KWS 特征工程
概述
本教程将重点介绍特征工程在优化音频分类任务(如语音识别)中的关键作用。需要注意的是,任何机器学习模型的性能都高度依赖于所用特征的质量。我们将深入探讨特征提取的底层机制,主要聚焦于音频信号处理领域的基石——梅尔频率倒谱系数(MFCC)。
机器学习模型,尤其是传统算法,并不能直接理解音频波形。它们理解的是以某种有意义方式排列的数字,也就是“特征”。这些特征封装了音频信号的特性,使模型能够区分不同的声音。
本教程专注于为音频分类生成特征。这对于将机器学习应用于各种音频数据(如语音识别、音乐分类、基于翅膀振动声的昆虫分类或其他声音分析任务)都非常有意义。
KWS 简介
最常见的 TinyML 应用是关键词检测(KWS),它属于语音识别的一个子领域。与将所有语音转录为文本的通用语音识别不同,KWS 只关注在连续音频流中检测特定“关键词”或“唤醒词”。系统会被训练识别这些预定义的短语或词汇,如 yes 或 no。简而言之,KWS 是一种专门化的语音识别形式,具有独特的挑战和需求。
下面是一个典型的基于 MFCC 特征转换器的 KWS 流程:
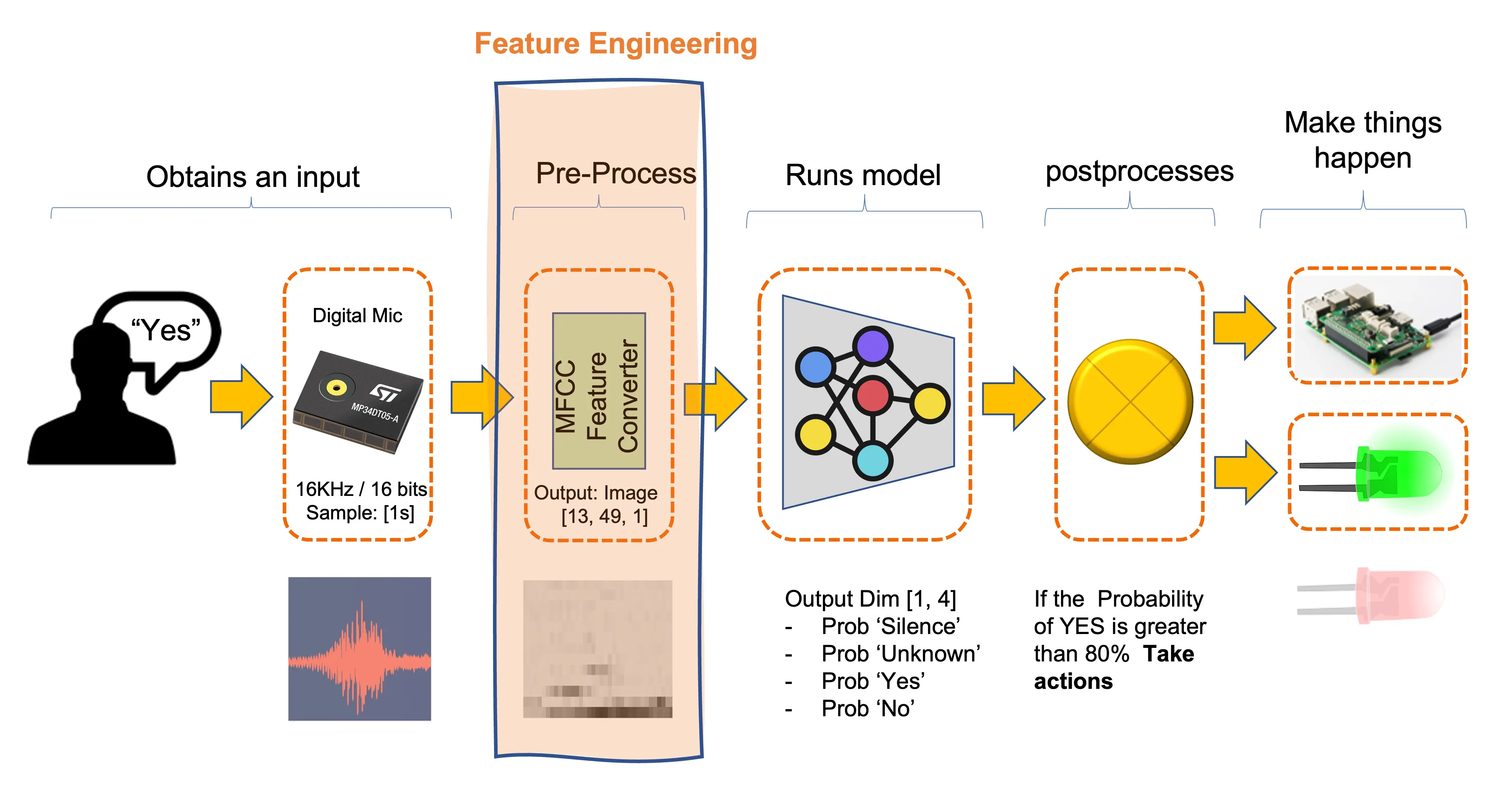
KWS 的应用场景
- 语音助手:如 Amazon Alexa 或 Google Home,KWS 用于检测唤醒词(如“Alexa”或“Hey Google”)以激活设备。
- 语音控制:在汽车或工业场景中,KWS 可用于触发特定命令,如“启动引擎”或“关闭灯光”。
- 安全系统:基于语音的安全系统可通过 KWS 识别口令进行身份验证。
- 电信服务:客服热线可利用 KWS 根据关键词分流来电。
与通用语音识别的区别
- 计算效率:KWS 通常比完整语音识别计算量更小,因为只需识别少量短语。
- 实时处理:KWS 通常要求实时、低延迟地检测关键词。
- 资源受限:KWS 模型通常设计得非常轻量,便于在微控制器或手机等资源有限的设备上运行。
- 任务聚焦:通用语音识别模型需应对丰富词汇和多种口音,而 KWS 模型则针对特定关键词进行精细调优,常常需要在嘈杂环境下准确识别。
音频信号基础
理解音频信号的基本属性对于有效特征提取和成功应用机器学习算法至关重要。音频信号是随时间变化的复杂波形,反映空气压力的波动。其主要属性包括采样率、频率和幅度。
频率与幅度: 频率 指波形每秒振荡的次数,单位为 Hz,不同频率对应不同音高。 幅度 表示振荡的大小,与声音的响度相关。二者都是描述音频信号音调和节奏特性的关键特征。
采样率: 采样率 (单位 Hz)表示每秒采集的样本数。采样率越高,数字信号越接近原始模拟信号,但计算资源消耗也越大。常见采样率有 44.1 kHz(CD 质量)、16 kHz 或 8 kHz(语音识别)。在 TinyML 项目中,通常采用 16 kHz。虽然人耳可听频率最高达 20 kHz,但语音信号一般不超过 8 kHz,传统电话系统采样率为 8 kHz。
为了准确还原信号,采样率至少应为信号最高频率的两倍。
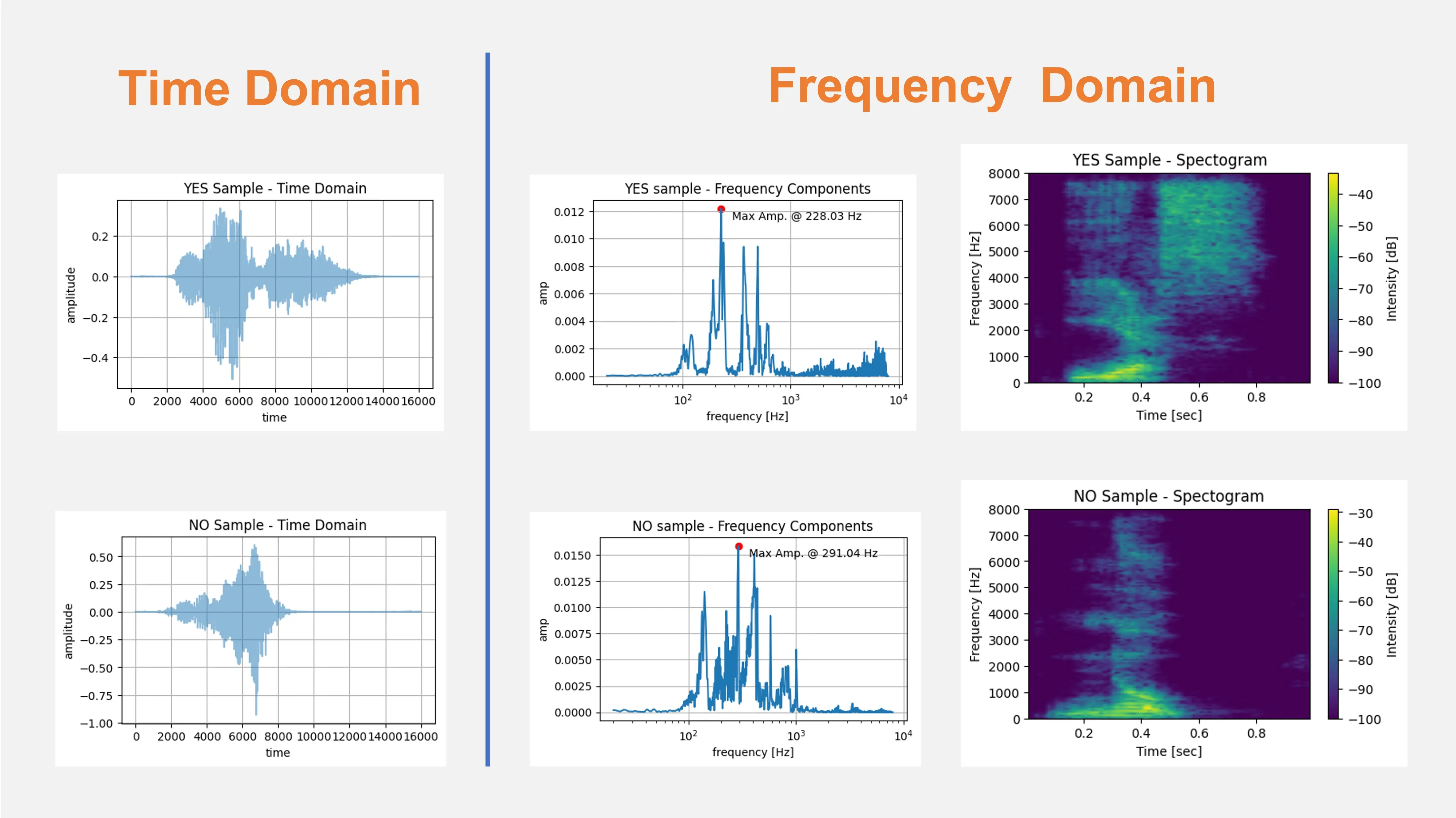
- 时域与频域:音频信号既可在时域(波形随时间变化)分析,也可在频域(各频率成分及其幅度)分析。时域有助于观察信号的时序特征(如起止点、持续时间),但难以体现音调特性。频域分析则通过傅里叶变换揭示信号的频谱结构,这对于识别音符或语音音素等任务尤为重要。
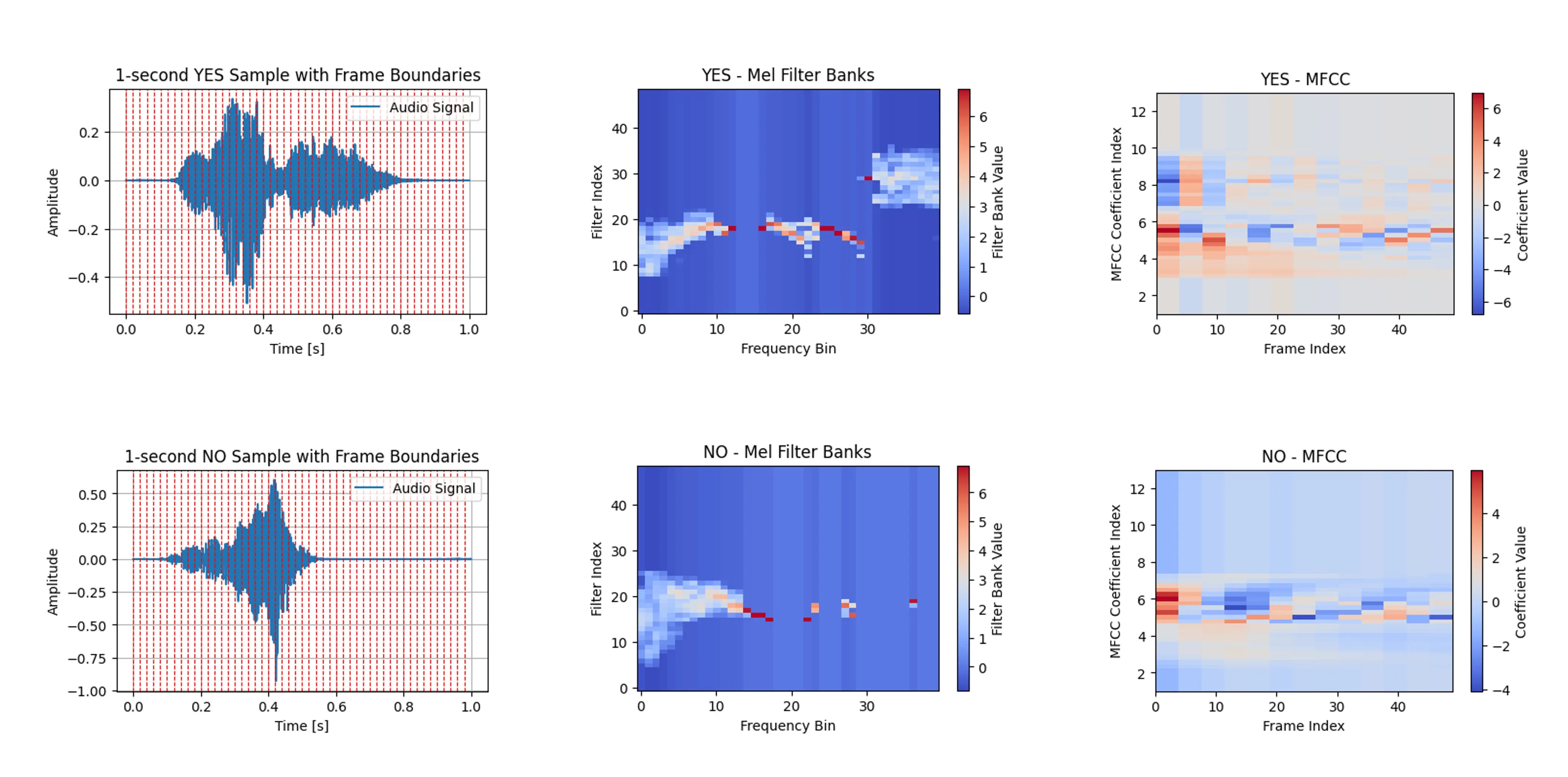
下图展示了单词 YES 和 NO 在时域(原始音频)与频域的典型表示:
为什么不用原始音频?
直接用原始音频数据进行机器学习虽然看似简单,但在构建高效、健壮模型时存在诸多挑战。
以 16 kHz 采样率为例,原始音频在 TinyML 设备上用于关键词检测(KWS)会面临高维度、时序特征难以捕捉、对噪声敏感、缺乏语义特征等问题。因此,像 MFCC 这样的特征提取方法更适合资源受限场景。
具体问题包括:
- 高维度:高采样率下,音频数据量巨大。例如 1 秒音频(16 kHz)有 16,000 个数据点,导致计算复杂度高、训练慢、资源消耗大,且信息密度低。
- 时序依赖:原始音频的时序结构复杂,简单模型难以捕捉。虽然循环神经网络(如 LSTM )可建模,但在微型设备上训练和推理都很困难。
- 噪声与变异性:原始音频易受环境噪声、录音距离、声源方向、房间声学等因素影响,数据复杂度高。
- 缺乏语义特征:原始波形不直接包含分类所需的语义特征,如音高、节奏、频谱特性等。
- 信号冗余:音频信号中常有大量冗余信息,部分数据对任务无贡献,导致学习效率低、易过拟合。
因此,常用 MFCC、Mel 频率能量(MFE)、频谱图等特征提取方法,将原始音频转化为更紧凑、信息量更高的特征,既降维又降噪,更适合机器学习。
MFCC 概述
什么是 MFCC?
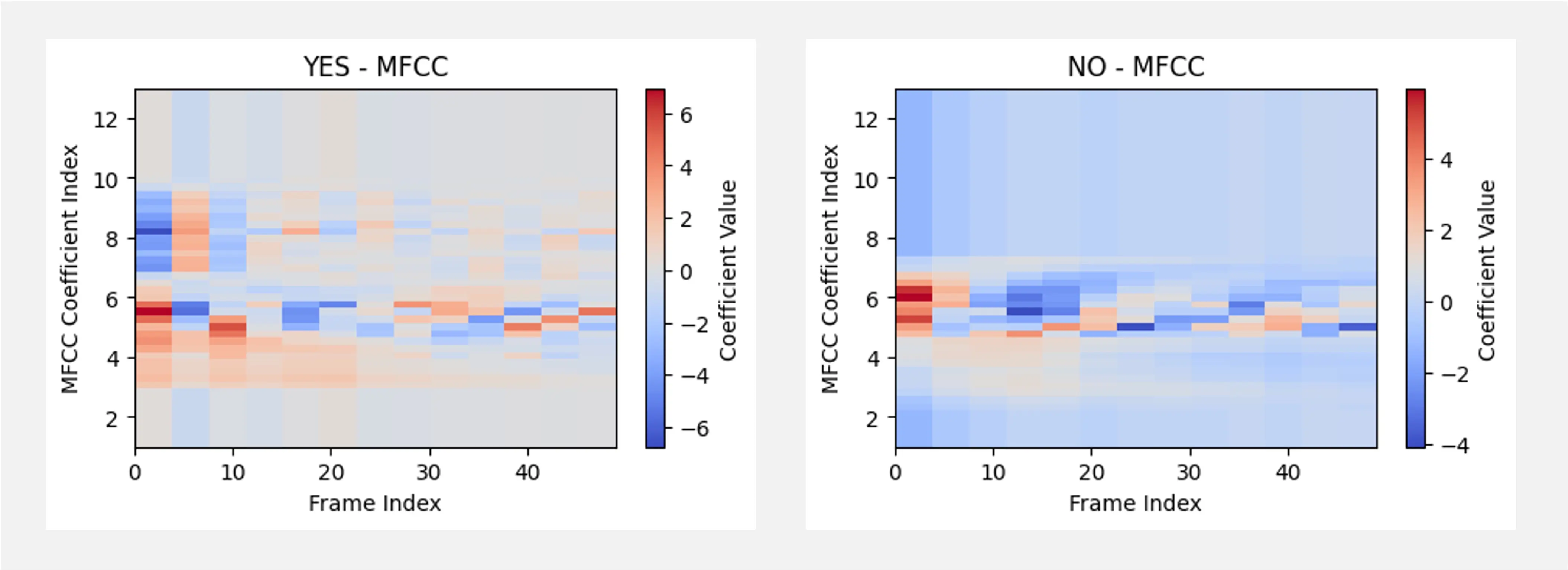
梅尔频率倒谱系数(MFCC) 是一组基于音频信号频谱内容提取的特征,模拟人耳对不同频率的感知,广泛用于捕捉语音信号的音素特性。MFCC 的计算过程包括预加重、分帧、加窗、快速傅里叶变换(FFT)、Mel 滤波器组、离散余弦变换(DCT)等步骤,最终得到紧凑的频谱特征表示。
下图展示了单词 YES 和 NO 的 MFCC 表示:
推荐观看此 视频 ,了解 MFCC 的原理及计算方法。
为什么 MFCC 重要?
MFCC 在关键词检测(KWS)和 TinyML 场景下尤为重要,原因如下:
- 降维:MFCC 能在保留音频关键信息的同时大幅降低数据维度,非常适合资源受限的 TinyML 应用。
- 稳健性:MFCC 对噪声、音高和幅度变化不敏感,特征稳定,适合音频分类。
- 模拟人耳听觉:MFCC 的 Mel 频率刻度贴合人耳对不同频率的感知,特别适合语音识别等需“拟人”感知的场景。
- 计算高效:MFCC 计算过程高效,适合实时、低功耗设备。
总之,MFCC 在信息丰富性和计算效率之间取得了良好平衡,是受限环境下音频分类的首选特征。
MFCC 的计算流程
MFCC 的计算主要包括以下步骤,尤其适用于 TinyML 设备上的 KWS 任务:
- 预加重:通过滤波器增强高频成分,平衡频谱。公式为 $y(t)=x(t)-\alpha x(t-1)$,$\alpha$ 通常取 0.97。
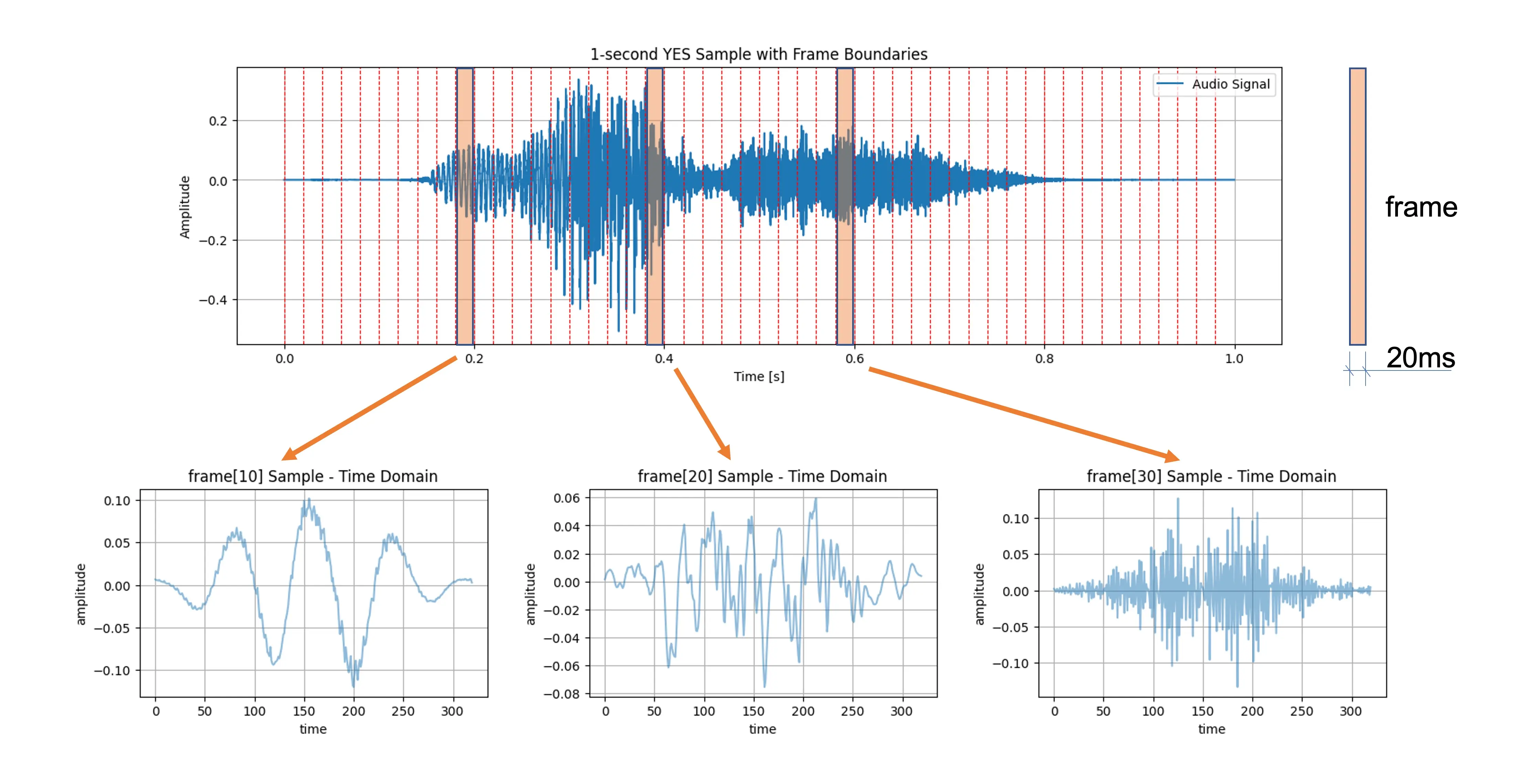
- 分帧:将音频信号分割为短帧(一般 20~40 毫秒),假设短时内信号频率特性稳定。帧移(stride)决定帧之间的重叠。
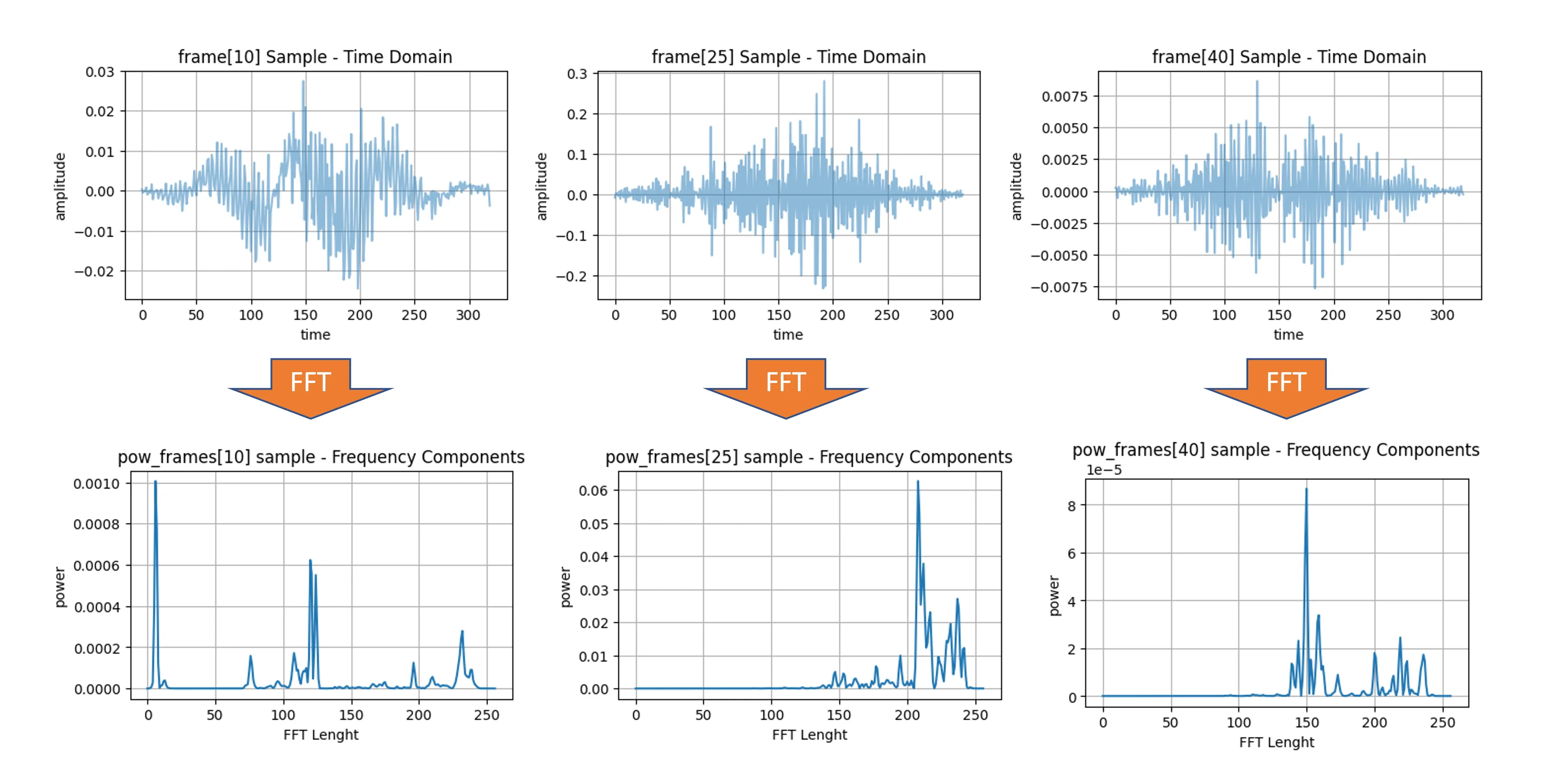
- 加窗:对每帧加窗(如 Hamming 窗),减少边界不连续性,为傅里叶变换做准备。下图展示了三帧(10、20、30)加窗后的时域样本(帧长、帧移均为 20 ms):
- 快速傅里叶变换(FFT):对每帧做 FFT,将信号从时域转为频域。只取幅度用于计算功率谱,功率谱反映各频率分量的能量。
功率谱 $P(f)$ 定义为 $P(f)=|X(f)|^2$,$X(f)$ 为信号 $x(t)$ 的傅里叶变换。平方操作突出强频率分量,有助于捕捉音频的关键频谱特征,适用于音频分类、语音识别、KWS 等任务。
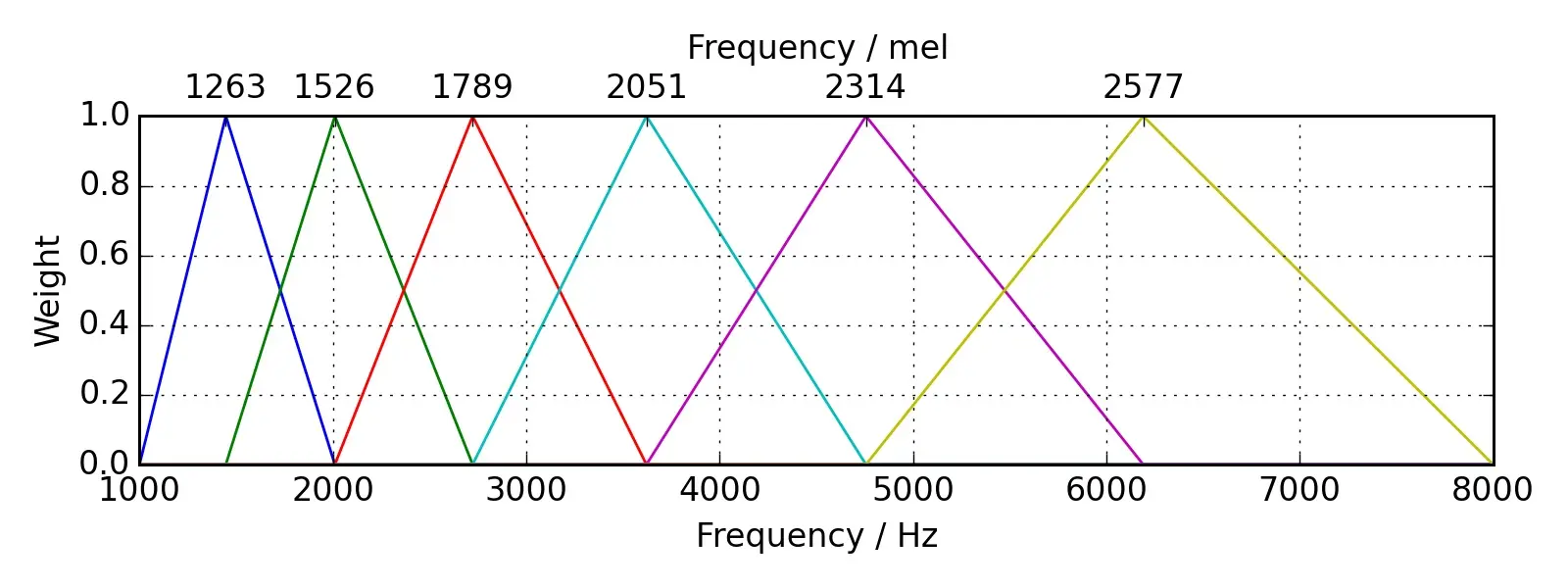
- Mel 滤波器组:将频域映射到 Mel 频率刻度 ,更贴近人耳听觉。低频区滤波器密集,高频区稀疏,通常提取 20~40 个三角滤波器的能量,并取对数以便后续处理。
- 离散余弦变换(DCT):对 Mel 能量取对数后做 DCT ,去相关并压缩数据,通常保留前 12~13 个系数,作为最终 MFCC 特征向量。
Python 实践
让我们用实际音频样本操作一遍上述流程。可在 Google CoLab 打开 notebook,提取你的音频样本的 MFCC 特征: 【在 Colab 打开】
总结
我们该选用哪种特征提取方法?
MFCC、Mel 频率能量(MFE)、频谱图等都是常用的音频特征提取技术,各有适用场景。
一般来说,MFCC 更关注于捕捉功率谱包络,对细粒度频谱变化不敏感,但抗噪声能力强,适合语音相关任务。频谱图或 MFE 则保留了更多细节,适合需要区分微小频谱差异的任务。
MFCC 特别适合
- 语音识别:MFCC 能有效识别语音信号中的音素信息。
- 说话人识别:可用于区分不同说话人的声音特征。
- 情感识别:能捕捉语音中反映情感状态的细微变化。
- 关键词检测:尤其适合 TinyML 场景,计算量小、特征紧凑。
频谱图或 MFE 更适合
- 音乐分析:频谱图能捕捉音乐的和声与音色结构,适合流派分类、乐器识别、音乐转录等任务。
- 环境声音分类:识别非语音环境声(如雨声、风声、交通声)时,频谱图更具区分力。
- 鸟鸣识别:鸟叫等生物声信号的细节常需频谱图来捕捉。
- 生物声学信号处理:如海豚、蝙蝠叫声分析,频谱细节至关重要。
- 音频质量检测:专业音频分析常用频谱图识别噪声、杂音等问题。