关于本书
概述
本节将介绍本书的编写初衷、开发背景,以及读者在学习过程中可以获得哪些收获。
写作目的
本书旨在为教育者和学习者提供一套系统、实用的机器学习系统原理与工程实践资源。内容持续更新,融入最新洞见与高效教学策略,力求在快速变化的领域中始终保持前沿与实用性。欢迎大家常来查阅!
背景与发展
本书起源于学生、研究者和业界实践者的协作努力。我们在保持学术严谨性的同时,注重实际应用价值,并通过定期更新和精心策划,持续反映机器学习系统领域的最新进展。
读者预期
本教材采用循序渐进的教学设计,模拟 ML 系统工程师成长路径,分为五个阶段:
阶段一:理论 —— 通过“基础篇章”和“设计原则”构建概念根基,建立系统性思维模型。
阶段二:性能 —— 掌握“性能工程”,将理论转化为能在真实资源受限环境下高效运行的系统。
阶段三:实践 —— 深入“稳健部署”,学会让系统在开发环境之外也能可靠运行。
阶段四:伦理 —— 探索“可信系统”,确保你的系统对社会有益且可持续。
阶段五:前沿 —— 展望“ML 系统前沿”,理解新兴范式,为下一代挑战做好准备。
实验环节 安排在核心理论基础之后,帮助你在多种嵌入式平台上动手实践。全书穿插有 小测验,便于在关键节点自查理解。
教学理念:基础为先
机器学习系统本质上是复杂的工程挑战,但它们都由一系列基础模块构建而成,只有真正理解这些基石,才能进阶到更复杂的实现。这一教学理念与传统教育路径一致:学生需先掌握基础算法,才能学习分布式系统;先精通线性代数,才能深入机器学习理论。ML 系统同样有其不可或缺的基础组成部分,是后续学习的根基。
我们的课程强调以下核心能力:
- 模型与硬件的交互机制
- 数据在系统中的流动模式
- 计算模式的涌现与优化
- 单体系统内的优化原理
通过对这些基础的深入理解,学生将具备分析复杂场景(如分布式训练架构、多设备协同协议、新兴技术范式)的能力。
“基础为先”的方法论强调概念深度而非表面广度,帮助学生构建持久的知识体系,为未来职业生涯中的 ML 系统演进打下坚实基础。
学习目标
本节介绍本书的教学框架及具体学习目标。
关键学习成果
本书结构参考 布鲁姆认知目标分类 (见下图),涵盖从基础知识到高级创新的六个层级:
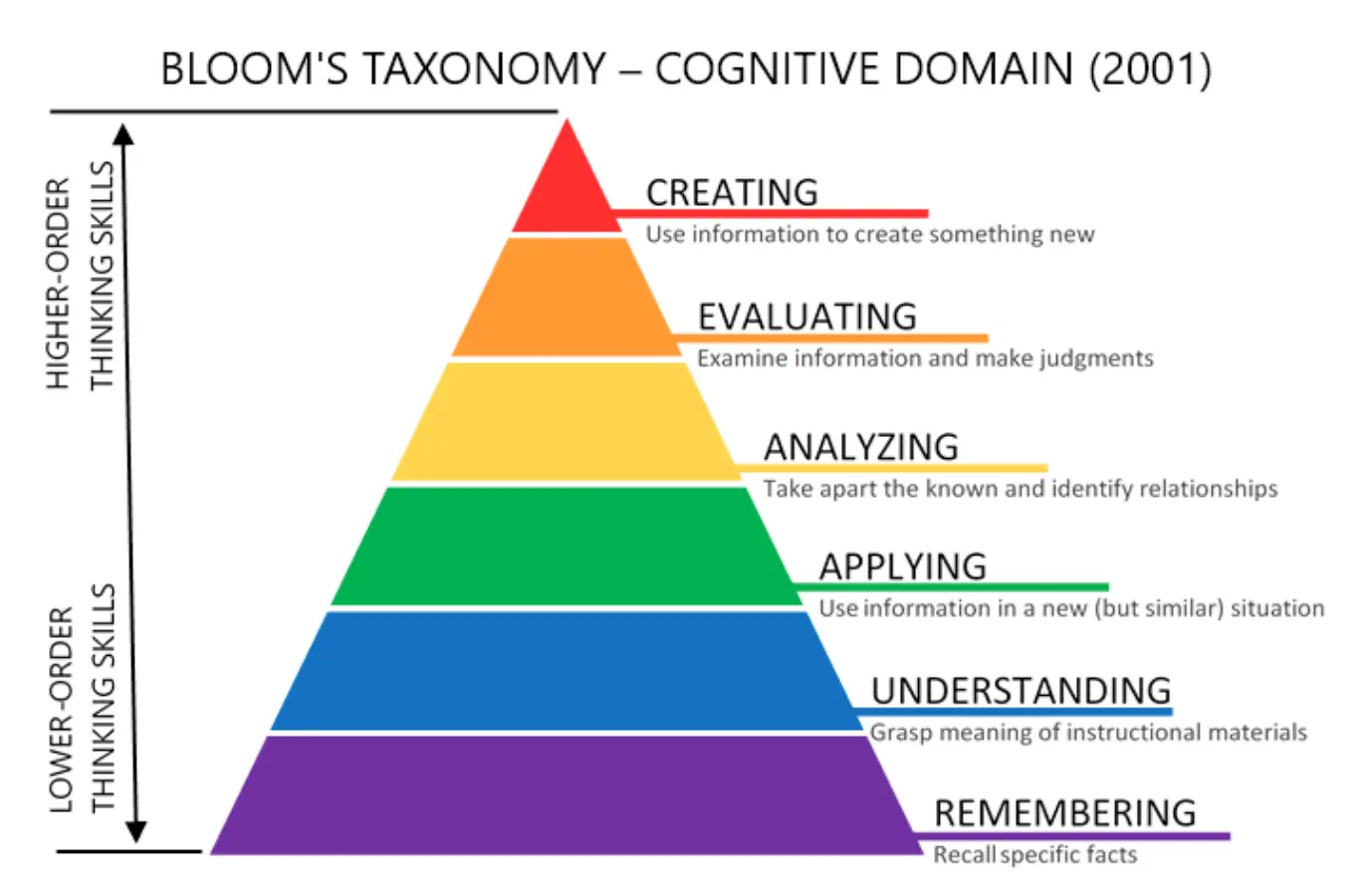
- 记忆:回忆基本事实和概念。
- 理解:解释思想或过程。
- 应用:在新情境中运用知识。
- 分析:将信息分解为组成部分。
- 评价:基于标准做出判断。
- 创造:产出原创作品或解决方案。
学习目标
本书帮助读者在 ML 系统全生命周期内培养实战能力:
- 系统思维:理解 ML 系统与传统软件的区别,掌握软硬件协同原理。
- 流程工程:设计端到端 ML 流水线,从数据工程到部署与运维。
- 性能优化:系统性提升系统速度、体积与资源效率。
- 生产部署:应对可靠性、安全、隐私与可扩展性等实际挑战。
- 负责任开发:把握伦理影响,构建可持续、利于社会的 AI 系统。
- 前瞻能力:具备评估新兴技术与适应变革的判断力。
- 动手实践:在多样嵌入式平台和资源受限环境中积累实战经验。
- 自主学习:借助集成测评与交互工具,持续跟踪进步、深化理解。
AI 学习助手
全书配备 SocratiQ AI 学习助手,提升你的学习体验。SocratiQ 借鉴苏格拉底式教学法,结合互动测验、个性化辅导和实时反馈,帮助你巩固理解、建立知识关联。作为生成式 AI 技术的集成示例,SocratiQ 鼓励批判性思考和主动学习。
SocratiQ 仍在持续完善,欢迎反馈建议。详情请参阅 AI 学习助手页面 。
如何使用本书
书籍结构
本书从 ML 系统的概念理解到实际构建与部署,分为以下部分:
核心内容:
- 基础篇章 夯实根基。 理解 ML 系统与传统软件的差异,掌握软硬件栈,熟悉基本架构与数学基础。
- 设计原则 工程化全流程。 学习端到端流水线设计,解决复杂数据工程难题,选择合适框架,组织大规模训练。
- 性能工程 面向真实约束优化。 掌握模型优化、硬件加速与系统性性能分析,让系统更快、更小、更高效。
- 稳健部署 打造生产级系统。 从单设备约束到系统级运维,掌握端上学习、安全隐私、稳健性与 ML 运维。
- 可信系统 负责任设计。 探索 ML 系统的社会与环境影响,践行负责任 AI,创造造福社会的技术。
- ML 系统前沿 面向未来。 理解新兴范式,预判未来挑战,培养评估新技术的能力。
实践环节:
实验练习 学以致用。 从微控制器到边缘计算平台,体验嵌入式 ML 的资源约束与优化挑战。
推荐阅读路径
- 初学者:从“基础篇章”入手,建立概念体系,再进入“设计原则”并选择相关实验练习。
- 工程实践者:重点阅读“设计原则”、“性能工程”和“稳健部署”,结合平台实验提升实战能力。
- 研究人员:关注“性能工程”、“可信系统”与“ML 系统前沿”,并参考工具实验室的对比分析。
- 动手型学习者:结合任意核心内容与 Arduino、Seeed、Grove Vision、树莓派等实验,获得全面实践体验。
针对不同背景的学生
本书欢迎来自计算机、工程、数学等多学科背景的学生。理解 ML 系统与既有知识的联系,有助于将理论转化为实践:
计算机专业学生:ML 系统是算法与数据结构在新领域的延伸。你可以将 ML 理解为自动根据数据模式自我优化的算法,而非固定指令。
你在系统设计、内存管理、并行处理和分布式系统方面的经验,可直接应用于 ML 部署。训练与推理阶段的时间和空间复杂度分析同样适用。
电子与计算机工程学生:ML 系统是信号处理与控制系统原理的自然进化。机器学习可视为从高维噪声信号中提取有意义模式的高级信号处理。
神经网络的卷积层本质上就是你学过的卷积操作。你对计算机系统结构和内存层级的理解,有助于优化大规模训练系统中的数据流动。
其他专业学生:可将 ML 系统类比为现代工厂流水线。正如工厂通过各环节协作将原材料变为成品,ML 系统通过各组件协作将原始数据转化为有用预测。
数学(线性代数、概率、微积分)是这条“流水线”的工具,但无需精通工具也能理解整体流程。大多数概念可通过具体案例理解,比如推荐系统就像图书管理员根据你的借阅历史推荐书籍。
关键能力是系统思维:理解数据管道、训练流程和部署基础设施如何协同,就像供应链、制造和分销在复杂运营中必须协调一样。
模块化设计
本书支持灵活学习,既可按章节独立阅读,也可遵循推荐路径。每章包含:
- 互动测验,自测与巩固知识
- 实践练习,理论与实现结合
- 实验体验,平台化动手学习
我们倡导内容迭代开发——有价值的见解会及时分享,而非等到“完美”才发布。你的反馈将帮助我们持续优化内容。
本书也借鉴并致敬领域专家的优秀成果,致力于打造知识共享、协作共进的学习生态。
透明与协作
本书起源于社区驱动项目,由哈佛大学 CS249r 学生、校内外同仁及 ML 系统社区共同推动。内容通过开放协作、反馈和现代编辑工具(包括规则脚本和生成式 AI 技术)不断完善。值得一提的是,正是我们研究的这些系统,也在帮助完善本书,展现了人机协作的魅力。当然,它们还远未能独立完成系统工程——至少目前还不行。
作为主要作者、编辑与策划者,我(Vijay Janapa Reddi 教授)始终保持人工审核,确保教材内容准确、前沿且高质量。当然,任何人都难免有疏漏,欢迎大家反馈指正。协作模式对于保证质量、开放知识和全球共享至关重要。
版权与许可
本书为开源项目,通过 GitHub 协作开发。除非另有说明,内容采用 知识共享署名 - 非商业性使用 - 相同方式共享 4.0 国际许可协议(CC BY-NC-SA 4.0) 授权。
贡献者对各自贡献保留著作权,可选择公有领域或与原项目相同的开源协议。详情请见 GitHub 仓库 。
加入社区
本教材不仅是学习资源,更是协作与共学的邀请。欢迎参与 社区讨论 ,分享见解、解决难题,与全球学生、研究者和工程师共同成长。
无论你是初学者、工程实践者还是前沿研究者,你的参与都将丰富我们的学习社区。欢迎自我介绍、分享目标,让我们一起深入理解机器学习系统。
中文版介绍
中文版由 Jimmy Song 独立翻译,完整保留了图书的原意和结构,但去除了测验及交互式内容。中文版未在原书的 GitHub 仓库中,而是由 Jimmy Song 独立维护,并提供 PDF 版本下载。由于采用 Hugo 和标准 Markdown 格式撰写,与英文版的排版和格式略有不同,建议直接 在线阅读 以获得最佳体验。