eBPF 程序
在这一章中,让我们来谈谈编写 eBPF 代码。我们需要考虑在内核中运行的 eBPF 程序本身,以及与之交互的用户空间代码。
内核和用户空间代码
首先,你可以用什么编程语言来编写 eBPF 程序?
内核接受字节码形式的 eBPF 程序 1。人工编写这种字节码是可能的,就像用汇编语言写应用程序代码一样——但对人类来说,使用一种可以被编译(即自动翻译)为字节码的高级语言通常更实用。
由于一些原因,eBPF 程序不能用任意的高级语言编写。首先,语言编译器需要支持发出内核所期望的 eBPF 字节码格式。其次,许多编译语言都有运行时特性——例如 Go 的内存管理和垃圾回收,使它们不适合。在撰写本文时,编写 eBPF 程序的唯一选择是 C(用 clang/llvm 编译)和最新的 Rust。迄今为止,绝大多数的 eBPF 代码都是用 C 语言发布的,考虑到它是 Linux 内核的语言,这是有道理的。
至少,用户空间的程序需要加载到内核中,并将其附加到正确的事件中。有一些实用程序,如 bpftool,可以帮助我们解决这个问题,但这些都是低级别的工具,假定你有丰富的 eBPF 知识,它们是为 eBPF 专家设计的,而不是普通用户。在大多数基于 eBPF 的工具中,有一个用户空间的应用程序,负责将 eBPF 程序加载到内核中,传入任何配置参数,并以用户友好的方式显示 eBPF 程序收集的信息。
至少在理论上,eBPF 工具的用户空间部分可以用任何语言编写,但在实践中,有一些库只支持相当少的语言。其中包括 C、Go、Rust 和 Python。这种语言的选择更加复杂,因为并不是所有的语言都有支持 libbpf 的库,libbpf 已经成为使 eBPF 程序在不同版本的内核中可移植的流行选择。(我们将在 第四章 中讨论 libbpf)。
附属于事件的自定义程序
eBPF 程序本身通常是用 C 或 Rust 编写的,并编入一个对象文件 2。这是一个标准的 ELF(可执行和可链接格式,Executable and Linkable Format)文件,可以用像 readelf 这样的工具来检查,它包含程序字节码和任何映射的定义(我们很快就会讨论)。如 图 3-1 所示,如果在前一章中提到的验证器允许的话,用户空间程序会读取这个文件并将其加载到内核中。
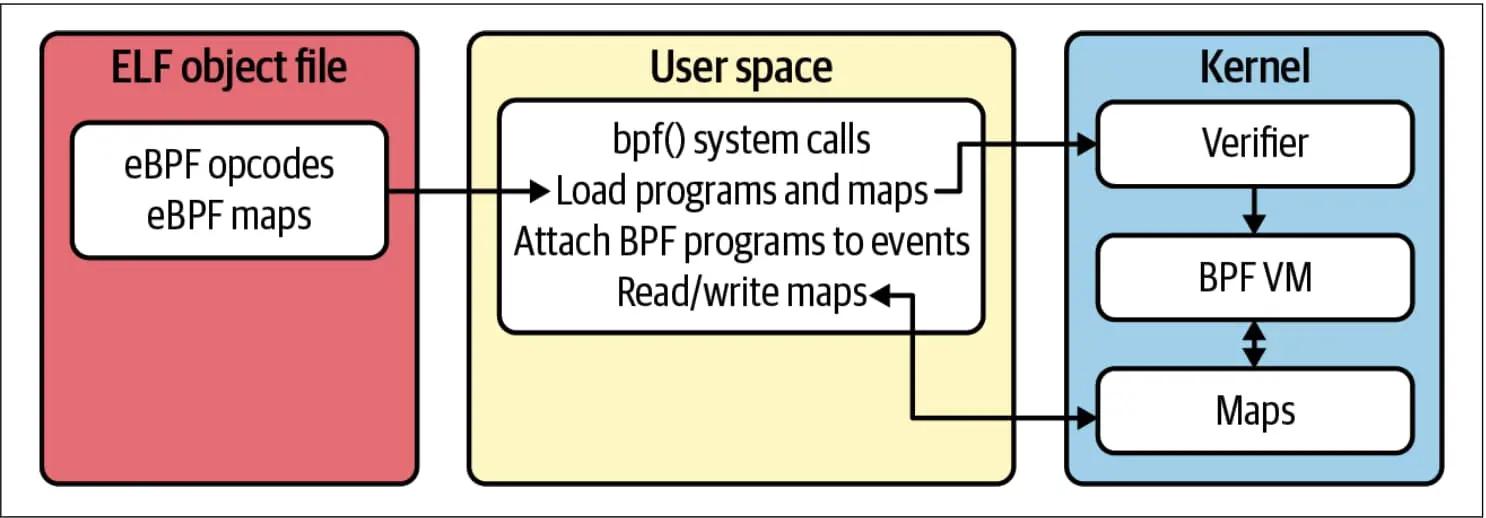
eBPF 程序加载到内核中时必须被附加到事件上。每当事件发生,相关的 eBPF 程序就会运行。有一个非常广泛的事件,你可以将程序附加到其中;我不会涵盖所有的事件,但以下是一些更常用的选项。
从函数中进入或退出
你可以附加一个 eBPF 程序,在内核函数进入或退出时被触发。当前的许多 eBPF 例子都使用了 kprobes(附加到一个内核函数入口点)和 kretprobes(函数退出)的机制。在最新的内核版本中,有一个更有效的替代方法,叫做 fentry/fexit 3。
请注意,你不能保证在一个内核版本中定义的所有函数一定会在未来的版本中可用,除非它们是稳定 API 的一部分,如 syscall 接口。
你也可以用 uprobes 和 uretprobes 将 eBPF 程序附加到用户空间函数上。
Tracepoints
你也可以将 eBPF 程序附加到内核内定义的 tracepoints 4。通过在 /sys/kernel/debug/tracing/events 下查找机器上的事件。
Perf 事件
Perf 5 是一个收集性能数据的子系统。你可以将 eBPF 程序挂到所有收集 perf 数据的地方,这可以通过在你的机器上运行 perf list 来确定。
Linux 安全模块接口
LSM 接口在内核允许某些操作之前检查安全策略。你可能见过 AppArmor 或 SELinux,利用了这个接口。通过 eBPF,你可以将自定义程序附加到相同的检查点上,从而实现灵活、动态的安全策略和一些运行时安全工具的新方法。
网络接口——eXpress Data Path
eXpress Data Path(XDP)允许将 eBPF 程序附加到网络接口上,这样一来,每当收到一个数据包就会触发 eBPF 程序。它可以检查甚至修改数据包,程序的退出代码可以告诉内核如何处理该数据包:传递、放弃或重定向。这可以构成一些非常有效的网络功能 6 的基础。
套接字和其他网络钩子
当应用程序在网络套接字上打开或执行其他操作时,以及当消息被发送或接收时,你可以附加运行 eBPF 程序。在内核的网络堆栈中也有称为 流量控制(traffic control) 或 tc 的 钩子,eBPF 程序可以在初始数据包处理后运行。
一些功能可以单独用 eBPF 程序实现,但在许多情况下,我们希望 eBPF 代码能从用户空间的应用程序接收信息,或将数据传递给用户空间的应用程序。允许数据在 eBPF 程序和用户空间之间,或在不同的 eBPF 程序之间传递的机制被称为 map。
eBPF Map
map 的开发是 eBPF 缩略语中的 e 代表 extended 重要区别之一。
map 是与 eBPF 程序一起定义的数据结构体。有各种不同类型的 map,但它们本质上都是键值存储。eBPF 程序可以读取和写入 map,用户空间代码也可以。map 的常见用途包括:
- eBPF 程序写入关于事件的指标和其他数据,供用户空间代码以后检索。
- 用户空间代码编写配置信息,供 eBPF 程序读取并作出相应的行为。
- eBPF 程序将数据写入 map,供另一个 eBPF 程序以后检索,允许跨多个内核事件的信息协调。
如果内核和用户空间的代码都要访问同一个映射,它们需要对存储在该映射中的数据结构体有一个共同的理解。这可以通过在用户空间和内核代码中加入定义这些数据结构体的头文件来实现,但是如果这些代码不是用相同的语言编写的,作者将需要仔细创建逐个字节兼容的结构体定义。
我们已经讨论了 eBPF 工具的主要组成部分:在内核中运行的 eBPF 程序,加载和与这些程序交互的用户空间代码,以及允许程序共享数据的 map。为了更具体化,让我们看一个例子。
Opensnoop 示例
在 eBPF 程序的例子中,我选择了 opensnoop,一个可以显示任何进程所打开的文件的工具。这个工具的原始版本是 Brendan Gregg 最初在
BCC 项目
中编写的许多 BPF 工具之一,你可以在 GitHub 上找到。它后来被重写为 libbpf(你将在下一章见到它),在这个例子中,我使用 libbpf-tools 目录下的较新版本。
当你运行 opensnoop 时,你将看到的输出在很大程度上取决于当时在虚拟机上发生了什么,但它应该看起来像这样。
PID COMM FD ERR PATH
93965 cat 3 0 /etc/ld.so.cache
93965 cat 3 0 /lib/x86_64-linux-gnu/libc.so.6
93965 cat 3 0 /usr/lib/locale/locale-archive
93965 cat 3 0 /usr/share/locale/locale.alias
...
每一行输出表示一个进程打开(或试图打开)一个文件。这些列显示了进程的 ID,运行的命令,文件描述符,错误代码的指示,以及被打开的文件的路径。
Opensnoop 的工作方式是将 eBPF 程序附加到 open() 和 openat() 系统调用上,所有应用程序都必须通过这些调用来要求内核打开文件。让我们深入了解一下这是如何实现的。为了简洁起见,我们将不看每一行代码,但我希望这足以让你了解它是如何工作的(如果你对这么深的内容不感兴趣的话,请跳到下一章!)。
Opensnoop eBPF 代码
eBPF 代码是用 C 语言编写的,在
opensnoop.bpf.c
文件中。在这个文件的开头,你可以看到两个 eBPF map 的定义 —— start 和 events:
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, u32);
__type(value, struct args_t);
} start SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
} events SEC(".maps");
当 ELF 对象文件被创建时,它包含了每个 map 和每个要加载到内核的程序的部分,SEC() 宏定义了这些部分。
当我们研究这个程序的时候,你会看到,在系统调用被处理的时候,start map 被用来临时存储系统调用的参数 —— 包括被打开的文件的名称。events map 7 用于将事件信息从内核中的 eBPF 代码传递给用户空间的可执行程序。如 图 3-2 所示。
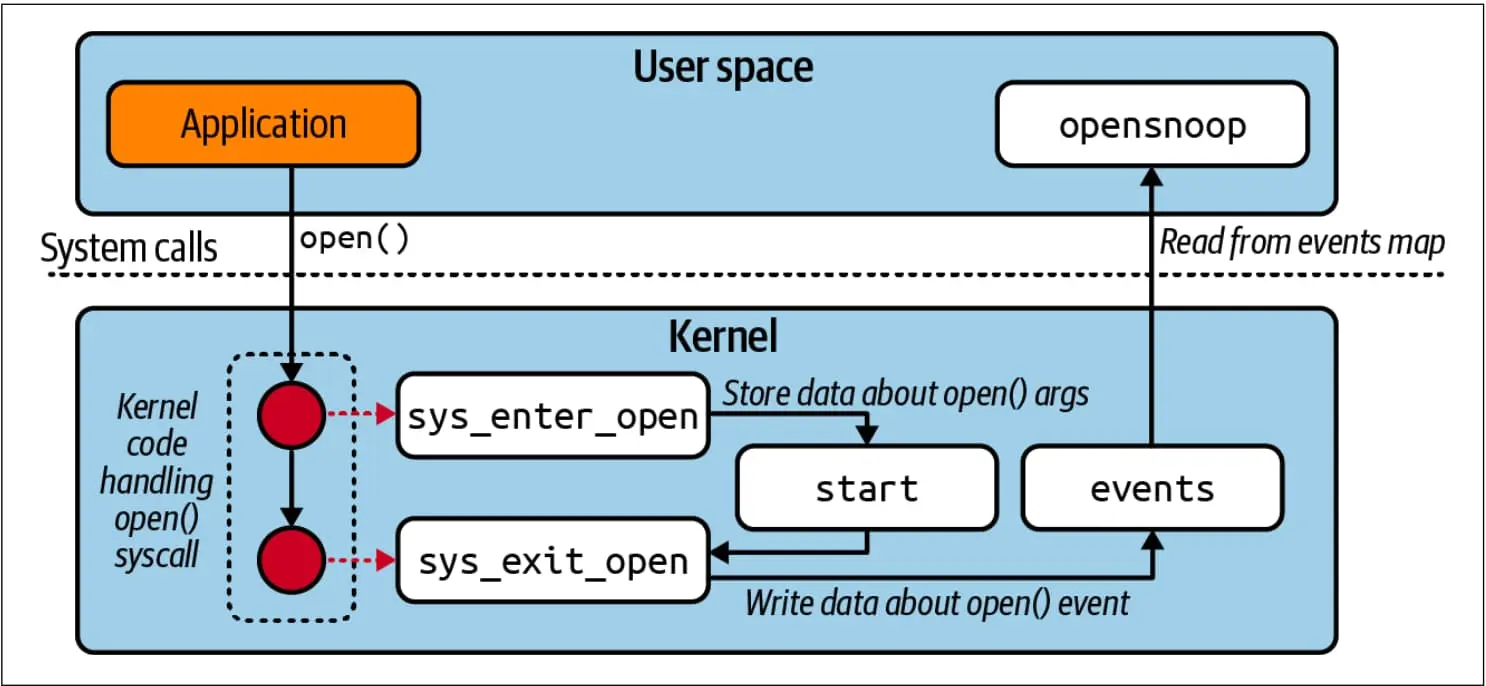
在 opensnoop.bpf.c 文件的后面,你会发现两个极其相似的函数:
SEC("tracepoint/syscalls/sys_enter_open")
int tracepoint__syscalls__sys_enter_open(struct trace_event_raw_sys_enter* ctx)
和
SEC("tracepoint/syscalls/sys_enter_openat")
int tracepoint__syscalls__sys_enter_openat(struct
trace_event_raw_sys_enter* ctx)
有两个不同的系统调用用于打开文件 8:openat() 和
open()。它们是相同的,除了 openat() 有一个额外的参数是目录文件描述符,而且要打开的文件的路径名是相对于该目录而言的。同样,除了处理参数上的差异,opensnoop 中的两个函数也是相同的。
正如你所看到的,它们都需要一个参数,即一个指向名为 trace_event_raw_sys_enter 结构体的指针。你可以在你运行的特定内核生成的 vmlinux 头文件中找到这个结构体的定义。编写 eBPF 程序之道包括找出每个程序接收的结构体作为其上下文,以及如何访问其中的信息。
这两个函数使用一个 BPF 辅助函数来检索调用这个 syscall 的进程 ID:
u64 id = bpf_get_current_pid_tgid();
这段代码得到了文件名和传递给系统调用的标志,并把它们放在一个叫做 args 的结构体中:
args.fname = (const char *)ctx->args[0];
args.flags = (int)ctx->args[1];
这个结构体被写入 start map 中,使用当前程序 ID 作为键。
这就是 eBPF 程序在进入 syscall 时所做的一切。但在 opensnoop.bpf.c 中定义了另一对 eBPF 程序,当系统调用退出时被触发。
这个程序和它的双胞胎 openat() 在函数 trace_exit() 中共享代码。你有没有注意到,所有被 eBPF 程序调用的函数的前缀都是 static __always_inline?这迫使编译器将这些函数的指令放在内联中,因为在旧的内核中,BPF 程序不允许跳转到一个单独的函数。新的内核和 LLVM 版本可以支持非内联的函数调用,但这是一种安全的方式,可以确保 BPF 验证器满意(现在还有一个 BPF 尾部调用的概念,即执行从一个 BPF 程序跳转到另一个程序。你可以在
eBPF 文档
中阅读更多关于 BPF 函数调用和尾部调用的内容)。
trace_exit() 函数创建一个空的事件结构体:
struct event event = {};
该结构体将用即将结束的 open/openat 系统调用的信息填充,并通过 events map 发送到用户空间。
在 start 哈希 map 中应该有一个与当前进程 ID 相对应的条目:
ap = bpf_map_lookup_elem(&start, &pid);
这里有先前在调用 sys_enter_open(at) 时写入的关于文件名和标志的信息。标志字段是一个直接存储在结构体中的整数,所以直接从结构体中读取它是可以的:
event.flags = ap->flags;
相反,文件名被写入用户空间内存的一些字节中,验证者需要确定这个 eBPF 程序从内存的那个位置读取这个字节数是安全的。这是用另一个辅助函数 bpf_probe_read_user_str() 完成的:
bpf_probe_read_user_str(&event.fname, sizeof(event.fname), ap->fname);
当前的命令名称(即进行 open(at) 系统调用的可执行文件的名称)也被复制到事件结构体中,使用另一个 BPF 辅助函数:
bpf_get_current_comm(&event.comm, sizeof(event.comm));
事件结构体被写入 events perf buffer map 中:
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &event, sizeof(event));
用户空间的代码从这个 map 中读取事件信息。在我们讨论这个问题之前,让我们简单看看 Makefile。
libbpf-tools Makefile
当你构建 eBPF 代码时,你得到一个包含 eBPF 程序和 map 的二进制定义的对象文件。你还需要一个额外的用户空间可执行文件,它将把这些程序和 map 加载到内核中,作为用户 9 的接口。我们看看如何构建 opensnoop 的 Makefile,看看它是如何创建 eBPF 对象文件和可执行文件的。
Makefile 由一组规则组成,这些规则的语法可能有点不透明,所以如果你不熟悉 Makefile,也不特别关心这些细节,请随意跳过这一节。
我们正在看的 opensnoop 的例子是一大批示例工具的其中之一,它们都是用 Makefile 构建的,你可以在 libbpf-tools 目录中找到。在这个文件中,并不是所有的东西都特别有意义,但有几个规则我想强调一下。第一条规则是使用 bpf.c 文件并使用 clang 编译器来创建一个 BPF 目标对象文件。
$(OUTPUT)/%.bpf.o: %.bpf.c $(LIBBPF_OBJ) $(wildcard %.h) $(AR..
$(call msg,BPF,$@)
$(Q)$(CLANG) $(CFLAGS) -target bpf -D__TARGET_ARCH_$(ARCH) \
-I$(ARCH)/ $(INCLUDES) -c $(filter %.c,$^) -o $@ && \
$(LLVM_STRIP) -g $@
因此,opensnoop.bpf.c 被编译成 \$(OUTPUT)/open snoop.bpf.o。这个对象文件包含将被加载到内核的 eBPF 程序和 map。
另一条规则使用 bpftool gen skeleton,从该 bpf.o 对象文件中包含的 map 和程序定义中创建一个骨架头文件:
$(OUTPUT)/%.skel.h: $(OUTPUT)/%.bpf.o | $(OUTPUT)
$(call msg,GEN-SKEL,$@)
$(Q)$(BPFTOOL) gen skeleton $< > $@
opensnoop.c 用户空间代码包括这个 opensnoop.skel.h 头文件,以获得它与内核中的 eBPF 程序共享的 map 的定义。这使得用户空间和内核代码能够了解存储在这些 map 中的数据结构体的布局。
下面的规则将用户空间的代码 opensnoop.c 的编译成为 $(OUTPUT)/opensnoop.o 的二进制对象:
$(OUTPUT)/%.o: %.c $(wildcard %.h) $(LIBBPF_OBJ) | $(OUTPUT)
$(call msg,CC,$@)
$(Q)$(CC) $(CFLAGS) $(INCLUDES) -c $(filter %.c,$^) -o $@
最后,有一条规则是使用 cc 将用户空间的应用对象(在我们的例子中是 opensnoop.o)链接成一组可执行文件:
$(APPS): %: $(OUTPUT)/%.o $(LIBBPF_OBJ) $(COMMON_OBJ) | $(OUT...
$(call msg,BINARY,$@)
$(Q)$(CC) $(CFLAGS) $^ $(LDFLAGS) -lelf -lz -o $@
现在你已经看到 eBPF 和用户空间程序分别是如何生成的,让我们看看用户空间的代码。
Opensnoop 用户空间代码
如前所述,与 eBPF 代码交互的用户空间代码几乎可以用任何编程语言编写。我们在本节讨论的例子是用 C 语言写的,但如果你有兴趣,你可以把它与用 Python 写的原始 BCC 版本相比较,你可以在 bcc/tools 中找到。
用户空间的代码在 opensnoop.c 文件中。文件的前半部分有 #include 指令(其中之一是自动生成的 opensnoop.skel.h 文件),各种定义,以及处理不同命令行选项的代码,我们在此不再赘述。我们还将略过 print_event() 等函数,该函数将一个事件的信息显示到屏幕上。从 eBPF 的角度来看,所有有趣的代码都在 main() 函数中。
你会看到像 opensnoop_bpf__open()、opensnoop_bpf__load() 和 opensnoop_bpf__attach() 这样的函数。这些都是在由 bpftool gen skeleton 10 自动生成的代码中定义的。这个自动生成的代码处理所有在 eBPF 对象文件中定义的单个 eBPF 程序、map 和附着点。
opensnoop 启动和运行后,它的工作就是监听 events 的 perf
buffer,并将每个事件中包含的信息写到屏幕上。首先,它打开与 perf buffer 相关的文件描述符,并将 handle_event() 设置为新事件到来时要调用的函数:
pb = perf_buffer__new(bpf_map__fd(obj->maps.events),
PERF_BUFFER_PAGES, handle_event, handle_lost_events,
NULL, NULL);
然后它对缓冲区事件进行轮询,直到达到一个时间限制,或者用户中断程序:
while (!exiting) {
err = perf_buffer__poll(pb, PERF_POLL_TIMEOUT_MS);
... }
传递给 handle_event() 的数据参数指向 eBPF 程序为该事件写进 map 的事件结构体。
用户空间的代码可以检索这些信息,将其格式化并写出来给用户看。
正如你所看到的,opensnoop 注册了 eBPF 程序,每当有应用程序进行 open() 或 openat() 系统调用时都会被调用。这些运行在内核中的 eBPF 程序收集有关该系统调用的上下文信息 —— 可执行文件名和进程 ID—— 以及被打开的文件的信息。这些信息被写进一个 map,用户空间可以从中读取并显示给用户。
你会在 libbpf-tools 目录中找到几十个这样的 eBPF 工具的例子,每个例子通常都是一个系统调用,或者是一系列相关的系统调用,如 open() 和 openat()。
系统调用是一个稳定的内核接口,它提供了一个非常强大的方式来观察(虚拟)机器上正在发生的事情。但是,不要以为 eBPF 编程只能用于拦截系统调用。还有很多其他的固定接口,包括 LSM 和网络堆栈中的各种点,eBPF 可以连接到这些接口。如果你愿意承担内核版本变更的风险,eBPF 程序可以附加的范围是绝对宽广的。
也可以跳过对象文件,使用 bpf() 系统调用直接将字节码加载到内核。 ↩︎
entry/fexit在 Alexei Starovoitov 的文章中描述:《引入 BPF Trampoline》(LWN.net,2019 年 11 月 14 日)。 ↩︎Oracle Linux 博客,《Taming Tracepoints in the Linux Kernel》,作者 Matt Keenan,2020 年 3 月 9 日发布。 ↩︎
Brendan Gregg 的网站是一个关于 perf events 的良好信息来源。 ↩︎
如果你有兴趣看到这方面的具体例子,你可以看一下我在 2021 年 eBPF 峰会上的 演讲 ,我在几分钟内实现了一个非常基本的负载均衡器,以此来说明我们如何使用 eBPF 来改变内核处理网络数据包的方式。 ↩︎
在写这篇文章的时候,这段代码使用的是事件映射的 perf 缓冲器。如果你今天为最近的内核编写这段代码,你会从一个 ring buffer 中获得更好的性能,这是一个更新的替代方案。 ↩︎
在一些内核中,你还会发现
openat2(),但这个版本的 opensnoop 没有处理这个问题,至少在写作本文时是这样的。 ↩︎你可以使用一个通用的工具,如 bpftool,它可以读取 BPF 对象文件并对其进行操作,但这需要用户知道关于加载什么以及将程序附加到什么事件的细节。对于大多数应用来说,编写一个特定的工具来为最终用户简化这一点是有意义的。 ↩︎