第 11 章:AI 加速
目标
为什么专用硬件加速不仅是机器学习落地的利器,更是计算系统设计范式的根本性转变?
实际的机器学习系统高度依赖硬件加速。没有专用处理器,计算需求在经济和物理层面都难以承受。通用 CPU 执行神经网络操作仅能达到 100 GFLOPS1,而现代训练任务需要每秒数万亿次运算,传统扩展方式已无法弥合性能鸿沟。硬件加速让原本不可行的计算变为现实,催生全新应用类别。工程师若想在现代 AI 系统中获得 100-1000$\times$ 的性能提升,实现实时推理、大规模训练和边缘部署的经济可行性,必须理解加速原理。
学习目标
- 梳理硬件加速从浮点协处理器到现代 AI 加速器的演进,理解其背后的架构原则
- 分类 AI 计算原语(向量操作、矩阵乘法、脉动阵列),分析其在主流加速器中的实现方式
- 评估 AI 加速器的存储层次结构设计,结合带宽与能耗指标预测性能瓶颈
- 针对神经网络层,设计映射到专用硬件架构的数据流与资源利用策略
- 应用编译器优化技术(图优化、算子融合、内存规划),将高层 ML 模型转化为高效硬件执行计划
- 比较多芯片扩展方案(chiplet、多 GPU、分布式系统),评估其对不同 AI 工作负载的适用性
- 批判性分析硬件加速常见误区,识别加速器选型与部署中的潜在陷阱
AI 硬件加速基础
现代机器学习系统对通用处理器架构提出了巨大挑战。前一章介绍的软件优化(如精度压缩、结构剪枝、执行优化)虽能提升算法效率,但始终受限于底层计算平台。CPU 执行典型机器学习任务时利用率仅 5-10%,原因在于其顺序处理模型与神经网络高度并行、数据密集的特性严重不匹配。
这种性能鸿沟推动了计算机体系结构领域向领域专用硬件加速的转型。硬件加速补足了软件优化的局限,通过架构重塑而非算法改造来突破效率瓶颈。机器学习算法与专用计算架构的协同演进,使得 AI 从高性能计算机上的实验研究走向数据中心与边缘设备的普及部署。
机器学习硬件加速位于计算机系统工程、体系结构与应用机器学习的交汇点。对于生产系统开发者而言,选择 GPU、TPU、类脑芯片等加速器,直接决定系统性能、能效和实现复杂度。自然语言处理、计算机视觉、自动驾驶等领域的实际部署,普遍实现了比通用方案高 2-3 个数量级的性能提升。
本章系统梳理机器学习硬件加速的原理与方法。首先回顾领域专用计算架构的历史演进,揭示从浮点协处理器到 GPU 的设计模式如何影响当代 AI 加速策略。随后,分析机器学习工作负载的计算原语(如矩阵乘法、向量操作、非线性激活),并剖析专用硬件通过脉动阵列、张量核心等创新机制优化这些操作。
存储层次结构设计对加速效果至关重要,因为数据搬运的能耗通常比计算高两个数量级以上。本章将探讨从片上 SRAM 缓存到高带宽内存接口的架构设计原则,以及如何最小化高能耗数据流。还将介绍编译器优化与运行时系统支持,分析理论硬件能力如何转化为实际系统性能。
最后,针对单芯片无法满足的算力需求,介绍多芯片扩展方法,包括 chiplet、多 GPU、分布式系统等,并分析其在并行性与通信开销间的权衡。通过对 NVIDIA GPU、Google TPU、类脑计算平台等系统的深入剖析,建立 AI 加速在不同场景下高效部署的理论基础与实践指南。
硬件专用化的演进
计算架构遵循着一个反复出现的模式:当计算负载复杂度提升,通用处理器效率下降,便催生专用硬件加速器。对更高计算效率、更低能耗和领域优化的需求推动了这一转变。机器学习加速正是这一演进的最新阶段,继承了浮点运算、图形处理、数字信号处理等领域的专用化路径。
这一历史进程有助于理解现代 ML 加速器(如带张量核心的 GPU、Google TPU2、Apple 神经引擎)如何从既有架构原则中演化而来。这些技术支撑了实时翻译、图像识别、个性化推荐等广泛应用。其背后的架构策略,源自数十年硬件专用化的研究与实践。
硬件专用化通过为高频操作设计专用电路,极大提升性能与效率。但这也带来灵活性、硅片面积利用率、编程复杂度等权衡。随着计算需求持续演进,专用加速器需在这些因素间取得平衡,实现持续的效率提升。
硬件专用化的历史为理解现代机器学习加速器提供了视角。早期浮点与图形加速器的设计原则,已成为 AI 专用硬件的基础。回顾这些趋势,有助于分析当代 AI 加速方案,并预判专用计算的未来发展。
专用计算
专用计算架构的兴起,源于通用处理器的局限。早期计算系统依赖 CPU 顺序执行所有任务,难以高效应对多样化、复杂化的负载。尤其是浮点运算,成为 CPU 的性能瓶颈,催生了专用硬件架构。
最早的专用硬件之一是 1980 年推出的 Intel 8087 数学协处理器3。该浮点单元(FPU)将密集运算从主 CPU 剥离,大幅提升了科学与工程计算性能。8087 的效率提升高达 100 倍,确立了“专用硬件可为特定任务带来数量级性能提升”的体系结构原则。
浮点协处理器4的成功推动了其集成进主流处理器。1989 年的 Intel 486DX 首次内置 FPU,省去了外部协处理器。这一集成提升了处理效率,也形成了体系结构的演进模式:专用功能成熟后,逐步成为通用处理器的标配。
早期浮点加速确立了影响至今的原则:
- 通过负载分析识别计算瓶颈
- 为高频操作开发专用电路
- 构建高效的软硬件接口
- 将成熟专用功能集成进通用处理器
这一从专用到集成的演进,塑造了现代计算架构。随着计算负载超越算术运算,这些原则被应用到图形处理、信号处理、机器学习加速等新领域。每个领域都催生了针对自身需求的专用架构,专用化成为提升复杂负载性能与效率的核心路径。
专用硬件的演进呈现出一致轨迹:架构创新为新兴计算瓶颈提供解决方案,随后被主流平台吸收。正如图 1 所示,每个计算时代都诞生了针对主流负载的加速器。这些发展推动了架构效率进步,也为现代机器学习系统奠定了基础。实时翻译、个性化推荐、端侧推理等能力,正是建立在浮点、图形、信号处理等领域的架构创新之上。

并行计算与图形处理
浮点加速确立的原则,为应对新计算挑战提供了蓝本。随着应用多样化,新的计算模式超越了通用处理器的能力。专用计算在多个领域扩展,各自为硬件加速策略贡献了独特见解。
90 年代,图形处理成为硬件专用化的主驱动力。早期图形加速器专注于位图传输、多边形填充等操作。1999 年 NVIDIA GeForce 256 引入可编程图形流水线,标志着专用计算的重大进步。GPU 通过并行架构高效处理数据并行负载,3D 渲染任务如纹理映射、顶点变换实现了 50-100$\times$ 加速。2004 年高端 GPU 已能每秒处理超亿多边形。
同时,数字信号处理器(DSP)通过专用乘加单元、环形缓冲等架构优化,实现了低功耗实时信号处理。1983 年的 TI TMS32010 展示了领域专用指令集对信号处理性能的巨大提升。
网络处理器则发展出多核、专用数据包处理单元、复杂内存管理等架构,以实现线速分组处理。Intel IXP2800 证明了多层次硬件专用化可应对复杂需求。
这些领域的专用化有如下共性:
- 识别领域特定计算模式
- 设计专用处理单元与存储层次结构
- 构建领域专用编程模型
- 向更灵活架构演进
这一时期的专用化扩展,证明了硬件加速可服务多样化需求。GPU 在 3D 图形并行化上的成功,促成了其在深度神经网络训练中的应用,AlexNet5(2012)即运行于消费级 NVIDIA GPU。DSP 的低功耗创新推动了语音助手、可穿戴设备等端侧推理。上述领域为 ML 硬件设计提供了借鉴,也确立了加速器可在云端与嵌入式场景广泛部署的原则。
领域专用架构的兴起
领域专用架构(DSA)6的出现,标志着计算系统设计范式的转变。其驱动力有二:一是传统工艺缩放定律失效,二是专用负载对算力的极致需求。摩尔定律7(18-24 个月晶体管密度翻倍)与 Dennard 缩放8(频率提升不增加功耗)双双失效,通用计算遭遇性能与能效瓶颈。Hennessy 与 Patterson 在 2017 年图灵奖演讲中指出,领域专用化将成为新一代体系结构的核心。
过去,处理器性能提升依赖工艺缩放与频率提升。随着功率密度受限、工艺微缩成本激增,架构师转向领域专用化:为特定应用优化硅资源,以牺牲灵活性换取效率。
领域专用架构通过以下原则实现高性能与能效:
- 定制数据通路:针对目标应用优化处理路径,直接硬件实现常用操作。例如 AI 加速器的矩阵乘法单元采用脉动阵列——网格状处理单元,数据在邻近单元间有节奏地流动,专为神经网络设计。
- 专用存储层次结构:围绕领域访问模式与数据复用优化内存系统,包括定制缓存、预取逻辑、专用内存控制器。
- 减少指令开销:实现领域专用指令集,将常用操作序列编码为单指令,降低解码与调度复杂度,提升性能与能效。
- 直接硬件实现:为高频操作设计专用电路,无需软件干预,消除指令处理开销,最大化吞吐。
这些原则在智能手机中有直观体现。现代手机可在几瓦功耗下解码 4K/60fps 视频,依赖专用硬件编解码器(如 H.264/AVC、H.265/HEVC),效率比软件解码高 100–1000$\times$。
专用化趋势持续加速,基因组学、区块链等新领域也涌现出定制加速器。基因组加速器优化序列比对与变异检测,大幅缩短 DNA 分析时间。区块链 ASIC9 针对加密哈希极致优化,比 CPU 能效高 10 万倍,但算法一变即报废(如 2022 年以太坊转 PoS,50 亿美元 ASIC 失效)。这些案例说明领域专用架构已成为应对现代计算复杂性与多样性的根本变革。
机器学习硬件专用化
机器学习具备独特的计算特性,推动了专用硬件架构的发展。与传统负载的非规则内存访问、指令流多样不同,神经网络以密集矩阵乘法、规律数据流、低精度容忍为特征。这些特性使专用硬件优化成为可能,带来远超通用计算的加速效果。
ML 加速器定义
机器学习加速器 是专为高效执行神经网络主导计算模式而设计的专用硬件。其优化对象为 矩阵乘法、张量操作 和 可预测数据流,能效比通用处理器高 100-1000×。ML 加速器覆盖从毫瓦级边缘设备到千瓦级数据中心,统一特征为:并行处理阵列、专用存储层次结构、低精度算术支持。
机器学习的计算需求暴露了传统处理器的局限。CPU 在神经网络负载下利用率仅 5-10%,算力约 100 GFLOPS1,功耗却高达数百瓦。其根本原因在于架构错配:CPU 优化单线程与非规则内存,神经网络则需大规模并行与可预测数据流。内存带宽10成为瓶颈:单层神经网络需访问数 GB 参数,远超为 KB 级工作集设计的 CPU 缓存层次11。
数据搬运的能耗主导加速器设计。DRAM 访问约需 640pJ,乘加仅 3.7pJ,能耗比达 173×(具体视工艺与设计而定),因此最小化数据流成为首要优化目标。这也解释了 GPU 到定制神经网络加速器的演进。GPU 通过大规模并行实现 15,000+ GFLOPS,但受限于图形架构。TPU 等定制加速器通过脉动阵列等机制,将利用率提升至 85% 以上,最大化数据复用、最小化搬运。
训练与推理的计算特性差异显著,影响加速器设计。训练需高精度(FP32/FP16)、双向数据流(反向传播)、大容量内存。推理可用低精度(INT8/INT4)、仅前向计算、优先延迟。数据中心训练加速器(如 NVIDIA H100、TPUv4)追求极致吞吐,功耗高达 700W,以天为单位缩短模型开发周期,带来数百万美元的运营成本节省。边缘部署则需极致能效,采用存算一体、动态电压调节、类脑架构等技术,实现毫瓦级持续运行。
应用场景决定架构选型。数据中心训练追求极致吞吐,边缘设备需能效与实时性,移动端平衡性能与续航,车载系统优先确定性响应。由此催生了丰富的专用加速器生态,各自针对特定场景与需求优化。
专用加速器的成功证明,没有单一架构能高效覆盖所有 ML 负载。2030 年预计将有 1560 亿台边缘设备,需能效与实时性优化架构;云端训练则持续突破算力极限。这一多样性驱动了专用架构的持续创新。
硬件专用化的演进揭示了一个系统原则:新计算模式出现并成熟后,硬件专用化随之而来,实现性能与能效最优。机器学习加速正是这一原则的典型体现。与追求灵活性的通用处理器不同,专用加速器针对明确负载优化执行,平衡性能、能效与软件集成。
下表总结了硬件专用化的关键里程碑,展示了各时代如何针对主流负载定制架构。这些加速器虽最初为特定领域设计,但其架构策略已成为现代系统的通用基石。理解这一历史,有助于分析专用化如何持续推动机器学习在多样环境下的高效执行。
| 时代 | 计算模式 | 架构示例 | 特征 |
|---|---|---|---|
| 1980s | 浮点与信号处理 | FPU、DSP | 单一功能引擎、精简指令集、协处理器接口 |
| 1990s | 3D 图形与多媒体 | GPU、SIMD 单元 | 大量同构计算单元、规律数据模式、宽内存接口 |
| 2000s | 实时媒体编解码 | 媒体编解码器、网络处理器 | 固定功能流水线、高吞吐处理、能效优化 |
| 2010s | 深度学习张量运算 | TPU、GPU 张量核心 | 矩阵乘法单元、大规模并行、内存带宽优化 |
| 2020s | 应用专用加速 | ML 引擎、智能网卡、领域加速器 | 负载定制数据通路、专用存储层次、应用优化设计 |
这一历史进程揭示了反复出现的模式:每一波硬件专用化都源于计算瓶颈(如图形渲染、媒体编码、神经网络推理)。2020 年代的不同之处在于专用化的普及性:AI 加速器已成为 YouTube 推荐、自动驾驶目标检测等应用的基础。与早期加速器不同,现代 AI 硬件需与动态软件框架深度集成,并支持云到边的全场景扩展。表格不仅总结了历史,也指明了未来高定制、高影响力计算平台的发展方向。
AI 加速的转型带来了超越硬件设计的挑战。机器学习加速器需与 TensorFlow、PyTorch、JAX 等主流框架无缝协作,确保跨硬件平台一致部署。编译器与运行时支持变得关键,图级优化、算子融合、内存调度等高级技术决定了专用加速器的实际效能。
可扩展性进一步增加了复杂度。AI 加速器需覆盖从高吞吐数据中心到资源受限的边缘与移动设备,需针对不同场景优化性能与能效。异构计算12环境下,专用单元需与 CPU、GPU 协同,要求高度的互操作性。
AI 加速器代表着系统级的变革,要求软硬件深度耦合。这一变革体现在三类计算原语上,决定了加速器设计的核心特征。理解这些原语,有助于把握 100-1000$\times$ 性能提升背后的架构与优化策略。
从浮点协处理器到 AI 加速器的演进,始终遵循“计算瓶颈驱动专用硬件”的规律。Intel 8087 针对占科学计算 80% 时间的浮点运算,现代 AI 负载则更极端——矩阵乘法与卷积占神经网络 95% 以上计算。这种高度集中为专用化带来前所未有的机会,解释了 AI 加速器为何能比通用处理器快 100-1000$\times$。
几十年硬件演进确立的原则——识别主导操作、定制数据通路、优化内存访问——如今指导着 AI 加速器设计。但神经网络的极端并行性、可预测数据流、低精度容忍等新特性,又催生了全新的架构方法。理解这些计算原语,有助于把握现代加速器如何将 第 10 章:模型优化 的理论效率转化为实际性能。这些软硬件协同优化,正是从 第 2 章:机器学习系统 到云端推理系统落地的关键。
在深入分析这些计算原语前,需理解支撑其高效执行的架构组织。现代 AI 加速器通过三大子系统协同,实现数量级性能提升。
处理基底由大量处理单元阵列组成,每个单元内含针对特定操作优化的计算单元:张量核心负责矩阵乘法,向量单元处理逐元素操作,特殊功能单元计算激活函数。这些单元以网格拓扑组织,实现大规模并行,充分挖掘神经网络的数据级并行性。
存储层次结构同样关键。高带宽内存为众多处理单元提供数据吞吐,多级缓存(L2、L1、scratchpad)最小化数据搬运能耗。AI 加速器的设计原则是:数据搬运能耗远高于计算,必须通过数据复用、就近存储等策略优化。
主机接口则实现加速器与系统的协同,通用 CPU 负责控制流与系统管理,加速器专注于神经网络的密集并行运算。这种分工体现了系统级专用化。
下图展示了现代 AI 加速器的架构组织,说明了专用计算单元、分层存储与主机接口如何协同优化 AI 负载。

AI 计算原语
理解 AI 专用硬件演进,需剖析驱动这一变革的计算模式。从通用 CPU 的 100 GFLOPS 到专用加速器的 100,000+ GFLOPS,正是对主导机器学习负载的计算模式进行架构优化的结果。这些模式,即“计算原语”,在各类神经网络架构中反复出现,无论应用领域或模型规模如何。
现代神经网络基于少数核心计算模式构建。无论是全连接、卷积还是注意力层,底层操作本质都是输入与权重的乘加累加。正是这种重复的乘加过程主导了神经网络的执行,定义了 AI 负载的算术基础。其规律性与高频性催生了 AI 计算原语:硬件级抽象,专为高效执行这些核心运算而设计。
神经网络具备高度结构化、数据并行的计算特性,极适合架构专用化。基于 第 11 章:AI 加速 介绍的并行化原则,这些模式强调可预测的数据复用与固定操作序列。AI 计算原语将这些模式提炼为可复用的架构单元,支撑高吞吐、低能耗的执行。
如下代码(示例 1)展示了框架层面的 dense 层定义:
示例 1:Dense 层定义:通过高层 API 定义 dense 层,体现神经网络对输入张量的并行变换。
dense = Dense(512)(input_tensor)
该高层调用在数学上展开如示例 2:
示例 2:层计算:神经网络每层输出由加权输入求和与激活函数变换组成。
output = matmul(input_weights) + bias
output = activation(output)
在处理器层面,计算归结为嵌套循环,依次乘加输入与权重、累加结果、应用非线性函数,如示例 3:
示例 3:嵌套循环:通过顺序矩阵乘加与偏置累加,再经激活函数得到最终输出。
for n in range(batch_size):
for m in range(output_size):
sum = bias[m]
for k in range(input_size):
sum += input[n, k] * weights[k, m]
output[n, m] = activation(sum)
这一转化揭示了四大计算特性:数据级并行(可同时执行)、结构化矩阵运算(定义负载)、可预测数据流(驱动存储优化)、高频非线性变换(催生专用功能单元)。
AI 计算原语的设计遵循三大标准:一是高频使用,值得专用硬件资源;二是专用实现能带来显著性能或能效提升;三是跨神经网络架构代际保持稳定。向量操作、矩阵操作、特殊功能单元正是现代 ML 加速器的基础原语,共同支撑高效、可扩展的神经网络执行。
向量操作
向量操作通过同时处理多个数据元素,实现硬件加速的第一层级。这种并行性存在于神经元、层乃至整个网络,是高效神经网络执行的基础。框架层代码最终转化为硬件指令,凸显向量处理在神经加速器中的关键作用。
高层框架操作
机器学习框架通过高层抽象屏蔽硬件复杂性。这些抽象逐步分解为底层操作,暴露硬件加速机会。如下示例 4 展示了线性层的执行流程:
示例 4:线性层:神经网络通过线性映射将输入数据变换到高维空间,实现复杂特征提取。
layer = nn.Linear(256, 512) # 256 输入,512 输出
output = layer(input_tensor) # 批量处理输入
该抽象在数学上如示例 5:
示例 5:全连接层:每个输出为所有输入加权求和加偏置,再经激活函数变换。线性变换是神经网络复杂结构的基础。
Z = matmul(weights, input) + bias # 每个输出依赖所有输入
output = activation(Z) # 对每个结果变换
处理器执行时进一步分解为嵌套乘加操作,如示例 6:
示例 6:线性层计算:每个输出神经元由所有输入特征加权求和,再经激活函数。理解此过程有助于把握神经网络的基本构建块。
for batch in range(32): # 批量处理 32 个样本
for out_neuron in range(512): # 计算每个输出神经元
sum = 0.0
for in_feature in range(256): # 每个输出依赖所有输入
sum += input[batch, in_feature] * weights[out_neuron, in_feature]
output[batch, out_neuron] = activation(sum + bias[out_neuron])
顺序标量执行
传统标量处理器顺序执行上述操作,逐个处理数据。以 32 批量为例,输出计算需 400 万次乘加,每次需加载输入与权重、相乘、累加。面对神经网络的海量同构操作,顺序执行极其低效。
现代处理器通过向量处理彻底改变了这一模式。
并行向量执行
向量处理单元可同时处理多个数据元素。如下 RISC-V13 汇编展示了现代向量处理能力:
vsetvli t0, a0, e32 # 每次处理 8 个元素
loop_batch:
loop_neuron:
vxor.vv v0, v0, v0 # 清空 8 个累加器
loop_feature:
vle32.v v1, (in_ptr) # 一次加载 8 个输入
vle32.v v2, (wt_ptr) # 一次加载 8 个权重
vfmacc.vv v0, v1, v2 # 8 路乘加
add in_ptr, in_ptr, 32 # 下 8 个输入
add wt_ptr, wt_ptr, 32 # 下 8 个权重
bnez feature_cnt, loop_feature
该实现每次并行处理 8 个数据,显著减少计算时间与能耗。向量加载指令一次传输 8 个值,最大化带宽利用。向量乘加指令并行处理 8 对数据,总指令数由 400 万降至约 50 万。
为便于理解向量指令与深度学习模式的映射,下表(表 2)介绍了常见向量操作及其在神经网络中的应用,如归约、gather、scatter、掩码操作等。这些操作广泛用于池化、嵌入查找、注意力机制等层。
| 向量操作 | 描述 | 神经网络应用 |
|---|---|---|
| 归约 | 跨向量元素聚合(如求和、最大值) | 池化层、注意力分数计算 |
| Gather | 加载多个非连续内存元素 | 嵌入查找、稀疏操作 |
| Scatter | 写入多个非连续内存位置 | 嵌入梯度更新 |
| 掩码操作 | 有选择地处理向量元素 | 注意力掩码、填充处理 |
| 向量 - 标量广播 | 标量作用于所有向量元素 | 偏置加法、缩放操作 |
向量处理不仅减少指令数量,还提升带宽利用与能效。多值并行加载提升内存带宽利用,控制逻辑复用提升能效。这些优势在深层神经网络中成倍放大,每次前向传播需执行数十亿次操作。
向量处理历史
向量操作自 70-80 年代起就是高性能计算的核心。Cray-114 等早期超级计算机通过专用向量单元,实现了对大规模数据的高效并行处理。其 64 元素向量寄存器与流水线单元,奠定了现代 AI 加速器“专用硬件流水线并行处理”的架构模板。
这些理念在机器学习中重现。神经网络的结构极适合向量化执行,向量加法、乘法、归约等操作成为主导。虽然现代 AI 加速器的规模与专用化程度远超前人,但底层架构原则一脉相承。向量处理在神经网络加速中的复兴,凸显了其高效计算的价值。
向量操作为神经网络加速奠定了基础,实现了独立数据元素的高效并行处理。其擅长逐元素变换(如激活函数),但神经网络还需跨多维度的结构化运算——即矩阵操作。下节将介绍矩阵操作这一架构原语。
矩阵操作
矩阵操作是神经网络的计算主力,通过结构化权重、激活与梯度,实现高维数据的变换。与向量操作的独立处理不同,矩阵操作可跨多维度协同计算,是硬件加速的核心驱动力。
神经网络中的矩阵操作
神经网络计算可分解为层次化的矩阵操作。如下示例 8,线性层通过矩阵变换实现输入到输出的映射:
示例 8:矩阵操作:神经网络通过矩阵乘法与偏置,实现输出预测。训练需管理输入批量与激活函数,优化模型性能。
layer = nn.Linear(256, 512) # 层将 256 维输入变换为 512 维输出
output = layer(input_batch) # 批量处理 32 个样本
# 框架内部:核心操作
Z = matmul(weights, input) # 矩阵:将 [256 x 32] 输入变为 [512 x 32] 输出
Z = Z + bias # 向量:对每个输出加偏置
output = relu(Z) # 向量:对每个元素激活
该计算展示了矩阵操作的规模。每个输出神经元(共 512 个)需处理所有输入特征(256 个),每批次 32 个样本。权重矩阵包含 $256\times512=131,072$ 参数,凸显高效矩阵乘法对性能的决定性作用。
神经网络在多种架构模式下广泛应用矩阵操作。
神经网络中的矩阵计算类型
矩阵操作在现代神经网络架构中反复出现,如下代码。卷积操作通过 im2col 技术15转化为矩阵乘法,便于在硬件上高效执行。
hidden = matmul(weights, inputs)
# weights: [out_dim x in_dim], inputs: [in_dim x batch]
# 结果为每个输出聚合所有输入
# 注意力机制 - 多次矩阵操作
Q = matmul(Wq, inputs)
# 输入投影到查询空间 [query_dim x batch]
K = matmul(Wk, inputs)
# 输入投影到键空间 [key_dim x batch]
attention = matmul(Q, K.T)
# 所有查询与所有键对比 [query_dim x key_dim]
# 卷积 - 预处理后矩阵乘法
patches = im2col(input)
# 将 [H x W x C] 图像转为 patch 矩阵
output = matmul(kernel, patches)
# 所有 patch 同时应用卷积核
这种普遍的矩阵乘法模式,直接影响硬件设计。高效矩阵操作的需求推动了专用硬件架构的发展。下节将分析现代 AI 加速器如何实现矩阵操作,聚焦其架构特性与性能优化。
矩阵操作的硬件加速
矩阵操作的计算需求推动了专用硬件优化。现代处理器实现了超越向量处理能力的专用矩阵单元。如下示例 10:
示例 10:矩阵单元操作:硬件加速系统中高效块级矩阵乘加,展示专用单元如何简化 AI/ML 关键计算。
mload mr1, (weight_ptr) # 加载如 16x16 权重块
mload mr2, (input_ptr) # 加载对应输入块
matmul.mm mr3, mr1, mr2 # 整块乘加
mstore (output_ptr), mr3 # 存储输出块
该矩阵单元可一次处理 $16\times16$ 块(256 次乘加),远超向量处理的 8 次。矩阵操作与向量操作互补,实现了多对多的结构化变换。二者的协同决定了神经网络执行的效率。
矩阵操作通过多维并行处理,为神经网络提供了算力(见表 3)。其支撑注意力、卷积等变换,但性能依赖高效数据处理。向量操作则擅长一对一变换,如激活、归一化。二者的区分凸显了数据流模式在神经加速器设计中的重要性。
| 操作类型 | 最适用场景 | 示例 | 关键特性 |
|---|---|---|---|
| 层变换 | |||
| 矩阵操作 | 多对多变换 | 注意力计算、卷积、激活函数 | 每个输出依赖多个输入 |
| 向量操作 | 一对一变换 | 层归一化、元素级梯度 | 每个输出仅依赖对应输入 |
矩阵计算的历史基础
矩阵运算长期以来一直是计算数学的基石,广泛应用于数值模拟、图形处理等领域。矩阵乘法和变换的结构化特性,使其自早期计算架构起就成为加速优化的重点。20 世纪 80、90 年代,专用数字信号处理器(DSP)和图形处理单元(GPU)针对矩阵计算进行了深度优化,极大提升了图像处理、科学计算和 3D 渲染等负载的效率。
随着机器学习的普及,高效矩阵计算的重要性进一步凸显。神经网络本质上依赖矩阵乘法和张量操作,这推动了超越传统向量处理的专用硬件架构的发展。现代张量处理单元(TPU)和 AI 加速器大规模实现矩阵乘法,其架构原则与早期科学计算和图形负载一脉相承。矩阵中心化架构的复兴,彰显了经典数值计算与当代 AI 加速之间的深层联系。
然而,虽然矩阵运算为神经网络提供了计算主干,但它只是加速挑战的一部分。神经网络还高度依赖非线性变换,这些变换无法仅通过线性代数高效表达。
特殊功能单元(SFU)
向量和矩阵操作高效处理神经网络中的线性变换,但非线性函数则带来了独特的计算挑战,需要专用硬件方案。特殊功能单元(SFU)为这些关键运算提供硬件加速,补齐了高效神经网络执行所需的基础处理原语。
非线性函数
非线性函数是机器学习的核心,使神经网络能够建模复杂关系。下例(示例 11)展示了典型的神经网络层序列。
示例 11:非线性变换:神经网络通过线性变换与非线性激活的组合处理输入数据,捕捉复杂模式,增强模型表达力与学习能力。
layer = nn.Sequential(
nn.Linear(256, 512), nn.ReLU(), nn.BatchNorm1d(512)
)
output = layer(input_tensor)
该序列引入了多重非线性变换,远超简单矩阵操作。下例(示例 12)展示了框架如何将这些操作分解为数学组件。
示例 12:非线性变换:神经网络通过线性与非线性操作,将输入数据转化为可供学习的特征。机器学习模型借助这些变换高效捕捉数据中的复杂模式。
Z = matmul(weights, input) + bias # 线性变换
H = max(0, Z) # ReLU 激活
mean = reduce_mean(H, axis=0) # BatchNorm 均值
var = reduce_mean((H - mean) ** 2) # 方差计算
output = gamma * (H - mean) / sqrt(var + eps) + beta
# 归一化
这些操作在传统处理器上的实现复杂度极高。看似简单的数学运算,实际需大量指令序列。例如 BatchNorm 的平方根计算需多次数值迭代,Softmax 等操作中的指数函数需级数展开或查表。即便是简单的 ReLU 激活,也会引入分支逻辑,影响指令流水线(见示例 13)。
示例 13:ReLU 与 BatchNorm 操作:神经网络处理输入数据时涉及条件操作,可能导致流水线停顿,归一化还需多次遍历数据,凸显传统实现的效率瓶颈。来源:IEEE Spectrum
for batch in range(32):
for feature in range(512):
# ReLU:需分支预测,可能流水线停顿
z = matmul_output[batch, feature]
h = max(0.0, z) # 条件操作
# BatchNorm:多次遍历数据
mean_sum[feature] += h # 第一次遍历求均值
var_sum[feature] += h * h # 第二次遍历求方差
temp[batch, feature] = h # 需额外内存存储
# 归一化需复杂算术
for feature in range(512):
mean = mean_sum[feature] / batch_size
var = (var_sum[feature] / batch_size) - mean * mean
# 平方根计算:多次迭代
scale = gamma[feature] / sqrt(var + eps) # 迭代近似
shift = beta[feature] - mean * scale
# 最终输出需再次遍历
for batch in range(32):
output[batch, feature] = temp[batch, feature] *
scale + shift
这些操作带来如下主要低效点:
- 多次遍历数据,增加内存带宽需求
- 复杂算术,需大量指令周期
- 条件操作,可能导致流水线停顿
- 中间结果需额外内存存储
- 向量单元利用率低
具体而言,BatchNorm 需多次遍历数据:一次求均值,一次求方差,最后输出变换。每次都需通过存储层次加载和存储数据。数学表达式简单的操作,实际需大量指令。平方根通常需 10-20 次数值迭代(如牛顿法)才能达到精度。ReLU 的 max 操作需分支指令,可能导致流水线停顿。实现还需临时存储中间值,增加内存占用和带宽消耗。向量单元虽擅长规则运算,但指数、平方根等常需标量操作,难以充分利用向量能力。
硬件加速
SFU 通过专用硬件实现,解决上述低效问题。现代 ML 加速器集成了专用电路,将复杂操作转化为单周期或固定延迟运算。加速器可一次加载向量数据,直接应用非线性函数,无需多次遍历和复杂指令序列(见示例 14)。
示例 14:硬件加速:单周期非线性操作使 ML 加速器高效向量处理,专用硬件极大降低计算延迟。
vld.v v1, (input_ptr) # 加载向量
vrelu.v v2, v1 # 单周期 ReLU
vsigm.v v3, v1 # 固定延迟 sigmoid
vtanh.v v4, v1 # 硬件 tanh
vrsqrt.v v5, v1 # 快速倒数平方根
每个 SFU 通过专用电路实现特定函数。例如,ReLU 单元用专用逻辑完成比较与选择,消除分支开销。平方根用硬件牛顿法等算法,固定迭代次数,保证延迟。指数、对数等常用查表 + 硬件插值(Costa 等,2019)。通过这些定制指令,SFU 消除了多次遍历、复杂算术序列,保持高效。下表(表 4)展示了常见硬件实现及典型延迟。
| 功能单元 | 操作 | 实现策略 | 典型延迟 |
|---|---|---|---|
| 激活单元 | ReLU、sigmoid、tanh | 分段近似电路 | 1-2 cycles |
| 统计单元 | 均值、方差 | 并行归约树 | log(N) cycles |
| 指数单元 | exp、log | 查表 + 硬件插值 | 2-4 cycles |
| 根/幂单元 | sqrt、rsqrt | 固定迭代牛顿法 | 4-8 cycles |
SFU 的历史
高效非线性函数计算的需求,数十年来一直影响着计算机体系结构。早期处理器就集成了对对数、三角等复杂函数的硬件支持,以加速科学计算和信号处理。70-80 年代,浮点协处理器专门处理复杂数学运算。90 年代,Intel SSE、ARM NEON 等指令集扩展为多媒体和信号处理提供了向量化数学变换的专用硬件。
机器学习负载重新激发了对专用功能单元的强烈需求。激活函数、归一化层、指数变换等成为神经网络计算的基础。现代 AI 加速器不再依赖软件近似,而是为这些操作实现了高速、固定延迟的 SFU,重现了科学计算领域的历史趋势。SFU 的回归,体现了硬件演进的周期性——领域需求推动经典架构理念在新计算范式下的重塑。
向量、矩阵与特殊功能单元的结合,为现代 AI 加速器提供了计算基础。但这些原语的高效利用,关键在于数据流动与访问模式。下文将探讨支撑神经网络高效执行的数据流架构、存储层次与优化策略。
计算单元与执行模型
前述向量、矩阵与特殊功能单元,是 AI 加速器的基础计算原语。现代 AI 处理器将这些原语封装为不同的执行单元,如 SIMD 单元、张量核心、处理单元(PE),决定了计算结构与用户可见的性能特征。理解这种组织,有助于开发者把握 AI 加速器的理论能力与实际表现。
从原语到执行单元的映射
从计算原语到执行单元的演进,体现了 AI 加速器日益复杂与专用化的结构层次:
- 向量操作 → SIMD/SIMT 单元,实现独立数据元素的并行处理
- 矩阵操作 → 张量核心、脉动阵列,实现结构化矩阵乘法
- 特殊函数 → 集成于处理单元的专用硬件
每个执行单元将这些计算原语与专用存储、控制机制结合,优化性能与能效。这种结构化封装,使硬件厂商既能提供标准化编程接口,又能在底层实现多样化架构以适应不同负载需求。执行单元的选择直接影响系统效率,包括数据局部性、计算密度与负载适应性。后续章节将分析这些执行单元如何在 AI 加速器中协同工作,最大化不同机器学习任务的性能。
SIMD 到 SIMT 架构的演进
单指令多数据(SIMD)16执行模式,将同一操作并行应用于多个数据元素,极大减少指令开销、提升数据吞吐。该模式广泛用于加速数据并行性强的负载,如神经网络。ARM SVE(Scalable Vector Extension)是现代 SIMD 高效实现的代表,见示例 15。
ptrue p0.s # 创建向量长度谓词
ld1w z0.s, p0/z, [x0] # 加载输入向量
fmul z1.s, z0.s, z0.s # 元素乘法
fadd z2.s, z1.s, z0.s # 元素加法
st1w z2.s, p0, [x1] # 存储结果
处理器架构不断扩展 SIMD 能力以满足增长的计算需求。Intel AMX(2021)、ARM SVE2(Stephens 等,2017)等架构提供灵活的 SIMD 执行,便于软件跨硬件扩展。
为突破 SIMD 局限,SIMT 允许多个独立线程并行执行,每个线程有独立程序计数器和架构状态。该模式天然适合矩阵计算,每个线程处理不同任务片段,同时共享指令流。在 NVIDIA GPU 架构中,每个流多处理器(SM)[^fn-streaming-multiprocessor]可协调数千线程并行,极大提升神经网络计算效率(见示例 16)。线程被组织为 warp[^fn-warp],是 SIMT 的基本执行单元。
示例 16:SIMT 执行:每个线程并行处理唯一输出元素,展示 SIMT 如何高效实现 GPU 上的矩阵乘法。
__global__ void matrix_multiply(float* C, float* A, float*
B, int N) {
// 每个线程处理一个输出元素
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
for (int k = 0; k < N; k++) {
// warp 内线程并行执行
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
SIMT 让神经网络计算可高效扩展至数千线程,并支持分支执行。AMD RDNA、Intel Xe 等架构也采用类似模型,SIMT 已成为 AI 加速的基础机制。
张量核心
SIMD/SIMT 单元高效执行向量操作,但神经网络高度依赖矩阵计算,需要专用单元实现结构化多维处理。矩阵操作的能耗经济性推动了这一专用化:标量处理每次需多次 DRAM 访问(640pJ),张量核心则将能耗分摊到整个矩阵块。张量处理单元通过专用硬件块,实现整块矩阵乘加,将能耗重心从内存搬运(173×)转为计算(3.7pJ),极大提升效率。
张量核心17(如 NVIDIA Ampere GPU)是典型代表。它们通过专用指令暴露矩阵计算能力,如 NVIDIA A100 的张量核心操作(示例 17)。
Tensor Core Operation (NVIDIA A100):
mma.sync.aligned.m16n16k16.f16.f16
{d0,d1,d2,d3}, // 目标寄存器
{a0,a1,a2,a3}, // 源矩阵 A
{b0,b1,b2,b3}, // 源矩阵 B
{c0,c1,c2,c3} // 累加器
单条张量核心指令可处理整个矩阵块,并将中间结果保存在本地寄存器,效率远超标量或向量实现。这种结构化方法让硬件实现高吞吐,同时简化了软件层的循环展开与数据管理。
张量处理单元架构因设计目标而异。NVIDIA Ampere 优化通用深度学习加速,Google TPUv4 采用大规模脉动阵列,追求训练吞吐,Apple M1 神经引擎18集成小型矩阵处理器,适配移动端推理,Intel Sapphire Rapids 引入 AMX tile,面向数据中心高性能。
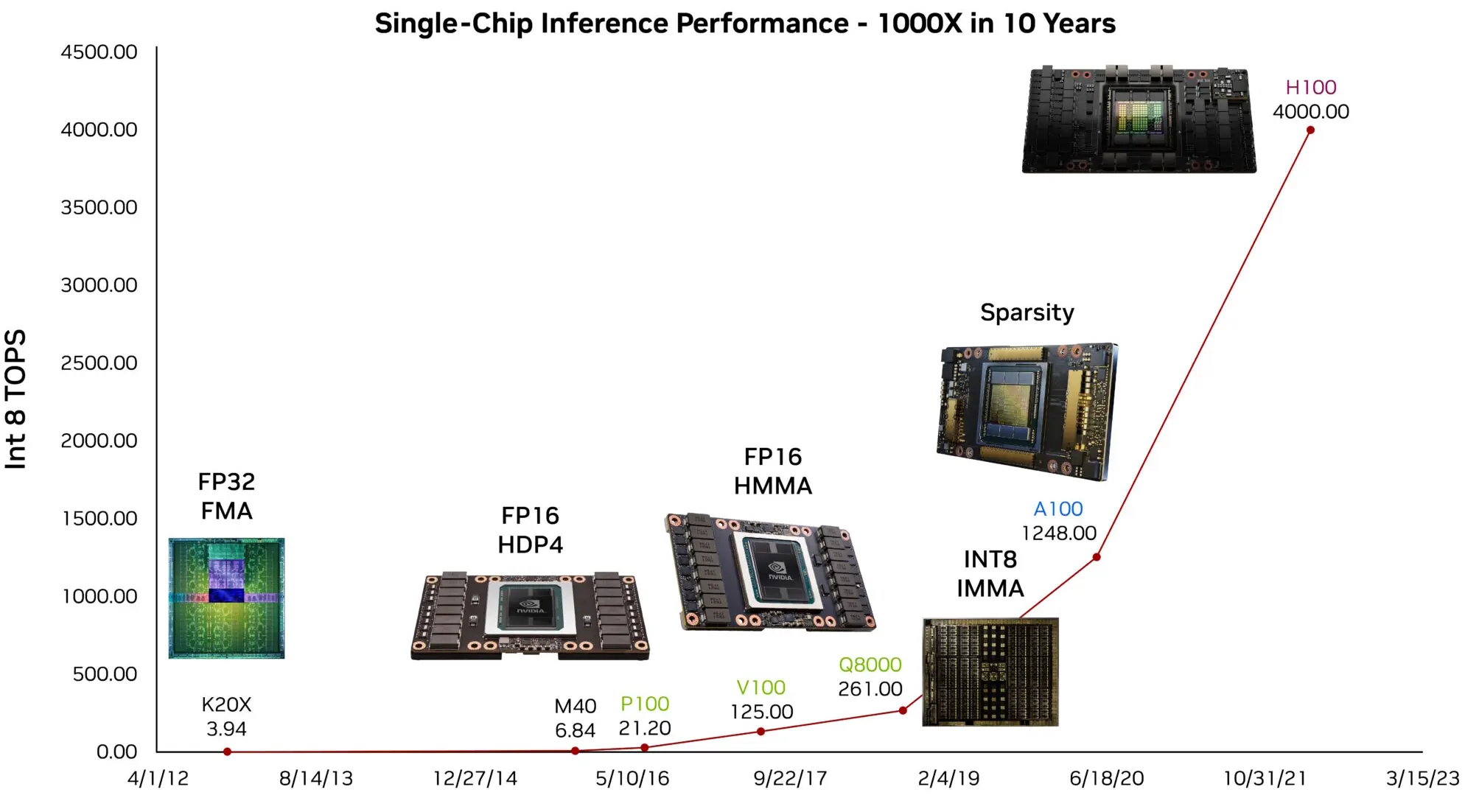
AI 硬件专用化带来了深度学习负载的巨大性能提升。下图(图 3)展示了 NVIDIA GPU AI 加速器性能的演进,从通用浮点单元到高度优化的张量核心。
处理单元(PE)
最高层次的执行单元组织,将多个张量核心与本地存储集成为处理单元(PE)。PE 是许多 AI 加速器的基本构建块,集成了向量单元(逐元素操作)、张量核心(矩阵计算)、特殊功能单元(非线性变换)及专用内存资源,优化数据局部性与搬运效率。
PE 在 AI 硬件中平衡了计算密度与内存访问效率。其设计因架构而异,以支持多样负载与可扩展性。Graphcore IPU 将计算分布在 1,472 个 tile,每个 tile 内含独立 PE,优化细粒度并行。Cerebras CS-2 集成 85 万个 PE,支持稀疏计算。Tesla D1 处理器将 PE 与大容量本地内存结合,优化自动驾驶实时吞吐与延迟。
PE 为大规模 AI 加速提供了结构基础,其效率不仅取决于算力,还受互连与存储层次设计影响。下文将探讨这些架构选择如何影响不同 AI 负载的性能。
张量处理单元通过硬件加速矩阵计算,实现了 AI 负载的高效能。随着架构对结构化稀疏性、负载定制优化的支持,PE 的作用持续演进。但其效能不仅取决于算力,还依赖于与存储层次、数据流机制的协同,后续章节将详细分析。
脉动阵列
张量核心将矩阵操作封装为结构化单元,脉动阵列则以连续数据流与操作数复用为优化目标。脉动架构的根本动因在于能效约束——通过架构设计最小化内存访问惩罚。脉动阵列将处理单元按网格排列,数据在单元间有节奏地流动,每个操作数在传播过程中参与多次计算,极大提升本地复用,减少外部内存访问。一份权重可在阵列内参与数十次运算,将能耗重心从内存搬运转为计算。
脉动阵列概念由 Kung 和 Leiserson19提出,正式用于高效矩阵运算的并行架构。与通用执行单元不同,脉动阵列利用空间与时间局部性,复用传播中的操作数。Google TPU 是典型代表。TPUv4 的 $128\times128$ 脉动阵列通过流水线方式处理矩阵运算,如图 4 所示。

脉动阵列通过同步数据流,实现高效并行。其结构包括:
- 控制单元:协调阵列时序与数据分发,保持全局同步
- 数据流:输入矩阵 A 横向、B 纵向流经阵列
- 处理单元网格:每个单元对流经数据执行乘加,累加部分结果
- 输出收集:边界聚合累加和,形成完整矩阵元素
同步数据流确保 A[i,k] 与 B[k,j] 在正确时刻相遇,执行 $C[i,j] = \sum A[i,k] \times B[k,j]$。操作数在多个单元间复用,极大减少内存带宽需求。
以 $2\times2$ 矩阵 A、B 为例,首周期 A[0,0]=2 横向、B[0,0]=1 纵向进入 PE(0,0),计算 2×1=2。下周期 A[0,0]=2 进入 PE(0,1) 与 B[0,1]=3 相遇,计算 2×3=6。A[0,1]=4 同时进入 PE(0,0) 参与下次运算。如此协调的数据流,使操作数在多个计算中复用,消除冗余内存访问,体现了脉动阵列的能效本质。
每个处理单元每周期执行一次乘加:
- 从上方接收输入激活
- 从左侧接收权重
- 相乘并累加到本地和
- 将激活向下、权重向右传递
这种结构化模型最小化全局内存与处理单元间的数据流,提高效率与可扩展性。脉动阵列以流式方式运行,特别适合深度学习训练与推理等高吞吐负载。
图 4 展示了一种常见实现,实际设计因用途而异。TPU 等训练架构采用大阵列追求吞吐,边缘推理则以小阵列优化能效。
核心原则始终一致:数据有序流经处理单元,输入横纵交错,累加部分和。但如 第 11 章:AI 加速 所述,实际效能最终受限于内存带宽。
$128\times128$ 脉动阵列每周期可执行 16,384 次运算,需持续供给新激活与权重,从片外内存经片上缓冲送至阵列边缘。TPU 片上带宽达 1,200 GB/s,利用率极高,但处理大模型时,带宽仍成瓶颈。
回顾 第 10 章:模型优化 ,量化通过将 FP32 权重转为 INT8,直接缓解带宽瓶颈,内存流量降 4 倍,使脉动阵列利用率提升。结构化剪枝则移除权重矩阵整行/列,减少数据流与计算。这些算法优化正因其直击内存瓶颈,才在实践中极具价值。
AI 加速中的数值精度
AI 加速器的效率不仅取决于算力,还受数值表示精度影响。数值格式的选择决定了精度、吞吐与能耗的平衡,影响 SIMD/SIMT、张量核心、脉动阵列等单元的设计与应用。
精度权衡
数值精度是现代 AI 加速器的关键设计参数。高精度带来稳定性与准确性,但功耗、带宽、吞吐成本高。寻找最优精度点已成为硬件架构的核心挑战。
早期深度学习模型主要用单精度浮点(FP32)训练与推理,虽稳定但效率低。随着模型增大,硬件逐步支持半精度(FP16)、bfloat16(BF16),在保证精度的同时降低内存与提升吞吐。近年,整数格式(INT8、INT4)在推理中崛起,极大提升能效,且精度损失可控。
高精度向低精度转变,深度嵌入硬件执行模型。如 第 11 章:AI 加速 所述,SIMD/SIMT 单元支持多精度,张量核心用低精度加速,脉动阵列过低精度提升复用、缓解带宽。
但深度学习模型并非总能用低比特表示。为此,现代加速器实现了混合精度计算,不同阶段采用不同格式。这些选择对模型公平性与可靠性有重要影响。例如,矩阵乘法用 FP16/BF16,累加用 FP32 防止精度损失。推理引擎用 INT8 算术,关键激活则保留高精度。
混合精度计算
现代 AI 加速器日益支持混合精度,不同阶段用不同数值格式。训练常用 FP16/BF16 乘法,累加用 FP32 保精度。推理则用 INT8/INT4,兼顾效率与精度。
这一趋势在硬件演进中尤为明显。早期如 NVIDIA Volta 仅支持 FP16,Turing、Ampere 扩展至 BF16、INT8、INT4。Ampere GPU 引入 TF32 兼顾 FP32/FP16,并广泛支持 BF16、INT8、INT4。见表 5。
| 架构 | 年份 | 张量核心支持精度 | CUDA 核心支持精度 |
|---|---|---|---|
| Volta | 2017 | FP16 | FP64, FP32, FP16 |
| Turing | 2018 | FP16, INT8 | FP64, FP32, FP16, INT8 |
| Ampere | 2020 | FP64, TF32, bfloat16, FP16, INT8, INT4 | FP64, FP32, FP16, bfloat16, INT8 |
表 5 显示新架构支持更多数值格式,反映了 AI 负载对灵活性的需求。未来加速器将持续扩展自适应精度,优化效率与精度平衡。
硬件数值格式影响深远。低精度减少执行单元与内存间数据量,降低带宽与存储需求。张量核心、脉动阵列可并行处理更多低精度元素,提升 FLOPS 吞吐。整数计算(如 INT8)能耗远低于浮点,推理场景尤为明显。
随着 AI 模型规模扩展,架构正向更高效数值格式演进。未来将引入自适应精度,按负载动态调整,进一步优化性能与能效。
架构集成
计算原语如何组织为执行单元,决定了 AI 加速器的效率。SIMD、张量核心、脉动阵列虽为基础构件,但其在芯片级的集成方式因架构而异。执行单元类型、精度支持、互连方式,决定了硬件能否高效扩展深度学习负载。
现代 AI 处理器因应用场景而权衡设计。NVIDIA A100 集成大量 FP16 张量核心,主攻训练;Google TPUv4 优先高吞吐 BF16 矩阵乘法;Intel Sapphire Rapids 集成 INT8 张量核心,优化推理;Apple M1 面向移动端,采用小型 FP16 PE。上述设计反映了精度与执行单元组织的灵活性,见表 6。
| 处理器 | SIMD 宽度 | 张量核心规模 | 处理单元数 | 主力负载 |
|---|---|---|---|---|
| NVIDIA A100 | 1024 位 | FP16 | 108 SMs | 训练、高性能计算 |
| Google TPUv4 | 128 宽 | BF16 | 2 核/芯片 | 训练 |
| Intel Sapphire | 512 位 AVX | INT8/BF16 | 56 核 | 推理 |
| Apple M1 | 128 位 NEON | FP16 | 8 NPU 核心 | 移动端推理 |
表 6 展示了不同架构为优化深度学习负载而配置的执行单元。训练加速器优先高吞吐浮点张量操作,推理处理器聚焦低精度整数,移动端则兼顾精度与能效。
性价比分析
架构规格定义了计算潜力,但实际部署需权衡不同加速器的性价比。单纯算力指标并不全面——现代 AI 加速的根本瓶颈是数据搬运效率。
前文已述,内存访问能耗远超计算,驱动了专用硬件革命。GPU 高带宽可达 40-60% 利用率,TPU 脉动阵列因极致数据复用可达 85%。
下表(表 7)给出主流加速器的性价比数据,但经济分析还需考虑利用率与能耗,这决定了实际性能。
| 加速器 | 标价(美元) | 峰值 FLOPS (FP16) | 内存带宽 | 性价比($/TFLOP) |
|---|---|---|---|---|
| NVIDIA V100 | ~$9,000 (2017-19) | 125 TFLOPS | 900 GB/s | $72/TFLOP |
| NVIDIA A100 | $15,000 | 312 TFLOPS (FP16) | 1,935 GB/s | $48/TFLOP |
| NVIDIA H100 | $25,000-30,000 | 756 TFLOPS (TF32) | 3,350 GB/s | $33/TFLOP |
| Google TPUv4 | ~$8,000* | 275 TFLOPS (BF16) | 1,200 GB/s | $29/TFLOP |
| Intel H100 | $12,000 | 200 TFLOPS (INT8) | 800 GB/s | $60/TFLOP |
例如,初创公司训练大模型可选 8 块 V100($72K,1,000 TFLOPS)或 4 块 A100($60K,1,248 TFLOPS)。但性能分析显示,Transformer 训练算术强度仅 0.5-2 FLOPS/字节,二者都受内存带宽限制。A100 的 1,935 GB/s 带宽比 V100 的 900 GB/s 高 2.15 倍,实际性能提升 115%,远超峰值 FLOPS 的 25%。再加上硬件成本低 17%、能效高 30%(每有效 TFLOP 400W vs 300W),A100 配置在多年部署中经济性更优。
这解释了新加速器虽单价更高却被快速采用。H100 的 $33/TFLOP 比 V100 优 54%,更重要的是 3,350 GB/s 带宽带来每美元 3.7 倍内存吞吐——这才是 Transformer 性能的决定性指标。云端部署更复杂,厂商通常按小时计费($2-4/h),购置与租用的盈亏点取决于利用率与能耗(3 年周期内占总成本 60-70%)。
框架选择也极大影响经济性——硬件 - 框架优化详见 第 7 章:AI 框架 ,性能评估方法见 第 12 章:AI 基准测试 。
执行单元决定加速器算力,但其效能根本受限于数据搬运与存储层次。高效利用算力需高效内存系统,最小化数据传输、优化局部性。理解这些约束,才能明白为何内存架构与计算设计同等重要。
AI 存储系统
前述 SIMD、张量核心、脉动阵列等执行单元,虽可实现 100-1000 TFLOPS 的神经网络算力,但若存储系统无法及时供数,理论能力难以落地。这一根本约束被称为 AI 内存墙,是现实加速器性能的主导瓶颈。
与传统负载不同,ML 模型需频繁访问大量参数、激活与中间结果,对内存带宽提出极高要求——这与 第 6 章:数据工程 中的数据管理策略密切相关。现代 AI 硬件通过分层存储、高效数据搬运与压缩等手段,提升执行效率与加速能力。
本节将从四个视角剖析存储系统设计。首先量化算力与带宽的扩展差距,揭示 AI 内存墙为何成为主导瓶颈。其次分析存储层次如何平衡速度、容量与能效,从片上 SRAM 到片外 DRAM 的分层结构。第三,剖析主机与加速器间的通信模式,揭示影响端到端性能的传输瓶颈。最后,分析不同神经网络架构(MLP、CNN、Transformer)对存储的压力模式,为硬件设计与优化提供依据。
理解 AI 内存墙
AI 内存墙是现代加速器性能的根本瓶颈——算力与带宽的扩展差距,使加速器难以发挥理论能力。虽然计算单元可通过向量、矩阵等原语每秒执行数百万次运算,但其完全依赖存储系统持续供给权重、激活与中间结果。
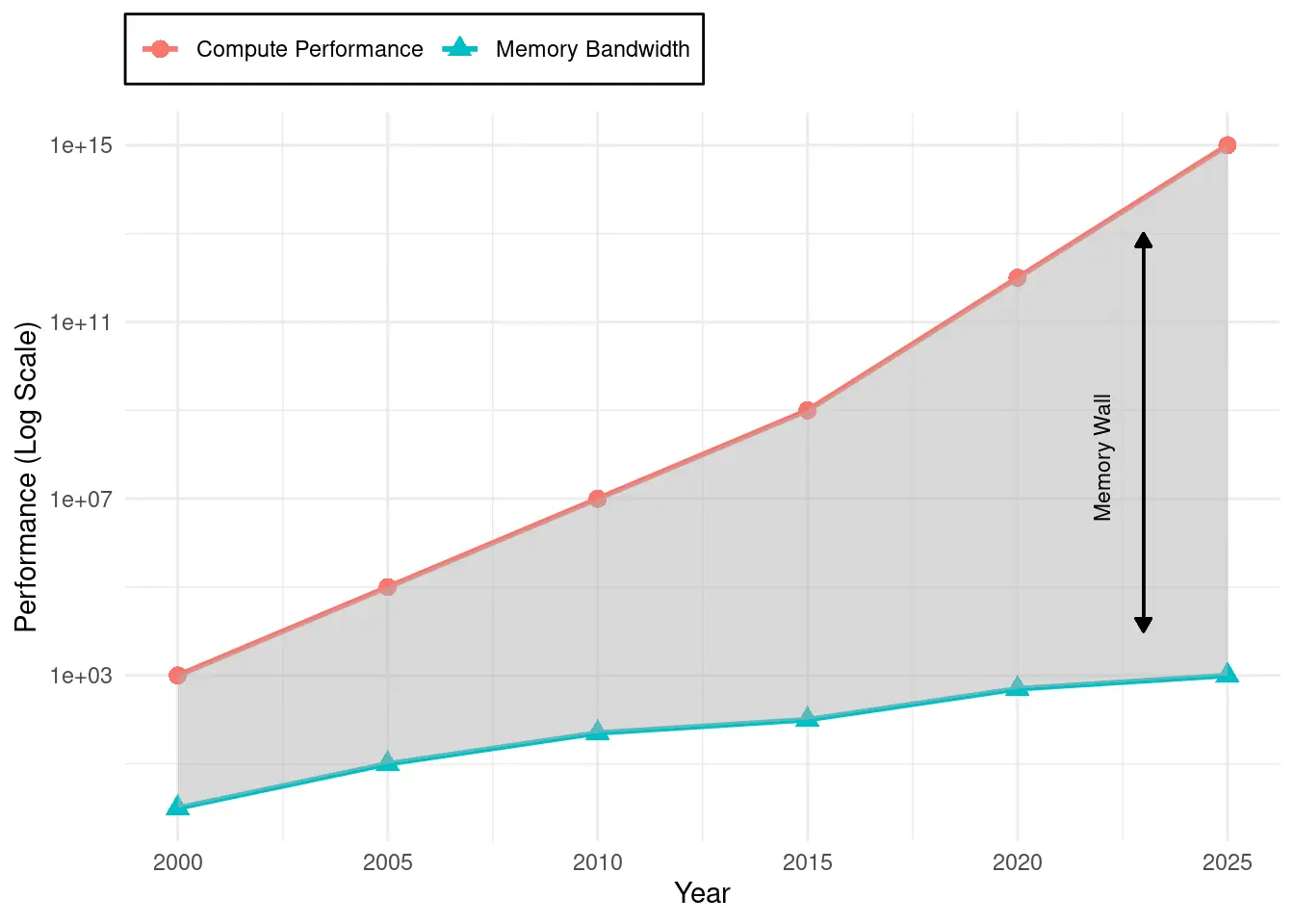
量化算力 - 内存性能差距
该约束的严重性可通过扩展趋势体现。过去 20 年,峰值算力每两年提升 3.0×,而 DRAM 带宽仅提升 1.6×。这一差距导致加速器虽有强大算力,却因数据供给不足而无法利用。现代硬件如 NVIDIA H100,算力 989 TFLOPS,带宽仅 3.35 TB/s,需每字节 295 次运算才能满载,远超神经网络常见的 1-10 次。
内存墙体现在三大约束:一是能耗差异——DRAM 访问 640pJ,计算仅 3.7pJ,能耗惩罚高达 173×,实际常受功耗而非算力限制;二是带宽限制——即便 TB/s 级带宽,也难以持续供给数千并行单元,典型负载下 50-70% 时间处于空闲;三是延迟层次——片外访问需数百周期,流水线停顿影响全局。
如图 5 所示,“AI 内存墙"持续扩大,使带宽而非算力成为 AI 加速的主约束。
除性能外,内存访问还带来巨大能耗。片外 DRAM 取数远高于算术运算。ML 模型参数大、访问频繁、数据流动不均,进一步加剧瓶颈。能耗差异驱动架构选择——Google TPU 通过脉动阵列与大容量片上存储,将能效提升 30-83$\times$。这些设计说明,能耗约束往往决定实际部署可行性。
ML 负载的内存访问模式
ML 负载因数据量大,对存储系统提出极高要求。与传统算力主导型应用不同,ML 负载以高数据搬运为特征。加速器效率不仅取决于算力,还取决于能否持续供数,避免等待与延迟。
神经网络执行涉及多种数据,每类数据访问模式各异:
- 模型参数(权重与偏置):大规模模型常含百万至十亿参数,高效存取权重是维持吞吐的关键。
- 中间激活:训练与推理均需暂存每层输出,深层网络激活占用显著内存。
- 梯度(训练时):反向传播需存取每个参数的梯度,进一步增加计算单元与存储间的数据流。
随着模型规模与复杂度提升,带宽与容量的提升变得至关重要。虽然专用计算单元加速了矩阵乘法等操作,但整体性能取决于能否持续高效地为处理单元供数。大规模 NLP、CV 应用常含百万至十亿参数,需最小化因数据搬运不畅导致的延迟与停顿。
可通过比较数据传输与计算所需时间来量化挑战。内存传输时间为 $$ T_{\text{mem}} = \frac{M_{\text{total}}}{B_{\text{mem}}}, $$ 其中 $M_{\text{total}}$ 为总数据量,$B_{\text{mem}}$ 为带宽。计算时间为 $$ T_{\text{compute}} = \frac{\text{FLOPs}}{P_{\text{peak}}}, $$ 即浮点运算数除以峰值算力 $P_{\text{peak}}$。若 $T_{\text{mem}} > T_{\text{compute}}$,系统即为内存受限,处理单元大部分时间在等待数据。此失衡凸显了存储优化与高效数据流策略的必要性。
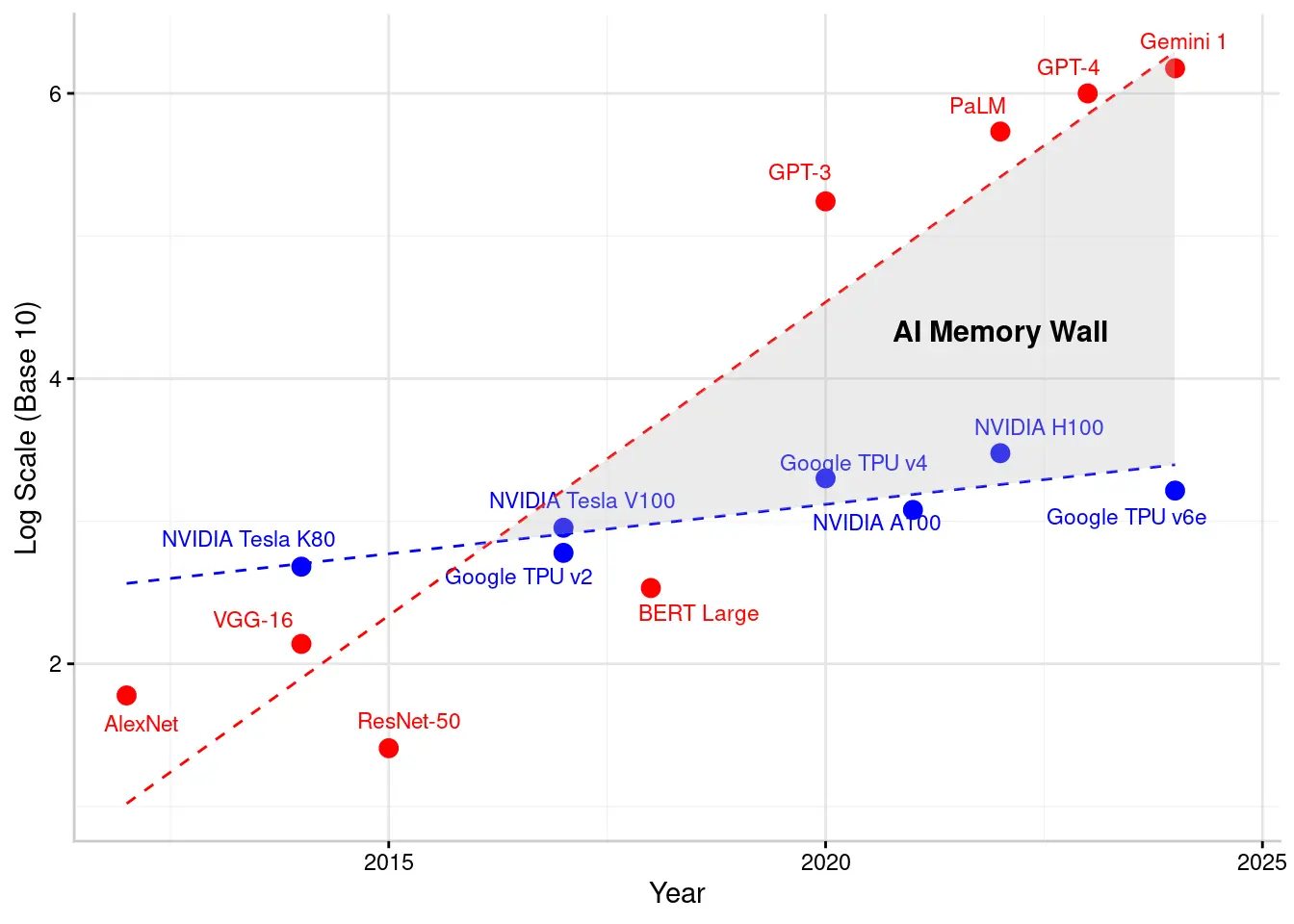
图 6 展示了模型规模与硬件带宽的扩展趋势,直观体现了“AI 内存墙”。图中红点为 AI 模型参数规模(如 2012 年 AlexNet ~62.3M,2023 年 Gemini 1 规模达万亿),蓝点为硬件带宽(NVIDIA GPU ~100-200 GB/s,TPU ~2-3 TB/s)。红线陡增,蓝线缓升,二者间阴影区即“AI 内存墙”,模型扩展远超带宽增长,需更复杂的存储管理与模型优化以维持效率。
非规则内存访问
与传统负载的结构化、可预测访问不同,ML 模型常表现出高度非规则的内存行为。其原因包括批量大小、层类型、稀疏性等。标准缓存与存储层次难以优化,导致延迟增加、带宽利用低下。
对比传统与 ML 负载的内存访问模式(见表 8),可见传统负载(如科学计算、数据库)常有良好局部性,易于缓存与预取。ML 负载则因稀疏性、注意力机制等,访问高度动态,难以用传统优化策略提升效率。
批量大小与执行顺序是非规则性的主要来源。小批量降低缓存复用,频繁访问片外内存;大批量虽提升复用,但对带宽需求更高,易造成层次拥堵。需在模型结构与硬件资源间权衡。
| 特性 | 传统计算负载 | 机器学习负载 |
|---|---|---|
| 访问模式 | 规律、可预测(如顺序读取、结构化模式) | 非规律、动态(如稀疏、注意力机制) |
| 缓存局部性 | 时间/空间局部性强 | 大模型常局部性差 |
| 数据复用 | 结构化循环,复用频繁 | 依层类型稀疏/动态复用 |
| 数据依赖 | 依赖明确,便于预取 | 依网络结构变化大 |
| 负载示例 | 科学计算(矩阵分解、物理仿真) | 神经网络(CNN、Transformer、稀疏模型) |
| 内存瓶颈 | DRAM 延迟、缓存未命中 | 片外带宽、内存碎片 |
| 能耗影响 | 中等,算术主导 | 高,数据搬运主导 |
不同神经网络层的内存行为也各异。卷积层因空间局部性,权重核小,易缓存;全连接层需频繁访问大权重矩阵,访问更随机,难以缓存。Transformer 的注意力机制需访问大规模键值对,序列长度与注意力跨度动态变化,传统预取策略难以奏效,延迟不可预测。
稀疏性20也是非规则访问的重要来源。现代模型常用剪枝、激活稀疏、结构稀疏等技术,虽降低计算量,但导致内存访问分散,标准硬件难以高效处理。动态计算路径(如专家混合、动态推理)进一步加剧不确定性,活跃神经元或组件每次推理都不同,极难优化预取与缓存。
这些非规则性带来显著后果。ML 负载缓存效率低,激活与权重难以按序访问,片外流量增加,执行变慢且能耗升高。访问模式不规则还导致内存碎片,数据分配与回收低效。最终,ML 加速器常因内存瓶颈无法充分利用算力。
存储层次结构
为应对 ML 加速的存储挑战,硬件设计者实现了复杂的分层存储结构,平衡速度、容量与能效。理解这一层次结构,是分析不同 ML 架构如何利用存储资源的基础。与通用计算的不可预测访问不同,ML 负载有结构化复用模式,可通过多级存储优化。
最高层为大容量但慢速的长期存储,最低层为高速寄存器与缓存,确保计算单元低延迟访问。中间层如 scratchpad、高带宽内存(HBM)、片外 DRAM,则在性能与容量间权衡。
下表(表 9)总结了现代 AI 加速器各存储层的关键特性。每层的延迟、带宽、容量直接影响权重、激活、中间结果的分配策略。
| 存储层级 | 延迟 | 带宽 | 容量 | 深度学习应用示例 |
|---|---|---|---|---|
| 寄存器 | ~1 cycle | 最高 | 少量 | 存储即用操作数 |
| L1/L2 缓存(SRAM) | ~1-10 ns | 高 | KB-MB | 缓存常用激活、小权重块 |
| Scratchpad | ~5-20 ns | 高 | MB | 显式管理中间计算 |
| 高带宽内存(HBM) | ~100 ns | 极高 | GB | 存储大模型参数、激活,需高速访问 |
| 片外 DRAM(DDR/GDDR) | 50-150 ns | 中等 | GB-TB | 存储无法片上存储的全部权重 |
| 闪存(SSD/NVMe) | 100µs-1ms | 低 | TB | 存储预训练模型、检查点,需加载到更快存储后执行 |
片上存储
每层存储在 AI 加速中各司其职,速度、容量、可访问性各异。寄存器最快,但容量极小,仅适合即用操作数。缓存作为中间缓冲,存储常用激活、权重、中间值,延迟低但容量有限,难以容纳完整特征图或大权重张量。Scratchpad 提供更大容量,允许软件显式管理,适合卷积等需多次复用的场景,减少片外访问,提升效率。
片外存储
片上容量不足时,高带宽内存(HBM)为大模型参数与激活提供高速访问。HBM 通过堆叠多层芯片与宽总线,实现高带宽、低延迟,适合存储需频繁访问的模型层。但其成本与功耗高,主要用于高性能加速器,边缘设备较少采用。
模型超出片上与 HBM 容量时,需依赖片外 DRAM(DDR、GDDR、LPDDR)。DRAM 容量大但延迟高,频繁访问会成为瓶颈。需通过模型结构优化,仅在必要时加载权重与激活,最小化长延迟影响。
最高层为闪存/SSD,存储大模型、数据集、检查点。容量大但速度慢,需先加载到更快存储后才能高效执行。
存储层次结构平衡了速度、容量与能效,但多级搬运带来延迟与带宽瓶颈。数据在层级间传输需付出延迟,带宽有限制,容量不足时需频繁搬运。最终,内存带宽成为现实加速器性能的决定性因素。
带宽与架构权衡
基于 第 11 章:AI 加速 的分析,本节量化不同带宽特性如何影响各类部署场景的系统性能。
现代加速器带宽 - 容量权衡各异:NVIDIA H100 GPU 提供 3.35 TB/s HBM3 带宽与 80GB 容量,适合多样负载。Google TPUv4 带宽 1.2 TB/s,片上存储 128MB,主攻张量能效。H100 的 3:1 带宽优势适合大模型,TPU 低带宽因高复用适合推理。
不同神经网络操作带宽利用率各异:Transformer 注意力机制仅达峰值带宽 20-40%,卷积因空间局部性可达 60-85%,全连接层批量大于 128 时可达 90%。
片上存储访问能耗 5-10pJ,片外 DRAM 需 640pJ,能耗差 65-125$\times$。AI 加速器通过权重驻留、输入驻留、输出驻留三大策略最小化 DRAM 访问。
带宽扩展路径因架构而异:
- GPU 扩展:带宽随通道线性提升,A100 900GB/s → H100 3,350GB/s,支持更大模型
- TPU 扩展:脉动阵列优化带宽,900GB/s,功耗比 GPU 低 35%
- 移动端扩展:Apple M3 神经引擎带宽 400GB/s,功耗 <5W,依赖电压调节
HBM 成本 $8-15/GB,DDR5 仅 $0.05/GB,成本差 160-300$\times$。高带宽加速器需 40-80GB HBM,制造成本增 $320-1,200。边缘加速器带宽仅 50-200GB/s,以实现 <$100 成本目标,兼顾推理性能。
这些带宽特性直接影响部署决策:云端训练优先带宽,边缘推理优化带宽能效,移动端平衡带宽与成本。硬件优化虽关键,系统级软硬件协同优化详见 第 9 章:高效 AI 。这些优化在 第 2 章:机器学习系统 、 第 13 章:机器学习运维 等场景的落地,决定了实际效果。
主机 - 加速器通信
机器学习加速器,如 GPU 和 TPU,通过并行执行实现高吞吐。然而,它们的效率从根本上受到主机(CPU)与加速器内存之间数据流动的限制。与完全在 CPU 内存系统中运行的通用负载不同,AI 工作负载需要在 CPU 主内存和加速器之间频繁传输数据,这会引入延迟、消耗带宽并影响整体性能。
主机 - 加速器数据流遵循一个结构化的顺序,如图 7 所示。在计算开始之前,数据从 CPU 内存复制到加速器的内存中。然后,CPU 发出执行指令,加速器并行处理数据。计算完成后,结果存储在加速器内存中并传回 CPU。每一步都可能引入低效,必须通过高效的内存管理和互连技术来优化性能。

主机 - 加速器数据流动中的关键挑战包括延迟、带宽限制和同步开销。通过高效的内存管理和互连技术优化数据传输,对于最大化加速器的利用率至关重要。
数据传输模式
ML 加速器的效率不仅取决于算力,还依赖于数据的持续供给。即使是高性能 GPU 和 TPU,如果数据搬运不畅,也会导致资源闲置。主机与加速器内存属于不同域,需通过 PCIe、NVLink 或专有互连进行显式传输。数据流动低效会造成执行停顿,因此优化数据搬运至关重要。
图 7 展示了这一结构化流程。第 (1) 步,数据从 CPU 内存复制到加速器内存,因为 GPU 无法高速直接访问主机内存。通常由直接内存访问(DMA)21引擎完成,无需占用 CPU 周期。第 (2) 步,CPU 通过 CUDA、ROCm 或 OpenCL 等 API 发起执行命令。第 (3) 步,加速器并行执行任务,若数据未及时到位则可能停顿。最后第 (4) 步,计算结果再复制回 CPU 内存,供后续处理。
延迟与带宽限制对 AI 负载影响极大。PCIe 峰值带宽 32 GB/s(PCIe 4.0),远低于加速器内部高带宽内存(可超 1 TB/s)。大规模数据搬运在深度学习任务中尤为突出。同步开销也会导致计算需等待数据搬运完成。高效调度与搬运与计算重叠,是缓解这些低效的关键。
数据搬运机制
主机(CPU)与加速器(GPU、TPU 或其他 AI 硬件)间的数据流动,依赖于两者间的互连技术。互连类型决定了搬运带宽、通信延迟与整体执行效率。常见机制包括 PCIe、NVLink、DMA 及统一内存架构。每种机制在优化上述四步数据流动中都发挥着关键作用。
PCIe 接口
大多数加速器通过 PCIe 与 CPU 通信,这是业界标准的数据搬运互连。PCIe 4.0 带宽最高 32 GB/s,PCIe 5.0 可达 64 GB/s,但仍远低于加速器内部 HBM 带宽,因此对大规模 AI 负载来说 PCIe 是瓶颈。
PCIe 还因包交换与内存映射 I/O 模型引入延迟。频繁的小规模搬运效率低,批量搬运可降低开销。计算命令也通过 PCIe 下发,进一步增加延迟,需通过调度优化加以缓解。
NVLink 接口
为突破 PCIe 带宽限制,NVIDIA 推出专有高速互连 NVLink,显著提升 GPU 间及部分 CPU-GPU 间带宽。NVLink 为点对点直连,避免 PCIe 总线争用,提升 AI 负载效率。
主机 - 加速器搬运时,NVLink 可在第 (1) 步以高于 PCIe 的速度将输入数据从主内存传至 GPU,NVLink 4.0 带宽最高达 600 GB/s,极大缓解数据搬运瓶颈,降低延迟。多 GPU 配置下,NVLink 支持加速器间直接数据交换,无需主内存中转,优化了第 (3) 步的计算过程。
但 NVLink 并非通用标准,仅适用于 NVIDIA 硬件,限制了其在非 NVLink GPU 系统中的应用。
DMA 数据搬运
传统内存搬运需 CPU 发起 load/store 指令,消耗处理周期。DMA 可异步搬运,无需 CPU 干预。
搬运过程中,CPU 发起 DMA 请求,数据在后台复制到加速器内存。结果回传主内存也可异步完成。这样计算与搬运可重叠,减少空闲时间,提升加速器利用率。
DMA 是实现异步搬运的关键,可让数据流与计算并行进行。AI 负载可在前一批数据计算时,流式搬运下一批数据,减少等待与资源闲置。
统一内存
PCIe、NVLink、DMA 优化了显式搬运,但部分 AI 负载需更灵活的内存模型,消除手动数据复制。统一内存提供主机与加速器共享的单一内存空间,系统自动搬运所需数据。
统一内存下,数据无需显式复制,计算需用到主机内存区域时,系统自动迁移到加速器,透明完成第 (1) 步。结果被 CPU 访问时,第 (4) 步也自动完成,无需手动管理。
统一内存简化了开发,但带来性能权衡。按需迁移可能导致不可预测的延迟,尤其是大数据集频繁搬运时。统一内存通过页迁移实现,细粒度访问可能触发过度搬运,降低效率。
对需精细内存控制的 AI 负载,显式搬运(PCIe、NVLink、DMA)通常性能更优。但对开发便利性优先的场景,统一内存是便捷选择。
数据搬运开销
主机 - 加速器数据流动带来额外开销,影响 AI 负载执行。与纳秒级片上内存访问不同,主机 - 加速器搬运需跨系统互连,增加延迟、带宽限制与同步等待。
互连延迟影响搬运速度,PCIe 作为主流互连因包交换与内存映射 I/O 开销显著,频繁小搬运效率低。NVLink 等更快互连可降低延迟、提升带宽,但受限于硬件生态。
同步等待也会加剧低效。同步搬运需等数据流动完成后再执行,保证一致性但增加空闲。异步搬运可让计算与搬运重叠,减少停顿,但需精细协调避免执行错位。
这些因素——互连延迟、带宽限制、同步开销——共同决定了 AI 负载效率。优化技术虽可缓解,但理解这些基础机制是提升性能的前提。
模型内存压力
机器学习模型的内存访问模式直接影响加速器性能。数据在主机与加速器间的搬运频率、缓存机制效率等,决定了整体执行效率。多层感知机(MLP)、卷积神经网络(CNN)、Transformer 等模型参数量大,内存需求各异,需针对性优化。理解这些差异,有助于解释不同硬件架构在不同负载下的效率表现。
多层感知机(MLP)
MLP(全连接网络)是最简单的神经架构之一。每层为密集矩阵乘法,每个神经元都与前一层所有神经元相连,导致权重带宽需求极高,每个输入激活都参与大量计算。
MLP 依赖大规模密集权重矩阵,常超出片上内存容量,需频繁访问片外内存。加速器无法高速直接访问主机内存,需通过 PCIe 或 NVLink 显式搬运,带来延迟与带宽消耗,影响执行效率。
尽管带宽需求高,MLP 的内存访问模式规律、可预测,便于预取与流式搬运优化。专用 AI 加速器通过将权重矩阵预存于高速 SRAM 缓存,并用 DMA 引擎实现搬运与计算重叠,减少执行停顿。这些优化让加速器即使处理大参数集也能保持高吞吐。
卷积神经网络(CNN)
CNN 广泛用于图像处理与计算机视觉。与 MLP 的密集矩阵乘法不同,CNN 用小型卷积核在输入特征图上滑动,结构局部化,数据复用度高,同一输入像素可参与多次卷积。
CNN 加速器受益于片上内存优化,卷积核权重复用度高,可存于本地 SRAM,减少片外访问。但激活图因体积大,需精细管理。主内存访问(如 PCIe)带来延迟与带宽瓶颈,CNN 加速器采用分块(tiling)技术,将特征图划分为适合片上缓冲的小块,减少外部搬运,提升效率。
CNN 负载比 MLP 更节省内存,但中间激活管理仍具挑战。加速器用分层缓存与 DMA 优化数据流,确保计算不因主机 - 加速器搬运低效而停顿。这些优化帮助 CNN 加速器通过减少片外带宽依赖,维持高吞吐。
Transformer 网络
Transformers 已成为自然语言处理(NLP)的主流架构,逐渐应用于视觉、语音等领域。与 CNN 的局部计算不同,Transformers 采用全局注意力机制,输入序列每个 token 可与所有其他 token 交互,导致内存访问模式极不规律且带宽需求极高,需频繁搬运大规模键值矩阵。
Transformer 参数量巨大,常超出片上内存容量,需频繁主机 - 加速器搬运,尤其依赖 PCIe 时延迟开销显著。统一内存架构可动态处理部分搬运,但按需迁移带来不可预测延迟。Transformer 负载以内存为主瓶颈,优化需依赖高带宽内存、张量分块与内存分区。
此外,注意力缓存机制与专用张量布局可减少冗余搬运,提升执行效率。传统互连带宽有限,NVLink 架构在大规模 Transformer 训练中优势明显,带宽高、延迟低。DMA 异步搬运可让计算与数据流重叠,减少停顿。
ML 加速器的架构启示
MLP、CNN、Transformer 的多样内存需求,凸显了针对负载定制存储架构的必要性。下表(表 10)对比了不同模型的内存访问模式。
| 模型类型 | 权重规模 | 激活复用 | 内存访问模式 | 主要瓶颈 |
|---|---|---|---|---|
| MLP(全连接) | 大且密集 | 低 | 规律、顺序(流式) | 带宽(片外) |
| CNN | 小且复用 | 高 | 空间局部性 | 特征图搬运 |
| Transformer | 巨大且稀疏 | 低 | 非规律、高带宽 | 内存容量 + 互连带宽 |
每种模型类型都带来独特挑战,直接影响加速器设计。MLP 需高速流式访问密集权重,带宽是性能关键,尤其是主机到加速器权重搬运。CNN 因激活复用高、访问结构化,可用片上缓存与分块策略减少片外搬运。Transformer 则对带宽与容量要求极高,注意力机制需频繁访问大规模键值矩阵,互连流量大,内存压力高。
为应对这些挑战,现代 AI 加速器集成多层次存储结构,平衡速度、容量与能效。片上 SRAM 缓存与 scratchpad 存储常用数据,高带宽外部存储为大模型扩展提供支持。高效互连(如 NVLink)可缓解主机 - 加速器搬运瓶颈,尤其在 Transformer 负载下,内存流动约束常主导执行时间。
随着 ML 负载复杂度提升,内存效率与算力同等重要。分析显示,DRAM 访问能耗高达 173×,是根本瓶颈;合理分层存储可提升有效带宽 10-100×;不同神经网络架构带来不同内存压力模式。这些约束——从带宽限制到通信开销——决定了理论算力能否转化为实际性能。理解内存系统如何限制加速器效能后,接下来将探讨映射策略如何系统性地应对这些挑战。
神经网络硬件映射基础
上一节分析的存储系统挑战——带宽限制、分层访问成本、模型特定压力模式——直接决定了神经网络在加速器上的执行效率。即使脉动阵列拥有 1,200 GB/s 片上带宽和复杂存储层次,若映射策略未考虑内存访问模式,性能提升也无从谈起。如 第 11 章:AI 加速 所述,极高的内存访问能耗要求映射策略优先考虑数据复用与局部性。这一现实驱动了系统化映射方法,需协调计算分配、内存分布与数据流动,充分发挥硬件能力,规避存储瓶颈。
高效执行机器学习模型需结构化的计算映射,确保资源充分利用、性能瓶颈最小化。分布式训练场景下尤为关键,详见 第 8 章:AI 训练 。与通用处理器依赖动态任务调度不同,AI 加速器采用结构化执行模型,通过精细分配计算任务至处理单元,最大化吞吐。该过程即“映射”,决定了计算如何分布于硬件资源,影响执行速度、内存访问与整体效率。
AI 加速器中的映射定义
AI 加速器中的映射 指将机器学习计算任务分配到硬件处理单元,以优化执行效率。该过程包括 空间分配(将计算分布到处理单元)、时间调度(按序安排操作以保持负载均衡)、内存感知执行(战略性分配数据以最小化访问延迟)。高效映射确保资源高利用率、减少内存停顿、提升能效,是 AI 加速的核心。映射机器学习模型到 AI 加速器面临多重挑战,既有硬件约束,也有模型架构多样性。现代加速器的分层存储系统要求映射策略精细管理数据访问时机与位置,最小化延迟与能耗,同时保证计算单元持续工作。映射不当会导致算力闲置、数据搬运过度、执行时间增加,最终降低整体效率。
可用工厂类比:将神经网络映射到加速器如同规划大型工厂的装配流程。你有数千名工人(处理单元)和复杂任务(计算),需决定谁做什么(计算分配)、零件存放何处(内存分配)、操作顺序如何安排(数据流)。细微调整会带来巨大产出差异。工厂布局不合理会导致工人闲置、材料搬运过远,神经网络映射不当同样会造成算力闲置与存储瓶颈。
映射包括三大核心方面:
- 计算分配:系统性地将操作(如矩阵乘法、卷积)分配到处理单元,最大化并行、减少空闲。
- 内存分配:精细确定模型参数、激活、中间结果在存储层次中的位置,优化访问效率。
- 数据流与执行调度:结构化数据在计算单元间的流动,减少带宽瓶颈,保证连续执行。
高效映射策略可最小化片外访问、最大化算力利用、优化数据流动。
编译器的作用
开发者很少手动完成复杂映射。专用编译器(如 NVIDIA NVCC、Google XLA)会将高层模型自动探索映射空间,生成针对目标硬件的最优执行计划。编译器是将模型计算图转化为高效硬件数据流的关键软件层,平衡计算分配、内存分配与执行调度三大方面。编译器支持详见 第 11 章:AI 加速 。下文将探讨影响执行效率的关键映射选择,并为优化策略奠定基础。
计算分配
现代 AI 加速器通过数千至百万级处理单元实现大规模并行,但仅有算力远不够,计算任务如何分配决定了整体效率。
分配不当会导致部分处理单元闲置、部分过载,资源浪费、内存流量增加、性能下降。计算分配即将操作战略性地映射到硬件资源,维持高吞吐、减少停顿、优化执行效率。
计算分配定义
AI 加速器含数千至百万级处理单元,计算分配是大规模问题。现代 GPU(如 NVIDIA H100)拥有 16,000+ 流处理器和 500+ 张量核心,专为矩阵运算加速。TPU 用脉动阵列连接数千 MAC 单元,Cerebras CS-2 单芯片集成 85 万核,极致并行。架构中,哪怕微小分配低效都会导致显著性能损失,算力闲置或数据搬运过度会在系统中成倍放大。
计算分配确保所有处理单元都高效参与执行。需合理分布负载,避免部分单元闲置、部分过载。分配还需最小化不必要的数据流动,过度搬运会引入延迟与能耗,降低系统性能。
神经网络计算因模型架构而异,分配策略也需适应。例如 CNN 分配时关注将图像区域划分给不同处理单元,最大化并行。$256\times256$ 图像可分块映射到数千 GPU 核心,卷积操作同步进行。Transformer 需适应自注意力机制,每个 token 与所有其他 token 交互,计算模式不规则且内存密集。图神经网络(GNN)更复杂,计算依赖稀疏动态图结构,需自适应负载分布。
计算分配直接影响资源利用率、执行速度与能效,是 AI 加速的关键。合理分配可将延迟降低数倍,分配不当则会让大量算力闲置。下节将探讨高效计算分配的必要性及映射策略失衡的后果。
计算分配的重要性
计算分配虽由硬件驱动,但其重要性本质上受神经网络负载结构影响。不同模型类型计算模式各异,直接决定了映射到加速器的效率。分配不当会导致负载失衡、内存访问低效、系统性能显著下降。
结构化计算模式(如 CNN)分配较简单。CNN 用滤波器处理局部区域,计算可均匀分布到处理单元,操作高度可并行,空间分块后各自独立,适合加速器的规则数据流,分配决策复杂度低。
但不规则计算模式(如 Transformer、GNN)分配难度大。Transformer 依赖自注意力,每个 token 与所有其他 token 交互,计算需求不均。与 CNN 不同,部分处理单元工作量远高于其他,易导致负载失衡,部分单元闲置、部分过载。
GNN 更复杂,计算依赖稀疏动态图结构,节点与边连接度变化大,部分区域计算量远高于其他,负载均衡难度极高。分配不当会让部分算力闲置,部分过载,执行效率低下。
分配失衡会导致负载不均、数据搬运过度、执行停顿与瓶颈。计算分布不均会让处理单元闲置,硬件利用率低,吞吐下降。分配低效会增加内存流量,频繁搬运数据,延迟高、能耗大。操作等待数据依赖时,流水线停顿,整体性能下降。
计算分配确保模型按自身结构高效执行。合理分配可降低执行时间、内存开销与能耗,分配不当则会导致流水线停顿与资源浪费。下节将探讨高效分配需考虑的关键因素,确保分配既高效又适应不同模型架构。
高效计算分配
计算分配需在硬件约束与负载特性间权衡。高效分配策略需兼顾并行性、内存访问与负载变化,确保处理单元充分利用。分配不当会导致执行失衡、数据搬运增加、性能下降,因此设计分配策略时需重点考虑如下因素。
表 11 总结了计算分配面临的关键挑战。高效映射策略需均衡负载分布、最小化数据搬运、优化处理单元间通信。
| 挑战 | 对执行的影响 | 分配需重点考虑 |
|---|---|---|
| 负载失衡 | 部分处理单元提前完成,部分过载,算力闲置 | 均匀分布操作,防止停顿,确保处理单元高利用率 |
| 不规则计算模式 | Transformer、GNN 等模型计算需求不均,静态分配难度大 | 用自适应分配策略,按负载特性动态调整执行 |
| 数据搬运过度 | 频繁内存搬运增加延迟与能耗 | 让常用数据靠近计算单元,减少片外访问 |
| 互连带宽有限 | 分配不当易造成拥堵,处理单元间数据流慢 | 优化空间与时间分配,降低通信开销 |
| 模型特定执行需求 | CNN、Transformer、GNN 执行模式各异,单一策略难奏效 | 针对模型结构定制分配策略 |
上述挑战凸显了计算分配的核心权衡:最大化并行性、最小化内存开销。CNN 优先结构化分块,提升数据复用;Transformer 分配需均衡注意力层负载;GNN 分配需动态适应稀疏计算。
除模型特定需求外,高效分配还需具备可扩展性。模型规模与复杂度提升时,分配策略需动态调整,不能依赖静态执行模式。未来 AI 加速器将集成运行时感知调度机制,分配按实时负载优化,而非预设计划。
高效计算分配需兼顾硬件能力与模型特性。下节将探讨分配与内存分配、数据流动的协同,确保 AI 加速器始终高效运行。
内存分配
高效内存分配是 AI 加速高性能的基础。随着模型复杂度提升,加速器需管理海量数据流动——加载参数、存储激活、中间梯度。数据在存储层次中的分布直接影响执行效率、能耗与系统吞吐。
内存分配定义
计算分配决定操作执行位置,内存分配则决定数据存储位置与访问方式。所有 AI 加速器都依赖分层存储系统,从片上缓存、scratchpad 到 HBM、DRAM。分配不当会导致频繁片外访问,带宽争用加剧,执行变慢。AI 加速器算力达 TFLOPS/PFLOPS,内存访问低效会造成严重瓶颈。
内存分配的首要目标是将常用数据尽可能靠近处理单元,降低延迟与能耗。不同架构实现了针对 AI 负载的分层存储。GPU 混合使用全局内存、共享内存与寄存器,需精细分块优化局部性。TPU 用片上 SRAM scratchpad,激活与权重需高效预加载,维持脉动阵列流水线。晶圆级处理器(如 Cerebras)集成数十万核,需复杂内存分区,避免互连流量过大。无论架构如何,内存分配效率决定了吞吐、能效与可扩展性。
内存分配通过数据存储与访问模式直接影响 AI 加速效率。与通用计算依赖缓存与动态分配不同,AI 加速器需显式数据布局,维持高吞吐、避免停顿。脉动阵列(见图 4)尤为明显,处理单元间数据流需精确时序。TPU 脉动阵列权重需预加载到片上 scratchpad,与输入激活同步流经阵列,维持流水线。分配不当会导致延迟、能耗高、瓶颈严重,算力难以发挥。
不同负载的内存挑战
神经网络架构内存需求各异,分配策略需适应。CNN 依赖结构化、局部化数据访问,分配不当会导致重复加载、缓存低效。Transformer 需频繁访问大参数与中间激活,对带宽极为敏感。GNN 更复杂,稀疏动态结构导致访问模式不可预测,易造成内存资源低效。分配不当主要带来三大后果:
- 内存延迟增加:常用数据未存于合适位置,需高延迟访问,执行变慢。
- 能耗提升:片外访问能耗远高于片上,规模化下效率低下。
- 算力吞吐下降:数据未及时到位,处理单元闲置,整体性能下降。
随着模型规模与复杂度提升,可扩展、高效的内存分配愈发重要。内存限制决定了可部署模型规模,影响可行性与性能。
| 挑战 | 对执行的影响 | 分配需重点考虑 |
|---|---|---|
| 高内存延迟 | 数据访问慢,执行延迟、吞吐下降 | 常用数据优先存于高速存储 |
| 片上存储有限 | 本地内存小,数据难以靠近算力 | 高效分配存储,最大化数据可用性,避免超限 |
| 片外带宽需求高 | 频繁外部访问延迟高、能耗大 | 精细管理搬运时机与方式,减少不必要的数据流动 |
| 不规则访问模式 | 部分模型访问不可预测,内存利用低效 | 数据布局需适应访问模式,减少冗余搬运 |
| 模型特定内存需求 | 不同模型需定制分配策略,优化性能 | 按负载结构与执行特性定制分配决策 |
表 12 总结了 AI 加速器内存分配需应对的关键挑战。高效分配策略通过精细管理数据位置与流动,缓解延迟、带宽与不规则访问带来的瓶颈。确保常用数据存储在快速访问位置,减少不必要的内存搬运,是维持性能与能效的关键。
每项挑战都需精细内存管理,兼顾执行效率与硬件约束。结构化模型可用规则布局优化访问,Transformer、图模型则需自适应分配应对复杂需求。分配还需具备可扩展性,模型规模增长时,分配策略需动态调整,不能依赖静态方案。确保常用数据随时可用,避免内存容量过载,是保持高效的关键。
组合复杂性
高效执行机器学习模型需兼顾分配与分配。分配涵盖计算与数据的空间分布,分配则涉及资源的时间分配。两者相互影响,每项决策都带来性能、能效与可扩展性的权衡。@tbl-combinatorial-complexity 总结了 AI 加速器中计算分配与资源分配的基本权衡。分配影响并行性、内存访问与通信开销,分配决定资源时间分布,影响执行效率。两者协同塑造整体性能,需精细平衡,避免同步、内存拥堵或算力闲置等瓶颈。优化这些权衡是确保 AI 加速器高效运行的关键。
每个维度都需在分配与分配间权衡。例如,空间分布计算可提升吞吐,但若数据分配不当,带宽瓶颈会限制性能。细粒度分配提升灵活性,但若分配策略不优,会带来同步开销。
| 维度 | 分配需考虑 | 分配需考虑 |
|---|---|---|
| 计算粒度 | 细粒度分配提升并行性,但同步开销大 | 粗粒度分配降低同步,但灵活性受限 |
| 空间 vs 时间映射 | 空间分配提升并行,但易资源争用、内存拥堵 | 时间分配平衡资源共享,但吞吐可能下降 |
| 内存与数据局部性 | 数据靠近算力可降延迟,但整体容量受限 | 多级分配提升容量,但访问成本高 |
| 通信与同步 | 算力集中可降通信延迟,但易争用 | 分配同步机制可缓解停顿,但带来额外开销 |
| 数据流与执行顺序 | 静态分配简化执行,但适应性差 | 动态分配提升适应性,但调度复杂度高 |
AI 加速器架构对计算执行位置与资源分配时间均有限制,选择高效映射策略需分配与分配协同。理解这些权衡如何影响执行效率,是优化加速器性能的基础。
配置空间探索
AI 加速器效率不仅取决于算力,还取决于神经网络计算如何映射到硬件资源。映射定义了计算分配、数据存储与流动、执行调度,直接影响算力利用率、内存带宽与能耗。
将机器学习模型映射到硬件,涉及庞大复杂的设计空间。与传统负载不同,模型执行涉及计算、数据流动、并行性、调度等多重因素,每项都带来约束与权衡。加速器分层存储结构进一步加剧复杂性,带宽、延迟、数据复用均有限制。高效映射策略需精细平衡各目标,最大化效率。
设计空间核心包括数据分配、计算调度、数据流动时序。数据分配指数据在片上缓冲、缓存、片外 DRAM 等层次的分布,管理得当可优化延迟与能耗。分配不当会导致频繁高成本访问,合理分配则让常用数据留在高速存储。计算调度决定操作顺序,影响并行性与内存访问,有些顺序优化并行但引入同步开销,有些提升局部性但吞吐下降。数据流动时序同样关键,层级间搬运带来延迟与能耗,优化策略需最大化复用、搬运与计算重叠。
这些因素共同构成庞大的组合设计空间,映射决策微调即可带来性能与能效巨大差异。映射不当会导致算力闲置、数据搬运过度、负载失衡,形成瓶颈。合理映射则可最大化吞吐与资源利用,充分发挥硬件能力。
因映射决策高度关联,不存在单一最优解——不同负载与硬件需不同策略。下节将分析设计空间结构及不同映射选择如何影响机器学习负载执行。
将机器学习计算映射到专用硬件需平衡多重约束,包括算力效率、内存带宽、执行调度。挑战在于映射决策空间巨大,计算分配、执行顺序、数据流动管理,每项都带来高维搜索空间,微小变化即可显著影响性能。
与传统负载执行模式可预测不同,机器学习模型结构多样,需灵活映射以适应数据复用、并行机会与内存约束。搜索空间组合爆炸,穷举不可行。理解复杂性,主要有三大来源:
计算与执行顺序排列
机器学习负载常用嵌套循环,遍历多维计算。例如矩阵乘法内核可遍历批量($N$)、输入特征($C$)、输出特征($K$)等。循环顺序对数据局部性、复用与效率影响极大。
$d$ 个循环的排列方式为阶乘增长: $$ \mathcal{O} = d! $$ 增长极快。典型卷积层有 7 个循环维度,排列方式为: $$ 7! = 5,040 \text{ 种执行顺序。} $$
若考虑多级存储,搜索空间扩展为: $$ (d!)^l $$ 其中 $l$ 为存储层级数。空间爆炸,优化执行顺序至关重要,顺序不当会导致内存流量激增,优化后可提升缓存利用。
处理单元并行化
现代 AI 加速器用数千处理单元提升并行性,但并行化哪些计算并非易事。过度并行化会带来同步开销与带宽压力,过少则算力闲置。
并行分配方式为二项式系数: $$ \mathcal{P} = \frac{d!}{(d-k)!} $$ $d$ 为循环数,$k$ 为并行维度。六维计算选三维并行,有: $$ \frac{6!}{(6-3)!} = 120 $$
单层即可有数百种并行策略,影响同步、内存争用与效率。多层、多模型组合后复杂度更高。
内存分配与数据流动
加速器分层存储结构带来额外约束,数据需高效分布于寄存器、缓存、共享内存、片外 DRAM。分配影响延迟、带宽与能耗,频繁慢速访问形成瓶颈,优化分配可减少高成本搬运。
分配方式为指数增长: $$ \mathcal{M} = n^{d \times l} $$ 其中:
- $n$ = 每层分配选择数
- $d$ = 计算维度数
- $l$ = 存储层级数
如:
- $d = 5$
- $l = 3$
- $n = 4$
则分配方式为: $$ 4^{5 \times 3} = 4^{15} = 1,073,741,824 $$
单层即可有十亿种分配方式,手动优化不可行。
映射搜索空间
综合计算顺序、并行化、内存分配复杂性,总映射空间为: $$ \mathcal{S} = \left( n^d \times d! \times \frac{d!}{(d-k)!} \right)^l $$ 其中:
- $n^d$ 表示内存分配选择
- $d!$ 表示计算顺序选择
- $\frac{d!}{(d-k)!}$ 表示并行化可能性
- $l$ 为存储层级数
该公式展示了搜索空间的指数增长,穷举仅适用于最简单场景。
数据流优化策略
映射策略决定了计算在加速器架构中的执行位置与数据存储位置,但并未规定数据在执行过程中如何流动。脉动阵列可用本地存储权重处理矩阵乘法,但权重、输入、输出在阵列中的流动顺序,决定了内存带宽消耗与能效。数据流模式——即优化策略——是将抽象映射决策转化为具体执行计划的关键实现维度。
权重驻留、输入驻留、输出驻留等策略直接影响加速器是算力受限还是内存受限。理解这些权衡至关重要,因为编译器与运行时系统需根据计算特性与存储层次能力(见 第 11 章:AI 加速 )选择合适的数据流模式。
高效映射机器学习计算到硬件,因配置空间庞大而极具挑战。模型复杂度提升,映射可能性指数增长。单层即可有数千种循环顺序、数百种并行策略、指数级内存分配方式,穷举不可行。
为解决这一难题,AI 加速器采用结构化映射策略,系统性平衡算力效率、数据局部性与并行执行。非穷举评估所有配置,而是结合启发式、分析与机器学习方法,高效找到高性能映射。
高效映射的关键在于理解并应用一系列核心技术,优化数据流动、内存访问与计算。下节将系统梳理这些映射策略的基础技术。
映射策略的基础技术
为应对映射决策复杂性,需用一系列优化执行的数据流、内存访问与计算效率的基础技术。这些技术为高性能映射策略提供结构化基础,最大化硬件性能、最小化瓶颈。
关键技术包括数据流动策略,决定计算过程中数据驻留位置,减少冗余搬运,如权重驻留、输出驻留、输入驻留。内存感知张量布局也至关重要,通过行主序、通道主序等数据组织方式优化访问模式与缓存效率。
其他策略包括算子融合,合并多步操作为单步计算,减少冗余内存写入。分块(tiling)将大规模计算划分为适合缓存的小块,提升缓存效率、降低带宽需求。最后,算力与通信平衡,管理并行执行与内存访问的权衡,实现高吞吐。
这些基础技术是高性能执行的核心,为启发式与模型驱动优化方法奠定基础。下节将探讨这些策略如何适应不同 AI 模型类型。
数据流动模式
计算映射决定操作发生的时间与位置,但其成效高度依赖于数据在存储层次间的流动效率。与传统负载结构化、可预测的访问不同,机器学习负载因频繁权重、激活、中间值搬运,访问模式极不规律。
即使计算单元映射高效,数据流动策略不当也会严重拖慢性能,导致频繁内存停顿、算力闲置。数据供给速度达不到需求时,算力闲置,延迟、流量与能耗增加。
以典型矩阵乘法为例(见示例 18),说明数据流动低效的影响。
示例 18:矩阵乘法:数据流动瓶颈会导致算力闲置,凸显高效数据流在优化机器学习模型性能中的重要性。
## 矩阵乘法
## weights: [512 x 256] - 模型参数
## input: [256 x 32] - 激活批量
## Z: [512 x 32] - 输出激活
## 计算每个输出元素 Z[i,j]
for i in range(512):
for j in range(32):
for k in range(256):
Z[i, j] += weights[i, k] * input[k, j]
该计算揭示了三大数据流挑战。第一,内存访问次数极多。每个输出 $Z[i,j]$ 需从权重矩阵取一整行、从输入矩阵取一整列。权重矩阵有 512 行,输入矩阵有 32 列,导致重复访问,带宽压力极大。
第二,权重复用。相同权重用于多个输入,理想映射应最大化权重局部性,避免重复搬运。复用不当会浪费带宽。
第三,中间结果累加。每个 $Z[i,j]$ 需累加 256 个权重 - 输入对,部分和需存取,若存储低效,频繁访问进一步加剧带宽压力。
SIMD、SIMT 并行模型可并行取值,但数据流动仍是瓶颈。问题不在于取数速度,而在于搬运频率与数据在存储层次中的位置。
数据搬运成本比计算高 100-1000×,加速器最重要目标是最小化内存访问。数据流策略即为最大化数据复用的架构模式。关键问题是:哪些数据最值得本地驻留?这正是 第 11 章:AI 加速 分析的 AI 内存墙挑战,极高能耗惩罚主导系统性能。
为应对这些约束,加速器实现了数据流策略,决定哪些数据固定驻留、哪些动态流动。权重驻留将模型参数本地化,输入驻留保持激活数据,输出驻留保存中间结果。每种策略在内存访问模式上权衡不同,以最大化数据复用、最小化高能耗搬运,解决 AI 加速的主瓶颈。
权重驻留(Weight Stationary)
权重驻留策略将权重固定在本地存储,输入激活和部分和则以流式方式动态传递。该方法在 CNN 和矩阵乘法等场景下尤为高效,因为同一组权重会被多次复用。通过让权重保持不动,显著减少了重复的内存读取,有效缓解带宽瓶颈并提升能效。
权重驻留的核心优势在于最大化权重复用,显著降低对外部存储的访问频率。由于权重参数常在多次计算中共享,固定在本地存储可消除不必要的数据搬运,降低整体计算能耗。对于权重占据主要内存开销的架构(如脉动阵列、定制 ML 加速器),该策略尤为有效。
下方代码(示例 19)展示了权重驻留矩阵乘法的简化实现。
示例 19:权重驻留矩阵乘法:权重驻留矩阵乘法将权重固定在本地存储,输入激活流式传递,最大化权重复用,降低能耗。
## 权重驻留矩阵乘法
## - 权重固定在本地存储
## - 输入激活流式传递
## - 部分和累加得到最终输出
for weight_block in weights: # 加载权重并固定
load_to_local(weight_block) # 固定在本地存储
for input_block in inputs: # 动态流式输入
for output_block in outputs: # 计算结果
output_block += compute(weight_block, input_block)
# 跨输入复用权重
权重驻留执行时,权重仅需加载一次并固定在本地存储,输入则动态流动,减少了重复的内存访问。部分和也在本地高效累加,避免了不必要的数据搬运,确保系统高吞吐与能效。
权重固定后,内存带宽需求大幅降低,无需每次计算都重新加载权重。系统可高效复用已存权重,提升执行吞吐,适合权重复用度高的负载,如 CNN 和矩阵乘法。
但该策略虽减少了权重相关流量,却带来输入和输出搬运的权衡。输入需动态流动,效率取决于激活能否及时送达计算单元,避免停顿。部分和作为中间结果,也需高效累加,避免过度内存流量。实际性能提升受限于片上存储容量,若权重矩阵过大,固定本地存储会成为瓶颈。
权重驻留适合权重复用度高、带宽受限的场景,常用于 CNN、脉动阵列和矩阵乘法内核。对于输入或输出复用更关键的模型,可考虑输出驻留或输入驻留等其他数据流策略。
输出驻留(Output Stationary)
输出驻留策略将部分和(中间结果)固定在本地存储,权重和输入激活则动态流动。该方法在全连接层、脉动阵列等需多次累加的操作中尤为高效。通过让部分和驻留,显著减少了中间结果的重复写入,降低带宽消耗并提升能效。
输出驻留的核心优势在于优化累加效率,确保每个输出元素在写入内存前都能高效计算。与权重驻留优先权重复用不同,输出驻留专注于减少中间结果频繁写入带来的带宽开销,适合累加主导的负载,如全连接层和 Transformer 的矩阵乘法。
下方代码(示例 20)展示了输出驻留矩阵乘法的简化实现。
示例 20:输出驻留执行:部分和本地累加,减少内存写入,提升矩阵乘法效率,适合 Transformer 等模型。
## - 部分和固定在本地存储
## - 权重和输入激活动态流动
## - 最终输出仅写入一次
for output_block in outputs: # 固定部分和
accumulator = 0 # 初始化累加缓冲
for weight_block, input_block in zip(weights, inputs):
accumulator += compute(weight_block, input_block)
# 累加部分和
store_output(accumulator) # 仅写入一次
输出驻留执行遵循如下原则:
- 部分和在本地存储中保持不动,整个计算过程均可访问。
- 权重和输入动态流动,确保中间结果始终本地可用。
- 最终输出仅写入一次,避免多次中间写入。
本地累加部分和可消除多余内存写入,提升系统效率。脉动阵列等结构化累加架构天然适合输出驻留,减少同步开销。
但输出驻留虽减少写入流量,却带来权重和输入搬运的权衡。权重和激活需动态流动,效率取决于数据能否及时送达系统,避免停顿。并行实现时,需精细同步部分和的更新,尤其是多个处理单元共同累加同一输出时。
输出驻留适合累加主导、需减少中间写入的负载,常用于全连接层、注意力机制和脉动阵列。对于输入复用更关键的模型,可考虑输入驻留等其他数据流策略。
输入驻留(Input Stationary)
输入驻留策略将输入激活固定在本地存储,权重和部分和则动态流动。该方法适合批量处理、Transformer 和序列模型等输入复用度高的场景。通过让激活驻留,显著减少了重复输入读取,提升数据局部性,降低内存流量。
输入驻留的核心优势在于最大化输入复用,显著降低激活访问频率。许多模型(如 NLP、推荐系统)会多次处理同一输入数据,固定输入可消除不必要的数据搬运,降低能耗。批量处理场景下,单批激活可参与多次权重变换,输入驻留尤为高效。
下方代码(示例 21)展示了输入驻留矩阵乘法的简化实现。
示例 21:输入驻留:输入激活固定,权重动态流动,最大化内存复用,降低能耗。
## - 输入激活固定在本地存储
## - 权重动态流动
## - 部分和累加后写出
for input_block in inputs: # 固定输入激活
load_to_local(input_block) # 固定在本地存储
for weight_block in weights: # 动态流式权重
for output_block in outputs: # 计算结果
output_block += compute(weight_block, input_block)
# 跨权重复用输入
输入驻留执行遵循如下原则:
- 输入激活加载到本地存储,计算期间保持不动。
- 权重动态流动,高效应用于多个输入。
- 部分和累加后写出,优化带宽利用。
输入驻留可显著减少输入数据的重复访问,降低外部带宽需求。Transformer 架构中,每个 token 在多个注意力头和层中复用,输入驻留尤为高效。批量处理场景下,激活本地驻留提升数据局部性,适合全连接层和矩阵乘法。
但输入驻留虽减少激活流量,却带来权重和输出搬运的权衡。权重需动态流动,效率取决于能否及时送达计算单元,避免停顿。部分和需高效累加后写出,可能需额外缓冲机制。
输入驻留适合输入复用度高、输入带宽受限的负载,常用于 Transformer、循环网络和批量处理。对于输出累加更关键的模型,可考虑输出驻留等其他数据流策略。
高效张量布局
高效执行机器学习负载不仅依赖数据流动策略,还需优化数据在内存中的存储与访问方式。张量布局,即多维数据在内存中的排列方式,直接影响内存访问效率、缓存性能与计算吞吐。布局选择不当会导致频繁内存停顿、缓存低效与数据搬运成本增加。
在 AI 加速器中,张量布局优化尤为重要,因为数据访问模式常受底层硬件架构影响。合理布局可确保内存访问与硬件友好,最小化高成本内存操作。
开发者有时可手动指定张量布局,但实际多由 ML 框架(如 TensorFlow、PyTorch、JAX)、编译器或加速器运行时自动决定。底层优化工具如 cuDNN(NVIDIA GPU)、XLA(TPU)、MLIR(定制加速器)会动态调整张量布局以优化性能。高层框架通常自动应用布局变换,但自定义内核或底层库(如 CUDA、Metal、OpenCL)开发者可直接控制张量格式。
例如,PyTorch 用户可用 tensor.permute() 或 tensor.contiguous() 手动调整布局,确保高效内存访问。TensorFlow 多由 XLA 编译器内部优化,针对硬件选择 NHWC(行主序)或 NCHW(通道主序)。硬件感知 ML 库如 cuDNN(GPU)、OneDNN(CPU)会强制特定布局以最大化缓存局部性和 SIMD 效率。最终,张量布局多由编译器和运行时系统自动决定,确保数据存储方式最适合底层硬件。
行主序布局(Row-Major)
行主序布局指多维张量在内存中的存储方式,按行依次排列,每行所有元素连续存储,下一行紧随其后。该格式广泛用于通用 CPU 和部分 ML 框架,因其顺序访问模式天然适合缓存优化。
以 $3\times3$ 像素、3 通道(RGB)图片为例,张量形状为 (3, 3, 3),内存存储如下:
$$ I(0,0,0), I(0,0,1), I(0,0,2), I(0,1,0), I(0,1,1), \ I(0,1,2), I(0,2,0), I(0,2,1), I(0,2,2), \ldots $$
每行数据连续存储,所有像素值顺序排列,便于 CPU 和缓存层次顺序预取。行主序适合逐行处理,如激活函数、算术变换等,内存读取高效,缓存利用最大化。
在 CPU 负载下,行主序布局优势明显,批归一化、矩阵乘法、逐元素算术等操作常顺序处理行数据。现代 CPU 预取机制可提前加载下一行数据,降低延迟,提升吞吐。
但行主序在跨通道访问时效率较低。例如卷积层需跨通道处理像素,通道值在行主序下交错分布,卷积操作需跨内存跳跃,难以实现向量化与合并访问,GPU/TPU 等加速器对此不友好。
尽管如此,行主序仍是 CPU ML 框架主流格式。TensorFlow 在 CPU 默认 NHWC(行主序),优化缓存局部性。GPU 负载则常动态调整为更高效的通道主序布局。
通道主序布局(Channel-Major)
通道主序布局将同一通道的所有值连续存储,依次排列各通道。该格式适合 GPU、TPU 等 AI 加速器,因其向量化与合并访问能力强,极大提升计算效率。
以同样的 $3\times3$、3 通道图片为例,通道主序内存结构如下:
$$ I(0,0,0), I(1,0,0), I(2,0,0), I(0,1,0), I(1,1,0), I(2,1,0), \ldots, \ I(0,0,1), I(1,0,1), I(2,0,1), \ldots, I(0,0,2), I(1,0,2), I(2,0,2), \ldots $$
所有红色通道值先存储,接着绿色、蓝色。该布局便于加速器高效加载整通道数据,适合卷积与 SIMD 并行。
通道主序在卷积操作中优势明显。卷积核需跨通道处理像素,通道主序可一次加载整通道,减少分散内存读取,降低延迟,提升吞吐,优化矩阵乘法等核心操作。
GPU/TPU 依赖内存合并访问[^fn-memory-coalescing],即连续线程访问连续地址,通道主序天然适配并行计算。NVIDIA GPU 中,每个 warp 线程处理同一通道不同元素,内存访问高效,避免跨步访问带来的性能损失。
但通道主序在 CPU 上效率较低,因其顺序访问优化不佳,逐行操作缓存局部性差。因此 ML 框架(如 TensorFlow、PyTorch)在 CPU 默认 NHWC(行主序),GPU 则优先 NCHW(通道主序),各自优化硬件优势。
现代框架和编译器常根据执行环境动态调整张量布局。例如 TensorFlow、PyTorch 会自动在 CPU、GPU、TPU 间切换 NHWC[^fn-nhwc-nchw] 与 NCHW,确保内存布局与执行路径最优。
行主序与通道主序对比
行主序(NHWC)与通道主序(NCHW)各有适用场景,效率取决于硬件架构、内存访问模式与计算需求。布局选择直接影响缓存利用、带宽效率与处理吞吐。下表(表 14)总结了两种布局在性能权衡与硬件兼容性上的差异。
| 特性 | 行主序(NHWC) | 通道主序(NCHW) |
|---|---|---|
| 内存存储顺序 | 像素逐行存储,通道交错 | 同一通道所有值先存储 |
| 最佳适用场景 | CPU、逐元素操作 | GPU、TPU、卷积操作 |
| 缓存效率 | 顺序行访问局部性高 | 通道合并访问优化 |
| 卷积性能 | 需跨步访问(GPU 效率低) | GPU 卷积核高效 |
| 内存读取 | 适合逐行顺序处理 | 优化 SIMD 并行通道处理 |
| 框架默认 | CPU 默认(如 TensorFlow NHWC) | GPU 默认(如 cuDNN 优先 NCHW) |
布局选择多由框架和编译器自动决定,依据硬件和操作类型动态调整。CPU 优先 NHWC,优化顺序访问;GPU 优先 NCHW,减少 ML 计算的内存读取开销。
实际应用中,TensorFlow XLA、PyTorch TorchScript 等编译器会自动布局变换,确保模型在不同处理单元下实现最高吞吐,无需开发者手动指定。
算子融合(Kernel Fusion)
AI 加速优化的核心技术之一是减少操作间中间数据搬运。算子融合通过将多个独立计算合并为统一操作,显著提升内存效率与执行性能。下文先分析中间写入带来的内存瓶颈,再探讨融合技术如何消除低效。
中间内存写入
优化内存访问是 AI 加速的根本挑战。尽管 AI 模型算力高,性能常受限于内存带宽与中间写入,而非算术运算。每次操作产生中间结果需写入内存、后续再读出,数据搬运开销导致执行停顿。
结合 第 10 章:模型优化 的软件优化与 第 11 章:AI 加速 的带宽约束,算子融合是软件与硬件加速的关键桥梁。许多 AI 负载存在多余中间写入,增加带宽消耗,降低效率。
下方代码(示例 22)展示了朴素执行模型,每步操作为独立内核,每个中间结果都需写入内存、后续再读出。
示例 22:朴素执行:每步操作都将中间结果写入内存,后续再处理,带宽消耗高,效率低。
import torch
## 输入张量
X = torch.randn(1024, 1024).cuda()
## 逐步执行(朴素方式)
X1 = torch.relu(X) # 中间张量写入内存
# 后续操作
X2 = torch.batch_norm(X1) # 再次写入中间张量
Y = 2.0 * X2 + 1.0 # 最终结果
每步操作都生成中间张量,需写入内存、后续再读出。大张量下,数据搬运开销常超过计算本身(Shazeer 等,2018)。下表(表 15)展示了朴素执行的内存开销。实际只需最终结果 $Y$,但多余中间张量导致内存流量和占用激增,形成性能瓶颈,内存优化对 AI 加速器至关重要。
| 张量 | 1024x1024 张量大小(MB) |
|---|---|
| X | 4 MB |
| X’ | 4 MB |
| X’’ | 4 MB |
| Y | 4 MB |
| 总内存 | 16 MB |
实际只需最终结果 $Y$,但多余三份中间张量占用额外内存,未贡献实际输出。过度内存占用限制可扩展性,浪费带宽,尤其在 AI 加速器中,减少数据搬运是关键。
融合优化内存效率
算子融合是减少中间写入、降低内存占用和带宽消耗的关键优化技术。
融合将多步计算合并为单一优化操作,无需存储和加载中间张量。传统实现每层或逐元素操作独立执行,每步都需写入内存,融合则让数据在高速寄存器或本地存储间直接流动。
常见 ML 序列如 ReLU 激活、BatchNorm、缩放等,朴素实现每步都生成中间张量:
$$ X’ = \text{ReLU}(X) X’’ = \text{BatchNorm}(X’) Y = \alpha \cdot X’’ + \beta $$
融合后,所有操作合并为单步,无需多余中间张量:
$$ Y = \alpha \cdot \text{BatchNorm}\big(\text{ReLU}(X)\big) + \beta $$
下表(表 16)量化了融合对内存效率的提升。中间结果仅在寄存器或本地存储中流动,无需写入主内存,极大减少内存流量。GPU、TPU 等并行架构尤为受益,减少内存访问可直接提升吞吐。与朴素模型相比,融合消除了中间张量存储,显著降低总内存占用,提升效率。
| 执行模型 | 存储中间张量 | 总内存占用(MB) |
|---|---|---|
| 朴素执行 | X’, X’’ | 16 MB |
| 融合执行 | 无 | 4 MB |
融合将总内存占用由 16 MB 降至 4 MB,消除冗余写入,提升执行效率。
性能优势与约束
融合带来多项优势,提升内存效率与计算吞吐。减少内存访问后,中间值可留在寄存器,无需反复写入和读取,显著降低流量。GPU、TPU 等高带宽受限架构尤为受益,减少内存操作可提升算力利用。
但并非所有操作都可融合。逐元素操作(如 ReLU、BatchNorm、算术变换)最适合融合,因其仅依赖单一输入元素。矩阵乘法、卷积等复杂依赖操作则难以直接融合,需多输入元素计算单一输出,无法合并为单一内核。
融合还需考虑寄存器压力。多步融合需所有临时值留在寄存器,虽消除冗余写入,但增加寄存器需求。若融合内核超出每线程可用寄存器,系统需将多余值溢出到共享内存,增加延迟,可能抵消融合优势。GPU 并行度受限于寄存器数量,融合过度会降低并行度,收益递减。
不同加速器和编译器融合策略各异。NVIDIA GPU 优先 warp 级并行,逐元素融合简单。TPU 优先脉动阵列矩阵运算,适合矩阵融合。XLA(TensorFlow)、TorchScript(PyTorch)、TensorRT(NVIDIA)、MLIR 等编译器会自动检测融合机会,用启发式方法平衡内存节省与执行效率。
融合并非总是最优。部分框架允许开发者选择性关闭融合,便于调试或频繁模型修改。融合决策需权衡内存效率、寄存器使用与硬件约束,确保实际性能提升。
高效分块(Tiling)策略
现代 AI 加速器算力虽高,性能常受限于内存带宽而非算力本身。数据供给不足时,执行停顿,算力闲置,硬件利用低下。
分块(tiling)通过将计算重构为更小、适合内存的子问题,缓解带宽瓶颈。与一次处理整个矩阵或张量不同,分块将计算划分为适合本地存储(如缓存、共享内存、寄存器)的块。这样可提升数据复用,减少内存读取,提升整体效率。
以矩阵乘法为例,朴素实现(见示例 23)会多次重复读取同一数据,带宽消耗高,效率低。
示例 23:未分块的朴素矩阵乘法
for i in range(N):
for j in range(N):
for k in range(N):
C[i, j] += A[i, k] * B[k, j] # 重复读取
# A[i, k] 和 B[k, j]
每次迭代都需从内存加载 $A$、$B$ 元素,数据搬运频繁,带宽压力大。矩阵规模越大,内存瓶颈越严重,性能受限。
分块可将矩阵分为适合本地存储的小块,提升复用效率,仅在必要时写回主内存。该技术在 AI 加速器中尤为关键,内存访问主导执行时间。将大矩阵分块后(见图 8),可在硬件上高效复用本地数据,提升计算效率。后续章节将系统介绍分块原理、不同策略及关键权衡。

分块原理
分块基于一个简单而强大的原理:与其一次处理整个数据结构,不如将计算划分为适合可用快速内存的小块。通过围绕这些块构建执行,最大化数据复用,减少冗余内存访问,提高整体效率。
以矩阵乘法为例,该操作通过两个输入矩阵 $A$ 和 $B$ 计算输出矩阵 $C$:
$$ C = A \times B $$
其中每个元素 $C[i,j]$ 通过以下公式计算:
$$ C[i,j] = \sum_{k} A[i,k] \times B[k,j] $$
朴素实现直接按公式执行(见示例 24)。
示例 24:朴素矩阵乘法:该代码直接实现矩阵乘法,展示输出矩阵中每个元素如何通过输入矩阵中对应元素的乘积求和计算得出。
for i in range(N):
for j in range(N):
for k in range(N):
C[i, j] += A[i, k] * B[k, j] # 重复读取
# A[i, k] 和 B[k, j]
乍一看,该方法似乎正确——它计算了期望的结果,并遵循数学定义。然而,问题在于内存访问方式。每当最内层循环运行时,它就从内存中获取一个矩阵和一个矩阵的元素,执行乘法,并更新一个矩阵的元素。由于矩阵很大,处理器经常需要重新加载相同的值,即使它们在先前的计算中刚刚被使用过。
这种不必要的数据搬运是昂贵的。从主内存(DRAM)获取值的速度比访问片上缓存或寄存器中的值慢数百倍。如果相同的值必须多次重新加载而不是存储在快速内存中,执行速度会显著下降。
分块的性能优势
与其一次计算一个元素并不断移动数据,不如分块一次处理子矩阵(块),在快速内存中保留常用值。其思想是将矩阵划分为适合处理器缓存或共享内存的小块,确保一旦加载块,就可以在处理多个计算后再转到下一个块。
下方代码(示例 25)展示了分块的矩阵乘法实现,通过处理数据块来优化内存使用,提升计算效率。
示例 25:分块矩阵乘法:该方法将矩阵划分为较小的块,以优化内存使用,通过在处理器缓存中复用数据,避免不必要的内存传输,从而提高计算效率。
TILE_SIZE = 32 # 根据硬件限制选择块大小
for i in range(0, N, TILE_SIZE):
for j in range(0, N, TILE_SIZE):
for k in range(0, N, TILE_SIZE):
# 计算子矩阵
# C[i:i+TILE_SIZE, j:j+TILE_SIZE]
for ii in range(i, i + TILE_SIZE):
for jj in range(j, j + TILE_SIZE):
for kk in range(k, k + TILE_SIZE):
C[ii, jj] += A[ii, kk] * B[kk, jj]
这种重构显著提升性能,主要有以下三方面原因:
更好的内存复用:与其反复从慢速内存中获取元素 $A$ 和 $B$,不如一次加载一小块数据到快速内存中,进行多次计算后再转到下一个块。这样可最大限度减少冗余内存访问。
降低内存带宽使用:由于每个块被多次使用,内存流量减少。大多数所需数据在 L1/L2 缓存或共享内存中可用,减少了对 DRAM 的访问。
提高计算效率:处理器无需等待数据,能更多地进行有用计算。在 GPU、TPU 等架构中,数千个并行处理单元同时工作,分块确保数据以结构化方式被读取和处理,避免不必要的停顿。
该技术在 AI 加速器中尤为有效,因为机器学习负载通常涉及大规模矩阵乘法和张量变换。若不分块,这些负载很快会受到内存带宽的限制,导致性能瓶颈。
分块方法
尽管分块的基本原理是将大计算划分为较小的子问题以提高内存复用,但根据计算结构和硬件限制,应用分块有不同的方法。主要有空间分块和时间分块两种策略。它们优化计算和内存访问的不同方面,实际应用中常结合使用以达到最佳性能。
空间分块
空间分块通过将数据结构划分为适合处理器快速内存的小块,减少冗余内存访问。该方法确保每个块在转向下一个块之前被完全处理,广泛用于矩阵乘法、卷积和 Transformer 模型的注意力机制等操作中。
空间分块如示例 26 所示,计算按输入矩阵的块顺序进行。
示例 26:空间分块:通过顺序处理矩阵块,减少冗余内存访问。
TILE_SIZE = 32 # 根据可用快速内存选择块大小
for i in range(0, N, TILE_SIZE):
for j in range(0, N, TILE_SIZE):
for k in range(0, N, TILE_SIZE):
# 一次处理一个子矩阵(块)
for ii in range(i, i + TILE_SIZE):
for jj in range(j, j + TILE_SIZE):
for kk in range(k, k + TILE_SIZE):
C[ii, jj] += A[ii, kk] * B[kk, jj]
在该实现中,每个 $A$ 和 $B$ 的块在处理前加载到缓存或共享内存中,确保相同数据无需反复从慢速内存中获取。块被充分利用后再转向下一个,最大限度减少冗余内存访问。由于数据以结构化、局部化方式访问,缓存效率显著提高。
空间分块在处理大张量时尤为有效,避免过度数据在内存层次间传输。该技术在 AI 加速器中广泛应用于机器学习负载,涉及大规模张量操作时,通过精确内存管理实现高性能。
时间分块
时间分块则通过重组计算过程来提高数据复用。许多机器学习负载涉及重复访问相同数据的操作。未使用时间分块时,可能导致冗余内存获取,降低效率。时间分块通过确保频繁使用的数据在快速内存中停留更长时间,减少不必要的内存访问。
卷积操作就是时间分块受益的经典例子,卷积核需在多个输入区域应用。未使用时间分块时,卷积核可能需多次从内存加载。使用时间分块后,计算被重组,以便在多个输入间复用相同的数据块,减少冗余内存获取,提高整体效率。
下方代码(示例 27)展示了矩阵乘法中时间分块的简化示例。
示例 27:时间分块:通过在多个矩阵乘法间缓存权重,减少冗余内存访问。
for i in range(0, N, TILE_SIZE):
for j in range(0, N, TILE_SIZE):
for k in range(0, N, TILE_SIZE):
# 计算前加载块到快速内存
A_tile = A[i:i+TILE_SIZE, k:k+TILE_SIZE]
B_tile = B[k:k+TILE_SIZE, j:j+TILE_SIZE]
for ii in range(TILE_SIZE):
for jj in range(TILE_SIZE):
for kk in range(TILE_SIZE):
C[i+ii, j+jj] += A_tile[ii, kk] *
B_tile[kk, jj]
时间分块通过确保加载到快速内存的数据被多次使用,减少数据加载次数,从而提高性能。在该实现中,矩阵 $A$ 和 $B$ 的小块在计算前显式加载到临时存储,减少内存获取开销。该重构使计算能够处理整个块后再转向下一个,降低数据加载频率。
该技术在卷积、循环神经网络(RNN)和 Transformer 自注意力机制等需重复使用某些值的负载中尤为有效。通过应用时间分块,AI 加速器可显著降低内存停顿,提高执行吞吐。
分块挑战与权衡
尽管分块通过优化内存复用和减少冗余内存访问显著提升性能,但也带来了一些挑战和权衡。选择合适的块大小至关重要,直接影响计算效率和内存带宽使用。若块大小过小,分块收益降低;若块大小过大,可能超出可用快速内存,导致缓存冲突和性能下降。
负载均衡是另一个关键问题。在 GPU、TPU 等架构中,计算在数千个处理单元间并行执行。若块分配不均,部分单元可能空闲而其他单元过载,导致计算资源利用率低下。有效的块调度确保并行执行均衡高效。
数据搬运开销也是重要考虑因素。尽管分块减少了慢速内存访问次数,但在不同内存层次间传输块仍需成本。尤其在层次化内存系统中,从缓存访问数据远快于从 DRAM 访问。高效的内存预取和调度策略可最小化延迟,确保数据按需可用。
除空间和时间分块外,混合方法结合两者策略,以实现最佳性能。混合分块根据工作负载特定约束动态调整块大小或重排计算。某些 AI 加速器对矩阵乘法采用空间分块,而对卷积层的权重复用则采用时间分块。
除分块外,还有其他方法可优化内存使用和计算效率,如寄存器分块、双缓冲和分层分块等。AI 编译器和运行时系统(如 TensorFlow XLA、TVM、MLIR)会根据硬件约束自动选择分块策略,实现精细化性能优化,无需手动干预。
下表(表 17)对比了空间、时间和混合分块方法,突出各自的优缺点。
| 方面 | 空间分块(数据分块) | 时间分块(循环阻塞) | 混合分块 |
|---|---|---|---|
| 主要目标 | 通过让数据在快速内存中停留更长时间来减少内存访问 | 增加跨循环迭代的数据复用 | 根据工作负载约束动态适应 |
| 优化重点 | 将数据结构划分为更小的、适合内存的块 | 重新排序计算以最大化复用,避免冗余访问 | 平衡空间和时间复用策略 |
| 内存使用 | 提高缓存局部性,减少 DRAM 访问 | 保持频繁使用的数据在快速内存中,减少换出 | 在确保高复用的同时最小化数据搬运 |
| 常见用例 | 矩阵乘法、CNN、自注意力机制 | 卷积、循环神经网络(RNN)、迭代计算 | 具有层次化内存、混合工作负载的 AI 加速器 |
| 性能提升 | 降低内存带宽需求,改善缓存利用率 | 降低内存获取延迟,改善数据局部性 | 在多种硬件类型上实现最大化效率 |
| 挑战 | 需要仔细选择块大小,低复用工作负载效率低下 | 可能增加寄存器压力,需要重构循环 | 动态调整块大小和执行顺序的复杂性 |
| 最佳场景 | 数据较大且需分块以高效处理 | 多次访问相同数据的迭代计算 | 空间分块和时间分块都很重要的场景 |
随着机器学习模型规模和复杂性不断增长,分块仍然是提升硬件效率的关键工具,确保 AI 加速器充分发挥潜力。尽管手动分块策略能带来显著收益,但现代编译器和硬件感知优化技术通过自动选择最有效的分块策略,进一步提升性能。
将映射策略应用于神经网络
尽管这些基础映射技术适用性广,但其有效性因神经网络架构的计算结构、数据访问模式和并行化机会而异。每种架构对数据流动、内存层次和计算调度施加不同约束,需量身定制映射策略以优化性能。
系统化的映射方法可有效应对将计算分配给 AI 加速器时出现的组合爆炸。不同模型并非各自独立优化,而是可应用相同的基本原理,只是其优先级根据工作负载特征而变化。目标是系统地选择和应用映射策略,以最大化不同机器学习模型的执行效率。
这些原理适用于三种典型 AI 工作负载,分别具有不同的计算需求。CNN 受益于空间数据复用,使权重驻留执行和分块技术尤为有效。Transformer 则本质上受制于内存,依赖于高效的 KV 缓存管理、融合注意力机制和高度并行的执行来减轻内存流量。MLP 涉及大量矩阵乘法操作,需采用结构化分块、优化权重布局和内存感知执行来提升整体性能。
尽管它们各不相同,但这些模型遵循一套共同的映射原理,优化策略的优先级有所不同。下表为不同优化策略与 CNN、Transformer 和 MLP 的适用性提供了结构化映射。该表可作为选择不同机器学习工作负载映射策略的路线图。
| 优化技术 | CNNs | Transformers | MLPs | 原理 |
|---|---|---|---|---|
| 数据流策略 | 权重驻留 | 激活驻留 | 权重驻留 | CNN 在空间位置复用滤波器;Transformer 复用激活(KV 缓存);MLP 在批次间复用权重。 |
| 内存感知张量布局 | NCHW(通道主序) | NHWC(行主序) | NHWC | CNN 卷积效率优先通道主序;Transformer 和 MLP 优先行主序以快速访问内存。 |
| 算子融合 | 卷积 + 激活 | 融合注意力 | GEMM 融合 | CNN 优化卷积 + 激活融合;Transformer 融合注意力机制;MLP 利用融合的矩阵乘法。 |
| 内存效率分块 | 空间分块 | 时间分块 | 块状分块 | CNN 在空间维度分块;Transformer 通过循环阻塞提升序列内存效率;MLP 对大矩阵乘法采用块状分块。 |
该表强调了每种机器学习模型受益于不同优化技术的组合,强化了针对工作负载计算和内存特征量身定制执行策略的重要性。
接下来,我们将探讨这些优化如何应用于每种网络类型,解释 CNN、Transformer 和 MLP 如何利用特定映射策略提升执行效率和硬件利用率。
卷积神经网络
CNN 的特征在于其结构化的空间计算,其中小滤波器(或核)反复应用于输入特征图。这种结构化的权重复用使得权重驻留执行成为 CNN 最有效的策略。通过在快速内存中保持滤波器权重,同时流式传递激活,确保权重无需反复从较慢的外部内存加载,从而显著降低内存带宽需求。由于每个权重在多个空间位置上应用,权重驻留执行最大化了算术强度,最小化了冗余内存传输。
内存感知张量布局在 CNN 执行中也起着关键作用。卷积操作受益于通道主序内存格式,通常表示为 NCHW(批次、通道、高度、宽度)。该布局与卷积的访问模式一致,能够在 GPU 和 TPU 等加速器上实现高效的内存合并。通过以优化缓存局部性的格式存储数据,加速器可以高效地获取连续的内存块,降低延迟,提高吞吐量。
算子融合是 CNN 优化的另一个重要方面。在典型的机器学习管道中,卷积操作后通常跟随激活函数如 ReLU 和批归一化。通过将这些操作视为单独的计算步骤,融合它们可以减少中间内存写入,提高执行效率。这一优化通过将中间值保留在寄存器中,而不是写入内存并在后续步骤中重新获取,最小化了内存带宽压力。
鉴于输入图像和特征图的大小,分块是确保计算适应快速内存层次结构的必要手段。空间分块,即按较小子区域处理输入特征图,能够高效利用片上缓存,同时避免过多的片外内存传输。该技术确保输入激活、权重和中间输出在高速缓存或共享内存中尽可能长时间地保持,从而减少内存停顿,提高整体性能。
这些优化确保 CNN 通过最大化权重复用、优化内存访问模式、减少冗余内存写入和结构化计算以适应快速内存限制,充分利用可用计算资源。
Transformer 架构
与依赖结构化空间计算的 CNN 不同,Transformers 处理可变长度序列,并高度依赖注意力机制。Transformers 的主要计算瓶颈是内存带宽,因为注意力机制需要频繁访问存储的键值对。鉴于这种访问模式,激活驻留执行是最有效的策略。通过在快速内存中保持键值激活,同时动态流式传递查询向量,最大化激活复用,最小化冗余内存获取。这一方法对于减少带宽开销至关重要,尤其是在自然语言处理等长序列任务中。
张量布局优化对于 Transformers 同样重要。与 CNN 受益于通道主序布局不同,Transformers 需要高效访问激活序列,因此更倾向于使用行主序格式(NHWC)。该布局确保激活在内存中连续访问,减少缓存未命中,提高矩阵乘法的内存合并效率。
算子融合在优化 Transformer 执行中发挥关键作用。在自注意力机制中,查询 - 键点积、softmax 归一化和加权求和等多个计算步骤可以融合为单一操作。融合注意力内核通过在单次执行步骤中计算注意力分数和执行加权求和,消除中间内存写入。这一优化显著减少了内存流量,特别是在大批量和长序列的情况下。
由于序列处理的特点,分块需适应性调整以提高内存效率。与对 CNN 有效的空间分块不同,Transformers 更益于时间分块,即结构化计算以高效处理序列块。该方法确保激活以可管理的块加载到快速内存中,减少过多的内存传输。时间分块对长序列模型尤为有效,因为此时键值激活的内存占用显著增加。通过将序列分块为较小的片段,改善了内存局部性,提高了缓存利用率,降低了带宽压力。
这些优化共同解决了 Transformer 模型中的主要瓶颈,通过优先激活复用、优化内存布局以适应高效批量计算、融合注意力操作以减少中间内存写入,以及采用适合序列处理的分块技术。
多层感知机
MLP 主要由全连接层组成,其中大量权重和激活矩阵相乘以生成输出表示。鉴于这种结构,权重驻留执行是 MLP 最有效的策略。与 CNN 类似,MLP 通过在流式传递激活的同时保持权重在本地存储中,避免频繁重新加载权重,从而减少冗余内存访问。
MLP 的首选内存布局与 Transformer 相同,行主序(NHWC)格式的矩阵乘法效率更高。由于激活矩阵是批量处理的,该布局确保输入激活高效访问,避免内存碎片。通过将张量存储与计算友好的内存访问模式对齐,改善了缓存利用率,降低了内存停顿。
算子融合主要应用于 MLP 的通用矩阵乘法(GEMM)22 操作。由于密集层后通常跟随激活函数和偏置加法,将这些操作融合为单一计算步骤可减少内存流量。GEMM 融合确保激活、权重和偏置在单个优化内核中处理,避免不必要的内存写入和重新加载。
为了进一步提高内存效率,MLP 采用块状分块策略,即将大矩阵乘法划分为适合加速器共享内存的小块。这种方法确保矩阵的频繁访问部分在整个计算过程中保持在快速内存中,减少对外部内存的访问。通过以平衡内存利用率和高效并行执行的方式构建计算,块状分块最大限度地减少带宽限制,提升吞吐量。
这些优化确保 MLP 通过围绕权重复用构建执行、优化密集矩阵操作的内存布局、通过算子融合减少冗余内存写入,以及采用块状分块策略最大化片上内存利用率,实现高计算效率。
混合映射策略
尽管通用映射策略提供了结构化优化框架,但实际架构通常涉及多样的计算需求,单一固定方法难以有效解决。混合映射策略使 AI 加速器能够动态地对模型内的特定层或组件应用不同的优化,确保每个计算都以最高效率执行。
机器学习模型通常由多种类型的层组成,每种层具有不同的内存访问模式、数据复用特性和并行化机会。通过针对这些特定属性量身定制映射策略,混合方法在计算效率、内存带宽利用率和数据搬运开销方面实现更高的性能。
层级特定映射
混合映射策略在卷积与全连接操作(如密集层或注意力机制)结合的模型中尤为有效。这些操作具有不同的特性,需要不同的映射策略以实现最佳性能。
在卷积神经网络中,混合策略常用于优化性能。具体而言,卷积层应用权重驻留执行,确保滤波器在动态流式传递激活时保持在本地存储。对于全连接层,则利用输出驻留执行,在矩阵乘法过程中减少冗余内存写入。此外,还集成了算子融合,将激活函数、批归一化和逐元素操作合并为单一计算步骤,从而降低中间内存流量。这些方法共同提升了计算效率和内存利用率,增强了网络整体性能。
Transformer 通过优化内存使用和计算效率的多种策略提升性能。在自注意力层中,采用激活驻留映射以最大化存储的键值对复用,减少内存获取。在前馈层中,则应用权重驻留映射,确保大权重矩阵在计算中高效复用。此外,这些模型还结合了融合注意力内核,将 softmax 和加权求和合并为单一计算步骤,显著提升执行速度。
对于多层感知机,混合映射策略通过一系列技术优化性能,提升内存效率和计算吞吐。具体而言,采用权重驻留执行以最大化权重在激活间的复用,减少冗余内存访问。同时,对大矩阵乘法采用块状分块策略,提升缓存局部性,将计算划分为适合快速内存的子块。此外,还应用了通用矩阵乘法融合,减少内存停顿,通过合并连续的矩阵乘法操作和后续的功能变换,提升执行效率。这些优化措施展示了如何通过量身定制的映射策略,系统地平衡多层感知机架构中的内存约束和计算需求。
混合映射策略在视觉 Transformer 中广泛应用,融合了卷积与自注意力操作。Patch embedding 层采用类似卷积的权重驻留映射,自注意力层则需激活驻留以高效复用键值缓存。MLP 部分则结合矩阵乘法融合和分块,实现高效密集矩阵运算。该分层优化框架有效平衡了内存局部性与计算效率,使视觉 Transformer 在 AI 加速器 上表现尤为优异。
混合映射策略的硬件实现
许多现代 AI 加速器采用混合映射策略,通过针对不同神经网络层的计算特点,灵活选择最优的映射方式以提升执行效率。例如,Google TPU 在卷积层采用权重驻留映射,而在 Transformer 的注意力层则采用激活驻留映射,确保关键数据始终保留在高速存储器中。NVIDIA GPU 则通过融合内核与混合内存布局,在同一模型中灵活应用多种映射策略,最大化性能表现。Graphcore IPU 能够根据每一层的需求动态选择执行策略,优化内存访问,从而提升整体计算效率。
这些实际案例说明,混合映射策略能够有效弥合不同类型机器学习计算的差异,使每一层都能以最高效的方式运行。但要让这些技术真正落地,硬件必须具备可编程的内存层级、高效互连和专用执行流水线等架构特性,才能充分发挥混合映射的优势。
混合映射为深度学习执行提供了灵活高效的方案,使 AI 加速器能够适应现代架构多样化的计算需求。通过为每一层选择最优映射方式,混合策略有助于缓解内存带宽瓶颈、提升数据局部性并最大化并行度。
不过,混合映射策略本质上仍属于静态设计时优化。在实际 AI 工作负载中,输入规模、内存争用或硬件资源可用性等执行条件会动态变化。机器学习编译器和运行时系统通过引入动态调度、内存优化和自动调优机制,将这些映射技术扩展为可适应的执行方案。这样,混合策略不再只是预设的执行选项,而是能够根据实际环境自适应调整的机制,使深度学习任务在不同加速器和部署场景下都能高效运行。下一节将介绍机器学习编译器和运行时如何通过即时调度、内存感知执行和负载均衡,实现这些自适应优化。
编译器支持
机器学习加速的性能不仅取决于硬件能力,更依赖于模型如何高效地转化为可执行操作。内核融合、分块、内存调度和数据移动等优化技术对于提升效率至关重要,但这些优化必须在执行前系统性地应用,确保与硬件约束和计算需求相匹配。
这一过程正体现了 第 11 章:AI 加速 中提出的软硬件协同设计原则:机器学习编译器在高层模型表达与底层硬件执行之间架起桥梁。编译器通过重构计算、选择高效执行内核、最大化硬件利用率来优化模型。与传统编译器主要针对通用计算不同,ML 工作负载需要专门面向张量计算和并行执行的优化方法。
面向 ML 工作负载的编译器设计差异
机器学习工作负载带来了传统编译器难以应对的独特挑战。与传统软件主要是顺序或多线程流程不同,机器学习模型以计算图形式表达大规模张量操作。这些图结构需要专门的优化,传统编译器难以高效处理。
下表(@tbl-ml-vs-traditional-compilers)对比了传统编译器与机器学习编译器的核心差异。传统编译器通过指令调度、循环展开和寄存器分配优化线性程序执行,而 ML 编译器则聚焦于计算图的优化,提升张量操作效率。这一差异至关重要,因为 ML 编译器必须引入领域特定的变换,如内核融合、内存感知调度和硬件加速执行计划,才能在 GPU、TPU 等专用加速器上实现高性能。
这种对比说明,机器学习模型需要完全不同的编译思路。ML 编译器不仅要优化指令级执行,更要对整个计算图进行变换,应用张量感知的内存优化,并在数千个并行处理单元间调度操作。传统编译器技术已无法满足现代深度学习的需求。
| 方面 | 传统编译器 | 机器学习编译器 |
|---|---|---|
| 输入表达 | 线性程序代码(C、Python) | 计算图(ML 模型) |
| 执行模型 | 顺序或多线程执行 | 大规模并行张量执行 |
| 优化重点 | 指令调度、循环展开、寄存器分配 | 图变换、内核融合、内存感知执行 |
| 内存管理 | 堆栈与堆内存分配 | 张量布局变换、分块、内存感知调度 |
| 目标硬件 | CPU(通用执行) | GPU、TPU 及定制加速器 |
| 编译输出 | 针对 CPU 的机器码 | 针对硬件的执行计划(内核、内存调度) |
ML 编译流程
现代框架定义的机器学习模型,最初以高层计算图形式描述张量操作。但这些表达并不能直接在 GPU、TPU 或定制 AI 芯片上高效执行。为实现高效运行,模型必须经过编译流程,转化为针对目标硬件优化的执行计划。
机器学习编译流程包含多个关键阶段,每一阶段都负责应用特定优化,确保内存开销最小、并行度最大、计算资源利用最优。主要阶段包括:
- 图优化:重构计算图,消除低效结构。
- 内核选择:将每个操作映射到硬件优化实现。
- 内存规划:优化张量布局和内存访问,降低带宽消耗。
- 计算调度:将任务分配到并行处理单元,最大化硬件利用率。
- 代码生成:将优化后的执行计划转化为硬件指令。
每一阶段都系统性地应用前述理论优化,如内核融合、分块、数据移动和计算分配,确保最终执行计划充分体现这些优化。
理解这一流程,有助于认识机器学习加速不仅依赖硬件进步,更离不开编译器驱动的软件优化。
图优化
AI 加速器提供专用硬件加速计算,但原始模型表达并未针对加速器优化。机器学习框架以高层计算图定义模型,节点代表操作(如卷积、矩阵乘法、激活),边则描述数据依赖。如果直接执行这些图,往往存在冗余操作、低效内存访问和次优执行序列,导致硬件无法充分发挥性能。
例如,Transformer 模型中的自注意力机制会在多个头部重复访问同一组键值对。如果编译器未优化,模型可能多次加载同一数据,造成大量内存流量。又如 CNN 中,卷积后分别执行批归一化和激活函数,若作为独立操作,会产生不必要的中间内存写入,增加带宽消耗。图优化阶段正是通过重构计算图,消除冗余操作、提升数据局部性。
编译器在此阶段以硬件无关的方式优化高层结构,为后续硬件特定优化打下基础。
计算图优化技术
图优化通过一系列结构化技术提升执行效率。核心方法包括内核融合,将连续操作合并,减少内存写入和内核启动次数,尤其在卷积神经网络中,融合卷积、批归一化和激活函数能显著加速处理。计算重排序则调整操作顺序,提升数据局部性和并行度。例如在 Transformer 中,重排序可复用缓存的键值对,避免重复加载,降低延迟。
冗余计算消除同样重要,识别并移除重复或无用操作,尤其在残差连接模型中,能避免重复计算公共子表达式。内存感知数据流调整则通过优化张量布局和数据移动,提升整体性能。例如将矩阵乘法分块以适配 TPU 的结构化阵列,确保硬件资源充分利用。这些方法不仅减少不必要计算,还使数据存储和移动更贴合加速器特点,实现多样化 AI 工作负载的高效执行。综合应用后,模型能以最小开销、最优算存平衡准备加速执行。
AI 编译器中的实现
现代 AI 编译器通过自动模式识别和结构化重写规则实现图优化,无需人工干预即可系统性提升计算图效率。例如 Google TensorFlow 的 XLA(加速线性代数)在 TPU 和 GPU 上应用融合与布局优化,简化执行流程。TVM(张量虚拟机)不仅优化张量布局和计算结构,还能针对嵌入式 Tiny ML 设备的严苛内存约束调整执行策略。
NVIDIA TensorRT 专注于通过融合操作和优化调度,减少 GPU 内核启动开销,提升大规模卷积网络推理延迟。MLIR(多层中间表示)则支持多阶段变换,优化执行顺序和内存访问,便于模型从 CPU 迁移到加速器。所有这些编译器都在保持模型数学正确性的前提下,重写计算图,为后续硬件特定优化奠定基础。
图优化的重要性
图优化是 AI 加速器高效运行的关键。没有这一阶段,即使最先进的硬件也会因模型执行方式低效而被严重浪费,出现内存阻塞、冗余计算和低效数据移动。编译器通过系统性重构计算图,安排操作以高效执行,提前消除瓶颈,减少内存移动、保持张量在高速存储中,并优化并行度,避免不必要的串行化,提升硬件利用率。例如,未优化的 Transformer 在边缘设备上可能因数据访问模式不佳而频繁内存阻塞,而通过有效图重构,则能大幅降低带宽消耗和延迟,实现实时推理。
完成图优化后,下一步是内核选择,编译器将每个操作映射到最优硬件实现,确保结构化执行计划转化为底层高效指令。
内核选择
此阶段,编译器将计算图中的抽象操作转化为针对目标加速器的优化底层函数。内核是针对特定硬件架构高效运行的计算操作实现。大多数加速器(GPU、TPU、定制 AI 芯片)为同一操作提供多种内核实现,分别适用于不同执行场景。为每个操作选择最合适的内核,是提升计算吞吐量、减少内存阻塞、充分利用专用处理单元的关键。
内核选择是在图优化基础上进行的,确保结构化执行计划能映射到最优实现。图优化消除模型层面的低效,内核选择则保证每个操作都用最优硬件例程执行。选择不当会抵消前期优化,带来额外计算开销或内存瓶颈。
以 Transformer 为例,自注意力中的矩阵乘法可根据硬件采用不同策略:在 CPU 上用通用矩阵乘法例程,利用向量化提升效率;在 GPU 上则选用张量核加速的混合精度实现;在 TPU 上则映射到结构化阵列,最大化数据复用、减少外部内存访问。推理场景下,整数算术内核(INT8)常优于浮点,实现低功耗高效计算。
编译器通常不从零生成内核,而是从厂商优化库中选择高性能实现。例如 NVIDIA 的 cuDNN、cuBLAS,Intel 的 oneDNN,Arm 的 ACL,CPU 的 Eigen、BLIS 等。这些库为不同架构提供高度调优的内核,编译器只需选择最优即可。
AI 编译器中的实现
AI 编译器通过启发式、性能分析和成本模型选择最优内核,确保每次计算都能最大化吞吐量、最小化内存瓶颈。
规则选择法根据硬件能力预设启发式规则。例如 TensorFlow 的 XLA 在启用混合精度时自动选择 NVIDIA GPU 的张量核优化内核,无需复杂分析即可快速决策。
性能分析法则通过实际基准测试不同内核,选取表现最佳者。TVM 的 AutoTVM 就是通过实测不同内核性能,针对实际工作负载调优执行策略,确保每次操作都用最优实现。
成本模型法则通过预测不同内核的执行时间和内存消耗,选择最优方案。MLIR 就采用此法,评估分块和内存访问策略,确保内核选择能兼顾执行成本和性能。
许多 AI 编译器还支持精度感知内核选择,根据 FP32、FP16、BF16、INT8 等数值格式优化内核。训练场景优先高精度,推理则倾向低精度以提升速度和降低功耗。例如 NVIDIA GPU 的 TensorRT 可根据模型精度动态选择 FP16 或 INT8 内核,兼顾精度与性能。
部分编译器还支持自适应内核调优,根据系统负载和资源动态调整执行策略。TVM 的 AutoTVM 能跨不同工作负载测量内核性能并动态优化,TensorRT 可根据批量大小、内存约束和 GPU 负载实时调整内核选择,Google TPU 编译器也会根据云资源和环境优化内核选择。
内核选择的重要性
AI 加速的效率不仅取决于计算结构,还取决于具体执行方式。即使计算图设计得再好,若选用的内核无法充分利用硬件,性能也会大打折扣。
合理的内核选择让模型能用最优算法执行,确保内存访问高效、专用加速特性(如张量核、结构化阵列)充分发挥。选择不当会导致计算资源闲置、内存传输过多、功耗增加,严重影响加速器性能。
例如,Transformer 在 GPU 上若未用张量核内核,矩阵乘法性能仅为理论值的一小部分;反之,若 FP32 模型强行用 INT8 内核,则可能数值不稳定、精度下降。这些选择既关乎性能,也关乎数值正确性。
完成内核选择后,编译流程进入执行调度和内存管理阶段,决定内核如何启动、数据如何在内存层级间流动。内核选择决定“做什么”,调度和内存管理则决定“何时、如何做”,确保 AI 加速器高效运行。
内存规划
内存规划阶段确保数据分配和访问方式能最大限度降低带宽消耗、减少延迟、提升缓存效率。即使执行计划再优化,若内存管理不当,模型性能也会严重受损。
机器学习工作负载通常对内存需求极高,需频繁在不同内存层级间移动大张量。编译器必须合理安排张量存储、访问和中间结果处理,防止内存成为瓶颈。
内存规划聚焦于优化张量布局、访问模式和缓冲区复用,避免执行时出现阻塞和争用。此阶段,张量按硬件访问模式高效排布,减少格式转换;内存访问结构化,降低缓存未命中和阻塞,减少带宽消耗;缓冲区复用则通过智能管理中间结果,减少冗余分配。综合这些策略,数据能高效存放和访问,提升 AI 工作负载的计算性能和能效。
AI 编译器中的实现
内存规划极为复杂,AI 模型需在多层内存层级间平衡可用性、复用和访问效率。AI 编译器采用多种关键策略高效管理内存,防止不必要的数据移动。
第一步是张量布局优化,编译器根据硬件偏好自动调整张量在内存中的排列方式,提升局部性、避免格式转换。例如 NVIDIA GPU 常用行主序(NHWC),TPU 则偏好通道主序(NCHW),编译器会自动转换布局,确保访问模式最优。
其次是缓冲区分配与复用,编译器通过分析计算图,识别中间张量复用机会,避免每次都新分配内存,减少内存占用。深度学习任务会生成大量临时张量(如激活、梯度),若不复用,很快就会耗尽片上内存。
第三是最小化不同内存层级间的数据移动。AI 加速器通常有高速片上内存(如缓存、SRAM)和大容量但较慢的外部 DRAM。若张量频繁在这些层级间移动,模型会受限于内存带宽,降低计算效率。编译器通过分块,将大计算拆分为适合本地内存的小块,减少昂贵的外部内存访问。
内存规划的重要性
没有高效内存规划,即使计算图和内核选择再优化,也无法实现高性能。过多的内存传输、低效布局和冗余分配都会成为瓶颈,阻碍加速器发挥最大吞吐量。
例如,CNN 在 GPU 上理论上计算效率很高,但若特征图布局不兼容(如用行主序而需转为通道主序),频繁格式转换会带来巨大开销。Transformer 在边缘设备上若内存规划不当,难以满足实时推理需求,频繁外部内存访问会导致延迟和功耗飙升。
通过合理张量布局、优化访问模式和减少数据移动,内存规划保障 AI 加速器高效运行,带来实际性能提升。
计算调度
完成图优化、内核选择和内存规划后,编译流程进入计算调度阶段。此阶段决定每项计算何时、何地执行,确保任务高效分配到处理单元,避免阻塞和资源争用。
AI 加速器依靠大规模并行实现高性能,但若调度策略不当,计算单元可能闲置、内存带宽未充分利用、执行效率下降。计算调度负责让所有处理单元保持活跃,正确管理依赖关系,优化任务分配。
调度阶段系统性管理并行执行、同步和资源分配。任务分解将大计算拆分为可高效分配的小任务;执行顺序优化则决定最优启动顺序,最大化硬件性能、减少阻塞;资源分配与同步确保计算核心、内存带宽和共享缓存高效利用,避免争用。通过这些协调策略,计算调度实现硬件利用最大化、内存访问延迟最小化、执行流程高效流畅。
AI 编译器中的实现
计算调度高度依赖底层硬件架构,不同加速器有独特的执行模型,编译器需针对性优化调度。
最基础的是任务分解,编译器将大计算图拆分为可并行执行的小单元。在 GPU 上,通常将矩阵乘法和卷积映射到数千个 CUDA 核心;TPU 上则分配到结构化阵列;CPU 上则分解为适合 SIMD 的向量化块。目标是高效分配任务,确保每个核心始终活跃。
调度还需优化执行顺序,减少依赖、提升吞吐量。许多 AI 模型包含可独立计算的操作(如批处理管道中的不同批次),也有严格依赖的操作(如 RNN 的循环层)。编译器分析这些依赖,尽量重排执行,减少空闲、提升并行效率。例如 Transformer 中,调度可优先预加载注意力矩阵,确保数据及时可用。
资源分配与同步同样关键,编译器决定计算核心如何共享内存、协调执行。现代加速器支持计算与数据传输重叠,编译器通过流式调度,让多个内核并行启动,精细管理同步,防止阻塞。TensorRT 和 XLA 就采用流式执行,多个内核并行启动,同步管理避免执行停滞。
计算调度的重要性
调度不当,即使模型优化得再好,也会因计算资源闲置、内存瓶颈和执行低效而性能受损。错误调度会让计算单元等待数据或同步事件,造成昂贵资源浪费。
例如,CNN 在 GPU 上即使内核和内存布局都优化,若调度不当,内核启动间隙会让计算单元闲置,吞吐量下降。Transformer 在 TPU 上矩阵乘法虽高效,但若注意力层未与内存传输重叠调度,性能同样受限。
高效调度是并行工作负载编排的核心,确保处理单元充分利用,防止空闲。通过计算与数据移动重叠,调度机制有效隐藏内存延迟,防止数据获取阻塞。精准解决执行依赖,减少等待,提升计算与数据传输并发。调度与数据管理的系统集成,不仅提升性能,也体现了现代加速器设计的严谨工程原则。
代码生成
与前述阶段需 AI 特定优化不同,代码生成遵循传统编译器的基本原则,包括指令选择、寄存器分配和最终优化,确保充分利用硬件特性(如向量化、预取、指令重排)。
对于 CPU 和 GPU,AI 编译器通常生成机器码或优化汇编指令;TPU、FPGA[^fn-fpga]等则输出优化字节码或执行图,由硬件运行时解释。
至此,编译流程完成:高层模型已转化为针对目标硬件的优化可执行格式。图变换、内核选择、内存感知执行和并行调度的结合,确保 AI 加速器以最高效率、最小内存开销和最优吞吐量运行工作负载。
编译 - 运行时支持
编译器在 AI 加速中扮演基础角色,将高层机器学习模型转化为针对专用硬件约束的优化执行计划。前文已介绍图优化重构计算、内核选择映射高效实现、内存规划优化数据布局、计算调度保障并行执行。每一阶段都至关重要,使 AI 模型充分利用现代加速器,实现高吞吐、低内存开销和高效执行流水线。
但仅靠编译并不能保证实际 AI 工作负载的高效执行。编译器基于已知模型结构和硬件能力进行静态优化,而 AI 执行环境往往动态且不可预测。批量大小变化、硬件资源多任务共享、加速器需适应实时性能约束,此时静态执行计划已无法满足,运行时管理成为保障模型高效执行的关键。
从静态编译到自适应执行的转变,正是 AI 运行时的价值所在。运行时提供动态内存分配、实时内核选择、任务调度和多芯片协调,使 AI 模型能根据实际执行条件自适应调整,持续保持高效。下一节将介绍 AI 运行时如何扩展编译器能力,使模型在多样化、可扩展部署场景下高效运行。
运行时支持
编译器在模型执行前进行优化,但实际部署环境充满动态和不可预测因素,单靠静态编译难以应对。AI 工作负载运行于多样化环境,批量大小、硬件资源、内存争用和延迟约束等因素要求实时自适应。预编译的执行计划若基于固定假设,实际运行时可能变得低效。
为解决这一问题,AI 运行时提供动态执行管理层,将编译时优化与实时决策结合。与传统编译程序执行固定指令序列不同,AI 工作负载需动态控制内存分配、内核执行和资源调度。运行时持续监控执行状态,实时调整,确保模型充分利用硬件、保持高效和性能保障。
AI 运行时主要管理三大执行关键点:
- 内核执行管理:根据系统状态动态选择和分发计算内核,确保任务以最小延迟执行。
- 内存自适应与分配:AI 工作负载常处理大张量,内存需求变化大,运行时需动态分配,防止瓶颈和多余数据移动。
- 执行扩展:运行时负责多加速器任务分配,支持多芯片、多节点或云环境下的大规模执行。
通过动态管理这些执行环节,AI 运行时补充编译器优化,确保模型在多变环境下持续高效。下一节将介绍 AI 运行时与传统软件运行时的区别,说明为何机器学习工作负载需要完全不同的执行策略。
ML 系统运行时架构差异
传统软件运行时主要管理通用程序执行,处理 CPU 上的顺序和多线程任务,负责内存分配、任务调度和指令级优化。而 AI 运行时则专为机器学习工作负载设计,需支持大规模并行计算、张量操作和动态内存管理。
下表(表 19)对比了传统与 AI 运行时的核心差异。最大区别在于执行流程:传统运行时按函数调用和线程预设控制路径执行,AI 运行时则需调度计算图,管理张量操作依赖、并行内核执行和高效内存访问。
| 方面 | 传统运行时 | AI 运行时 |
|---|---|---|
| 执行模型 | 顺序或多线程执行 | 大规模并行张量执行 |
| 任务调度 | CPU 线程管理 | 加速器内核分发 |
| 内存管理 | 静态分配(堆栈/堆) | 动态张量分配、缓冲区复用 |
| 优化重点 | 低延迟指令执行 | 最小化内存阻塞、最大化并行度 |
| 自适应性 | 基本静态执行计划 | 可根据批量和硬件动态调整 |
| 目标硬件 | CPU(通用执行) | GPU、TPU 及定制加速器 |
内存管理也是重要区别。传统运行时处理小规模、频繁分配,优化缓存和低延迟访问;AI 运行时则需动态分配、复用和优化大张量,确保内存访问模式适合加速器。内存管理不善会导致性能瓶颈,尤其是外部内存传输和缓存利用低效。
AI 运行时天生强调自适应。传统运行时多采用静态执行计划,AI 工作负载则常在云加速器或多租户硬件上运行,环境高度变化。运行时需持续调整批量、重新分配计算资源、实时调度,保证高吞吐和低延迟。
这些差异说明,AI 运行时必须采用完全不同的执行策略。它不仅管理 CPU 进程,更要协调大规模张量执行、多设备协作和实时任务自适应,确保机器学习模型在多变环境下高效运行。
动态内核执行
动态内核执行是将机器学习模型映射到硬件并优化运行时执行的过程。静态编译虽能打好基础,但高效执行机器学习任务需实时适应内存、数据规模和计算负载等变化。运行时作为中介,持续调整执行策略,兼顾硬件约束和工作负载特点。
模型映射到硬件时,矩阵乘法、卷积、激活等操作需分配到最合适的处理单元。映射不是固定的,需根据输入数据、内存可用性和系统负载实时调整。动态内核执行让运行时能实时决策内核选择、执行顺序和内存管理,确保任务始终高效。
例如,AI 加速器执行图像分类 DNN 时,若高分辨率图片批量超出预期,静态计划可能导致缓存抖动或频繁外部内存访问。动态运行时可即时调整分块策略,将张量操作拆分为适合片上高速存储的小块,防止内存阻塞,优化缓存利用。
Transformer NLP 模型推理时,输入文本序列长度可能变化。静态计划若只针对固定长度,处理短序列时资源利用不足,长序列时内存压力过大。动态内核执行可根据实际序列长度选择不同内核实现,动态分配内存和调整执行策略,保持高效。
计算与内存移动重叠是缓解性能瓶颈的关键。AI 工作负载常因内存瓶颈而延迟,运行时通过异步执行和双缓冲等技术,确保计算无需等待内存传输。例如大模型中,图像数据可预取,计算同时处理上一批数据,保持数据流畅,避免流水线阻塞。
CNN 在 GPU 上执行卷积层时,若需调度多个卷积内核,静态调度可能因层大小和计算需求差异导致资源利用低下。动态调度可在计算单元部分占用时优先调度小内核,提升硬件利用率。NVIDIA TensorRT 运行时会动态融合小内核为大执行单元,优化延迟敏感推理任务。
动态内核执行确保机器学习模型高效运行,通过实时调整执行策略,优化训练和推理性能,适应多种硬件平台。
运行时内核选择
编译器可根据模型和硬件静态选择内核,但 AI 运行时常需在执行时覆盖这些决策。实际可用内存、硬件利用率和任务优先级等实时因素,可能与编译假设大相径庭。运行时动态选择和切换内核,能适应这些变化,确保模型持续高效。
例如,Transformer 语言模型执行时,大量时间用于矩阵乘法。AI 运行时需根据系统状态选择最优执行方式。若在具备 Tensor Core 的 GPU 上,运行时可从标准 FP32 内核切换到 FP16 内核,充分利用硬件加速。若 FP16 精度不足,运行时可采用混合精度,仅在需要高精度时用 FP32。
内存约束也影响内核选择。带宽有限时,运行时可调整执行策略,重排操作或改变分块方式,使计算能在缓存内完成,减少对慢速主存的依赖。例如大矩阵乘法可拆分为小块,确保计算在 GPU 片上内存内完成,降低延迟。
批量大小同样影响内核选择。混合小批量和大批量任务时,运行时可为小批量选用低延迟内核,大批量则用高吞吐内核,确保模型在不同场景下都能高效运行,无需手动调优。
内核调度与利用率
运行时选定内核后,下一步是高效调度,最大化并行度和资源利用。与传统任务调度只管理 CPU 线程不同,AI 运行时需协调大量任务在 GPU 核心、张量处理单元或定制加速器间并行。高效调度确保计算资源充分利用,防止瓶颈、提升吞吐量。
例如,图像识别模型中的卷积层可分配到多个处理单元,不同滤波器并行运行,确保硬件充分利用,加速执行。批归一化和激活函数也需高效调度,避免阻塞流水线、降低吞吐量。
高效内核调度还需结合实时内存管理。运行时确保中间数据(如深度网络特征图)提前预载入缓存,防止因等待数据加载而延迟,保证执行连续。
这些技术让 AI 运行时实现资源利用最大化和高效并行计算,尤其适用于需多加速器扩展的高性能机器学习模型。
编译器和运行时系统优化了单加速器内的执行——管理计算映射、内存层级和内核调度。虽然单芯片优化已能带来显著性能提升,但现代 AI 工作负载已远超单加速器能力。训练 GPT-3 需单台 H100 连续运行 10 年,消耗 314 百万亿次浮点运算。全球实时推理服务需求也远超单加速器吞吐量。这些需求源于 第 9 章:高效 AI 中的扩展定律,推动从单芯片优化向分布式加速转型。
多芯片 AI 加速
从单芯片到多芯片架构的转变,不仅仅是简单复制——它要求重新思考如何在处理器间分配计算、数据如何在芯片间流动,以及系统如何在大规模下保持一致性。单芯片优化侧重于在固定资源内最大化利用率,而多芯片系统则必须在计算分布、通信开销、内存一致性和同步复杂性之间取得平衡。这些挑战从根本上改变了优化格局,要求超越单个加速器开发的新抽象和技术。
现代 AI 工作负载日益需要超出单芯片加速器能力的计算资源。本节将探讨 AI 系统如何从单处理器扩展到多芯片架构,分析不同扩展方法背后的动机及其对系统设计的影响。这些扩展考虑因素对于 第 8 章:AI 训练 中讨论的分布式训练策略,以及 第 13 章:机器学习运维 中讨论的操作挑战至关重要。分布式加速的安全隐患,尤其是模型保护和数据隐私方面,将在 第 15 章:安全与隐私 中探讨。通过理解这一进程,我们可以更好地认识到 AI 硬件栈中每个组件(从计算单元到内存系统)如何适应大规模机器学习工作负载。
AI 系统的扩展遵循自然进程,从通过芯片组架构在单一封装内集成,扩展到服务器内的多 GPU 配置,再到分布式加速器组,最后实现晶圆级集成。每种方法在计算密度、通信开销和系统复杂性之间存在独特权衡。例如,芯片组架构在封装内维持高速互连,而分布式系统则牺牲通信延迟以获得大规模并行。
理解这些扩展策略至关重要。首先,它揭示了不同硬件架构如何应对 AI 工作负载日益增长的计算需求。其次,它揭示了超越单芯片执行时出现的基本挑战,例如管理芯片间通信和协调分布式计算。最后,它为后续讨论如何映射策略、编译技术和运行时系统演变以支持高效大规模执行奠定基础。
这一进程始于芯片组架构,芯片组架构是多芯片扩展中最紧密集成的形式。
基于芯片组的架构
芯片组架构通过将大型设计划分为多个较小的模块化芯片,在单一封装内实现扩展,如图 9 所示。
现代 AI 加速器,如 AMD 的 Instinct MI300,通过集成多个计算芯片和内存芯片,并通过高速芯片间互连链接,实现了这一点。这种模块化设计使制造商能够绕过单片芯片的制造限制,同时仍实现高密度计算。
然而,即使在单一封装内,扩展也并非没有挑战。随着更多芯片的集成,芯片间通信延迟、内存一致性23和热管理成为关键因素。与传统的多芯片系统不同,基于芯片组的设计必须在多个芯片之间平衡延迟敏感的工作负载,而不会引入过多的瓶颈。
多 GPU 系统
超越芯片组设计,AI 工作负载经常需要多个独立的 GPU 协同工作。在多 GPU 系统中,每个加速器都有自己专用的内存和计算资源,但它们必须高效地共享数据和同步执行。
一个常见的例子是 NVIDIA DGX 系统,它集成了通过 NVLink 或 PCIe 连接的多个 GPU。这种架构使工作负载能够在 GPU 之间拆分,通常使用数据并行(每个 GPU 处理不同的数据批次)或模型并行(不同的 GPU 处理神经网络的不同部分)。这些并行化策略在 第 8 章:AI 训练 中有深入探讨。
如图 9 所示,NVSwitch 互连使得 GPU 之间能够进行高速通信,减少分布式训练中的瓶颈。然而,GPU 数量的增加带来了基本的分布式协调挑战,这些挑战成为主导性能的制约因素。以 GPT-3 规模模型为例,其训练过程中,梯度同步需要频繁在 GPU 之间进行,而这会产生巨大的通信开销。尽管 NVSwitch 提供了 600 GB/s 的双向带宽,但当 8 个 H100 GPU 同时交换梯度时,这一带宽就会成为瓶颈,造成 4.8 TB/s 的聚合需求,超出可用带宽。协调的复杂性也呈指数级增长——两个 GPU 只需一个通信通道,而八个 GPU 则需要 28 条互连路径,容错要求还需要冗余通信模式。此外,内存一致性协议进一步增加了协调的复杂性,因为不同 GPU 可能在不同时间观察到权重更新,这需要复杂的同步原语来处理,可能导致每个训练步骤增加 10-50 微秒的延迟,这看似微小的延迟在百万次迭代的训练中会累积成数小时的训练时间。

通信开销与阿姆达尔定律分析
分布式 AI 训练的根本限制在于阿姆达尔定律,该定律量化了通信开销如何限制并行加速,而不管可用的计算能力有多强大。对于分布式神经网络训练而言,梯度同步中的通信开销造成了一个顺序瓶颈,即使有无限的并行能力,速度提升也会受到限制。
分布式训练的最大加速比受阿姆达尔定律限制: $$ \text{Speedup} = \frac{1}{(1-P) + \frac{P}{N}} $$ 其中 $P$ 是可并行化工作的比例,$N$ 是处理器数量。然而,对于 AI 训练而言,通信开销引入了额外的顺序时间: $$ \text{Speedup}_{\text{AI}} = \frac{1}{(1-P) + \frac{P}{N} + \frac{C}{N}} $$ 其中 $C$ 表示通信开销比例。
以 1000 个 H100 GPU 训练 1750 亿参数的模型为例:
- 每次迭代的计算时间:100 毫秒的前向/反向传播
- 通信时间:在 1000 个 GPU 之间进行 1750 亿参数(700 GB,FP32)的 AllReduce 操作
- 可用带宽:每条 NVSwitch 链路 600 GB/s
- 通信开销:$\frac{700\text{GB}}{600\text{GB/s}} \times \log_2(1000) \approx 11.6\text{ms}$
即使只有 5% 的训练需要通信(P = 0.95),最大加速比也为: $$ \text{Speedup} = \frac{1}{0.05 + \frac{0.95}{1000} + \frac{0.116}{100}} \approx 8.3\text{x} $$
这表明,对于大规模模型训练,增加超过 ~100 个 GPU 的收益递减。
通信需求随着模型大小和参数数量的增加而超线性扩展。现代 Transformer 模型在每次训练步骤中都需要跨所有参数进行梯度同步:
- GPT-3(175 亿参数):每步需交换 700 GB 的梯度
- GPT-4(估计 1.8 万亿参数):每步需 ~7 TB 的梯度交换
- 未来 10 万亿参数模型:每步需 ~40 TB 的梯度交换
即使使用先进的互连技术如 NVLink 4.0(1.8 TB/s),对 10 万亿参数模型的梯度同步也需 22 秒以上,且需算法创新如梯度压缩或异步更新才能使分布式训练成为可能。
多 GPU 系统还面临内存带宽竞争的瓶颈。当 8 个 H100 GPU 同时访问 HBM 进行梯度计算时,每个 GPU 的有效内存带宽从 3.35 TB/s 降至约 2.1 TB/s,下降幅度达 37%。这一内存性能下降与通信开销叠加,进一步限制了可扩展性。
理解阿姆达尔定律有助于指导优化策略:
- 梯度压缩:通过稀疏化和量化将通信量减少 10-100 倍
- 流水线并行:通过隐藏梯度同步延迟来重叠通信与计算
- 模型并行:在设备间划分模型以减少梯度同步需求
- 异步更新:放宽一致性要求以消除同步障碍
这些技术通过改变阿姆达尔公式中 $P$ 和 $C$ 的有效值,改善扩展性,但往往以算法复杂性为代价。
TPU Pods
随着模型和数据集的不断扩大,训练和推理工作负载必须超越单服务器配置。这一扩展需求催生了复杂的分布式系统,将多个加速器通过网络连接起来。Google 的 TPU Pods 就是应对这一挑战的开创性尝试,数百个 TPU 互联形成一个统一系统。
TPU Pods 的架构设计与传统多 GPU 系统有根本区别。传统多 GPU 配置通常依赖 NVLink 或 PCIe 连接单机内的多个 GPU,而 TPU Pods 则采用高速光纤链路,在数据中心级别互连加速器。这种设计实现了 2D 环形拓扑,有效减少了随着工作负载在节点间扩展而产生的通信瓶颈。
这种架构在性能扩展能力上表现出色。如图 11 所示,在运行 ResNet-50 时,TPU Pod 的性能在从四分之一 Pod 扩展到完整 Pod 配置时几乎线性提升。在与 16 TPU 基线相比时,扩展到 1024 个芯片时速度提升达到惊人的 33.0 倍。尤其在较大配置中,这种扩展效率尤为显著,从 128 扩展到 1024 个芯片时,性能仍能保持强劲增长。

然而,将 AI 工作负载分布在整个数据中心内会引入与单节点系统截然不同的分布式协调挑战。尽管 2D 环形互连提供了高切带宽,但在训练大规模 Transformer 模型时,跨所有 1024 个 TPU 进行 AllReduce 操作时会出现通信瓶颈。每个参数梯度必须通过环网的多个跳转才能到达目的地,最坏情况下的通信需要 32 次跳转才能在远端 TPU 之间完成,这会造成延迟惩罚,并随着模型规模的扩大而加剧。
分布式内存架构则使协调复杂性加倍——与具有共享主机内存的多 GPU 系统不同,每个 TPU 节点都有独立的内存空间,迫使程序员显式处理数据调度和同步协议。网络分区容忍度在此变得至关重要,因为光纤链路故障可能将 Pod 分割成不相连的部分,需复杂的一致性算法来维持训练一致性。
此外,协调的能耗成本也呈指数级增长:通过 Pod 的光纤互连移动数据的能耗是片上通信的 1000 倍,使得分布式训练变成计算并行与通信效率之间的微妙平衡,整体训练吞吐量由 AllReduce 带宽而非计算能力决定。
晶圆级 AI
在 AI 扩展的最前沿,晶圆级24集成代表了一种范式转变——放弃传统的多芯片架构,转而采用单一、巨大的 AI 处理器。此方法不再将计算划分到离散芯片上,而是将整个硅晶圆视为统一的计算结构,消除芯片间通信的低效。
如图 12 所示,Cerebras 的晶圆级引擎(WSE)处理器打破了 CPU、GPU 和 TPU 的历史性晶体管扩展趋势。这些架构的晶体管数量稳步增加,呈指数级增长,而 WSE 则引入了一种全新的扩展范式,将万亿级晶体管集成到单个晶圆上——远超最先进的 GPU 和 TPU。通过 WSE-3,这一轨迹得以延续,将晶圆级 AI 推向前所未有的高度。
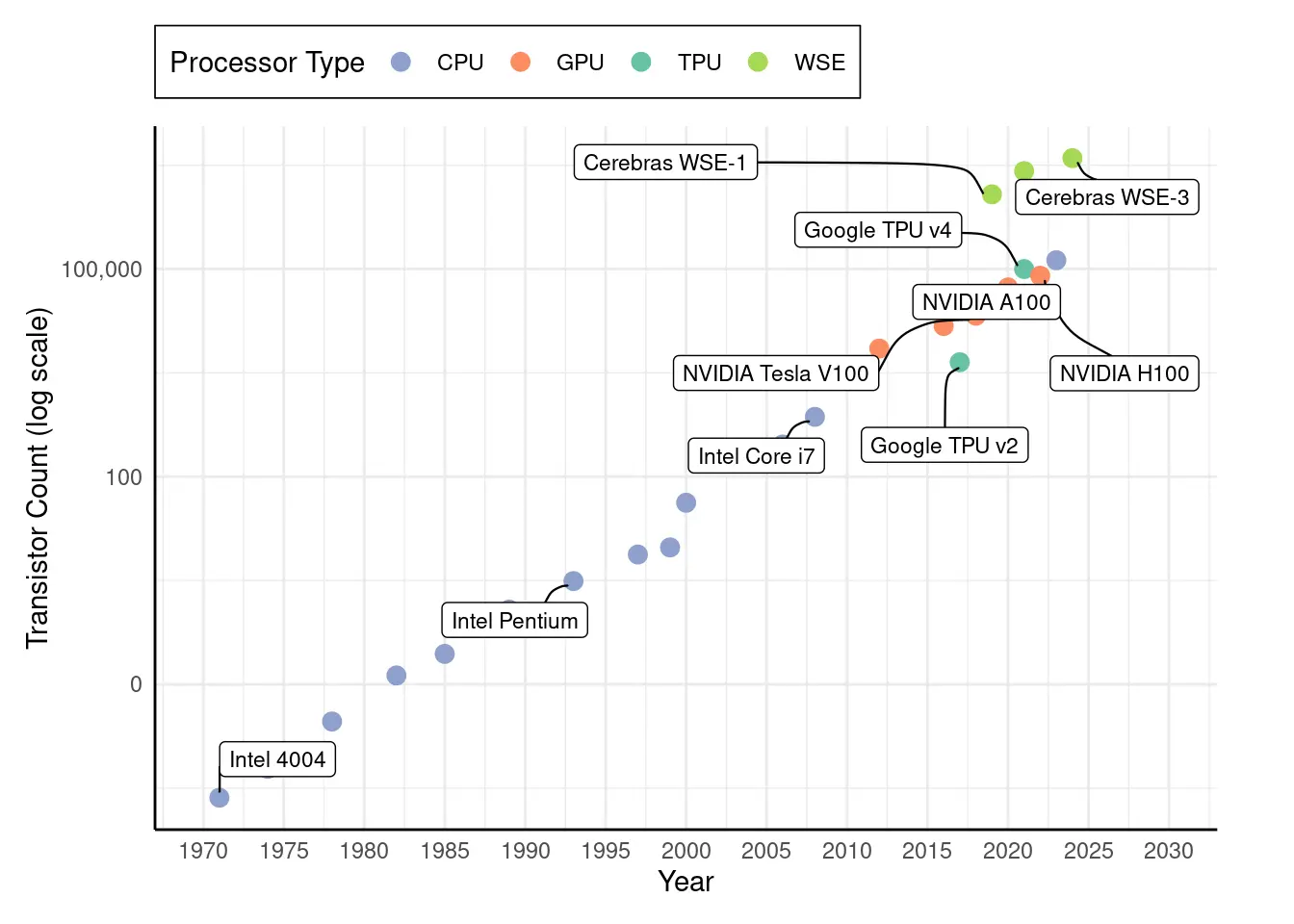
晶圆级 AI 的根本优势在于其超快的芯片内通信。与芯片组、GPU 或 TPU Pods 不同,晶圆级 AI 无需跨设备物理边界传输数据,允许其在庞大的计算阵列中实现近乎瞬时的数据传输。这一架构大幅降低了通信延迟,释放出传统多芯片系统无法企及的性能。
然而,实现这一集成水平需要巨大的工程挑战。热耗散、容错和制造良率成为制造此规模处理器的主要制约因素。这些可持续性挑战,包括能源消耗和资源利用,将在 第 18 章:可持续 AI 中讨论。与动态重路由工作负载以应对故障的 TPU 系统不同,晶圆级 AI 必须内置冗余机制,以容忍硅片内的局部缺陷。成功应对这些挑战对于实现晶圆级计算的全部潜力至关重要,标志着 AI 加速的下一个前沿。
AI 系统扩展轨迹
表 20 概述了 AI 加速的渐进式扩展,从单芯片处理器到日益复杂的架构,如基于芯片组的设计、多 GPU 系统、TPU Pods 和晶圆级 AI。每一步演变都带来了与数据移动、内存访问、互连效率和工作负载分配相关的新挑战。芯片组实现封装内的模块化扩展,但引入延迟和内存一致性问题。多 GPU 系统依赖高速互连如 NVLink,但面临同步和通信瓶颈。TPU Pods 通过跨集群分配工作负载进一步推动可扩展性,但必须应对互连拥塞和工作负载划分问题。最极端的情况是,晶圆级 AI 将整个晶圆集成到单个计算单元中,带来了热管理和容错的独特挑战。
| 扩展方法 | 关键特征 | 挑战 |
|---|---|---|
| 芯片组 | 封装内的模块化扩展 | 芯片间延迟、内存一致性 |
| 多 GPU | 外部 GPU 互连(NVLink) | 同步开销、通信瓶颈 |
| TPU Pods | 分布式加速器集群 | 互连拥塞、工作负载划分 |
| 晶圆级 AI | 整个晶圆作为单个处理器 | 热耗散、容错 |
计算和内存扩展变化
随着 AI 系统从单芯片加速器扩展到多芯片架构,计算和内存中的基本挑战不断演变。在单个加速器中,执行主要针对局部性进行优化——确保计算有效映射到可用处理单元,同时最小化内存访问延迟。然而,随着 AI 系统超越单个芯片,这些优化的范围大幅扩大。计算现在必须分布在多个加速器上,内存访问模式受到互连带宽和通信开销的限制。
多芯片执行映射
在单芯片 AI 加速器中,计算位置仅涉及将工作负载映射到处理单元、向量单元和张量核心,映射策略旨在最大化数据局部性,确保计算访问附近内存,从而减少昂贵的数据移动。
而在多芯片执行中,计算位置必须考虑几个关键因素。工作负载需要在多个加速器之间进行分区,这需要明确协调执行顺序和依赖关系。这一划分至关重要,因为跨芯片通信固有的延迟与单芯片系统中受益于共享片上内存的情况截然不同。因此,计算调度必须考虑互连,以有效管理这些延迟。此外,实现加速器间的负载平衡至关重要;任务分配不均可能导致某些加速器未被充分利用,而其他加速器则满负荷运转,最终妨碍整体系统性能。
例如,在多 GPU 训练中,计算映射必须确保每个 GPU 拥有均衡的工作负载,同时尽量减少昂贵的跨 GPU 通信。同样,在 TPU Pods 中,映射策略必须与环形互连拓扑相一致,确保计算位置能最大限度减少远程数据传输。
因此,单芯片系统中的计算位置优化是局部优化问题,而多芯片架构中的计算位置优化则成为全球优化挑战,执行效率依赖于最小化芯片间通信和任务分配的平衡。
分布式访问内存分配
单芯片 AI 加速器中的内存分配策略旨在通过使用片上缓存、SRAM 和 HBM 来最小化外部内存访问。通过分块、数据重用和内核融合等技术,确保计算高效利用快速本地内存。
而在多芯片 AI 系统中,每个加速器管理自己的本地内存,这就需要在设备间显式分配模型参数、激活值和中间数据。与单芯片执行中数据一次性提取和重用不同,多芯片设置需要有意识地制定策略,以尽量减少冗余数据传输,因为数据必须在加速器之间进行通信。此外,当重叠数据被多个加速器处理时,共享数据的同步可能会引入显著的开销,必须谨慎管理,以确保高效执行。
例如,在多 GPU 深度学习中,跨 GPU 的梯度同步是一项内存密集型操作,必须优化以避免网络拥塞。在晶圆级 AI 中,内存分配还必须考虑容错和冗余机制,以确保有缺陷区域不会影响整体系统性能。
因此,单芯片加速器中的内存分配侧重于本地缓存效率,而多芯片架构中的内存分配则必须在加速器之间进行显式协调,以平衡内存带宽、最小化冗余传输和减少同步开销。
数据移动限制
在单芯片 AI 加速器中,数据移动优化主要集中在最小化片上内存访问延迟。通过权重定常、输入定常和分块等技术,确保常用数据靠近执行单元,减少外部内存流量。
而在多芯片架构中,数据移动不仅是芯片内问题,更是系统范围内的瓶颈。扩展引入了几个关键挑战,其中最重要的是芯片间带宽限制;通信链路如 PCIe、NVLink 和 TPU 互连的速度远低于片上内存访问速度。此外,当加速器共享模型参数或中间计算结果时,随之而来的数据同步开销(包括延迟和争用)可能显著阻碍执行。因此,优化集体通信对于需要频繁数据交换的工作负载至关重要,例如在深度学习训练中,最小化同步梯度时的延迟是实现高效系统性能的关键。
例如,在 TPU Pods 中,脉动式执行模型确保数据以结构化方式移动,减少不必要的芯片外传输。在多 GPU 推理中,异步数据获取和计算与通信重叠等技术有助于减轻芯片间延迟。
因此,单芯片系统中数据移动优化侧重于缓存局部性和分块,而多芯片架构中,主要挑战是减少芯片间通信开销,以实现高效。
编译器和运行时适应
随着 AI 加速超越单芯片,编译器和运行时必须适应在多个加速器之间管理计算位置、内存组织和执行调度。尽管 AI 加速的基本原理保持不变,但其实现需要针对分布式执行的新策略。
扩展 AI 执行时,计算位置是主要挑战。在单芯片加速器中,工作负载映射到处理单元、向量单元和张量核心,强调最小化片上数据移动和最大化并行执行。然而,在多芯片系统中,计算必须分层划分,工作负载不仅在核心间分配,还要在多个加速器间分配。编译器通过实现互连感知调度来处理此问题,优化工作负载位置以最小化昂贵的芯片间通信。
内存管理在扩展时也发生变化,随着规模的扩大,内存管理必须在多个加速器间进行明确协调。在单芯片系统中,局部缓存、HBM 重用和高效分块策略确保常用数据靠近计算单元。然而,在多芯片系统中,每个加速器都有独立的内存,需显式进行内存分区和协调。编译器优化分布式执行的内存布局,运行时则引入数据预取和缓存机制,以减少芯片间内存访问开销。
超越计算和内存,数据移动在规模扩展中成为主要瓶颈。在单芯片加速器中,数据高效缓存和最小化 DRAM 访问确保数据重复利用。然而,在多芯片系统中,通信感知执行变得至关重要,要求编译器生成重叠计算与数据传输的执行计划。运行时处理芯片间同步,确保工作负载在等待远程加速器数据时不会停滞。
最后,调度需扩展至全局协调。在单芯片 AI 执行中,调度主要关注并行性和最大化计算占用率。然而,在多芯片系统中,调度必须平衡加速器间的工作负载分配,同时考虑互连带宽和同步延迟。运行时通过实现自适应调度策略来管理这种复杂性,动态调整执行计划以适应系统状态和网络拥塞。
表 21 总结了这些关键适应,强调编译器和运行时如何扩展能力,以高效支持多芯片 AI 执行。
因此,尽管 AI 加速的基本原理保持不变,但编译器和运行时必须扩展功能,以便在分布式系统中高效运行。下一节将探讨映射策略如何演变,以进一步优化多芯片 AI 执行。
| 方面 | 单芯片 AI 加速器 | 多芯片 AI 系统及编译器/运行时适应方式 |
|---|---|---|
| 计算位置 | 处理单元、张量核心、向量单元本地映射 | 分层映射、互连感知调度 |
| 内存管理 | 缓存、HBM 重用、本地分块 | 分布式分配、预取、缓存 |
| 数据移动 | 片上重用、最小化 DRAM 访问 | 通信感知执行、重叠传输 |
| 执行调度 | 并行性、计算占用最大化 | 全局调度、互连感知平衡 |
执行模型适应
随着 AI 加速器规模超越单芯片,执行模型必须演变以应对分布式计算、内存分区和芯片间通信带来的复杂性。在单芯片加速器中,执行针对本地处理单元进行优化,调度策略平衡并行性、局部性和数据重用。然而,在多芯片 AI 系统中,执行必须在多个加速器间协调,引入新的工作负载调度、内存一致性和互连感知执行挑战。
本节探讨 AI 加速规模扩展带来的执行模型变化,重点关注多芯片系统中的调度、内存协调和运行时管理。
跨加速器调度
在单芯片 AI 加速器中,执行调度主要旨在优化处理器内部的并行性。这涉及通过增强数据局部性和资源利用率的技术,确保工作负载有效映射到张量核心、向量单元和特殊功能单元。例如,静态调度使用预先确定的执行顺序,经过优化以提高局部性和重用,而动态调度则实时适应工作负载需求的变化。此外,流水线执行将计算分为多个阶段,通过保持操作的连续流动,最大化硬件利用率。
而在多芯片架构中,调度必须解决跨芯片依赖带来的额外挑战。此类系统中的工作负载分配涉及将任务分布到各个加速器,确保每个加速器获得最佳工作量,同时最小化因过度通信而产生的开销。互连感知调度对于协调执行时序与芯片间带宽限制至关重要,从而防止性能停滞。隐藏延迟技术同样关键,它们使计算与通信重叠,减少等待时间。
例如,在多 GPU 推理场景中,执行调度允许数据在计算时并行预取,从而减轻内存阻塞。同样,TPU Pods 利用脉动阵列模型,将执行调度与数据流紧密结合,确保每个 TPU 核心在需要时能及时获得数据。因此,单芯片执行调度主要关注内部并行性最大化,而多芯片系统则需要一种更全面的方法,明确管理通信开销并协调加速器间的工作负载分配。
跨加速器协调
在单芯片 AI 加速器中,内存协调通过复杂的本地缓存策略来管理,确保常用数据靠近执行单元。采用分块、内核融合和数据重用等技术,减少对较慢内存层级的依赖,从而提高性能和降低延迟。
而在多芯片架构中,分布式内存协调挑战需要更为精细的管理。每个加速器都有独立的内存,必须通过显式的内存分区来组织,以尽量减少跨芯片数据访问。此外,确保共享数据的一致性和同步也是维持计算正确性的关键。高效的通信机制必须实施,以在限制同步延迟开销的同时调度数据传输。
例如,在分布式深度学习训练中,跨多个 GPU 的模型参数同步采用 all-reduce 方法,聚合梯度时减少通信延迟。在晶圆级 AI 中,内存协调还必须考虑容错和冗余机制,确保有缺陷区域不会影响整体系统性能。因此,单芯片系统中的内存协调主要关注缓存优化,而多芯片架构则需管理分布式内存访问、同步和通信,以实现高效执行。
跨加速器执行管理
单芯片 AI 加速器中的执行由 AI 运行时管理,处理工作负载调度、内存分配和硬件执行。这些运行时在内核级别优化执行,确保计算在可用资源内高效执行。
而在多芯片 AI 系统中,运行时必须纳入分布式执行的策略。确保计算和内存访问在多个加速器间无缝协调,充分利用硬件资源,最小化数据传输瓶颈。
这些系统需要强大的跨芯片工作负载同步机制。依赖关系的精确管理和加速器间的及时协调对于防止因芯片间通信延迟而导致的执行停滞至关重要。这种同步对于维持计算流畅性尤为关键,尤其是在延迟可能显著影响整体性能的环境中。
最后,自适应执行模型在当代多芯片架构中发挥着关键作用。这些模型根据当前硬件可用性和通信约束动态调整执行计划,确保系统能够实时响应变化条件,优化性能。综合这些策略,为管理分布式 AI 执行的复杂性提供了一个强大的框架。
例如,在 Google TPU Pods 中,TPU 运行时负责跨多个 TPU 核心调度计算,确保工作负载以最小通信瓶颈的方式执行。在多 GPU 框架(如 PyTorch 和 TensorFlow)中,运行时执行必须在 GPU 之间同步操作,确保数据高效传输的同时保持执行顺序。
因此,单芯片运行时专注于优化单一处理器内的执行,而多芯片运行时则必须处理系统范围的执行,平衡计算、内存和互连性能。
计算位置适应
随着 AI 系统超越单芯片执行,计算位置必须适应以考虑跨加速器的工作负载分配和互连效率。在单芯片加速器中,编译器通过将工作负载映射到张量核心、向量单元和处理单元来优化位置,确保最大化并行性同时最小化片上数据移动。然而,在多芯片系统中,位置策略必须解决芯片间带宽限制、同步延迟和跨多个加速器的分层工作负载划分。
下表(表 22)突出显示了这些适应。为减少昂贵的跨芯片通信,编译器现在实施互连感知的工作负载分区策略,根据通信成本战略性地分配计算。例如,在多 GPU 训练中,编译器优化位置以最小化 NVLink 或 PCIe 流量,而 TPU Pods 则利用环形互连拓扑来增强数据交换。
| 方面 | 单芯片 AI 加速器 | 多芯片 AI 系统及编译器/运行时适应方式 |
|---|---|---|
| 计算位置 | 处理单元、张量核心、向量单元本地映射 | 分层映射、互连感知调度 |
| 工作负载分配 | 优化于单一芯片内 | 跨加速器分区,最小化芯片间通信 |
| 同步 | 在本地执行单元内管理 | 运行时动态平衡工作负载,调整执行计划 |
运行时通过动态管理执行任务,实时调整任务分配,平衡多加速器间的负载。与假定硬件拓扑固定的静态编译不同,AI 运行时会持续监控系统状态,按需迁移任务,防止瓶颈。这保证了即使在负载波动或硬件资源变化的环境下,也能高效执行。
因此,大规模计算分配是在本地执行优化的基础上,进一步引入了芯片间协调、通信感知执行和动态负载均衡等新挑战——这些挑战也要求存储层次结构适应多芯片架构下的高效执行。
多芯片 AI 系统的复杂性应对
AI 硬件从单芯片加速器发展到多芯片系统乃至晶圆级集成,凸显了高效执行大规模机器学习任务的复杂性不断提升。AI 系统扩展带来了计算分配、内存管理和数据流动的新挑战。虽然加速的基本原则不变,但具体实现必须适应分布式执行、互连带宽限制和同步开销等约束。
多芯片 AI 架构是应对现代机器学习模型算力需求的重要进步。通过将任务分布到多个加速器,这类系统提升了性能、内存容量和可扩展性。但要真正发挥这些优势,必须精细考虑计算如何映射到硬件、内存如何分区与访问,以及分布式系统下如何调度执行。
本文仅概述了多芯片 AI 加速的核心概念与挑战,实际还有更多值得深入探讨。随着 AI 模型规模和复杂度持续增长,新的架构创新、映射策略和运行时优化将不断涌现以支撑高效执行。这些新趋势和未来方向正在快速演进。AI 硬件与软件的持续发展也反映了计算领域的更广泛趋势——专业化和领域专用架构正成为应对新兴负载独特需求的关键。
理解多芯片 AI 加速的原理与权衡,有助于机器学习工程师和系统设计者做出更优的模型部署与优化决策。无论是在 TPU Pod 上训练大语言模型,还是在多 GPU 系统上部署计算机视觉应用,能否高效地将计算映射到硬件,将始终是释放 AI 最大潜力的关键。
异构 SoC AI 加速
前文讨论的多芯片架构主要聚焦于数据中心场景下的算力极限,通常功耗预算高达数千瓦,冷却系统支持机架级部署。然而,硬件加速的基本原则——专用计算单元、存储层次优化和任务映射策略——在移动和边缘环境下必须彻底适应。智能手机仅有 2-5 瓦功耗预算,自动驾驶要求确定性实时响应,物联网传感器需数年电池续航。这些约束催生了异构系统级芯片(SoC)架构,在单芯片内协调多种专用处理器,同时满足与数据中心截然不同的功耗、热管理和延迟要求。
移动 AI 的兴起彻底改变了我们对 AI 加速的认知,从同质化的数据中心架构转向异构 SoC 设计,协调多种专用处理器。现代智能手机、汽车系统和物联网设备集成了 CPU 核心、GPU 着色器、数字信号处理器(DSP)和专用神经处理单元(NPU),需要复杂的调度与协作,在严格的功耗和热约束下实现最优性能。
移动 SoC 架构演进
高通 Snapdragon AI 引擎是移动 AI 异构计算的典范,协调 Kryo CPU、Adreno GPU、Hexagon DSP 和专用 NPU25,共享统一内存层次。Snapdragon 8 Gen 3 通过智能任务分配实现 73 TOPS 性能——计算机视觉内核在 GPU 并行着色器上运行,音频处理用 DSP 专用算术单元,Transformer 注意力机制则由 NPU 优化矩阵引擎加速。此类协作需毫秒级调度,既满足实时约束,又兼顾热管理和续航优化。
高通强调多处理器专用化,Apple 则通过软硬件深度协同实现更复杂的异构执行。M2 芯片的 16 核神经引擎(15.8 TOPS)与 10 核 GPU、8 核 CPU 通过统一内存架构协作,消除数据复制开销。神经引擎专用矩阵乘法单元处理 Transformer 层,GPU 的 Metal Performance Shaders 加速卷积,CPU 负责控制流和动态层选择。如此细粒度协作,实现了实时语言翻译和端侧图像生成,响应时间可控在毫秒级。
除高通和 Apple 的垂直集成方案外,ARM 的 IP 授权模式为 SoC 设计者提供了定制处理器组合的灵活路径。Mali-G78 GPU 可与 Ethos-N78 NPU 配合,实现通用与 AI 加速的平衡;Cortex-M55 微控制器集成 Ethos-U55 微型 NPU,适用于超低功耗边缘应用。模块化灵活性让汽车 SoC 可优先确定性实时处理,智能手机 SoC 则优化交互性能与电池效率。
动态任务分配策略
异构 SoC 拥有多种专用处理器,关键挑战在于如何智能分配神经网络操作,最大化性能,同时兼顾功耗和延迟约束。
现代神经网络需根据操作特性和系统状态智能划分到异构处理器。卷积层数据访问规律,适合 GPU 着色器并行执行;全连接层稀疏性高,可能在大缓存的通用 CPU 上更高效。Transformer 的注意力机制在序列较长时适合 NPU 矩阵引擎,序列较短时则因 NPU 启动开销,CPU 执行更优。
异构 SoC 不仅静态映射操作到处理器,还需根据多重约束动态选择:
- 功耗预算:电池模式下,系统可将计算分配到低功耗 DSP,而非高性能 GPU
- 热状态:接近热阈值时,任务从高功耗 NPU 迁移到更高效的 CPU
- 延迟需求:汽车安全关键应用优先确定性 CPU 执行,而非可能更快但延迟波动的 NPU
- 并发负载干扰:多 AI 应用需在处理器间负载均衡,保障服务质量
共享内存架构下,多处理器同时访问 LPDDR,需复杂仲裁。Snapdragon 8 Gen 3 的内存控制器实现优先级调度,摄像头处理优先于后台 AI,确保实时视频处理,后台神经网络则根据可用带宽自适应调整执行模式。大模型推理等内存密集型任务,参数流式加载需跨处理器精细协调。
功耗与热管理
移动 AI 需在严格功耗和热约束下保持高性能,异构处理器间需复杂协作。
异构 SoC 通过多处理器协同 DVFS(动态电压频率调整)优化功耗 - 性能曲线。某处理器为满足延迟需求提升频率,系统可降低其他处理器电压以维持总功耗。AI 负载下计算阶段可能快速切换处理器,系统需预测负载变化,提前调整工作点,避免频率/电压震荡导致效率下降。
DVFS 无法单独维持功耗时,移动 SoC 通过智能任务迁移实现热降频,而非简单降低频率。NPU 在神经网络高负载下接近热极限时,运行时可将部分层迁移到 GPU 或 CPU,保持吞吐。此策略在热事件期间维持性能,但需复杂的负载特征分析,预测不同处理器的执行时间和功耗。
除实时功耗与热管理外,移动 AI 系统还需根据电池状态和充电情况调整计算策略。低电量时,系统可切换到高效近似模型,将任务从高功耗 NPU 迁移到节能 DSP,或降低推理频率以保持响应。充电时则可启用高性能模型,提升处理频率,增强用户体验。
汽车异构 AI 系统
汽车应用结合了移动端的能效需求与严格的实时和功能安全要求,需完全不同的架构设计。
汽车 SoC 必须保障安全关键功能的确定性推理延迟,同时支持高级驾驶辅助系统(ADAS)。Snapdragon Ride 平台在安全域内协调多 AI 加速器——冗余处理单元保障功能安全,高性能加速器负责感知、规划和控制。架构需实现安全与便利功能的时间隔离,通过硬件分区和定时调度实现。
安全需求更复杂,现代汽车集成多 AI SoC,分别处理视觉、雷达和中央决策。分布式系统需在微秒级精度下保持多传感器时序一致,需专用 SoC 间通信协议和分布式同步机制。
车载传感器之外,车联网(V2X)进一步提升异构处理复杂度,AI 算法需协调本地传感器与外部车辆/基础设施信息。5G 模块、AI 加速器和控制系统需在毫秒级时限内协同处理,同时保障功能安全。
软件栈挑战
异构 SoC 架构复杂,带来编程模型、内存管理和运行时优化等多方面的软件开发挑战。
编程异构 SoC 需框架抽象处理器差异,同时暴露性能关键优化机会。OpenCL、Vulkan 支持跨处理器执行,但要实现最优性能仍需针对处理器定制优化,增加了可移植开发的复杂度。现代 ML 框架如 TensorFlow Lite、PyTorch Mobile 实现自动处理器选择,但开发者仍需理解异构执行模式才能获得最佳效果。
异构 SoC 的共享内存架构进一步加剧编程难度,需复杂内存管理,兼顾处理器缓存行为、访问模式和一致性要求。CPU 缓存可能干扰 GPU 内存访问,NPU 的 DMA 操作需与 CPU 缓存同步,保障数据一致性。
为应对手动优化的复杂性,先进异构 SoC 实现了基于机器学习的运行时优化,通过学习执行模式提升处理器选择、热管理和功耗优化。这些系统收集负载特征、处理器利用率和功耗数据,建立模型预测新负载的最优执行策略。
异构 AI 加速代表了计算的未来,没有单一处理器架构能高效覆盖现代 AI 应用的多样计算模式。理解这些协同挑战,是开发高效移动 AI 系统的基础,确保在边缘部署场景下兼顾高性能、低功耗、热管理和实时性。
但异构系统的复杂性也带来了误解和低效设计的风险。以下常见误区和陷阱,提醒大家在加速器选型和部署时需谨慎权衡。
常见误区与陷阱
硬件加速涉及专用架构、软件栈和负载特性的复杂交互,极易因误解而导致低效部署。AI 加速器的高性能数据常掩盖了实际应用中的约束和权衡,影响不同场景下的真实效果。
误区: 更专用的硬件总能比通用方案性能更好。
这一观点假定专用加速器在所有 AI 负载下都能自动优于通用处理器。实际上,只有当负载与架构假设和优化目标高度匹配时,专用硬件才能发挥极致性能。对于内存访问不规律、小批量或动态计算图的模型,灵活的通用处理器反而可能优于为密集、规则计算设计的专用加速器。数据搬运、格式转换和同步的开销可能抵消专用计算的优势。硬件选型需根据负载特性匹配架构优势,而非盲目追求专用化。
陷阱: 选型时忽略内存带宽限制。
许多实践者只关注算力指标,忽略了常常主导实际性能的内存带宽瓶颈。AI 加速器算力再强,若内存带宽不足,硬件利用率会极低。计算强度与内存访问需求的比例决定了加速器能否发挥理论性能。忽视这一点会导致高价硬件部署却无法实现预期性能,因为负载受限于内存而非算力。
误区: 增加加速器数量,性能线性提升。
这一误解让团队期望通过增加加速器获得成比例的性能提升。多加速器系统引入通信开销、同步成本和负载均衡挑战,扩展效率常被严重限制。小模型并行度不足,无法充分利用多加速器;大模型则受限于设备间通信带宽。分布式训练和推理还面临梯度聚合、模型分区和协调开销,扩展关系远非线性。
陷阱: 只做厂商专用优化,忽略长期可移植性和灵活性。
许多组织为追求极致性能,深度绑定特定硬件厂商,忽略了系统灵活性和未来迁移的影响。深度集成厂商专用库、自定义内核和专有优化工具会造成锁定,升级硬件、切换厂商或多厂商部署时极为困难。虽然专用优化能带来显著性能提升,但需兼顾系统可移植性和适应未来硬件变化的能力。保持一定的硬件抽象层,既能保留战略灵活性,又能获得大部分性能收益。
总结
硬件加速已成为推动机器学习从学术探索到实际应用的关键力量,彻底重塑了计算系统和算法设计。通用处理器到专用 AI 加速器的演进,不只是渐进提升,更是向领域专用计算范式的根本转变,软硬件协同优化特定计算模式。CPU、GPU、TPU、NPU 乃至晶圆级系统的发展历程,说明理解负载特性如何驱动架构创新,通过针对性专用化实现数量级性能提升。
AI 加速的技术挑战贯穿计算栈各层,从底层存储层次优化到高层编译器变换和运行时编排。内存带宽限制是根本瓶颈,需用分块、算子融合和层次化调度等复杂技术突破。将神经网络计算映射到硬件,涉及不同数据流模式、内存分配策略和执行调度方法的复杂权衡,需在计算效率与资源利用间取得平衡。
在这些基础概念之上,多芯片和分布式加速系统的出现又带来了通信开销、内存一致性和任务划分等新复杂性,需系统级优化。
核心要点
- 专用 AI 加速器通过针对张量操作和数据流模式优化的领域专用架构实现性能提升
- 存储层次管理常是 AI 加速的主瓶颈,需复杂的数据搬运优化策略
- 软硬件协同设计通过算法特性与架构能力的深度匹配,实现数量级性能提升
- 多芯片扩展带来分布式计算挑战,需新的通信、同步和资源管理方法
本文确立的硬件加速原理,为理解基准测试方法如何评估加速器性能,以及部署策略如何兼顾硬件约束和能力奠定了基础。随着 AI 模型持续扩展,能否高效利用专用硬件将成为实际系统部署的关键,影响能效、成本优化、实时推理和大规模训练的可行性。
测验:AI 硬件加速
测试你对机器学习硬件加速原理与实践的理解
GFLOPS(十亿次浮点运算每秒):衡量计算吞吐量的指标,1 GFLOPS 代表每秒 10 亿次浮点运算。TOPS(万亿次运算每秒)常用于 AI 加速器的整数运算能力。 ↩︎ ↩︎
TPU 起源:Google 于 2013 年秘密研发 TPU,因 CPU 无法满足神经网络的计算需求。TPUv1 于 2015 年投入使用,推理能效比同期 GPU 高 15-30$\times$,彻底改变了业界对 AI 硬件的认知,证明了领域专用架构在神经网络任务上的巨大优势。 ↩︎
Intel 8087 影响:8087 协处理器售价高达数百美元(约合今日 2,100-2,400 美元),但彻底改变了科学计算。CAD 工作站的复杂计算由数小时缩短至数分钟,催生了协处理器市场,并确立了“为特定领域性能溢价”的经济模式。 ↩︎
协处理器:为主 CPU 设计的专用处理器,专攻其不擅长的任务。8087 是首个成功案例,随后有图形协处理器(GPU)、网络处理器。现代“加速器”本质上是进化版协处理器,随着其在目标负载上超越 CPU,术语也随之演变。AI 加速器正沿袭这一路径。 ↩︎
AlexNet GPU 革命:AlexNet 的突破不仅在算法,更在于 GPU 训练速度比 CPU 快 10 倍。团队将 8 层网络分布在两块 NVIDIA GTX 580(各 512 核),训练时间由数周缩短至数天。此举引发“深度学习淘金热”,NVIDIA 数据中心 GPU 销售由 2 亿美元飙升至 2024 年的 470 亿美元。现代 GPU(如 H100)已集成 16,896 个流处理器,展现了自 AlexNet 以来并行能力的巨大跃升。 ↩︎
领域专用架构(DSA):为特定应用领域优化的计算架构。与追求灵活性的 CPU 不同,DSA 牺牲可编程性换取极致效率。Google TPU 在神经网络任务上能效比 GPU 高 15-30$\times$,视频编解码器则比软件解码快 100-1000$\times$。2018 年图灵奖正是对这一趋势的肯定。 ↩︎
摩尔定律:Intel 联合创始人 Gordon Moore 1965 年提出,晶体管密度每 18-24 个月翻倍。50 年来推动了从智能手机到超级计算机的进步。但 2005 年后物理极限导致增速放缓,3nm 芯片开发成本高达 200 亿美元(1999 年仅 300 万),产业被迫转向专用架构。 ↩︎
Dennard 缩放:1974 年 Robert Dennard 提出,随着晶体管缩小,功率密度保持不变,可提升频率而不增功耗。2005 年前 CPU 频率可达 3+ GHz。量子效应与漏电流终结了 Dennard 缩放,体系结构转向效率优先,多核成为主流。 ↩︎
专用集成电路(ASIC):为单一应用定制的芯片,通过剔除无用功能实现极致效率。比特币挖矿 ASIC 比 CPU 能效高 10 万倍,但灵活性极差,算法一变即淘汰。2022 年以太坊转 PoS,50 亿美元 ASIC 报废。 ↩︎
内存带宽:处理器与内存间的数据传输速率,单位 GB/s 或 TB/s。AI 负载常受带宽限制。NVIDIA H100 提供 3.35 TB/s(约为 DDR5-4800 的 40$\times$),因神经网络需持续访问权重,带宽成为主要瓶颈。 ↩︎
缓存层次结构:L1、L2、L3 多级缓存,容量递增、延迟递增。CPU 优化 32-64KB L1 缓存(<1ns),神经网络需 GB 级权重,频繁访问 DRAM(100ns),缓存命中率由 90% 降至 <10%。 ↩︎
异构计算:将不同类型处理器(CPU、GPU、TPU、FPGA)组合优化多样负载。现代数据中心常用 x86 CPU 控制、GPU 训练、TPU 推理。编程需 OpenCL、CUDA 等框架协调多架构执行,可实现 10-100$\times$ 效率提升。 ↩︎
RISC-V 与 AI:RISC-V(2010,伯克利)因可自由定制,正成为 AI 加速器新宠。SiFive、Google 等已推出带 AI 扩展的 RISC-V 芯片。与专有架构不同,RISC-V 允许硬件设计者无授权费添加 ML 指令,有望打破 x86/ARM 垄断。 ↩︎
Cray-1 向量遗产:Cray-1(1975)售价 880 万美元(2024 年约 4,000-4,500 万),每秒 1.6 亿次浮点运算,比同代快 1000 倍。其向量架构成为现代 AI 加速器的蓝本。 ↩︎
Im2col(图像转列):将卷积操作转为矩阵乘法的预处理,将图像块展开为列向量。3×3 卷积在 224×224 图像上生成约 5 万列,便于高效 GEMM,但内存占用提升 9×。现代 ML 加速器的卷积本质上是矩阵运算。 ↩︎
SIMD 演进:SIMD 源自 Flynn 1966 年的科学计算分类,神经网络让其从 HPC 小众概念变为主流。现代 CPU 拥有 512 位 SIMD 单元(AVX-512),AI 推动了 SIMT(单指令多线程)发展,数千线程并行——GPU 架构现可同时调度 65,536+ 线程,传统 SIMD 难以企及。 ↩︎
张量核心突破:NVIDIA 在 V100(2017)引入张量核心,加速神经网络常见的 $4\times 4$ 矩阵操作。A100 第三代张量核心 FP16 算力达 312 TFLOPS,比传统 CUDA 核心快 20$\times$。这一创新让 GPT-3 等模型训练成为可能,彻底改变了 AI 研究规模。 ↩︎
Apple 神经引擎战略:Apple 于 2017 年 9 月 A11 芯片首次集成神经引擎,实现端侧 ML 推理低功耗。M1 的 16 核神经引擎达 11 TOPS,整芯片 TDP 仅 20W,支持实时文本识别、语音处理等,无需云端。该“硬件隐私”理念推动业界重视边缘 AI。 ↩︎
脉动阵列复兴:H.T. Kung 与 Charles Leiserson 1979 年在 CMU 提出脉动阵列用于 VLSI 信号处理,因编程复杂一度沉寂。Google 2016 年 TPU 复活该架构,TPUv1 的 $256\times256$ 脉动阵列 8 位整数算力达 92 TOPS,功耗仅 40W,脉动阵列成为当今主流 AI 架构。 ↩︎
神经网络稀疏性:神经网络中大部分权重或激活为零,可优化计算与存储。自然稀疏如 ReLU 激活零化 50-90% 值,人工稀疏如剪枝可去除 90-99% 权重且精度损失极小。稀疏网络可缩小/加速 10-100$\times$,但需专用硬件(如 NVIDIA A100 的 2:4 稀疏)或软件优化,否则标准硬件对零乘法无效。 ↩︎
直接内存访问(DMA):硬件机制,允许设备在无 CPU 干预下与内存直接交换数据。1981 年 IBM PC 首次引入,DMA 引擎让 CPU 可专注其他任务,数据在系统内存与加速器间自由流动。现代 GPU 拥有多路 DMA 引擎,PCIe 4.0 可达 32 GB/s,NVLink 可达 900 GB/s。异步搬运能力对 AI 负载尤为关键,可与计算重叠,提升系统利用率。 ↩︎
通用矩阵乘法(GEMM):基础操作 C = αAB + βC,支撑大多数神经网络计算。GEMM 占用深度网络训练 90-95% 的计算时间,且是大多数 AI 硬件优化的目标。优化过的 GEMM 库如 cuBLAS(NVIDIA)、oneDNN(Intel)和 CLBlast 通过寄存器分块、向量化和分层分块等技术实现 80-95% 的理论峰值性能。现代 AI 加速器本质上是专门化的 GEMM 引擎,额外支持激活函数和数据搬运。 ↩︎
内存一致性:确保系统中所有处理器在多个核心/芯片访问相同数据时看到相同的一致的共享内存视图。传统的缓存一致性协议如 MESI 为多核 CPU 添加 10-50 纳秒的延迟。对于具有数千个核心的 ML 硬件,大多数采用显式内存管理,程序员手动控制数据放置和同步。 ↩︎
晶圆级集成:将整个 300 毫米硅晶圆作为单个处理器使用,而不是切割成单独的芯片。Cerebras 的 WSE-3 包含 4 万亿个晶体管,拥有 850,000 个核心,是最大 GPU 的 125 倍以上。制造挑战包括 100% 的良率要求(通过冗余核心解决)和冷却 23 千瓦的功率。此方法消除了芯片间的通信延迟,但每片晶圆成本高达 200-300 万美元,而相当于 GPU 集群的成本仅为 4 万美元。 ↩︎
神经处理单元(NPU):专为神经网络推理设计的处理器,区别于通用 GPU。Apple 于 2017 年 A11 芯片首次引入消费级 NPU,单芯片实现 6000 亿次运算/秒,功耗不足 1 瓦。现代 NPU(如 Apple M3 Neural Engine)可达 18 TOPS,支持实时图像处理、语音识别和计算摄影。NPU 擅长低功耗、固定功能 AI 任务,但灵活性不及 GPU,难以支持多样化 ML 研究。 ↩︎