目标检测
概述
在完成图像分类的学习后,我们将目光转向更高级的计算机视觉任务——目标检测。图像分类为整张图片分配一个标签,而目标检测则进一步识别并定位图片中的多个目标。这一能力为边缘计算和物联网设备(如 Raspberry Pi)带来了更多应用场景和挑战。
目标检测融合了分类与定位两大任务。它不仅判断图片中有哪些对象,还能通过绘制边界框等方式,精确标注对象的位置。这种复杂性让目标检测成为理解视觉场景的强大工具,但也对模型和训练方法提出了更高要求。
在边缘 AI 场景下,受限于计算资源,实现高效的目标检测模型尤为关键。图像分类中遇到的模型体积、推理速度与精度的平衡问题,在目标检测中被进一步放大。但回报也更大,因为目标检测能实现更细致、丰富的视觉数据分析。
目标检测在边缘设备上的典型应用包括:
- 安防监控系统
- 自动驾驶与无人机
- 工业质检
- 野生动物监测
- 增强现实应用
在本章实践中,我们将基于图像分类的知识,深入目标检测。重点介绍适合边缘设备的主流目标检测架构,如:
- 单阶段检测器(如 MobileNet、EfficientDet)
- FOMO(Faster Objects, More Objects)
- YOLO(You Only Look Once)
想进一步了解目标检测模型,可参考教程 A Gentle Introduction to Object Recognition With Deep Learning 。
我们将分别体验以下目标检测模型:
- TensorFlow Lite Runtime(现已更名为 LiteRT )
- Edge Impulse Linux Python SDK
- Ultralitics
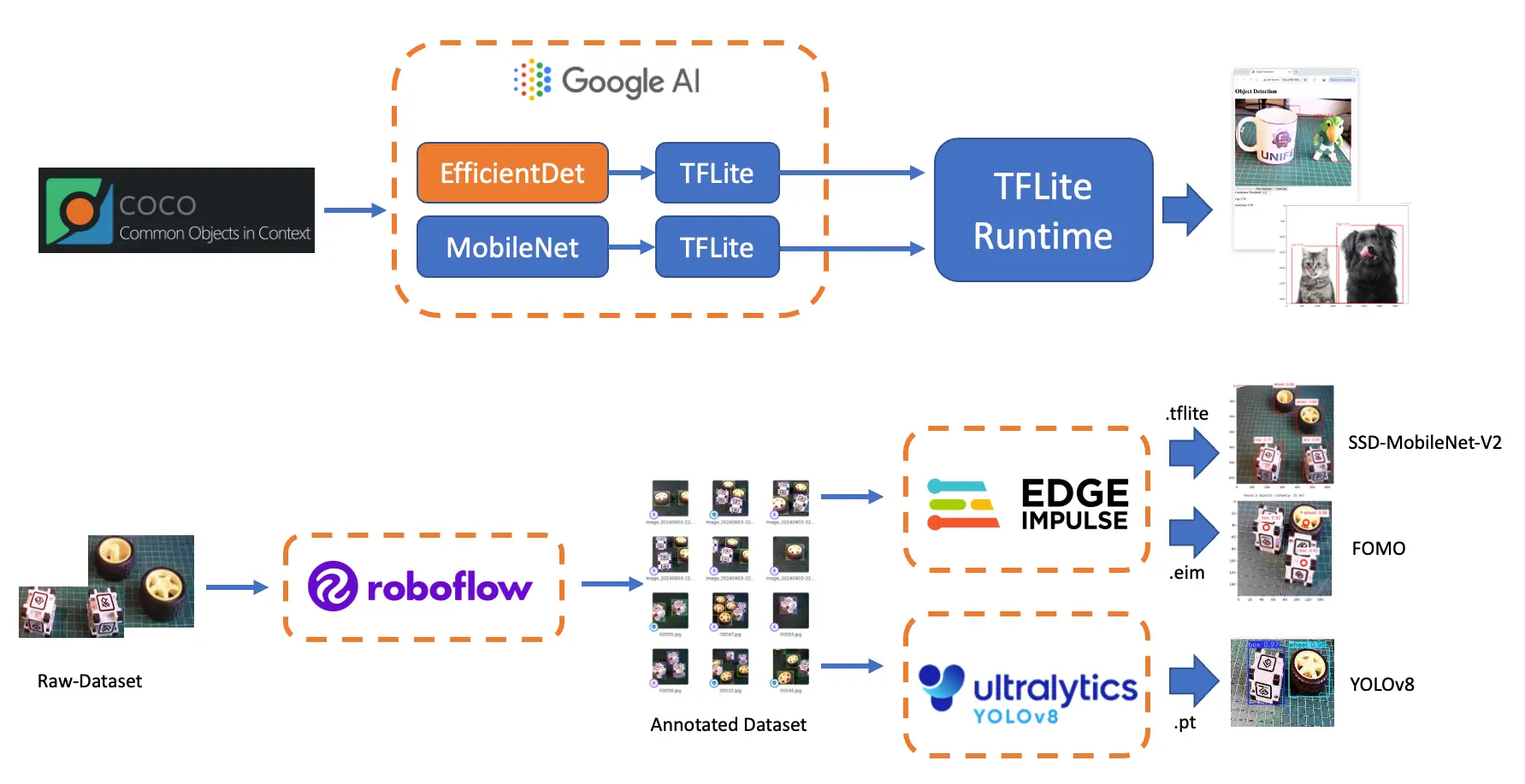
在本实验中,我们将系统学习目标检测的基本原理及其与图像分类的区别,并掌握如何基于自建数据集训练、微调、测试、优化和部署主流目标检测模型。
目标检测基础
目标检测是在图像分类基础上的重要扩展。理解目标检测,首先要明确它与图像分类的核心区别:
图像分类 vs. 目标检测
图像分类:
- 为整张图片分配一个标签
- 回答“这张图片的主要内容是什么?”
- 输出单一类别预测
目标检测:
- 识别并定位图片中的多个对象
- 回答“图片中有哪些对象?它们分别在哪里?”
- 输出多个预测结果,每个包含类别标签和边界框
举例说明:
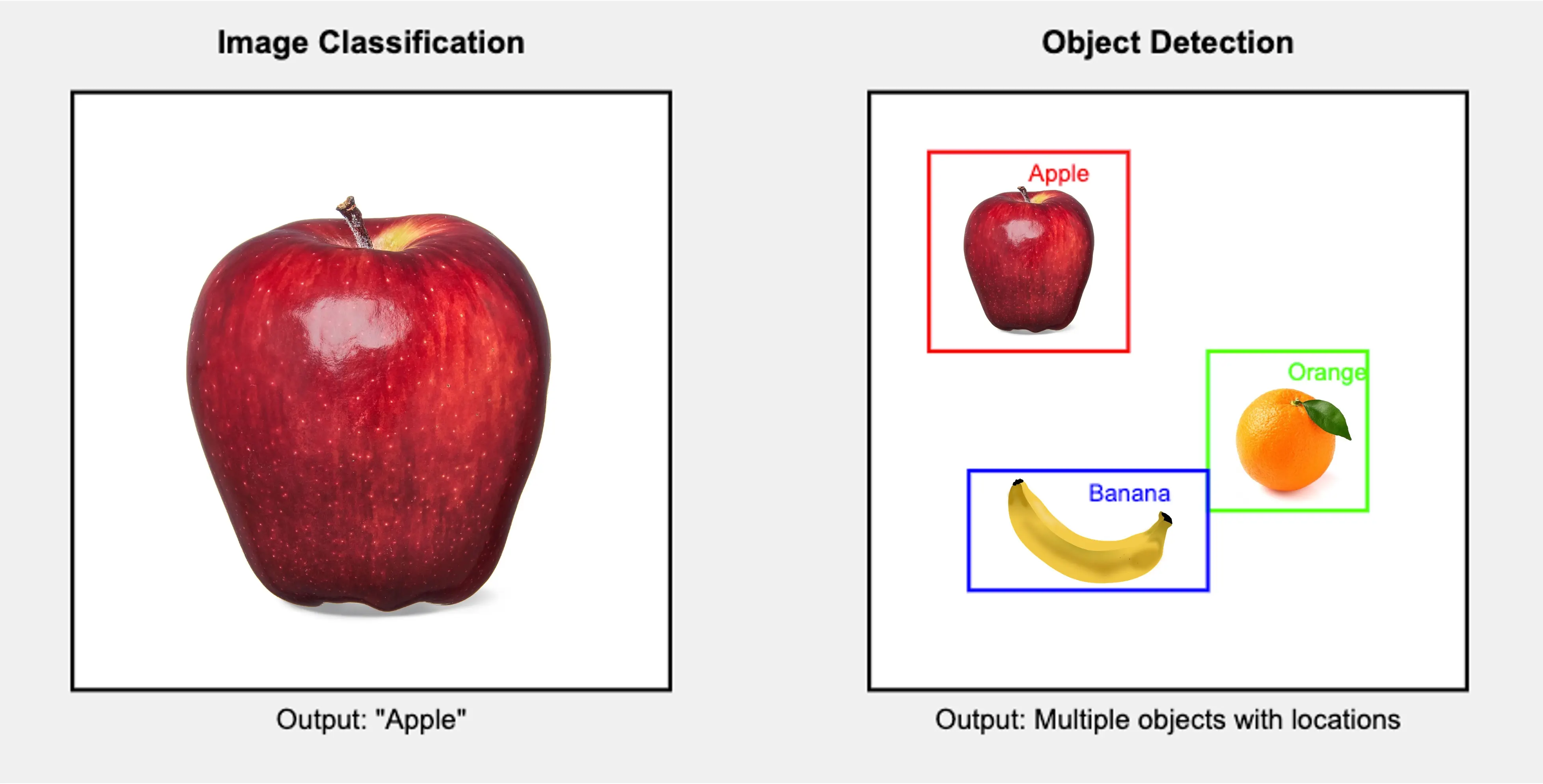
如上图所示,图像分类只给出整体标签,而目标检测能识别多个对象及其具体位置。
目标检测的关键组成
目标检测系统通常包含两大核心模块:
- 目标定位:确定对象在图片中的位置,通常输出边界框(矩形区域)。
- 目标分类:对每个定位到的区域进行类别判别,类似于图像分类,但针对每个局部区域。
目标检测的挑战
相比图像分类,目标检测面临更多挑战:
- 多目标:一张图片可能包含多个不同类别、大小、位置的对象
- 尺度变化:对象在图片中可能有不同尺寸
- 遮挡:对象可能部分被遮挡或重叠
- 背景干扰:复杂背景下区分目标更难
- 实时性:许多应用要求极快的推理速度,尤其在边缘设备上
目标检测方法
主流目标检测方法分为两类:
- 两阶段检测器:先生成候选区域,再对每个区域分类。典型如 R-CNN 系列(Fast R-CNN、Faster R-CNN)。
- 单阶段检测器:一次前向传播同时预测边界框和类别概率。典型如 YOLO、EfficientDet、SSD、FOMO。单阶段方法速度更快,更适合 Raspberry Pi 等边缘设备。
评估指标
目标检测常用的评估指标有:
- IoU(交并比):衡量预测框与真实框的重叠程度
- mAP(平均精度均值):综合各类别和 IoU 阈值下的精度与召回率
- FPS(帧率):检测速度,边缘设备实时应用的关键指标
预训练目标检测模型概览
如前所述,目标检测模型可对图片或视频流中的已知对象进行识别,并输出其在图片中的位置。
可在线体验常见模型: Object Detection - MediaPipe Studio
在
Kaggle
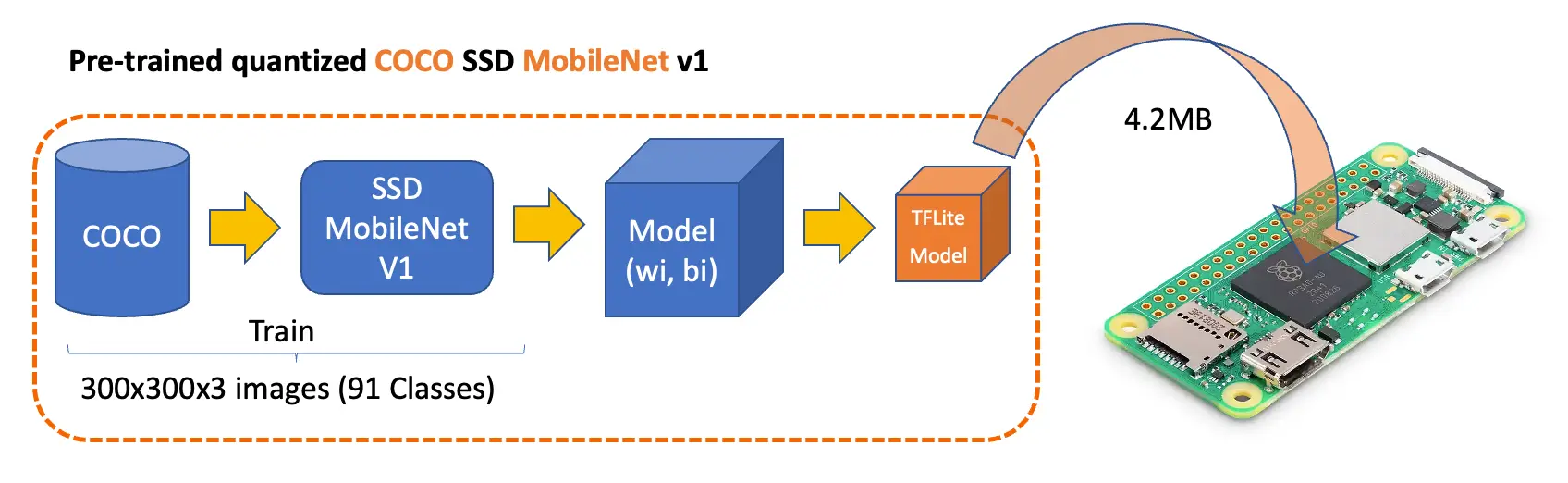
上可找到适用于 Raspberry Pi 的主流 tflite 预训练模型,如
ssd_mobilenet_v1
和
EfficientDet
。这些模型基于 COCO 数据集(91 类,20 万张标注图片)训练。下载模型后上传至 Raspi 的 ./models 文件夹。
也可在 GitHub 获取模型及 COCO 标签文件。
本实验首先聚焦于 $300\times 300$ 的 SSD-Mobilenet V1 预训练模型,并与 $320\times 320$ 的 EfficientDet-lite0 进行对比,二者均基于 COCO 2017 数据集训练,已转换为 TensorFlow Lite 格式(SSD Mobilenet 4.2 MB,EfficientDet 4.6 MB)。
SSD-Mobilenet V2/V3 更适合迁移学习,但本节以公开的 V1 TFLite 模型为例进行演示。
配置 TFLite 环境
请确认已完成上一节“图像分类”实验的相关步骤:
- 更新 Raspberry Pi
- 安装所需库
- (可选)创建虚拟环境
source ~/tflite/bin/activate
- 安装 TensorFlow Lite Runtime
- 在虚拟环境中安装其他 Python 库
创建工作目录
假设上节已创建 Documents/TFLITE 文件夹,现在为目标检测实验新建专用目录:
cd Documents/TFLITE/
mkdir OBJ_DETECT
cd OBJ_DETECT
mkdir images
mkdir models
cd models
推理与后处理
新建 notebook 按步骤实现目标检测:
导入所需库:
import time
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import tflite_runtime.interpreter as tflite
加载 TFLite 模型并分配张量:
model_path = "./models/ssd-mobilenet-v1-tflite-default-v1.tflite"
interpreter = tflite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
获取输入输出张量信息:
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
输入信息 指明模型期望的图片格式。形状为 (1, 300, 300, 3),类型为 uint8,即输入为未归一化的 $300\times 300\times 3$ 彩色图片,单张输入(Batch=1)。
输出信息 包含类别(classes)、概率(scores)、边界框(boxes)及检测到的对象数量(num_detections)。模型最多可检测 10 个对象。
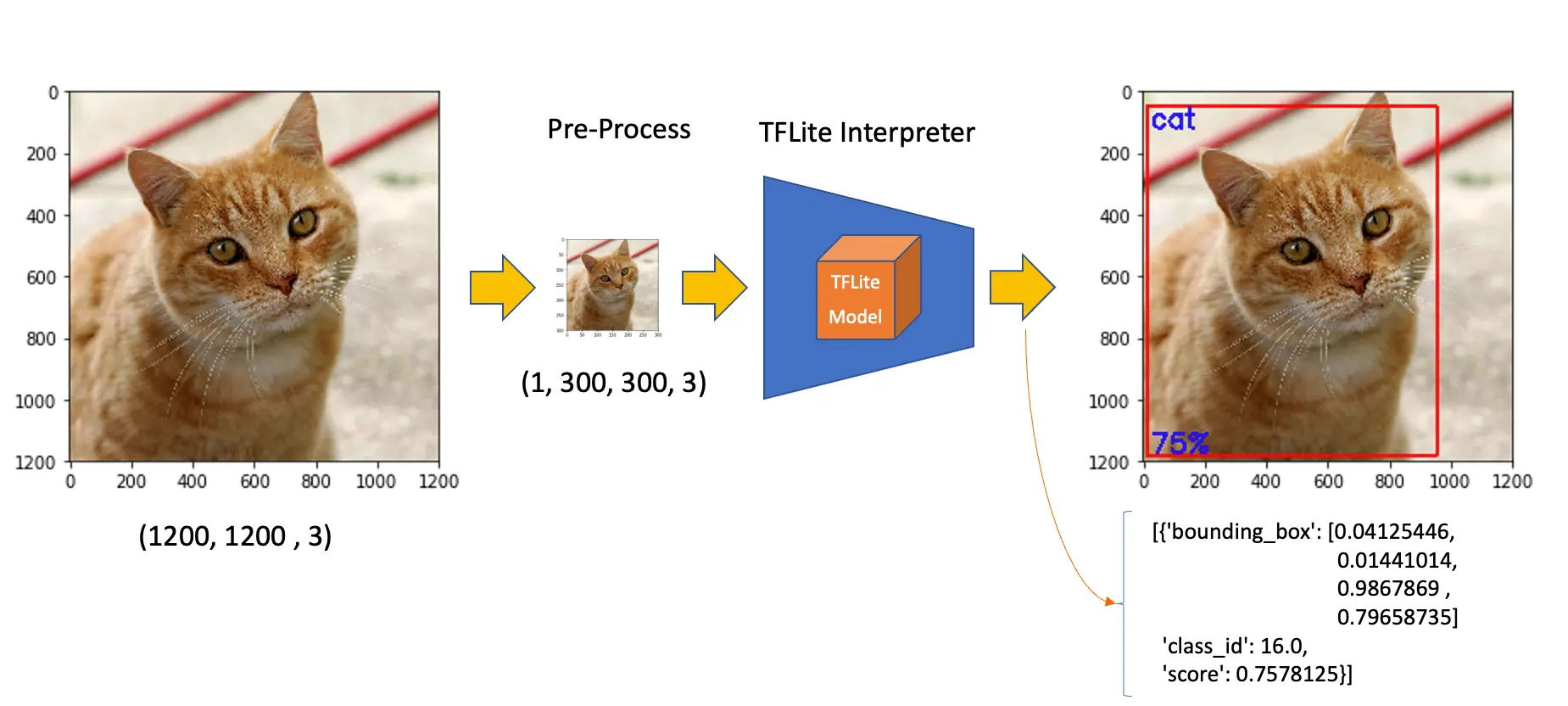
如上例,模型以 76% 概率检测到类别 ID 为 16 的对象,边界框为 [0.028011084, 0.020121813, 0.9886069, 0.802299],分别对应 ymin、xmin、ymax、xmax。
y 轴自上而下,x 轴自左至右。已知图片尺寸,即可绘制目标的矩形框:
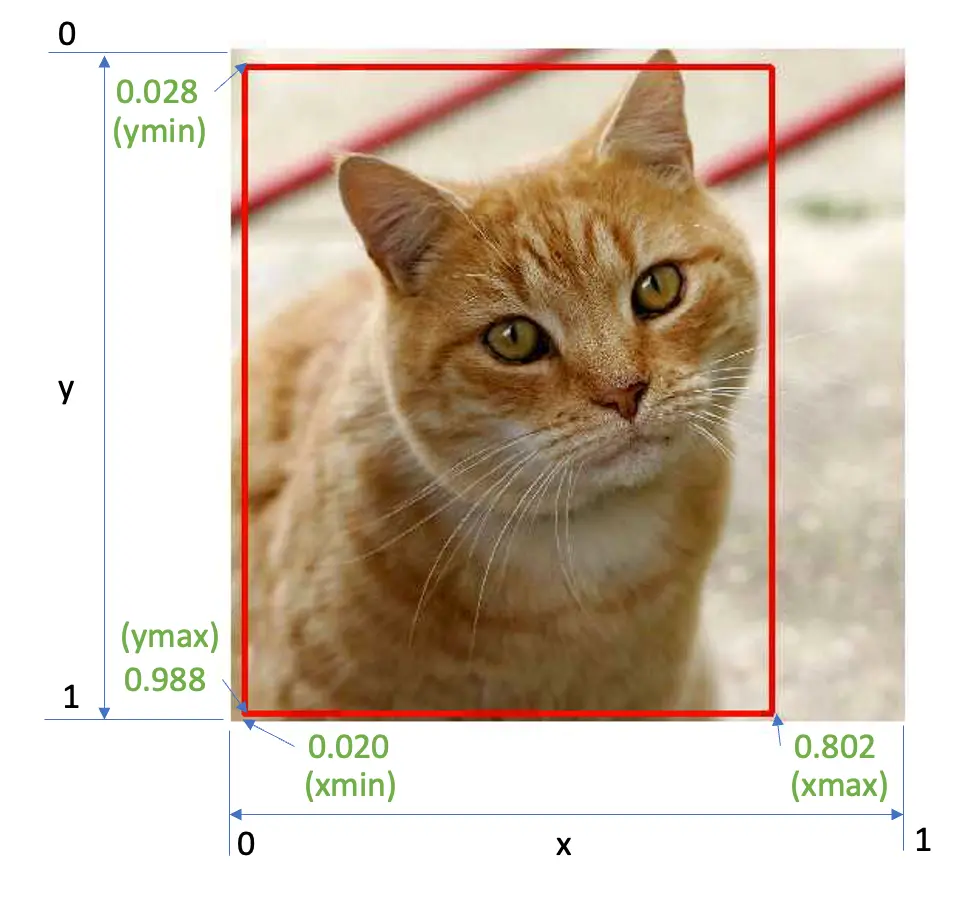
查找类别 ID 16 的含义,打开 coco_labels.txt,第 16 行为 cat,概率即为得分。
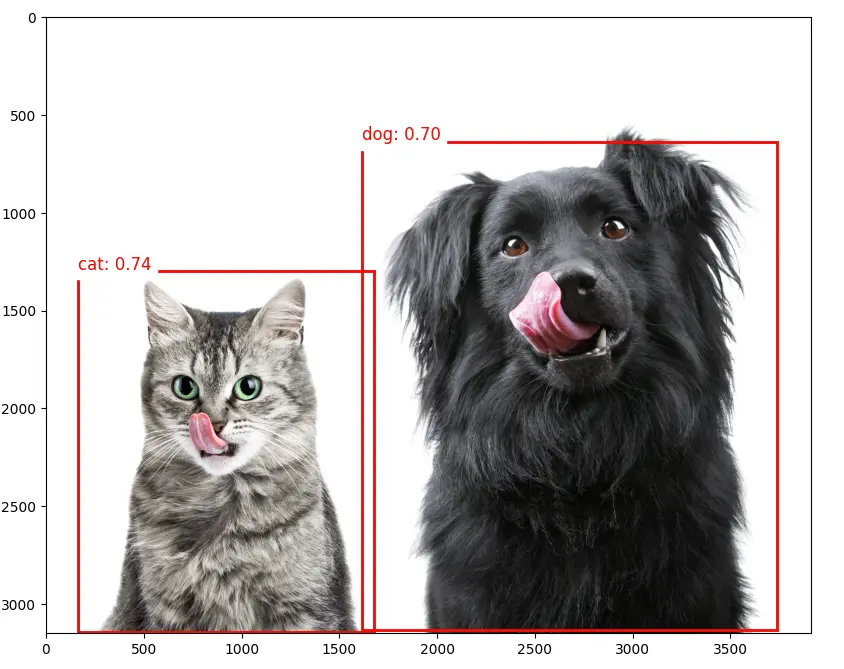
接下来上传包含多个对象的图片进行测试。
img_path = "./images/cat_dog.jpeg"
orig_img = Image.open(img_path)
# 显示图片
plt.figure(figsize=(8, 8))
plt.imshow(orig_img)
plt.title("原始图片")
plt.show()

根据输入信息,预处理图片:
img = orig_img.resize(
(input_details[0]["shape"][1], input_details[0]["shape"][2])
)
input_data = np.expand_dims(img, axis=0)
input_data.shape, input_data.dtype
新输入数据形状为 (1, 300, 300, 3),类型为 uint8,与模型要求一致。
推理并计时:
start_time = time.time()
interpreter.set_tensor(input_details[0]["index"], input_data)
interpreter.invoke()
end_time = time.time()
inference_time = (
end_time - start_time
) * 1000 # 毫秒
print("推理时间:{:.1f}ms".format(inference_time))
约 800ms,可获取 4 个输出:
boxes = interpreter.get_tensor(output_details[0]["index"])[0]
classes = interpreter.get_tensor(output_details[1]["index"])[0]
scores = interpreter.get_tensor(output_details[2]["index"])[0]
num_detections = int(
interpreter.get_tensor(output_details[3]["index"])[0]
)
快速查看得分大于 0.5 的目标:
for i in range(num_detections):
if scores[i] > 0.5:
print(f"Object {i}:")
print(f" Bounding Box: {boxes[i]}")
print(f" Confidence: {scores[i]}")
print(f" Class: {classes[i]}")

可视化检测结果:
plt.figure(figsize=(12, 8))
plt.imshow(orig_img)
for i in range(num_detections):
if scores[i] > 0.5:
ymin, xmin, ymax, xmax = boxes[i]
(left, right, top, bottom) = (
xmin * orig_img.width,
xmax * orig_img.width,
ymin * orig_img.height,
ymax * orig_img.height,
)
rect = plt.Rectangle(
(left, top),
right - left,
bottom - top,
fill=False,
color="red",
linewidth=2,
)
plt.gca().add_patch(rect)
class_id = int(classes[i])
class_name = labels[class_id]
plt.text(
left,
top - 10,
f"{class_name}: {scores[i]:.2f}",
color="red",
fontsize=12,
backgroundcolor="white",
)
EfficientDet 简介
EfficientDet 虽不属于 SSD(单次检测器)模型,但与 SSD 等架构有诸多相似之处,并在此基础上创新:
EfficientDet:
- 2019 年 Google 提出
- 以 EfficientNet 为骨干网络
- 引入 BiFPN(双向特征金字塔网络)
- 采用复合缩放策略,整体高效扩展
与 SSD 的相似点:
- 均为单阶段检测器,单次前向传播完成定位与分类
- 均利用多尺度特征图检测不同尺寸目标
主要区别:
- 骨干网络:SSD 常用 VGG/MobileNet,EfficientDet 用 EfficientNet
- 特征融合:SSD 用简单金字塔,EfficientDet 用 BiFPN
- 缩放方式:EfficientDet 复合缩放,整体更灵活
优势:
- 精度与效率权衡优于 SSD 等主流模型
- 支持多种规模,适配不同性能需求
EfficientDet 可视为单阶段检测架构的进化,输出结构与 SSD 类似(边界框与类别分数)。
可参考 notebook 进一步探索 EfficientDet。
目标检测项目实战
接下来,我们将从数据采集到训练与部署,完整实现一个目标检测项目。训练模型包括 SSD-MobileNet V2、FOMO 和 YOLO,均基于同一数据集。
项目目标
所有机器学习项目都需明确目标。假设我们在工厂需对 轮子 和特殊 盒子 进行分拣与计数。

即需实现多标签分类,每张图片可能有三类:
- 背景(无对象)
- 盒子
- 轮子
原始数据采集
明确目标后,首要任务是采集数据集。可用手机、Raspi 或混合方式采集原始图片(无标签)。Raspberry Pi 可通过 Web 应用实时预览并采集 QVGA (320 x 240) 图片。
从 GitHub 获取 get_img_data.py 脚本并运行:
python3 get_img_data.py
访问 Web 界面:
- 若在 Raspberry Pi 本地(有桌面环境):浏览器访问
http://localhost:5000 - 局域网其他设备:浏览器访问
http://<raspberry_pi_ip>:5000(将<raspberry_pi_ip>替换为实际 IP),如http://192.168.4.210:5000
该脚本基于 Raspberry Pi 摄像头,提供 Web 采集界面,便于机器学习项目采集图片数据。
在浏览器输入标签(如 box-wheel),点击 Start Capture 开始采集。
注意,采集图片暂不标注具体类别,后续再标注。
通过实时预览调整拍摄,点击 Capture Image 保存图片至当前标签文件夹(如 dataset/box-wheel)。
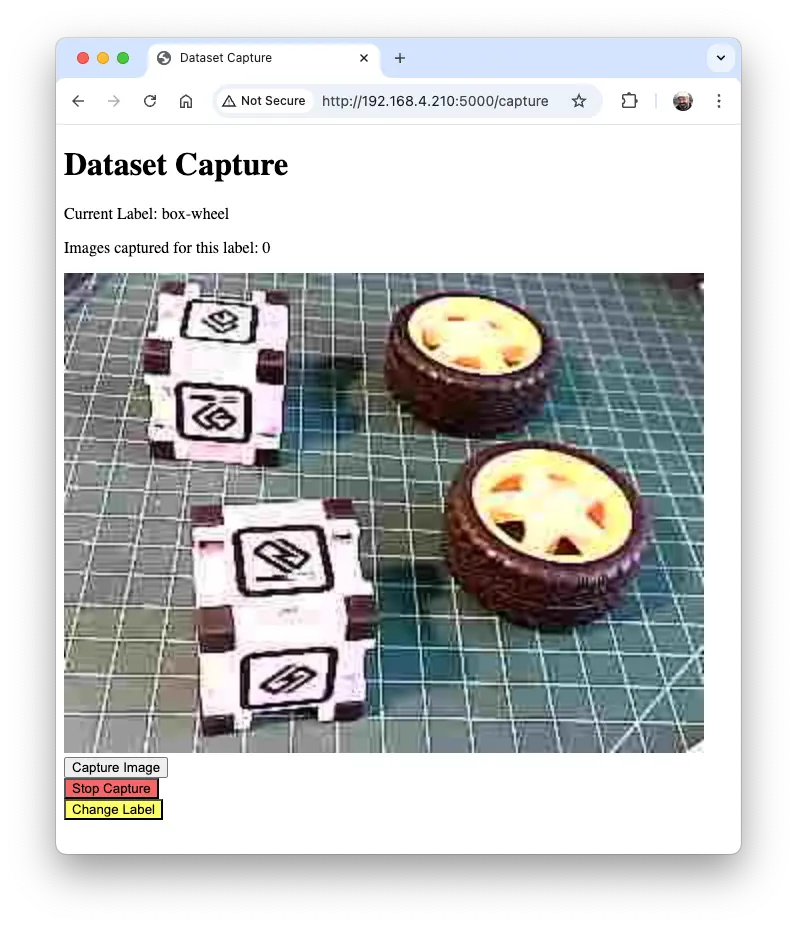
采集足够图片后,点击 Stop Capture。图片保存在 dataset/box-wheel 文件夹:
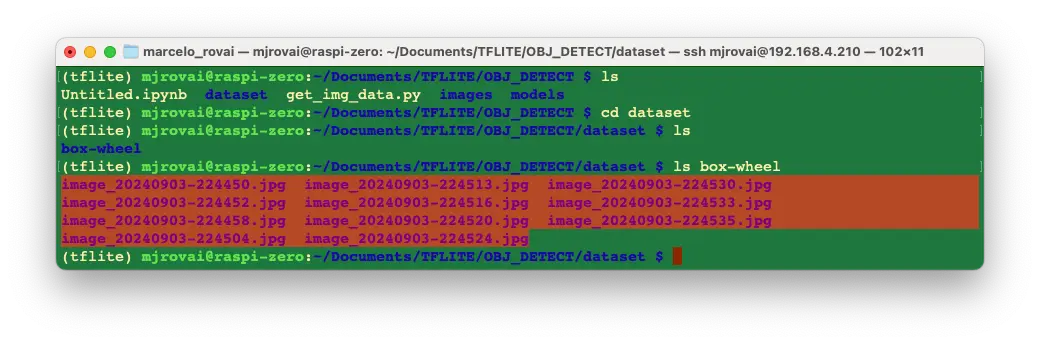
建议采集约 60 张图片,涵盖不同角度、背景和光照。可用 Filezilla 将数据集传至主机。
数据标注
目标检测项目的下一步是为图片打标签,即为每个对象绘制边界框。可用 LabelImg 、 CVAT 、 Roboflow 或 Edge Impulse Studio 。本节以 Roboflow 为例。
选用 Roboflow(免费版)主要因其支持自动标注和多格式导出,便于在 Edge Impulse、Ultralitics 等平台训练。Edge Impulse 标注数据无法直接用于其他平台。
上传原始数据集至 Roboflow ,新建项目(如“box-versus-wheel”)。
Roboflow 标注流程详见其官方教程,此处不再赘述。
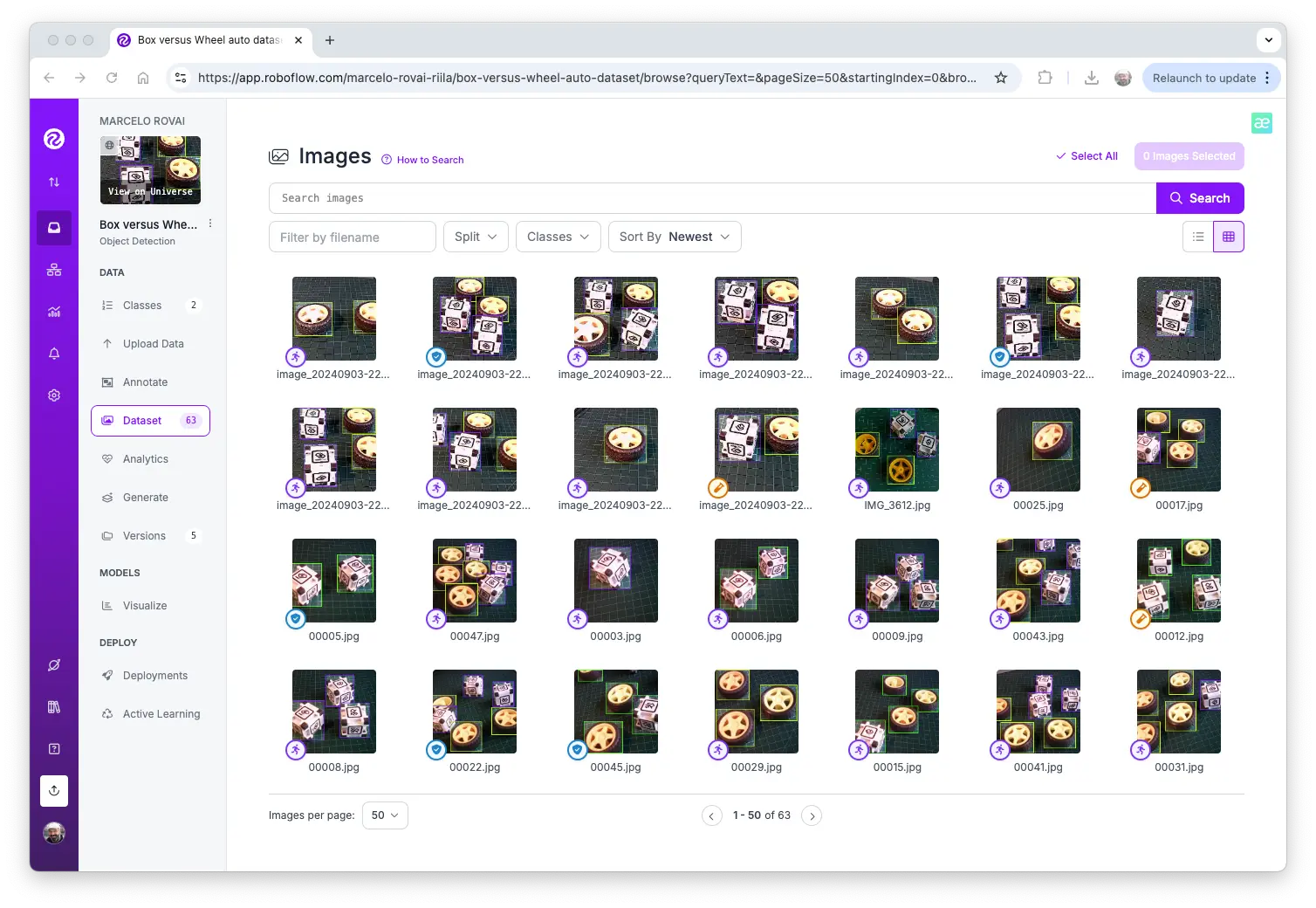
标注
项目创建并上传图片后,使用“Auto-Label”工具自动标注。可上传仅含背景的图片,无需标注。
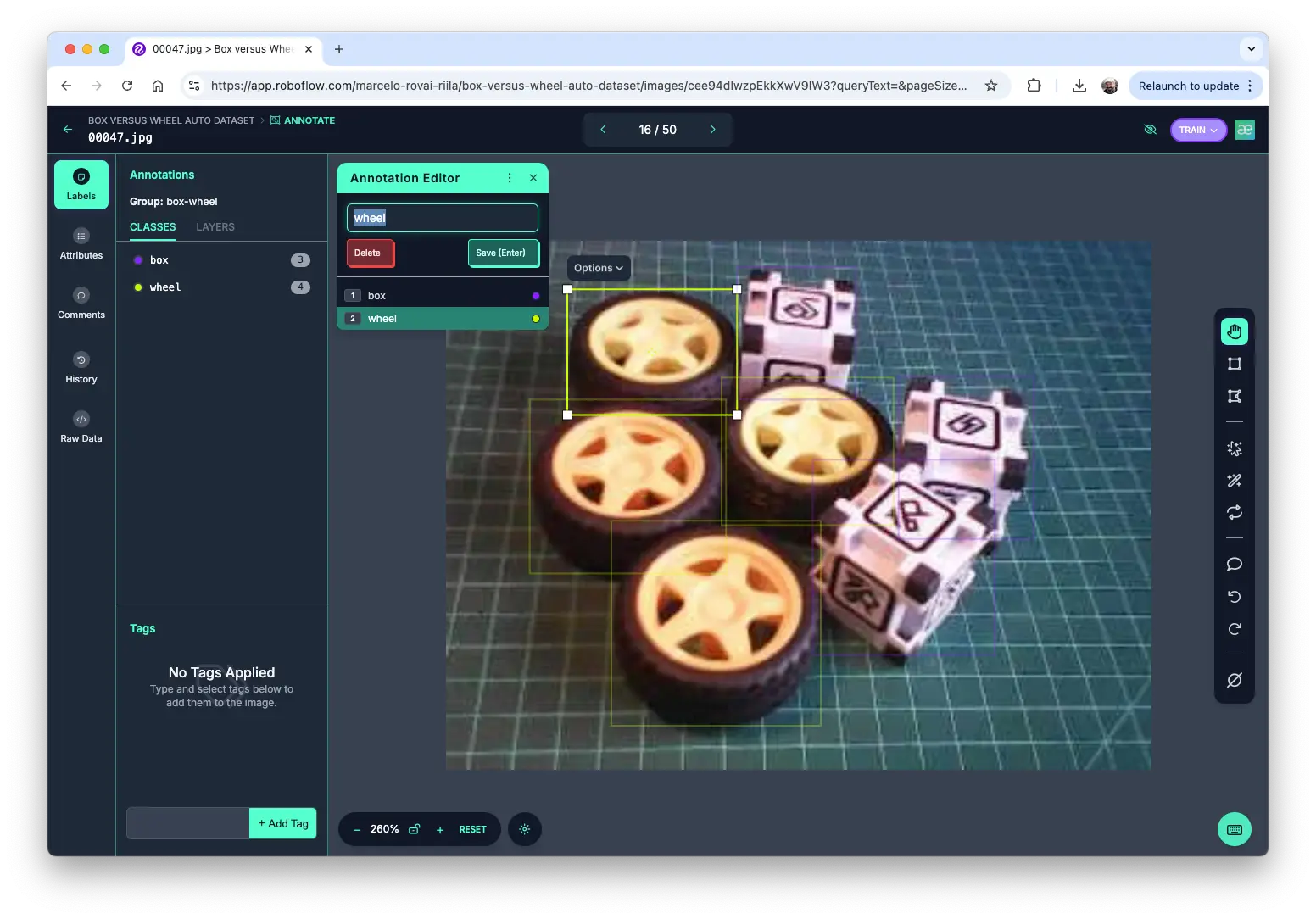
标注完成后,按训练、验证、测试划分数据集。
数据预处理
最后一步是预处理数据集,生成最终训练集。将所有图片调整为 $320\times 320$,并进行数据增强(如旋转、裁剪、亮度调整)。
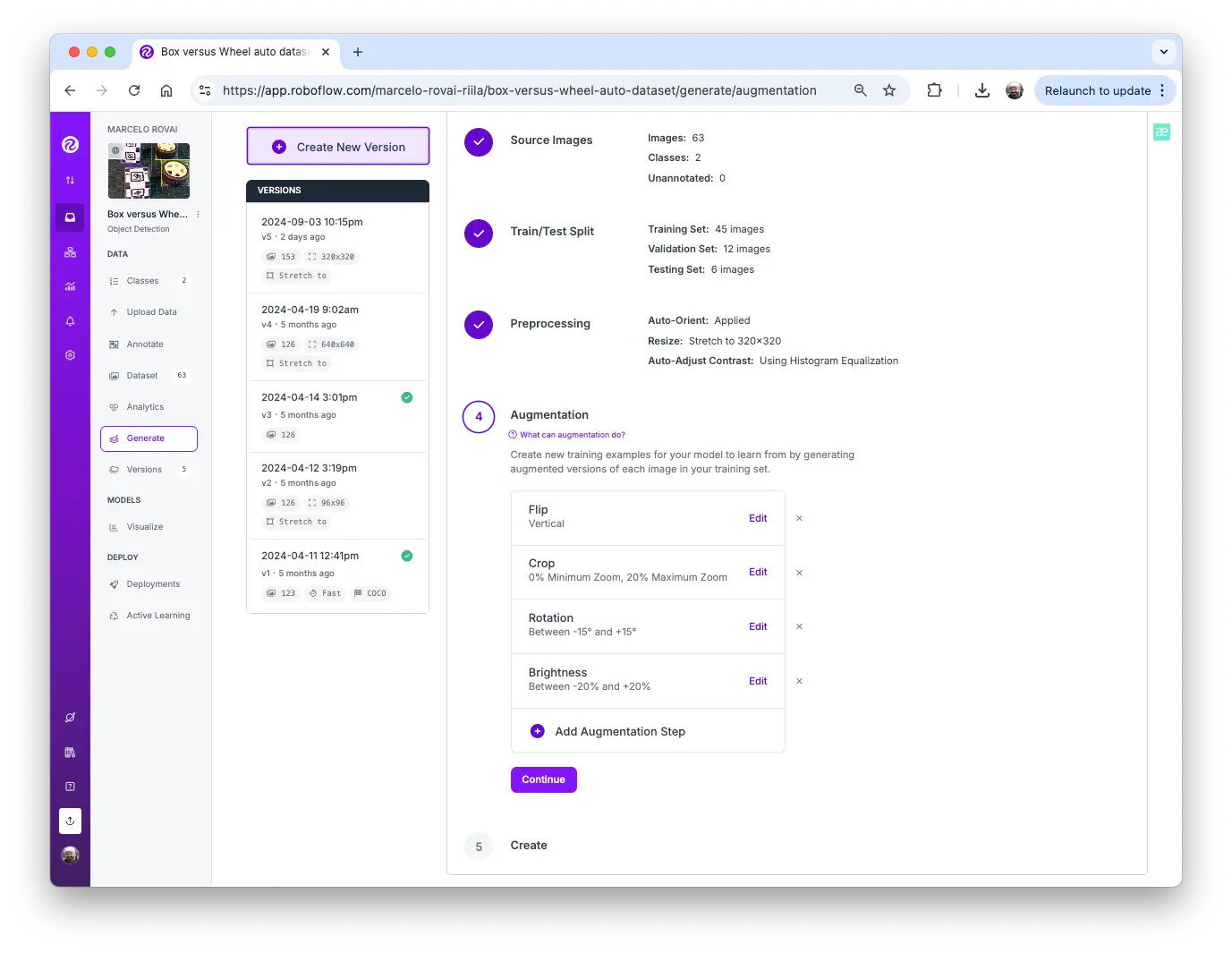
最终得到 153 张图片。
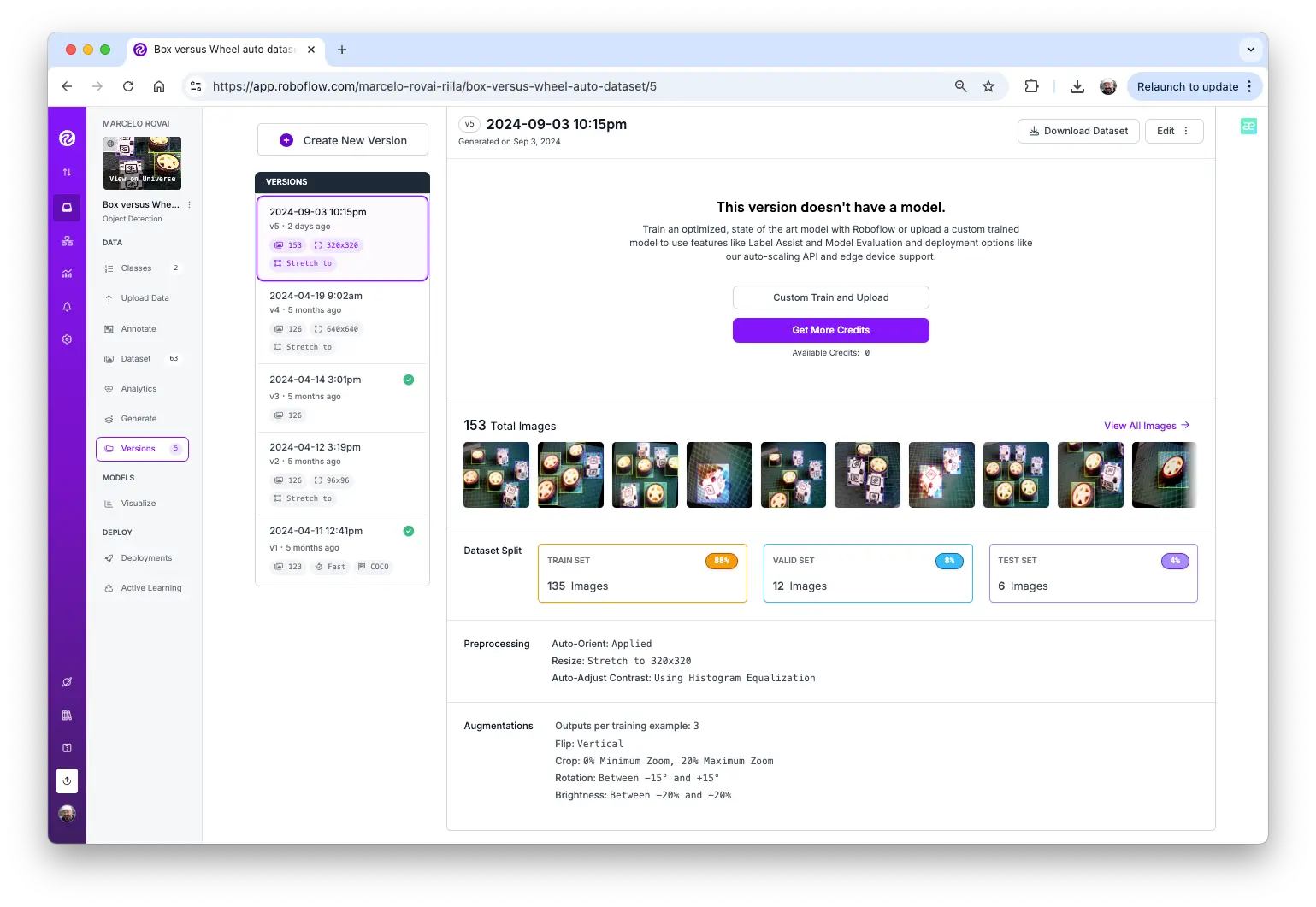
导出数据集为 Edge Impulse、Ultralitics 等支持的格式(如 YOLOv8),下载压缩包。
数据集结构如下:
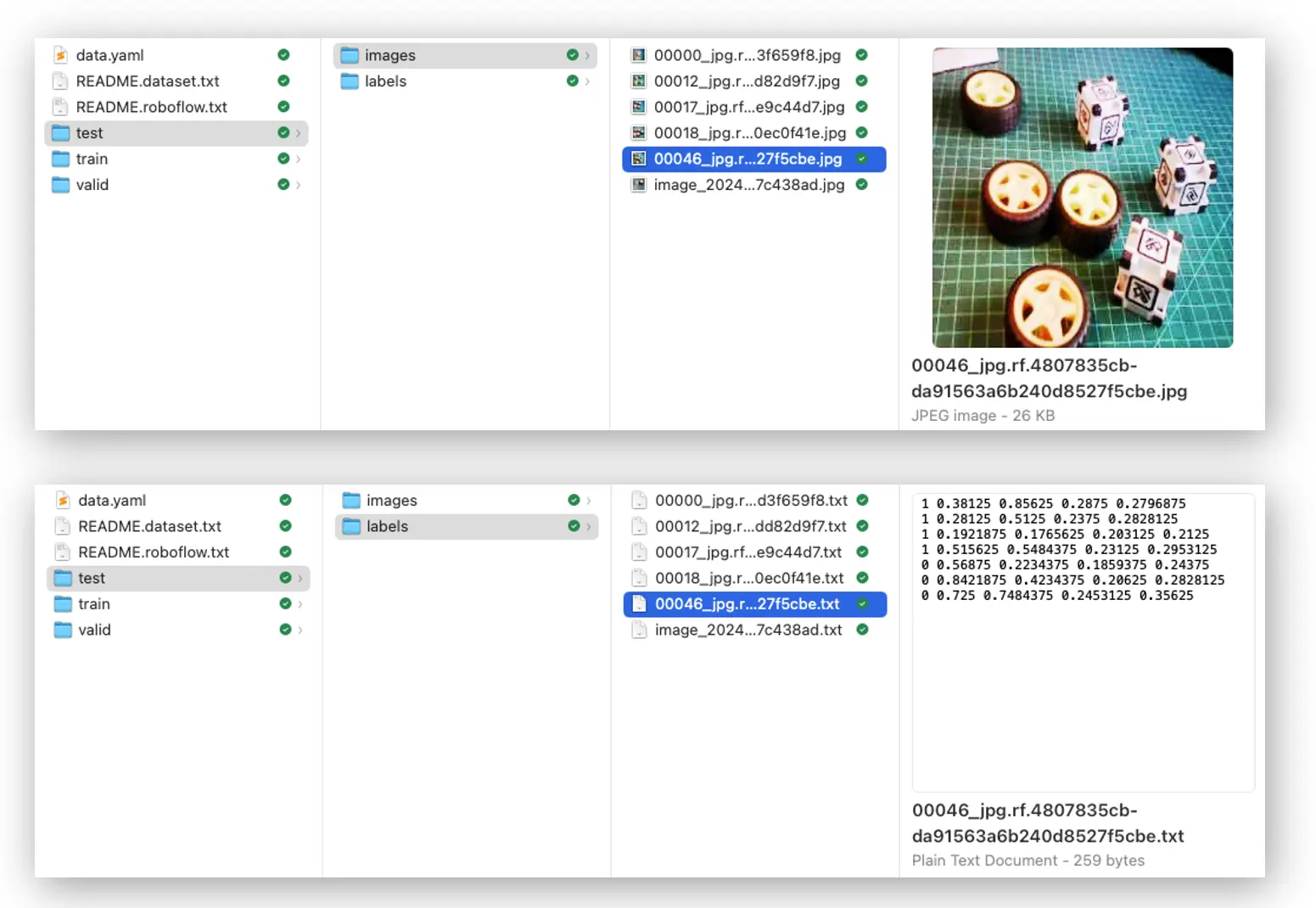
三大文件夹分别为 train、test、valid,每个包含 images 和 labels 子文件夹。标签文件格式为 class_id bounding box coordinates,本例中 0 表示 box,1 表示 wheel,编号按类别字母顺序排列。
data.yaml 文件包含类别名等信息,符合 YOLO 格式。
预处理后的数据集可在 Roboflow 获取。
在 Edge Impulse Studio 训练 SSD MobileNet 模型
登录 Edge Impulse Studio ,新建项目。
可直接克隆本实验项目: Raspi - Object Detection 。
在 Dashboard 页,Project info 处选择 Bounding boxes (object detection) 作为标注方式。
上传标注数据
在 Data acquisition 页,UPLOAD DATA 区域上传本地数据集。
选择 train 文件夹(含 images 和 labels),标签格式选 “YOLO TXT”,上传至 Training,点击 Upload data。
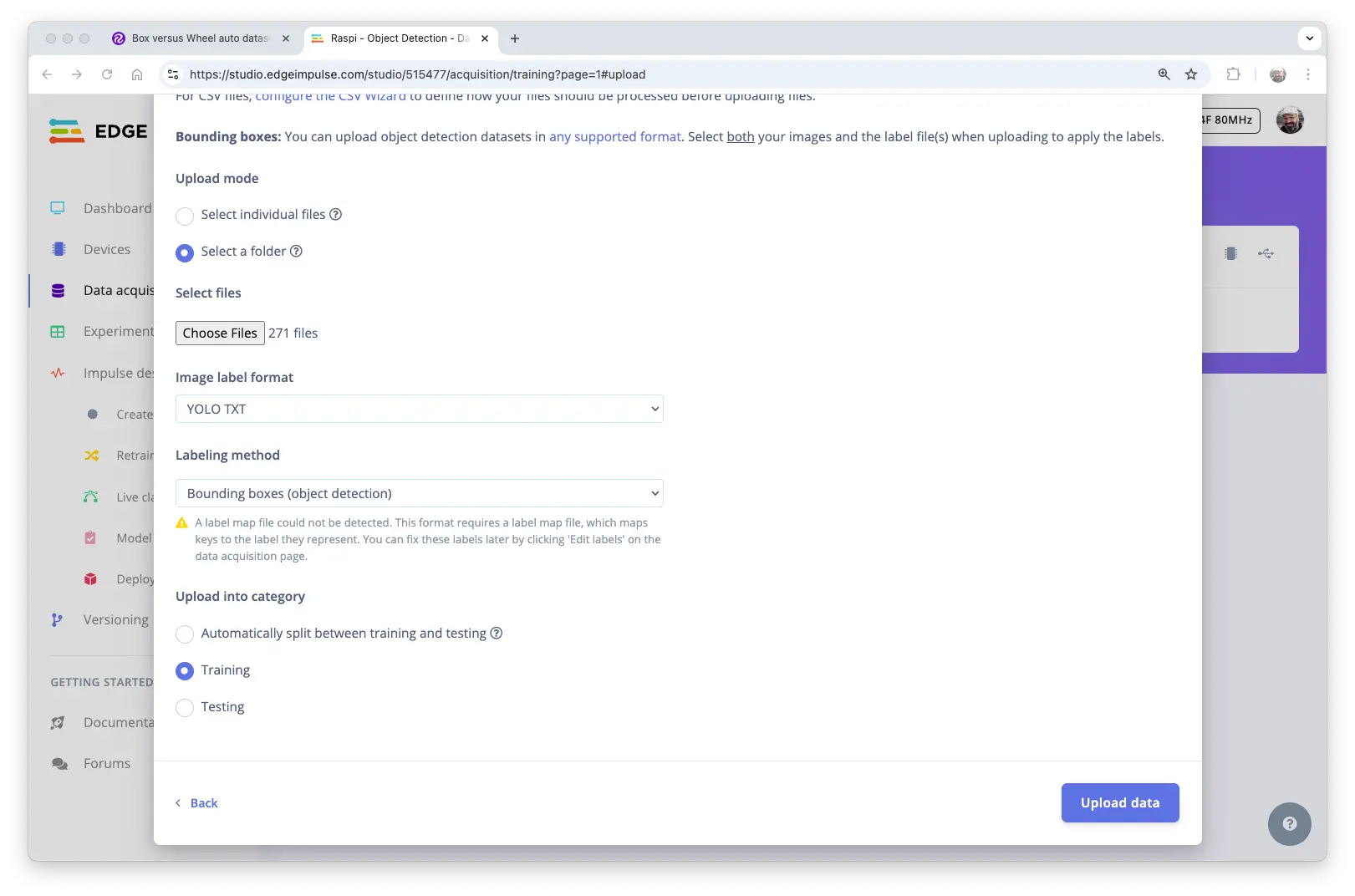
同理上传 test 和 valid 数据。最终数据集共 153 张图片,训练/测试比例约 84%/16%。
标签文件中
0、1分别对应box和wheel。
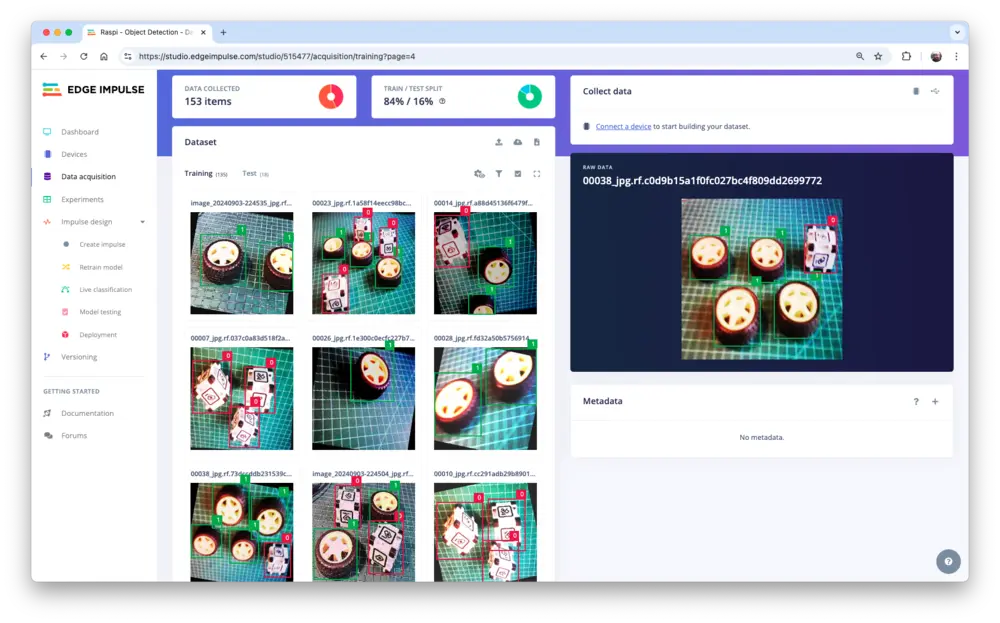
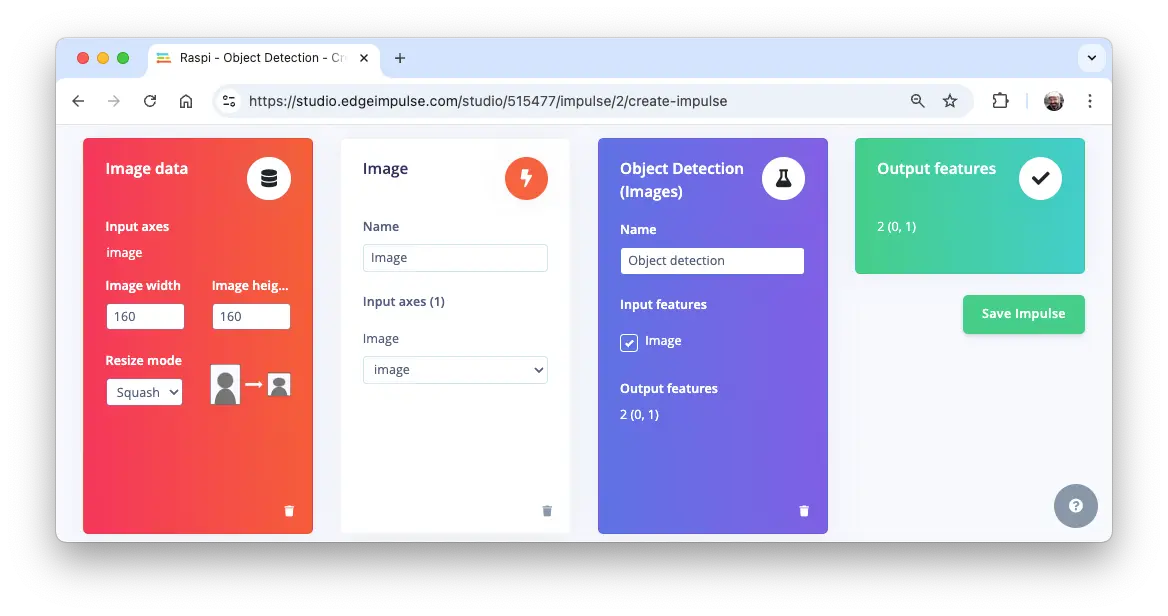
Impulse 设计
进入 Create impulse 步骤,首先选择部署目标设备。弹窗中选择 Raspberry 4(介于 Raspi-Zero 与 Raspi-5 之间)。
该选择仅影响延迟估算,不影响训练。
本阶段需定义:
- 预处理:图片已在 Roboflow 预处理为
320x320,无需调整。若上传非正方形图片,将自动拉伸为正方形。 - 模型设计:选择 “Object Detection”。
数据集预处理
在 Image 区域,选择 Color depth 为 RGB,点击 Save parameters。
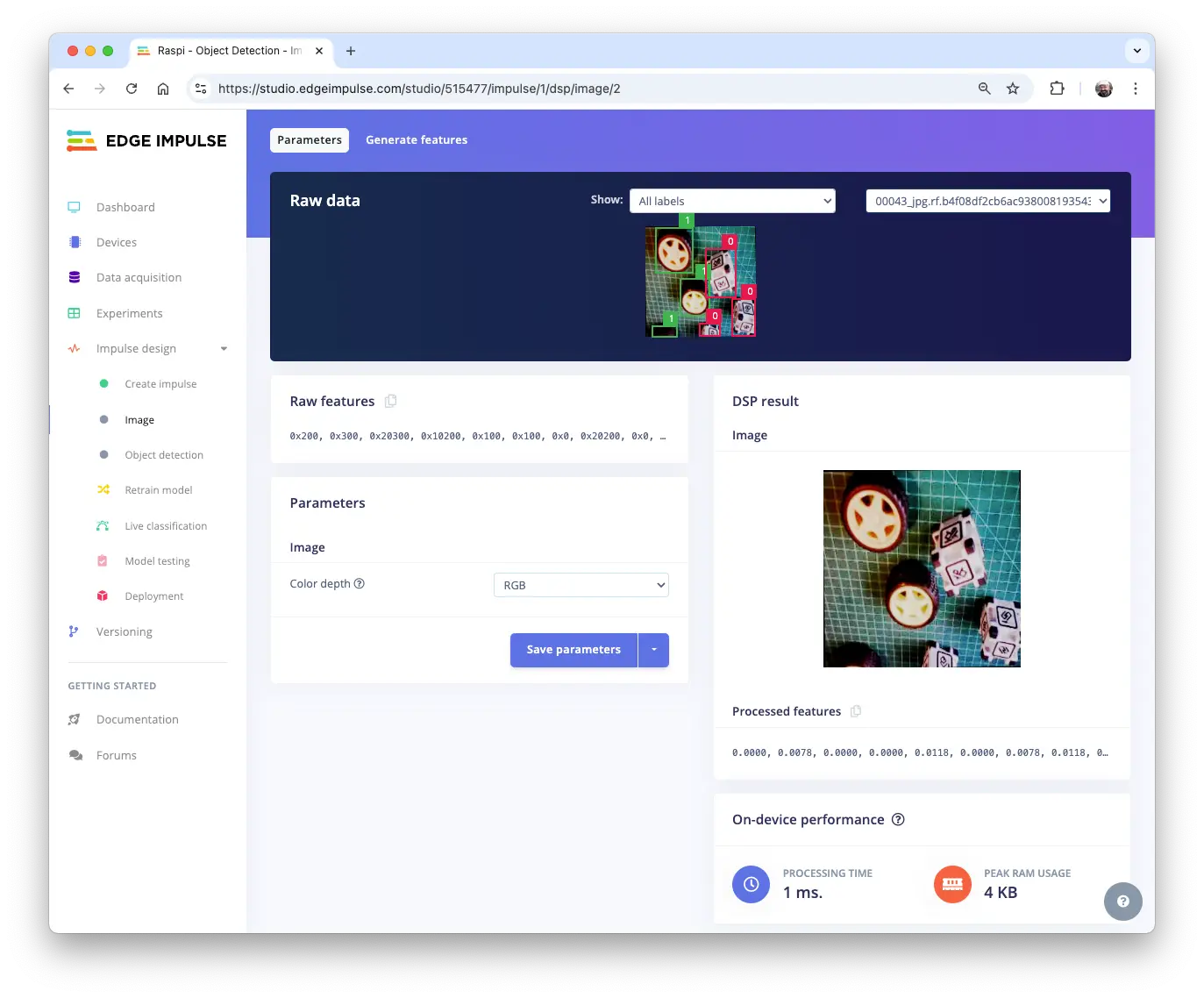
自动进入 Generate features,所有样本预处理后共 480 个对象:207 个 box,273 个 wheel。
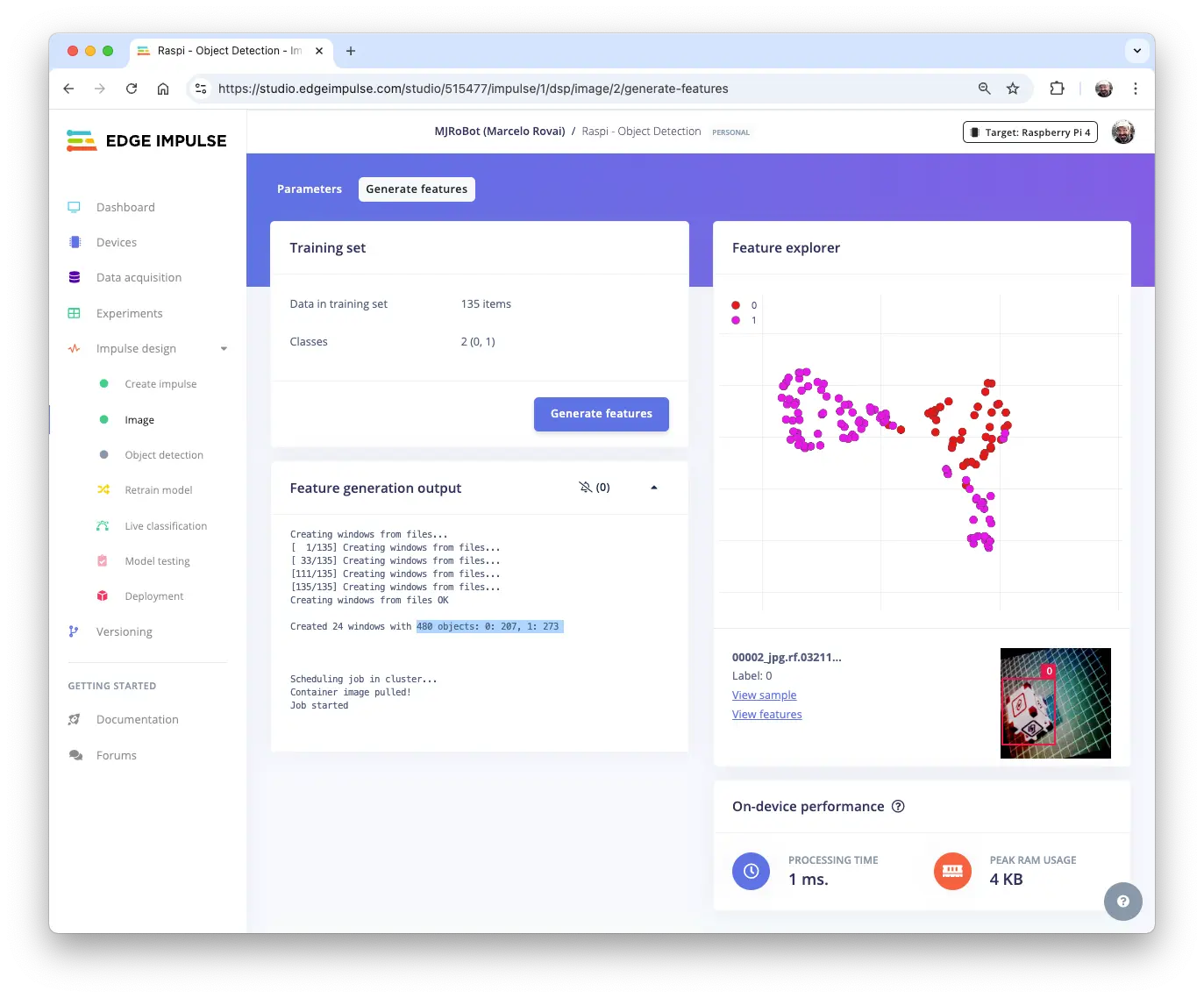
特征可视化显示样本分布良好。
模型设计、训练与测试
选择预训练模型:MobileNetV2 SSD FPN-Lite (320x320 only),支持最多检测 10 个对象,模型约 3.7 MB,输入为 $320\times 320$ RGB。
训练超参数:
- 轮数(Epochs):25
- 批量大小(Batch size):32
- 学习率(Learning Rate):0.15
训练时 20% 数据用于验证。
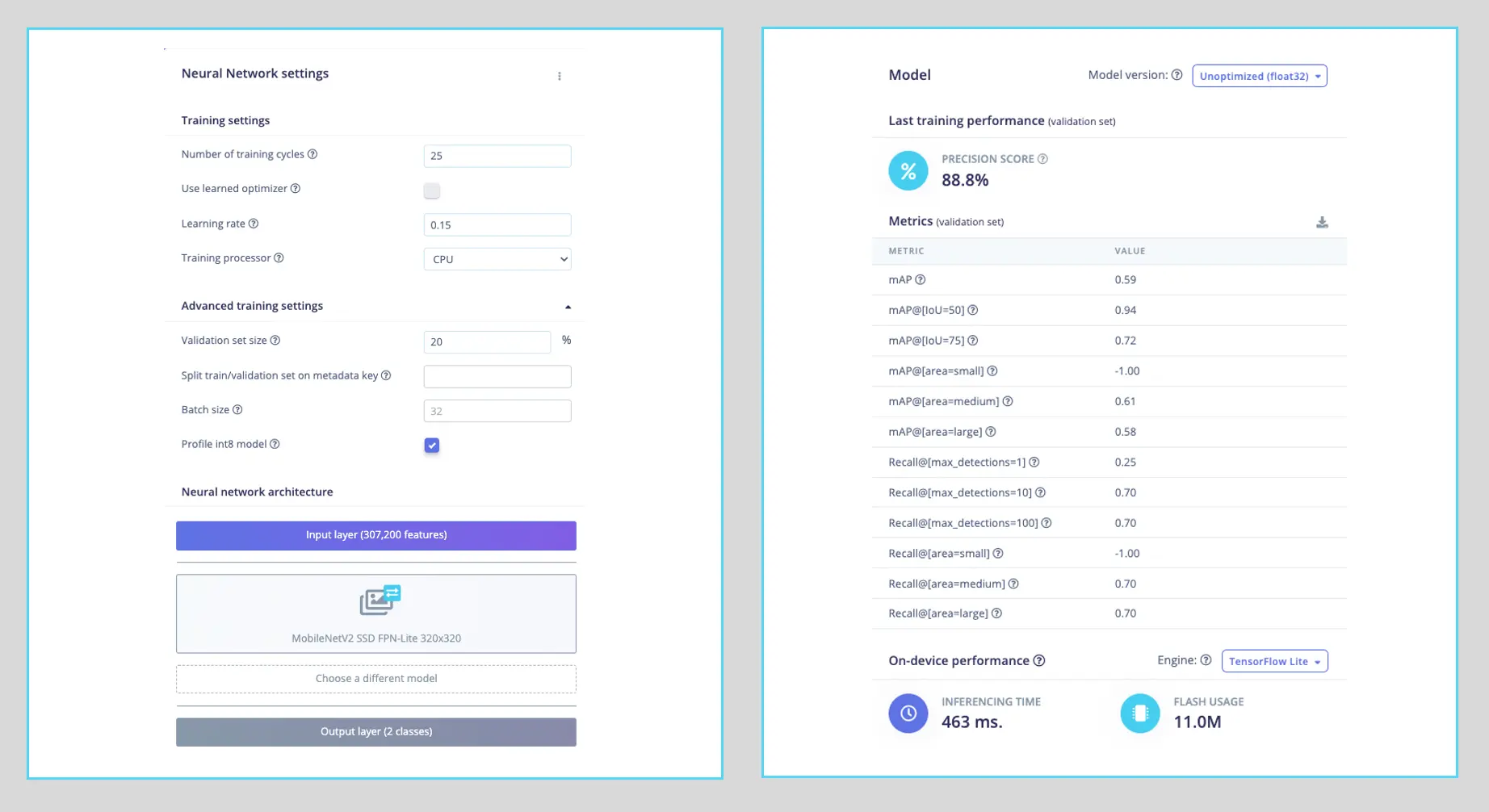
最终模型 COCO mAP 精度 88.8%,测试集精度 83.3%。
部署模型
两种部署方式:
- TFLite 模型:导出
.tflite,Raspi 可用 Python 推理 - Linux (AARCH64):导出 Linux 可执行文件,支持 Python SDK
选择 TFLite 模型,在 Dashboard 页下载 Transfer learning model (int8 quantized):
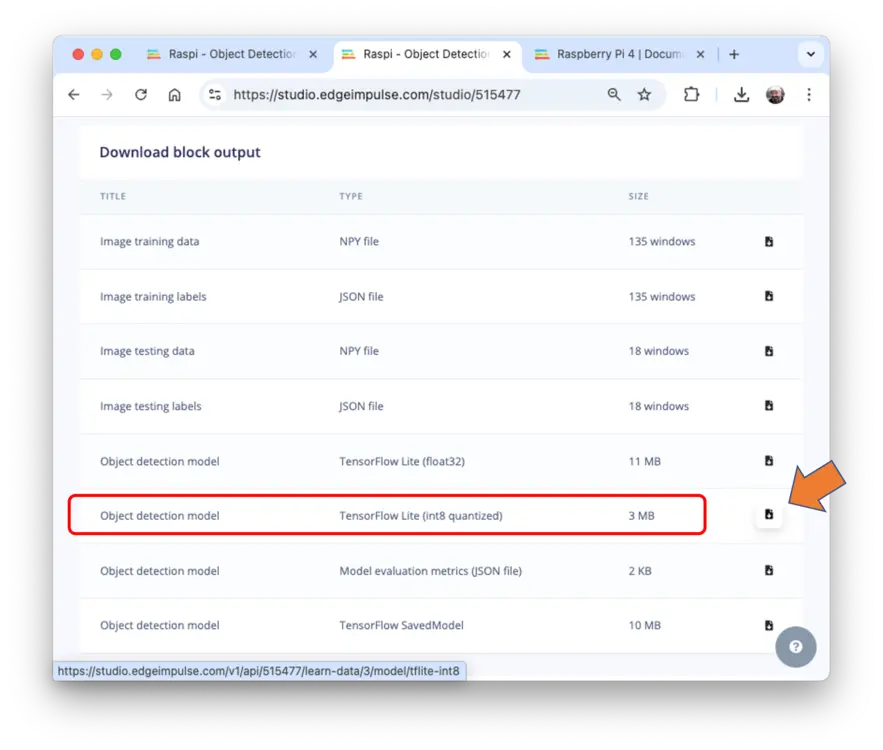
将模型传至 Raspi ./models,采集或准备图片至 ./images。
推理与后处理
推理流程同“预训练目标检测模型”章节。新建 notebook 实现检测。
导入库:
import time
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
import tflite_runtime.interpreter as tflite
定义模型路径与标签:
model_path = "./models/ei-raspi-object-detection-SSD-\
MobileNetv2-320x0320-int8.lite"
labels = ["box", "wheel"]
模型输出类别 ID(0、1),按类别字母顺序排列。
加载模型、分配张量、获取输入输出信息:
# 加载 TFLite 模型
interpreter = tflite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
# 获取输入输出张量
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
注意输入类型为 int8,需归一化处理:
input_dtype = input_details[0]["dtype"]
input_dtype
numpy.int8
加载并显示图片:
# 加载图片
img_path = "./images/box_2_wheel_2.jpg"
orig_img = Image.open(img_path)
# 显示图片
plt.figure(figsize=(6, 6))
plt.imshow(orig_img)
plt.title("原始图片")
plt.show()

预处理图片:
scale, zero_point = input_details[0]["quantization"]
img = orig_img.resize(
(input_details[0]["shape"][1], input_details[0]["shape"][2])
)
img_array = np.array(img, dtype=np.float32) / 255.0
img_array = (
(img_array / scale + zero_point).clip(-128, 127).astype(np.int8)
)
input_data = np.expand_dims(img_array, axis=0)
检查输入数据:
input_data.shape, input_data.dtype
((1, 320, 320, 3), dtype('int8'))
推理并计时:
# Raspi-Zero 上推理
start_time = time.time()
interpreter.set_tensor(input_details[0]["index"], input_data)
interpreter.invoke()
end_time = time.time()
inference_time = (
end_time - start_time
) * 1000 # 毫秒
print("推理时间:{:.1f}ms".format(inference_time))
Raspi-Zero 上约 600ms,Raspi-5 更快。
获取输出:
boxes = interpreter.get_tensor(output_details[1]["index"])[0]
classes = interpreter.get_tensor(output_details[3]["index"])[0]
scores = interpreter.get_tensor(output_details[0]["index"])[0]
num_detections = int(
interpreter.get_tensor(output_details[2]["index"])[0]
)
输出检测结果:
for i in range(num_detections):
if scores[i] > 0.5:
print(f"Object {i}:")
print(f" Bounding Box: {boxes[i]}")
print(f" Confidence: {scores[i]}")
print(f" Class: {classes[i]}")

可视化检测结果(阈值 0.5):
threshold = 0.5
plt.figure(figsize=(6, 6))
plt.imshow(orig_img)
for i in range(num_detections):
if scores[i] > threshold:
ymin, xmin, ymax, xmax = boxes[i]
(left, right, top, bottom) = (
xmin * orig_img.width,
xmax * orig_img.width,
ymin * orig_img.height,
ymax * orig_img.height,
)
rect = plt.Rectangle(
(left, top),
right - left,
bottom - top,
fill=False,
color="red",
linewidth=2,
)
plt.gca().add_patch(rect)
class_id = int(classes[i])
class_name = labels[class_id]
plt.text(
left,
top - 10,
f"{class_name}: {scores[i]:.2f}",
color="red",
fontsize=12,
backgroundcolor="white",
)
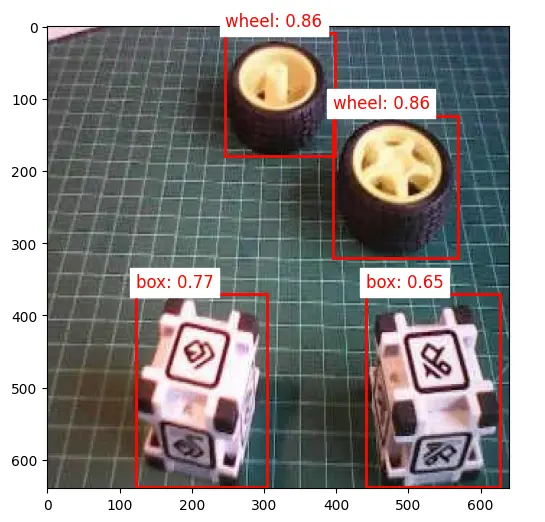
降低阈值至 0.3:
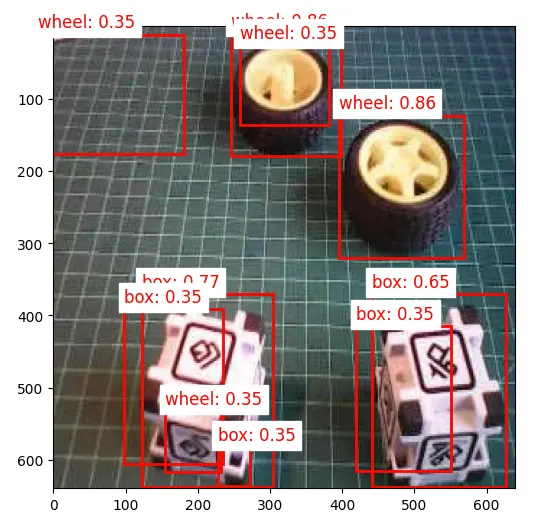
此时出现误检和多重检测(同一对象被多次检测)。
为提升检测效果,可实现 非极大值抑制(NMS),去除重叠框,仅保留置信度最高的检测。
定义 non_max_suppression() 函数:
def non_max_suppression(boxes, scores, threshold):
# Convert to corner coordinates
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= threshold)[0]
order = order[inds + 1]
return keep
函数说明略。
定义可视化函数,结合 IoU 阈值,仅显示 NMS 后目标:
def visualize_detections(
image, boxes, classes, scores, labels, threshold, iou_threshold
):
if isinstance(image, Image.Image):
image_np = np.array(image)
else:
image_np = image
height, width = image_np.shape[:2]
# Convert normalized coordinates to pixel coordinates
boxes_pixel = boxes * np.array([height, width, height, width])
# Apply NMS
keep = non_max_suppression(boxes_pixel, scores, iou_threshold)
# Set the figure size to 12x8 inches
fig, ax = plt.subplots(1, figsize=(12, 8))
ax.imshow(image_np)
for i in keep:
if scores[i] > threshold:
ymin, xmin, ymax, xmax = boxes[i]
rect = patches.Rectangle(
(xmin * width, ymin * height),
(xmax - xmin) * width,
(ymax - ymin) * height,
linewidth=2,
edgecolor="r",
facecolor="none",
)
ax.add_patch(rect)
class_name = labels[int(classes[i])]
ax.text(
xmin * width,
ymin * height - 10,
f"{class_name}: {scores[i]:.2f}",
color="red",
fontsize=12,
backgroundcolor="white",
)
plt.show()
定义推理主函数:
def detect_objects(img_path, conf=0.5, iou=0.5):
orig_img = Image.open(img_path)
scale, zero_point = input_details[0]["quantization"]
img = orig_img.resize(
(input_details[0]["shape"][1], input_details[0]["shape"][2])
)
img_array = np.array(img, dtype=np.float32) / 255.0
img_array = (
(img_array / scale + zero_point)
.clip(-128, 127)
.astype(np.int8)
)
input_data = np.expand_dims(img_array, axis=0)
# Raspi-Zero 上推理
start_time = time.time()
interpreter.set_tensor(input_details[0]["index"], input_data)
interpreter.invoke()
end_time = time.time()
inference_time = (
end_time - start_time
) * 1000 # 毫秒
print("推理时间:{:.1f}ms".format(inference_time))
# 提取输出
boxes = interpreter.get_tensor(output_details[1]["index"])[0]
classes = interpreter.get_tensor(output_details[3]["index"])[0]
scores = interpreter.get_tensor(output_details[0]["index"])[0]
num_detections = int(
interpreter.get_tensor(output_details[2]["index"])[0]
)
visualize_detections(
orig_img,
boxes,
classes,
scores,
labels,
threshold=conf,
iou_threshold=iou,
)
调用示例:
img_path = "./images/box_2_wheel_2.jpg"
detect_objects(img_path, conf=0.3, iou=0.05)

在 Edge Impulse Studio 训练 FOMO 模型
虽然 SSD MobileNet 模型的推理效果不错,但在 Raspi-Zero 上延迟较高,推理时间在 0.5 到 1.3 秒之间,约等于或低于 1 帧每秒(FPS)。为提升速度,可以采用 FOMO(Faster Objects, More Objects)算法。
FOMO 是一种新型机器学习算法,可在实时场景下计数多个目标并定位其在图片中的位置,所需算力和内存仅为 MobileNet SSD 或 YOLO 的 $1/30$。其核心在于,传统模型通过边界框标注目标大小,而 FOMO 只关注目标的中心点坐标,忽略目标尺寸,从而极大提升效率。
FOMO 的工作原理
在典型的目标检测流程中,第一步是从输入图片中提取特征。FOMO 利用 MobileNetV2 完成特征提取,高效捕捉纹理、形状和边缘等关键信息。
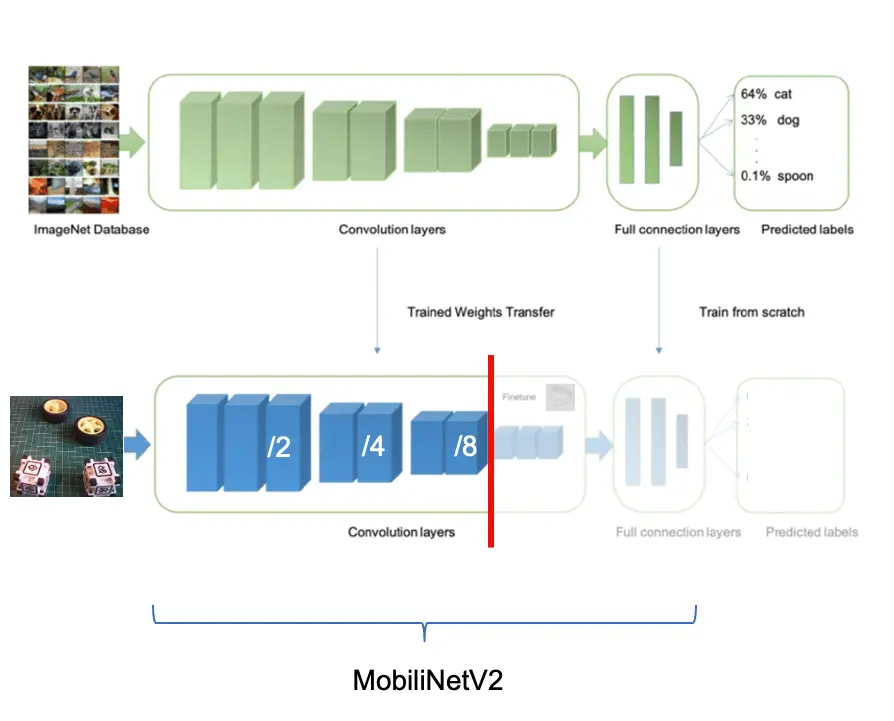
特征提取后,FOMO 采用简化的中心点检测架构,将特征图划分为网格,每个单元格判断是否存在目标中心点。模型为每个单元格输出置信度,表示该区域存在目标的概率。
以 $96\times 96$ 输入为例,FOMO 将图片划分为 $12\times 12$ 网格($96/8=12$);$160\times 160$ 输入则为 $20\times 20$ 网格。FOMO 对每个像素块进行分类,判断是否包含 box 或 wheel,并确定概率最高的区域。若某块无目标,则归为 background。最终,FOMO 输出每个目标中心点的坐标(归一化到图片尺寸)。
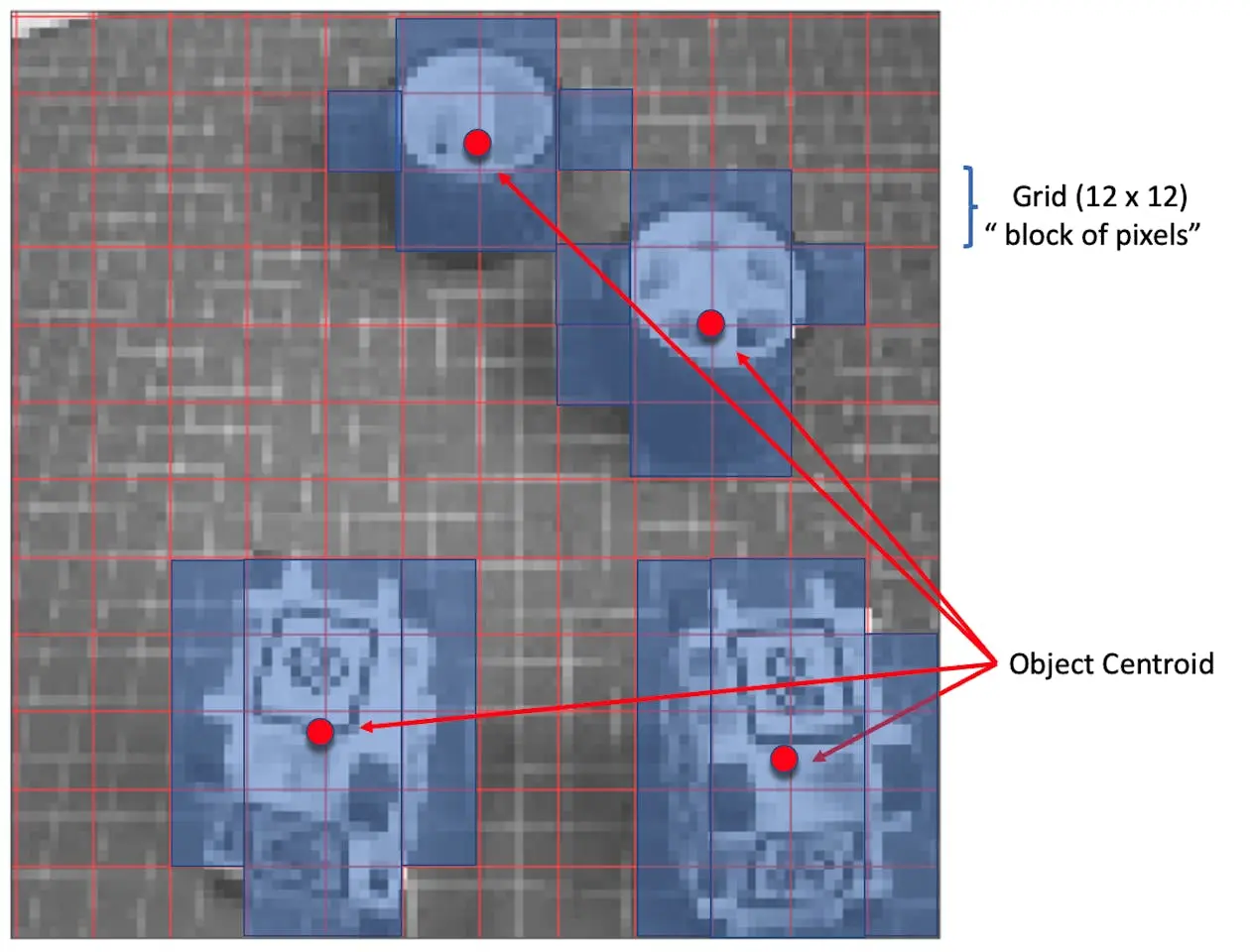
速度与精度的权衡:
- 网格分辨率:FOMO 使用固定分辨率网格,每个单元格独立检测目标中心,牺牲部分定位精度以换取极高速度,非常适合边缘设备。
- 多目标检测:各单元格独立,FOMO 可同时检测多目标。
Impulse 设计、训练与测试
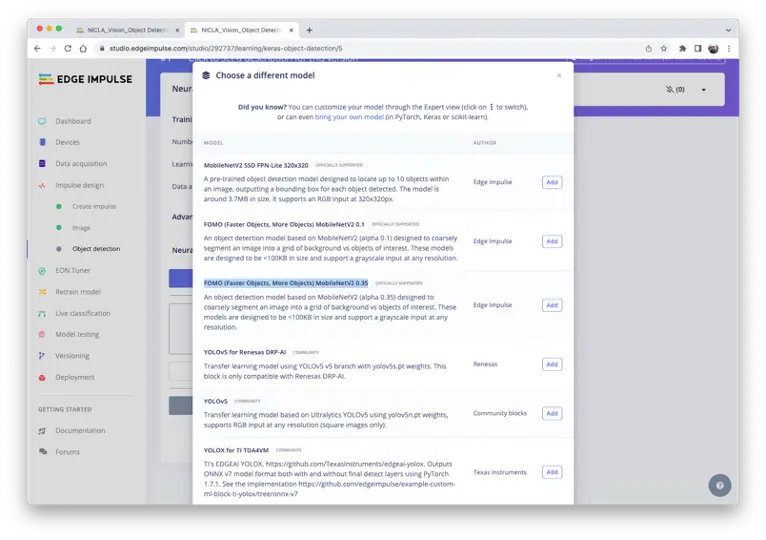
回到 Edge Impulse Studio,在 Experiments 标签页新建 impulse,输入图片尺寸设为 $160\times 160$(MobileNetV2 推荐输入)。
在 Image 标签页生成特征后,进入 Object detection 标签。
选择预训练模型:FOMO (Faster Objects, More Objects) MobileNetV2 0.35。
训练超参数如下:
- 轮数(Epochs):30
- 批量大小(Batch size):32
- 学习率(Learning Rate):0.001
训练时 20% 数据用于验证。由于数据集在 Roboflow 标注阶段已增强,训练集(80%)无需再做数据增强。
最终模型 F1 分数达 93.3%,在 Raspi-4 上推理延迟仅 8 毫秒,比 SSD MobileNetV2 快约 $60$ 倍。
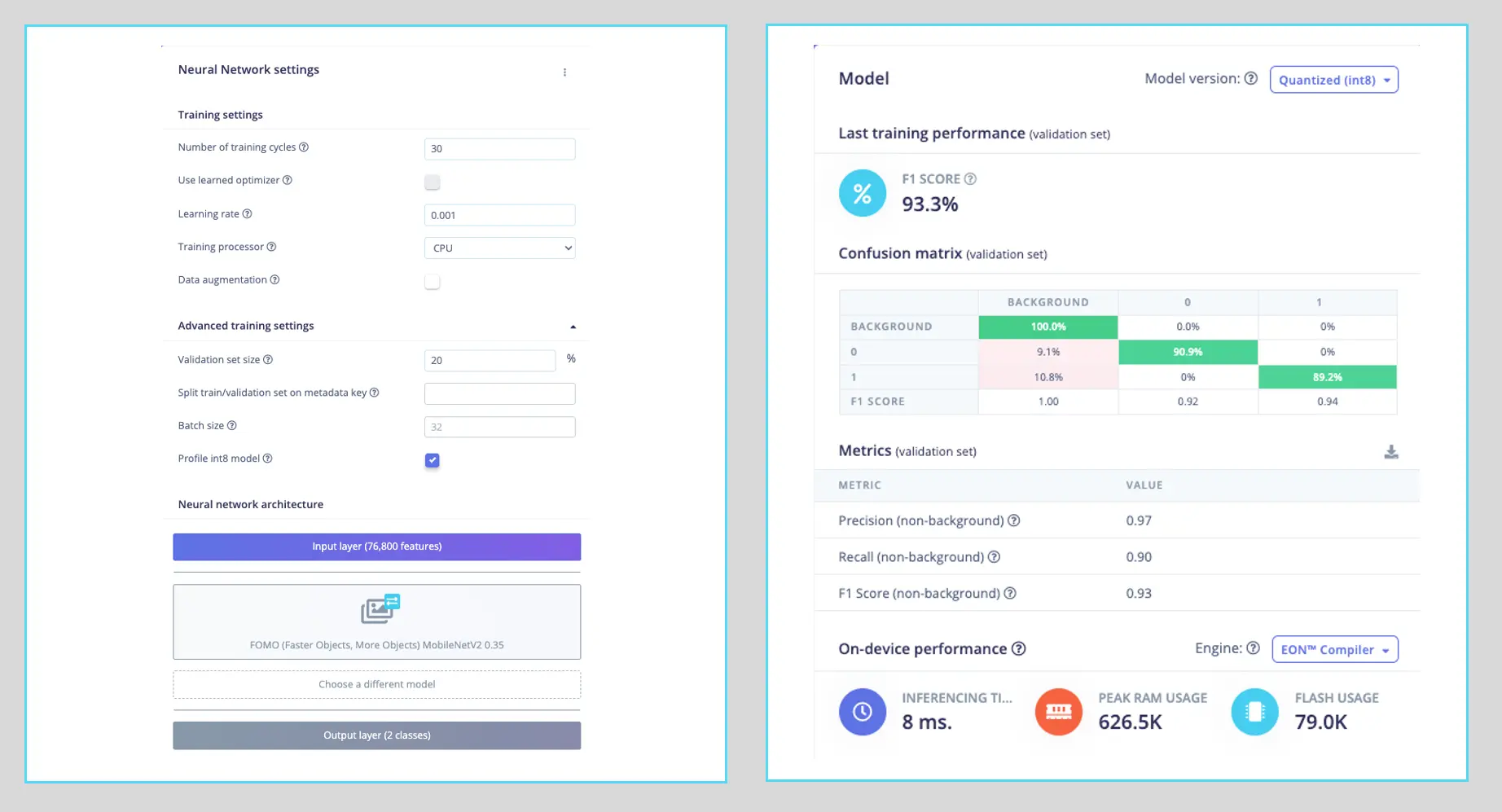
注意,FOMO 会自动为原有的 box(0)和 wheel(1)类别添加第三类 background。
在 Model testing 标签页可见模型准确率为 94%。下图为测试样例:

目标检测任务中,准确率并非主要 评估指标 。FOMO 只输出中心点而非边界框,单纯用准确率衡量模型表现并不全面。
部署模型
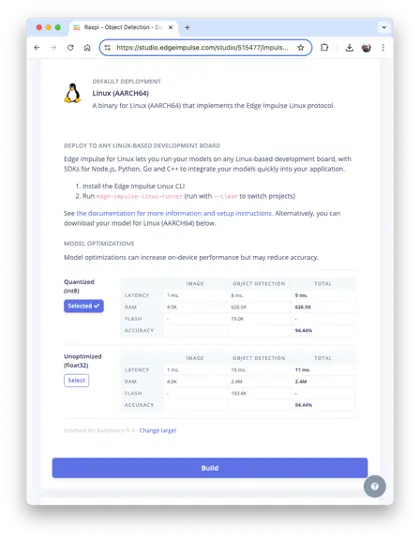
如前所述,训练好的模型可导出为 TFLite 或 Linux (AARCH64) 格式。此处选择 Linux (AARCH64),即 Edge Impulse Linux 协议的可执行文件。
Edge Impulse for Linux 模型以 .eim 格式交付,
可执行文件
包含完整 impulse(信号处理、学习与异常检测模块),针对处理器或 GPU 优化(如 ARM NEON),并内置简易 IPC 层。
在 Deploy 标签页选择 Linux (AARCH64),选择 int8 模型并点击 Build。
模型将自动下载至本地。
在 Raspi 上新建工作目录:
cd ~
cd Documents
mkdir EI_Linux
cd EI_Linux
mkdir models
mkdir images
重命名模型便于识别,如 raspi-object-detection-linux-aarch64-FOMO-int8.eim,并传至 ./models,采集或准备图片至 ./images。
推理与后处理
推理采用 Linux Python SDK 。该库支持在 Linux 设备上用 Python 运行模型与采集数据,开源地址: edgeimpulse/linux-sdk-python 。
创建虚拟环境:
python3 -m venv ~/eilinux
source ~/eilinux/bin/activate
安装依赖库:
sudo apt-get update
sudo apt-get install libatlas-base-dev libportaudio0 libportaudio2
sudo apt-get install libportaudiocpp0 portaudio19-dev
pip3 install edge_impulse_linux -i https://pypi.python.org/simple
pip3 install Pillow matplotlib pyaudio opencv-contrib-python
sudo apt-get install portaudio19-dev
pip3 install pyaudio
pip3 install opencv-contrib-python
赋予模型可执行权限:
chmod +x raspi-object-detection-linux-aarch64-FOMO-int8.eim
安装 Jupyter Notebook:
pip3 install jupyter
本地启动 notebook(Raspi-4/5 桌面环境):
jupyter notebook
或在电脑浏览器远程访问:
jupyter notebook --ip=192.168.4.210 --no-browser
新建 notebook ,按步骤用 FOMO 模型检测图片中的 box 和 wheel。
导入库:
import sys, time
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
import cv2
from edge_impulse_linux.image import ImageImpulseRunner
定义模型路径与标签:
model_file = "raspi-object-detection-linux-aarch64-int8.eim"
model_path = "models/" + model_file # Edge Impulse 训练模型
labels = ["box", "wheel"]
模型输出类别 ID(0、1),按字母顺序排列。
加载并初始化模型:
# 加载模型文件
runner = ImageImpulseRunner(model_path)
# 初始化模型
model_info = runner.init()
model_info 包含模型关键信息。与 TFLite 不同,EI Linux Python SDK 会自动准备模型推理。
加载并显示图片(需用 OpenCV 读取并转为 RGB):
# 加载图片
img_path = "./images/1_box_1_wheel.jpg"
orig_img = cv2.imread(img_path)
img_rgb = cv2.cvtColor(orig_img, cv2.COLOR_BGR2RGB)
# 显示图片
plt.imshow(img_rgb)
plt.title("原始图片")
plt.show()

用 runner 获取特征与预处理图片(cropped):
features, cropped = (
runner.get_features_from_image_auto_studio_settings(img_rgb)
)
推理并计时:
res = runner.classify(features)
输出检测到的类别、中心点坐标及置信度:
print(
"Found %d bounding boxes (%d ms.)"
% (
len(res["result"]["bounding_boxes"]),
res["timing"]["dsp"] + res["timing"]["classification"],
)
)
for bb in res["result"]["bounding_boxes"]:
print(
"\t%s (%.2f): x=%d y=%d w=%d h=%d"
% (
bb["label"],
bb["value"],
bb["x"],
bb["y"],
bb["width"],
bb["height"],
)
)
Found 2 bounding boxes (29 ms.)
1 (0.91): x=112 y=40 w=16 h=16
0 (0.75): x=48 y=56 w=8 h=8
结果显示检测到两个目标:类别 0(box)和类别 1(wheel),均正确。
可视化检测结果(默认阈值 0.5):
print(
"\tFound %d bounding boxes (latency: %d ms)"
% (
len(res["result"]["bounding_boxes"]),
res["timing"]["dsp"] + res["timing"]["classification"],
)
)
plt.figure(figsize=(5, 5))
plt.imshow(cropped)
# 遍历所有检测框
bboxes = res["result"]["bounding_boxes"]
for bbox in bboxes:
# 获取检测框中心
left = bbox["x"]
top = bbox["y"]
width = bbox["width"]
height = bbox["height"]
# 绘制中心圆
circ = plt.Circle(
(left + width // 2, top + height // 2),
5,
fill=False,
color="red",
linewidth=3,
)
plt.gca().add_patch(circ)
class_id = int(bbox["label"])
class_name = labels[class_id]
plt.text(
left,
top - 10,
f'{class_name}: {bbox["value"]:.2f}',
color="red",
fontsize=12,
backgroundcolor="white",
)
plt.show()

使用 Ultralytics 探索 YOLO 模型
本实验将带你体验 YOLOv8。 Ultralytics 的 YOLOv8 是著名实时目标检测与图像分割模型 YOLO 的一个版本。YOLOv8 基于深度学习和计算机视觉的最新进展,兼具极高的速度与精度,结构简洁,适用于从边缘设备到云 API 的多种硬件平台,易于集成和扩展。
YOLO 模型简介
YOLO(You Only Look Once)是一种高效且广泛应用的目标检测算法,以其实时处理能力著称。与传统目标检测系统通过分类器或定位器多步检测不同,YOLO 将检测问题视为单一回归任务。该创新方法使 YOLO 能够在一次前向推理中同时预测多组边界框及其类别概率,大幅提升了检测速度。
主要特性
单网络架构:
- YOLO 采用单一神经网络处理整张图片,将图片划分为网格,每个网格单元直接预测边界框及类别概率。端到端训练提升了速度并简化了模型结构。
实时处理能力:
- YOLO 最大亮点之一是实时目标检测能力。根据不同版本和硬件,YOLO 可实现高帧率(FPS)处理,非常适合视频监控、自动驾驶、体育赛事分析等对速度和准确性要求极高的场景。
版本演进:
- YOLO 从 v1 发展到最新的 v10,每一代都在精度、速度和效率上持续优化。YOLOv8 引入了更优的网络结构、训练方法和硬件适配,性能更强。
- 虽然 YOLOv10 是家族最新成员,论文表现优异,但截至 2024 年 5 月尚未完全集成进 Ultralytics 库。根据精度 - 召回曲线分析,YOLOv8 通常优于 YOLOv9,能更好地捕获真阳性并减少误报(详见 相关分析 )。因此本实验以 YOLOv8n 为基础。
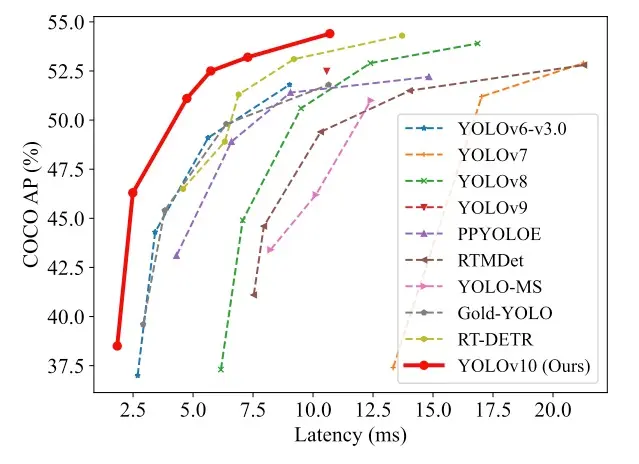
图 41: YOLO 版本演进示意图
精度与效率兼备:
- 早期 YOLO 以速度换取部分精度,近年版本在两者间取得更好平衡。新模型不仅更快,还能检测小目标(如蜜蜂),在复杂数据集上表现优异。
广泛应用场景:
- YOLO 的通用性使其在交通监控、安防、农业等领域广泛应用,如车辆计数、威胁识别、农作物与牲畜监测等,几乎适用于所有需高效目标检测的场景。
活跃社区与持续开发:
- YOLO 拥有强大的开发者和研究者社区(YOLOv8 社区尤为活跃)。开源实现和丰富文档便于定制和集成。主流深度学习框架如 Darknet、TensorFlow、PyTorch 均支持 YOLO,极大拓展了其适用范围。
- Ultralytics YOLOv8 不仅支持 检测 (本实验重点),还支持 分割 、 姿态估计 (基于 COCO 数据集预训练),以及 分类 (基于 ImageNet 预训练)。 跟踪 模式适用于所有检测、分割和姿态模型。

图 42: Ultralytics YOLO 支持的任务类型
安装步骤
在树莓派上,先退出当前环境,创建新的工作目录:
deactivate
cd ~
cd Documents/
mkdir YOLO
cd YOLO
mkdir models
mkdir images
为 Ultralytics YOLOv8 创建虚拟环境:
python3 -m venv ~/yolo
source ~/yolo/bin/activate
安装 Ultralytics 及其本地推理依赖:
更新软件包列表,安装 pip 并升级:
sudo apt update sudo apt install python3-pip -y pip install -U pip安装带可选依赖的
ultralytics包:pip install ultralytics[export]重启设备:
sudo reboot
YOLO 测试
树莓派重启后,激活 yolo 环境,进入工作目录:
source ~/yolo/bin/activate
cd /Documents/YOLO
使用 YOLOv8n(家族中最小模型)在终端运行推理,自动下载测试图片:
yolo predict model='yolov8n' \
source='https://ultralytics.com/images/bus.jpg'
YOLO 模型家族均基于 COCO 数据集预训练。
推理结果会在终端显示。以 bus.jpg 为例,检测到 4 个 person,1 个 bus 和 1 个 stop signal:
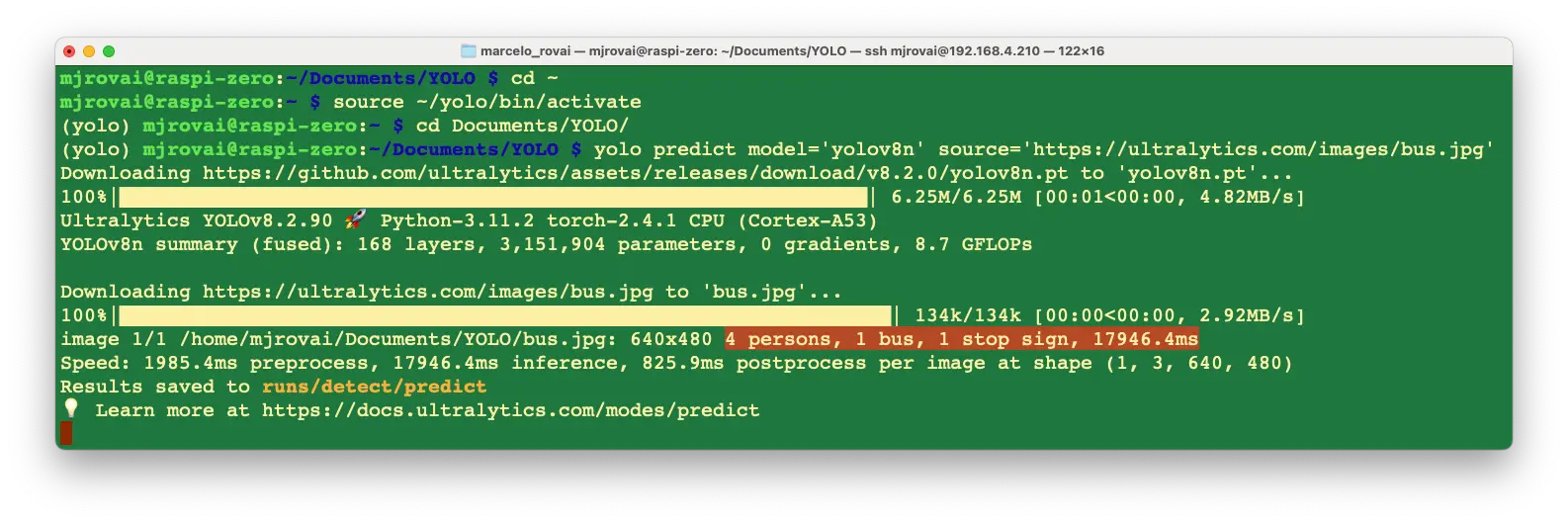
同时会提示 Results saved to runs/detect/predict。在该目录下可找到保存的图片(bus.jpg),可通过 FTP 下载到桌面查看:
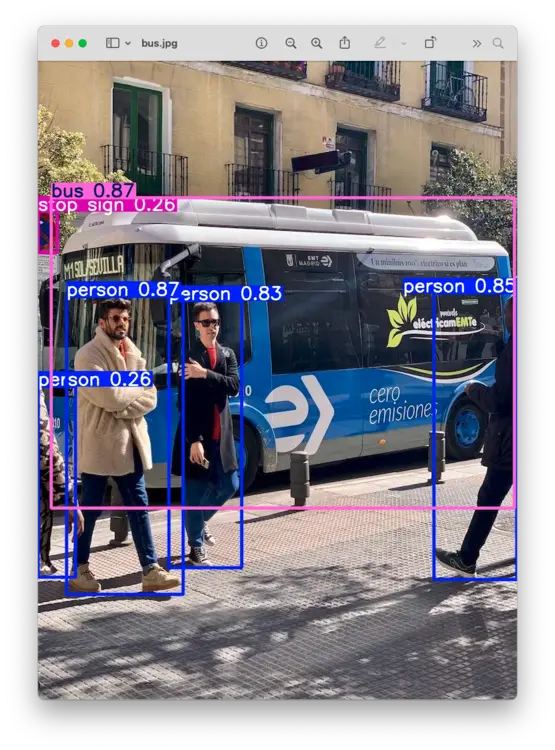
说明 Ultralytics YOLO 已在树莓派上正确安装。但在 Raspi-Zero 上,即使使用最小模型 YOLOv8n,单次推理延迟约 18 秒,速度较慢。
导出模型为 NCNN 格式
在算力有限的边缘设备(如 Raspi-Zero)上部署视觉模型时,延迟是常见问题。可通过导出为高性能格式优化推理速度。
Ultralytics 支持多种导出格式,其中 NCNN 是专为移动端优化的高性能神经网络推理框架,无第三方依赖,跨平台,推理速度优于 TFLite 等主流开源框架。
在树莓派等 ARM 架构设备上,NCNN 推理速度表现最佳。
模型转换及推理流程如下:
将 YOLOv8n PyTorch 模型导出为 NCNN 格式,生成
/yolov8n_ncnn_model:yolo export model=yolov8n.pt format=ncnn使用导出的模型进行推理(此时可直接用本地 bus.jpg 图片):
yolo predict model='./yolov8n_ncnn_model' source='bus.jpg'
首次加载模型推理延迟较高(约 17 秒),后续推理可降至 2 秒左右。
用 Python 交互式探索 YOLO
可通过 Python 解释器逐步体验 YOLO 推理流程:
python3
导入 Ultralytics YOLO 库并加载模型:
from ultralytics import YOLO
model = YOLO("yolov8n_ncnn_model")
对图片进行推理(以 bus.jpg 为例):
img = "bus.jpg"
result = model.predict(img, save=True, imgsz=640, conf=0.5, iou=0.3)
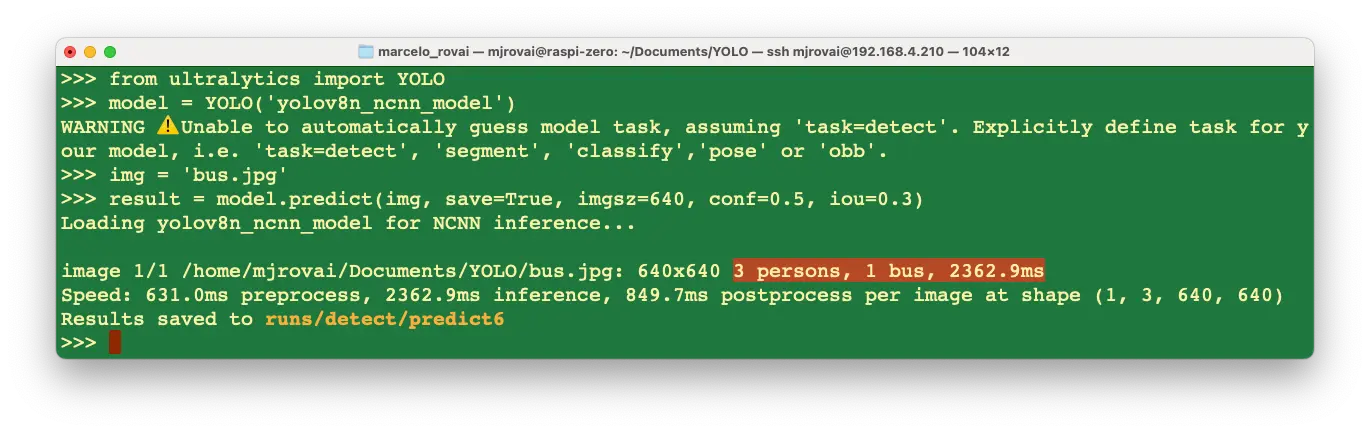
结果与命令行推理基本一致,但使用 NCNN 模型时可能检测不到公交站牌,且延迟更低。
进一步分析 result 内容:
例如,result[0].boxes.data 返回主推理结果,为形状 (4, 6) 的张量,每行分别为 4 个边界框坐标、第 5 列为置信度、第 6 列为类别(如 0: person,5: bus):
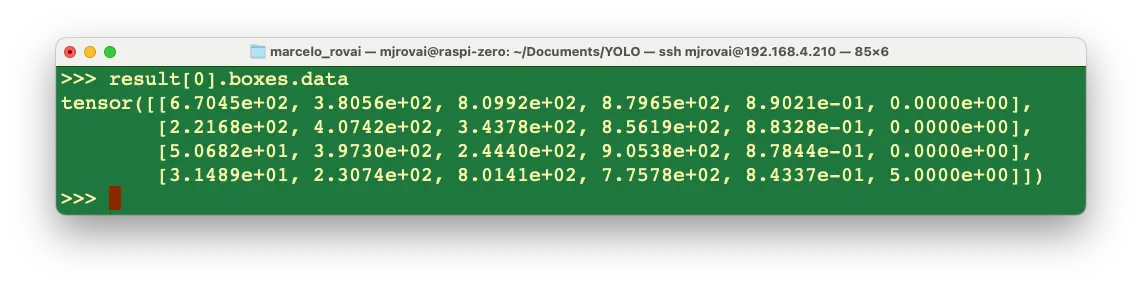
可分别获取推理时间并格式化输出:
inference_time = int(result[0].speed["inference"])
print(f"Inference Time: {inference_time} ms")
统计检测到的目标数量:
print(f"Number of objects: {len (result[0].boxes.cls)}")
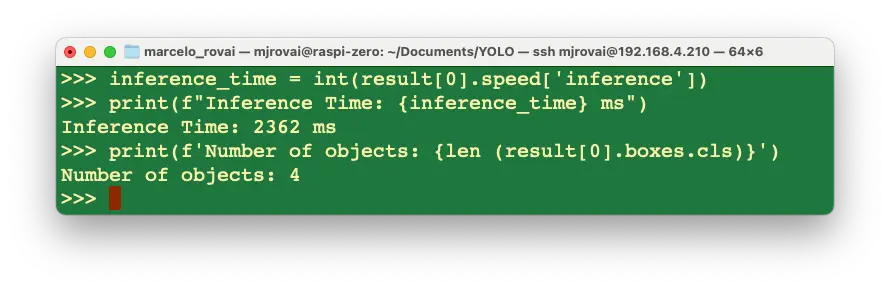
通过 Python 可灵活定制输出,详见 Ultralytics YOLO 推理文档 。
建议将上述流程写入脚本,便于复用。以 nano 编辑器新建 yolov8_tests.py:
nano yolov8_tests.py
输入如下代码:
from ultralytics import YOLO
# 加载 YOLOv8 模型
model = YOLO("yolov8n_ncnn_model")
# 推理
img = "bus.jpg"
result = model.predict(img, save=False, imgsz=640, conf=0.5, iou=0.3)
# 输出结果
inference_time = int(result[0].speed["inference"])
print(f"Inference Time: {inference_time} ms")
print(f"Number of objects: {len (result[0].boxes.cls)}")
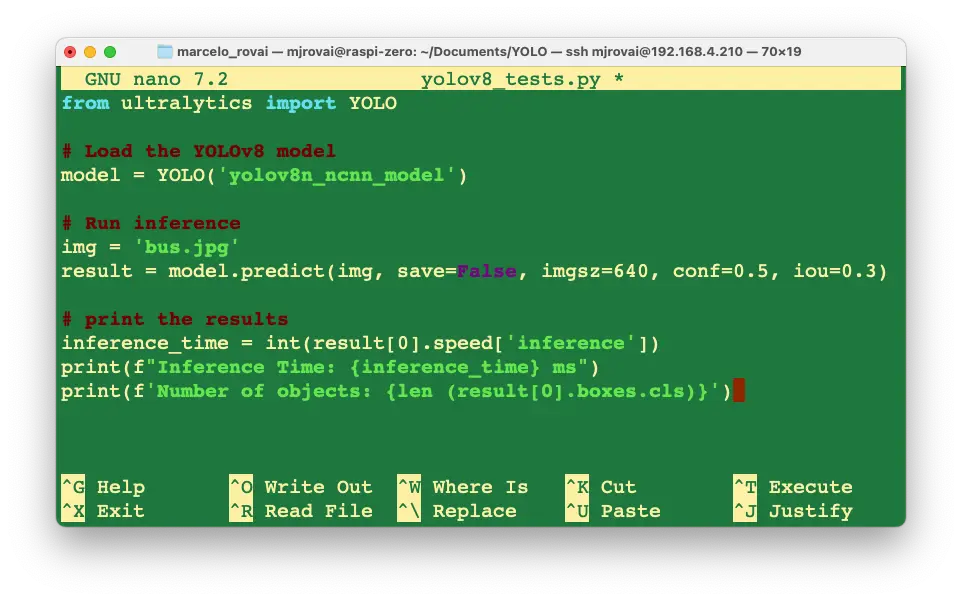
保存并退出([CTRL+O] + [ENTER] + [CTRL+X])。
运行脚本:
python yolov8_tests.py
结果与命令行和交互式推理一致。
首次加载 YOLO 库和模型推理耗时较长,后续推理速度显著提升。单次推理可由数秒降至 1 秒以内。
用自定义数据集训练 YOLOv8
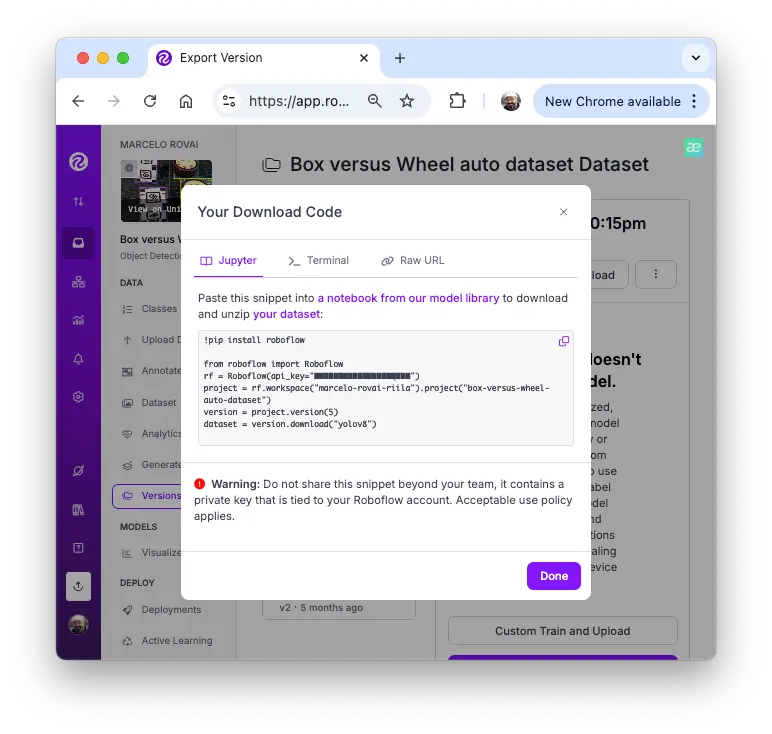
回到我们在 Roboflow 标注的“Box versus Wheel”数据集。下载数据集时,选择“Show download code”以便在训练 notebook 中直接引用。
训练建议基于 Ultralytics 官方 Colab 示例进行适配。以下为可直接使用的 Colab 链接:
- YOLOv8 Box versus Wheel 数据集训练 [Colab 在线运行]
Notebook 关键步骤
选择 GPU 运行环境(推荐 NVidia T4,免费)。
使用 PIP 安装 Ultralytics。
图 50: Ultralytics 安装截图
导入 YOLO 并上传数据集,粘贴 Roboflow 下载代码,数据集将挂载到
/content/datasets/: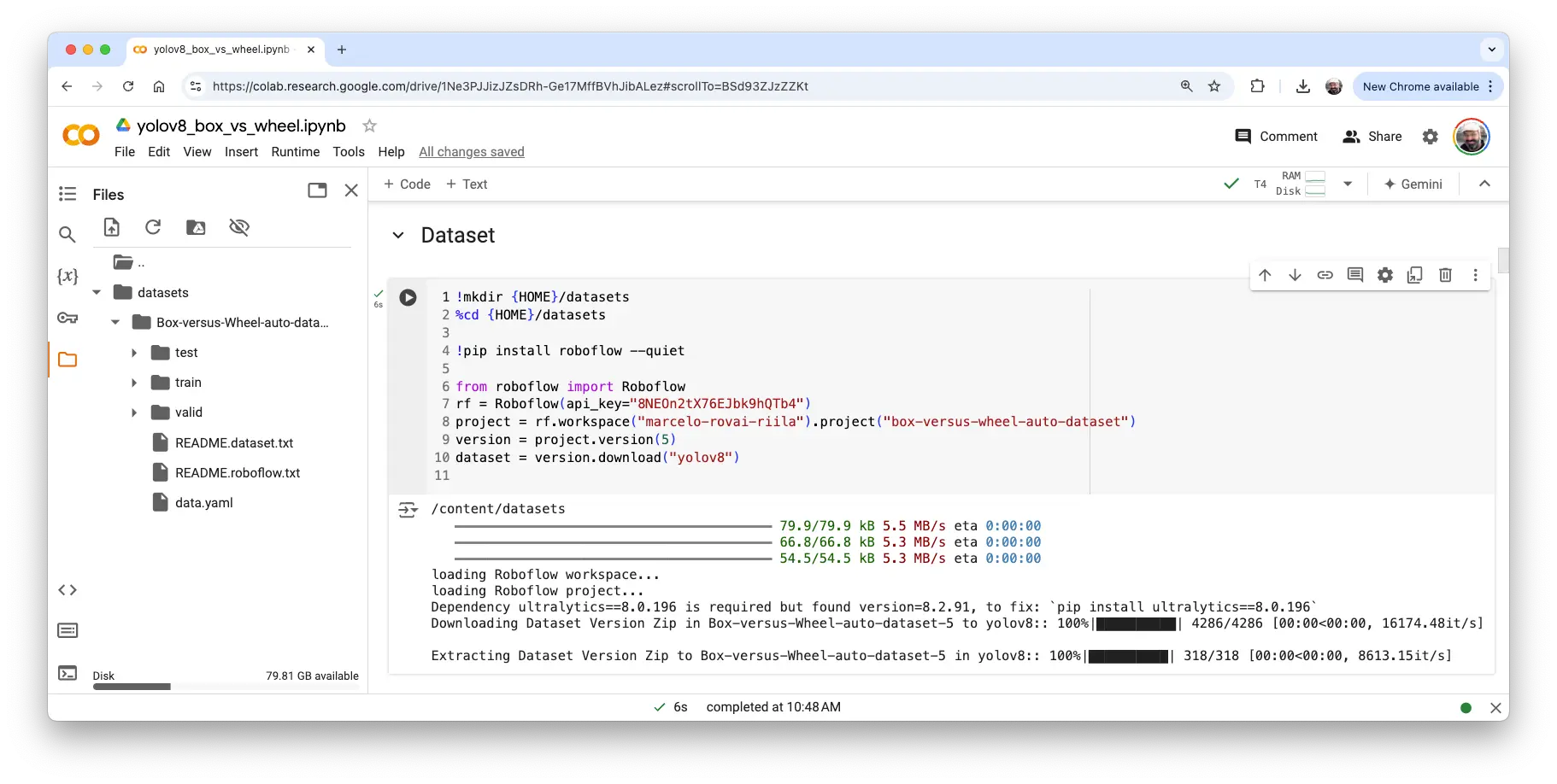
图 51: 数据集上传截图 检查并修改
data.yaml,确保图片路径正确:names: - box - wheel nc: 2 roboflow: license: CC BY 4.0 project: box-versus-wheel-auto-dataset url: https://universe.roboflow.com/marcelo-rovai-riila/ \ box-versus-wheel-auto-dataset/dataset/5 version: 5 workspace: marcelo-rovai-riila test: /content/datasets/Box-versus-Wheel-auto-dataset-5/ \ test/images train: /content/datasets/Box-versus-Wheel-auto-dataset-5/ \ train/images val: /content/datasets/Box-versus-Wheel-auto-dataset-5/ \ valid/images设置主要超参数,例如:
MODEL = 'yolov8n.pt' IMG_SIZE = 640 EPOCHS = 25 # 正式项目建议至少 100 轮运行训练(命令行方式):
!yolo task=detect mode=train model={MODEL} \ data={dataset.location}/data.yaml \ epochs={EPOCHS} imgsz={IMG_SIZE} plots=True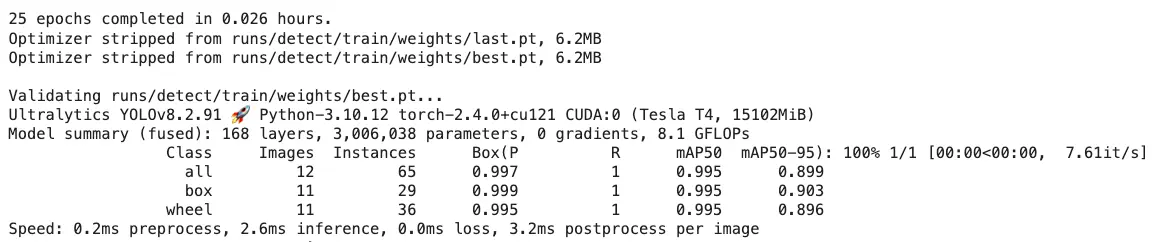
图 52: 训练结果截图 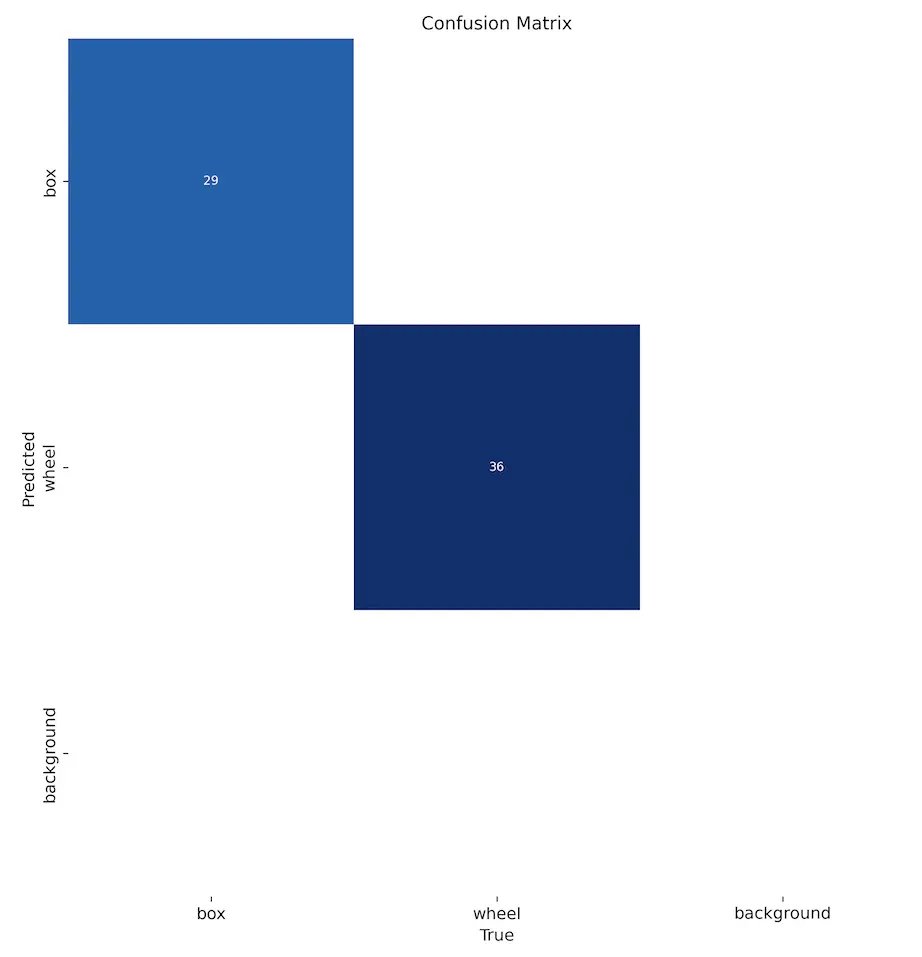
图 53: 混淆矩阵截图 训练完成后,模型(
best.pt)保存在/runs/detect/train/weights/。用验证集评估模型:!yolo task=detect mode=val model={HOME}/runs/detect/train/\ weights/best.pt data={dataset.location}/data.yaml验证结果与训练相近。
用测试集图片推理:
!yolo task=detect mode=predict model={HOME}/runs/detect/train/\ weights/best.pt conf=0.25 source={dataset.location}/test/\ images save=True推理结果保存在
runs/detect/predict文件夹。部分结果如下:
图 54: 测试集推理结果 建议将训练、验证和测试结果导出到 Google Drive。先挂载云盘:
from google.colab import drive drive.mount('/content/gdrive')然后将
/runs文件夹内容复制到 Drive 指定目录:!scp -r /content/runs '/content/gdrive/MyDrive/\ 10_UNIFEI/Box_vs_Wheel_Project'
在树莓派上用训练模型推理
将训练好的模型 /runs/detect/train/weights/best.pt 下载到本地,通过 FileZilla FTP 上传至树莓派 models 文件夹(可重命名为 box_wheel_320_yolo.pt)。
同样用 FTP 上传部分测试集图片到 ./YOLO/images。
回到 YOLO 目录,进入 Python 解释器:
cd ..
python
导入 YOLO 库并加载自定义模型:
from ultralytics import YOLO
model = YOLO("./models/box_wheel_320_yolo.pt")
指定图片并推理(本次保存推理结果图片以便外部查看):
img = "./images/1_box_1_wheel.jpg"
result = model.predict(img, save=True, imgsz=320, conf=0.5, iou=0.3)
可对多张图片重复操作。推理结果保存在 runs/detect/predict8。
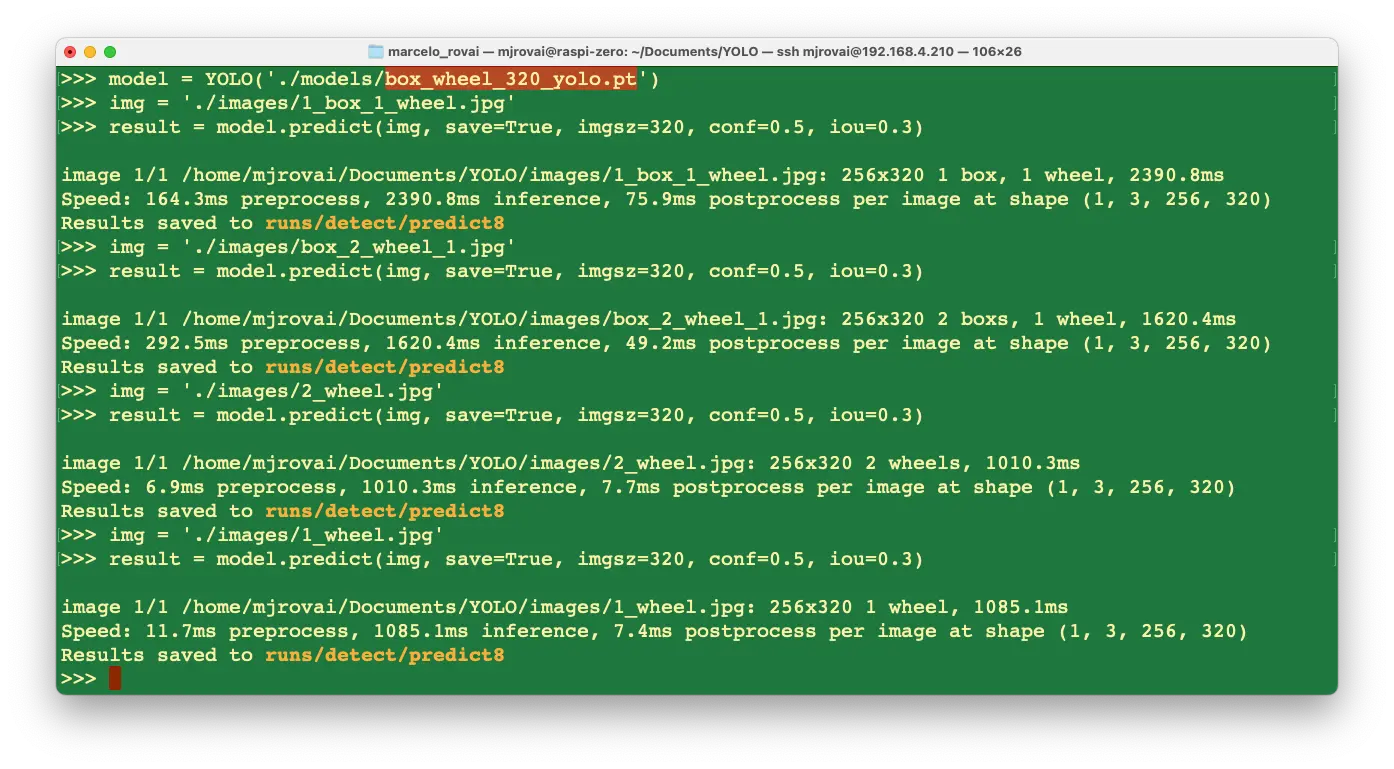
用 FileZilla FTP 将推理结果下载到桌面查看:

可以看到推理效果非常好!本模型基于 YOLOv8n(家族最小模型)训练。推理延迟约 1 秒,如需进一步优化可转换为 TFLite 或 NCNN 格式。
实时视频流目标检测
本实验涉及的所有模型均可通过摄像头实现实时目标检测。只需将摄像头采集的图片作为模型输入即可。在 Raspi-4/5 桌面环境下,可用 OpenCV 捕获帧并实时显示推理结果。
此外,也可基于 Flask 和 TensorFlow Lite 快速搭建实时目标检测 Web 应用。例如,基于图像分类应用脚本稍作修改,即可实现 基于 TensorFlow Lite 和 Flask 的实时目标检测 Web 应用。
本应用适用于所有 TFLite 模型。请确保模型路径正确,例如:
model_path = "./models/ssd-mobilenet-v1-tflite-default-v1.tflite"
从
GitHub
下载 Python 脚本 object_detection_app.py。
在终端运行:
python3 object_detection_app.py
访问 Web 界面:
- 树莓派本机(有桌面环境):浏览器访问
http://localhost:5000 - 局域网其他设备:浏览器访问
http://<raspberry_pi_ip>:5000(将<raspberry_pi_ip>替换为树莓派 IP),如http://192.168.4.210:5000
外部桌面运行效果如下:
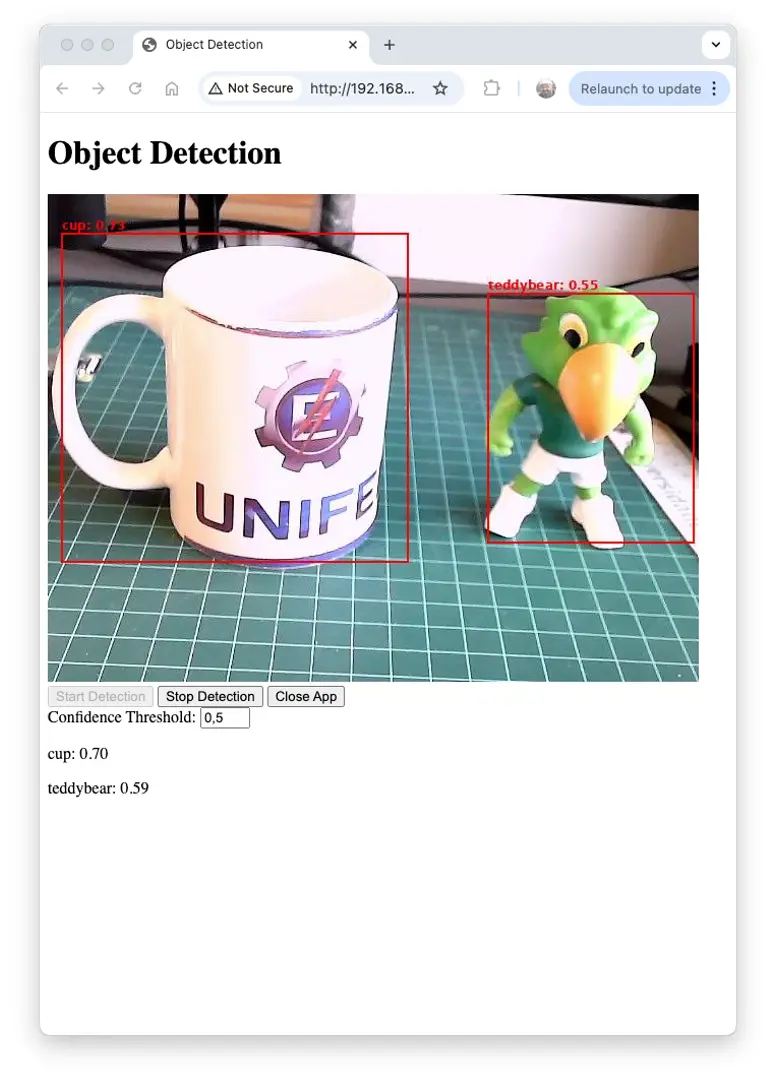
下面简要介绍应用关键模块:
- TensorFlow Lite (tflite_runtime):
- 用于边缘设备高效推理,模型体积小、性能优,支持硬件加速和量化。
- 关键函数:
Interpreter加载模型,get_input_details()、get_output_details()交互模型。
- Flask:
- 轻量级 Web 框架,适合快速开发和部署,资源占用低。
- 关键组件:路由装饰器定义 API,
Response流式传输视频,render_template_string动态 HTML。
- Picamera2:
- 树莓派摄像头接口库,性能优于旧版 Picamera。
- 关键函数:
create_preview_configuration()配置相机,capture_file()捕获帧。
- PIL (Python Imaging Library):
- 图像处理库,用于调整大小、绘制边框、格式转换。
- 关键类:
Image加载处理图片,ImageDraw绘制形状和文本。
- NumPy:
- 高效数组运算,适合处理图像数据和模型输入输出。
- 关键函数:
array()创建数组,expand_dims()增加维度。
- Threading:
- 并发执行,保证实时性能。
- 关键组件:
Thread创建线程,Lock线程同步。
- io.BytesIO:
- 内存二进制流,高效处理图片数据,减少 I/O。
- time:
- 时间相关函数,
sleep()控制帧率和性能测量。
- 时间相关函数,
- jQuery (前端):
- 简化 DOM 操作和 AJAX 请求,动态更新界面。
- 关键函数:
.get()、.post()AJAX,DOM 操作。
主要系统架构:
- 主线程:运行 Flask 服务器,处理 HTTP 请求和 Web 界面。
- 相机线程:持续采集摄像头帧。
- 检测线程:用 TFLite 模型处理帧,进行目标检测。
- 帧缓冲区:共享内存(加锁)存储最新帧和检测结果。
数据流简述:
- 相机采集帧 → 帧缓冲区
- 检测线程读取帧 → TFLite 推理 → 更新检测结果
- Flask 路由访问缓冲区,提供最新帧和结果
- Web 客户端 AJAX 获取更新,动态刷新界面
该架构使树莓派等资源有限设备也能高效实现实时目标检测。多线程与高效库(TFLite、PIL)保证实时处理,Flask 和 jQuery 提供友好交互。
如需测试其他模型(如 EfficientDet),只需更改模型路径:
model_path = "./models/lite-model_efficientdet_lite0_\
detection_metadata_1.tflite"
若需支持 Edge Impulse Studio 训练的 SSD-MobileNetV2 模型,需根据输入细节调整代码,详见 notebook 。
总结
本实验系统展示了在树莓派等边缘设备上实现目标检测的完整流程,体现了在资源受限硬件上运行先进视觉任务的强大潜力。主要内容包括:
- 模型对比:分析了 SSD-MobileNet、EfficientDet、FOMO、YOLO 等多种目标检测模型在边缘设备上的性能与权衡。
- 训练与部署:以自定义“箱子与轮子”数据集(Roboflow 标注)为例,演示了 Edge Impulse Studio 与 Ultralytics 的训练与部署流程。
- 优化技巧:介绍了模型量化(TFLite int8)、格式转换(如 NCNN)等多种推理加速方法。
- 实时应用:以实时目标检测 Web 应用为例,展示了模型在实际交互系统中的集成方式。
- 性能考量:贯穿实验讨论了模型精度与推理速度的平衡,这对边缘 AI 应用至关重要。
边缘设备目标检测为精准农业、工业自动化、质量检测、智能家居、环境监测等领域带来无限可能。数据本地处理可降低延迟、提升隐私、适应弱网环境。
未来可进一步探索:
- 多模型流水线实现更复杂任务
- 树莓派硬件加速方案
- 目标检测与多传感器融合,打造更完整的边缘 AI 系统
- 构建边缘 - 云协同的智能解决方案
边缘目标检测让 AI 能力深入物理世界,打造智能、响应迅速的系统,开拓人机交互与环境感知新前沿。