硬件加速)。这些需求指导评估优先级,排除无法满足基本约束的选项。
风险评估关注框架成熟度、生态稳定性和迁移复杂度。供应商依赖评估包括治理结构、许可协议和长期支持承诺。迁移成本分析需估算采纳新框架的开发投入、团队培训和基础设施改造。
系统化效率评估为部署决策提供量化依据,同时兼顾生产运维的实际需求。该方法帮助团队在满足特定效率目标的同时,保持未来部署场景的灵活性和可扩展性。
框架选择的常见误区
机器学习框架是复杂软件生态,抽象了大量计算复杂性,同时为开发者做出关键架构决策。可用框架种类繁多(各有不同设计哲学和优化策略),常导致对其可互换性和选择标准的误解。理解这些常见误区,有助于从容应对框架选择。
误区: 相同模型在所有框架中性能相当。
这一误解导致团队仅根据 API 便利性或熟悉度选择框架,而忽视性能影响。不同框架对操作的实现有不同优化策略、内存管理方法和硬件利用模式。PyTorch 中高效的模型在 TensorFlow 中可能表现不佳,反之亦然。即使是相同的模型架构,框架开销、自动微分实现和张量操作调度的差异,也可能导致显著的性能差异。框架选择需基于实际工作负载基准测试,而非假设性能等同。
误区: 流行框架都能满足所有需求。
许多开发者基于社区规模、教程可得性或行业采纳度选择框架,而未分析自身技术需求。流行框架往往针对通用用例,而非特定部署场景。优化用于大规模云训练的框架,可能不适合移动部署;而专注研究的框架,可能缺乏生产部署能力。有效的框架选择需将技术能力与具体需求匹配,而非追随流行趋势。
误区: 框架抽象能隐藏所有系统级复杂性。
这一观点认为框架自动处理所有性能优化和硬件利用,无需开发者理解。尽管框架提供便利抽象,但要实现最佳性能,仍需理解其底层计算模型、内存管理策略和硬件映射方法。将框架视为黑箱的开发者,常会遇到意想不到的性能瓶颈、内存问题或部署失败。有效利用框架,需理解其提供的抽象及其底层实现影响。
误区: 通过框架特定模型格式和 API 锁定供应商。
团队常在不考虑互操作性需求的情况下,围绕单一框架构建整个开发工作流。框架特定的模型格式、自定义算子和专有优化技术,造成迁移、部署或跨工具协作的复杂性。这种锁定在部署需求变化、性能需求演变或框架开发方向偏离项目目标时,尤为成问题。保持模型可移植性,需关注标准化格式,避免无法跨平台转换的框架特定特性。在实施负责任的 AI 实践时,考虑模型审计、公平性测试和偏见缓解等跨部署环境的灵活性,显得尤为重要。
总结
机器学习框架是将数学概念转化为实际计算工具的软件抽象,构建和部署 AI 系统。这些框架将复杂操作(如自动微分、分布式训练和硬件加速)封装在友好的接口后面,使高效开发成为可能,适用于各种应用领域。从基础数值库到现代框架的演变,展示了软件基础设施如何塑造机器学习开发的可及性和能力。
这一演变带来了具有不同优化策略的多样生态。现代框架体现了不同的设计哲学,反映了机器学习开发中的不同优先级。研究型框架优先考虑灵活性和快速实验,支持对新颖架构和算法的快速迭代。面向生产的框架则强调可扩展性、可靠性和大规模系统的部署效率。专用框架针对特定部署环境,从云端大规模分布式系统到资源受限的边缘设备,优化不同的性能和效率需求。
关键要点
- 框架抽象复杂计算操作(如自动微分和分布式训练),提供开发者友好的接口
- 不同框架体现不同设计哲学:研究灵活性、生产可扩展性、部署效率
- 针对计算环境的专用框架变体,支持云、边缘、移动和微控制器等多种部署,优化特定性能需求
- 理解框架能力和局限性,有助于做出明智的架构决策,实施 第 10 章:模型优化 中的模型优化技术、 第 11 章:AI 加速 中的硬件加速策略和 第 13 章:机器学习运维 中的部署模式
测验:AI 框架
测试对机器学习框架演进、核心概念、架构设计和选型策略的理解
线性变换:数学操作,保持向量加法和标量乘法,神经网络中通常以矩阵乘法实现。每层通过学习的权重矩阵进行线性变换,再加非线性激活(如 ReLU、sigmoid),让网络能从简单数学构件学习复杂模式。 ↩︎
BLAS(基础线性代数子程序):最初由阿贡国家实验室开发,成为线性代数运算的事实标准,分为一级(向量 - 向量)、二级(矩阵 - 向量)、三级(矩阵 - 矩阵)操作,至今仍是所有现代 ML 框架的底层支撑。 ↩︎
LAPACK(线性代数包):继承 LINPACK 和 EISPACK,采用块算法显著提升了缓存效率和并行执行能力,成为数据规模从 MB 到 TB 时代的关键创新。 ↩︎
Theano:以古希腊数学家 Theano 命名,开创了 Python 中符号数学表达的先河,是所有现代深度学习框架的奠基者。 ↩︎
计算图:1964 年 Wengert 在自动微分文献中首次形式化提出,成为现代 ML 框架的核心,支持大规模前向与反向微分。 ↩︎
即时执行:操作调用即刻执行,类似标准 Python,Torch 2002 年首创,优先考虑开发者体验和调试便利,成为 PyTorch、TensorFlow 2.x 的默认模式。 ↩︎
TensorFlow:以张量在计算图中流动命名,开源了 Google 内部 DistBelief 系统,让研究者瞬间获得原本只有大公司才有的基础设施。 ↩︎
静态计算图:预定义的计算结构,模型架构在执行前全部指定,支持全局优化和高效内存规划。TensorFlow 1.x 首创,牺牲运行时灵活性换取极致性能,适合生产部署。 ↩︎
算子融合:将多个操作(如矩阵乘法、加偏置、激活)合并为单一 GPU 内核,减少内存带宽需求 10 倍以上,消除中间内存分配。对复杂深度学习模型尤为关键。 ↩︎
内存规划:框架在执行前分析计算图,确定最优内存分配策略,实现原地操作和内存复用,训练时峰值内存可降 40-60%。 ↩︎
PyTorch:受 NYU 原始 Torch 框架启发,将“定义即运行”语义带入 Python,让研究者能在执行时修改模型,调试如同普通 Python 程序,极大加速了科研进展。 ↩︎
JAX:意为“Just After eXecution”,结合 NumPy API 与函数式变换(jit、grad、vmap、pmap),让研究者用简洁代码自动扩展到 TPU、GPU 集群,同时兼容 NumPy。 ↩︎
TPU(张量处理单元):Google 第一代 TPU(v1)在神经网络任务上性能/功耗比同代 GPU、CPU 高 15-30 倍,证明了专用架构在 ML 计算上的巨大优势。 ↩︎
脉动阵列:1978 年由 H.T. Kung(CMU)和 Charles Leiserson(MIT)发明的并行计算架构,数据在处理单元网格中有节奏地流动,每个单元执行简单操作,极适合神经网络的矩阵运算。 ↩︎
ASIC(专用集成电路):为特定任务定制的芯片,区别于通用 CPU。ML 领域如 Google TPU、Tesla FSD 芯片,牺牲灵活性换取 10-100 倍效率,但开发周期需 2-4 年,成本数百万美元。 ↩︎
中间表示(IR):框架内部格式,介于高层用户代码与硬件机器码之间,支持优化与跨平台部署。现代 ML 框架如 TensorFlow XLA、PyTorch TorchScript,能将同一模型编译到 CPU、GPU、TPU、移动设备。 ↩︎
有向无环图(DAG):ML 框架中,DAG 表示计算,节点为操作(如矩阵乘法、激活函数),边为数据依赖。与通用计算机科学 DAG 不同,ML 计算图专为自动微分优化,支持反向遍历高效计算梯度。 ↩︎
梯度累积:多批次计算并累加梯度,统一更新参数,模拟大批次训练而不增加内存消耗。适合大模型训练,单设备批次可小至 1。 ↩︎
梯度检查点(Gradient Checkpointing):一种内存优化技术,通过只保存部分中间激活值,其余在反向传播时重算,从而用更多计算时间换取更低内存消耗。对于深层网络,内存可降 50-90%,训练时间仅增加 20-33%。 ↩︎
算子融合(Operation Fusion):编译器优化,将多步连续操作合并为单一内核,降低内存带宽和延迟。例如,将矩阵乘法、加偏置和 ReLU 激活融合,可消除中间内存分配,在现代 GPU 上实现 2-3 倍加速。 ↩︎
数据并行:分布式训练策略,将同一模型副本分布到多台设备上,并行处理不同数据子集,最后同步梯度。可实现近线性加速,但要求模型能装入单设备内存,适合处理数十亿样本的数据集。 ↩︎
模型并行:用于超大模型训练,将模型结构拆分到多台处理器上。适用于如 GPT-3(1750 亿参数)等超出 GPU 内存限制的模型,但需优化分区间通信以降低开销。 ↩︎
Horovod:Uber 分布式深度学习框架,统一 API 支持 TensorFlow、Keras、PyTorch、MXNet,ring-allreduce 算法在高速互联上可达理论带宽 85-95%。 ↩︎
不可变数据结构:创建后不可修改,任何操作都生成新副本,保证原数据不变,防止误改并支持安全并行处理。 ↩︎
无状态函数:同样输入总是同样输出,不依赖或修改外部状态,便于优化和并行。 ↩︎
自动向量化:将单点操作转为数组或批量操作,充分利用 SIMD 并行能力,显著提升效率。 ↩︎
即时编译(JIT):运行时将高层代码转为优化机器码,针对实际数据和硬件做性能优化。 ↩︎
纯函数:无副作用,同样输入总是同样输出,便于数学推理和安全变换。 ↩︎
ONNX(开放神经网络交换格式):业界标准模型表示,支持框架间互操作。微软、Facebook、AWS 等支持,可将 PyTorch 训练模型部署到 TensorFlow Serving 或用 TensorRT 优化,解决框架碎片化问题。 ↩︎