小型语言模型(SLM)
概述
在人工智能快速发展的今天,边缘计算为传统依赖强大中心服务器的能力带来了去中心化的机会。本实验将带你实践如何在树莓派 5 上集成主流大语言模型(LLM)的精简版本,将这一边缘设备变为可实时本地处理数据的 AI 中枢。
随着大语言模型规模和复杂度的提升,小型语言模型(SLM)为边缘设备提供了兼顾性能与资源效率的理想选择。通过在树莓派上本地运行这些模型,我们可以打造响应迅速、保护隐私的应用,即使在网络受限或离线环境下也能正常工作。
本实验将指导你在树莓派上安装、优化并使用 SLM。我们将探索 Ollama 的安装与使用,这一开源框架让我们能在本地(无论是桌面还是树莓派、NVidia Jetson 等边缘设备)运行 LLM。Ollama 设计高效、可扩展且易用,适合部署如 Microsoft Phi、Google Gemma、Meta Llama、LLaVa(多模态)等模型。我们还将结合 Python 生态,将这些模型集成到实际项目中,探索其在真实场景下的潜力(或至少为此指明方向)。

环境准备
此前的实验可用任意树莓派型号,但本实验推荐使用树莓派 5(Raspi-5)。它基于 Broadcom BCM2712,搭载 2.4 GHz 四核 64 位 Arm Cortex-A76 CPU,支持加密扩展和增强缓存,配备 VideoCore VII GPU,支持双 4Kp60 HDMI® 输出和 4Kp60 HEVC 解码。内存有 4GB 和 8GB LPDDR4X SDRAM 可选,运行 SLM 推荐 8GB。存储支持 microSD 卡和 PCIe 2.0 接口,可扩展 M.2 SSD。
实际 SLM 应用中,SSD 比 SD 卡更适合。
正如 Alasdair Allan 所述,在树莓派 5 上仅用 CPU 推理(无 GPU 加速)已可媲美 Coral TPU 的性能。
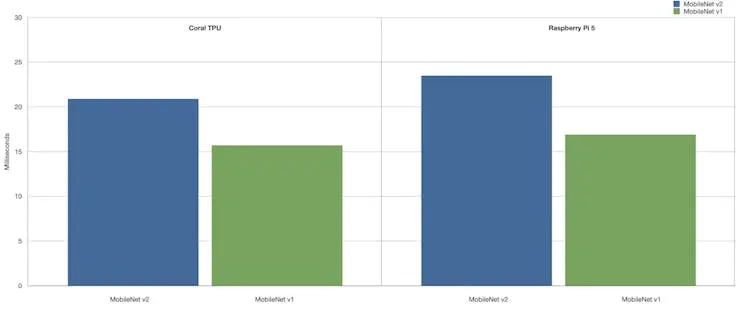
更多信息请参考原文: Benchmarking TensorFlow and TensorFlow Lite on Raspberry Pi 5 。
树莓派主动散热器
建议为树莓派 5 安装主动散热器(Active Cooler),这是一款专为 Raspi-5 设计的夹扣式散热方案,结合铝制散热片和温控风扇,可在运行 SLM 等高负载时保持设备温度。

主动散热器自带导热垫,通过弹簧卡扣直接安装在主板上。树莓派固件会主动调节风扇转速:60°C 启动,67.5°C 加速,75°C 全速,温度降低后自动降速。
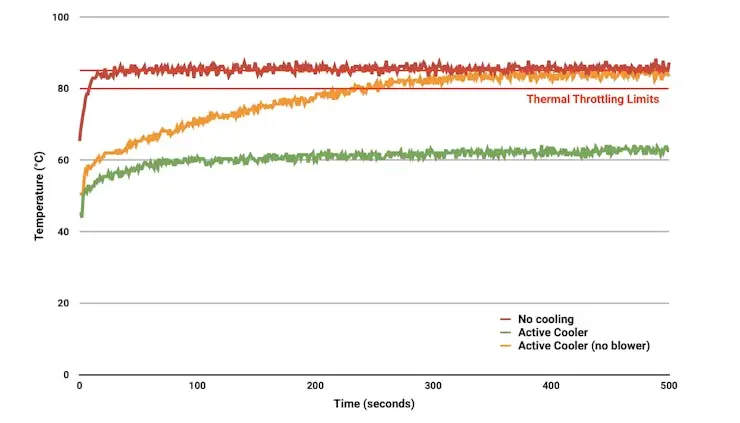
为防止过热,所有树莓派主板在温度达到 80°C 时开始降频,85°C 达到最大降频(详见 官方说明 )。
生成式 AI(GenAI)
生成式 AI 指能够在文本、图像、音频、视频等多种媒介上生成全新内容的人工智能系统。这类系统通过学习已有数据的模式,生成前所未有的新输出。大语言模型(LLM)、小型语言模型(SLM) 和 多模态模型 都可用于生成式任务,属于 GenAI 的范畴。
GenAI 提供了 AI 驱动内容创作的理论基础,LLM 是强大的通用文本生成器,SLM 则将此能力带到边缘计算,多模态模型则扩展到多种数据类型。它们共同推动了 AI 内容创作与理解的进步。
大语言模型(LLM)
大语言模型(LLM)是能够理解、处理并生成类人文本的先进 AI 系统,具有以下特点:
- 规模庞大:通常包含数十亿参数,如 GPT-3 有 1750 亿参数,部分新模型已超万亿。
- 训练数据丰富:训练数据量巨大,涵盖书籍、网站等,规模达数百 GB 甚至 TB。
- 架构先进:多采用 Transformer 架构 ,可并行处理输入。
- 能力广泛:无需专门微调即可完成文本生成、翻译、摘要、问答、代码生成、逻辑推理等多种任务。
- 少样本学习:可通过极少示例理解并完成新任务。
- 资源消耗大:运行需强大 GPU/TPU 支持。
- 持续演进:新模型与技术不断涌现。
- 伦理挑战:涉及偏见、虚假信息、环境影响等问题。
- 应用广泛:内容创作、客服、科研、开发等领域均有应用。
- 局限性:可能输出错误或有偏见的信息,缺乏真正的理解与推理能力。
值得注意的是,除了文本,LLM 还可扩展为多模态模型,即同时处理多种输入类型(如文本、图像、音频、视频)。
闭源与开源模型
闭源模型(专有模型)指内部机制、代码和训练数据未公开的 AI 模型,如 GPT-4(OpenAI)、Claude(Anthropic)、Gemini(Google)。
开源模型则公开底层代码、架构,甚至训练数据,如 Gemma(Google)、LLaMA(Meta)、Phi(Microsoft)。
开源模型更适合在树莓派等边缘设备上运行,便于定制和优化,但需注意许可证要求。开源模型的授权多样,影响商业用途;闭源模型则有明确但更严格的服务条款。
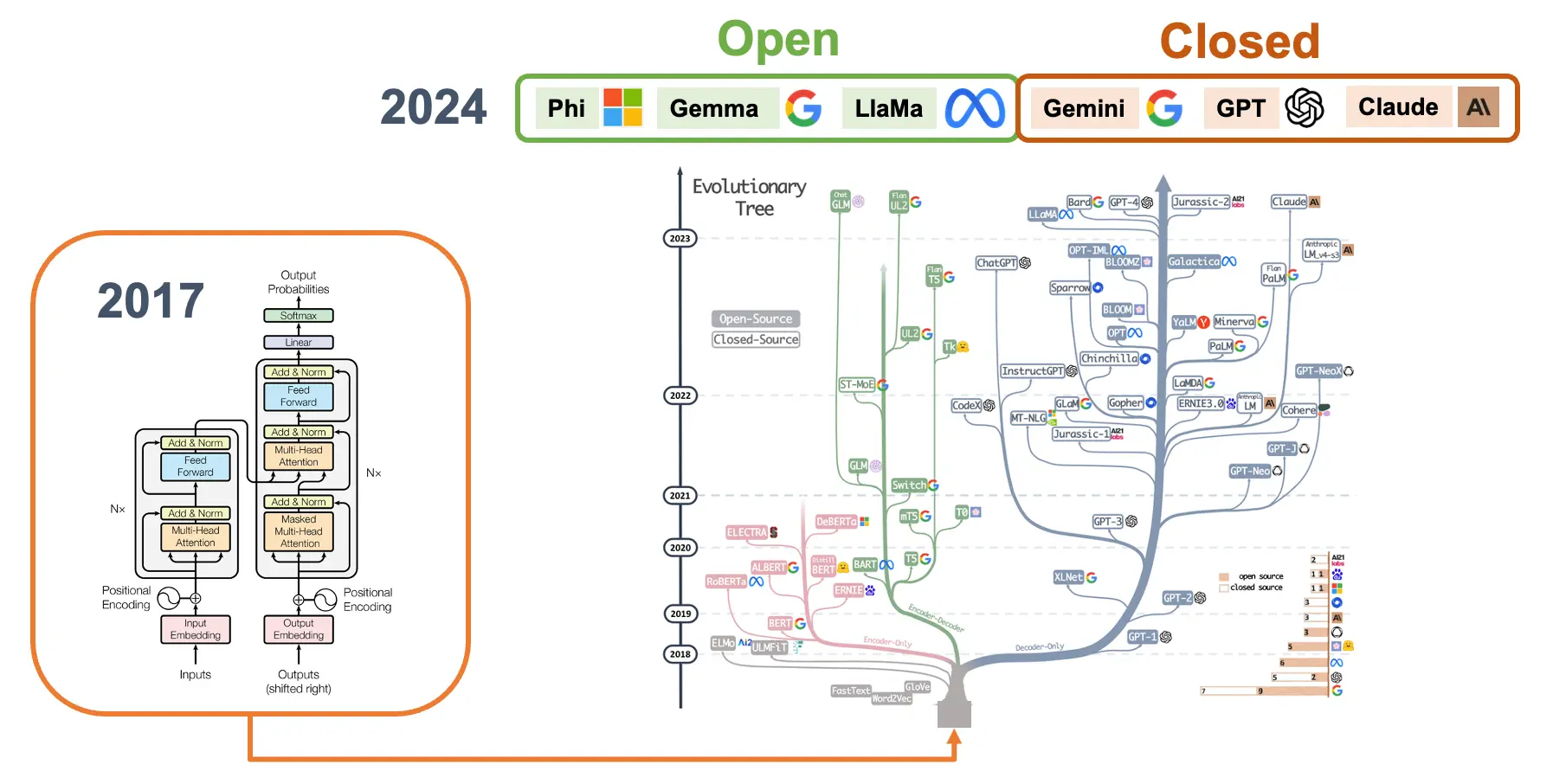
在树莓派等边缘计算场景下,完整的 LLM 通常过于庞大,难以直接运行,这推动了更小巧高效的 SLM 发展。
SLM 是为资源受限设备(如手机、IoT、树莓派)设计的 LLM 精简版,参数量和计算需求大幅降低,但仍具备强大的语言理解与生成能力。
SLM 主要特性:
- 参数量减少:通常为数亿到数十亿参数。
- 内存占用低:仅需几 GB 内存即可运行。
- 推理速度快:边缘设备上响应可达毫秒至秒级。
- 能耗低:适合电池供电设备。
- 隐私保护:本地处理,无需上传云端。
- 离线可用:无网络环境下也能运行。
SLM 通过知识蒸馏、模型剪枝、量化等技术实现小型化。虽然能力不及大型模型,但在特定任务和场景下表现优异,非常适合边缘设备。
本文将 SLM 定义为参数量低于 50 亿、4 位量化的语言模型。
SLM 代表如 Meta Llama、Microsoft PHI、Google Gemma 等模型的压缩版,可在边缘设备上完成文本分类、情感分析、问答、有限文本生成等任务。
更多 SLM 资料可参考论文: LLM Pruning and Distillation in Practice: The Minitron Approach 以及 SMALL LANGUAGE MODELS: SURVEY, MEASUREMENTS, AND INSIGHTS 。
Ollama

Ollama 是一款开源框架,支持在本地运行大/小语言模型。其主要特点:
- 本地模型运行:可在个人电脑或树莓派等边缘设备本地运行,无需云端 API。
- 易用性强:提供简单命令行界面,便于下载、运行和管理模型。
- 模型丰富:支持 Phi、Gemma、Llama、Mistral 等多种开源模型。
- 可定制:支持自定义模型,满足特定需求。
- 轻量高效:适合消费级硬件。
- API 集成:可与其他应用和服务集成。
- 注重隐私:本地运行,数据不出本地。
- 跨平台:支持 macOS、Windows、Linux。
- 持续更新:功能和模型不断丰富。
- 社区驱动:社区贡献活跃,模型共享丰富。
更多 Ollama 原理介绍可参考 Matt Williams 的短视频:
https://www.youtube.com/embed/90ozfdsQOKo
推荐 Matt 的 Ollama 免费课程: https://youtu.be/9KEUFe4KQAI?si=D_-q3CMbHiT-twuy
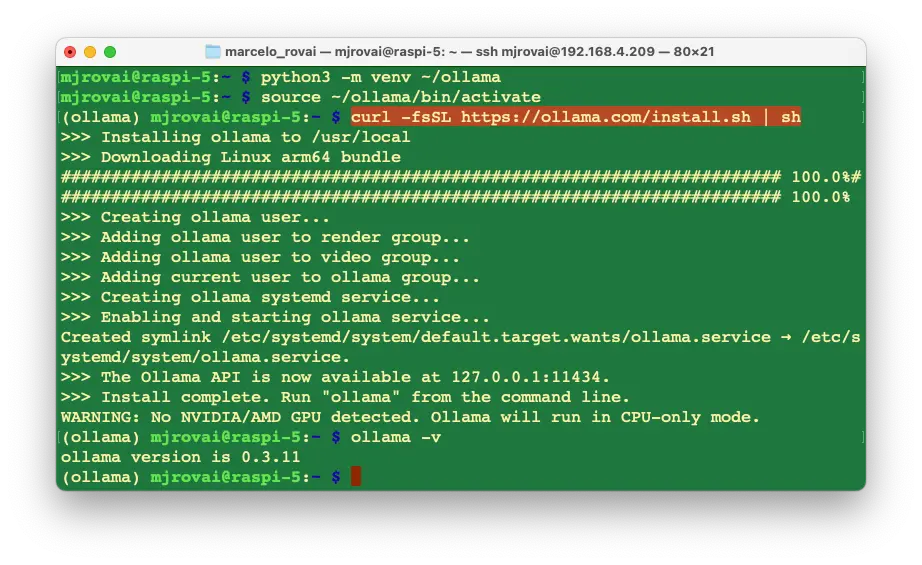
安装 Ollama
首先创建并激活 Python 虚拟环境:
python3 -m venv ~/ollama
source ~/ollama/bin/activate
安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
安装完成后,Ollama API 会在 127.0.0.1:11434 后台运行。可通过终端运行 Ollama。首先验证安装:
ollama -v
在 Ollama Library 可查找支持的模型,如 Meta Llama、Google Gemma、Microsoft Phi、LLaVa 等。
Meta Llama 3.2 1B/3B

安装并运行 Llama 3.2 1B(及 3B)模型。Llama 3.2 系列为多语言生成模型,参数量分别为 10 亿和 30 亿,支持文本输入输出。指令微调版本适合多语言对话、信息检索、摘要等任务,在行业基准测试中表现优异。
1B/3B 模型由 Llama 8B 剪枝而来,并通过 8B/70B 模型的 logits 进行 token 级蒸馏,训练数据达 9 万亿 token。1B 模型为 1.24B 参数(Q8_0 量化),3B 为 3.12B(Q4_0 量化),文件大小分别为 1.3GB 和 2GB,支持 131,072 token 上下文窗口。
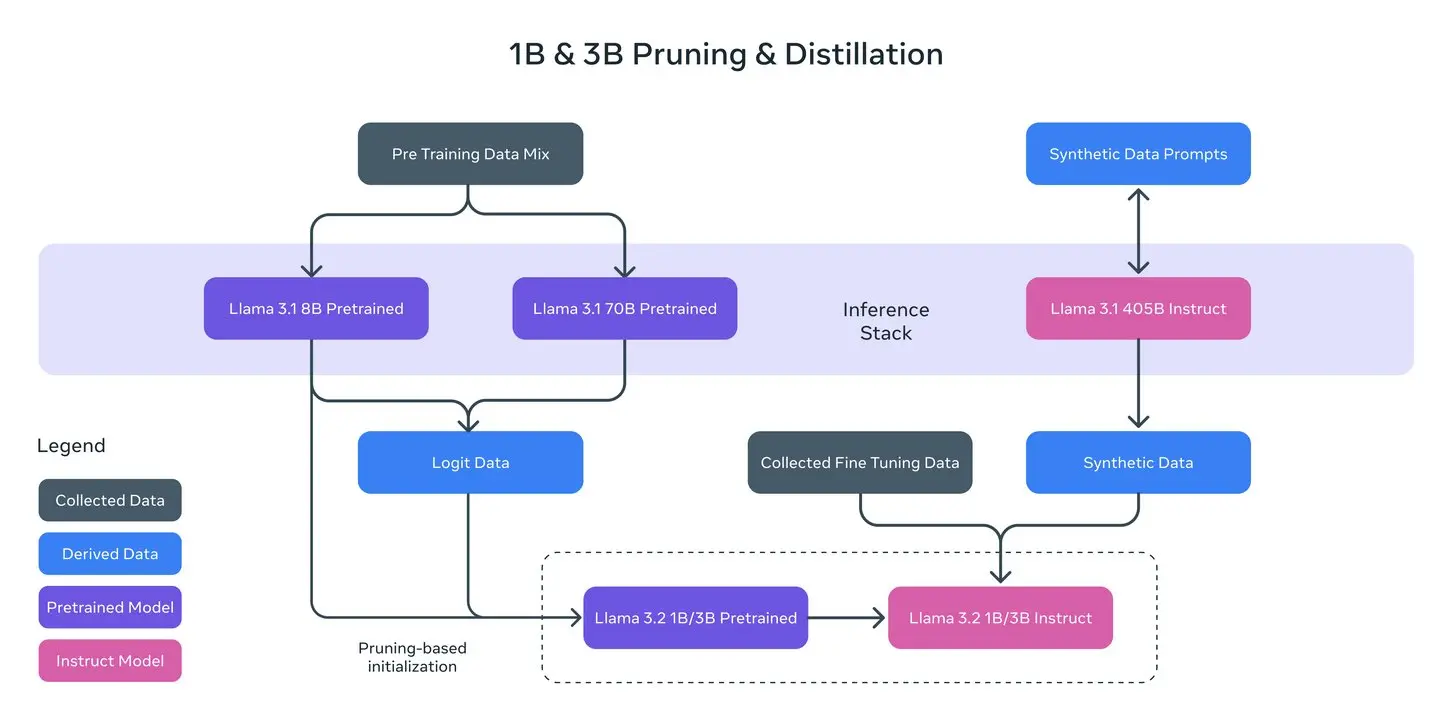
安装并运行模型
ollama run llama3.2:1b
运行后会进入 Ollama 提示符,可直接输入问题:
>>> 法国的首都是哪里?
几乎瞬间返回正确答案:
法国的首都是巴黎。
加上 --verbose 参数可输出性能统计(首次运行会自动下载模型)。
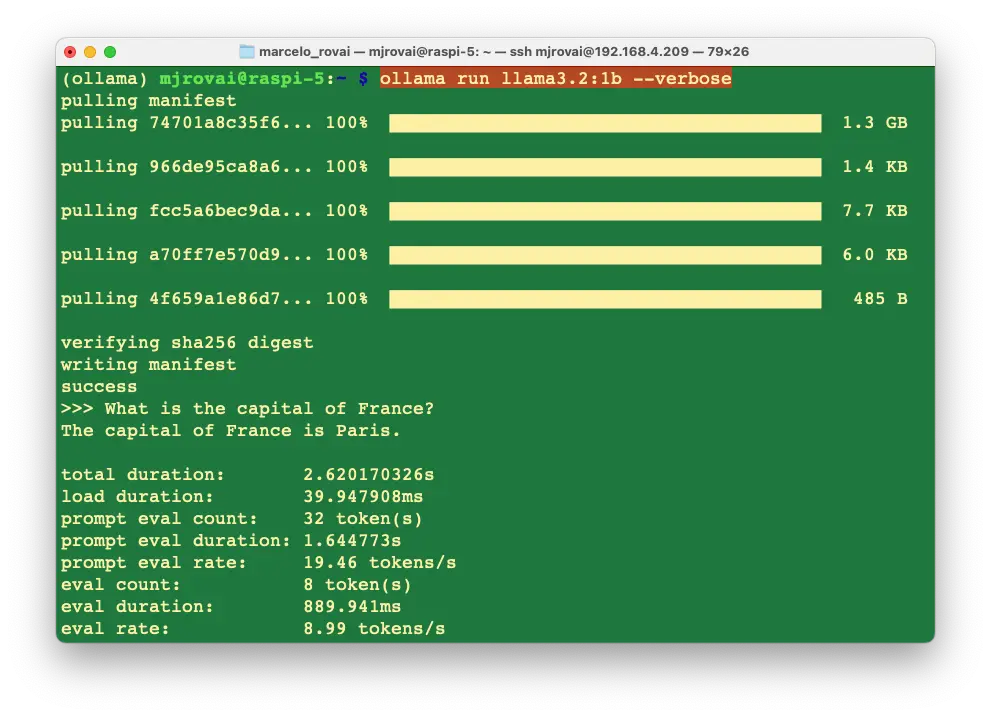
各项指标说明:
- Total Duration:命令执行总时长,包括加载模型、处理输入、生成响应。
- Load Duration:模型加载到内存所需时间。
- Prompt Eval Count:输入提示的 token 数。
- Prompt Eval Duration:处理输入提示所需时间。
- Prompt Eval Rate:输入 token 处理速度。
- Eval Count:模型输出的 token 数。
- Eval Duration:生成输出所需时间。
- Eval Rate:输出 token 生成速度。
这些指标有助于分析 SLM 在树莓派等边缘设备上的性能瓶颈。
加载并运行 3B 模型,可对比同一问题下的性能差异:
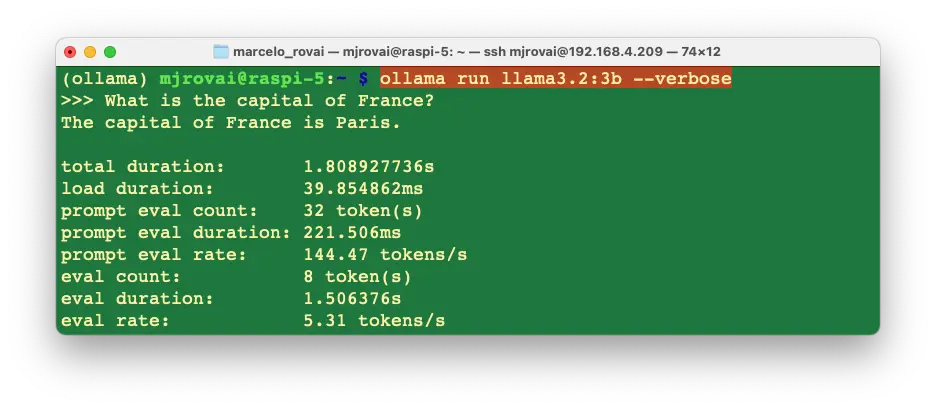
3B 模型 eval rate 更低(5.3 tokens/s),但准确率更高。
例如:
>>> 巴黎和智利圣地亚哥的距离是多少?
1B 模型答 9,841 公里(不准确),3B 模型答 11,700 公里(接近真实值 11,642 公里)。
查询巴黎坐标:
>>> 巴黎的经纬度是多少?
巴黎的纬度和经度分别为 48.8567° N(48°55'42" N)和 2.3510° E(2°22'8" E)。
1B/3B 模型均答对。
Google Gemma 2 2B
安装 Gemma 2 ,高效轻量,分 2B/9B/27B 三种。我们用 Gemma 2 2B ,2.6B 参数,Q4_0 量化,1.6GB,支持 8,192 token 上下文。

安装并运行模型
ollama run gemma2:2b --verbose
输入:
>>> 法国的首都是哪里?
几乎瞬间返回:
法国的首都是 **巴黎**。🗼
性能统计如下:
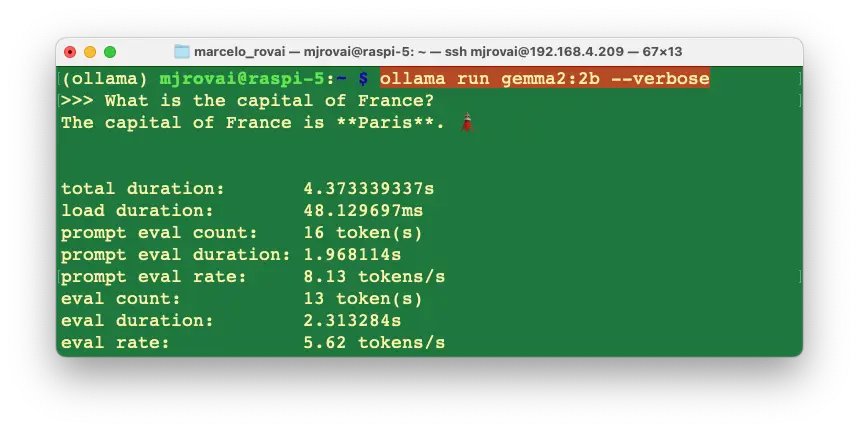
Gemma 2:2B 性能与 Llama 3.2:3B 接近,但参数更少。
其他示例:
>>> 巴黎和智利圣地亚哥的距离是多少?
巴黎和智利圣地亚哥之间的距离约为 **7,000 英里(11,267 公里)**。
准确率略低于 Llama3.2:3B。
>>> 巴黎的经纬度是多少?
巴黎的纬度为 48.8566° N, 经度为 2.3522° E。
答案准确,表达更丰富。
Microsoft Phi3.5 3.8B
拉取更大但仍属小型的 PHI3.5 ,微软开源 3.8B 轻量模型,支持 128K token 上下文,支持多种语言。
模型大小取决于量化格式,4 位量化(Q4_0)需 2.2GB 内存,兼顾质量与性能。
ollama run phi3.5:3.8b --verbose
输入:
>>> 法国的首都是哪里?
法国的首都是巴黎。它在国家历史、文化、政治等方面具有重要地位,是欧洲著名城市,以艺术、时尚、美食和文化闻名。
答案较为冗长,可通过优化 prompt 控制输出。
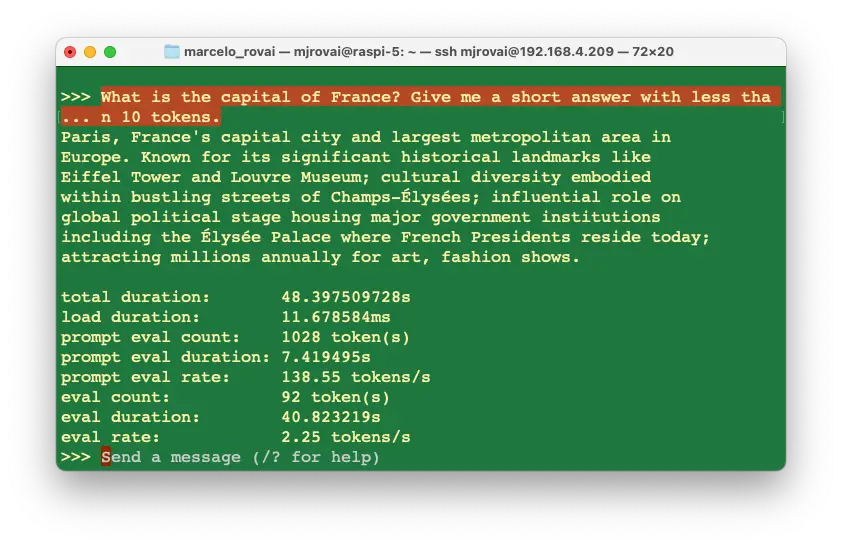
eval rate 为 2.25 tokens/s,低于 Gemma 和 Llama。
同样问题下,距离答案不准确,但坐标答对。Phi 输出较为啰嗦(每次 200+ token)。
选择合适的 prompt 是使用 LLM 的关键技能,无论模型大小。
综合来看,Llama2:3B 性能更优。可根据需求尝试更多模型,参考 🤗 Open LLM Leaderboard 。
最适合的模型取决于具体需求,且模型更新极快。
多模态模型
多模态模型可同时处理文本、图像、音频等多种输入。在本实验中,我们用 LLaVA-Phi-3 ,基于 Phi 3 Mini 4k 微调,性能与原版 LLaVA 相当。
LLaVA-Phi-3 结合视觉编码器和语言模型,支持多模态输入。
安装模型:
ollama run llava-phi3:3.8b --verbose
文本输入示例:
>>> 你是一个乐于助人的 AI 助手。法国的首都是哪里?
法国的首都是巴黎。它不仅是全国最大城市,也是政治和行政中心,以埃菲尔铁塔、巴黎圣母院、卢浮宫等地标著称,被誉为世界最浪漫的城市之一。
响应约 30 秒,eval rate 3.93 tokens/s,表现不错。
图片输入示例,先准备图片:
cd Documents/
mkdir OLLAMA
cd OLLAMA
下载一张 $640\times 320$ 的巴黎图片( Wikipedia: Paris, France ):

上传至 Raspi-5,命名为 image_test_1.jpg,获取完整路径:
/home/mjrovai/Documents/OLLAMA/image_test_1.jpg
输入:
>>> Describe the image /home/mjrovai/Documents/OLLAMA/image_test_1.jpg
结果详尽,但推理延迟较高,约 4 分钟。
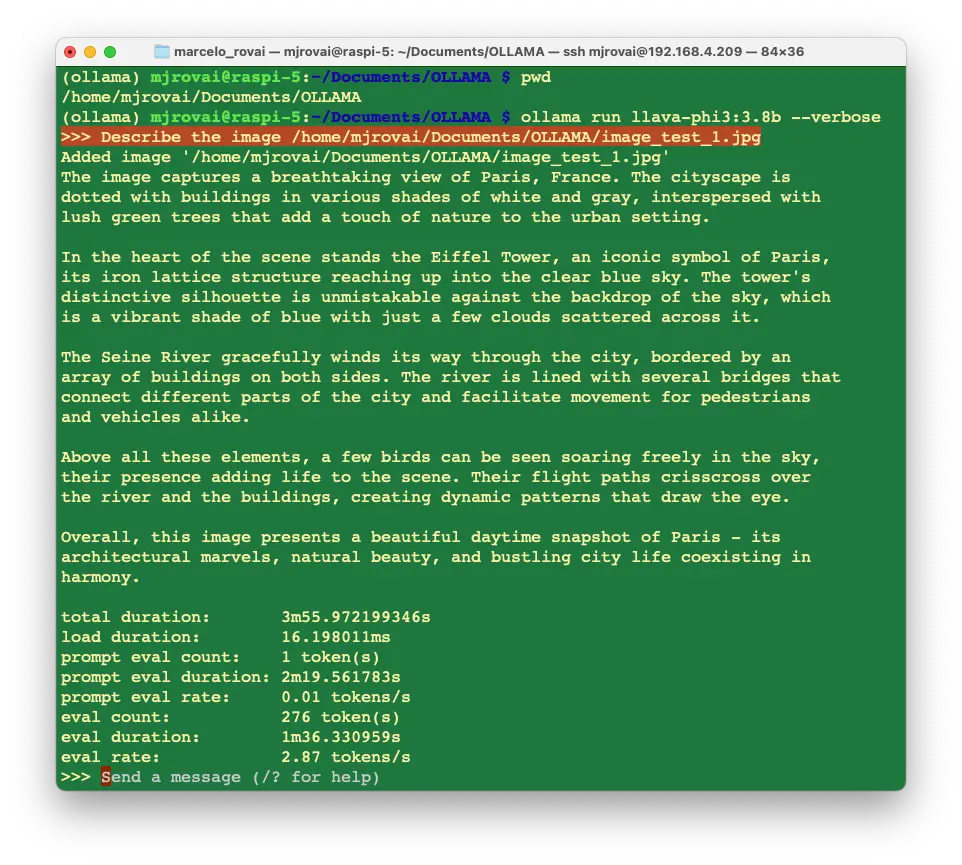
查看本地资源
用 htop 监控设备资源:
htop
模型运行时,4 核 CPU 几乎满载,内存占用 3.24GB,退出 Ollama 后降至 377MB。
温度监控:
桌面环境可在任务栏显示温度:

无桌面可用命令:
vcgencmd measure_temp
空闲时约 50°C,推理时可达 70°C,低于 80°C/85°C 安全阈值,说明主动散热器工作正常。
Ollama Python 库
前文通过命令行体验了 SLM 聊天能力,实际项目集成推荐用 Python。Ollama 官方提供了 Python 库,简化与 LLM 交互,便于集成到 Python 3.8+ 项目。
更多 Ollama Python 应用可参考 Matt Williams 视频 :
https://www.youtube.com/embed/_4K20tOsXK8
安装方法:
pip install ollama
如需开发环境,可用 Thonny、Geany、VS Code 等编辑器,或安装 Jupyter Notebook:
pip install jupyter
jupyter notebook --generate-config
启动 Jupyter:
jupyter notebook --ip=192.168.4.209 --no-browser
在 Raspi 工作目录新建 Python 3 notebook,测试已安装模型:
import ollama
ollama.list()
输出模型列表字典。
用 ollama.generate() 生成响应:
MODEL = "gemma2:2b"
PROMPT = "法国的首都是哪里?"
res = ollama.generate(model=MODEL, prompt=PROMPT)
print(res)
输出 JSON 格式响应,包括 response、context、total_duration、eval_count 等。
如只需输出结果和推理耗时:
print(f"\n{res['response']}")
print(
f"\n [INFO] Total Duration: "
f"{res['total_duration']/1e9:.2f} seconds"
)
使用 Ollama.chat()
ollama.chat() 支持多轮对话,适合持续会话。示例:
PROMPT_1 = "法国的首都是哪里?"
response = ollama.chat(
model=MODEL,
messages=[
{
"role": "user",
"content": PROMPT_1,
},
],
)
resp_1 = response["message"]["content"]
print(f"\n{resp_1}")
print(
f"\n [INFO] Total Duration: "
f"{(response['total_duration']/1e9):.2f} seconds"
)
PROMPT_2 = "意大利的首都呢?"
response = ollama.chat(
model=MODEL,
messages=[
{
"role": "user",
"content": PROMPT_1,
},
{
"role": "assistant",
"content": resp_1,
},
{
"role": "user",
"content": PROMPT_2,
},
],
)
resp_2 = response["message"]["content"]
print(f"\n{resp_2}")
print(
f"\n [INFO] Total Duration: "
f"{(response_2['total_duration']/1e9):.2f} seconds"
)
多轮对话可保持上下文。
图片描述示例:
用 ollama.generate() 结合图片输入:
MODEL = "llava-phi3:3.8b"
PROMPT = "描述这张图片"
with open("image_test_1.jpg", "rb") as image_file:
img = image_file.read()
response = ollama.generate(model=MODEL, prompt=PROMPT, images=[img])
print(f"\n{response['response']}")
print(
f"\n [INFO] Total Duration: "
f"{(res['total_duration']/1e9):.2f} seconds"
)
输出详细图片描述,推理约 4 分钟。
相关实验见 10-Ollama_Python_Library 。
函数调用(Function Calling)
通过函数调用可让模型输出结构化结果,便于集成到实际项目。例如,输入国家名,输出首都及经纬度,再用 Python 计算与圣地亚哥的距离。
安装依赖:
pip install haversine
pip install openai
pip install pydantic
pip install instructor
核心代码结构:
import sys
from haversine import haversine
from openai import OpenAI
from pydantic import BaseModel, Field
import instructor
country = sys.argv[1]
MODEL = "phi3.5:3.8b"
mylat = -33.33
mylon = -70.51
class CityCoord(BaseModel):
city: str = Field(..., description="城市名")
lat: float = Field(..., description="城市纬度")
lon: float = Field(..., description="城市经度")
client = instructor.patch(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON,
)
resp = client.chat.completions.create(
model=MODEL,
messages=[
{
"role": "user",
"content": f"返回 {country} 首都的经纬度。",
}
],
response_model=CityCoord,
max_retries=10,
)
distance = haversine((mylat, mylon), (resp.lat, resp.lon), unit="km")
print(
f"圣地亚哥距离 {resp.city} 约 {int(round(distance, -1))} 公里。"
)
运行效果:
圣地亚哥距离华盛顿约 8,060 公里。
圣地亚哥距离波哥大约 4,250 公里。
圣地亚哥距离巴黎约 11,630 公里。
相关实验见 20-Ollama_Function_Calling 。
图片输入场景
进一步扩展,输入图片,模型识别城市及经纬度,再计算距离。代码分两步:先用 LLM 生成图片描述,再提取结构化信息。
def image_description(img_path):
with open(img_path, "rb") as file:
response = ollama.chat(
model=MODEL,
messages=[
{
"role": "user",
"content": """返回图片中城市的经纬度、名称及所属国家""",
"images": [file.read()],
},
],
options={
"temperature": 0,
},
)
return response["message"]["content"]
再用 Pydantic 结构化输出,结合 haversine 计算距离。
相关实验见 30-Function_Calling_with_images 。
SLM 优化技术
LLM/SLM 部署与优化面临诸多挑战,如幻觉(hallucination)、算力消耗、知识时效性、隐私、领域适配等。主流优化技术包括微调、提示工程(Prompt Engineering)、检索增强生成(RAG)。
- 微调:针对特定领域/任务进一步训练模型,提升专业表现。
- 提示工程:精心设计输入 prompt,引导模型输出更准确结果。
- RAG:结合外部知识库检索,提升模型准确性,减少幻觉。
边缘应用更适合用 RAG,无需本地微调即可提升效果。
RAG 实现
RAG 流程:用户提问 → 检索知识 → 结合检索结果生成答案。
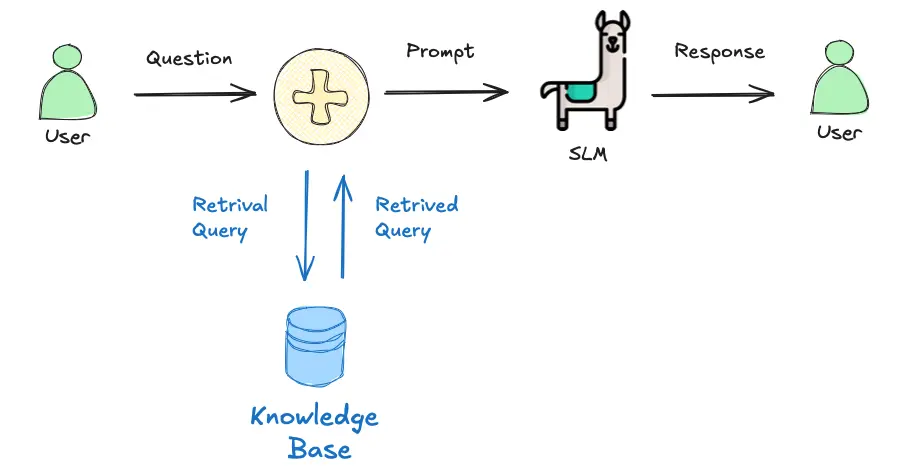
简单 RAG 项目
步骤:
- 确定文档类型:优选纯文本,PDF 需特殊处理。
- 文本分块:按字符、token、段落等分割。
- 生成嵌入向量:用嵌入模型(如 nomic-embed-text)将文本转为向量。
- 存储到向量数据库:用 Chromadb 存储检索。
- 构建 prompt:检索相关片段,拼接到 prompt。
安装依赖:
pip install ollama chromadb
拉取嵌入模型:
ollama pull nomic-embed-text
示例代码略,详见原文。
相关实验见 40-RAG-simple-bee 。
拓展应用
小型 LLM 在边缘侧表现良好,尤其在文本和图片场景。实际应用可结合目标检测(如 YOLO)等模型,先识别图片内容,再交由 LLM 处理。
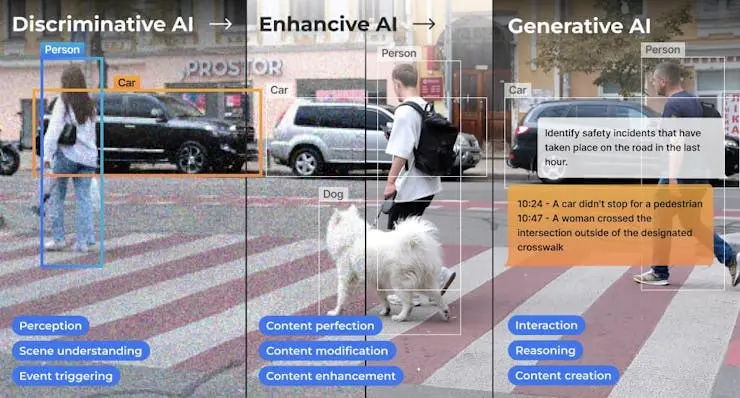
Hailo CTO Avi Baum 观点:AI 在边缘侧的演进正从传统视觉、判别式 AI、增强式 AI 迈向生成式 AI,未来智能系统将无缝融入日常生活,实现感知与创造的结合。
总结
本实验展示了如何将树莓派 5 打造成可运行 LLM 的 AI 中枢,支持本地实时数据分析与洞察。树莓派的灵活性与小型 LLM(如 Llama 3.2、LLaVa-Phi-3-mini)结合,为边缘计算应用提供了强大平台。
更多创新应用建议:
1. 智能家居自动化
集成 SLM 实现本地语音指令解析、传感器数据分析,实现智能家居自动化,无需云端依赖。
2. 野外数据采集与分析
在农业、环境监测、应急响应等场景,部署 SLM 实现实时本地数据采集与分析。
3. 教育工具
开发交互式教育工具,支持即时反馈、翻译、辅导,适合网络受限地区。
4. 医疗健康
用于医疗诊断、患者监测,实时分析症状并建议处理方案,适合远程医疗或便携设备。
5. 本地商业智能
在零售/小微企业场景分析客户行为、库存管理、运营优化,保障隐私。
6. 工业物联网
集成 SLM 实现预测性维护、质量控制、流程优化,提升自动化可靠性。
7. 自动驾驶与机器人
处理传感器数据,实现实时决策与导航,适用于无人机、机器人、自动驾驶等。
8. 文化旅游
为文化遗产、博物馆等场景提供本地化智能讲解,无需联网。
9. 艺术与创意项目
分析/生成音乐、艺术、文学等内容,支持创新型交互体验。
10. 定制辅助技术
为残障人士开发个性化辅助工具,如实时语音转文字、翻译等。
参考资料
- 10-Ollama_Python_Library notebook
- 20-Ollama_Function_Calling notebook
- 30-Function_Calling_with_images notebook
- 40-RAG-simple-bee notebook
- calc_distance_image python script