In the AI era, open source is no longer just “visible source code”—it’s about “loadable models and tunable intelligence.” US companies build moats with closed models, while Chinese vendors open source to build ecosystems. The meaning and practice of open source have fundamentally changed.
Introduction
A decade ago, the cloud native wave saw US companies like Google, Red Hat, and Docker open source massive infrastructure software—Kubernetes, Docker, and Istio became the common language for developers worldwide.
But in the era of large language models, the situation has reversed: US tech giants rarely open source their core models, while Chinese vendors (such as Zhipu, Alibaba, MiniMax, 01.AI, Moonshot, etc.) frequently release open source models. Why this shift? What are the fundamental differences between “AI open source” and “infrastructure open source”?
How Open Source Logic Has Changed: Cloud Native vs. AI Era
The table below compares the core logic, monetization, and resource dependencies of open source in the cloud native and AI eras.
| Era | Representative Technologies | Core Open Source Logic | Monetization Model | Resource Dependency |
|---|---|---|---|---|
| Cloud Native Era (2010s) | Istio, Kubernetes, Docker | Building standards, expanding ecosystem | Managed services (GKE, EKS) | CPU-level compute, community-driven |
| AI Large Model Era (2020s) | Ollama, GPT, Qwen | Model as asset, data control | API services or closed SaaS | GPU-level compute, centralized |
Cloud native open source emphasizes “building standards together,” while AI large model open source means “opening up core assets.” Their essence and motivations are fundamentally different.
Why US Companies No Longer Truly Open Source
US tech companies have chosen closed source in the AI era for several reasons:
- Business logic has shifted to moat-building: Training costs are high, model weights are the core barrier, and open sourcing means giving up competitiveness.
- Compute and data are not reproducible: The community cannot replicate GPT-4-level models.
- Security and compliance constraints: Model weights may involve user data and face strict regulation.
- “Open” is redefined as “API accessible”: Platforms are open in terms of interfaces, not code or weights.
Why Chinese Companies Are More Willing to Open Source
Chinese vendors actively open source in AI for several reasons:
- Open source is used to build ecosystems and brand awareness quickly.
- Dual-track model of “open source + commercial license” balances ecosystem growth and revenue.
- Data policy environment is more flexible, with policies encouraging proprietary models.
- National strategy drives “independent controllability” and “open source ecosystem” as technology priorities.
The Shift of Open Source Platforms: From GitHub to Hugging Face
The platform for open source has also changed. The table below shows the differences between GitHub and Hugging Face in open source forms.
| Platform | Era | Core Asset | Open Source Form |
|---|---|---|---|
| GitHub | Software / Cloud Native | Source code (.go /.py /.js) | Compilable, runnable |
| Hugging Face | AI Models | Model weights + Tokenizer + Inference scripts | Loadable, tunable |
GitHub mainly open sources “program logic,” while Hugging Face open sources “model intelligence.” Their core assets are completely different.
Core Elements of AI Open Source
Open source in the AI era is not just about code—it includes weights, inference code, and fine-tuning capability. Below are the three key elements.

Open Weights
All knowledge learned during model training is stored in the weight parameters. Having the weights means owning the “intelligence body” of the model. Closed models (like GPT-4) only provide APIs, not weights.
Open Inference Code
Inference code defines how to load weights, tokenize, perform concurrent computation, and optimize memory. The code below demonstrates how to load the Qwen3 model:
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model and tokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # Automatically select FP16 or FP32
device_map="auto" # Automatically assign to GPU / CPU
)
# Inference
prompt = "Hello, please briefly explain the principle of fine-tuning large models."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Fine-tuning
Fine-tuning means further training an open source model to adapt it to specific data and scenarios. Common methods include LoRA / QLoRA, which are low-cost and can turn general models into enterprise-specific assistants.
Why Enterprises Prefer Self-Deployment Over API
In practice, enterprises often prefer to self-deploy open source models. The table below summarizes the main reasons and explanations.
| Reason | Explanation |
|---|---|
| Data privacy | Sensitive data cannot be sent externally |
| Cost control | API is billed per call, expensive long-term |
| Customizability | Can integrate enterprise knowledge for RAG / Agent |
| Operability | Can run offline, unified monitoring, compliant deployment |
Qwen3-4B-Instruct-2507 Model Structure and Usage
Taking Qwen3-4B-Instruct-2507 as an example, here is the directory structure and usage on Hugging Face.
Directory Structure Explanation
After downloading, the model directory looks like this:
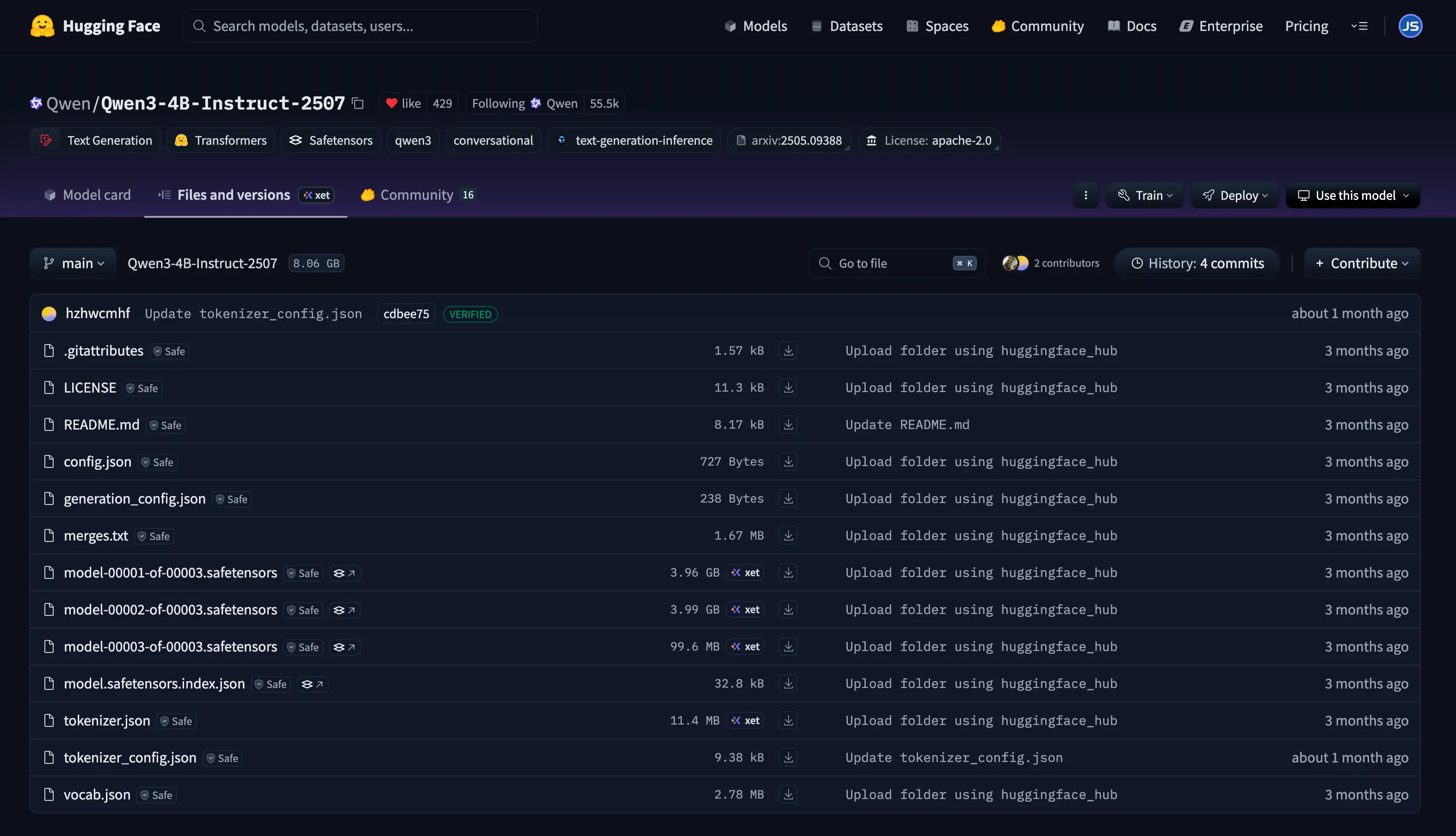
The directory structure of open source models can be illustrated as follows:
In the directory, the model.safetensors file contains the model weights, storing billions of parameters.
Other files such as README.md, LICENSE, .gitattributes serve the following purposes:
| Category | Files | Purpose |
|---|---|---|
| Model Definition | config.json, model.safetensors.*, model.safetensors.index.json | Defines model structure and weights |
| Tokenizer | tokenizer.json, tokenizer_config.json, vocab.json, merges.txt | Defines text input/output encoding |
| Inference Config | generation_config.json | Controls generation strategy (temperature, top_p, etc.) |
| Metadata | README.md, LICENSE, .gitattributes | Model introduction, license, Git attributes |
Loading and Inference Code Example
The following code shows how to load and run the Qwen3-4B-Instruct-2507 model:
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
device_map="auto"
)
# Build input and run inference
prompt = "Hello, explain the meaning of cloud native."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
If GPU memory is insufficient, you can use quantized loading:
mdl = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
device_map="auto",
load_in_8bit=True
)
Developer Application Scenarios for Open Source LLMs
Open source large models bring developers a wealth of application scenarios. The table below summarizes common directions, uses, and tools.
| Direction | Use Case | Tools |
|---|---|---|
| Chat / Assistant | Local ChatGPT | LM Studio, TextGen WebUI |
| Knowledge Base RAG | Private data Q&A | LangChain, LlamaIndex |
| Agent | Task execution, tool calling | LangGraph, Autogen |
| Fine-tuning / Adaptation | Custom enterprise knowledge | PEFT, LoRA |
| Model Service | Deploy as API service | vLLM, TGI, Ollama |
| Research | Model compression, quantization | BitsAndBytes, FlashAttention |
Open Source Model Lifecycle
The full lifecycle of an open source model from download to production deployment is as follows:
- Download model weights
- Load inference code
- Local inference or deploy as a service
- Fine-tune with proprietary data
- Integrate with enterprise RAG / Agent
- Launch in production
How to Judge the License of Open Source Large Models
Downloading an open source model = owning a “loadable, trainable, and potentially commercializable intelligent brain”; But whether you can use it for profit depends on its license.
Just like traditional open source projects, whether a large model can be used commercially depends on its license.
How to check:
- Hugging Face model homepage (top right) →
License: ... LICENSEorREADME.mdfile in the repository root
A brief decision flow:
Summary
In the AI era, open source has shifted from “visible source code” to “loadable models and tunable intelligence.” US vendors maintain business moats with closed models, while Chinese vendors use open source to seize ecosystem leadership. The true value of open source is empowering developers—enabling everyone to own their own “general-purpose brain” and build intelligent infrastructure.