第 16 章:稳健 AI
目标
我们如何为真实世界部署开发具备容错性和高韧性的机器学习系统?
现实中的机器学习系统需要在多变的运行环境下实现容错执行。这些系统面临诸多削弱其能力的挑战,包括硬件异常、对抗性攻击,以及与训练假设偏离的不可预测数据分布。这些脆弱性要求 AI 系统在设计和部署阶段始终将稳健性与可信性置于核心。构建具备弹性的机器学习系统,意味着它们能在动态和不确定的环境中安全、有效地运行。理解稳健性原理,有助于工程师设计能抵御硬件故障、对抗恶意攻击并适应分布变化的系统。这一能力使得 ML 系统能够应用于安全关键场景,如自动驾驶、医疗诊断等对可靠性要求极高的领域。
学习目标
- 能将影响 ML 系统的硬件故障分为瞬时、永久和间歇三类,并理解各自特征
- 分析位翻转、内存错误和组件失效如何在神经网络计算中传播并降低模型性能
- 比较硬件故障检测机制,包括 BIST、自检码和冗余投票系统
- 设计结合硬件级保护与软件监控的 ML 部署容错策略
- 评估神经网络对抗攻击的多种方式,包括基于梯度、优化和迁移的攻击技术
- 通过异常检测、数据清洗和稳健训练方法,实现对数据投毒攻击的防御
- 利用监控和统计漂移检测方法,评估分布变化对模型准确率的影响
- 将稳健性原则贯穿于 ML 全流程,从数据采集到模型部署与监控
稳健 AI 系统简介
传统软件出错时,通常表现为明显的故障:服务器崩溃、应用报错、用户收到清晰的失败提示。而机器学习系统出错时,往往是“静默失效”。自动驾驶汽车的感知系统不会崩溃,而是把卡车识别成天空;需求预测模型不会报错,而是开始给出极不准确的预测;医疗诊断系统不会停机,而是悄悄地给出错误分类,甚至危及生命。这种“静默失效”让 AI 系统的稳健性成为独特且关键的挑战。工程师不仅要防范代码 bug,更要面对现实世界与训练数据不符的复杂性。
随着 ML 系统在云、边缘、嵌入式等多样场景下部署,这种静默失效的风险被进一步放大。系统复杂度提升、应用于安全关键场景1,都要求设计和实现必须以稳健和容错为核心,保障系统完整性。
在 第 14 章:设备端学习 中,我们讨论了适应性部署所面临的挑战;在 第 15 章:安全与隐私 中,我们探讨了安全漏洞。现在,我们将目光投向全面的系统可靠性。ML 系统在多种领域中运行,面临着硬件和软件故障、恶意输入(如对抗性攻击和数据投毒)以及环境变化等系统性故障,这些故障可能导致从经济损失到危及生命的严重后果。
为应对这些风险,研究人员和工程师必须开发出先进的故障检测、隔离和恢复技术,超越单纯的安全防护措施。虽然 第 15 章:安全与隐私 已经阐述了如何防范故意攻击,但确保可靠运行还需要解决可能影响系统行为的全方位潜在故障,包括故意和非故意的因素。
这一容错需求奠定了我们对稳健 AI 的定义基础:
稳健 AI 的定义
韧性人工智能(Resilient AI) 是指 AI 系统在面对 内部和外部系统错误、恶意输入以及数据或环境变化 时,能够保持 性能和可靠性 的能力。韧性 AI 系统被设计为具备 容错性,能够有效应对 操作环境中的变化和错误。实现韧性 AI 涉及 故障检测、缓解和恢复 的策略,同时在 AI 开发生命周期中优先考虑 韧性。
本章通过我们统一的三类框架,审视稳健性所面临的挑战,基于 第 14 章:设备端学习 中提出的适应性部署挑战,以及 第 15 章:安全与隐私 中检查的安全漏洞。我们系统的方法确保在操作部署前实现全面的系统可靠性。
在叙事弧中的定位: 第 14 章:设备端学习 确立了资源受限环境下的适应性部署挑战, 第 15 章:安全与隐私 则解决了这些适应性带来的安全漏洞,而本章则确保了针对所有故障模式(包括故意攻击、无意故障和自然变化)的系统级可靠性。这一全面的可靠性框架,对于 第 13 章:机器学习运维 中详细描述的操作工作流至关重要。
第一类是系统性硬件故障,这在计算系统中带来了重大挑战(见 第 2 章:机器学习系统 )。无论是瞬时故障2、永久故障,还是间歇性故障,这些故障都可能破坏计算过程,降低系统性能。其影响范围从暂时性故障到组件完全失效,要求采用稳健的检测和缓解策略以维持可靠的操作。这种以硬件为中心的视角,超越了其他章节对算法优化的讨论,关注物理层面的脆弱性。
第二类是恶意操控,我们从工程的角度审视对抗性稳健性,而非 第 15 章:安全与隐私 中以安全为先的做法。尽管该章节讨论了认证、访问控制和隐私保护,但我们关注的是在攻击下如何维持模型性能。对抗性攻击、数据投毒尝试和提示注入漏洞等都可能导致模型错误分类输入或生成不可靠输出,因此需要专门的防御机制,这些机制不同于传统的安全措施。
与这些故意威胁相辅相成的是环境变化,这构成了我们第三类稳健性挑战。不同于 第 13 章:机器学习运维 中讨论的操作监控,我们考察的是模型在数据分布随时间自然变化时如何维持准确性。算法、库和框架中的错误、设计缺陷和实现错误可能在系统中传播,形成超越单个组件故障的系统性脆弱性3。这种系统层面的稳健性视角,涵盖了从数据摄取到推理的整个 ML 流程。
实现稳健性的具体方法,因部署环境和系统限制而异。尽管 第 9 章:高效 AI 确立了优化原则,但大规模云计算环境通常通过冗余和复杂的错误检测机制来强调容错性。而边缘设备(见 第 14 章:设备端学习 )则必须在严格的计算、内存和能源限制内解决稳健性挑战,因此需要针对资源受限环境的专门加固策略。这些限制要求仔细的优化和针对性的加固策略4。
尽管存在这些上下文差异,稳健 ML 系统的基本特征包括容错性、错误恢复力和持续性能。通过理解和解决这些多方面的挑战,工程师可以开发出能够在真实世界环境中有效运行的可靠 ML 系统。
与 第 18 章:可持续 AI 中建立的可持续性原则相对,稳健 AI 系统不可避免地需要比基本实现更多的计算资源。错误修正机制消耗额外的 12-25% 内存带宽,冗余处理使能耗增加 2-3$\times$,而持续监控则增加 5-15% 的计算开销。这些稳健性措施还会产生额外的热量,加剧热管理挑战,限制部署密度,并需要增强冷却基础设施。理解这些可持续性权衡,使工程师能够在最大限度降低环境影响的同时,做出关于稳健性投资价值的明智决策。
本章系统地审视了这些多维稳健性挑战,探讨了硬件、算法和环境领域的检测和缓解技术。在边缘系统的部署策略(见 第 14 章:设备端学习 )和资源效率原则(见 第 18 章:可持续 AI )的基础上,我们制定了全面的方法,解决所有计算环境中的容错需求,同时考虑能源和热量限制。这里提供的稳健性挑战系统检查,为构建在真实世界部署中保持性能和安全的可靠 AI 系统奠定了基础,使稳健性从事后考虑变为生产机器学习系统的核心设计原则。
真实世界的稳健性失败案例
要理解机器学习系统稳健性的重要性,必须检查故障在实际中的表现。真实世界的案例研究揭示了云端、边缘和嵌入式环境中硬件和软件故障的后果。这些例子突显了容错设计、严格测试和稳健系统架构在确保多样化部署场景中可靠运行的关键需求。
云基础设施故障
2017 年 2 月,亚马逊网络服务(AWS)因例行维护中的人为错误,经历了 一次重大故障 。一名工程师不小心输入了错误的命令,导致美国东部地区多个服务器关闭。这次持续了 4 小时的故障中断了 150 多个 AWS 服务,初步估计影响了约 54% 的互联网流量,给受影响的企业造成了约 1.5 亿美元的损失。在故障期间,亚马逊的 AI 助手 Alexa(全球超过 4000 万台设备使用)完全无法响应。通常在 200-500 毫秒内处理的语音识别请求,完全失败,展示了基础设施故障对 ML 服务的连锁影响。此事件强调了人为错误对云端 ML 系统的影响,以及稳健的维护协议和安全机制的重要性5。
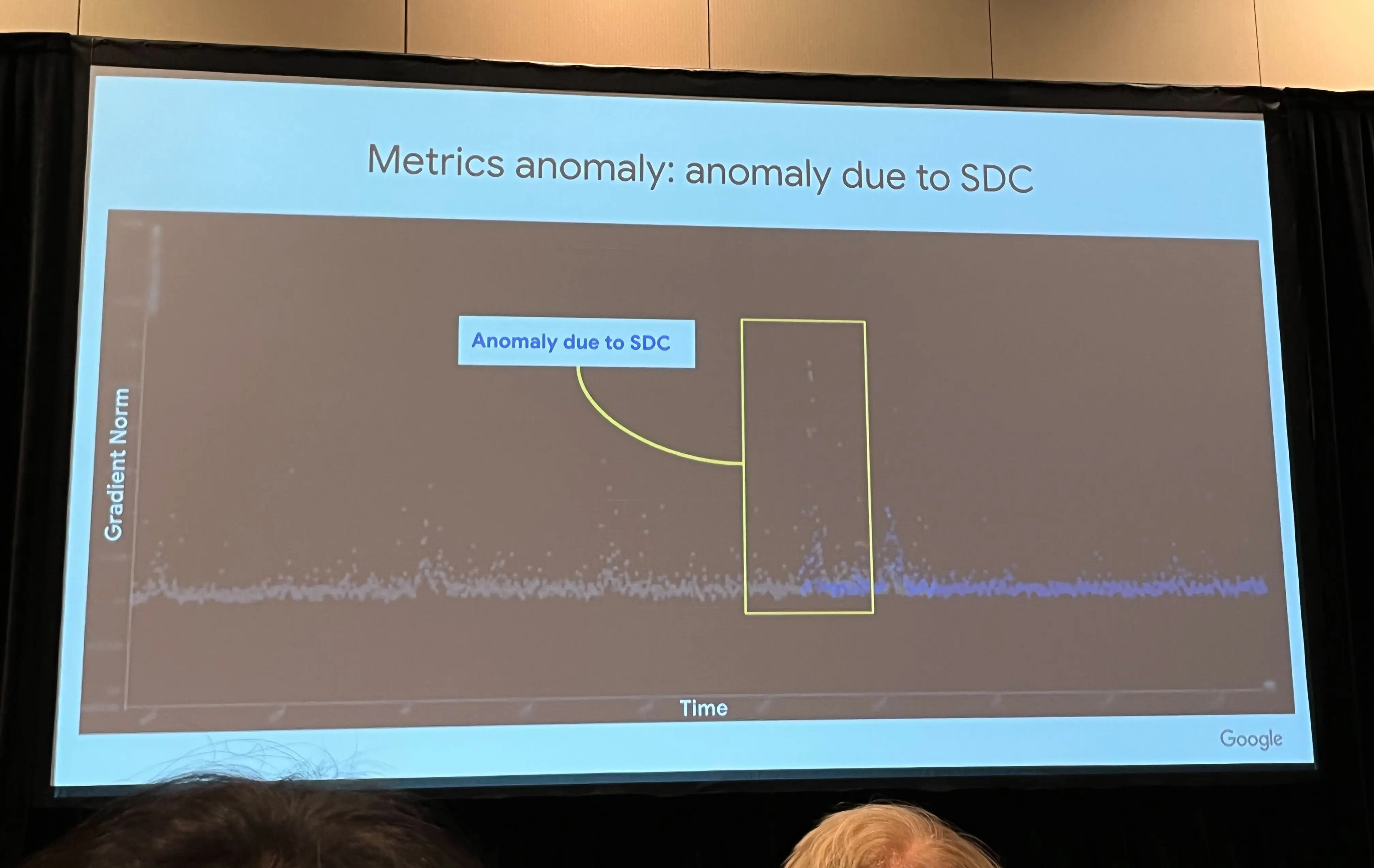
在另一起案例中,Facebook 在其分布式查询基础设施中遇到了静默数据损坏(SDC)问题6。如图 2 所示,SDC 是指在计算或数据传输过程中未被检测到的错误,这些错误在系统层中静默传播。Facebook 的系统处理类似 SQL 的查询,并支持一种旨在减少数据存储占用的压缩应用。当未使用时,文件会被压缩,并在读取请求时解压。解压前会进行大小检查以确保文件有效。然而,意外故障偶尔会返回有效文件的零大小,导致解压失败和输出数据库中缺失条目。该问题偶尔出现,某些计算返回正确的文件大小,使其诊断特别困难。

此案例展示了静默数据损坏如何在应用程序堆栈的多个层中传播,导致大规模分布式系统中的数据丢失和应用失败。如果不加以解决,这类错误可能会降低 ML 系统的性能,特别是影响训练过程(见第 8 章:AI 训练)。例如,由于 SDC 导致的训练数据损坏或数据管道不一致,可能会损害模型的准确性和可靠性。其他大型公司报告的类似问题进一步证实了此类问题的普遍性。如图 2 所示,Google DeepMind 和 Google Research 的首席科学家 Jeff Dean 在 2024 年 MLSys 大会的主题演讲中强调了 AI 超级计算机中的这些问题。

边缘设备的脆弱性
从集中式云环境转向分布式边缘部署,以自动驾驶车辆为例,突显了故障如何在边缘计算领域严重影响 ML 系统的情况7。这些车辆依赖机器学习进行感知、决策和控制,因此特别容易受到硬件和软件故障的影响。

2016 年 5 月,一起致命事故发生在一辆特斯拉 Model S 上,当时该车处于自动驾驶模式8,与一辆白色半挂车相撞。该系统依赖计算机视觉和机器学习算法,未能在明亮的天空背景下识别出拖车,导致高速碰撞。司机在事发时 reportedly 分心,未能及时干预,如图 3 所示。此事件引发了人们对基于 AI 的感知系统可靠性的严重担忧,并强调了自动驾驶车辆中稳健安全失效机制的必要性。
2018 年 3 月,另一类似事件发生,当时一辆优步自驾测试车辆在亚利桑那州坦佩市 撞上 并导致一名行人死亡。事故原因是车辆的物体识别软件存在缺陷,未能将行人识别为需要避让的障碍物。
嵌入式系统的限制
嵌入式系统9 的应用超越了边缘计算,进入资源受限且通常是安全关键的环境。随着 AI 能力越来越多地集成到这些系统中,故障的复杂性和后果显著增加。
一个例子来自太空探索。1999 年,NASA 的火星极地着陆者任务因其着陆检测系统中的软件错误而经历了 灾难性故障 。着陆者的软件错误地将着陆腿展开时产生的振动误判为成功着陆,导致引擎过早关闭,造成坠毁。此事件展示了严格的软件验证和稳健系统设计的重要性,尤其是对于那些无法恢复的远程任务。随着 AI 在航天系统中变得愈发重要,确保其稳健性和可靠性对于任务成功至关重要。

嵌入式系统故障的后果不仅限于太空探索,还扩展到商业航空。2015 年,一架波音 787 梦幻客机因其发电机控制单元中的软件错误,在飞行中经历了完全的电力关闭。此故障强调了安全关键系统10 满足严格可靠性要求的重要性。故障发生在所有四个发电机控制单元在连续供电 248 天后同时启动的情况下,导致它们同时进入安全失效模式,禁用所有交流电力。
“如果四个主发电机控制单元(与发动机安装的发电机相关联)同时通电,在连续供电 248 天后,所有四个 GCU 将同时进入安全失效模式,导致无论飞行阶段如何,所有交流电力的丧失。” — 联邦航空管理局指令 (2015)
随着 AI 在航空领域的应用日益增多,包括自主飞行控制和预测性维护等任务,嵌入式系统的稳健性直接影响乘客安全。
当我们考虑植入式医疗设备时,风险变得更高。例如,智能 心脏起搏器 如果因软件或硬件故障而发生故障或异常行为,可能会危及患者生命。随着 AI 系统在此类应用中承担感知、决策和控制等角色,新来源的脆弱性随之出现,包括与数据相关的错误、模型不确定性11 和在极端边缘情况下的不可预测行为。某些 AI 模型的不透明特性使故障诊断和恢复变得更加复杂。
这些真实世界的故障场景凸显了系统性稳健性评估和缓解的必要性。每一个故障——无论是影响数百万次语音交互的 AWS 中断、导致致命车祸的自动驾驶车辆感知错误,还是导致任务失败的航天器软件错误——都揭示了可以为稳健系统设计提供信息的共同模式。
在这些具体的系统故障案例基础上,我们现在建立一个统一的框架,以系统的方式理解和解决稳健性挑战。
稳健 AI 的统一框架
尽管上述故障的原因和背景各不相同,但它们在某些特征上是相似的。这些事件无论是 AWS 的语音助手停摆、自动驾驶车辆的感知失败,还是航天器的软件错误,都揭示了可以为系统稳健性提供信息的模式。
基于先前概念
在建立我们的稳健性框架之前,我们将这些挑战与早期章节中的基础概念联系起来。硬件加速架构(见 第 11 章:AI 加速 )阐明了 GPU 内存层次结构、互连结构和专用计算单元如何创建复杂的故障传播路径,稳健性系统必须解决这些问题。第 15 章:安全与隐私 中的安全框架介绍的威胁建模原则,直接影响我们对对抗性攻击和防御策略的理解。来自 第 13 章:机器学习运维 的操作监控系统提供了检测和响应生产环境中稳健性威胁的基础设施。
这些早期概念在稳健 AI 系统中交汇:GPU 内存错误可能会破坏模型权重,对抗性输入可能会利用学习到的脆弱性,而操作监控必须检测硬件、算法和环境维度的异常。这些在 第 9 章:高效 AI 中涵盖的效率优化,成为在可接受性能预算内实施冗余和错误修正机制的关键限制。
从 ML 性能到系统可靠性
为了系统地理解这些故障模式,我们必须弥合 ML 系统性能概念(见于早期章节)与稳健部署所需的可靠性工程原则之间的差距。在传统的 ML 开发中(见 第 2 章:机器学习系统 ),我们关注模型准确性、推理延迟和吞吐量等指标。然而,真实世界的部署增加了一个维度:执行我们模型的基础计算平台的可靠性。
考虑硬件可靠性如何直接影响 ML 性能:关键神经网络权重的单个位翻转,可能导致 ResNet-50 在 ImageNet 上的分类准确率从 76.0%(前 1 名)降至 11%;而训练过程中内存子系统的故障,则可能导致梯度更新损坏,模型无法收敛。现代变压器模型(如具有 1750 亿参数的 GPT-3)在每次推理中执行 10^15 次浮点运算,单次前向传播中就可能出现超过一百万次的硬件故障。GPU 内存系统的带宽高达 900 GB/s(如 V100 HBM2),以 10^-17 的基本错误率处理每秒 10^11 位数据,这意味着每小时操作中可能出现多个故障。
这种硬件可靠性与 ML 性能之间的联系,要求我们采用可靠性工程的概念12,包括描述故障发生方式的故障模型、在影响结果之前识别问题的错误检测机制,以及恢复系统操作的恢复策略。这些可靠性概念补充了 第 9 章:高效 AI 中涵盖的性能优化技术,确保优化后的系统在真实世界条件下仍能正确运行。
在此概念桥梁的基础上,我们建立了一个统一的框架,以理解 ML 系统各个维度的稳健性挑战。该框架为理解来自硬件、对抗性输入或软件缺陷的不同类型故障提供了概念基础,这些故障具有共同特征,可以通过系统的方法加以解决。
稳健 AI 的三大支柱
稳健 AI 系统必须应对三类主要挑战,这些挑战可能会危及系统的可靠性和性能。图 5 展示了这一三支柱框架,说明了系统级故障、输入级攻击和环境变化如何分别代表对 ML 系统稳健性的不同但相互关联的威胁:

系统级故障包括所有源自基础计算基础设施的故障。这些故障包括来自宇宙辐射的瞬时硬件错误、组件的永久性退化,以及间歇性故障。系统级故障影响执行 ML 计算的物理基础,可能会破坏计算、内存访问模式或组件之间的通信。
输入级攻击是指通过精心构造的输入或训练数据操纵模型行为的故意尝试。对抗性攻击通过向输入添加不可察觉的扰动来利用模型的脆弱性,而数据投毒则破坏训练过程本身。这些威胁针对信息处理管道,颠覆模型学习到的表示和决策边界。
环境变化则代表了真实世界条件的自然演变,这些变化可能会随着时间的推移而降低模型性能。分布变化、概念漂移和操作上下文的变化,挑战着模型训练的核心假设。与故意攻击不同,这些变化反映了部署环境的动态特性以及静态训练范式的固有限制。
共同的稳健性原则
这三类挑战源于不同的因素,但具有几个关键特征,这些特征为我们构建韧性系统的方法提供了指导:
检测和监控是任何稳健性策略的基础。硬件监控系统通常以 1-10 Hz 的频率采样,检测温度异常(±5°C)、电压波动(±5%)和超过 10^-12 错误/比特/小时的内存错误率。对抗性输入检测利用统计测试,p 值阈值为 0.01-0.05,检测率达到 85-95%,假阳性率低于 2%。分布监控使用 MMD 测试,每次评估处理 1000-10000 个样本,检测到的偏移量在 95% 置信区间内的 Cohen’s d > 0.3。
在此检测能力的基础上,优雅降级确保系统即使在压力下也能维持核心功能。稳健系统应表现出可预测的性能下降,而不是灾难性故障,从而保留关键能力。ECC 内存系统以 99.9% 的成功率从单比特错误中恢复,同时增加 12.5% 的带宽开销。将模型从 FP32 量化为 INT8 可将内存需求减少 75%,推理时间缩短 2-4$\times$,以牺牲 1-3% 准确率换取在资源受限情况下的持续运行。集成备份系统在主模型失效时仍能维持 85-90% 的峰值性能,切换延迟低于 10 毫秒。
自适应响应使系统能够根据检测到的威胁或变化的条件调整其行为。适应可能涉及激活错误修正机制、应用输入预处理技术或动态调整模型参数。关键原则是,稳健性不是静态的,而是需要持续调整以保持有效性。
这些原则超越了故障恢复,涵盖了贯穿于 ML 系统设计中的全面性能适应策略。检测策略为监控系统奠定基础,优雅降级指导组件失效时的备份机制,自适应响应则使系统能够随环境变化而演变。
跨 ML 流程的集成
要实现稳健性,不能仅依靠对单个组件应用孤立的技术。相反,它需要在整个 ML 流程中进行系统集成,从数据收集到部署和监控。这种集成方法认识到,单个组件的脆弱性可能会危及整个系统,无论其他地方实施了何种保护措施。
在建立了这一统一基础后,接下来我们将系统地检查每个支柱,提供必要的概念基础,以理解用于稳健性评估和改进的专门工具和框架。
硬件故障
在建立了统一框架后,我们现在详细检查每个支柱,首先是系统级故障。硬件故障代表了稳健性挑战的基础层,因为所有 ML 计算最终都是在可能以各种方式发生故障的物理硬件上执行的。
硬件故障对 ML 系统的影响
要理解硬件可靠性对机器学习工作负载特别重要的原因,需要考察几个关键因素。与传统应用相比,ML 系统在多个方面放大了硬件故障的影响:
- 计算密集型:现代 ML 工作负载每秒执行数百万次操作,造成许多机会让故障破坏结果
- 长时间运行的训练:训练任务可能持续数天或数周,增加了遇到硬件故障的概率
- 参数敏感性:模型权重的微小损坏可能导致输出预测的重大变化
- 分布式依赖性:大规模训练依赖于多个处理器之间的协调,单点故障可能会中断整个工作流
基于这些特定于 ML 的考虑,硬件故障主要分为三类,依据其时间特征和持续性,每类对 ML 系统可靠性提出了不同的挑战。
为了说明硬件故障对神经网络的直接影响,考虑权重矩阵中的单个位翻转。如果由于影响 IEEE 754 浮点表示法中符号位的瞬时故障,ResNet-50 模型中的一个关键权重从 0.5 翻转为 -0.5,则会改变特征图的符号,导致后续层出现错误级联。研究表明,针对关键层的单个有针对性的比特翻转,可以使 ImageNet 的准确率从 76% 降至不足 10% 。这表明,硬件可靠性直接影响模型性能,而不仅仅是基础设施稳定性。与传统软件中单个比特错误可能导致崩溃或计算错误不同,在神经网络中,它可能悄悄地破坏决定系统行为的学习表示。
瞬时故障是由宇宙射线或电磁干扰等外部因素引起的短暂干扰。这些非重复性事件(如内存中的比特翻转)会导致错误计算,但不会造成永久性硬件损坏。对于 ML 系统,瞬时故障可能会在训练过程中破坏梯度更新,或在推理过程中改变模型权重,从而导致暂时但可能显著的性能下降。
永久故障则是指由物理缺陷或组件磨损引起的不可逆损害,例如卡住故障或设备故障,需要更换硬件。这些故障对于长时间运行的 ML 训练任务尤其成问题,因为硬件故障可能导致数天或数周的计算损失,并需要从最近的检查点重新启动整个任务。
间歇性故障由于不稳定的条件(如松动的连接或老化的组件)而时有时无,诊断和重现起来特别具有挑战性。这些故障可能导致 ML 系统出现非确定性行为,从而导致不一致的结果,损害模型的验证和可重复性。
理解这一故障分类法,为设计容错 ML 系统奠定了基础,使其能够在不同的操作环境中检测、缓解和恢复硬件故障。由于现代 AI 工作负载的计算密集型、分布式特性和长时间运行的特点,硬件故障对 ML 系统的影响超出了传统计算应用的范畴。
瞬时故障
我们从最常见的类别开始详细检查瞬时故障,这类故障在硬件中以各种形式表现,每种形式都有其独特的特征和原因。这些故障是短暂的,不会对硬件组件造成永久性损害。
瞬时故障特性
瞬时故障的特征是持续时间短且非永久性。它们不会持续存在,也不会对硬件产生持久影响。然而,如果处理不当,它们仍然可能导致错误计算、数据损坏或系统错误行为。一个经典的例子如图 6 所示,其中内存中的单个位意外改变状态,可能会改变关键数据或计算。
这些表现形式包括几类不同的故障。常见的瞬时故障类型包括由宇宙射线和电离辐射引起的单事件干扰(SEUs)13、电源不稳定引起的电压波动、来自外部电磁场的电磁干扰(EMI)14、静电放电(ESD)引起的突发电压、由于信号耦合不当而产生的串扰15、多路输出同时切换引起的地弹跳、信号时序约束违反引起的时序违规,以及组合逻辑中的软错误。理解这些故障类型,有助于设计稳健的硬件系统,以减轻其影响,确保可靠运行。
故障分析和性能影响
现代 ML 系统需要精确了解故障率及其对性能的影响,以便做出明智的工程决策。瞬时故障的定量分析揭示了显著的模式,为稳健系统设计提供了信息。
先进的半导体工艺显示出显著更高的软错误率。与 65 nm 节点相比,现代 7 nm 节点的软错误率大约高出 1000$\times$,这是由于节点电容和电荷收集效率降低。对于基于尖端工艺制造的 ML 加速器,这转化为大约每 10^14 次操作 1 次的基本错误率,因此需要系统的错误检测和修正策略。
这些理论故障率转化为实际的可靠性指标,这些指标因部署环境和工作负载特征而异。典型的 AI 加速器在不同部署环境下表现出显著不同的平均故障间隔时间(MTBF)16 值:
- 云 AI 加速器(Tesla V100、A100):在受控数据中心条件下,MTBF 为 50000-100000 小时
- 边缘 AI 处理器(NVIDIA Jetson、Intel Movidius):在不受控制的环境中,MTBF 为 20000-40000 小时
- 移动 AI 芯片(Apple Neural Engine、Qualcomm Hexagon):在热量和电源限制下,MTBF 为 30000-60000 小时
这些 MTBF 值在分布式训练场景中显著增加。具有 50000 小时 MTBF 的 1000 个加速器集群,预计每 50 小时就会发生一次故障,因此需要稳健的检查点和恢复机制。
除了了解故障率,系统设计者还必须考虑保护成本。硬件容错机制引入了可测量的性能和能量损失,这些损失必须在系统设计中加以考虑。表 1 定量分析了不同保护机制的权衡:
| 保护机制 | 性能 开销 | 能量开销 | 面积开销 |
|---|---|---|---|
| 单比特 ECC | 2-5% | 3-7% | 12-15% |
| 双比特 ECC | 5-12% | 8-15% | 25-30% |
| 三重冗余 | 200-300% | 200-300% | 200-300% |
| 检查点/重启 | 10-25% | 15-30% | 5-10% |
这些开销对内存带宽利用率的影响尤为显著,而内存带宽是 ML 工作负载的关键限制。ECC 内存17 由于额外的存储需求(每 64 个数据比特 8 个 ECC 比特),有效带宽减少 12.5%。错误检测的内存清理操作根据清理频率和内存配置,额外消耗 5-15% 的可用带宽。
这些带宽开销直接影响性能。对于典型的以内存带宽为限制的变压器训练工作负载,这些带宽减少直接导致训练时间成比例增加。一个需要 900 GB/s 内存带宽的模型,使用 ECC 保护后实际带宽仅为 787 GB/s,训练时间大约延长 14%。
内存层次结构和带宽影响
内存子系统被认为是现代 ML 系统中最容易出现故障的组件,其容错机制对带宽利用率和整体系统性能都有显著影响。要理解内存层次结构的稳健性,需分析不同内存技术之间的相互作用、它们的错误特性以及保护机制的带宽影响。
这种复杂性源于内存技术的多样特性,这些技术表现出不同的故障模式和保护需求。表 2 显示了 ECC 保护如何影响不同技术下的内存带宽:
- DRAM:基本错误率为每 10^17 比特 1 次,主要是单比特软错误。需要基于刷新错误检测和更正。
- HBM(高带宽内存):由于 3D 堆叠效应和热密度,错误率高出 10$\times$。需要高级 ECC 以确保可靠操作。
- SRAM(缓存):软错误率较低(每 10^19 比特 1 次),但对电压变化和工艺变化的脆弱性较高。
- NVM(非易失性内存):新兴技术如 3D XPoint 具有独特的错误模式,需要专门的保护方案18。
- GDDR:针对带宽而非可靠性优化,通常比标准 DRAM 高 2-3$\times$ 的错误率。
内存技术和保护机制的选择,直接影响 ML 工作负载的可用带宽:
| 内存技术 | 基础带宽 (GB/s) | ECC 开销 (%) | 有效带宽 (GB/s) |
|---|---|---|---|
| DDR4-3200 | 51.2 | 12.5% | 44.8 |
| HBM2 | 900 | 12.5% | 787 |
| HBM3 | 1,600 | 12.5% | 1,400 |
| GDDR6X | 760 | 通常无 | 760 |
现代内存系统通过内存清理实现持续的后台错误检测,定期读取和重写内存位置,以检测和更正累积的软错误。这种后台活动消耗内存带宽,并与 ML 工作负载产生干扰:
- 清理速率:典型的 24 小时全内存扫描消耗 2-5% 的总带宽
- 优先级仲裁:ML 内存请求必须与清理操作竞争,增加 10-15% 的延迟变化
- 热影响:清理操作使内存功耗增加 3-8%,影响热设计和冷却需求
先进的 ML 系统实施分层保护方案,在内存层次结构中平衡性能和可靠性:
- L1/L2 缓存:奇偶校验保护,具有即时检测和重放能力
- L3 缓存:单比特 ECC,带错误日志记录和逐步缓存行退役
- 主内存:双比特 ECC,带高级综合分析和预测性故障检测
- 持久存储:使用分布式冗余的里德 - 所罗门编码,跨多个设备实现
现代 AI 加速器将内存保护与计算管道设计相结合,以最小化性能影响:
- 错误检测流水线:内存 ECC 检查与算术操作重叠,以隐藏保护延迟
- 自适应保护级别:根据工作负载重要性和错误率监控动态调整保护强度
- 带宽分配策略:服务质量机制,优先保证关键 ML 内存流量,而非背景保护操作

瞬时故障的起源
外部环境因素是上述瞬时故障类型的主要来源。如图 7 所示,宇宙射线——来自外太空的高能粒子——撞击内存单元或晶体管等敏感硬件区域,诱发电荷干扰,改变存储或传输的数据。来自附近设备的电磁干扰(EMI)会产生电压尖峰或故障,暂时干扰正常操作。静电放电(ESD)事件会产生影响敏感电子元件的瞬时电压浪涌。
除了这些外部环境因素,电源和信号完整性问题构成了瞬时故障的另一个主要类别,这些问题影响硬件系统(见 第 11 章:AI 加速 )。由于电源噪声或不稳定引起的电压波动,可能导致逻辑电路在其规定的电压范围之外工作,从而导致错误计算。地弹跳是由于多个输出同时切换引起的,导致地参考电压的瞬时变化,可能影响信号完整性。串扰是由于相邻导体之间的信号耦合引起的,可能会诱发噪声,暂时破坏数据或控制信号,影响训练过程(见第 8 章:AI 训练)。
时序和逻辑脆弱性为瞬时故障提供了额外的传播途径。时序违规发生在信号由于工艺变化、温度变化或电压波动未能满足建立或保持时间要求时。这些违规可能导致顺序元件中错误的数据捕获。组合逻辑中的软错误即使在不涉及内存的情况下也可能影响电路输出,特别是在深逻辑路径中,噪声裕度降低。
瞬时故障传播
基于这些根本原因,瞬时故障可能通过不同机制表现,具体取决于受影响的硬件组件。在 DRAM 或 SRAM 等内存设备中,瞬时故障通常表现为比特翻转,即单个比特值从 0 改变为 1 或反之。这可能会破坏存储的数据或指令。在逻辑电路中,瞬时故障可能导致电压尖峰或故障通过组合逻辑传播,导致错误的输出或控制信号。广泛用于 ML 工作负载的图形处理单元(GPU)19 的故障率显著高于传统 CPU,研究表明,GPU 的错误率比 CPU 高 10-1000$\times$,这归因于其并行架构、更高的晶体管密度和激进的电压/频率调整。这种差异使得在训练和推理操作中,GPU 加速的 AI 系统特别容易受到瞬时故障的影响。瞬时故障还可能影响通信通道,导致数据传输过程中的比特错误或数据包丢失。在分布式 AI 训练系统中,网络分区20 以可测量的频率发生——对大规模集群的研究表明,1-10% 的节点每天会受到分区事件的影响,具体取决于分区类型和检测机制,恢复时间从几秒到几小时不等。
瞬时故障对 ML 的影响
瞬时故障的一个常见例子是在主内存中的比特翻转。如果重要的数据结构或关键指令存储在受影响的内存位置,可能导致错误计算或程序错误行为。例如,如果存储循环计数器的内存发生比特翻转,可能导致循环无限执行或过早终止。控制寄存器或标志位的瞬时故障可能会改变程序执行的流程,导致意外跳转或错误的分支决策。在通信系统中,瞬时故障可能会破坏传输的数据包,导致重传或数据丢失。
这些一般影响在 ML 系统中尤为明显,因为瞬时故障在训练阶段可能产生重大影响。ML 训练涉及迭代计算和基于大数据集对模型参数的更新。如果模型权重或梯度的存储内发生瞬时故障,可能导致错误更新,妨碍训练过程的收敛和准确性。例如,神经网络权重矩阵中的比特翻转可能导致模型学习错误的模式或关联,从而导致性能下降。在数据管道中的瞬时故障,例如训练样本或标签的损坏,也可能引入噪声,影响学习模型的质量。
如图 8 所示,来自 Google 生产环境的一个真实案例,显示 SDC 异常如何导致梯度范数的显著偏差,梯度范数是更新模型参数幅度的度量。这种偏差可能干扰优化过程,导致收敛速度变慢或无法达到最优解。
在推理阶段,瞬时故障可能会影响 ML 预测的可靠性和可信度。如果在存储训练模型参数的内存中,或在推理结果计算过程中发生瞬时故障,可能导致不正确或不一致的预测。例如,神经网络激活值中的比特翻转可能会改变最终的分类或回归输出。在安全关键应用中1,这些故障可能导致严重后果,导致不正确的决策或行动,可能危及安全或导致系统故障。
在资源受限环境(如 TinyML)中,这些脆弱性尤为明显,因为有限的计算和内存资源加剧了它们的影响。一个突出的例子是二值神经网络(BNNs),它们以单比特精度表示网络权重,以实现计算效率和更快的推理时间。尽管这种二进制表示对资源受限系统有利,但也使得 BNNs 对比特翻转错误特别脆弱。例如,先前的研究表明,对于像 MNIST 分类这样简单任务的双隐层 BNN 架构,在模型权重中以 10% 的概率插入随机比特翻转错误后,测试准确率从 98% 下降到 70%。为了解决这些脆弱性,正在探索诸如翻转感知训练和新兴的随机计算等技术,以增强其容错性。
永久故障
从短暂干扰转向持久性问题,永久故障是指对受影响组件造成不可逆损害的硬件缺陷。这些故障的特征在于其持久性,需通过修复或更换故障硬件来恢复正常系统功能。
永久性故障特性
永久性故障会导致硬件组件持续且不可逆的失效。受影响的组件在修复或更换之前将一直无法正常工作。这类故障具有一致性和可复现性,也就是说,每次使用该组件时都会出现相同的故障行为。它们可能影响处理器、内存模块、存储设备或互连线路,最终导致系统崩溃、数据损坏,甚至系统完全失效。
为了说明永久性故障的严重影响,这里有一个著名案例: Intel FDIV bug(奔腾除法错误) ,于 1994 年被发现。该缺陷影响了部分 Intel 奔腾处理器的浮点除法(FDIV)单元,导致特定除法运算结果错误,进而引发计算不准确。
FDIV bug 的根源在于除法单元使用的查找表21出现了错误。在极少数情况下,处理器会读取到错误的值,导致结果精度略低于预期。例如,图 9 展示了在存在 FDIV 故障的奔腾处理器上计算 4195835/3145727 的结果。三角区域标记了发生错误计算的位置。理想情况下,所有正确值应四舍五入为 1.3338,但故障结果显示为 1.3337,说明第五位出现了误差。
虽然该错误很小,但在大量运算中会累积,影响对精度要求极高的应用,如科学仿真、金融计算和计算机辅助设计。最终,该 bug 导致这些领域的结果不准确,凸显了永久性故障可能带来的严重后果。
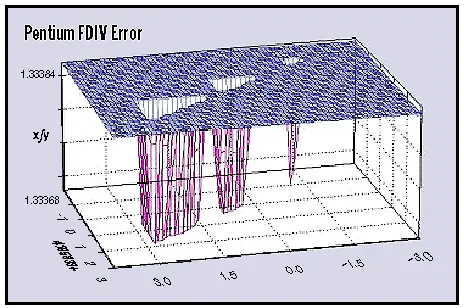
FDIV bug 为 ML 系统敲响了警钟。在此类系统中,硬件组件的永久性故障可能导致计算结果错误,影响模型的准确性和可靠性。例如,如果 ML 系统依赖于存在类似 FDIV bug 的处理器浮点单元,训练或推理过程中就可能持续出现错误。这些错误会在模型中传播,导致预测不准确或学习结果偏差。
在 第 19 章:AI 向善 探讨的安全敏感应用1中,这一点尤为关键,因为计算错误的后果可能极其严重。ML 从业者必须意识到这些风险,并采用包括硬件冗余、错误检测与纠正、稳健算法设计等容错技术加以缓解。彻底的硬件验证和测试有助于在永久性故障影响系统性能和可靠性之前发现并解决问题。
永久性故障的成因
永久性故障主要来源于两类:制造缺陷和老化失效。
第一类, 制造缺陷 ,是在芯片制造过程中引入的瑕疵,包括蚀刻不当、掺杂错误或污染。这些缺陷可能导致组件完全或部分失效。另一类, 老化失效 ,则是由于长期使用和运行压力导致的。电迁移22、氧化层击穿23和热应力24等现象会逐步削弱组件的完整性,最终导致永久性失效。
永久性故障的传播
永久性故障的表现机制多样,取决于其性质和位置。常见的一种是“卡住故障”(stuck-at fault),即信号或内存单元永久性地固定为 0 或 1,无论输入如何,如图 10 所示。这类故障可发生在逻辑门、内存单元或互连线路中,通常导致计算错误或持续性数据损坏。

其他机制还包括器件失效,即由于制造缺陷或老化,晶体管或内存单元等硬件组件完全失效。桥接故障是指两个或多个信号线意外连通,可能引发短路或难以定位的逻辑错误。
更隐蔽的情况如延迟故障,即信号传播时间超过允许的时序约束。逻辑值可能正确,但时序违规仍会导致错误行为。类似地,互连故障包括断路(连接断开)、高阻路径(阻碍电流流动)和电容增加(信号过渡失真),都可能严重降低电路性能和可靠性。
内存子系统尤其容易受到永久性故障影响。转换故障会导致内存单元无法成功改变状态,耦合故障则因相邻单元间的干扰导致非预期状态变化。邻域模式敏感故障表现为内存单元的状态被附近单元的数据错误影响,反映了电路布局与逻辑行为的复杂交互。
永久性故障还可能发生在电源网络或时钟分配系统等关键基础设施组件中。这些子系统的失效会影响整个电路的功能,引入时序错误,或导致大范围的运行不稳定。
综上所述,这些机制展示了永久性故障破坏计算系统行为的多样且复杂的方式。对于对正确性和一致性要求极高的 ML 应用,理解这些故障模式对于开发韧性硬件和软件解决方案至关重要。
永久性故障对 ML 的影响
永久性故障可能严重破坏计算系统的行为和可靠性。例如,处理器算术逻辑单元(ALU)的卡住故障会导致持续的计算错误,进而引发程序异常或崩溃。内存模块中的此类故障可能导致数据损坏,存储设备则可能出现坏块甚至数据全部丢失。互连故障可能干扰数据传输,导致系统卡死或数据损坏。
对于 ML 系统,这些故障在训练和推理阶段都带来重大风险。与瞬时故障类似(见前文相关章节),永久性故障在训练期间会造成梯度计算错误和参数损坏,但其影响会持续,直到硬件更换,因此需要更全面的恢复策略。与仅暂时干扰训练的瞬时故障不同,存储中的永久性故障可能损坏整个训练数据集或已保存模型,影响长期一致性和可靠性。
在推理阶段,故障可能导致预测结果失真或运行时失败。例如,存储模型权重的硬件出现错误,可能导致使用过时或损坏的模型;处理器故障则可能产生错误输出。
缓解永久性故障需要综合性的容错设计,将硬件冗余和错误更正码与如检查点和重启机制25等软件方法结合。
定期监控、测试和维护有助于在关键错误发生前发现并更换故障组件。
间歇性故障
间歇性故障是指系统中偶发且不可预测的硬件故障。图 11 展示了一个例子,材料中的裂纹会导致电路电阻增加。这类故障由于时隐时现,难以检测和诊断,难以复现和定位根本原因。根据其发生频率和位置,间歇性故障可能导致系统不稳定、数据损坏和性能下降。

间歇性故障特性
间歇性故障的特点是行为零散且不可预测。它们发生不规律,持续时间短暂,并且没有固定的出现模式。与永久性故障不同,间歇性故障并不会在每次使用受影响组件时都出现,这使得它们极难检测和复现。这类故障可能影响多种硬件部件,包括处理器、内存模块、存储设备和互连线路,进而导致瞬态错误、系统行为异常或数据损坏。
间歇性故障对系统可靠性的影响可能非常显著。例如,处理器控制逻辑中的间歇性故障可能扰乱正常的执行路径,导致程序流程异常或系统无故挂起。在内存模块中,这类故障会不规律地改变存储值,产生难以追踪的错误。受影响的存储设备可能出现偶发的读写错误或数据丢失,而通信通道中的间歇性故障则会导致数据损坏、丢包或连接不稳定。随着时间推移,这些故障会累积,降低系统性能和可靠性。
间歇性故障成因
间歇性故障的成因多样,既有物理老化,也有环境影响。常见原因之一是电子元件的老化和疲劳。硬件在长期运行、热循环和机械应力下,可能出现裂纹、断裂或疲劳,进而引发间歇性故障。例如,球栅阵列(BGA)或倒装芯片封装中的焊点会随时间退化,导致间歇性开路或短路。
制造缺陷和工艺波动也可能引入边缘组件,这些组件在大多数情况下表现正常,但在压力或极端条件下会间歇性失效。例如,图 12 展示了 DRAM 芯片中由残留物引发的间歇性故障,导致偶发性失效。

环境因素如热循环、湿度、机械振动或静电放电会加剧这些弱点,诱发原本不会出现的故障。松动或退化的物理连接(如连接器或 PCB 板上的焊点)也是间歇性故障的常见来源,尤其是在经常移动或温度变化较大的系统中。
间歇性故障传播机制
间歇性故障可通过多种物理和逻辑机制表现出来,具体取决于其根本原因。其中一种机制是间歇性开路或短路,即物理不连续或部分连接导致信号路径行为不可预测。这类故障可能短暂干扰信号完整性,产生毛刺或意外的逻辑跳变。
另一常见机制是间歇性延迟故障,即由于时序边缘条件导致信号传播时间波动,进而引发同步问题和计算错误。在存储单元或寄存器中,间歇性故障可能表现为瞬时位翻转或软错误,造成难以检测或复现的数据损坏。由于这些故障往往依赖于特定的热、电压或负载条件,因此诊断难度更高。
间歇性故障对机器学习的影响
间歇性故障对 ML 系统构成重大挑战,破坏计算一致性和模型可靠性。在训练阶段,处理单元或内存中的间歇性故障会导致梯度、权重更新或损失值的偶发性计算错误。这些错误虽不持续,但可能在多次迭代中累积,导致收敛不稳定或模型效果下降。存储中的间歇性故障还可能损坏输入数据或模型检查点,进一步影响训练流程。
在推理阶段,间歇性故障可能导致预测结果不一致或错误。处理错误或内存损坏会扭曲模型的激活、输出或中间表示,尤其是当故障影响模型参数或输入数据时。数据管道中的间歇性故障(如传感器或存储系统不可靠)会引入微妙的输入错误,降低模型稳健性和输出准确性。在自动驾驶、医疗诊断等高风险场景下,这些不一致可能导致危险决策或操作失败。
缓解 ML 系统中间歇性故障影响需要多层次手段。硬件层面可通过稳健设计、环境控制和高质量元件降低故障风险,冗余和错误检测机制有助于识别和恢复瞬时故障。
软件层面可采用运行时监控、异常检测和自适应控制等技术提升稳健性,并结合 第 7 章:AI 框架 和 第 13 章:机器学习运维 中介绍的框架能力和部署策略。数据校验、异常值检测、模型集成和运行时模型自适应等容错方法可集成到 ML 流水线中,提升系统在偶发错误下的可靠性。
设计能够优雅应对间歇性故障的 ML 系统,有助于保持其准确性、一致性和可靠性。这需要主动的故障检测、定期系统监控和持续维护,确保问题早发现、早修复。通过在架构和运维流程中嵌入稳健性(详见 第 13 章:机器学习运维 ),ML 系统即使在易受偶发硬件故障影响的环境下也能保持稳健。
有效的容错不仅仅是检测,还包括在不同系统条件下的自适应性能管理。全面的资源管理策略(如负载均衡、故障条件下的动态扩缩容)详见 第 13 章:机器学习运维 。对于资源受限场景,可采用动态量化、选择性剪枝等自适应模型复杂度降低技术,相关内容见 第 10 章:模型优化 和 第 9 章:高效 AI 。
硬件故障检测与缓解
故障检测技术(包括硬件级和软件级方法)及有效的缓解策略可提升 ML 系统的稳健性。稳健 ML 系统设计要点、案例分析和容错 ML 研究为构建可靠系统提供了参考。
稳健的故障缓解需要全栈协同适应。虽然本节聚焦于故障检测和基础恢复机制,但全面的性能自适应策略需通过动态资源管理( 第 13 章:机器学习运维 )、容错分布式训练( 第 8 章:AI 训练 )和在资源受限下保持性能的自适应模型优化( 第 10 章:模型优化 、 第 9 章:高效 AI )实现。这些策略确保 ML 系统不仅能检测和恢复故障,还能通过智能资源分配和模型复杂度调整维持最优性能。面向更高稳健性的未来架构范式详见 第 20 章:通用人工智能系统 。
硬件故障检测方法
故障检测技术用于识别和定位 ML 系统中的硬件故障,基于 第 12 章:AI 基准测试 的性能测量原理。这些技术大致分为硬件级和软件级两类,各有独特优势。
硬件级检测
硬件级故障检测在系统物理层实现,目标是识别底层硬件部件的故障。常见方法包括以下几类。
内建自测试(BIST)机制
BIST 是检测硬件故障的强大手段。它通过在系统中集成额外电路,实现自测试和故障检测。BIST 可应用于处理器、内存模块、ASIC 等多种部件。例如,处理器可通过扫描链(scan chains)26 实现 BIST,扫描链为测试提供对内部寄存器和逻辑的访问。
BIST 过程中,预设测试模式作用于处理器内部电路,响应与期望值比对,若有差异即表明存在故障。例如,Intel Xeon 处理器在启动时通过 BIST 检测 CPU 核心、缓存等关键部件。

错误检测码
错误检测码广泛用于检测数据存储和传输中的错误。通过为原始数据增加冗余位,实现比特错误检测。例如,奇偶校验是一种简单的错误检测码,如图 13 所示27。单比特奇偶校验方案为每个数据字添加一位,使 1 的数量为偶数(偶校验)或奇数(奇校验)。
读取数据时,校验奇偶性,若与期望不符则检测到错误。更高级的错误检测码如循环冗余校验(CRC)28,基于数据计算校验和并附加到消息末尾。
硬件冗余与投票机制
硬件冗余通过复制关键部件并比对输出,实现故障检测和屏蔽。投票机制如双模冗余(DMR)29 或三模冗余(TMR)30,通过多实例比对输出,识别并屏蔽故障行为。
DMR/TMR 系统中,两个或三个相同部件(如处理器或传感器)并行计算,输出送入投票电路,取多数值为最终输出。若某实例因故障输出错误,投票机制可屏蔽错误,保证正确性。TMR 常用于航空航天等高可靠性场景。例如,波音 777 飞控系统采用 TMR 保证飞控功能的可用性和正确性。
特斯拉自动驾驶计算机则采用 DMR 架构,保障感知、决策和控制等关键功能的安全可靠,如图 14 所示。两套独立硬件单元(冗余计算机)并行处理传感器数据、执行算法、生成控制指令。

两套冗余单元的输出持续比对,若一致则认为均正常,控制指令下发至执行机构。若输出不一致,系统判定某单元可能故障,并采取措施保障安全。
特斯拉 DMR 架构为自动驾驶系统提供了额外的安全和容错层。通过两套独立单元并行计算,系统可检测并缓解单元故障,防止单点失效,确保关键功能持续运行。
系统还可通过诊断算法、与其他传感器或子系统比对、分析输出一致性等方式定位故障单元。一旦识别出故障单元,系统可隔离并仅用正常单元输出继续运行。
特斯拉还采用 DMR 以外的冗余机制,如冗余电源、转向和制动系统,以及多样化传感器套件31(摄像头、雷达、超声波等),多层容错共同提升自动驾驶系统的安全性和可靠性。
DMR 可检测和一定程度屏蔽故障,但若两单元同时故障或比对机制失效,系统可能无法识别故障。因此,特斯拉 SDC 结合 DMR 与多种冗余机制,实现高容错。
DMR 在特斯拉自动驾驶计算机中的应用,凸显了高可靠性场景下硬件冗余的重要性。通过冗余计算单元和输出比对,系统可检测并缓解故障,提升自动驾驶功能的整体安全性和可靠性。
另一种硬件冗余方式是热备(hot spares)32,如 Google 数据中心在 ML 训练中应对 SDC。与 DMR/TMR 并行冗余不同,热备通过备用硬件单元在检测到故障时无缝接管计算,实现容错。图 15 展示了 Google 的做法:正常训练时,多台同步训练 worker 并行处理数据,若某 worker 出现 SDC,SDC 检查器自动识别并将训练迁移至热备机,同时将故障机送修。该冗余机制保障 ML 训练连续性和可靠性,最大限度减少停机和数据损坏。

看门狗定时器
看门狗定时器是监控关键任务或进程执行的硬件部件,常用于检测和恢复因软件或硬件故障导致系统无响应或死循环的情况。在嵌入式系统中,看门狗定时器可监控主控循环,如图 16 所示。软件定期复位看门狗,表示系统正常运行。若在规定时间内未复位,看门狗判定系统故障,触发预设恢复动作(如重启或切换备份部件)。看门狗广泛应用于汽车电子、工业控制等安全关键场景,确保及时检测和恢复故障。

软件级检测
软件级故障检测依赖于算法和监控机制,可在操作系统、中间件或应用层实现。
运行时监控与异常检测
运行时监控通过持续观察系统及其组件的行为,检测异常、错误或意外行为,扩展了 第 13 章:机器学习运维 中的运维监控实践。例如,自动驾驶汽车中的 ML 图像分类系统可实现运行时监控,跟踪模型性能和行为。
异常检测算法可应用于模型预测或中间层激活,如统计异常检测或基于 ML 的方法(如 One-Class SVM、自动编码器)。图 17 展示了异常检测示例。若监控系统检测到显著偏离预期模式(如准确率骤降或分布外样本),可发出警报,提示模型或数据管道可能存在故障,实现早期干预和故障缓解。

一致性校验与数据验证
一致性校验和数据验证确保 ML 系统各阶段数据的完整性和正确性,帮助检测数据损坏、不一致或错误。例如,在分布式 ML 系统中,多节点协作训练模型时,可通过一致性校验验证共享参数的完整性。每个节点可在训练前后计算参数的校验和或哈希值,如图 17 所示,通过比对校验和检测不一致或数据损坏。输入数据和模型输出也可进行范围校验,确保在合理区间。例如,自动驾驶感知系统检测到物体尺寸或速度异常,可能提示传感器或算法故障。
心跳与超时机制
心跳和超时机制常用于分布式系统,检测组件存活性和响应性,与硬件中的看门狗定时器类似。例如,分布式 ML 系统中,多节点协作完成数据预处理、训练或推理任务,可通过心跳机制监控各节点健康状态。每节点定期向协调器或其他节点发送心跳,表明自身状态。若某节点在规定超时时间内未发送心跳(如图 18 所示),则视为故障,可重新分配任务或启动故障转移。大规模分布式训练集群中,网络分区每天影响 1-10% 节点,心跳系统需区分节点故障与网络异常,避免误触发故障转移。超时机制还可检测和处理卡死或无响应组件,如数据加载过程超时,系统可采取纠正措施。

软件实现容错(SIFT)技术
SIFT 技术在软件层引入冗余和故障检测机制,提升系统可靠性和容错性。例如,N 版本编程是一种 SIFT 技术,由不同团队独立开发多个等价软件组件,可应用于 ML 系统中的模型推理引擎。多版本推理引擎并行执行,比对输出一致性,多数输出为正确结果,若有分歧则触发错误处理。另一例是基于软件的纠错码(如 Reed-Solomon 码),用于数据存储或传输的错误检测和纠正,如图 19 所示。通过为数据增加冗余,实现一定范围内的错误检测和修正,增强系统容错能力。

硬件故障小结
表 3 对比分析了瞬态、永久和间歇性故障,列出了区分这三类故障的主要特征或维度。下表总结了相关维度,并进一步探讨了三类故障的细微差别。
硬件故障只是系统脆弱性的一个维度,实际中很少单独发生。我们讨论的物理失效常常与 AI 系统的算法组件弱点相互作用。例如,攻击者可通过精心设计的输入,利用硬件故障暴露的模型漏洞——这正是下一节输入级攻击的关注重点。
| 维度 | 瞬态故障 | 永久故障 | 间歇性故障 |
|---|---|---|---|
| 持续时间 | 短暂、临时 | 持续存在,需修复或更换 | 零散出现,间歇性消失 |
| 持久性 | 故障条件消失后即消失 | 持续存在,直至修复 | 不规则复现,非持续存在 |
| 成因 | 外部因素(如电磁干扰、宇宙射线) | 硬件缺陷、物理损坏、老化 | 硬件条件不稳定、连接松动、部件老化 |
| 表现 | 位翻转、毛刺、临时数据损坏 | 卡死、部件损坏、设备完全失效 | 偶发位翻转、信号异常、零散故障 |
| 对 ML 影响 | 引入临时计算误差或噪声 | 持续性错误或失效,影响可靠性 | 零散且不可预测的错误,难以诊断和缓解 |
| 检测方法 | 错误检测码、与期望值比对 | 内建自测试、错误检测码、一致性校验 | 异常监控、错误模式分析与相关性分析 |
| 缓解措施 | 纠错码、冗余、检查点与重启 | 硬件修复或更换、部件冗余、故障转移机制 | 稳健设计、环境控制、运行时监控、容错技术 |
意图性输入操控
输入级攻击代表了一种不同于无意硬件故障的威胁模型。与随机位翻转和组件故障不同,这些攻击涉及故意操控数据以破坏系统行为。这些复杂的攻击通过精心设计的输入或损坏的训练数据操控 ML 模型行为。这些攻击载体可以放大硬件故障的影响,例如,当攻击者专门设计输入以触发故障的边缘情况时。
对抗性攻击
概念基础
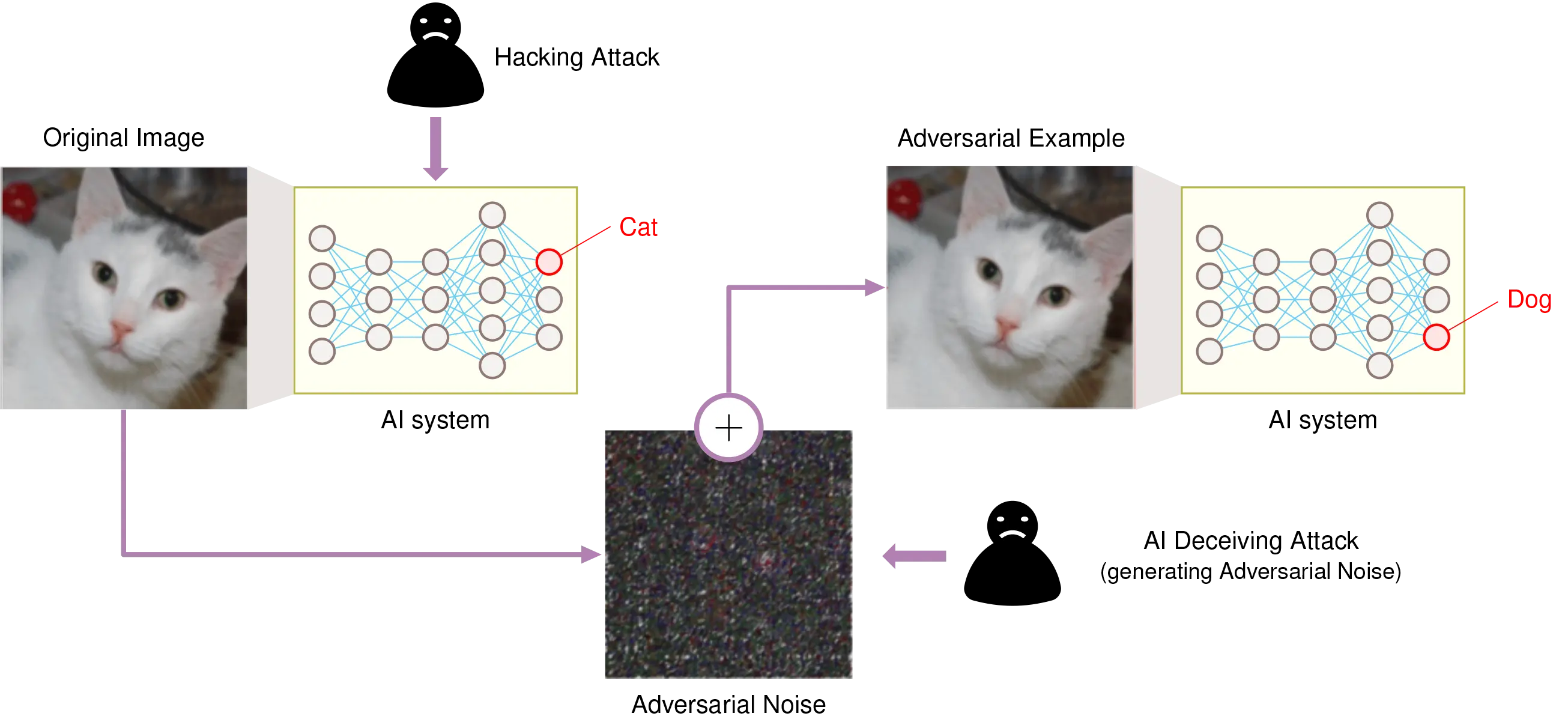
对抗性攻击的核心思想出奇简单:对输入添加微小的、经过精确计算的变化,以愚弄模型,同时对人类保持隐形。想象一下,在一张猫的照片上调整几个像素,这些变化微妙到你无法看出,但模型却以 99% 的置信度将其分类为烤面包机。这种违反直觉的脆弱性源于神经网络处理信息的方式与人类的不同。
为了通过类比理解其潜在机制,可以考虑一个通过寻找尖耳朵来识别猫的人。对这个人来说,对一张狗的照片进行对抗性攻击,就像在狗的垂耳上几乎看不见的地方仔细画上小尖耳朵。因为这个人的算法过于依赖尖耳朵这个特征,他们自信地将狗错误分类为猫。这就是对抗性攻击的工作原理:它们找到模型依赖的特定特征(通常是表面的),并加以利用,即使这些变化对人类观察者来说毫无意义。
ML 模型学习统计模式,而不是语义理解。它们在高维空间中操作,在那里决策边界可能出奇脆弱。在这个空间中,微小的移动(在输入域中不可察觉)可以越过这些边界并触发错误分类。
技术机制
对抗性攻击利用 ML 模型对微小输入扰动的敏感性,这些扰动对人类是不可察觉的,但会导致模型输出的剧烈变化。这些攻击揭示了模型学习决策边界和从训练数据中泛化的脆弱性。其数学基础依赖于模型的梯度信息,以识别最有效的扰动方向。
快速梯度符号法(FGSM) 是最早和最有影响力的对抗性攻击技术之一。FGSM 通过在损失函数的梯度方向上添加小扰动来生成对抗样本,有效地将输入“推向”错误分类的边界。例如,对于 ImageNet 分类器,使用 ε = 8/255(几乎不可察觉的扰动)的 FGSM 攻击可以将准确率从 76% 降至 10% 以下,证明了深度网络对小输入修改的脆弱性。
投影梯度下降(PGD)攻击通过迭代地施加小扰动并投影回允许的扰动空间,扩展了 FGSM。使用 40 次迭代和步长 α = 2/255 的 PGD 攻击在未防御模型上几乎达到 100% 的攻击成功率,将 CIFAR-10 的准确率从 95% 降至 5% 以下。这些攻击被认为是最强的一级对抗攻击,并作为评估防御机制的基准。
物理世界攻击对部署的 AI 系统构成特别挑战。研究表明,对抗性示例可以在打印、拍照或屏幕显示时保持其攻击有效性。停止标志攻击在交通标志上放置物理补丁时达到 87% 的错误分类率,导致自动驾驶车辆将“停止”标志误解为“限速 45”的标志,可能导致灾难性后果。实验室研究表明,对抗性示例在不同光照条件(2,000-10,000 lux)、视角(±30 度)和相机距离(2-15 米)下保持有效。
数据中毒攻击
数据中毒攻击通过向训练数据集中注入恶意样本,导致模型学习错误的关联或在特定输入上表现出特定行为,从而针对训练阶段。这些攻击在训练数据来自不可信来源或通过众包收集的场景中尤为令人担忧。
标签翻转攻击修改训练样本的标签,以引入错误的关联。研究表明,在 CIFAR-10 中仅翻转 3% 的标签,就会将目标类别的准确率从 92% 降至 11%,而整体模型准确率仅下降 2-4%,这使得检测变得困难。对于 ImageNet,损坏 0.5% 的标签(6,500 张图像)会导致特定类别的目标错误分类率超过 90%,同时保持 94% 的干净准确率。
后门攻击向训练样本中注入特定触发模式,当测试输入中存在触发器时,导致模型表现出攻击者控制的行为。研究表明,在仅 1% 的训练数据中插入后门触发器,在带有触发器的测试输入上实现 99.5% 的攻击成功率。模型在干净输入上的表现正常,但在包含后门触发器的输入上会持续错误分类,而干净准确率通常下降不到 1%。
基于梯度的中毒攻击伪装成良性样本,但导致训练期间的梯度更新朝向攻击者目标移动。这些攻击需要精确的优化,但可能造成毁灭性后果:在 CIFAR-10 中中毒 50 张精心制作的图像(占训练数据的 0.1%)使目标错误分类率超过 70%。其计算成本很高,生成最佳中毒样本需要 15-20$\times$ 的训练时间,但通过视觉检查无法检测到攻击。
检测与缓解策略
稳健的 AI 系统针对输入级攻击采用多种防御机制,遵循我们统一框架中建立的检测、优雅降级和自适应响应原则。
输入清洗通过预处理技术去除或减少对抗性扰动,防止其到达模型。将 JPEG 压缩质量因子设置为 75% 可消除 60-80% 的对抗性示例,同时仅降低 1-2% 的干净准确率。使用高斯滤波器(σ = 0.5)的图像去噪可以阻止 45% 的 FGSM 攻击,但需要仔细调整以避免降低合法输入的质量。随机旋转(±15°)和缩放(0.9-1.1$\times$)等几何变换提供 30-50% 的防御效果,且对干净准确率的损失很小。
对抗性训练将对抗性示例纳入训练过程,教会模型在存在对抗性扰动的情况下保持正确预测。在 CIFAR-10 上进行 PGD 对抗性训练可使 ε = 8/255 攻击的稳健准确率达到 87%,而未防御模型的稳健准确率为 0%。尽管干净准确率从 95% 降至 84%,但训练时间由于每个时期都要生成对抗性示例而增加 6-10$\times$,需要专用硬件加速以实现实际应用。
认证防御提供了在指定扰动范围内对模型稳健性的数学保证。随机平滑对 ImageNet 的 ℓ2 扰动实现 67% 的认证准确率(σ = 0.5),而干净准确率为 76%。对于 54% 的测试输入,认证半径增加到 ε = 1.0,提供可证明的稳健性保证。然而,由于需要进行蒙特卡罗采样(通常每个预测 1,000 个样本),推理时间增加了 100-1000$\times$。
集成方法利用多个模型或检测机制来识别和过滤对抗性输入。经过独立训练的 5 个模型的集成,使用预测熵阈值(τ = 1.5)对对抗性示例的检测率达到 94%,在干净数据上的误报率低于 2%。计算开销与集成大小成线性比例,5 模型集成需要 $5\times$ 的推理时间和内存,实时部署具有挑战性。
虽然输入级攻击代表了故意破坏模型行为的尝试,但 AI 系统还必须应对其操作环境中自然变化的挑战,这些变化可能同样具有破坏性。
环境变化
稳健 AI 的第三个支柱解决了自然演变的现实条件,这些条件可能随着时间的推移而降低模型性能。与输入级攻击的故意操控或硬件故障的随机性不同,环境变化反映了在动态环境中部署静态模型所固有的挑战,在这些环境中,数据分布、用户行为和操作上下文不断演变。这些变化可能与其他脆弱性类型协同作用。例如,经历分布变化的模型可能更容易受到对抗性攻击,而硬件错误在不同环境条件下可能表现不同。
分布变化与概念漂移
直观理解
考虑一个在现代医院的 X 光图像上训练的医疗诊断模型。当部署在配备较旧设备的乡村诊所时,模型的准确率骤降,这并不是因为基础的医疗条件发生了变化,而是因为图像特征不同。这就是分布变化的典型例子:模型所遇到的世界与其学习的世界不同。
分布变化是环境演变的自然结果。用户偏好季节性变化,语言随着新俚语的出现而演变,经济模式也随着市场条件的变化而变化。与需要恶意意图的对抗性攻击不同,这些变化是由现实世界系统的动态特性自然产生的。
技术类别
协变量变化是指输入分布变化,而输入与输出之间的关系保持不变。以自主车辆感知模型为例,在白天图像(亮度 1,000-100,000 lux)上训练的模型在夜间条件(0.1-10 lux)下部署时,准确率下降 15-30%,尽管物体识别任务没有变化。天气条件引入的协变量变化也很明显:雨天物体检测的平均精度(mAP)下降 12%,雪天下降 18%,雾天下降 25%,而与晴朗天气相比。
概念漂移是指输入与输出之间的基本关系随时间变化。信用卡欺诈检测系统的相关性在 6 个月内衰减率为 0.2-0.4,要求模型每 90-120 天重新训练一次,以保持超过 85% 的精度。电子商务推荐系统由于季节性偏好变化和用户行为模式演变,在 3-6 个月内准确率下降 15-20%。
标签变化是指输出类别的分布发生变化,但输入输出关系不变。新冠疫情导致医疗影像领域的标签发生剧烈变化:肺炎发生率在某些医院系统中从 12% 增加到 35%,需要重新校准诊断阈值。农业监测中的季节性标签变化显示,作物病害发生率在生长季节之间变化 40-60%,需要自适应决策边界以准确预测产量。
监控与适应策略
有效应对环境变化需要持续监控部署条件和自适应机制,以维持模型性能。
统计距离度量通过测量训练数据和部署数据分布之间的差异,定量评估分布变化的程度。使用 RBF 核的最大均值差异(MMD)(γ = 1.0)对 Cohen’s d > 0.5 的变化提供 0.85 的检测灵敏度,处理 10,000 个样本仅需 150 毫秒。Kolmogorov-Smirnov 检验对单变量变化的检测率达到 95%(样本数超过 1,000),但对高维数据的扩展性较差。人口稳定性指数(PSI)在 0.1-0.25 的阈值指示显著变化,需对模型进行调查。
在线学习使模型能够在保持对先前学习模式的性能的同时,持续适应新数据。随机梯度下降(SGD)在学习率 η = 0.001-0.01 下对概念漂移适应的收敛性在 100-500 个样本内实现。内存开销通常需要 2-5 MB,以维持足够的历史上下文,而计算开销在实时适应中增加 15-25% 的推理延迟。弹性权重巩固通过正则化系数 λ = 400-40,000 防止灾难性遗忘。
模型集成与选择维持多个针对不同环境条件优化的模型,根据检测到的环境特征动态选择最合适的模型。由 3-7 个模型组成的集成系统在分布变化下的准确率比单一模型高出 8-15%,选择开销为每个预测 2-5 毫秒。基于近期表现的动态加权(滑动窗口 500-2,000 个样本)提供了对逐渐漂移的最佳适应。
联邦学习使分布在多个部署环境中的模型能够在保护隐私的同时进行分布式适应。具有 50-1,000 个参与者的 FL 系统在 10-50 次通信轮次内收敛,每次轮次需要 10-100 MB 的参数传输,具体取决于模型大小。每轮的本地训练通常需要 5-20 个周期,当带宽低于 1 Mbps 时,通信成本占主导地位。差分隐私(ε = 1.0-8.0)添加噪声,但在大多数应用中保持超过 90% 的模型实用性。
稳健性评估工具
在研究了稳健 AI 的三大支柱——硬件故障、输入级攻击和环境变化——之后,学生们现在具备了理解专门用于稳健性评估和改进的工具和框架的概念基础。这些工具在所有三类威胁中实施检测、优雅降级和自适应响应原则。
硬件故障注入工具如 PyTorchFI 和 TensorFI 使得系统地测试 ML 模型对前面描述的瞬态、永久和间歇性故障的稳健性成为可能。对抗性攻击库实现了 FGSM、PGD 和认证防御技术,用于评估输入级稳健性。分布监测框架提供了统计距离度量和漂移检测能力,这对于环境变化管理至关重要。
现代稳健性工具可以直接与流行的 ML 框架(PyTorch、TensorFlow、Keras)集成,使稳健性评估无缝融入 第 13 章:机器学习运维 中建立的开发工作流程。有关这些工具及其实际应用的全面审查见于 第 16 章:稳健 AI ,提供了构建稳健 AI 系统的详细实施指南。
输入级攻击与模型稳健性
虽然硬件故障代表了对基础计算基础设施的无意干扰,但模型稳健性问题则扩展到针对 AI 系统决策过程的故意攻击以及操作环境的自然变化。从硬件可靠性到模型稳健性的转变,反映了保护计算的物理基底与防御定义模型行为的学习表示和决策边界之间的转变。
这种转变需要改变视角。硬件故障通常表现为计算、内存或通信错误,这些错误以可预测的方式通过系统传播,受到底层计算图的指导。相比之下,模型稳健性挑战则利用或暴露了模型对其问题域理解的核心局限性。对抗性攻击精心制作输入以触发错误分类,数据中毒攻击则破坏训练过程本身,而分布变化则揭示了模型在超出训练假设的部署时的脆弱性。
根据 第 16 章:稳健 AI 中的三类威胁框架,不同类型的挑战需要互补的防御策略。硬件故障缓解通常依赖于冗余、错误检测码和优雅降级,而模型稳健性则需要对抗性训练、输入清洗、领域适应和持续监控模型行为等技术。
理解这种双重视角的重要性在于,现实世界的 AI 系统面临复合威胁,其中硬件故障和模型脆弱性可能以复杂方式相互作用。损坏模型权重的硬件故障可能会产生新的对抗性脆弱性,而对抗性攻击可能会触发类似硬件故障的错误条件。我们在 第 16 章:稳健 AI 中提出的统一框架,为系统地解决这些相互关联的挑战提供了概念基础。
对抗性攻击
对抗性攻击揭示了现代机器学习系统中的违反直觉的脆弱性。这些攻击利用神经网络学习和表示信息的核心特性,揭示了模型对精心制作的、对人类观察者不可察觉的输入修改的极端敏感性。这些攻击通常涉及向输入数据添加微小的、经过精确设计的扰动,可能导致模型错误分类,如图 20 所示。
理解脆弱性
要理解这些攻击为何如此有效,就需要检查它们暴露的神经网络架构的核心局限性。对抗性示例的存在揭示了人类感知与机器感知之间的根本差异33。
这种脆弱性源于神经网络学习的几个特性34。高维输入空间35 为攻击者同时利用多个维度提供了可能。
理解对抗性示例存在的深层原因,对于开发有效的防御措施至关重要。这种脆弱性反映了神经网络在高维空间中处理和表示信息的核心特性,而不仅仅是软件错误或训练工件。解释神经网络36 天生容易受到对抗性扰动影响的理论基础,详见 第 3 章:深度学习基础 .
攻击类别与机制
对抗性攻击可以根据其扰动生成方法和攻击者可用信息的不同,分为几类。每种类别利用模型脆弱性的不同方面,需采取不同的防御措施。
基于梯度的攻击
最直接和广泛研究的类别是基于梯度的攻击,它利用神经网络训练的一个核心方面:用于训练模型的相同梯度信息可以被用作攻击模型的武器。这些攻击通过利用模型自身的学习机制,反向运行训练过程,揭示了对抗性示例生成的直接方法。
概念基础
基于梯度的攻击的关键见解在于,神经网络计算梯度是为了了解输入变化如何影响输出。在训练过程中,梯度指导权重更新以最小化预测错误。对于攻击而言,这些相同的梯度揭示了哪些输入修改将最大化预测错误——本质上是反向运行训练过程。
为了说明这一概念,考虑一个在照片中正确识别猫的图像分类模型。相对于输入图像的梯度显示了模型预测对每个像素变化的敏感性。攻击者可以利用这个梯度信息,确定最有效的修改特定像素的方法,从而改变模型的预测,例如,可能导致模型将猫错误分类为狗,同时保持对人类观察者的不可察觉性。
快速梯度符号法(FGSM)
快速梯度符号法37 是基于梯度的攻击中最具代表性和危险性的攻击之一。FGSM 采取了一个概念上简单的方法,即朝着最迅速增加模型预测错误的方向移动。
其基本数学公式直观地捕捉了这一过程:
$$ x_{\text{adv}} = x + \epsilon \cdot \text{sign}\big(\nabla_x J(\theta, x, y)\big) $$
其中各成分表示:
- $x$: 原始输入(如猫的图像)
- $x_{\text{adv}}$: 将愚弄模型的对抗性示例
- $\nabla_x J(\theta, x, y)$: 表示对每个输入特征的损失函数变化的梯度,指示哪些输入修改最有效地增加模型预测错误
- $\text{sign}(\cdot)$: 仅提取变化方向,忽略幅度差异
- $\epsilon$: 控制扰动强度(通常为归一化输入的 0.01-0.3)
- $J(\theta, x, y)$: 测量预测错误的损失函数
梯度 $\nabla_x J(\theta, x, y)$ 量化了损失函数相对于每个输入特征的变化,指示哪些输入修改最有效地增加模型预测错误。函数 $\text{sign}(\cdot)$ 提取了最陡上升的方向,而扰动幅度 $\epsilon$ 控制施加于每个输入维度的修改强度。
该方法通过朝着最迅速增加损失的方向迈出一步,生成对抗性示例,如图 21 所示。
在此基础上,投影梯度下降(PGD)攻击通过迭代施加梯度更新步骤,扩展了 FGSM,生成更精细和强大的对抗性示例。PGD 在原始输入周围的约束范数球内投影每次扰动步骤,从而确保对抗性示例保持在指定的失真限制内。这使得 PGD 成为更强的白盒攻击和评估模型稳健性的基准。
基于雅可比的显著性图攻击(JSMA)是另一种基于梯度的方法,它识别最有影响力的输入特征并对其施加扰动以创建对抗性示例。通过构建基于模型输出相对于输入的雅可比矩阵的显著性图,JSMA 有选择地改变少量最可能影响目标类别的输入维度。这使得 JSMA 比 FGSM 或 PGD 更加精确和有针对性,通常需要更少的扰动就能愚弄模型。
基于梯度的攻击在攻击者完全了解目标模型(如模型架构和梯度)的白盒环境中尤其有效。它们的效率和相对简单性使其成为研究中攻击和评估模型稳健性的常用工具。
基于优化的攻击
虽然基于梯度的方法提供了速度和简单性,但基于优化的攻击将对抗性示例的生成形式化为更复杂的优化问题。Carlini 和 Wagner(C&W)攻击就是这一类别中的一个突出例子。它找到可以导致错误分类的最小扰动,同时保持与原始输入的感知相似性。C&W 攻击采用迭代优化过程,最小化扰动的同时最大化模型的预测错误。它使用自定义损失函数和置信度项,以生成更有把握的错误分类。
C&W 攻击尤其难以检测,因为扰动通常对人类不可察觉,并且往往可以绕过许多现有的防御。根据所需的对抗性扰动特性,攻击可以在各种范数约束(如 L2、L∞)下进行表述。
扩展这一优化框架,弹性网攻击(EAD)结合了弹性网正则化(L1 和 L2 惩罚的组合),以生成具有稀疏扰动的对抗性示例。这可以导致对输入的最小和局部化的变化,从而更难以识别和过滤。EAD 在需要对扰动的幅度和空间范围进行约束的设置中尤其有用。
这些攻击比基于梯度的方法计算上更为密集,但提供了对对抗性示例属性的更精细控制,通常需要在 第 10 章:模型优化 中详细介绍的专用优化技术。它们通常用于对隐蔽性和精确度要求较高的高风险领域。
基于迁移的攻击
基于迁移的攻击则利用了对抗性示例的可迁移性38。可迁移性是指为一个 ML 模型生成的对抗性示例,往往也能愚弄其他模型,即使它们具有不同的架构或在不同的数据集上训练。这使得攻击者能够使用代理模型生成对抗性示例,然后将其转移到目标模型上,而无需直接访问其参数或梯度。
基于迁移的攻击特别适用于实际威胁场景,例如攻击商业 ML API,在这些场景中,攻击者可以观察输入和输出,但无法访问内部计算。攻击成功通常取决于模型之间的相似性、训练数据的一致性以及使用的正则化技术等因素。可以使用输入多样性(随机调整大小、裁剪)和优化过程中的动量等技术来提高可迁移性。
物理世界攻击
物理世界攻击将对抗性示例带入现实场景。这些攻击涉及创建物理对象或操控,使其在被传感器或相机捕捉时能够欺骗 ML 模型。对抗性补丁就是一个例子,它们是小型、精心设计的图案,可以放置在物体上,以愚弄物体检测或分类模型。这些补丁被设计成能够在不同的光照条件、视角和距离下工作,从而在现实环境中具有稳健性。
当附加在真实物体上时,例如停止标志或衣物,对抗性补丁可以导致模型错误分类或未能准确检测物体。值得注意的是,这些攻击的有效性在打印出来并通过相机镜头观察后仍然存在,弥合了对抗性机器学习中数字和物理之间的鸿沟。
对抗性物体(如 3D 打印的雕塑或修改过的交通标志)也可以被制作出来,以在物理环境中欺骗 ML 系统。例如,一种 3D 海龟对象即使从不同角度观察,也被图像分类器始终错误地分类为步枪。这些攻击突显了在物理空间中部署的 AI 系统面临的风险,例如自动驾驶车辆、无人机和监视系统,并提出了负责任的 AI 部署的关键考虑,详见 第 17 章:可信 AI .
物理世界攻击的研究还包括开发通用对抗性扰动的努力,即可以欺骗多种输入和模型的扰动。这些威胁对 AI 系统的安全性、稳健性和泛化能力提出了严峻挑战。
总结
表 4 简要概述了不同类别的对抗性攻击,包括基于梯度的攻击(FGSM、PGD、JSMA)、基于优化的攻击(C&W、EAD)、基于迁移的攻击和物理世界攻击(对抗性补丁和物体)。每种攻击都有简要描述,突出了其关键特征和机制。
对抗性攻击的机制揭示了 ML 模型的决策边界、输入数据和攻击者目标之间的复杂相互作用。通过精心操控输入数据,攻击者可以利用模型的敏感性和盲点,导致错误的预测。对抗性攻击的成功凸显了对 ML 模型稳健性和泛化能力的深入理解的必要性。
| 攻击类别 | 攻击名称 | 描述 |
|---|---|---|
| 基于梯度的攻击 | 快速梯度符号法(FGSM)投影梯度下降(PGD)雅可比显著性图攻击(JSMA) | 通过在梯度方向添加小噪声来扰动输入数据,以最大化预测错误。通过迭代应用梯度更新步骤来扩展 FGSM,以获得更精细的对抗性示例。识别最有影响力的输入特征并对其施加扰动以创建对抗性示例。 |
| 基于优化的攻击 | Carlini 和 Wagner(C&W)攻击 弹性网攻击(EAD) | 找到导致错误分类的最小扰动,同时保持感知相似性。结合弹性网正则化生成具有稀疏扰动的对抗性示例。 |
| 基于迁移的攻击 | 基于可迁移性的攻击 | 利用对抗性示例在不同模型之间的可迁移性,实现黑盒攻击。 |
| 物理世界攻击 | 对抗性补丁 对抗性物体 | 小型、精心设计的补丁,放置在物体上以愚弄物体检测或分类模型。制作的物理对象(如 3D 打印的雕塑、修改过的交通标志),在物理环境中欺骗 ML 系统。 |
防御对抗性攻击需要 第 16 章:稳健 AI 中详细介绍的多方面防御策略,包括对抗性训练、防御性蒸馏、输入预处理和集成方法。
随着对抗性机器学习的发展,研究人员探索新的攻击机制并开发更复杂的防御措施。攻击者和防御者之间的军备竞赛推动了确保 ML 系统抵御对抗性威胁的不断创新和警惕。理解攻击机制对于开发稳健可靠的 ML 模型,抵御不断演变的对抗性示例至关重要。
对 ML 的影响
对抗性攻击对 ML 系统的影响远超简单的错误分类,如图 22 所示。这些脆弱性在部署领域造成系统性风险。

对抗性攻击影响的一个显著例子是 2017 年的研究。研究人员在停车标志上实验性地粘贴了小黑白贴纸。这些贴纸在视觉上并未遮挡标志或影响其可读性。然而,当这些贴纸修改的停车标志的图像被输入到标准的交通标志分类 ML 模型中时,结果令人震惊。模型错误地将停车标志分类为限速标志的概率超过 85%。
这一实验揭示了简单的对抗性贴纸如何欺骗 ML 系统,导致其错误解读关键交通标志的惊人潜力。这种攻击在现实世界中的影响是重大的,特别是在自动驾驶汽车的背景下。如果在实际道路上部署,这些对抗性贴纸可能导致自动驾驶汽车将停车标志误解为限速标志,从而导致危险情况,如图 23 所示。研究人员警告说,这可能导致车辆在路口未能停车或意外加速,危及公共安全。
微软的 Tay 聊天机器人则提供了一个对抗性用户如何利用部署 AI 系统中稳健性缺失的明显例子。在发布后的 24 小时内,协调用户操纵 Tay 的学习机制,生成不当和攻击性的内容。该系统缺乏内容过滤、用户输入验证和行为监控等保护措施,未能抵御对抗性攻击。这一事件凸显了对部署的 AI 系统,特别是那些从用户交互中学习的系统,进行全面输入验证、内容过滤系统和持续行为监控的关键必要性。

这一示范说明了对抗性示例如何利用 ML 模型模式识别中的基本脆弱性。攻击的简单性——对人类不可察觉的轻微输入修改导致预测的剧烈变化——揭示了深层次的架构限制,而非表面错误。
除了性能下降,对抗性脆弱性还会导致级联的系统风险。在医疗领域,针对医疗影像的攻击可能导致误诊。在金融系统中,交易算法可能被操纵,导致经济损失。这些脆弱性通过暴露模型对肤浅模式而非稳健概念理解的依赖,根本上破坏了模型的可信度。
防御对抗性攻击通常需要额外的计算资源,并可能影响整体系统性能。对抗性训练等技术,通过在对抗性示例上训练模型以提高稳健性,可能显著增加训练时间和计算需求。运行时检测和缓解机制(如输入预处理或预测一致性检查)会引入延迟,影响 ML 系统的实时性能。
对抗性脆弱性的存在还使 ML 系统的部署和维护变得复杂。系统设计者和操作员必须考虑对抗性攻击的可能性,并纳入适当的防御和监控机制。模型的定期更新和重新训练变得必要,以适应新的对抗性技术,并维持系统的安全性和性能。
数据中毒
数据中毒对机器学习系统的完整性和可靠性构成了严峻挑战。攻击者通过在训练流程中引入精心设计的恶意数据,可以在难以通过常规验证程序发现的情况下,悄然操控模型行为。
与对抗性攻击的关键区别在于攻击的时机和目标。对抗性攻击发生在模型训练之后(对测试输入加噪声),而数据中毒则发生在训练之前(污染训练数据本身)。这就像是在考试时欺骗已经学好的学生,和在学生学习过程中灌输错误信息的区别。两者都可能导致错误答案,但利用的是不同阶段的脆弱性:
- 对抗性攻击针对已部署模型,影响推理阶段,可通过监控输出检测
- 数据中毒则针对训练数据,影响学习过程,更难检测,因为模型“诚实地”学到了错误模式
与推理阶段的对抗样本不同,中毒攻击利用系统的上游环节,如数据采集、标注或导入。随着 ML 系统在自动化和高风险环境中的广泛部署,理解中毒如何发生及其在系统中的传播机制,对于制定有效防御至关重要。
数据中毒特性
数据中毒39 是一种通过有意篡改训练数据以破坏机器学习模型性能或行为的攻击,如下文所述并在图 24 中展示。攻击者可能会篡改已有训练样本、引入恶意样本,或干扰数据采集流程,最终导致模型学习到有偏、错误或可被利用的模式。

数据中毒通常分为三个阶段。注入阶段,攻击者将中毒样本混入训练集,这些样本可能是修改过的现有数据,也可能是专门设计的新实例,表面看似正常,实则有意影响模型行为。攻击者可能针对特定类别、插入恶意触发器,或设计离群点以扭曲决策边界。
训练阶段,模型将中毒数据纳入学习,形成虚假或误导性模式。这些关联可能导致模型偏向错误分类、引入后门或漏洞。由于中毒数据在统计上与正常数据相似,常规训练和评估流程往往难以察觉污染过程。
最后,在部署阶段,攻击者利用被破坏的模型实现恶意目的,比如触发特定行为(如输入隐藏模式时误分类),或利用模型性能下降。实际系统中,这类攻击往往难以追溯到训练数据,尤其是系统只在边缘场景或对抗条件下表现异常时。
在医疗等高风险领域,即便训练数据的微小干扰也可能导致危险的误诊或 AI 系统信任危机。
文献中主要识别出四类中毒攻击。可用性攻击通过大规模污染训练数据(如系统性标签翻转,将 $y=1$ 改为 $y=0$),大幅降低整体模型性能,使其在广泛输入下失效。
相比之下,定向中毒攻击只针对特定类别或实例,攻击者只需修改少量数据,就能让特定输入被误分类,而整体准确率基本不变。这种隐蔽性使定向攻击极难检测。
后门中毒40 在训练数据中植入隐藏触发器,模型学会将特定模式与指定输出关联。推理时只要出现触发器,模型就会被操控输出预设结果。即使触发模式对人类不可察觉,这类攻击依然高效。
子群体中毒则针对数据中的特定子集(如某一人群或特征簇),对其进行可用性式破坏,而不影响整体性能。这类攻击在公平性敏感场景下尤为隐蔽且危险。
这些中毒策略的共同点是隐蔽性强。被操控样本通常与正常数据难以区分,难以通过人工检查或常规数据验证发现。操控方式可能是数值微调、标签细微不一致或嵌入视觉模式,均旨在融入数据分布同时影响模型行为。
攻击者既可能是有权限的数据工程师、标注员等内部人员,也可能是利用数据采集流程漏洞的外部攻击者。在众包或开放数据采集场景下,攻击者只需向共享数据集注入恶意样本或影响用户生成内容即可。
关键在于,中毒攻击往往针对 ML 流水线的早期环节(如采集、预处理),这些环节监管有限。如果数据来自未经验证的来源或缺乏强校验,攻击者可悄然注入统计上正常的中毒数据。缺乏完整性校验、异常检测或数据溯源机制会进一步加剧风险。
这些攻击的目标是破坏学习过程本身。被中毒数据训练出的模型可能学到虚假关联、对错误信号过拟合,或对特定条件极易被利用。无论结果是模型性能下降还是被植入后门,系统的可信性和安全性都将严重受损。
数据中毒攻击方式
数据中毒可通过多种机制实现,取决于攻击者对系统和数据流程的了解与访问权限。
最直接的方法是篡改训练数据标签。攻击者选取部分训练样本,将 $y=1$ 改为 $y=0$,或在多分类任务中重新分配类别。如图 25 所示,即便小规模的标签不一致也会导致分布漂移和学习中断。

另一种方式是修改训练样本的输入特征而不改变标签,如对图像像素级微调、结构化数据的细微扰动,或嵌入作为后门攻击触发器的固定模式。这些修改通常通过优化技术设计,既最大化对模型的影响,又最小化可检测性。
更复杂的攻击会生成全新的恶意训练样本。这些合成样本可通过对抗方法、生成模型或数据合成工具创建,目的是精心设计输入,纳入训练集后扭曲模型决策边界。这类输入表面自然合法,实则为模型埋下漏洞。
还有攻击者专注于数据采集和预处理流程的薄弱环节。如果训练数据来自网页爬取、社交媒体或不可信用户提交,恶意样本可在上游注入,经过不充分的清洗或验证后以“可信”形式进入模型。自动化流水线中,人工审核有限或缺失时尤为危险。
在物理部署系统中,攻击者甚至可在数据源头操控数据,例如通过微调路标上的视觉标记,使自动驾驶汽车在训练时学到错误分类。这种环境级中毒模糊了对抗攻击与数据中毒的界限,但本质上都是破坏训练数据。
在线学习系统则是另一类独特的攻击面。这类系统持续适应新数据流,极易被渐进式中毒。攻击者可逐步引入恶意样本,使模型行为缓慢但持续地偏移。如图 26 所示。

内部协作则进一步增加复杂性。拥有合法训练数据访问权限的恶意标注员、研究员或数据供应商,可设计更隐蔽、针对性更强的中毒策略。这些内部人员可能了解模型架构或训练流程,能更有效地实施中毒。
防御这些多样化机制需多管齐下:安全的数据采集协议、异常检测、健壮的预处理流程和严格的访问控制。验证机制不仅要能检测离群点,还要能识别巧妙伪装在统计常模内的中毒样本。
数据中毒对 ML 的影响
数据中毒的影响远不止准确率下降。一般而言,中毒数据集会导致模型被污染,但具体后果取决于攻击向量和攻击者目标。
常见结果是整体性能下降。大规模标签翻转或引入噪声特征后,模型难以识别有效模式,准确率、召回率或精度下降。在医疗诊断、欺诈检测等关键应用中,即便小幅性能损失也可能带来严重后果。
定向中毒则带来另一种风险。这类攻击不破坏模型整体性能,而是导致特定输入被误分类。例如,恶意软件检测器可被设计为忽略某一特征,从而让特定攻击绕过安全防护。人脸识别模型也可能被操控为只对某个人识别失效,其余正常。
部分中毒攻击通过后门或木马植入隐藏漏洞。这类模型在评估时表现正常,但遇到特定触发器时会恶意响应。攻击者可按需“激活”漏洞,绕过系统防护且不触发警报。
偏见是数据中毒的另一隐蔽影响。攻击者若针对特定人群或特征组中毒,可导致模型输出偏向或歧视。这类攻击威胁公平性,放大社会不公,且若整体指标仍高则极难诊断。
归根结底,数据中毒破坏了系统的可信性。即使模型在基准评测中表现良好,只要训练数据被污染,就不能视为可靠。在自动化系统、金融建模和公共政策等领域,这种信任的丧失影响深远。
案例分析:用中毒保护艺术作品
有趣的是,数据中毒并非总是恶意的。研究者已开始探索其作为防御工具的应用,尤其是在保护创作者作品不被生成式 AI 滥用方面。
芝加哥大学团队开发的 Nightshade 就是一个典型案例,帮助艺术家防止作品被爬取用于训练图像生成模型。Nightshade 允许艺术家在发布前对图片施加微妙扰动,这些变化对人类不可见,却会严重破坏将其纳入训练的生成模型。
当 Stable Diffusion 仅用 300 张中毒图片训练后,模型开始输出奇怪结果,如输入“car”时生成奶牛,输入“dog”时生成猫状生物。如图 27 所示,毒化样本能极大扭曲模型的概念关联。

Nightshade 的强大之处在于中毒概念的级联效应。生成模型依赖类别间的语义关系,被毒化的“car”会影响“truck”“bus”“train”等相关概念,导致广泛的幻觉输出。
但如同所有强大工具,Nightshade 也带来风险。用于保护艺术内容的技术同样可被滥用以破坏合法训练流程,凸显现代机器学习安全的“双用途困境”41。
分布变化
分布变化是实际部署 ML 系统中最常见且最具挑战性的稳健性问题之一。与对抗性攻击或数据中毒不同,分布变化多为环境自然演变所致,是系统可靠性的核心难题。本节将分析分布变化的类型、发生机制、对 ML 系统的影响及检测与缓解的实用方法。
分布变化特性
分布变化指 ML 模型在部署时遇到的数据分布与训练时不同,挑战了 第 8 章:AI 训练 和 第 4 章:DNN 架构 中建立的泛化能力,如图 28 所示。这种分布变化往往不是恶意攻击,而是现实环境自然演变的结果。其本质是数据的统计特性、模式或假设在训练与推理阶段发生变化,导致模型性能意外下降。

分布变化通常有以下几种形式:
- 协变量变化:输入分布 $P(x)$ 变化,标签条件分布 $P(y \mid x)$ 不变。
- 标签变化:标签分布 $P(y)$ 变化,$P(x \mid y)$ 不变。
- 概念漂移:输入与输出关系 $P(y \mid x)$ 随时间演变。
这些定义有助于理解实际中常见的分布变化案例。
最常见的原因之一是领域不匹配,即模型部署在与训练数据不同的领域。例如,基于影评训练的情感分析模型在推特上表现不佳,因为语言、语气和结构不同,模型学到的特征难以泛化。
另一大来源是时间漂移,输入分布随时间逐渐或突然变化。生产环境中,数据因新趋势、季节效应或用户行为变化而变化。例如,欺诈检测系统中的欺诈模式会随着攻击者策略演变。缺乏持续监控或再训练,模型会变得陈旧失效。如图 29 所示。
情境变化则源于部署环境与训练条件的外部差异,如光照、传感器差异或用户行为。例如,在实验室受控光照下训练的视觉模型,在户外或动态环境中表现会下降。
训练数据代表性不足也是一个关键因素。如果训练集未能覆盖生产环境的全部变异性,模型泛化能力会很差。例如,人脸识别模型若主要在某一人群上训练,部署后对其他人群预测会偏差或不准确。这种变化反映了训练数据多样性或结构的缺失。

分布变化会极大降低 ML 模型在生产环境中的性能和可靠性。构建稳健系统不仅要理解这些变化,还要主动检测和应对。
特斯拉 Autopilot 系统展示了现实部署中的分布变化如何挑战先进 ML 系统。视觉系统主要在高速公路数据上训练,遇到施工区、特殊路况和天气变化时性能下降,难以处理训练数据未覆盖的边缘场景,如施工障碍、特殊车道标记和临时交通模式。这凸显了多样化训练数据采集和稳健分布变化处理在安全关键应用中的重要性。
分布变化机制
分布变化源于多种自然和系统驱动机制。理解这些机制有助于检测、诊断和设计缓解策略。
常见机制之一是数据源变化。推理时数据来自与训练时不同的传感器、API、平台或硬件,即使分辨率、格式或噪声的微小差异也会引入显著变化。例如,语音识别模型在不同麦克风类型上的表现可能差异很大。
时间演化指底层数据随时间变化。推荐系统中用户偏好变化,金融领域市场条件变化。这些变化可能缓慢连续,也可能突然剧烈。缺乏时间感知或持续评估,模型常常在毫无预警的情况下失效。图 30 通过犬种的选择性育种展示了时间演化的影响。早期犬种体型瘦长,现代则更为健壮,头型和肌肉结构明显不同。这类似于 ML 应用中数据分布随时间演变,初始训练数据与后续数据可能差异巨大。正如进化压力塑造生物特征,用户行为、市场力量或环境变化会改变 ML 系统中的数据分布。若不定期再训练或适应,模型在新分布下会表现不佳甚至失效。

领域特异性变化则指模型在一个环境训练后应用于另一个环境。例如,医疗诊断模型在不同医院部署时,由于设备、人口或流程差异,表现会下降。这类变化通常需领域泛化或微调等适应策略。
选择偏差则源于训练数据未能准确反映目标人群,可能由采样策略、数据访问限制或标注选择导致。结果是模型对特定群体过拟合,泛化能力差。需通过合理采集和持续验证解决。
反馈回路是一种更隐蔽的机制。在某些系统中,模型预测会影响用户行为,进而影响未来输入。例如,动态定价模型会改变购买模式,进而扭曲未来训练数据分布。这些回路会强化狭窄模式,使模型行为难以预测。
最后,攻击者可通过引入分布外样本或精心设计输入,故意诱发分布变化,利用模型决策边界的薄弱点。这些输入远离训练分布,可能导致模型输出异常或不安全。
这些机制常常相互作用,使实际分布变化的检测和缓解极为复杂。从系统角度看,这要求持续监控、日志和反馈流水线——而这些功能在早期或静态 ML 部署中常常缺失。
分布变化对 ML 的影响
分布变化几乎影响 ML 系统性能的所有维度,包括预测准确率、延迟、用户信任和系统可维护性。
最直接的后果是预测性能下降。推理时数据与训练数据不同,模型可能系统性地产生不准确或不一致的预测。在高风险应用(如欺诈检测、自动驾驶、临床决策支持)中,这种准确率下降尤为危险。
另一个严重影响是可靠性和信任度下降。分布变化后,用户可能注意到系统行为不一致或异常。例如,推荐系统可能开始推送无关甚至冒犯性内容。即使整体准确率尚可,用户信任的丧失也会削弱系统价值。
分布变化还会放大模型偏见。若训练数据中某些群体或片段代表性不足,模型在这些群体上的失败率会更高。分布变化下,这些失败会更加突出,导致歧视性结果或公平性问题。
医疗领域的 ML 模型常因分布变化而在不同医院部署时性能下降。例如,基于某医院 CT 扫描仪数据训练的诊断模型,在不同厂家或协议下的图像上准确率下降。这说明即使是采集流程和设备的微小差异,也会造成显著分布变化,影响模型性能甚至患者安全。
不确定性和运维风险也随之增加。生产环境中,模型决策常直接驱动业务或自动化操作。分布变化下,这些决策变得不可预测、难以验证,增加了级联故障或错误决策的风险。
从系统维护角度看,分布变化会复杂化再训练和部署流程。缺乏健全的漂移检测和性能监控,变化常常在性能严重下降后才被发现。一旦检测到,需再训练,涉及数据采集、标注、模型回滚和验证等挑战。这会增加 CI/CD 流程的摩擦,显著降低迭代效率。
分布变化还会增加对抗性攻击风险。攻击者可利用模型在陌生数据上的校准失效,通过微小扰动将输入推离训练分布,导致系统性失败。系统存在反馈回路或自动决策流水线时尤为危险。
从系统角度看,分布变化不仅是建模问题,更是核心运维挑战。需要端到端的系统支持,包括数据日志、漂移检测、自动告警、模型版本管理和定期再训练。ML 系统必须能够检测生产环境性能下降,诊断是否由分布变化引起,并触发相应缓解措施,如人工审核、回退策略、再训练流水线或分阶段部署。
在成熟的 ML 系统中,应对分布变化已成为基础设施、可观测性和自动化问题,而不仅仅是建模技巧。忽视分布变化,系统将在动态现实环境中悄然失效——而这正是 ML 系统最应发挥价值的地方。
下表总结了常见分布变化类型、对模型性能的影响及系统级应对措施。
| 分布变化类型 | 原因或示例 | 对模型的影响 | 系统级应对措施 |
|---|---|---|---|
| 协变量变化 | 输入特征变化(如传感器校准漂移) | 标签不变但模型错误分类新输入 | 监控输入分布,基于新特征再训练 |
| 标签变化 | 标签分布变化(如使用场景中新类别频率变化) | 预测概率偏斜 | 跟踪标签先验,重加权或校准输出 |
| 概念漂移 | 输入输出关系演变(如欺诈手法变化) | 性能随时间下降 | 频繁再训练,采用持续/在线学习 |
| 领域不匹配 | 训练用影评,部署于推特 | 词汇或风格不同导致泛化差 | 领域适应或微调 |
| 情境变化 | 新部署环境(如光照、用户行为) | 性能随环境变化 | 采集情境数据,监控条件准确率 |
| 选择偏差 | 训练时代表性不足 | 对未见群体预测有偏 | 验证数据集平衡,扩充训练数据 |
| 反馈回路 | 模型输出影响未来输入(如推荐系统) | 强化漂移,模式不可预测 | 监控反馈效应,考虑反事实日志 |
| 对抗性变化 | 攻击者引入分布外输入或扰动 | 模型易受定向失败攻击 | 稳健训练,检测分布外输入 |
分布变化的系统影响
输入攻击检测与防御
在理解模型脆弱性的理论基础上,下面我们将探讨实际的防御策略。
对抗性攻击防御
在明确了对抗性攻击的机制和影响后,我们进一步分析其检测与防御方法。
检测技术
检测对抗性样本是防御对抗性攻击的第一道防线。已有多种技术用于识别和标记可能为对抗性的可疑输入。
统计方法是一种通过分析输入数据分布属性来检测对抗性样本的方式。这类方法将输入数据分布与参考分布(如训练数据分布或已知良性分布)进行比较。常用技术包括 Kolmogorov-Smirnov 检验42和 Anderson-Darling 检验,可衡量分布间的差异,标记显著偏离预期分布的输入。
除了分布分析,输入变换方法也是一种检测策略。特征压缩(feature squeezing)43 通过降维或离散化减少输入空间复杂度,消除对抗性样本常依赖的微小扰动。
模型不确定性估计则提供了另一种检测范式,通过量化预测置信度来识别异常。对抗性样本常利用模型决策边界的不确定区域,因此高不确定性的输入可被标记为可疑。常见的不确定性估计方法各有精度与计算开销的权衡。
贝叶斯神经网络(Bayesian neural networks)44 通过将权重视为概率分布,利用近似推断同时捕获数据内在(aleatoric)和模型(epistemic)不确定性,提供最为严谨的不确定性估计。集成方法(详见 第 16 章:稳健 AI )通过多个独立模型的预测方差估算不确定性,二者均具备稳健性但计算开销较大。
Dropout45 最初为防止过拟合而设计,通过训练时随机失活部分神经元,促使网络避免对单一神经元的过度依赖、提升泛化能力。该机制可在推理时通过蒙特卡洛 Dropout 多次前向传播近似不确定性分布。尽管这种方法不如专为不确定性设计的贝叶斯方法精确,但结合轻量集成或贝叶斯近似可在效率与质量间取得平衡,适合实际部署。
防御策略
检测到对抗性样本后,可采用多种防御策略缓解其影响、提升模型稳健性。
对抗性训练通过将对抗性样本加入训练集并重新训练模型,使其在训练阶段就学会正确分类对抗性输入,从而提升稳健性。如下代码清单 1 展示了核心实现模式。
对抗性训练虽能提升稳健性,但会带来显著的计算开销,需在生产系统中合理管理。
每步训练需生成对抗性样本,训练时间增加 3-10 倍。动态生成对抗性样本需额外的前向和反向传播,显著增加计算需求。存储干净与对抗性样本及攻击生成时的梯度,内存需求增加 2-3 倍。若采用 PGD 等迭代攻击,需专用基础设施以高效生成对抗性样本。
稳健模型通常需牺牲 2-8% 的干净准确率以换取更强的对抗性稳健性,这是稳健优化目标的基本权衡。若集成方法或不确定性估计与对抗性训练结合,推理时间也会增加。为提升梯度稳定性,模型结构常需加宽或增加归一化层,模型体积也会增大。
在平衡稳健性与性能目标时,超参数调优变得更复杂。验证流程需用多种攻击方法评估干净与对抗性性能,确保稳健性全面。部署基础设施需支持对抗性训练的额外计算需求,包括 GPU 内存和对抗性样本缓存。
清单 1:对抗性训练实现:使用 FGSM 在训练时生成对抗性样本,将干净与扰动数据混合,提升模型对基于梯度攻击的稳健性。
def adversarial_training_step(model, data, labels, epsilon=0.1):
# 使用 FGSM 生成对抗性样本
data.requires_grad_(True)
outputs = model(data)
loss = F.cross_entropy(outputs, labels)
model.zero_grad()
loss.backward()
# 创建对抗性扰动并与干净数据混合
adv_data = data + epsilon * data.grad.sign()
adv_data = torch.clamp(adv_data, 0, 1)
mixed_data = torch.cat([data, adv_data])
mixed_labels = torch.cat([labels, labels])
return F.cross_entropy(model(mixed_data), mixed_labels)
上述实现通过对输入数据计算梯度(第 2190 行)、取符号提取扰动方向(第 2196 行),并将生成的对抗性样本与干净数据混合(第 2199-2200 行),实现动态生成。torch.clamp() 保证像素值有效,最终拼接将批量大小加倍。该方法需精细调整扰动预算 $ϵ$,训练时间通常为标准训练的 2-3 倍(Shafahi 等,2019)。
生产部署模式、MLOps 流水线集成与稳健 ML 系统监控策略详见 第 13 章:机器学习运维 ,大规模分布式稳健性协调与容错见 第 8 章:AI 训练 。
防御性蒸馏通过训练第二个模型(学生模型)模仿原始模型(教师模型)行为。学生模型在教师模型输出的软标签上训练,对小扰动不敏感。推理时使用学生模型可降低对抗性扰动影响,因为其泛化能力更强,对对抗性噪声不敏感。
输入预处理与变换技术尝试在输入进入模型前去除或减弱对抗性扰动,包括图像去噪、JPEG 压缩、随机缩放、填充或随机变换等。通过降低对抗性扰动影响,这些预处理步骤有助于提升模型稳健性。
集成方法通过组合多个模型提升预测稳健性。不同架构、训练数据或超参数的多模型集成可降低对抗性攻击影响。能愚弄单一模型的对抗性样本未必能愚弄集成系统,从而提升整体可靠性。通过为每个模型采用不同预处理或特征表示等多样化技术,还可进一步增强稳健性。
评估与测试
需全面评估和测试对抗性防御技术的有效性,衡量 ML 模型的稳健性。
对抗性稳健性指标量化模型对对抗性攻击的抵抗力,包括模型在对抗性样本上的准确率、愚弄模型所需的平均扰动量,或不同攻击强度下的性能。通过对比不同模型或防御技术的这些指标,可评估和比较其稳健性水平。
标准化的对抗性攻击基准和数据集为评估和比较 ML 模型稳健性提供了统一标准。这些基准包括预生成的对抗性样本数据集及攻击生成工具。常用基准有 MNIST-C 、 CIFAR-10-C 和 ImageNet-C,均包含原始数据的损坏或扰动版本。
通过采用本节介绍的检测技术和防御策略,实践者可开发更稳健的系统。对抗性稳健性仍是持续研究领域,需要多层次防御机制和定期测试以应对不断演变的威胁。
数据中毒防御
数据中毒攻击旨在破坏 ML 模型训练所用数据,主要针对 第 6 章:数据工程 中的数据采集与预处理环节,削弱其完整性。如图 31 所示,这些攻击可操控或污染训练数据,使模型学习错误模式,部署后产生错误预测或不良行为。鉴于训练数据对 ML 系统性能的基础性作用,检测和缓解数据中毒对维护模型可信性和可靠性至关重要。

异常检测技术
统计离群点检测方法识别与大多数数据显著偏离的数据点,假设中毒实例往往为统计离群点。常用技术包括 Z-score 方法 、 Tukey 方法 或 马氏距离 ,用于衡量每个数据点与数据集中心的偏离程度。超出阈值的数据点被标记为潜在离群点,视为可疑中毒数据。
基于聚类的方法根据特征将相似数据点分组,假设中毒实例可能形成独立簇或远离正常数据簇。通过 K-means 、 DBSCAN 或 层次聚类 等算法,可识别异常簇或不属于任何簇的数据点,将其视为潜在中毒数据。
自编码器(autoencoders)46 是通过压缩表示重构输入数据的神经网络,如图 32 所示。可用于异常检测,通过学习数据的正常模式,识别偏离这些模式的实例。训练时用干净数据训练自编码器,推理时计算每个数据点的重构误差。重构误差高的数据点被视为异常和潜在中毒,因为它们不符合已学的正常模式。

数据清洗与预处理
通过清洗数据可避免数据中毒,包括识别并移除或修正噪声、不完整或不一致的数据点。可采用数据去重、缺失值填补和离群点移除等技术提升训练数据质量。通过剔除或过滤可疑或异常数据点,可降低中毒实例的影响。
数据验证包括核查训练数据的完整性和一致性,如数据类型一致性、范围校验和字段间依赖。通过定义和执行数据验证规则,可识别并标记异常或不一致的数据点,提示可能存在数据中毒,便于进一步调查。
数据溯源与谱系追踪记录数据来源、变换和在 ML 流水线中的流转。通过记录数据源、预处理步骤及所有修改,实践者可追溯异常或可疑模式的来源,有助于定位中毒点并推动调查和缓解。
稳健训练
可通过稳健优化技术调整训练目标,最小化离群点或中毒实例的影响。可采用对极值不敏感的稳健损失函数,如 Huber 损失或改进版 Huber 损失47。正则化技术48(如 L1/L2 正则化 )也可通过约束模型复杂度、防止过拟合,降低对中毒数据的敏感性。
稳健损失函数设计为对离群点或噪声数据点不敏感,如改进版 Huber 损失 、Tukey 损失和截断均值损失。这些损失函数在训练时降低异常实例的权重或忽略其贡献,减少其对模型学习过程的影响。稳健目标函数如极小极大(minimax)49 或分布稳健目标,旨在优化模型在最坏情况下或对抗扰动下的表现。
数据增强通过对现有数据施加随机变换或扰动(如图 33),生成更多训练样本,提升数据集多样性和稳健性。通过引入受控变化,模型对中毒实例中的特定模式或伪影不敏感。随机抽样或自助聚合等随机化技术也可通过在不同数据子集上训练多个模型并集成预测,降低中毒数据影响。

安全数据采集
采用最佳数据采集与管理实践可降低数据中毒风险,包括建立明确的数据采集协议、验证数据源的真实性和可靠性、定期进行数据质量评估。从可信供应商采购数据并遵循安全数据处理流程,可减少中毒数据进入训练流程的可能性。
健全的数据治理与访问控制机制对防止训练数据被未授权修改或篡改至关重要。包括明确数据访问角色与职责、基于最小权限原则50 实施访问控制策略、监控和记录数据访问活动。通过限制访问和维护审计日志,可及时发现和调查潜在的数据中毒行为。
检测和缓解数据中毒攻击需结合异常检测、数据清洗、稳健训练和安全数据采集等多种手段。数据中毒仍是活跃研究领域,需要主动和自适应的数据安全策略。
分布变化自适应
分布变化为已部署 ML 系统带来持续挑战,需要系统化的检测与缓解方法。本节聚焦于识别分布变化的实用技术,以及在变化发生时维持系统性能的策略,涵盖统计检测方法、自适应算法和生产系统实现要点。
检测与缓解
分布变化指 ML 模型在部署时遇到的数据分布与训练时不同。这种变化会显著影响模型性能和泛化能力,导致次优或错误预测。检测和缓解分布变化对确保 ML 系统在实际场景下的稳健性和可靠性至关重要。
检测技术
可用统计检验比较训练与测试数据分布,识别显著差异。如下清单 2 展示了生产环境中监控分布变化的实用实现:
清单 2:分布变化检测:结合 Kolmogorov-Smirnov 检验和领域分类器,监控生产环境中数据分布变化的核心统计方法。
from scipy.stats import ks_2samp
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
def detect_distribution_shift(
reference_data, new_data, threshold=0.05
):
"""使用统计检验检测分布变化"""
# 针对每个特征进行 Kolmogorov-Smirnov 检验
ks_pvalues = []
for feature_idx in range(new_data.shape[1]):
_, p_value = ks_2samp(
reference_data[:, feature_idx], new_data[:, feature_idx]
)
ks_pvalues.append(p_value)
# 领域分类器检测整体分布差异
X_combined = np.vstack([reference_data, new_data])
y_labels = np.concatenate(
[np.zeros(len(reference_data)), np.ones(len(new_data))]
)
clf = RandomForestClassifier(n_estimators=50, random_state=42)
clf.fit(X_combined, y_labels)
domain_auc = roc_auc_score(
y_labels, clf.predict_proba(X_combined)[:, 1]
)
return {
"ks_shift_detected": any(p < threshold for p in ks_pvalues),
"domain_shift_detected": domain_auc > 0.8,
"severity_score": domain_auc,
}
如 Kolmogorov-Smirnov 检验、Anderson-Darling 检验等技术可衡量两分布间的差异,定量评估分布变化。将这些检验应用于输入特征或模型预测,可检测训练与测试分布间的统计显著差异。
散度度量用于量化两个概率分布的差异。常用的有 Kullback-Leibler (KL) 散度 和 Jensen-Shannon (JS) 散度 。通过计算训练与测试数据分布的散度,可评估分布变化的程度。高散度值表明分布差异显著,提示存在分布变化。
不确定性量化技术(如贝叶斯神经网络51 或集成方法52)可估算模型预测的不确定性。当模型应用于不同分布的数据时,预测不确定性可能升高。通过监控不确定性水平,若测试样本的不确定性持续超过阈值,说明模型已超出训练分布。
此外,领域分类器可训练区分不同领域或分布。通过训练分类器区分训练与测试域,若分类器区分准确率高,说明底层分布差异显著,其性能可作为分布变化的度量。
缓解技术
迁移学习通过迁移一个领域的知识提升另一个领域的表现,如图 34 所示。利用预训练模型或迁移已学特征,可缓解分布变化影响。预训练模型可在目标域少量标注数据上微调,适应新分布。迁移学习在源域与目标域特征相似或目标域标注数据稀缺时尤为有效。

持续学习(continual/lifelong learning)使 ML 模型能在保留既有知识的同时,持续适应新数据分布。弹性权重巩固(EWC,Kirkpatrick 等,2017)、梯度回忆(GEM,Lopez-Paz 和 Ranzato,2017)等技术可随时间适应数据分布变化,平衡模型的可塑性(学习新数据能力)与稳定性(保留旧知识能力)。通过增量更新和缓解灾难性遗忘,持续学习有助于模型应对分布变化。
数据增强技术(如前述方法)通过对训练数据施加变换或扰动,提升多样性和对分布变化的稳健性。引入旋转、平移、缩放或加噪等变化,帮助模型学习不变特征,更好泛化到未见分布。训练和推理阶段均可采用数据增强,提升模型应对分布变化的能力。
集成方法(详见 第 16 章:稳健 AI )同样可提升对分布变化的稳健性。面对分布变化,集成系统可利用各模型优势,做出更准确、稳定的预测。
定期用目标分布的新数据更新模型对缓解分布变化至关重要。随着数据分布演变,模型应在最新数据上再训练或微调,以适应变化模式,结合 第 14 章:设备端学习 中的持续学习方法。监控模型性能和数据特征有助于判断何时需更新。保持模型最新,可确保其在分布变化下仍具相关性和准确性。
采用对分布变化不敏感的稳健指标评估模型,可更可靠地衡量性能。如精确率 - 召回率曲线下的面积(AUPRC)或 F1 分数53,对类别不平衡更稳健,能更好反映不同分布下的模型表现。采用与目标域期望结果一致的领域特定评估指标,可更有意义地衡量模型有效性。
分布变化的检测与缓解是持续过程,需要不断监控、适应和改进。通过本节介绍的检测与缓解技术,实践者可主动应对实际部署中的分布变化。
面向稳健性的自监督学习
自监督学习(SSL)方法通过从数据结构中学习,而非死记硬背输入输出映射,为构建更稳健的 AI 系统提供了新路径。与依赖标注样本的监督学习不同,SSL 通过解决前置任务,要求模型理解数据的底层模式和关系,从而自动发现有效表征。
自监督方法有望解决导致神经网络脆弱性的若干核心问题。SSL 能从环境规律和数据结构中学习表征,捕捉在不同条件下依然稳定的不变特征。对比学习等技术鼓励模型在不同视角下提取一致特征,从而提升对变换和扰动的稳健性。掩码语言建模及视觉领域的类似技术则通过上下文预测,促使模型发展出更具泛化能力的内部表征,而非仅依赖表面模式。
自监督表征在迁移能力上往往优于监督学习表征,说明其更能抓住数据结构的本质。基于数据结构而非标签学习,天然更具稳健性,因为它依赖于跨领域、跨条件都存在的稳定模式。SSL 能利用大量无标注数据,通过暴露于更广泛的自然变异,提升模型泛化能力。这种对多样无标注数据的接触,有助于模型形成对实际部署中常见分布漂移更具韧性的表征。
在稳健系统设计中,可通过多种策略引入自监督学习。例如,先用自监督目标进行预训练,再针对具体任务微调,可为模型打下更易迁移的稳健基础。多任务方法将自监督与监督目标结合训练,兼顾表征学习与任务表现。用 SSL 学得的表征作为后续稳健微调的基础,往往能用更少标注样本实现稳健性。
尽管前景广阔,面向稳健性的自监督学习仍是活跃研究领域,存在重要局限。当前 SSL 方法在攻击者了解前置任务时,仍可能受到对抗性攻击。SSL 提升稳健性的理论机制尚未完全明晰。自监督预训练的计算开销较大,需权衡资源约束。
这一方向预示着稳健 AI 研发范式的演进,未来可能不再仅依赖防御性技术,而是通过本质上更可靠的学习方法提升系统稳健性。
我们前文探讨的三大支柱——硬件故障、输入级攻击和环境变化——各自针对 AI 系统的不同层面,但它们都运行于复杂的软件基础设施之上,而这些基础设施本身也存在独特的脆弱性。
软件故障
前述稳健性挑战——硬件故障、输入级攻击和环境变化——各自影响系统的不同层级。硬件故障破坏物理计算,对抗攻击利用算法边界,环境变化挑战模型泛化。而软件故障则引入第四维度:现代 AI 部署所依赖的复杂软件生态中的 bug 和实现错误,会放大前三类威胁的影响。
这一类别与前两类不同。硬件故障多源于物理现象,模型稳健性问题则源于学习算法的内在局限,而软件故障则是系统设计和实现中的人为错误。这些故障可能影响 AI 流水线的任意环节,从数据预处理、模型训练到推理和结果解释,往往表现隐蔽,难以第一时间察觉。
AI 系统中的软件故障尤为棘手,因为它们可能与其他稳健性威胁相互作用并放大。例如,数据预处理中的 bug 可能制造分布漂移,暴露模型脆弱性。数值计算实现错误可能表现得与硬件故障类似,但缺乏硬件级错误检测机制。分布式训练中的竞态条件可能导致模型损坏,其表现与对抗攻击下的表征破坏类似。
这些相互作用源于现代 AI 软件栈的高度复杂性——涵盖框架、库、运行时、分布式系统和部署基础设施——为故障的产生和传播提供了众多机会。理解并缓解这些软件层面的威胁,是构建真正稳健、能在生产环境可靠运行的 AI 系统的关键。
机器学习系统依赖于远超模型本身的复杂软件基础设施。这些系统构建于 第 7 章:AI 框架 详述的框架、库和运行环境之上,支撑模型训练、评估和部署。与所有大型软件系统一样,支撑 ML 工作流的组件也易受故障影响——即由缺陷、bug 或设计疏漏导致的非预期行为,带来超出 第 13 章:机器学习运维 标准实践范围的运维挑战。这些故障可出现在 ML 流水线的各个阶段,若未及时发现和修复,可能导致性能下降、安全受损,甚至结果失效。本节将探讨 ML 系统中软件故障的本质、成因与后果,以及检测与缓解策略。
软件故障特性
理解软件故障对 ML 系统的影响,需分析其独特特性。ML 框架中的软件故障来源广泛,包括编程错误、架构不匹配和版本不兼容等。这些故障具有若干重要特性,影响其产生和传播方式。
首先,软件故障类型多样。从语法和逻辑错误,到更复杂的内存泄漏、并发 bug 或集成逻辑失效,类型繁多,增加了定位和修复的难度,且常以隐蔽方式暴露。
其次,软件故障易跨系统边界传播。底层模块(如张量分配或预处理函数)中的错误,可能级联影响模型训练、推理或评估。由于 ML 框架常由多个互联组件组成,流水线某一环节的故障可能导致看似无关模块的失效。
部分故障具有间歇性,仅在高负载、特定硬件配置或极端输入下出现。这类瞬态故障极难复现和诊断,常规测试难以覆盖。
更令人担忧的是,软件故障可能与 ML 模型本身产生微妙交互。例如,数据变换脚本中的 bug 可能引入系统性噪声或分布漂移,导致模型输出偏差或不准确。类似地,服务基础设施中的故障可能导致训练和推理时行为不一致,破坏部署一致性。
软件故障的后果涉及系统多方面属性。它们可能通过引入延迟或低效内存使用损害性能,通过限制并行度降低可扩展性,或通过暴露系统于异常行为或恶意利用而削弱可靠性和安全性。
此外,软件故障的表现常受外部依赖影响,如硬件平台、操作系统或第三方库。版本不匹配或硬件特有行为可能导致仅在特定运行时条件下出现的隐蔽 bug。
全面理解这些特性,是发展 ML 软件工程稳健实践的基础,也为后续检测与缓解策略奠定了理论基础。
软件故障传播机制
上述特性说明,ML 框架中的软件故障可通过多种机制产生,反映出现代 ML 流水线和分层工具架构的复杂性。这些机制对应实际中常见的软件失效类型。
一类突出问题是资源管理失误,尤其是内存管理。内存分配不当(如未释放缓冲区或文件句柄)会导致内存泄漏,最终资源耗尽。深度学习应用中,大型张量和 GPU 内存分配尤为常见。如图 35 所示,内存使用低效或未释放 GPU 资源,会导致训练中断或运行性能严重下降。

除资源管理外,并发与同步错误也是常见故障机制。在分布式或多线程环境下,进程间协调不当会引发竞态条件、死锁或状态不一致。这些问题常与 异步操作 (如非阻塞 I/O 或并行数据加载)使用不当有关。同步 bug 会破坏训练状态一致性,或导致模型检查点不可靠。
兼容性问题常因软件环境变化而产生,延续了 第 7 章:AI 框架 中的框架兼容性问题。例如,升级第三方库但未验证下游影响,可能引入行为变化或破坏现有功能。训练与推理环境在硬件、操作系统或依赖版本上的差异,会加剧这些问题。ML 实验的可复现性往往取决于对这些环境不一致的管理。
数值不稳定相关故障在 ML 系统中也很常见,尤其是在优化过程中。浮点精度处理不当、除零、下溢/上溢等问题,会导致梯度计算和收敛过程不稳定。详见 相关资源 ,多层计算中的舍入误差积累会扭曲参数或延迟收敛。
异常处理虽常被忽视,却对 ML 流水线稳定性至关重要。异常管理不当或过于宽泛,可能导致系统在非关键错误下静默失败或崩溃。模糊的错误信息和糟糕的日志记录会阻碍诊断,延长修复时间。
这些故障机制虽来源各异,但都可能严重损害 ML 系统。理解其成因,是制定有效系统级防护措施的基础。
软件故障对 ML 的影响
软件故障的产生机制决定了其对 ML 系统的影响。其后果可能极为严重,不仅影响模型输出的正确性,还会波及 ML 系统在生产环境中的可用性和可靠性。
最直观的影响是性能下降,常由内存泄漏、资源调度低效或线程争用引起。这些问题会随时间累积,导致延迟增加、吞吐量下降,甚至系统崩溃。如相关研究所述,组件间性能回退的积累会严重限制大规模 ML 系统的运行能力。
除性能外,故障还可能导致预测不准确。例如,预处理错误或特征编码不一致会悄然改变模型输入分布,输出偏差或不可靠。这类故障尤为隐蔽,虽未触发明显故障,却会破坏下游决策。长时间训练或深层架构中,舍入误差和精度损失会进一步放大不准确性。
可靠性也会因软件故障受损。系统可能意外崩溃、无法从错误中恢复,或多次运行结果不一致。间歇性故障尤为棘手,既破坏用户信任,又难以用常规调试手段定位。在分布式环境下,检查点或模型序列化故障会导致训练中断或数据丢失,降低长时训练流水线的韧性。
安全漏洞常因被忽视的软件故障而产生。缓冲区溢出、校验不当或输入未加防护,可能被攻击者利用,篡改模型行为、窃取数据或发起拒绝服务攻击。如相关研究所述,这类漏洞在 ML 系统集成于关键基础设施或处理敏感数据时,风险尤为严重。
最后,故障的存在会增加开发和运维难度。调试耗时,尤其是故障行为不确定或依赖外部配置时。频繁的软件更新或库补丁可能引入回归,需反复测试。工程开销增加会拖慢迭代、抑制实验、分散模型开发资源。
综上,这些影响凸显了在 ML 中系统化软件工程实践的重要性——需预见、检测并缓解由软件故障引入的多样失效模式。
软件故障检测与预防
鉴于软件故障对 ML 系统的重大影响,需在开发、测试、部署和监控各阶段采取一体化策略,结合 第 13 章:机器学习运维 的运维最佳实践。有效的缓解框架应将主动检测方法与稳健设计模式和运维防护结合起来。
下表 6 总结了这些技术,并按阶段和目标分类,便于梳理各策略在 ML 生命周期中的应用场景。该表为后文详细说明提供了高层参考。
| 类别 | 技术手段 | 目标 | 应用阶段 |
|---|---|---|---|
| 测试与验证 | 单元测试、集成测试、回归测试 | 验证正确性,发现回归 | 开发阶段 |
| 静态分析与 Lint | 静态分析器、代码风格检查、代码评审 | 检测语法错误、不安全操作、强制最佳实践 | 集成前 |
| 运行时监控与日志 | 指标收集、错误日志、性能分析 | 观察系统行为,检测异常 | 训练与部署阶段 |
| 容错设计 | 异常处理、模块化架构、检查点 | 最小化故障影响,支持恢复 | 设计与实现阶段 |
| 更新管理 | 依赖审计、测试分阶段、版本追踪 | 防止回归和兼容性问题 | 系统升级或部署前 |
| 环境隔离 | 容器化(如 Docker、Kubernetes)、虚拟环境 | 保证可复现性,避免环境相关 bug | 开发、测试、部署 |
| CI/CD 与自动化 | 自动化测试流水线、监控钩子、部署门禁 | 强制质量保证,早期捕获故障 | 持续开发全周期 |
第一道防线是系统化测试。单元测试验证组件在正常和边界条件下的行为,集成测试确保模块间交互正确,回归测试检测代码变更引入的错误。持续测试对快速演进的 ML 环境至关重要,流水线频繁变更,微小修改也可能带来系统级影响。如图 36 所示,自动回归测试有助于长期保持功能正确性。
静态代码分析工具在编译期补充动态测试,识别变量误用、不安全操作或语言规范违例。结合代码评审和风格强制,静态分析可减少可避免的编程错误。
运行时监控对观察实际条件下的系统行为至关重要。日志框架应捕获内存使用、输入输出轨迹和异常事件等关键信号。监控工具可跟踪模型吞吐、延迟和故障率,及早预警软件故障。性能分析(详见 微软资源 )有助于定位瓶颈和架构低效,提示更深层次问题。
稳健系统设计进一步提升容错能力。结构化异常处理和断言检查可防止小错误级联为系统性故障。冗余计算、备用模型和故障转移机制提升组件失效下的可用性。模块化架构封装状态、隔离副作用,便于诊断和局部化故障。检查点技术(如相关文献所述)支持训练中断恢复,避免数据丢失。
保持 ML 软件更新也是关键策略。定期应用更新和安全补丁可修复已知 bug 和漏洞。但更新需通过测试分阶段环境验证,避免引入回归。查阅 发布说明 和变更日志,确保团队了解新版本的行为变化。
容器化技术如 Docker 和 Kubernetes 使团队能定义可复现的运行环境,缓解兼容性问题。通过隔离系统依赖,容器防止开发、测试和生产中的系统级差异引入故障。
最后,围绕持续集成与持续部署(CI/CD)构建的自动化流水线,为故障感知开发提供基础设施。可将测试、验证和监控直接嵌入 CI/CD 流程。如图 37 所示,这类流水线降低了回归未被发现的风险,确保只有经过测试的代码进入生产环境。

这些实践共同构成了 ML 系统软件故障管理的完整方法。系统化采用后,可降低系统失效概率,提升长期可维护性,并增强对模型性能和可复现性的信任。
故障注入工具与框架
鉴于构建稳健 AI 系统的重要性,近年来研究者和工程师们开发了多种工具和框架,基于 第 7 章:AI 框架 中的软件基础设施,旨在理解硬件故障如何表现和传播,从而影响 ML 系统。这些工具和框架在评估 ML 系统对硬件故障的稳健性方面发挥着关键作用,通过模拟各种故障场景及其对系统性能的影响,帮助设计者识别潜在脆弱性并制定有效的缓解策略,最终构建出更稳健、更可靠的 ML 系统,确保其在故障发生时依然安全运行,支持 第 13 章:机器学习运维 中详述的部署策略。本节将概述文献中广泛使用的故障模型54 以及为评估这些故障对 ML 系统影响而开发的工具和框架。
故障与错误模型
如前所述,硬件故障可能以多种方式表现,包括瞬态、永久和间歇性故障。除了研究故障类型外,故障的表现方式同样重要。例如,故障是在内存单元中发生,还是在功能单元的计算过程中?故障影响单个比特,还是多个比特?故障是否会一直传播并影响应用(导致错误),还是会很快被掩盖而被视为良性?所有这些细节都会影响故障模型的定义,而故障模型在模拟和测量故障发生时系统的反应中起着重要作用。
研究硬件故障对 ML 系统影响时,理解故障模型和错误模型的概念至关重要。故障模型描述硬件故障在系统中的表现方式,而错误模型则表示故障是如何传播并影响系统行为的。
故障模型通常通过几个关键属性进行分类。首先,它们可以根据持续时间来定义:瞬态故障是暂时的,快速消失;永久故障是持续的;而间歇性故障则是偶尔发生的,难以识别或预测。另一个维度是故障位置,故障可能发生在硬件组件的不同位置,如内存单元、功能单元或互连线路。故障还可以根据其粒度进行特征化——有些故障仅影响单个比特(例如,比特翻转),而其他故障则可能同时影响多个比特,如突发错误。
错误模型则描述故障传播到系统行为的影响。这些模型帮助研究人员理解硬件级干扰是如何表现为系统行为的,例如在 ML 模型中通过损坏的权重或计算错误的激活值。这些模型可以在各个抽象层次上运行,从低级硬件错误到 ML 框架中的高级逻辑错误。
选择合适的故障或错误模型对于稳健性评估至关重要。例如,旨在研究单比特瞬态故障的系统,对于永久性多比特故障的影响则无能为力,因为其设计和假设完全基于不同的故障模型。
有趣的是,无论抽象层次如何,某些故障行为模式是一致的。例如,研究表明,无论是在硬件级别还是软件级别,单比特故障造成的干扰都大于多比特故障。然而,诸如错误掩盖之类的现象,可能仅在较低的抽象层次上可观察到。如图 38 所示,这种掩盖现象可能导致故障在传播到更高层次之前就被过滤掉,因此仅依赖软件的错误检测工具可能完全无法察觉这些影响。

为了解决这些差异,开发了 Fidelity 等工具,以跨抽象层对故障模型进行对齐。通过将软件观察到的故障行为映射到相应的硬件级模式(Cheng et al. 2016),Fidelity 提供了一种更准确的手段,在软件层面模拟硬件故障。虽然较低级别的工具捕捉了故障在硬件系统中真实传播的情况,但它们通常速度较慢且更复杂。软件级工具(如在 PyTorch 或 TensorFlow 中实现的工具)则更快且更易于大规模稳健性测试,尽管精度较低。
硬件级故障注入
硬件级故障注入方法允许研究人员直接在物理系统中引入故障,并观察其对 ML 模型的影响。这些方法对于验证软件级故障注入工具中的假设,以及研究现实世界中的硬件故障如何影响系统行为至关重要。尽管大多数 ML 稳健性研究中使用的错误注入工具是基于软件的,但由于其速度和可扩展性,硬件级方法仍然是研究硬件故障影响的最准确手段。
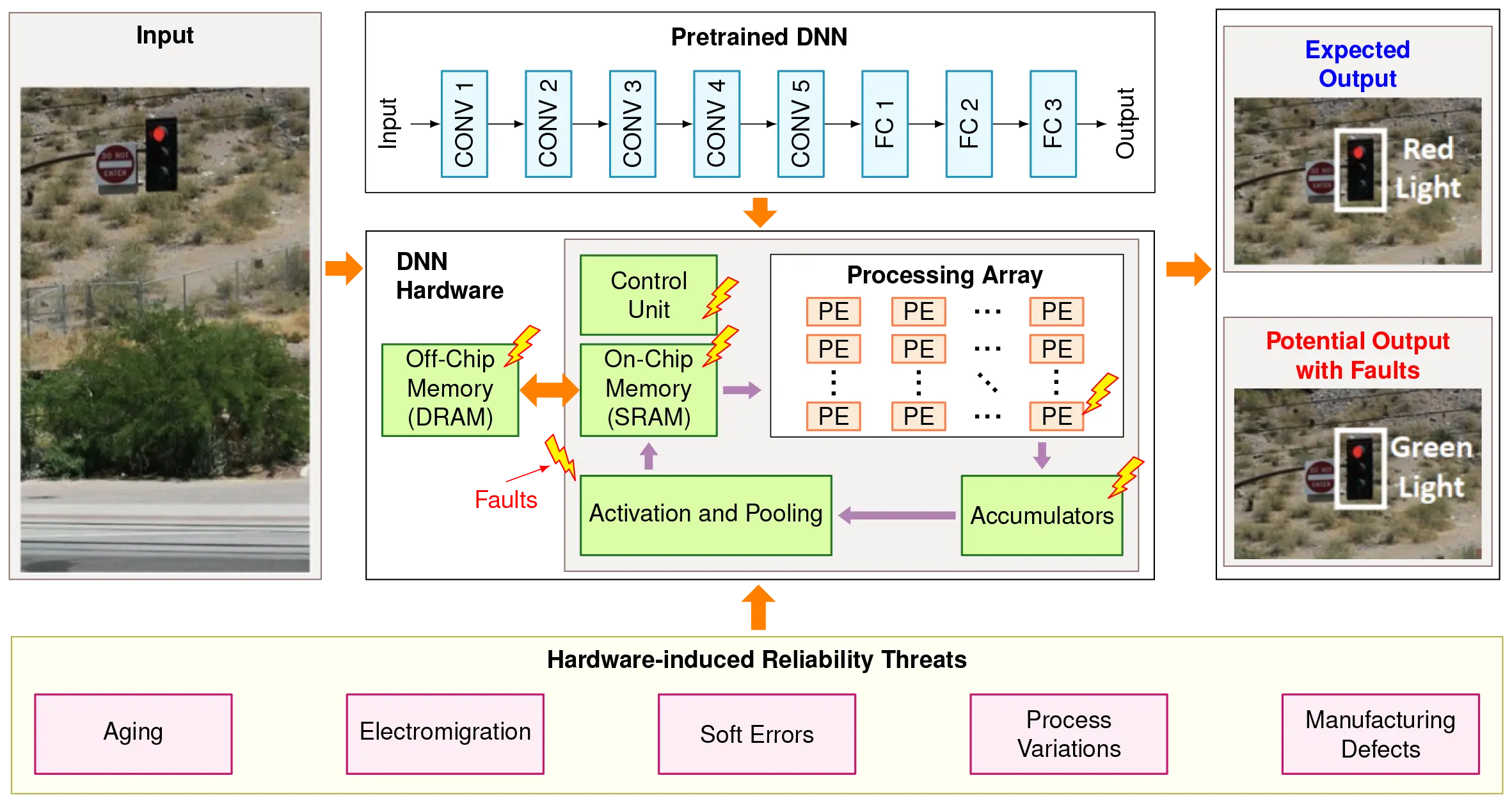
如图 39 所示,硬件故障可以在深度神经网络(DNN)处理流水线的各个环节出现。这些故障可能影响控制单元、片上内存(SRAM)、片外内存(DRAM)、处理单元和累加器,导致结果错误。在正常情况下,DNN 可能正确识别红灯,但由于硬件老化、电迁移、软错误、工艺变化和制造缺陷等现象引起的硬件故障,可能导致 DNN 错误地将信号分类为绿灯,从而在实际应用中可能导致灾难性后果。
这些方法使研究人员能够观察系统在真实故障条件下的行为。本节将详细描述软件和硬件两种错误注入工具。
硬件注入方法
两种最常见的硬件级故障注入方法是基于 FPGA 的故障注入和辐射或束流测试。
基于 FPGA 的故障注入。现场可编程门阵列(FPGA)55 是可重构的集成电路,可以被编程实现各种硬件设计。在故障注入的背景下,FPGA 提供了高精度和高准确性,研究人员可以针对硬件中的特定比特或比特集进行故障注入。通过修改 FPGA 配置,可以在执行 ML 模型的特定位置和时间引入故障。基于 FPGA 的故障注入允许对故障模型进行精细控制,使研究人员能够研究不同类型故障(如单比特翻转或多比特错误)的影响。这种控制能力使基于 FPGA 的故障注入成为理解 ML 系统对硬件故障的韧性的重要工具。
尽管基于 FPGA 的方法允许精确、可控的故障注入,但其他方法旨在复制自然环境中存在的故障条件。
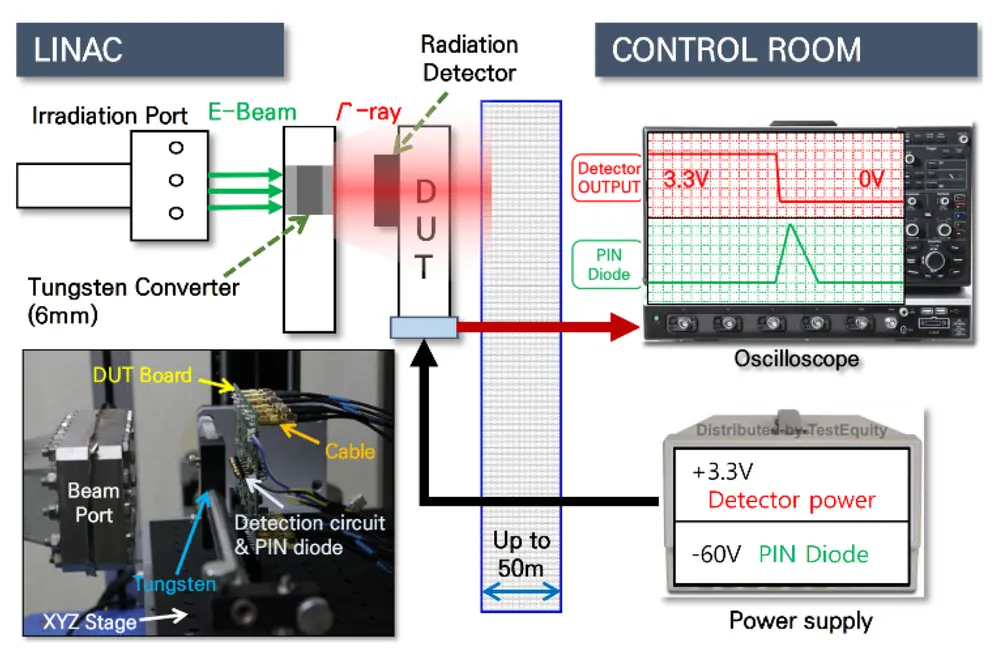
辐射或束流测试。辐射或束流测试将运行 ML 模型的硬件暴露于高能粒子(如质子或中子)辐射下。如图 40 所示,专用测试设施可以控制辐射暴露,以诱发比特翻转和其他硬件级故障。这种方法被广泛认为是测量粒子撞击导致的错误率的最准确方法之一。束流测试提供了高度真实的故障场景,模拟了辐射丰富环境中的条件,对于验证用于太空任务或粒子物理实验的系统特别有价值。然而,尽管束流测试提供了卓越的真实性,但其缺乏 FPGA 基于注入的精确定位能力——粒子束无法高精度地瞄准特定硬件比特或组件。尽管存在这些局限性及其显著的操作复杂性和成本,束流测试仍然是一个受信赖的行业实践,用于严格评估硬件在真实辐射效应下的可靠性。
硬件注入局限性
尽管硬件级故障注入方法具有高准确性,但由于其高成本和复杂性,限制了其广泛应用。
首先,成本是一个主要障碍。FPGA 和束流测试56 方法都需要专用硬件和设施,这些硬件和设施的建立和维护成本较高。这使得资金或基础设施有限的研究小组难以承受。
其次,这些方法在可扩展性方面面临挑战。在硬件上直接注入故障并收集数据的过程耗时较长,限制了在合理时间内可以进行的实验数量。这在分析大型 ML 系统或在许多故障场景中进行统计评估时尤其具有限制性。
第三,灵活性有限。当需要针对各种故障和错误类型进行建模时,硬件级方法可能不如基于软件的替代方案那样灵活。为了适应新的故障模型,改变实验设置往往需要耗时的硬件重新配置。
尽管存在这些局限性,硬件级故障注入仍然是验证软件工具准确性和研究系统在真实故障条件下行为的重要手段。通过将硬件级方法的高保真度与软件级工具的可扩展性和灵活性相结合,研究人员可以更全面地了解 ML 系统对硬件故障的韧性,并制定有效的缓解策略。
基于软件的故障注入
随着 TensorFlow、PyTorch 和 Keras 等机器学习框架成为开发和部署 ML 模型的主流平台,基于软件的故障注入工具作为一种灵活且可扩展的方法,迅速发展起来,用于评估这些系统对硬件故障的稳健性。与直接作用于物理系统的硬件级方法不同,基于软件的方法通过修改模型的底层计算图、张量值或中间计算,来模拟硬件故障的影响。
这些工具因其直接与 ML 开发流水线集成、无需专用硬件、并且能够快速、经济高效地进行大规模故障注入实验而变得越来越受欢迎。通过在软件层面模拟硬件级故障(包括权重、激活值或梯度中的比特翻转),这些工具能够高效测试故障容忍机制,并提供有关模型脆弱性的宝贵见解。
本节其余部分将探讨基于软件的故障注入方法的优缺点,介绍主要的工具类别(包括通用和特定领域的工具),并讨论它们如何有助于构建具有韧性的 ML 系统。
软件注入权衡
基于软件的故障注入工具提供了若干优势,使其在研究 ML 系统的韧性时颇具吸引力。
主要优点之一是速度。这些工具完全在软件栈内操作,避免了修改物理硬件或配置专用测试环境所带来的开销。这种高效性使研究人员能够在显著更短的时间内进行大量故障注入实验。快速模拟各种故障的能力,特别适用于对大规模 ML 模型进行压力测试或进行需要数千次注入的统计分析。
这些工具还具有高度的灵活性。基于软件的故障注入器可以轻松适配多种故障类型。研究者可以模拟单比特翻转、多比特损坏,甚至更复杂的突发错误或部分张量损坏等行为。软件工具允许在 ML 流水线的不同阶段(训练、推理或梯度计算)注入故障,实现对不同系统组件或层的精准定位。
这些工具的可及性也很高,仅需标准的 ML 开发环境即可使用。与硬件方法不同,软件工具无需昂贵的实验设备、定制电路或辐照测试场地。这种易用性让故障注入研究惠及更多机构和开发者,包括学术界、初创公司或资源有限的团队。
但这些优势也带来权衡。最主要的问题是准确性。由于软件工具在更高抽象层模拟故障,可能无法完全捕捉底层硬件交互对故障传播的影响。例如,在 ML 框架中模拟的比特翻转,可能忽略了硬件层的数据缓冲、缓存或操作方式,导致结论过于简化。
与此密切相关的是保真度问题。虽然可以近似真实故障行为,但软件工具在掩蔽、时序或数据流动等细微交互上,可能与真实硬件行为存在偏差。这类仿真结果高度依赖底层错误模型的假设,需与真实硬件测量结果对照验证。
尽管存在这些局限,基于软件的故障注入工具在 ML 稳健性研究中仍不可或缺。其速度、灵活性和可及性使研究者能广泛评估并推动容错 ML 架构的发展。后续章节将介绍该领域的主要工具及其应用场景。
软件注入的局限性
虽然基于软件的故障注入工具在速度、灵活性和可及性方面具有显著优势,但也存在一定局限。这些约束会影响故障注入实验的准确性和真实性,尤其是在评估 ML 系统对真实硬件故障稳健性时。
首要问题是准确性。软件工具在更高抽象层运行,可能无法捕捉硬件故障产生的全部效应。底层硬件交互(如时序误差、电压波动、架构副作用)在高层仿真中可能完全被忽略。因此,完全依赖软件模型的故障注入研究,可能低估或高估系统对某些故障类型的真实脆弱性。
保真度问题同样突出。虽然软件方法常被设计为模拟特定故障行为,但其对真实硬件条件的还原程度各异。例如,模拟神经网络权重的单比特翻转,未必能真实反映该比特错误在内存层级或芯片计算单元中的传播方式。工具抽象层级越高,仿真行为与物理故障下的实际表现偏差越大。
由于软件工具易于修改,反而可能无意中偏离真实的故障假设。如果选用的故障模型过于简化,或未基于真实硬件数据,仿真结果就会失真。正如后文关于软硬件间隙的讨论,Fidelity 等工具试图通过对齐软件模型与已知硬件故障特性来解决这些问题。
尽管如此,软件故障注入仍是 ML 稳健性研究的重要组成部分。合理使用,尤其结合硬件验证时,这些工具为探索大规模设计空间、识别脆弱组件和制定缓解策略提供了高效可扩展的手段。随着故障建模技术不断进步,将硬件感知洞见融入软件工具,是提升其真实性和影响力的关键。
软件注入工具类别
近年来,针对多种 ML 框架和应用场景,开发了大量基于软件的故障注入工具。这些工具在抽象层级、目标平台和可模拟故障类型上各不相同。许多工具可与 PyTorch、TensorFlow 等主流 ML 库集成,便于研究者和工程师直接在现有生态中使用。
最早且有影响力的工具之一是 Ares,最初为 Keras 框架设计。在 DNN 日益流行的早期,Ares 是首批系统性探索硬件故障对 DNN 影响的工具之一。它支持注入单比特翻转,并评估权重和激活值的比特错误率(BER)。重要的是,Ares 曾与实际硅实现的 DNN 加速器对比验证,证明其对硬件级故障建模的相关性。随着领域发展,Ares 也扩展支持 PyTorch,便于分析现代 ML 环境下的故障行为。
在此基础上,PyTorchFI 作为专为 PyTorch 设计的故障注入库被提出。由 Nvidia Research 合作开发,PyTorchFI 支持对模型权重、激活和梯度等关键组件注入故障。其原生 GPU 加速支持,使其特别适合高效评估大模型。如图 41 所示,即使简单的比特级故障也可能导致严重的视觉和分类错误,包括图像中出现“幽灵”物体,这在自动驾驶等领域可能带来安全隐患。

PyTorchFI 的模块化和易用性促使其被多个后续项目采用。例如,Intel xColabs 开发的 PyTorchALFI 扩展了 PyTorchFI 的能力,用于汽车应用的系统级安全评估。Meta 的 Dr. DNA 则引入了更简洁的 Python 风格 API,简化了故障注入流程。GoldenEye 进一步支持了 AdaptivFloat、BlockFloat 等新型数值类型(如 bfloat16),用于研究非传统数值格式在硬件比特错误下的容错性。
对于 TensorFlow 生态,TensorFI 提供了类似的解决方案。与 PyTorchFI 类似,TensorFI 支持在 TensorFlow 计算图中注入多种故障模型。其广泛适用性是一大优势——不仅可用于 DNN,还能评估多种 ML 模型。BinFi 等扩展则通过聚焦模型中最关键的比特位,加速了故障注入过程。这种优先级排序有助于在缩短仿真时间的同时,捕捉最具代表性的错误模式。
在更低的软件栈层级,NVBitFI 提供了直接在 GPU 汇编代码中注入故障的平台无关工具。由 Nvidia 开发,NVBitFI 可对任意 GPU 加速应用(不仅限于 ML 工作负载)进行故障注入。这使其成为研究指令级稳健性的强大工具,能捕捉错误在底层的复杂传播。NVBitFI 是 PyTorchFI、TensorFI 等高层工具的重要补充,提供了对 GPU 行为的细粒度控制,并支持更广泛的应用类型。
这些工具共同构成了丰富的故障注入能力谱系。有的与高层 ML 框架紧密集成,便于上手;有的则支持更低层次的高保真建模。研究者可根据抽象层级、性能需求和目标应用选择合适工具,获得更具指导性的 ML 稳健性洞见。下一节将聚焦这些工具在自动驾驶、机器人等安全关键系统中的领域应用。
面向 ML 的专用注入工具
为应对特定应用领域的独特挑战,研究者开发了针对不同 ML 系统的专用故障注入工具。在自动驾驶、机器人等高风险环境中,领域专用工具对评估硬件故障下的系统安全和可靠性至关重要。本节介绍了三类工具:面向自动驾驶的 DriveFI 和 PyTorchALFI,以及面向无人机的 MAVFI。每种工具都能向感知、控制、传感等关键组件注入故障,帮助研究者洞察硬件错误在实际 ML 流水线中的传播机制。
DriveFI 是专为自动驾驶系统开发的故障注入工具。它支持在感知和控制流水线中注入硬件故障,便于研究这些故障对系统行为和安全性的影响。DriveFI 能与 Nvidia DriveAV、百度 Apollo 等行业标准平台集成,提供真实的测试环境。通过这种集成,DriveFI 让实践者能在故障条件下评估自动驾驶架构的端到端稳健性。
PyTorchALFI 则扩展了 PyTorchFI 的能力,专为自动驾驶领域设计。由 Intel xColabs 开发,PyTorchALFI 增强了底层注入框架的领域特性,包括支持对多模态传感器数据57(如摄像头、激光雷达输入)注入故障。这有助于深入分析自动驾驶感知系统对底层硬件故障的响应,进一步完善对系统脆弱性和失效模式的理解。
MAVFI 是专为机器人(尤其是无人机)设计的领域专用故障注入框架。基于 ROS(机器人操作系统)构建,MAVFI 提供了模块化、可扩展的平台,可向无人机的各子系统(如传感器、执行器、飞控算法)注入故障。通过评估注入故障对飞行稳定性和任务成功率的影响,MAVFI 为开发和验证容错无人机架构提供了实用手段。
这些工具展示了领域故障注入研究的不断进步。通过对故障注入位置和方式的精细控制,领域专用工具能提供通用框架难以获得的可操作洞见。它们的开发极大提升了 ML 社区设计和评估稳健系统的能力,尤其是在可靠性、安全性和实时性要求极高的场景。
弥合软硬件间隙
虽然基于软件的故障注入工具在速度、灵活性和可及性方面有诸多优势,但它们并不总能捕捉硬件故障对系统全部影响。这主要源于抽象层级的差异:软件工具在更高层运行,可能忽略底层硬件交互或细致的错误传播机制,而这些对 ML 系统行为有关键影响。
如相关研究所述,硬件故障可能呈现复杂的空间分布模式,纯软件模型难以复现。研究者总结了四类典型故障传播模式:single point(单点),即特征图中单个值被破坏;same row(同行),即特征图中部分或整行被破坏;bullet wake(弹道尾迹),即多个特征图中同一位置被影响;shatter glass(碎玻璃),即同行与弹道尾迹的复杂组合。这些模式如图 42 所示,凸显了简单注入策略的局限,也强调了评估 ML 稳健性时硬件感知建模的必要性。

为弥合这一抽象鸿沟,研究者开发了专门工具,将底层硬件错误行为映射到软件可见效应。Fidelity 就是其中之一,通过研究硬件级故障如何传播并在高层软件中显现,搭建了软硬件间的桥梁。下一节将详细介绍 Fidelity。
仿真保真度挑战
Fidelity 旨在在软件故障注入实验中更准确地建模硬件故障,其核心目标是通过模拟故障在计算栈中的传播,弥合硬件故障行为与 ML 系统高层效应之间的差距。
Fidelity 的核心洞见是,并非所有故障都需在硬件层逐一建模才能获得有意义的结果。它关注故障在软件可见状态下的表现,并识别等价关系,从而用代表性建模覆盖整个故障类别。具体方法包括:
首先,研究故障传播路径,理解硬件故障如何穿越架构寄存器、内存层级、数值运算等多层,最终改变软件中的值。Fidelity 捕捉这些路径,确保软件注入的故障能真实反映实际系统中的表现。
其次,工具识别故障等价性,即将导致相似软件可见结果的硬件故障归为一类。通过关注代表性样本而非穷举所有比特翻转,Fidelity 能在不牺牲准确性的前提下提升仿真效率。
最后,Fidelity 采用分层建模方法,从硬件故障起点到其在 ML 模型权重、激活或预测中的效应,逐层捕捉系统行为。这保证了硬件故障影响在 ML 系统中的真实仿真。
通过这些技术,Fidelity 让研究者能高效灵活地运行与真实硬件系统行为高度一致的故障注入实验。这在安全关键场景尤为宝贵,因其对硬件故障的准确理解至关重要。
硬件行为建模
在软件故障注入工具中准确反映硬件故障行为,对提升 ML 系统的可靠性和稳健性至关重要。当硬件故障有细微但重要影响时,只有高保真建模才能发现。
准确反映硬件行为有多重意义。首先,提升准确性。能真实还原硬件故障传播和表现的软件工具,能为故障对模型行为的影响提供更可靠的洞见。这对设计和验证容错架构、确保缓解策略基于真实系统行为至关重要。
其次,提升可复现性。忠实捕捉硬件效应后,故障注入结果可在不同系统和环境间可靠复现,这是严谨科学研究的基石。研究者能更好地对比结果、验证发现、确保一致性。
第三,提升效率。聚焦最具代表性和影响力的故障场景,无需穷举所有比特翻转,能节省计算资源,同时获得全面洞见。
最后,理解硬件故障在软件层的表现,是设计有效缓解策略的前提。研究者若能掌握特定硬件问题对 ML 系统各组件的影响,就能有针对性地加固——如只重训练特定层、有选择地冗余、或提升瓶颈组件的架构稳健性。
Fidelity 等工具正是这一努力的核心。通过建立低层硬件行为与高层软件效应的映射,Fidelity 让研究者能高效、可扩展地开展与真实系统行为一致的故障注入实验。
随着 ML 系统规模不断扩大、部署于越来越多的安全关键场景,这类硬件感知建模将愈发重要。相关领域的持续研究正致力于进一步完善软硬件故障模型的映射,开发兼具效率与真实性的稳健性评估工具。这些进步将为社区提供更强大、可靠的方法,理解并防御硬件故障对 ML 系统的影响。
常见误区与陷阱
稳健性威胁的复杂性和相互关联性,常导致人们对有效防御策略产生误解,特别是认为稳健性技术提供了普遍保护,而没有权衡其局限性。
误区: 对抗稳健性可以通过防御技术实现,而无需权衡。
这一误解使团队相信,对抗性训练或输入预处理等稳健性技术提供了完全的保护,而没有成本。对抗性防御通常会带来显著的权衡,包括降低干净准确性、增加计算开销或对新攻击方法的脆弱性。许多看似对特定攻击有效的防御技术,在面对更强大或自适应的对手时会失效。攻击与防御之间的军备竞赛意味着,稳健性不是一个已解决的问题,而是一个持续的工程挑战,需要不断适应和评估不断演变的威胁。
陷阱: 仅针对已知攻击方法测试稳健性,而不是进行全面的威胁建模。
许多从业者通过针对一些标准对抗攻击进行测试来评估模型稳健性,而没有考虑潜在威胁的全谱。这种方法在模型在有限的测试用例中表现良好时提供了虚假的信心,但在面对新颖攻击载体时却会灾难性失败。现实世界的威胁不仅包括复杂的对抗样本,还包括硬件故障、数据损坏、分布漂移和软件漏洞,这些可能与学术攻击场景大相径庭。全面的稳健性评估需要系统的威胁建模,考虑整个攻击面,而不是仅仅关注一小部分已知漏洞。
误区: 通过收集更多样本的训练数据,可以解决分布漂移问题。
这一信念假设数据集的多样性可以确保对部署中遇到的分布漂移的稳健性。虽然多样化的训练数据确实有帮助,但它无法预见动态现实世界环境中发生的所有可能的分布变化。训练数据集与部署条件相比,始终是有限的。一些分布漂移是不可预测的,源于用户行为的变化、数据源的演变或外部环境因素。有效的稳健性需要自适应系统,具备监测、检测和响应能力,而不仅仅依赖于全面的训练数据。
陷阱: 假设针对一种威胁类别设计的稳健性技术可以保护所有故障模式。
团队往往对特定威胁开发的稳健性技术进行应用,而不理解其在其他故障模式下的局限性。针对基于梯度的攻击设计的对抗性训练,可能无法提高对硬件故障或数据中毒的稳健性。同样,处理良性分布漂移的技术,可能无法应对旨在利用模型弱点的对抗性分布漂移。每种威胁类别都需要专门的防御,有效的稳健性需要分层保护策略,针对潜在故障的全谱,而不是假设跨领域的有效性。
误区: 不同的故障模式是独立的,可以单独解决。
这一假设忽视了不同故障类型之间复杂的相互作用,这可能导致复合脆弱性,超过单个威胁的总和。现实世界的故障往往涉及级联效应,其中一个漏洞启用或放大其他漏洞。考虑以下复合场景:
硬件 - 对抗交互:模型权重中的比特翻转,可能无意中产生对抗性脆弱性,而这种脆弱性在原始模型中并不存在。攻击者发现这些损坏后,可以制作针对性对抗样本,利用特定的权重扰动,攻击成功率达到 95%,而未损坏模型仅为 20%。相反,旨在提高稳健性的对抗性训练,因增加了 2-3$\times$ 的模型复杂度,而提高了因内存和计算需求增加而发生硬件故障的概率。
环境 - 软件级联:逐渐的分布漂移可能因监测软件中的错误而未被检测到,这些错误导致未能记录异常样本。随着漂移在 3-6 个月内的进展,模型准确性下降 40%,但故障监测系统却报告正常。当问题被发现时,数据漂移和检测延迟的复合效应,导致需要完全重新训练模型,而非增量适应,恢复成本增加 10$\times$。
攻击 - 分布利用:攻击者观察到已部署系统中的自然分布漂移,并制作中毒攻击,加速特定方向的漂移。通过注入仅 0.1% 的中毒样本,攻击者可以导致性能下降速度提高 5$\times$,同时躲避针对纯对抗或纯漂移场景校准的检测系统。
三重威胁场景:考虑一个自动驾驶汽车场景,宇宙射线引起的比特翻转损坏感知模型权重,对抗性路标利用这些损坏,季节性天气变化导致分布漂移。组合后,在特定条件下,停车标志的误分类率高达 85%,而单一威胁仅导致 15-20% 的准确性下降。
这些复合场景表明,稳健 AI 系统必须通过全面的失效模式分析、跨领域测试(评估组合脆弱性)和考虑级联故障的防御策略,来应对威胁之间的相互作用,而不是孤立地处理每个威胁。
总结
本章将稳健 AI 确立为在现实世界环境中可靠运行的机器学习系统的核心要求。通过对云端、边缘和嵌入式部署中具体故障的检查,展示了稳健性挑战的多维特性,以及对检测、缓解和恢复的系统化方法的需求。
所提出的统一框架,将稳健性挑战组织为三个相互关联的支柱,这些支柱具有共同的原则,但需要专门化的方法。系统级故障涉及所有 ML 计算的物理基础可靠性,从瞬态宇宙射线效应到永久性硬件退化。输入级攻击则包括通过对抗样本和数据中毒技术,故意操纵模型行为的尝试。环境变化则代表了部署条件的自然演变,这些变化通过分布漂移和概念变化,挑战静态模型假设。
在这三大支柱中,稳健 AI 系统实施了共同的检测和监测原则,以便在威胁影响系统行为之前识别它们;优雅降级原则,以便在压力下维持核心功能;以及自适应响应原则,以便根据检测到的条件调整系统行为。这些原则在不同支柱中的体现各异,但为构建全面的稳健性解决方案提供了统一的基础。
稳健 AI 的实际实现需要贯穿整个 ML 流水线的集成,从数据收集到部署和监测。硬件容错机制必须与对抗性防御和漂移检测系统协调,以提供全面的保护。这一稳健性基础,为第 13 章中详细介绍的操作框架,提供了必要的可靠性保障。在没有本章所开发的全面可靠性机制的情况下,下一章中描述的操作工作流程将缺乏生产部署所需的基本弹性。
表 7 提供了一个实用参考,将三大故障类别映射到其主要检测和缓解策略,为工程师提供了一个系统化框架,以便在稳健 AI 三大支柱中实施全面的稳健性解决方案:
| 故障类别 | 检测方法 | 缓解策略 |
|---|---|---|
| 系统级 | ECC 内存 | 冗余(TMR/DMR) |
| 故障 | BIST(自检)看门狗计时器 电压/温度监测 | 检查点 硬件冗余 纠错码 |
| 输入级 | 输入净化 | 对抗性训练 |
| 攻击 | 异常检测 统计测试 行为分析 | 防御性蒸馏 输入预处理 模型集成 |
| 环境 | 统计监测(MMD、PSI) | 持续学习 |
| 漂移 | 分布比较 性能下降跟踪 概念漂移检测 | 模型重训练 自适应阈值 集成方法 |
关键要点
- 稳健 AI 系统必须应对三大相互关联的威胁类别:系统级故障、输入级攻击和环境变化
- 检测、优雅降级和自适应响应的共同原则适用于所有威胁类型,但需要专门化的实现
- 硬件可靠性直接影响 ML 性能,单比特错误可能导致模型准确性下降 10-50%
- 现实世界的稳健性需要贯穿整个 ML 流水线的集成,而非孤立的保护机制
- 现代 AI 部署需要系统化的稳健性评估和缓解方法
在这些稳健性基础之上,后续章节将探讨可信 AI 系统的其他重要方面。隐私和安全性考虑(第 15 章:安全与隐私)为稳健部署基础设施增加了额外的操作要求,需要专门的技术来保护敏感数据,同时保持系统可靠性。本章所制定的威胁检测和响应原则,为隐私保护和安全 AI 系统设计提供了基础性模式,构建了跨多种环境和应用的可信 AI 部署的综合框架。
构建稳健 AI 系统需要在整个开发过程中嵌入稳健性考虑,从初始设计到部署和维护,通过第 12 章:AI 基准测试中详细说明的系统评估方法进行验证,并与第 17 章:可信 AI 中的负责任 AI 原则保持一致。自动驾驶、医疗设备和基础设施系统等关键应用,要求采取主动方法,预见失效模式并实施广泛的保护措施。这一挑战不仅涉及单个组件,还包括系统级交互,要求全面的方法,以确保在现实世界部署中,在多样和不断变化的条件下可靠运行,同时考虑第 18 章:可持续 AI 中涵盖的稳健系统设计的可持续性影响。
测验:稳健 AI
测试你对机器学习系统稳健性挑战的理解,包括硬件故障、对抗性攻击和分布变化
安全关键应用:系统失效可能导致人员伤亡、重大财产损失或环境破坏的场景,如核电站、飞机控制系统、医疗设备等。这些领域的 ML 部署需满足最高可靠性标准。 ↩︎ ↩︎ ↩︎
瞬时故障与永久故障:瞬时故障是指由宇宙射线或电磁干扰等因素引起的短暂干扰(持续时间从微秒到秒不等),而永久故障则是指造成持久性损害、需要更换组件的故障。现代系统中,瞬时故障的发生频率是永久故障的 1000$\times$。 ↩︎
系统性脆弱性:影响整个系统架构而非单个组件的弱点。与孤立的错误不同,这些错误可能在多个层面上级联,导致成千上万的互联服务同时受到影响。 ↩︎
加固策略:通过冗余、输入验证和安全失效机制等技术,提高系统对故障和攻击的韧性。由于资源限制,边缘系统通常仅对关键组件进行选择性加固。 ↩︎
安全机制:故障发生时自动切换到安全状态的系统。例如,防止故障蔓延的断路器和在组件失效时保持核心功能的优雅降级机制。 ↩︎
静默数据损坏(SDC):在计算或数据传输过程中,硬件或软件错误导致数据损坏而未触发错误检测机制。研究表明,SDC 在大规模系统中影响每 1000-10000 次计算中的 1 次,是一个主要的可靠性问题。 ↩︎
边缘计算:在数据源附近处理数据,而不是在集中式云服务器中,从而将延迟从 ~100 毫秒降低到 <10 毫秒。这对于自动驾驶至关重要,因为毫秒级的延迟可能意味着避免碰撞与灾难性故障之间的区别。 ↩︎
自动驾驶仪:特斯拉的驾驶辅助系统,提供转向、制动和加速等半自动化功能,但仍需驾驶员主动监控。 ↩︎
嵌入式系统:为特定控制功能而设计的计算机系统,通常具有实时约束。从具有千字节内存的 8 位微控制器,到复杂的系统级芯片,范围不一,通常在没有人工干预的情况下运行多年。 ↩︎
ASIL(汽车安全完整性等级):在 ISO 26262 中定义的安全标准,根据风险等级将汽车系统分类,从 ASIL A(最低)到 ASIL D(最高)。安全关键的汽车 ML 系统,如自动驾驶,必须满足 ASIL C 或 D 要求,需具备 99.999% 的可靠性和全面的容错机制,包括冗余传感器、安全失效行为和严格的验证协议。 ↩︎
模型不确定性:机器学习模型无法捕捉数据生成过程的全部复杂性。 ↩︎
可靠性工程:一种工程学科,旨在确保系统在规定时间内无故障地执行其预定功能。最初起源于航空航天和核工业,如今在安全关键应用的 AI 系统中变得至关重要。 ↩︎
单事件干扰(SEUs):由宇宙射线或α粒子引起的辐射诱导的内存或逻辑中的比特翻转。现代 DRAM 的错误率约为每 10^17 次访问 1 次,海平面每个千兆比特大约每月发生 1 次。对于处理大数据集的 AI 系统,1 TB 的模型检查点在一次读取操作中预计会经历 80 次比特翻转,因此错误检测对于可靠的 ML 训练至关重要。 ↩︎
电磁干扰(EMI):由外部电磁源引起的干扰,可能会干扰电子电路。常见来源包括手机、WiFi 和附近的开关电源,因此在敏感系统中需要仔细屏蔽。 ↩︎
串扰:由于寄生电容和电感引起的相邻导体之间的信号耦合。随着电路密度的增加,这个问题变得越来越严重,可能导致时序违规和数据损坏。 ↩︎
平均故障间隔时间(MTBF):一种可靠性指标,测量系统故障之间的平均运行时间。由美国军方在 1960 年代首次正式化(MIL-HDBK-217,1965),基于 1950 年代的可靠性理论,MTBF 计算假设在有用寿命期间故障呈指数分布。对于 AI 系统,MTBF 分析指导检查点频率——一个具有 50000 小时 MTBF 的系统应每 1-2 小时进行一次检查点,以最小化恢复开销,同时保持故障容忍带来的性能影响低于 1%。 ↩︎
错误更正码(ECC)内存:通过冗余信息自动检测和更正比特错误的内存技术。ECC 内存在每 64 位用户数据中添加 8 位错误更正数据,使其能够进行单比特错误更正和双比特错误检测。对于内存错误可能损坏模型权重的 AI 系统至关重要——关键参数的单比特翻转可能导致准确率下降 10-50%,具体取决于受影响的层。 ↩︎
非易失性内存(NVM)技术:存储级内存,介于 DRAM 和传统存储之间,包括英特尔的 3D XPoint(Optane)和新兴的电阻式 RAM 技术。2017 年商业化,NVM 提供比 SSD 快 1000$\times$ 的访问速度,同时保持数据持久性,使新的 ML 系统架构成为可能,模型可以跨电源周期保持在内存中。 ↩︎
GPU 故障特征:图形处理器的错误率显著高于 CPU,因为它们有成千上万个简单核心以更高的频率运行,并进行激进的电源优化。NVIDIA 的 V100 包含 5120 个 CUDA 核心,而服务器 CPU 仅有 24-48 个核心,故障点数量相差 100$\times$。此外,GPU 内存(HBM2)在 V100 中以高达 1.6 TB/s 的带宽运行,几乎没有错误更正,这使得 AI 训练特别容易受到静默数据损坏的影响。 ↩︎
网络分区:分布式系统中临时失去通信的节点组,违反网络连通性假设。1978 年 Lamport 首次系统研究,分区影响大规模 ML 训练,数千个节点必须同步梯度。现代解决方案包括梯度压缩、异步更新和拜占庭容错协议,尽管 10-30% 的节点发生故障,仍能维持训练进度。这些网络中断可能导致训练任务失败、参数同步问题和数据不一致,要求稳健的分布式协调协议以维持系统可靠性。 ↩︎
查找表:一种用更简单的数组索引操作替代运行时计算的数据结构。 ↩︎
电迁移:在电场作用下,导体中金属原子的迁移现象。 ↩︎
氧化层击穿:晶体管中氧化层因电场过强而失效。 ↩︎
热应力:反复经历高低温循环导致的老化。现代 AI 加速器在高负载下常常出现热降频,处理器为防止过热会降低主频,导致 20-60% 的性能下降。这种降频直接影响 ML 训练时长和推理吞吐量,因此热管理对于生产环境下 AI 系统性能一致性至关重要。 ↩︎
检查点与重启机制:定期保存程序状态,以便在故障后从最近的状态恢复运行。 ↩︎
扫描链(Scan Chains):处理器内部专用路径,用于测试时访问寄存器和逻辑。 ↩︎
奇偶校验(Parity Checks):通过增加一位,统计数据字中 1 的总数,实现基本错误检测。 ↩︎
循环冗余校验(CRC):由 W. Wesley Peterson 于 1961 年提出的错误检测算法,广泛应用于数字通信和存储。CRC 通过多项式校验和检测 99.9% 以上的传输错误,计算开销极低。对于 ML 数据管道,CRC-32 常用于分布式训练系统中验证梯度更新,防止数据损坏影响模型性能。接收端重新计算校验和并比对,检测错误。ECC 内存模块则采用更高级的检测和纠错码,能检测并修正单比特或多比特内存错误。 ↩︎
双模冗余(DMR):将计算过程复制两份,通过比对识别和纠正错误的容错方法。 ↩︎
三模冗余(TMR):三份计算并比对,多数投票确定结果的容错方法。 ↩︎
传感器融合(Sensor Fusion):集成多种传感器数据,获得比单一传感器更准确可靠的感知。最早应用于 1980 年代军事领域,融合摄像头(可见光)、激光雷达(深度)、雷达(抗恶劣天气)、超声波(短距离)等。特斯拉方案同时处理 8 个摄像头、12 个超声波和前向雷达,每小时生成 40GB 传感器数据,实现稳健的自动驾驶决策。 ↩︎
热备(Hot Spares):系统冗余设计中的备用部件,随时准备在主部件故障时无缝接管,保障系统不中断运行。 ↩︎
人类与机器感知的差异:人类视觉强调物体不变性和语义理解,而机器视觉则从训练数据中学习统计模式,形成脆弱的决策边界,容易受到不可察觉的扰动的攻击。2013 年,Szegedy et al. 首次提出了这一差异,揭示了微小扰动如何在不改变语义内容的情况下,显著改变模型预测。 ↩︎
神经网络学习机制:神经网络从数据中学习模式的基本过程,包括基于梯度的优化、决策边界的形成和高维特征表示。这些核心概念在 第 3 章:深度学习基础 中有全面介绍。 ↩︎
对抗性设置中的维度诅咒:在高维空间中(例如,224×224×3 = 150,528 维用于 ImageNet 图像),微小的扰动会显著累积。以 ε=0.01 为例,总扰动幅度可达 √150,528 × 0.01 ≈ 3.88,足以在保持对人类的不可察觉性的同时,改变模型预测。非线性决策边界造成复杂的分离,使模型对精确的输入修改敏感。 ↩︎
神经网络理论基础:神经网络处理信息、学习表示和在高维空间中进行预测的数学和算法原理。完整的理论内容见 第 3 章:深度学习基础 . ↩︎
快速梯度符号法(FGSM):由 Goodfellow et al. 于 2014 年提出的第一个实用对抗性攻击方法。通过沿梯度符号的方向移动,单步生成对抗性示例,计算高效但通常效果不如迭代方法。 ↩︎
可迁移性:2015 年发现的一个惊人特性,即对抗性示例通常可以在不同的神经网络之间迁移。成功率通常在 30-70% 之间,使得在没有直接模型访问的情况下,进行实际的黑盒攻击成为可能。 ↩︎
数据中毒:2012 年 Biggio 等人首次正式提出的攻击方法,攻击者通过向训练数据注入恶意样本来破坏模型行为。与针对推理阶段的对抗样本不同,中毒攻击针对学习过程本身,因此更难检测和防御。 ↩︎
后门攻击:Gu 等人于 2017 年提出,通过在训练数据中植入隐藏触发器,使模型在推理时遇到特定模式即激活恶意行为。攻击成功率可超 99%,且对干净输入的准确率影响极小,极具危险性。 ↩︎
双用途困境:在 AI 领域,指具有正负两面潜力的技术如何防止被滥用的挑战。 ↩︎
Kolmogorov-Smirnov 检验:Kolmogorov(1933)和 Smirnov(1939)提出的非参数统计检验,用于比较概率分布。在对抗性检测中,K-S 检验将输入特征分布与训练数据比对,p 值 <0.05 表示可能存在对抗性操控。计算效率高(O(n log n)),但仅适用于单变量分布,高维输入(如图像)需降维处理。 ↩︎
特征压缩:通过降低精度(如 8 位量化为 4 位)或空间分辨率(如中值滤波)减少输入复杂度。Xu 等人在 2017 年提出,利用对抗性扰动通常需高精度的特点。将色阶从 256 降至 16 可消除 70-90% 的对抗性样本,同时保持 95%+ 的干净准确率,适合实时部署。原始与压缩输入预测不一致时,提示可能存在对抗性操控。 ↩︎
贝叶斯神经网络:将权重视为概率分布、引入概率推断的高级神经网络架构。需理解 第 3 章:深度学习基础 中的神经网络基础。 ↩︎
Dropout 机制:训练时随机失活神经元的正则化技术,防止过拟合、提升泛化能力。详见 第 3 章:深度学习基础 。 ↩︎
自编码器:专为学习高效数据表示而设计的神经网络架构,通过压缩编码重构输入数据。需理解 第 3 章:深度学习基础 的神经网络基础。 ↩︎
Huber 损失:一种用于稳健回归的损失函数,对数据中的异常值不如平方误差敏感。 ↩︎
正则化:神经网络中通过在损失函数中加入惩罚项防止过拟合的方法。 ↩︎
极小极大:博弈论和决策理论中的决策策略,试图最小化最大可能损失。 ↩︎
最小权限原则:安全理念,用户仅被授予完成工作所需的最低访问权限。 ↩︎
贝叶斯神经网络:在权重上引入概率分布的神经网络,可量化预测不确定性,提升决策稳健性。 ↩︎
集成方法:通过组合多个模型提升预测准确性的机器学习方法。 ↩︎
F1 分数:综合精确率(正确正例预测)和召回率(实际正例识别比例)的模型准确性指标,为二者的调和平均数。 ↩︎
故障模型:描述硬件故障如何表现和传播的形式化规范。包括固定故障模型(位元永久为 0 或 1)、单比特翻转模型(暂时性位元反转)和拜占庭模型(任意恶意行为)等。对设计现实的故障注入实验至关重要。 ↩︎
现场可编程门阵列(FPGAs):可重构硬件设备,包含数百万个逻辑块,可被编程实现自定义数字电路。最早由 Xilinx 于 1985 年开发,FPGA 在软件灵活性和硬件性能之间架起了桥梁,使快速原型设计和专用加速器成为可能。 ↩︎
束流测试:一种通过控制粒子辐射暴露硬件来评估其对软错误的抵抗力的测试方法。广泛应用于航空航天、医疗设备和高可靠性计算等领域。 ↩︎
多模态传感器数据:同时采集自多种传感器(如摄像头、激光雷达、雷达)的信息,为环境感知提供互补视角。对自动系统的稳健感知至关重要。 ↩︎