视觉 - 语言模型(VLM)
简介
在本实验中,我们将持续探索边缘侧的 AI 应用,从微软最新视觉基础模型 Florence-2 的基础部署,到在树莓派等设备上的高级实现。你将学习如何利用视觉 - 语言模型(VLM)在树莓派上完成图片描述、目标检测、定位、分割和 OCR 等任务。
为什么要在边缘部署 Florence-2?
Florence-2 是微软开源的视觉 - 语言模型(MIT 协议),通过轻量级架构与强大能力的结合,极大推动了 VLM 发展。其训练数据集 FLD-5B 包含 1.26 亿张图片和 54 亿条视觉标注,使 Florence-2 在性能上媲美更大规模的模型,非常适合在算力受限的边缘设备上部署。
本教程将带你体验 Florence-2 在实时计算机视觉场景下的应用,包括:
- 图片描述
- 目标检测
- 图像分割
- 视觉定位
视觉定位(Visual grounding) 指将文本描述与图片中的具体区域进行关联。模型能够理解 prompt 中描述的对象或实体在图片中的具体位置。例如,prompt 为“红色汽车”时,模型会定位并高亮图片中红色汽车所在区域。视觉定位适用于需要文本与视觉内容精准对齐的场景,如人机交互、图片标注和交互式 AI 系统。
本教程将涵盖以下内容:
- 在树莓派上部署 Florence-2
- 运行目标检测、图片描述等推理任务
- 优化模型以提升边缘设备性能
- 探索实际应用与微调方法
Florence-2 模型架构
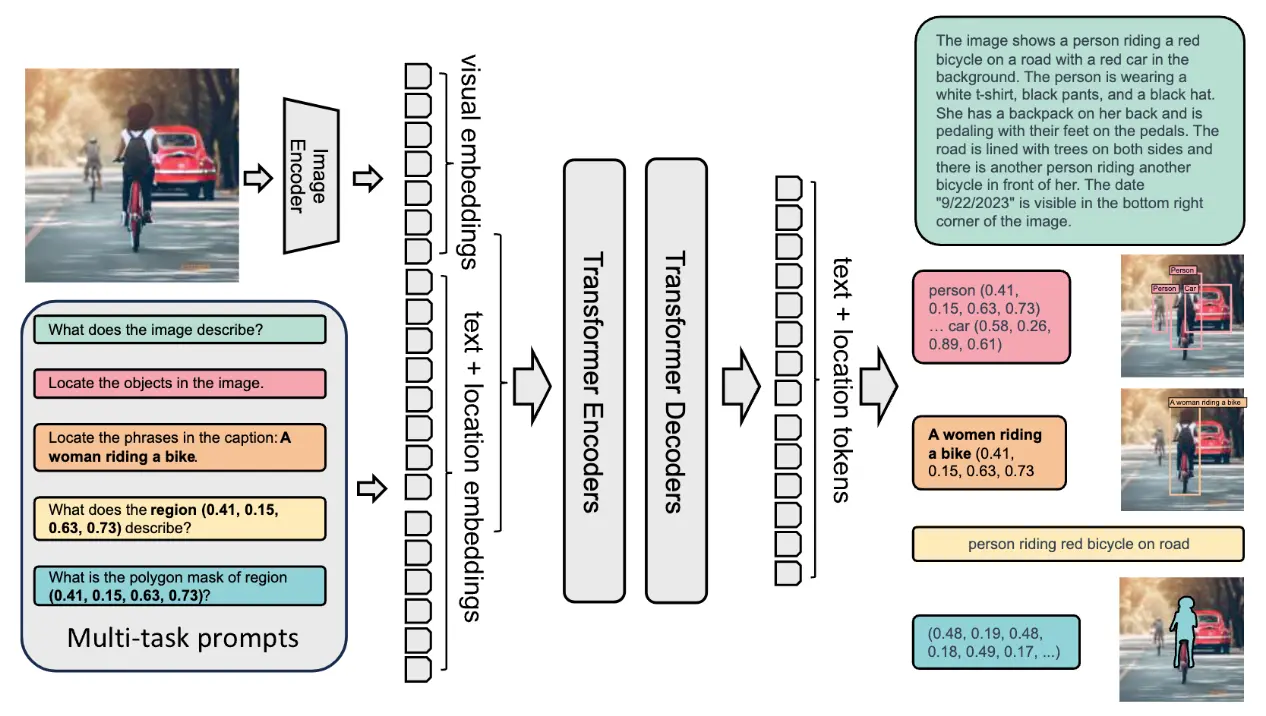
Florence-2 采用统一的 prompt 表达方式,支持多种视觉 - 语言任务。模型主要由两部分组成:图像编码器 和 多模态 Transformer 编码 - 解码器。

- 图像编码器:基于 DaViT(双注意力视觉 Transformer)架构 ,将输入图片转换为视觉 token 嵌入,捕捉图片的空间和上下文信息。
- 多模态 Transformer 编码 - 解码器:核心部分将图像编码器输出的视觉 token 与 BERT 类模型生成的文本嵌入结合,实现视觉和文本的联合处理,支持图片描述、目标检测、分割等多任务。
模型在大规模 FLD-5B 数据集上的训练,使其无需针对具体任务做结构调整即可胜任多种视觉任务。Florence-2 通过 prompt 激活不同任务,具备极强的灵活性和零样本泛化能力。对于目标检测、视觉定位等任务,模型还引入了位置 token,精准表达图片区域的空间关系。
Florence-2 的紧凑架构和创新训练方式,使其即便在树莓派等资源有限的设备上也能高效完成计算机视觉任务。
技术概览
Florence-2 拥有多项创新特性,具体如下:
架构特点
- 轻量化设计:提供两种模型规模
- Florence-2-Base:2.32 亿参数
- Florence-2-Large:7.71 亿参数
- 统一表达:单一架构支持多种视觉任务
- DaViT 视觉编码器:将图片转为视觉 token 嵌入
- 基于 Transformer 的多模态编码 - 解码器:联合处理视觉与文本特征
训练数据集(FLD-5B)
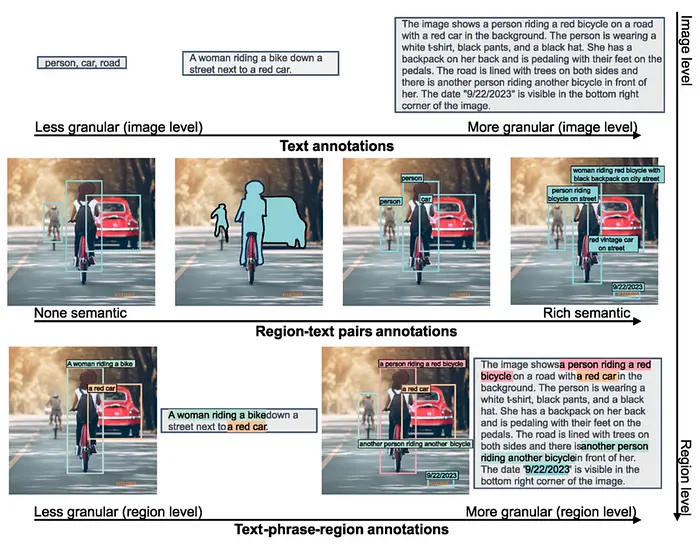
- 1.26 亿张独立图片
- 54 亿条高质量标注,包括:
- 5 亿文本标注
- 13 亿区域 - 文本标注
- 36 亿文本 - 短语 - 区域标注
- 自动化标注流程,结合专家模型
- 多轮迭代优化,确保标注质量
主要能力
Florence-2 在多项视觉任务中表现突出:
零样本性能
- 图片描述:COCO 数据集 CIDEr 得分 135.6
- 视觉定位:Flickr30k recall@1 达 84.4%
- 目标检测:COCO val2017 mAP 37.5
- 指代表达理解:RefCOCO 准确率 67.0%
微调性能
- 在特定任务上可媲美专业模型
- 在部分基准测试中超越更大规模模型
- 能高效适应新任务
典型应用场景
Florence-2 可广泛应用于以下领域:
内容理解
- 自动图片描述,提升无障碍体验
- 视觉内容审核
- 媒体资产管理
电商领域
- 商品图片分析
- 视觉搜索
- 自动商品标签生成
医疗健康
- 医学影像分析
- 辅助诊断
- 科研数据处理
安防监控
- 目标检测与跟踪
- 异常检测
- 场景理解
Florence-2 与其他 VLM 对比
Florence-2 以强大的零样本能力脱颖而出。与 Google PaliGemma 等需大量微调的模型不同,Florence-2 开箱即用,且在多项任务上可与 GPT-4V、Flamingo 等更大参数量模型竞争。例如,Florence-2 在零样本下优于参数量两倍的 Kosmos-2。
在 COCO 图片描述、指代表达等任务基准测试中,Florence-2 表现优异,超越 PolyFormer、UNINEXT 等模型,是对性能与资源效率均有要求的实际应用场景的理想选择。
部署与安装
本实验选用树莓派 5(Raspi-5)作为边缘设备。其硬件平台基于 Broadcom BCM2712,2.4GHz 四核 64 位 Arm Cortex-A76 CPU(支持加密扩展和增强缓存),配备 VideoCore VII GPU,双 4Kp60 HDMI® 输出(支持 HDR),4Kp60 HEVC 解码。内存可选 4GB/8GB 高速 LPDDR4X SDRAM,本实验选用 8GB 版本以运行 Florence-2。存储支持 microSD 卡扩展,并提供 PCIe 2.0 接口,可连接 M.2 SSD 等高速外设。
实际应用中,建议优先选择 SSD 作为存储介质,优于 SD 卡。
建议为树莓派 5 安装主动散热器(Active Cooler),该专用风扇散热片组合可在高负载(如运行 Florence-2)时保持设备稳定运行。

环境配置
在树莓派 5 上运行 Microsoft Florence-2 需安装以下依赖:
- Florence-2 依赖 Hugging Face 的
transformers库进行模型加载与推理,便于实现图片描述、目标检测等任务。该库负责模型交互、输入处理和输出获取。
- Florence-2 依赖 Hugging Face 的
PyTorch:
- PyTorch 是深度学习框架,提供张量运算、GPU 加速(如有)、模型训练与推理等功能。Florence-2 训练于 PyTorch,需依赖其算子和计算能力在树莓派上完成推理。
Timm(PyTorch Image Models):
- Florence-2 的图像编码器部分采用
timm,该库提供高效的视觉模型实现和预训练权重,尤其适合边缘设备。主要用于管理 DaViT 架构和视觉主干网络。
- Florence-2 的图像编码器部分采用
Einops:
einops用于灵活高效地处理张量变换,便于多模态数据的对齐和重组。视觉 - 语言模型常需对图片、文本嵌入等进行复杂变换,einops 可大幅提升代码可读性和简洁性。
简而言之:
- Transformers 和 PyTorch 用于模型加载与推理
- Timm 提供高效视觉编码器
- Einops 便于特征重组与融合
这些组件协同工作,使 Florence-2 能在树莓派等设备上高效完成复杂视觉 - 语言任务。
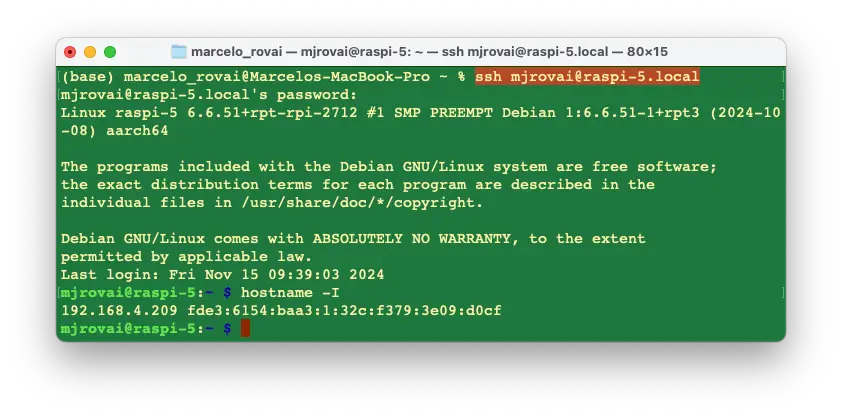
假设树莓派已安装操作系统,可通过 SSH 远程连接:
查询设备分配的 IP:
hostname -I
例如:
192.168.4.209
更新树莓派系统
首先确保系统为最新:
sudo apt update
sudo apt upgrade -y
PIP 基础环境配置:
sudo apt install python3-pip
sudo rm /usr/lib/python3.11/EXTERNALLY-MANAGED
pip3 install --upgrade pip
安装依赖库
sudo apt-get install libjpeg-dev libopenblas-dev libopenmpi-dev \
libomp-dev
创建并激活 Florence-2 虚拟环境:
python3 -m venv ~/florence
source ~/florence/bin/activate
安装 PyTorch
pip3 install setuptools numpy Cython
pip3 install requests
pip3 install torch torchvision \
--index-url https://download.pytorch.org/whl/cpu
pip3 install torchaudio \
--index-url https://download.pytorch.org/whl/cpu
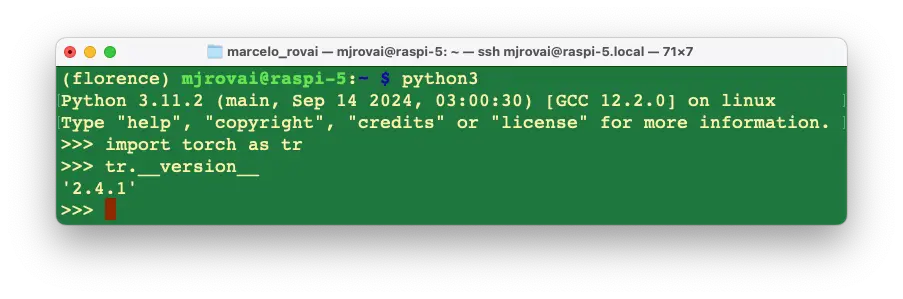
验证 PyTorch 安装:
安装 Transformers、Timm 和 Einops:
pip3 install transformers
pip3 install timm einops
安装模型包:
pip3 install autodistill-florence-2
Jupyter Notebook 及常用 Python 库
如需在 Jupyter Notebook 中测试代码,可安装如下:
pip3 install jupyter
pip3 install numpy Pillow matplotlib
jupyter notebook --generate-config
安装测试
在远程树莓派上运行 Jupyter Notebook:
jupyter notebook --ip=192.168.4.209 --no-browser
执行后,终端会显示本地 URL,可在浏览器中访问:
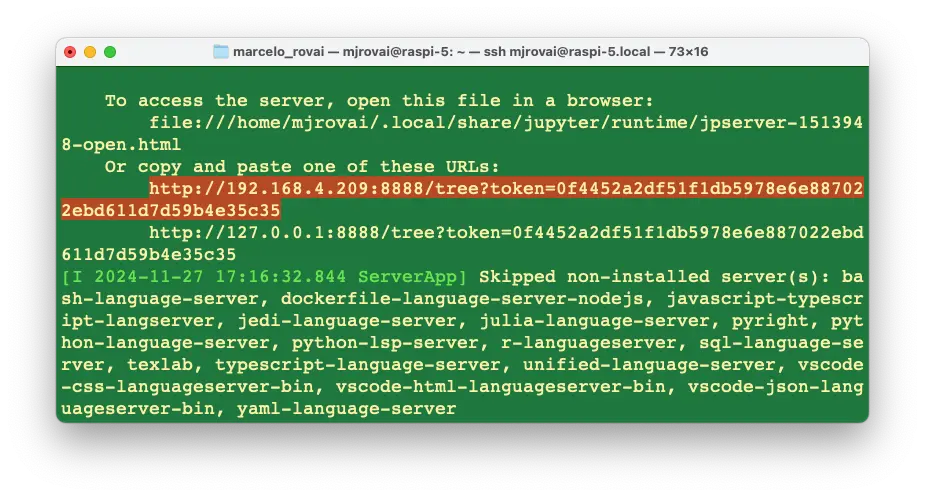
本实验相关 Notebook 可在 Lab GitHub 获取:
在远程电脑浏览器输入树莓派 IP 和 token,即可访问 Notebook。
在主页新建 [Python 3 (ipykernel) ],复制
Hugging Face Hub 示例代码
。
以下代码演示如何在指定图片上运行 Florence-2 进行目标检测,包括模型加载、图片与 prompt 处理、生成检测结果等步骤。
- processor:负责文本和图片输入的预处理
- model:根据处理后的输入生成推理结果
- 后处理:将原始输出转为可解释的结构化结果(如检测框)
该流程充分发挥 Florence-2 在视觉 - 语言任务上的通用性,依赖 PyTorch、Transformers 及相关图像处理工具实现高效推理。
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = (
torch.float16 if torch.cuda.is_available() else torch.float32
)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Florence-2-base",
torch_dtype=torch_dtype,
trust_remote_code=True,
).to(device)
processor = AutoProcessor.from_pretrained(
"microsoft/Florence-2-base", trust_remote_code=True
)
prompt = "<OD>"
url = (
"https://huggingface.co/datasets/huggingface/"
"documentation-images/resolve/main/transformers/"
"tasks/car.jpg?download=true"
)
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors="pt").to(
device, torch_dtype
)
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
do_sample=False,
num_beams=3,
)
generated_text = processor.batch_decode(
generated_ids, skip_special_tokens=False
)[0]
parsed_answer = processor.post_process_generation(
generated_text,
task="<OD>",
image_size=(image.width, image.height),
)
print(parsed_answer)
下面逐步解析上述代码:
导入依赖库
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
- requests:用于 HTTP 请求,这里用于下载图片
- PIL (Pillow):图片处理库,用于打开下载的图片
- torch:PyTorch,负责张量运算和设备检测(CPU/GPU)
- transformers:加载 Florence-2 预训练模型和处理器
设备与数据类型选择
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = (
torch.float16 if torch.cuda.is_available() else torch.float32
)
- 设备选择:检测是否有 CUDA GPU,优先用 GPU,否则用 CPU
- 数据类型选择:GPU 下用 float16 提升速度和节省内存,CPU 下用 float32 保证兼容性
加载模型与处理器
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Florence-2-base",
torch_dtype=torch_dtype,
trust_remote_code=True,
).to(device)
processor = AutoProcessor.from_pretrained(
"microsoft/Florence-2-base", trust_remote_code=True
)
- 模型加载:
AutoModelForCausalLM.from_pretrained()从 Hugging Face 加载 Florence-2 预训练模型,设置数据类型和信任远程代码.to(device)将模型迁移到指定设备
- 处理器加载:
AutoProcessor.from_pretrained()加载 Florence-2 专用处理器,负责文本和图片的预处理
定义 Prompt
prompt = "<OD>"
- Prompt 定义:
"<OD>"表示“目标检测”,引导模型对图片进行目标检测任务
下载与加载图片
url = "https://huggingface.co/datasets/huggingface/"
"documentation-images/resolve/main/transformers/"
"tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
- 下载图片:
requests.get()从指定 URL 获取图片,stream=True以流式方式下载 - 打开图片:
Image.open()打开图片,便于后续处理
输入处理
在本节中,我们将介绍如何处理输入数据,包括文本和图片的预处理。
inputs = processor(text=prompt, images=image, return_tensors="pt").to(
device, torch_dtype
)
- 输入数据处理:
processor()函数用于处理文本(prompt)和图片(image)。参数return_tensors="pt"会将处理后的数据转换为 PyTorch 张量,便于后续输入模型。 - 迁移到设备:
.to(device, torch_dtype)会将输入数据迁移到指定的设备(CPU 或 GPU),并设置合适的数据类型。
生成输出
下面的代码用于根据输入数据生成模型输出。
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
do_sample=False,
num_beams=3,
)
- 模型生成:
model.generate()根据输入数据生成输出。input_ids:表示 prompt 的分词结果。pixel_values:包含处理后的图片数据。max_new_tokens=1024:限制生成的最大新 token 数,控制输出长度。do_sample=False:禁用采样,采用确定性方法(如 beam search)生成。num_beams=3:启用 3 路 beam search,提高输出质量。
解码生成文本
生成的 token 需要解码为可读文本。
generated_text = processor.batch_decode(
generated_ids, skip_special_tokens=False
)[0]
- 批量解码:
processor.batch_decode()将生成的 token 解码为文本。skip_special_tokens=False表示保留特殊 token。
生成结果后处理
对生成的文本进行进一步处理,提取结构化信息。
parsed_answer = processor.post_process_generation(
generated_text,
task="<OD>",
image_size=(image.width, image.height),
)
- 后处理:
processor.post_process_generation()根据任务类型(如"<OD>"表示目标检测)和图片尺寸,对生成文本进行解析,提取如目标检测框等结构化信息。
输出结果
最后,打印处理后的结果。
print(parsed_answer)
- 输出展示:通过
print(parsed_answer)展示最终结果,例如检测到的目标框坐标和标签。
运行结果示例
运行上述代码后,得到如下解析结果:
[{'<OD>': {
'bboxes': [
[34.23999786376953, 160.0800018310547, 597.4400024414062],
[371.7599792480469, 272.32000732421875, 241.67999267578125],
[303.67999267578125, 247.4399871826172, 454.0799865722656],
[276.7200012207031, 553.9199829101562, 370.79998779296875],
[96.31999969482422, 280.55999755859375, 198.0800018310547],
[371.2799987792969]
],
'labels': ['car', 'door handle', 'wheel', 'wheel']
}}]
图片可视化
首先,我们可以查看原始图片:
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.axis("off")
plt.show()

目标检测结果分析
根据目标检测结果:
'labels': ['car', 'door handle', 'wheel', 'wheel']
可以看到模型检测出了若干目标。我们还可以编写代码将检测框绘制在图片上:
def plot_bbox(image, data):
# 创建画布和坐标轴
fig, ax = plt.subplots()
# 显示图片
ax.imshow(image)
# 绘制每个检测框
for bbox, label in zip(data["bboxes"], data["labels"]):
# 解包检测框坐标
x1, y1, x2, y2 = bbox
# 创建矩形框
rect = patches.Rectangle(
(x1, y1),
x2 - x1,
y2 - y1,
linewidth=1,
edgecolor="r",
facecolor="none",
)
# 添加矩形到坐标轴
ax.add_patch(rect)
# 标注类别
plt.text(
x1,
y1,
label,
color="white",
fontsize=8,
bbox=dict(facecolor="red", alpha=0.5),
)
# 去除坐标轴刻度
ax.axis("off")
# 显示结果
plt.show()
检测框 (x0, y0, x1, y1):坐标分别对应检测框的左上角和右下角。
调用如下:
plot_bbox(image, parsed_answer['<OD>'])
效果如下图所示:

Florence-2 支持的任务
Florence-2 支持多种视觉和视觉 - 语言任务,通过不同的 prompt 激活。只需更换 prompt,即可让模型适应不同任务,无需修改模型结构。这得益于 Florence-2 统一的架构和大规模多任务训练(FLD-5B 数据集)。
以下是 Florence-2 支持的主要任务及示例 prompt:
目标检测(Object Detection, OD)
- Prompt:
"<OD>" - 说明:识别图片中的目标并返回检测框,适用于视觉检测、安防、通用目标识别等场景。
图片描述(Image Captioning)
- Prompt:
"<CAPTION>" - 说明:为输入图片生成简要描述,帮助理解图片内容。
详细描述(Detailed Captioning)
- Prompt:
"<DETAILED_CAPTION>" - 说明:生成更详细的图片描述,包括场景、对象及其关系等丰富信息。
视觉定位(Visual Grounding)
- Prompt:
"<CAPTION_TO_PHRASE_GROUNDING>" - 说明:将文本描述与图片中的具体区域关联。例如,输入 “a green car”(一辆绿色的汽车),模型会高亮图片中绿色汽车的位置。该功能适用于人机交互等需要根据文本查找特定目标的场景。
分割(Segmentation)
- Prompt:
"<REFERRING_EXPRESSION_SEGMENTATION>" - 说明:根据指代表达(如 “the blue cup”)进行分割,模型会识别并分割出图片中对应的目标区域(所有相关像素)。
密集区域描述(Dense Region Captioning)
- Prompt:
"<DENSE_REGION_CAPTION>" - 说明:为图片中的多个区域生成描述,详细标注所有可见区域,包括不同对象及其关系。
区域 OCR(OCR with Region)
- Prompt:
"<OCR_WITH_REGION>" - 说明:对图片进行光学字符识别(OCR),并返回检测到文本的边界框。适用于提取和定位图片中的文字信息,如标识、标签等。
短语定位(Phrase Grounding for Specific Expressions)
- Prompt:
"<CAPTION_TO_PHRASE_GROUNDING>",并附带具体表达,如"a wine glass"。 - 说明:定位图片中与特定文本短语对应的区域。适合通过关键词查找特定对象或元素。
开放词汇目标检测(Open Vocabulary Object Detection)
- Prompt:
"<OPEN_VOCABULARY_OD>" - 说明:模型可检测不限于预定义类别的目标,能基于通用视觉理解识别更广泛的物体。
计算机视觉与视觉 - 语言任务探索
为便于探索,所有代码可在 GitHub 获取:
我们可以使用 Dall-E 生成的图片,并通过 FileZilla 上传到 Raspi-5,图片保存在 images 子文件夹:
dogs_cats = Image.open("./images/dogs-cats.jpg")
table = Image.open("./images/table.jpg")

为便于实验和统计不同任务的延迟,我们可以定义如下函数:
def run_example(task_prompt, text_input=None, image=None):
start_time = time.perf_counter() # 开始计时
if text_input is None:
prompt = task_prompt
else:
prompt = task_prompt + text_input
inputs = processor(
text=prompt, images=image, return_tensors="pt"
).to(device)
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
early_stopping=False,
do_sample=False,
num_beams=3,
)
generated_text = processor.batch_decode(
generated_ids, skip_special_tokens=False
)[0]
parsed_answer = processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=(image.width, image.height),
)
end_time = time.perf_counter() # 结束计时
elapsed_time = end_time - start_time # 计算耗时
print(
f" \n[INFO] ==> Florence-2-base ({task_prompt}), \
took {elapsed_time:.1f} seconds to execute.\n"
)
return parsed_answer
图片描述(Caption)
1. 狗与猫
run_example(task_prompt="<CAPTION>", image=dogs_cats)
[INFO] ==> Florence-2-base (<CAPTION>), \
took 16.1 seconds to execute.
{'<CAPTION>': 'A group of dogs and cats sitting in a garden.'}
2. 桌子
run_example(task_prompt="<CAPTION>", image=table)
[INFO] ==> Florence-2-base (<CAPTION>), \
took 16.5 seconds to execute.
{'<CAPTION>': 'A wooden table topped with a plate of fruit \
and a glass of wine.'}
详细描述(Detailed Caption)
1. 狗与猫
run_example(task_prompt="<DETAILED_CAPTION>", image=dogs_cats)
[INFO] ==> Florence-2-base (<DETAILED_CAPTION>), \
took 25.5 seconds to execute.
{'<DETAILED_CAPTION>': 'The image shows a group of cats and \
dogs sitting on top of a lush green field, surrounded by plants \
with flowers, trees, and a house in the background. The sky is \
visible above them, creating a peaceful atmosphere.'}
2. 桌子
run_example(task_prompt="<DETAILED_CAPTION>", image=table)
[INFO] ==> Florence-2-base (<DETAILED_CAPTION>), \
took 26.8 seconds to execute.
{'<DETAILED_CAPTION>': 'The image shows a wooden table with \
a bottle of wine and a glass of wine on it, surrounded by \
a variety of fruits such as apples, oranges, and grapes. \
In the background, there are chairs, plants, trees, and \
a house, all slightly blurred.'}
更详细描述(More Detailed Caption)
1. 狗与猫
run_example(task_prompt="<MORE_DETAILED_CAPTION>", image=dogs_cats)
[INFO] ==> Florence-2-base (<MORE_DETAILED_CAPTION>), \
took 49.8 seconds to execute.
{'<MORE_DETAILED_CAPTION>': 'The image shows a group of four \
cats and a dog in a garden. The garden is filled with colorful \
flowers and plants, and there is a pathway leading up to \
a house in the background. The main focus of the image is \
a large German Shepherd dog standing on the left side of \
the garden, with its tongue hanging out and its mouth open, \
as if it is panting or panting. On the right side, there are \
two smaller cats, one orange and one gray, sitting on the \
grass. In the background, there is another golden retriever \
dog sitting and looking at the camera. The sky is blue and \
the sun is shining, creating a warm and inviting atmosphere.'}
2. 桌子
run_example(task_prompt="<MORE_DETAILED_CAPTION>", image=table)
INFO] ==> Florence-2-base (<MORE_DETAILED_CAPTION>), \
took 32.4 seconds to execute.
{'<MORE_DETAILED_CAPTION>': 'The image shows a wooden table \
with a wooden tray on it. On the tray, there are various \
fruits such as grapes, oranges, apples, and grapes. There \
is also a bottle of red wine on the table. The background \
shows a garden with trees and a house. The overall mood \
of the image is peaceful and serene.'}
可以看到,描述越详细,延迟越高,且有时会出现识别错误(如“4 只猫和 1 只狗”,实际为 2 只狗和 3 只猫)。
目标检测(Object Detection)
同样可以用 <OD> prompt 进行目标检测:
task_prompt = "<OD>"
results = run_example(task_prompt, image=dogs_cats)
print(results)
输出如下:
[INFO] ==> Florence-2-base (<OD>), took 20.9 seconds to execute.
{'<OD>': {'bboxes': [
[737.79, 571.90, 1022.46, 980.48],
[0.51, 593.40, 211.45, 991.74],
[445.95, 721.40, 680.44, 850.43],
[39.42, 91.64, 491.00, 933.37],
[570.88, 184.83, 974.33, 782.84]
],
'labels': ['cat', 'cat', 'cat', 'dog', 'dog']
}}
仅通过标签 ['cat', 'cat', 'cat', 'dog', 'dog'] 就能看出主要目标已被检测。我们可以用前文的绘制检测框函数:
plot_bbox(dogs_cats, results["<OD>"])

同理,桌子图片:
task_prompt = "<OD>"
results = run_example(task_prompt, image=table)
plot_bbox(table, results["<OD>"])
[INFO] ==> Florence-2-base (<OD>), took 40.8 seconds to execute.

密集区域描述(Dense Region Caption)
可以将目标检测与区域描述结合,对图片的子区域进行描述:
task_prompt = "<DENSE_REGION_CAPTION>"
results = run_example(task_prompt, image=dogs_cats)
plot_bbox(dogs_cats, results["<DENSE_REGION_CAPTION>"])
results = run_example(task_prompt, image=table)
plot_bbox(table, results["<DENSE_REGION_CAPTION>"])

短语定位(Caption to Phrase Grounding)
该任务下,可以输入如 “a wine bottle”、“a wine glass”、“a half orange” 等短语,Florence-2 会定位图片中的对应目标:
task_prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
results = run_example(
task_prompt, text_input="a wine bottle", image=table
)
plot_bbox(table, results["<CAPTION_TO_PHRASE_GROUNDING>"])
results = run_example(
task_prompt, text_input="a wine glass", image=table
)
plot_bbox(table, results["<CAPTION_TO_PHRASE_GROUNDING>"])
results = run_example(
task_prompt, text_input="a half orange", image=table
)
plot_bbox(table, results["<CAPTION_TO_PHRASE_GROUNDING>"])

[INFO] ==> Florence-2-base (<CAPTION_TO_PHRASE_GROUNDING>), \
took 15.7 seconds to execute
each task.
级联任务(Cascade Tasks)
还可以将图片描述作为输入文本,进一步让 Florence-2 检测更多目标:
task_prompt = "<CAPTION>"
results = run_example(task_prompt, image=dogs_cats)
text_input = results[task_prompt]
task_prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
results = run_example(task_prompt, text_input, image=dogs_cats)
plot_bbox(dogs_cats, results["<CAPTION_TO_PHRASE_GROUNDING>"])
切换 task_prompt 为 <CAPTION>、<DETAILED_CAPTION>、<MORE_DETAILED_CAPTION>,可获得更多目标。

开放词汇检测(Open Vocabulary Detection)
<OPEN_VOCABULARY_DETECTION> 让 Florence-2 能检测图片中所有可识别目标,无需预定义类别。与 <CAPTION_TO_PHRASE_GROUNDING> 需指定短语不同,开放词汇检测会全面扫描图片,识别所有对象。
适用于需要全面了解图片内容的场景。例如:
task_prompt = "<OPEN_VOCABULARY_DETECTION>"
text = [
"a house",
"a tree",
"a standing cat at the left",
"a sleeping cat on the ground",
"a standing cat at the right",
"a yellow cat",
]
for txt in text:
results = run_example(
task_prompt, text_input=txt, image=dogs_cats
)
bbox_results = convert_to_od_format(
results["<OPEN_VOCABULARY_DETECTION>"]
)
plot_bbox(dogs_cats, bbox_results)

[INFO] ==> Florence-2-base (<OPEN_VOCABULARY_DETECTION>), \
took 15.1 seconds to execute
each task.
注意:尝试检测未被识别的目标时,模型可能会出错(详见 Notebook 示例)。
指代表达分割(Referring expression segmentation)
可以对图片中特定目标进行分割并生成描述,如桌子图片中的“a wine bottle”或狗猫图片中的“a German Sheppard”。
分割结果格式:{'<REFERRING_EXPRESSION_SEGMENTATION>': {'Polygons': [[[polygon]], ...], 'labels': ['', '', ...]}},每个目标用多边形点集表示,格式为 [x1, y1, x2, y2, ..., xn, yn]。
多边形 (x1, y1, …, xn, yn):顺时针依次为多边形顶点。
首先定义绘制分割多边形的函数:
from PIL import Image, ImageDraw, ImageFont
import copy
import random
import numpy as np
colormap = [
"blue",
"orange",
"green",
"purple",
"brown",
"pink",
"gray",
"olive",
"cyan",
"red",
"lime",
"indigo",
"violet",
"aqua",
"magenta",
"coral",
"gold",
"tan",
"skyblue",
]
def draw_polygons(image, prediction, fill_mask=False):
"""
在图片上绘制分割多边形。
参数说明:
- image: 图片对象。
- prediction: 包含 'polygons' 和 'labels' 的字典。
- fill_mask: 是否填充多边形。
- fill_mask: Boolean indicating whether to fill the polygons
with color.
"""
# Load the image
draw = ImageDraw.Draw(image)
# Set up scale factor if needed (use 1 if not scaling)
scale = 1
# Iterate over polygons and labels
for polygons, label in zip(
prediction["polygons"], prediction["labels"]
):
color = random.choice(colormap)
fill_color = random.choice(colormap) if fill_mask else None
for _polygon in polygons:
_polygon = np.array(_polygon).reshape(-1, 2)
if len(_polygon) < 3:
print("Invalid polygon:", _polygon)
continue
_polygon = (_polygon * scale).reshape(-1).tolist()
# 绘制多边形
if fill_mask:
draw.polygon(_polygon, outline=color, fill=fill_color)
else:
draw.polygon(_polygon, outline=color)
# 绘制标签
draw.text(
(_polygon[0] + 8, _polygon[1] + 2), label, fill=color
)
# Save or display the image
# image.show() # Display the image
display(image)
运行分割任务:
task_prompt = "<REFERRING_EXPRESSION_SEGMENTATION>"
results = run_example(
task_prompt, text_input="a wine bottle", image=table
)
output_image = copy.deepcopy(table)
draw_polygons(
output_image,
results["<REFERRING_EXPRESSION_SEGMENTATION>"],
fill_mask=True,
)
results = run_example(
task_prompt, text_input="a german sheppard", image=dogs_cats
)
output_image = copy.deepcopy(dogs_cats)
draw_polygons(
output_image,
results["<REFERRING_EXPRESSION_SEGMENTATION>"],
fill_mask=True,
)

[INFO] ==> Florence-2-base
(<REFERRING_EXPRESSION_SEGMENTATION>), took 207.0 seconds
to execute each task.
区域到分割(Region to Segmentation)
也可以通过输入目标坐标进行分割,输入格式为 '<loc_x1><loc_y1><loc_x2><loc_y2>',坐标范围 [0, 999]。
例如:
task_prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
results = run_example(
task_prompt, text_input="a half orange", image=table
)
results
输出:
{'<CAPTION_TO_PHRASE_GROUNDING>': {'bboxes': [[343.552001953125,
689.6640625,
530.9440307617188,
873.9840698242188]],
'labels': ['a half']}}
使用检测框坐标:
task_prompt = "<REGION_TO_SEGMENTATION>"
results = run_example(
task_prompt,
text_input=("<loc_343><loc_690>" "<loc_531><loc_874>"),
image=table,
)
output_image = copy.deepcopy(table)
draw_polygons(
output_image, results["<REGION_TO_SEGMENTATION>"], fill_mask=True
)
得到对应区域的分割结果(延迟 83 秒):

区域到文本(Region to Texts)
也可以输入区域坐标,获取该区域的类别或描述:
task_prompt = "<REGION_TO_CATEGORY>"
results = run_example(
task_prompt,
text_input=("<loc_343><loc_690>" "<loc_531><loc_874>"),
image=table,
)
results
[INFO] ==> Florence-2-base (<REGION_TO_CATEGORY>), \
took 14.3 seconds to execute.
{{
'<REGION_TO_CATEGORY>':
'orange<loc_343><loc_690>'
'<loc_531><loc_874>'
}
模型识别出该区域为橙子。进一步获取描述:
task_prompt = "<REGION_TO_DESCRIPTION>"
results = run_example(
task_prompt,
text_input=("<loc_343><loc_690>" "<loc_531><loc_874>"),
image=table,
)
results
[INFO] ==> Florence-2-base (<REGION_TO_CATEGORY>), \
took 14.6 seconds to execute.
{
'<REGION_TO_CATEGORY>':
'orange<loc_343><loc_690>'
'<loc_531><loc_874>'
}
本例未给出更多细节,可尝试其他区域。
OCR 文字识别
Florence-2 支持图片文字识别(OCR),可用 task_prompt = '<OCR>' 获取图片文字内容,或用 task_prompt = '<OCR_WITH_REGION>' 获取文字及其位置。
上传一张巴西讲座海报(葡萄牙语)到 Raspi,测试多语言识别:
flayer = Image.open("./images/embarcados.jpg")
# 显示图片
plt.figure(figsize=(8, 8))
plt.imshow(flayer)
plt.axis("off")
plt.show()

用 <MORE_DETAILED_CAPTION> 进行描述:
[INFO] ==> Florence-2-base (<MORE_DETAILED_CAPTION>), \
took 85.2 seconds to execute.
{'<MORE_DETAILED_CAPTION>': 'The image is a promotional poster \
for an event called "Machine Learning Embarcados" hosted by \
Marcelo Roval. ...'}
描述非常准确。用 OCR 任务提取文字:
task_prompt = "<OCR>"
run_example(task_prompt, image=flayer)
[INFO] ==> Florence-2-base (<OCR>), took 37.7 seconds to execute.
{'<OCR>':
'Machine Learning Café com Embarcado Embarcados '
'Democratizando a Inteligência Artificial para Paises em '
'25 de Setembro às 17h Desenvolvimento Toda quarta-feira '
'Marcelo Roval Professor na UNIFIEI e Transmissão via in '
'Co-Director do TinyML4D'}
定位文字区域:
task_prompt = "<OCR_WITH_REGION>"
results = run_example(task_prompt, image=flayer)
绘制检测到的文字框:
def draw_ocr_bboxes(image, prediction):
scale = 1
draw = ImageDraw.Draw(image)
bboxes = prediction["quad_boxes"]
labels = prediction["labels"]
for box, label in zip(bboxes, labels):
color = random.choice(colormap)
new_box = (np.array(box) * scale).tolist()
draw.polygon(new_box, width=3, outline=color)
draw.text(
(new_box[0] + 8, new_box[1] + 2),
"{}".format(label),
align="right",
fill=color,
)
display(image)
output_image = copy.deepcopy(flayer)
draw_ocr_bboxes(output_image, results["<OCR_WITH_REGION>"])

可查看检测到的文字:
results["<OCR_WITH_REGION>"]["labels"]
'</s>Machine Learning',
'Café',
'com',
'Embarcado',
'Embarcados',
'Democratizando a Inteligência',
'Artificial para Paises em',
'25 de Setembro ás 17h',
'Desenvolvimento',
'Toda quarta-feira',
'Marcelo Roval',
'Professor na UNIFIEI e',
'Transmissão via',
'in',
'Co-Director do TinyML4D']
延迟总结
在树莓派(Raspi-5)上运行 Florence-2 不同任务的延迟如下:
- 图片描述:约 16-17 秒
- 详细描述:约 25-27 秒
- 更详细描述:约 32-50 秒,描述越复杂延迟越高
- 目标检测:约 20-41 秒,取决于图片复杂度和目标数量
- 视觉定位:约 15-16 秒
- OCR:约 37-38 秒
- 分割及区域分割:约 83-207 秒,取决于分割区域数量和复杂度
这些延迟反映了边缘设备资源有限的现实,需优化模型和环境以实现更实时的性能。
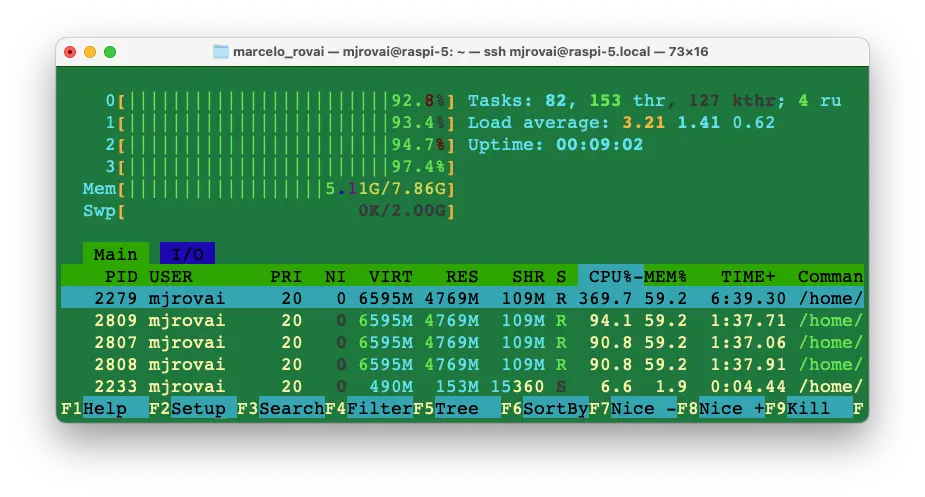
运行复杂任务时,Raspi-5 的 8GB 内存会被大量占用。上图为 Florence OD 任务时,4 核满载,内存占用超 5GB。建议将 SWAP 增加到 2GB。
用 vcgencmd measure_temp 检查 CPU 温度,最高可达 80°C 以上。
微调(Fine-Tuning)
Florence-2 开箱即用支持多种任务(描述、检测、OCR 等),但如需适应特定领域(如医学、遥感),需用自定义数据集微调。Roboflow 教程 How to Fine-tune Florence-2 for Object Detection Tasks 介绍了如何微调 Florence-2 提升特定场景下的检测能力。
基于该教程,可微调模型检测如前文实验中的 box 和 wheel:

需要注意,微调后模型仍可检测自定义数据集外的类别(如猫、狗、葡萄等)。
完整微调项目见:
另见 Hugging Face 博客 Fine-tuning Florence-2 - Microsoft’s Cutting-edge Vision Language Models ,展示了在 DocVQA 上微调 Florence 的案例。作者指出,Florence-2 可用于视觉问答(VQA),但官方模型未包含 VQA 能力。
总结
Florence-2 为边缘侧视觉 - 语言任务提供了强大且灵活的解决方案,性能媲美 YOLO(目标检测)、BERT/RoBERTa(文本分析)、专业 OCR 等专用模型。
得益于多模态 Transformer 架构,Florence-2 比 YOLO 更灵活,支持目标检测、图片描述、视觉定位等多任务。
与专注于语言的 BERT 不同,Florence-2 融合视觉与语言,适合需要多模态理解的场景。
而传统 OCR(如 Tesseract、EasyOCR)仅识别图片文字,Florence-2 的 OCR 能力还包含上下文理解和视觉 - 文本对齐,适合需要语境分析的场景。
总体来看,Florence-2 能高效整合多种视觉 - 语言任务,适合在树莓派等边缘设备部署,是开发者和研究者探索边缘 AI 应用的理想选择。
Florence-2 主要优势
统一架构
- 单模型支持多任务,省去多模型部署与集成
- API 和接口一致,易于开发
性能对比
- 目标检测:COCO mAP 37.5,接近 YOLOv8(39.7),且为通用模型
- 文字识别:多语言支持,媲美专业 OCR
- 语言理解:具备 BERT 类文本处理能力,并融合视觉上下文
资源效率
- Base 版仅 2.32 亿参数,性能强劲
- 可在树莓派等边缘设备流畅运行
- 单模型部署,简化运维
权衡与不足
与专用模型对比
- YOLO 系列纯检测速度更快
- 专业 OCR 处理复杂文档更强
- BERT/RoBERTa 纯文本理解更深
资源需求
- 边缘设备延迟较高(15-200 秒)
- 树莓派需注意内存管理
- 实时应用需进一步优化
部署复杂度
- 初始配置比单一模型复杂
- 需理解多任务 prompt
- prompt 工程有学习曲线
适用场景
资源受限环境
- 边缘设备需多视觉能力
- 存储/部署空间有限
- 需灵活视觉处理的应用
多模态应用
- 内容审核
- 无障碍辅助
- 文档分析
快速原型开发
- 快速集成多视觉能力
- 多任务测试无需多模型
- 概念验证
未来展望
Florence-2 代表了视觉模型统一化趋势,未来有望在许多场景替代专用架构。尽管专用模型在特定任务仍有优势,但统一模型的便利性和效率使其在实际部署中越来越受青睐。
本实验展示了 Florence-2 在边缘设备上的可行性,预示着未来在物联网、移动计算、嵌入式系统等领域的广泛应用。
参考资源
- 10-florence2_test.ipynb
- 20-florence_2.ipynb
- 30-Finetune_florence_2_on_detection_dataset_box_vs_wheel.ipynb