本文译自 TheNewStack 推出的 eBOOK Kubernetes at the Edge ,仅供参考。
边缘计算的多重含义:定义“边缘”
什么是边缘?边缘在哪里?
和许多 IT 术语一样,边缘计算有多种含义,讨论起来容易混淆。但无论定义如何,“边缘”都指的是核心 IT 基础设施之外的某个位置——可以是物理的,也可以是逻辑的。
传统上,核心基础设施指的是企业自有的数据中心,存放着服务器和数据存储。随着时间推移,这一定义扩展到了企业数据中心、托管机房,以及 AWS、GCP、Azure 等云数据中心。
即使采用边缘计算,架构原则依然不变:核心基础设施是企业 IT 的基础,包括业务运行所需的数据库、操作系统、网络和硬件,与企业的核心业务逻辑相区分。
在企业场景中,边缘可能指的是远程用户通过 VPN 或互联网访问核心数据中心,此时“边缘”是网络拓扑中的一个位置。
但边缘也指计算和存储的位置;简单来说,边缘是一个地方,而不仅仅是拓扑的概念。这个位置又细分为三个层级:近边缘、远边缘和设备边缘:
- 近边缘:通常指边缘数据中心,即靠近终端用户和设备的小型分布式计算设施,旨在本地处理数据以降低延迟、提升实时应用性能。例如,企业用户通过互联网或 VPN 连接到边缘数据中心,再由边缘数据中心通过广域网(WAN,通常是 SD-WAN)连接到核心数据中心。近边缘位置可以拥有自己的 CDN 缓存、安全框架和性能优化机制。
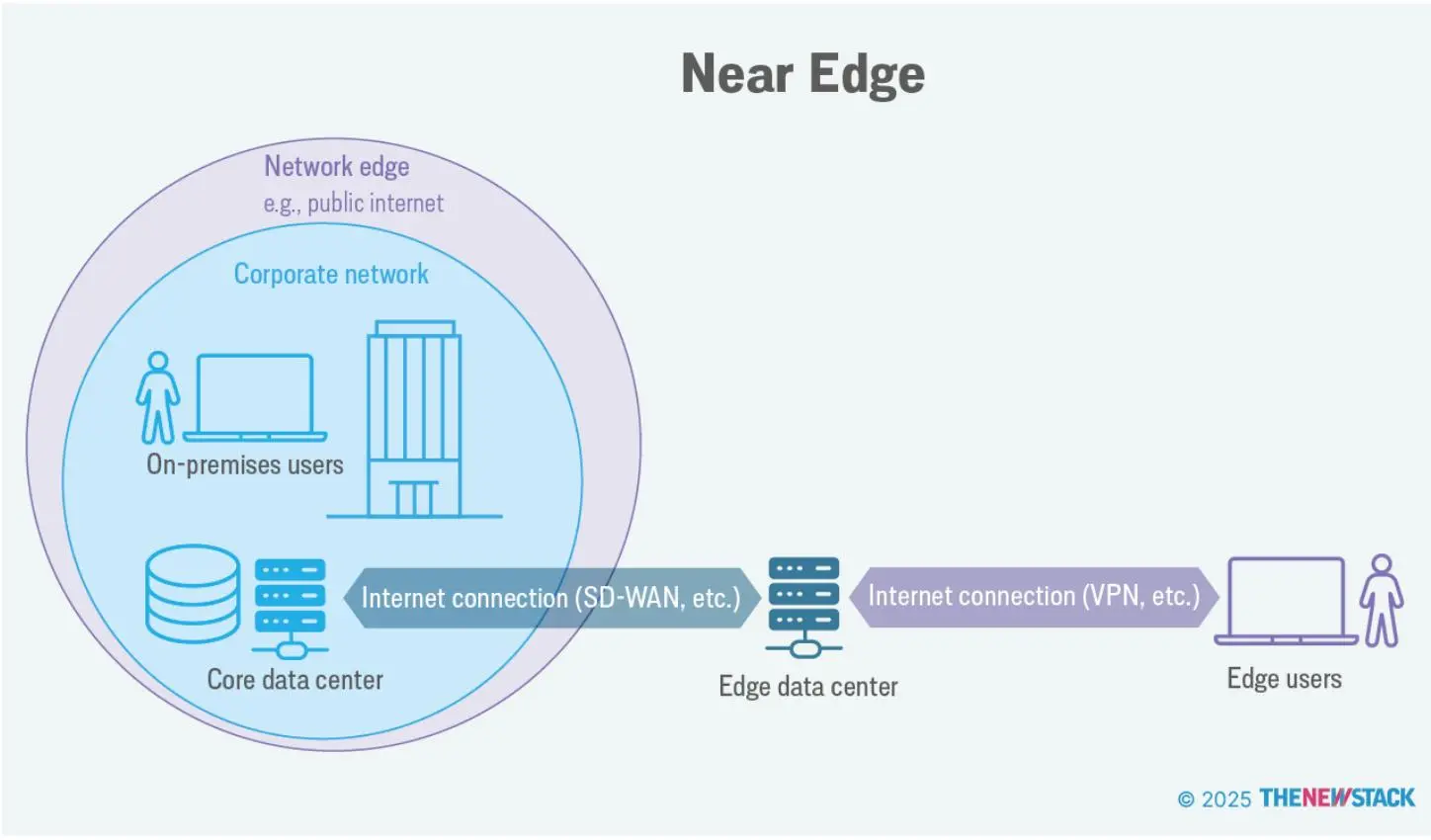
远边缘:指最分散的地点,基础设施部署在终端设备和用户附近,如基站、零售或餐饮的 POS 系统。
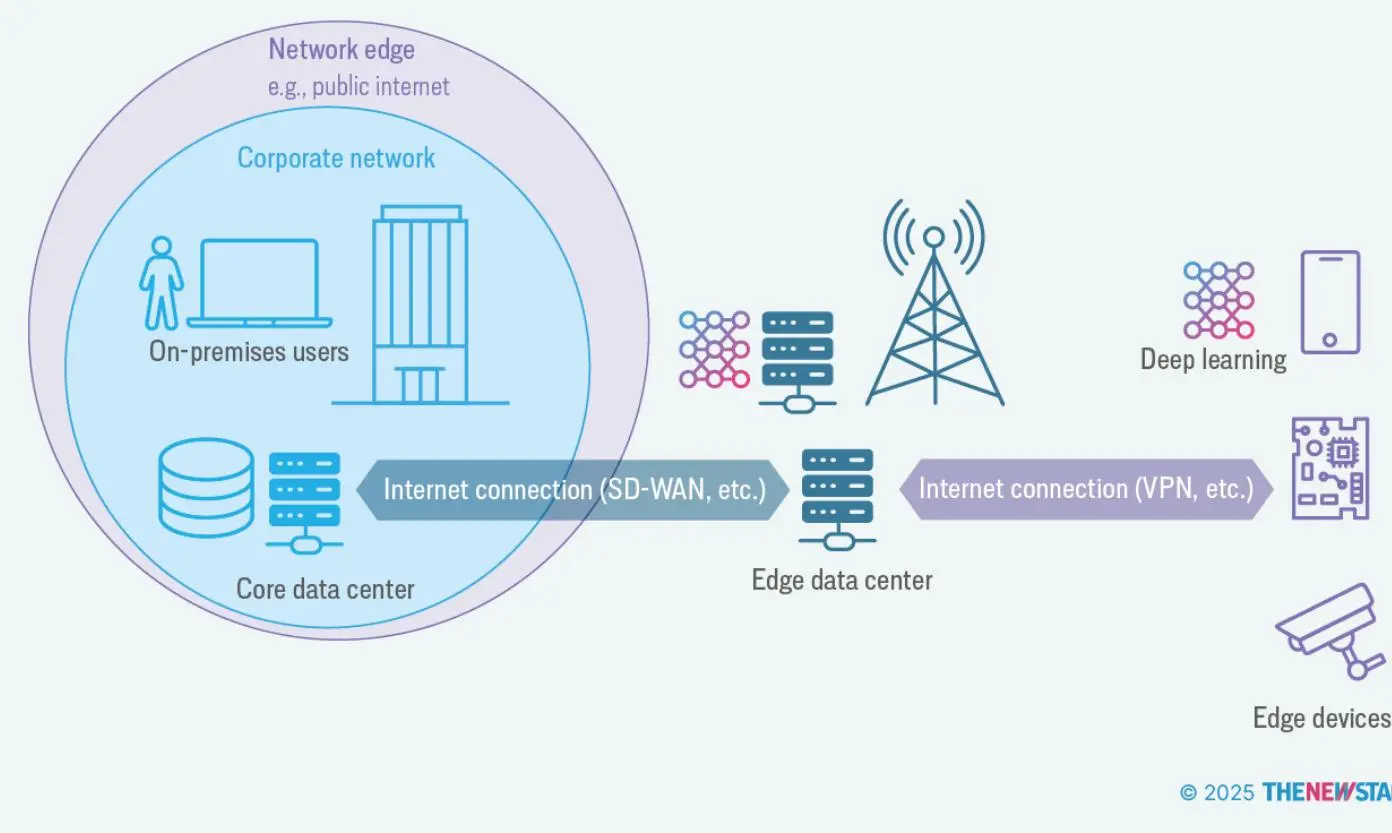
设备边缘:指传感器和控制器等终端设备的位置,包括实际的边缘设备及其周边。这些设备通过基站或边缘服务器连接到企业数据中心或云端。边缘设备包括智能摄像头、工业传感器、可穿戴健康监测仪、医疗成像扫描仪等,广泛应用于零售、交通、医疗、制造等行业。
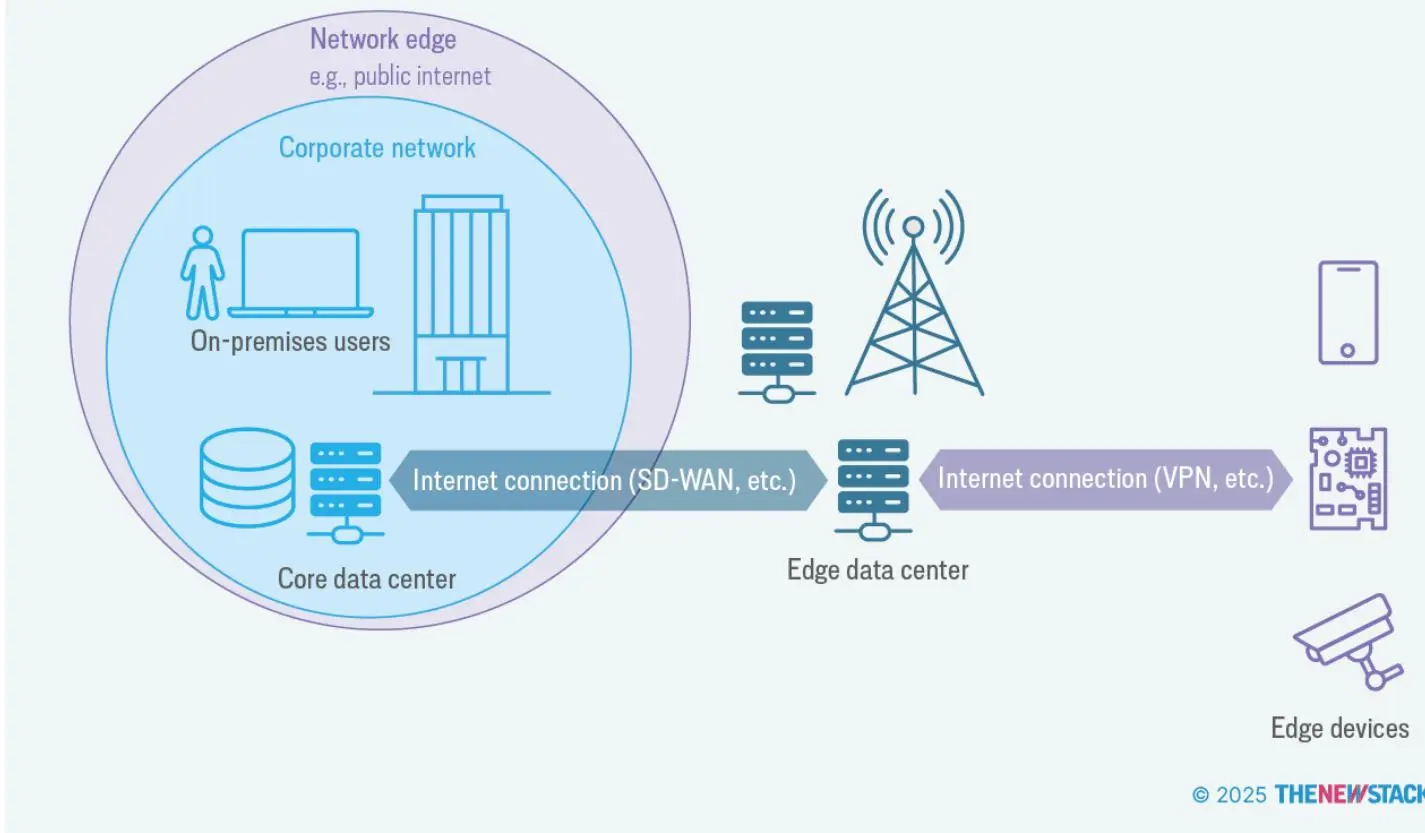
边缘设备通常专注于某一特定任务,如视频监控或自动化生产线上的机械控制。它们的计算能力仅够支持专属活动。我们所说的物联网(IoT),无论是消费级还是工业级,指的就是这些边缘设备。
换个角度看,边缘计算覆盖了从小型数据中心和区域设施(近边缘),到零售门店和餐厅(远边缘),再到单个设备(设备边缘)——每个层级都需根据连接性、资源和工作负载关键性采用不同方案。
边缘的优势
近边缘和远边缘相比中心化模型有六大优势:
- 数据本地处理,降低延迟、提升响应速度。
- 提高网络带宽效率,减少数据传输到云端的需求。
- 降低碳排放,减少网络流量。
- 本地处理敏感信息,增强数据安全和隐私。
- 分布式架构提升可靠性和弹性。
- 更好支持实时应用及 AI/ML 模型。
中心化也会带来隐私成本,且某些数据处理可能违反数据主权法规。
以设备边缘为例,无论这些设备部署在风电场、工厂、医院还是车辆,现代嵌入式设备都能产生海量数据。例如,风力发电机配备了振动、温度、声音传感器,以及用于检测损坏或预测故障的 AI 声学传感器。
由于数据量巨大,边缘设备成为 AI/ML 的理想目标。传统的数据分析和机器学习通常需要将数据传回中心处理。
这样可以利用高性能硬件(如 GPU),让数据科学团队深入分析、优化模型。
但数据中心化也带来诸多挑战,如连接不稳定、带宽受限、延迟高。以风电场为例,带宽不足可能导致无法将所有数据传回核心数据中心。
中心化还会带来隐私成本,甚至可能违反数据主权法规。
因此,将数据处理迁移到数据产生地更为合理。尤其是训练机器学习模型时,边缘处理更有利于隐私保护。结合设备端联邦学习、差分隐私和安全聚合等技术,可以进一步提升隐私安全。
边缘不仅仅是 AI。荷兰绿色能源公司 Vandebron 管理着数百个风电和太阳能场,实时跟踪全国能源产量以平衡电网和需求。公司通过在线市场直接连接供需,买家可明确了解能源来源和资金流向。
更广泛地说,若目标是构建更可持续的 IT 系统,边缘计算能减少网络流量,而网络流量约占 IT 行业碳排放的一半。还能利用电池储能,或通过时段调度在清洁能源时充电。
此外,减少数据中心的按需计算任务可降低制冷需求,节能减排。边缘数据中心也需制冷,但因靠近居民区,废热可用于供暖或加热游泳池。T.Loop 就是将数据中心废热转化为供暖的公司之一。
为降低成本,云“去迁移”——即将工作负载从超大规模云迁回边缘——越来越常见。这也能降低延迟、提升资源利用率,并在需要时支持云端弹性扩展。
边缘的挑战
这些优势——更好的隐私、更低碳排放、更低成本——固然重要,但边缘计算也有挑战,主要有两点:
- 计算资源有限:边缘设备虽日益强大,但受限于体积、重量和功耗(SWaP),CPU/GPU 和内存资源有限。
- 网络连接不稳定或受限:许多软件假定“始终在线”,但边缘节点需能在网络受限或中断时正常运行。
卡内基梅隆大学软件工程研究所的 Marc Novakouski 和 Grace Lewis 总结了两类对这些挑战尤为敏感的系统:
- 人道主义边缘:救援人员在恶劣环境下工作,随时可能发生变化。
- 战术边缘:军事人员在野外执行任务,环境多变。
为实现这些能力,软件工程师需设计可分布式系统,将组件分布到多个节点,类似数据中心的微服务架构。
即使你的场景没那么极端,有限硬件、差连接、恶意攻击等问题依然存在。
值得注意的是,边缘用户往往不是技术人员,可能是医生录入病历或管理充电桩的工作人员。因此,需锁定设备防止误操作,强化安全,简化更新部署。
这些挑战促使容器化成为边缘软件部署的热门方式。
从 Docker 到边缘编排
卡内基梅隆大学与边缘设备渊源颇深。1982 年,计算机系学生将自动售货机接入 ARPANET(互联网前身),实现远程查询饮料余量。1991 年,剑桥大学实验室为避免员工扑空,首次安装了咖啡壶摄像头,实现网络实时监控。
容器化自 1979 年 Unix chroot 诞生以来就有,但自 2013 年 Docker 发布后才广泛流行。容器已无处不在,是许多项目 CI/CD 流水线的核心。
容器化是一种虚拟化方式,将应用的代码、依赖和配置打包为镜像,由容器运行时引擎在主机上执行。容器类似虚拟机,但不虚拟化操作系统内核,而是复用主机内核。
去除虚拟化带来的资源开销,使容器轻量,非常适合资源受限的边缘设备。但容器隔离性和可移植性不如虚拟机,因此操作系统需加固。
现代容器引擎普遍采用 OCI 镜像格式,标准化了容器打包和运行方式,实现可预测、可复现的部署。
标准化打包还带来“不可变基础设施”:每次更新都构建新镜像,替换原有镜像,无需增量更新,且可快速回滚。
举例来说,早年我在英国某银行部署互联网银行系统时,四台集群服务器需手动安装软件和补丁,顺序和配置必须完全一致,极易出错,常常无法全部上线。
不可变基础设施曾被视为激进,但因极大简化部署,已成主流。对于设备边缘,可能要部署数百、数千甚至数万台设备,这种可预测性至关重要。
但大规模自动化部署、管理、扩容和网络配置容器非常繁琐。好在容器引擎提供了标准接口,第三方工具可控制容器应用的启动、停止和资源分配。通常由容器编排器负责管理——Kubernetes 是最主流的大规模容器编排方案,但在边缘场景应用尚属新兴。这样能保持数据中心的运维模式,对 IT 团队极为有利。
不同边缘层需定制方案:近边缘和远边缘适合完整 Kubernetes,资源受限的远边缘可用轻量级发行版,设备边缘则常用 Podman 等容器工具。
边缘计算实践:行业应用案例
2018 年,麦肯锡分析师列举了 100 多个边缘计算应用场景。近年来,硬件、网络和 AI/ML 进步带来了更多实际应用。以下四个行业——农业、能源、医疗和零售——展示了 Kubernetes 和容器在边缘的实际应用。
农业
农业是边缘和 AI 技术的重要应用领域。
联合国预计全球人口将在 2080 年代达到 100-110 亿,比 2022 年的 80 亿大幅增加。人口增长让农民需在减少化肥、农药使用的同时应对气候变化、土地退化和水资源短缺。
全球大部分地区粮食产量提升显著,但撒哈拉以南非洲仍然较低。Hannah Ritchie 在《Not the End of the World》中指出,非洲谷物产量仅为印度的一半、美国的五分之一。未来 30 年,非洲人口将再增 10 亿,之后再增 10 亿。
传统技术如化肥、优良种子和灌溉仍是关键。精准农业则利用 AI、机器人和无人机优化生产、减少环境影响。
但高成本让精准农业难以普及到中小农户,这些农户往往地处偏远,缺乏电力和网络,也不懂 IT。
2023 年,跨公司团队开发了智能边缘农业架构,获 TM Forum 可持续发展与社会影响奖。平台涵盖传感器边缘(Red Hat Device Edge + AWS IoT Greengrass)、MEC 上的 Red Hat OpenShift AI(NVIDIA GPU)、云端 IBM watsonx.ai。
项目验证了畜牧和作物健康三大精准农业用例。例如,智能除草方案利用 AI/ML 分析无人机图像,识别需喷洒区域,由 OpenShift AI 生成地图,指导无人机精准作业。边缘 AI/ML 实时处理传感器和天气数据,帮助农民制定决策。5G 边缘计算和低延迟处理提升模型效率。
智能灌溉则分析土壤湿度、温度和天气数据,推算最佳播种时间和灌溉量。
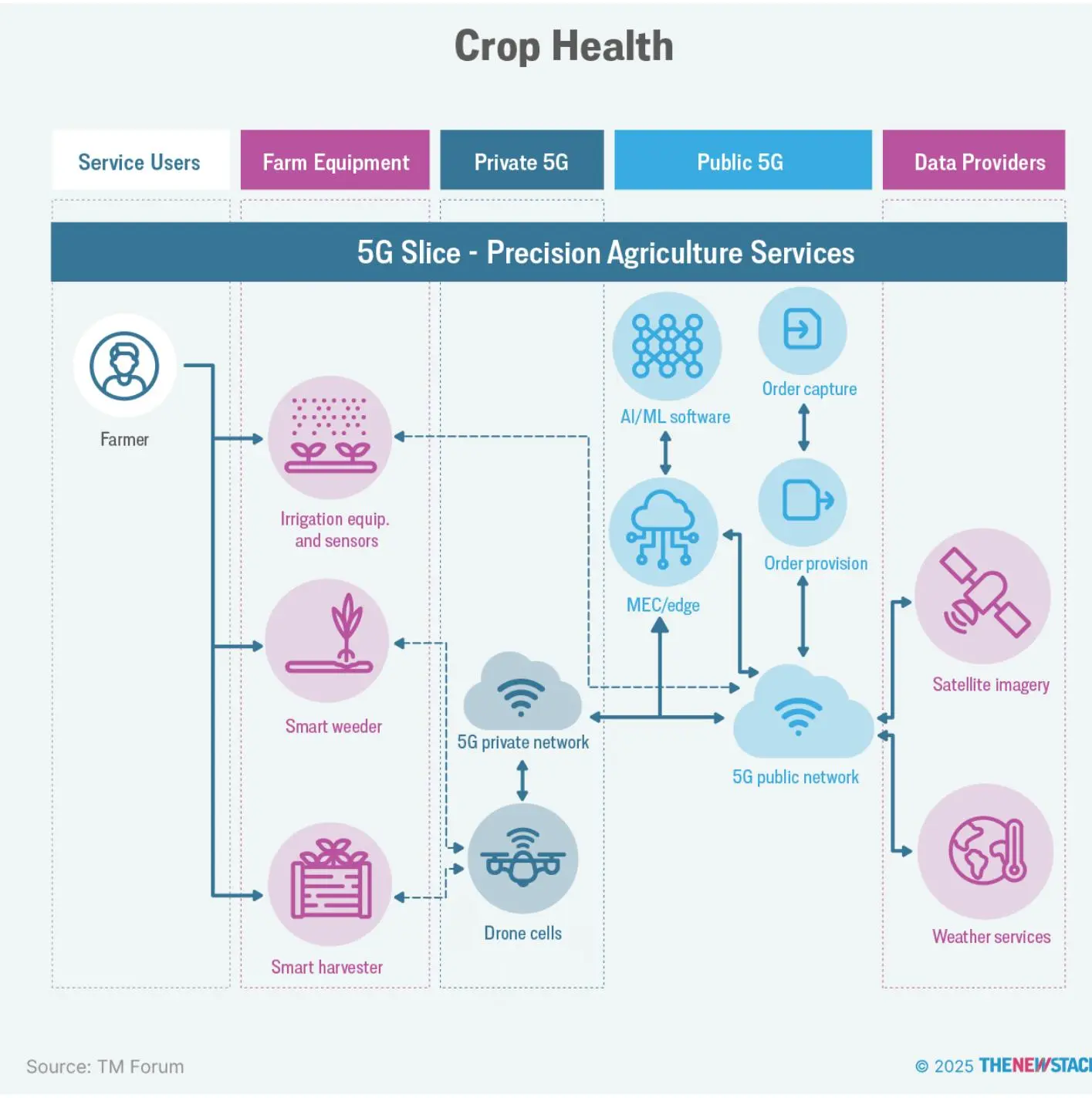
平台还能计算每种作物所需降水量,建立完整农场模型。Red Hat 全球架构师 David Kypuros 介绍:“平台会生成土壤地图,长期跟踪作物反应,指导灌溉和施肥。”
参考实现采用 5G 网络切片,支持 10Gbps 峰值速率,实现软件快速部署。
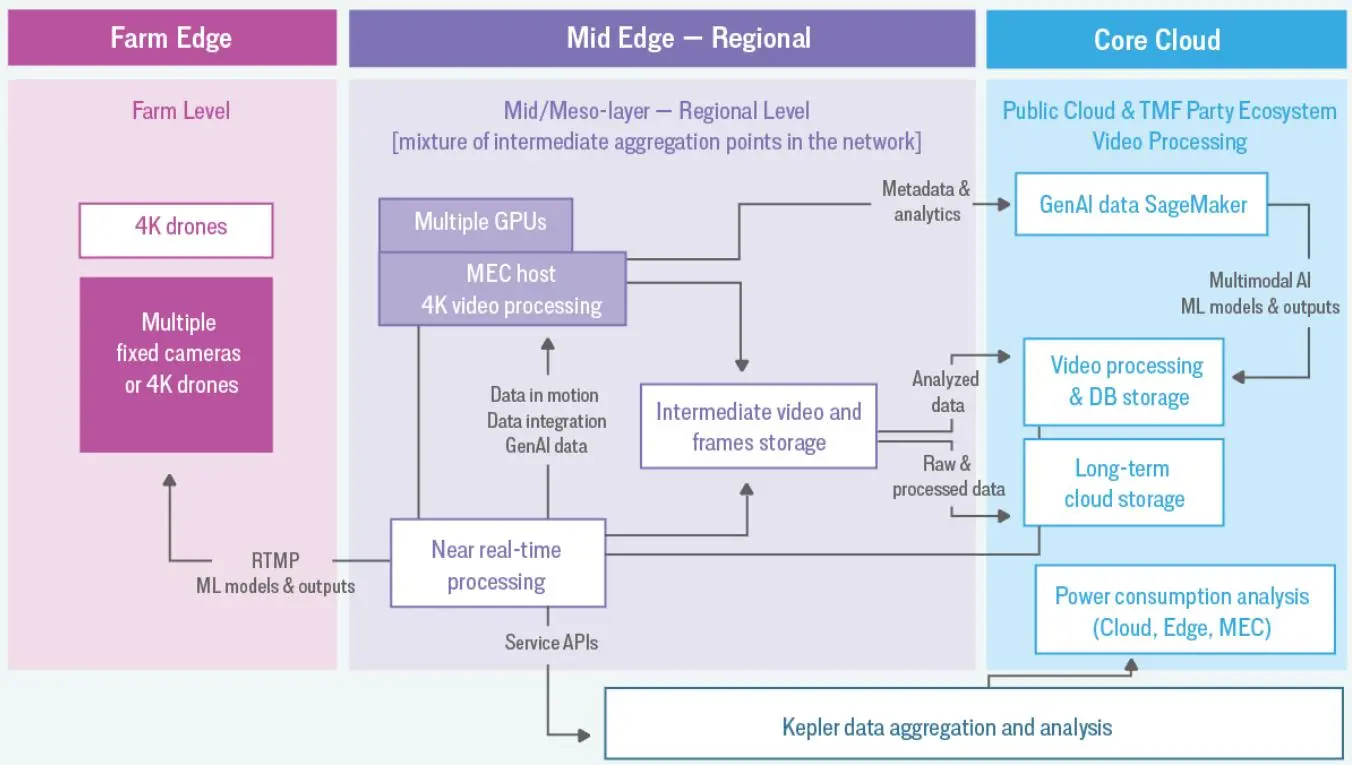
团队还用 Kepler(CNCF 沙盒项目)测量云原生基础设施能效。Kepler 利用 eBPF 采集 CPU 性能计数器和内核追踪点数据,输入机器学习模型,估算 Kubernetes Pod 的能耗。
能耗统计以 Prometheus 指标展示,可用于 Pod 调度、能耗报告和可视化,也可扩展碳强度指标。
精准除草方案在农场实测,蓝色染料评估准确率,结果显示水和农药用量减少 20%-30%。
许多国家出台了减少土壤氮肥的税收激励,AI 模型结合当地政策优化施肥。平台数据可用于农民、政府等制定可持续农业政策。
能源与可再生能源
油气开采中的“放空”指释放和燃烧甲烷等气体,2023 年全球放空 1440 亿立方米,排放 4 亿吨二氧化碳,相当于 9 万亿英里汽车行驶。
虽然有安全需求,但很多公司为节省成本而放空气体,尤其在产量小或偏远地区。
化石能源公司也积极采用边缘技术和 AI。例如,Aramco 建立 AI 中心分析油气田每天 50 亿个数据点,提升勘探和钻井决策。AI 模型帮助公司自 2010 年起将放空量减少 50%。
Aramco 还探索边缘 AI,如机器视觉分析火炬角度、长度和烟雾比,预测放空规模。
PowerFlex(EDF Renewables 子公司)则在可再生能源领域应用边缘技术。PowerFlex X 平台支持智能能源管理,帮助企业高效充电和需求管理。
PowerFlex 系统结合历史和实时数据,自动优化现场资产。
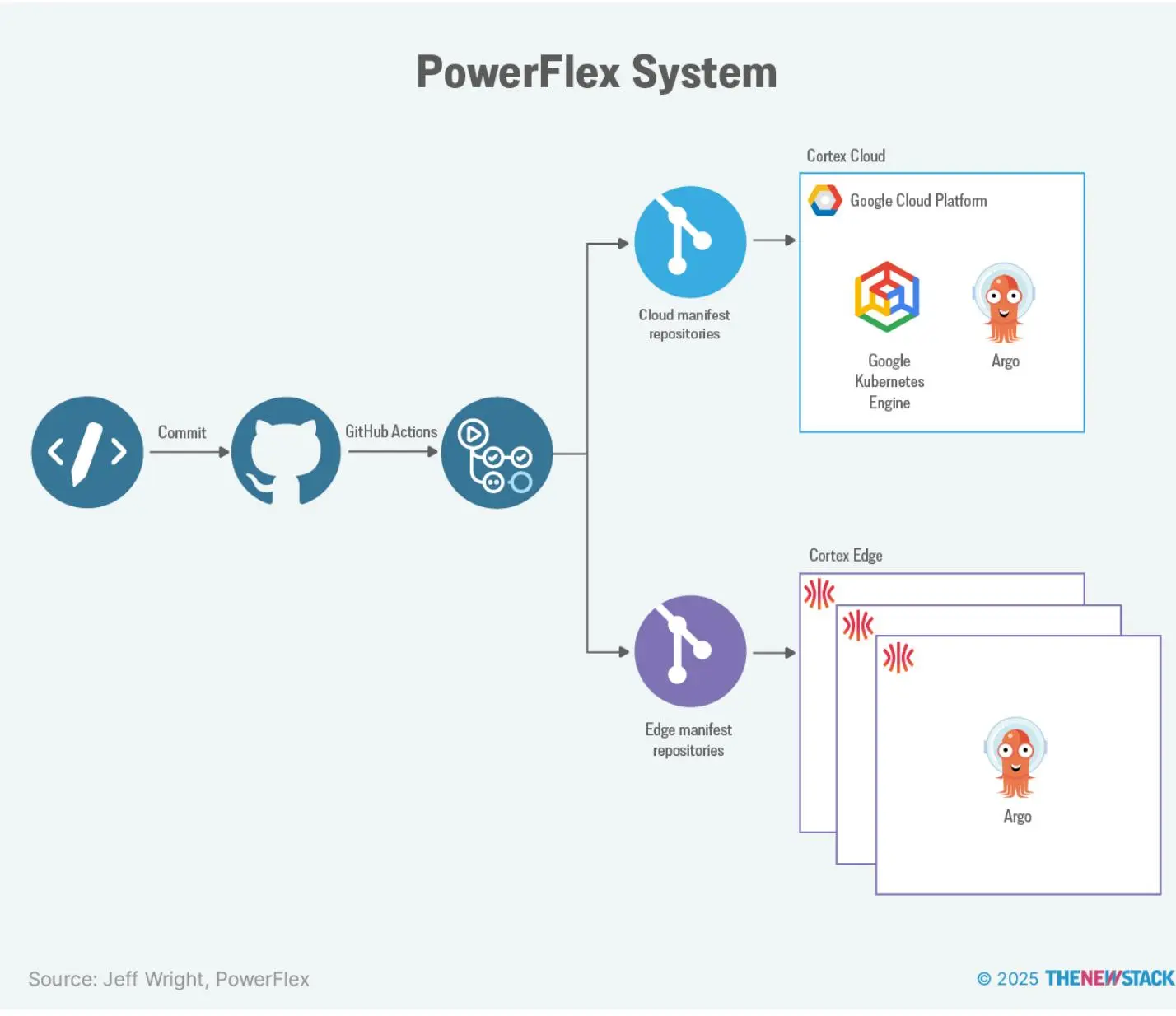
PowerFlex 采用自动化部署流水线,利用 GitHub Actions 构建 Docker 镜像并推送部署清单,Argo CD 实现 Kubernetes 云和边缘同步。
早期边缘部署为客户定制 ISO 镜像,随着业务扩展,团队转向更易复用和自动化的方案。
PowerFlex 选择 Talos Linux 作为边缘操作系统,因其可构建通用镜像,后续可按需补丁,灵活定制驱动、IP、主机名和网络规则,适应各种环境。
PowerFlex 还用 Sidero 的 Omni 平台统一管理所有 Talos Linux 集群,简化集群创建和管理,支持 Google/GitHub 认证和负载均衡。
Omni 提供集群健康、日志、MAC 地址等元数据查看,支持远程重启和补丁,无需现场运维。
这些案例展示了边缘计算和 AI 在能源领域的应用,从减少排放到优化可再生能源系统,智能边缘解决方案正成为行业可持续发展的关键工具。
医疗
随着能源转型加速,成功实施分布式计算的企业将获得竞争优势,并推动环境目标实现。关键在于战略性部署技术,解决实际问题。
医疗行业采用边缘计算本地处理敏感数据,兼顾安全和合规。无论是制药巨头还是 AI 初创公司,都在用容器化边缘部署提升服务能力。实现实时处理和高安全性。
罗氏(Roche)是全球制药和健康诊断领导者,分布于全球数千地点。
过去,每次部署新应用(如实验室检测),都需自备硬件和软件,重复建设,难以管理。
为此,罗氏组建平台团队,统一硬件和通用软件组件,应用在边缘集群上。
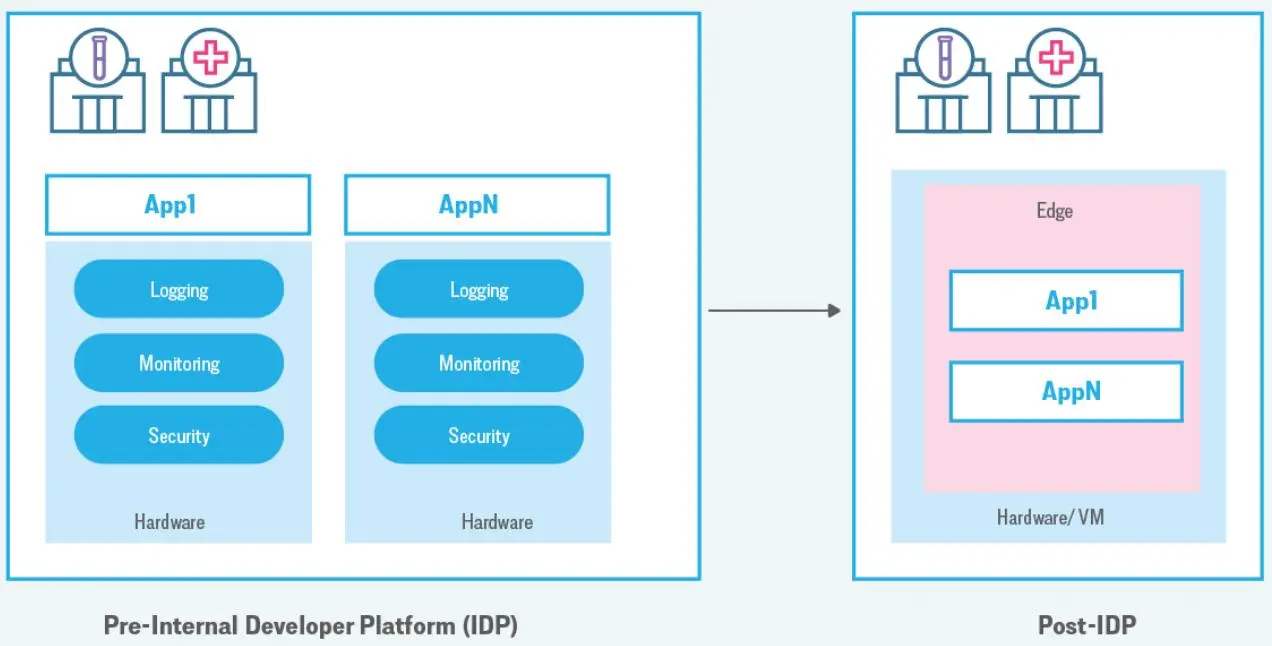
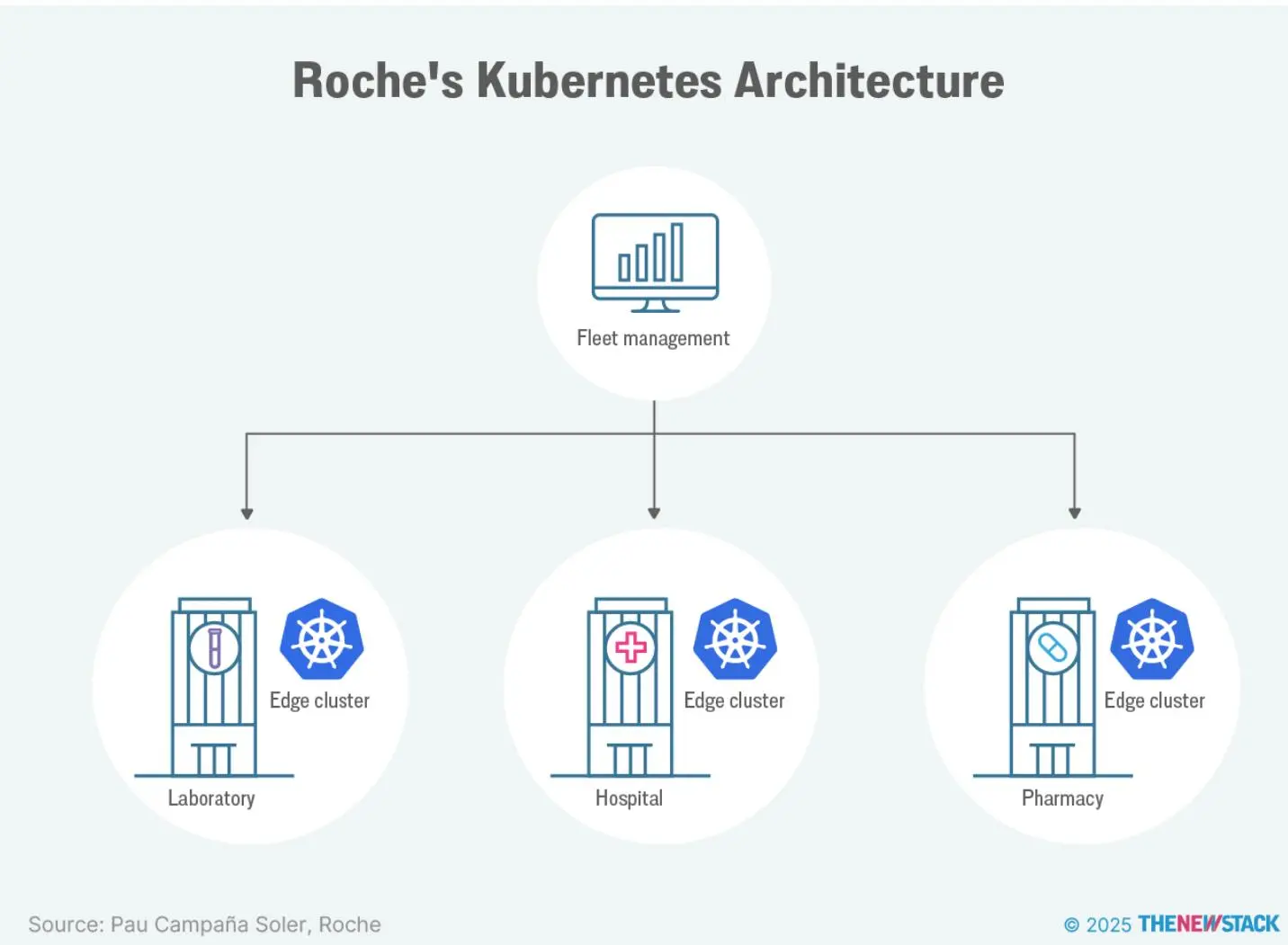
罗氏部署大量 Kubernetes 集群,预计 2027 年将达 1 万个边缘集群,一切需自动化。
平台包括:
- 车队管理:通过 Web 控制台集中查看所有边缘集群状态、日志、监控和注册表。
- 边缘集群:简化集群创建,基于 GitOps 的应用部署和自动升级,无需 Kubernetes 专业知识,默认集成 Grafana、Prometheus 等组件,开发者专注于应用。
平台工程师 Pau Campaña Soler 在 TalosCon 2024 介绍,首版平台基于自定义 Linux、RKE2 和 Rancher,生产环境超 10 个集群,但遇到升级复杂、配置不标准和安全风险,后转用 Talos Linux,因其不可变和安全性更高。
罗氏平台可创建两类集群:
- Local-talos:开发用,基于 Docker 创建 Talos Linux 集群,版本与生产一致,方便测试。
- Baremetal-talos:生产用,提供 ISO 镜像,支持裸机或虚拟机,利用 Secure Boot 保证安全。
因患者数据极为敏感,罗氏高度重视安全和不可变性。Talos Linux 挂载根文件系统为只读,移除 SSH 等主机访问,杜绝配置漂移。
医疗 AI 公司 RapidAI 提供 MRI 和 CTA 图像分析,旗舰产品将缺血性卒中理想治疗窗口从 6 小时延长至 24 小时。
RapidAI 平台和移动应用支持团队协作和图像分享,IT 团队使用 Go、Python、C++、Java、JavaScript、TypeScript、Swift 等多种语言。
系统完全容器化,采用 Docker 和 Kubernetes,利用 Spectro Cloud Palette 部署和管理。为防硬件故障,采用 3 或 5 节点 Kubernetes 边缘集群,支持节点故障容忍。集群支持物理和虚拟设备,RapidAI 仅用虚拟设备。
集群更新采用滚动升级,节点逐个脱离、升级、重入,维护 A/B 分区,监控系统健康。
医疗行业通过容器化边缘计算,成功实现实时处理、安全合规和大规模运维。
零售
跨地区管理数千家门店,技术挑战远超传统企业 IT。每家门店都是独立的边缘环境,网络、安防和运维需求各异,需兼顾弹性和简易性。
JYSK 是国际家居零售商,1979 年在丹麦成立,现有 3500 多家门店和电商,遍布 50 国。
JYSK 开发团队主要用 Java 和 Go,IT 架构为混合模式:本地运行隐私或成本敏感应用,电商在云端,门店用物理边缘。技术选型以应用需求为准。
公司正向产品中心化转型,构建内部开发平台(IDP),统一方法,包括远边缘。
PoC 阶段,JYSK 在 3500 多家门店部署轻量级 Kubernetes 和操作系统,保持一致的部署策略。
“我们云端和本地都用 Kubernetes,主要是为了简化,让开发和运维说同一种语言。”技术负责人 Ryan Gough 说。
为简化应用管理,JYSK 采用 GitOps 控制应用发布和配置漂移,Cilium 提供 eBPF 网络可观测性和高效通信。
PoC 成功,但暴露了更新和补丁规模大、网络负载重、门店网络多样等问题。集中拉取容器镜像复杂且资源消耗大。
为解决这些问题,JYSK 采用 Talos Linux。“我最看重的是不可变性,”Gough 说,“门店是拓扑边缘,易受电力、环境、网络甚至战争影响,不可变和快速恢复很关键。”
Talos Linux 体积小,简化了门店网络流量管理。“我们要部署到 2500 个地方,需要足够小的系统,Talos Linux 完美满足。”
JYSK 还采用“养牛而非养宠物”理念,集群可快速重建和再部署。定制镜像由 HashiCorp Packer 自动化创建,通过 Talos Image Factory API 拉取镜像并预配置,确保一致性。配置采用 cloud-init NoCloud 数据存储本地引导。
部署后与 API 通信,实现自动化交接。
“硬件故障时,只需更换设备,插电开机,几分钟即可恢复。全自动,Talos Linux 安装仅需约 46 秒。”Gough 说。
大规模边缘 Kubernetes 部署需重视 Day 2 运维——集群的持续管理、更新和维护。
“我低估了这项工作的复杂度。”Gough 说。
自动化对规模化和效率至关重要,尤其是镜像创建、配置和管理。
JYSK 遇到的网络、安防、运维和 Day 2 挑战,是所有大规模零售商的共性。要满足新需求,零售商需投资于边缘技术和分布式系统的运维框架。
成功的零售商会像 JYSK 一样,拥抱自动化、不可变和“养牛”理念,打造可扩展且易于门店操作的技术基础设施。
边缘厂商格局:选型指南
第二章案例展示了 Kubernetes 在边缘环境的价值,也揭示了其复杂性,规模越大越复杂。
Spectro Cloud 研究显示,企业平均有 20 多个 Kubernetes 集群,6% 超过 100 个,奔驰 2023 年接近 1000 个集群,罗氏预计 2027 年将有 1 万个边缘集群。
大规模复杂性催生了 Kubernetes 管理平台,核心功能是通过自动化和抽象,减少运维团队规模,简化部署、管理、安全和监控。
边缘环境受限于网络和算力,正适合 Kubernetes 管理平台。但边缘 Kubernetes 部署仍属新兴,厂商格局变化快。
经济决策者的关键考量
经济决策者(掌控预算和风险)选型时关注:
- 连接性挑战:分布式环境连接难,尤其是数千集群分布在远程地点。
- 远程管理:边缘缺乏现场 IT,需远程部署、监控、故障排查和管理。
- 安全与可观测性:厂商采用安全供应链和保密计算,降低风险。
- 自动化:简化大规模部署和管理。
- 工作负载加速:支持 GPU、TPU 等专用硬件,提升容器效率。
- 操作系统灵活性:优选专为边缘设计的 Linux 发行版,或支持多操作系统。
此外,还需关注:
- 开发者体验(DevEx):工具是否易用。
- 碳排放:监控环境影响。
- 成本管理:控制支出。
Kubernetes 管理工具无需满足所有标准,可根据现有工具链和实际需求补充功能。
每家企业需求不同,厂商 DevEx 等主观体验也因环境而异,分析报告很少涉及。
市场主流厂商简评
本节简要评述主流厂商,调研时间为 2025 年 5-7 月,方式包括厂商简报、客户访谈、产品安装、文档和源码审查。未参与调研的厂商仅 desk research。
以下厂商未详细讨论:AWS EKS Anywhere、Outposts、Canonical MicroK8s、Mirantis kOs/kOsmotron、Rafay、Wind River Studio Cloud Platform。
未列出不代表不可选,实际选型时应纳入本章介绍的所有厂商。
Rakuten Cloud Native Platform
Rakuten 提供面向边缘计算的 Kubernetes 方案,适用于 Open RAN、5G Core、私有 5G、MEC 和企业应用。
Day 2 运维表现优异,支持声明式策略自动恢复、扩容和迁移,支持 NUMA、CPU 绑定、HugePages、亲和/反亲和、CRI 多容器(容器、虚拟机)、策略编排,支持 CNI/CSI 插件,但不支持修改 etcd/CRI 等核心组件。
集成度高,支持 Intel CAT、NVIDIA GPU 切片、5G 优化、DMTF Redfish 编排,与 Google Distributed Cloud 紧密结合。
零接触部署和云原生编排器简化多环境部署,Symworld Site Management 和 AI/ML 自动化缩短部署时间。
网络支持 IPv4/IPv6 双栈和 Multus 等二级网络。
未见支持工作负载加速或 x86 以外指令集。
适合地理分布广的行业,如电信运营商。
Red Hat Device Edge
2023 年 11 月 GA,扩展 OpenShift 能力,聚焦资源受限和远程环境的轻量级 Kubernetes。集成 RHEL 和 MicroShift(OpenShift 衍生的 CNCF 认证 Kubernetes),实现一致的容器编排。
RHEL 支持高效镜像更新,仅传输变更部分,减少带宽和时间,支持可靠回滚。
连接性支持单栈 IPv6 或双栈,支持气隙部署,MicroShift 可嵌入不可变 RHEL 边缘镜像,离线安装和应用部署。仅支持 RHEL,不支持其他发行版。
工作负载加速强大,支持 GPU、DPU、FPGA,适合高性能计算和断网场景。近期新增低延迟和近实时能力,支持 NVIDIA Jetson Orin/IGX Orin。
自动化可选用 Ansible Automation Platform,支持 Helm 和 Operator,适合运维人员,声明式、幂等、可重复。
车队管理较复杂,需多工具(console.redhat.com、ACM、Ansible)支持不同部署和连接模式。
OpenShift 支持 CNI/CSI 插件定制,但限制核心组件修改。
适合 OpenShift 用户,但 OpenShift 与 Device Edge 操作模式不同,需注意。
适用于工业 IoT、自动驾驶、在线游戏、智慧城市等低延迟和 AI 应用。
Scale Computing HyperCore
2008 年成立,2012 年推出 HyperCore 超融合产品。
平台包括:
- 硬件:自有 HE100/500 系列,分别基于 Intel NUC 和联想设备。
- HyperCore:Linux 操作系统,集成 KVM 虚拟化、SCRIBE 存储、AIME 自动化管理。
- Fleet Manager:SaaS 车队监控。
支持多种部署,包括传统虚拟机、容器运行时(Docker、Kubernetes)、多种管理方案(Rancher、OpenShift、Avassa、Anthos)。现已支持软件订阅。
容器运行在虚拟机内,支持 Talos Linux、containerd、Docker、CRI-O 等。适合小型 Kubernetes 部署,如单节点集群,三节点集群可获得存储弹性。自带轻量编排引擎,简化容器部署、扩容和恢复。
自动化通过 REST API 实现,支持单集群和 Fleet Manager,另有 Ansible Collection 和 Terraform 集成。
边缘到云通信基于 MQTT,安全性有 Secure Link 反向隧道、TLS 加密、Secure Boot、访问控制和 RBAC。
支持 USB 一键气隙部署,适合无云连接场景。HyperCore UI 与 Fleet Manager UI 不同,需切换。
GPU 加速仅支持部分 NVIDIA GPU,无 DPU/FPGA 支持。
服务团队支持从试点到大规模部署,提供最佳实践蓝图。
传统聚焦中小企业,现扩展至零售、制造、医疗等大规模边缘。硬件和应用部署优势明显,容器运行时灵活但需客户自行配置。
Sidero Talos Linux 和 Omni
Sidero 通过 Omni 平台和 Talos Linux(极简不可变 Linux)简化边缘 Kubernetes 部署,强调安全、一致性和易维护。
Sidero 最具主见,专注 Kubernetes 层,CI/CD 需自备工具。
Talos Linux 是声明式、不可变、极简发行版,专为 Kubernetes 设计,极适合边缘部署。
核心特点:无 Bash、SSH、systemd,API 管理和配置驱动。API 提供调试数据,双向 mTLS 加密,gRPC 通信。
配置通过声明式 YAML 文件提交,PID 1 进程(Go 编写)负责服务管理和状态一致性。Kubernetes 成为操作系统。
适合熟悉 Kubernetes 的运维人员,但对习惯传统 Linux 的人有学习曲线。无 Shell 需验证存储和安全工具兼容性。
安全性高,体积小,攻击面小,维护负担低。支持 Trusted Boot(磁盘加密 + 安全启动),CIS 基准加固,SBOM 可集成安全工具,FIPS 140-3 合规。
网络支持 IPv4/IPv6 双栈和 Multus CNI。
远程管理强大,可扩展至数千集群,API 驱动,WireGuard 隧道支持受限环境。首次启动自动建立 Omni 隧道,无需公网 IP。
气隙环境下,Talos Linux 1.9 支持镜像缓存,安装 ISO 可 USB 部署。
工作负载加速支持 GPU、DPU、SR-IOV、DPDK,无 FPGA。
Omni 支持 CNI/CRI/CSI 定制,核心组件如 etcd 不支持互换。
Sidero 是 Kubernetes 的“易用按钮”,垂直集成,适合新手快速部署,更新近乎无缝。Talos Linux 最轻量,适合硬件受限环境和单机设备边缘。
中大型企业若能接受集成方案,Omni 的集中管理和不可变设计可降低运维风险,适合零售、制造、电信等分布式场景。
除 JYSK、PowerFlex,Berkshire Grey、CrossnoKaye、Forterro、Hathora、Nokia、SNCF 等也在边缘用 Talos/Omni。
Spectro Cloud Palette
Spectro Cloud 专注 Kubernetes 生命周期管理,Palette Edge 是其主打产品,包含 CNCF 认证的边缘优化发行版 PXK-E,支持集中管理。
Palette 可从管理控制台为边缘主机部署集群,支持全流程管理、扩容、升级和重配置。
安全性显著提升,与 Intel 合作开发 SENA 边缘安全架构,支持 SBOM 漏洞扫描、不可变镜像、加固配置和 Trusted Boot。
政府和合规场景可用 PXK-E 的 FIPS 加密,支持 RKE2、K3s 等多发行版。安全性强,核心组件定制有限。
自动化支持低/零接触部署,适合气隙场景,Local UI 简化现场操作,降低人为风险。
Day 2 运维由集群代理本地执行策略,自动证书续签、升级、备份/恢复(Velero)。
网络支持 IPv4/IPv6 双栈,支持虚拟叠加网络,稳定 IP 管理。
高可用支持 2/3/5 节点集群,滚动升级,A/B 分区架构,内置健康监控。
支持 KubeWirt 虚拟机编排,VM 和容器可同机运行。
操作系统可定制,默认 openSUSE,也支持 Ubuntu、RHEL、自定义,EdgeForge 构建 ISO 或 Kairos 镜像,Agent 模式支持自定义集群。
工作负载加速略逊于部分竞品,但 RapidAI、Nokia、Tevel、Dentsply Sirona、GE HealthCare 均用 Palette 跑 AI。支持 DPU、GPU(NVIDIA Operator Pack),无 FPGA。
Palette Edge 是完整解决方案,适合新部署或替换旧系统,灵活可扩展,支持 1 万集群。操作系统灵活,支持 VM、容器和多硬件,但设置复杂度略高。
SUSE Edge Suite
SUSE Edge Suite 整合 Rancher Prime、K3s、RKE2 等组件,简化边缘 Kubernetes 部署和运维。
远程管理强大,Rancher Prime 多集群管理,Elemental 支持安全“phonehome”自动绑定和 GitOps 更新,支持数万集群,适合带宽受限或断网场景。
支持 Metal3、MetalLB、CAPI,实现裸金属全生命周期管理。
气隙环境下,SUSE Edge Image Builder 可生成定制安装介质,支持单/多节点高可用集群,无需外网或集中管理平台。
安全性强,SUSE Security 提供漏洞扫描、深度包检测和实时防护,RKE2 适合政府和合规行业。
但不支持远程证明等新特性,部分高安全场景受限。
支持 CNI/CSI/CRI 和 etcd 等核心组件定制。
操作系统仅支持 SUSE Linux Micro,不可变、优化容器和边缘工作负载,稳定性高但不支持第三方系统或 Windows/macOS。
SUSE Linux Micro 支持 x86 和 ARM,GPU 加速由 SUSE 和 NVIDIA 提供。
适合零售、制造、电信等大规模边缘部署。
如何选择合适的边缘 Kubernetes 平台
Kubernetes 的兴起和 VMware 被收购带来基础设施市场剧变,企业更开放新方案。
边缘 Kubernetes 市场正处于转型期,传统“一刀切”方案让位于分布式专用解决方案。老牌厂商如 Red Hat、SUSE 利用企业 Linux 经验打造综合平台,新兴厂商如 Sidero 通过极简专用方案大幅简化边缘部署。
选型需结合现有基础设施、边缘需求和对复杂性与控制的容忍度。未来市场将向能平衡简易性、安全性和可扩展性的方案整合,厂商也会持续增强工作负载加速和 AI 功能。
最成功的厂商将是那些能抽象 Kubernetes 复杂性,同时保留其灵活性的方案。
边缘 Kubernetes 市场正处于转型期,专用分布式解决方案逐渐取代传统“一刀切”模式。
边缘 Kubernetes 实践技巧
30 年软件生涯中,我见证了五次重大变革:高级语言、敏捷、云、DevOps/持续交付、微服务。每次变革都缩短了价值实现周期,让企业能更快将创意落地,试错成本更低。生成式 AI 是否会成为第六次变革,尚待观察。
边缘容器化的兴起与历史模式类似。复用云端 CI/CD 等实践,推动开发者中心化,即使在分布式物理环境下也能统一打包、部署,简化复杂流程。
随着企业探索 AI,边缘成为新前沿。设备算力提升,实时推理、数据本地性和延迟需求推动计算向数据源靠近。
建议逐步加大学习和信息投入,直到找到最适合组织的方案。
灾难边缘
边缘不是“更近的云计算”,而是将云原生实践扩展到传统云假设失效的场所。边缘环境极具挑战,需关注:
- IT 人员缺乏:边缘故障时,现场可能无人能处理。
- 物理约束:设备算力有限,电力不稳定,环境恶劣,故障率高。
- 安全:数据中心易控物理访问,边缘则难以限制,需特别关注设备安全。
- 连接和中断:网络可能受限,不能依赖互联网。
- 需求不可预测:企业常有本地运行数十年旧应用,与现代云原生容器并存。
如何组建团队
要将云原生实践应用于边缘,需组建跨学科团队,既懂物理硬件,又能架构高层系统,需具备领域经验和迭代开发能力。
掌握云原生边缘实践的组织,将最有能力利用实时洞察、响应本地条件、交付前所未有的能力和体验。
最低需求:
- 深入了解问题领域的专家。
- 有嵌入式设备开发经验的工程师。
- 熟悉云原生、DevOps、容器和 Kubernetes 的工程师。
组建团队时,除技术外,还需好奇心、适应力和协作能力。
领域专长外,团队多样性也很重要。Daniel Situnayake 和 Jenny Plunkett 在《AI at the Edge》中指出,多元化是防止社会伤害的最佳防线,前提是有心理安全文化。
编程如写作,是创造性过程,需要自由和试错。鼓励探索和创新,才能激发边缘部署潜力。
逐步加码
团队到位后,需逐步积累经验。例如 JYSK 先用非关键应用试水边缘 Kubernetes。建议与现有虚拟化平台(如 VMware、Proxmox)并行运行,优先非关键工作负载。
逐步加码,积累经验,找到最优方案。类似“逐步加码”,如《Cloud Native Transformation》所述。
Jamie Dobson 在《Visionaries, Rebels, and Machines》中说,风险大小取决于未来的确定性。
“如果足够明确,公司可做‘无悔举措’。若未来不确定,需通过实验降低不确定性。”
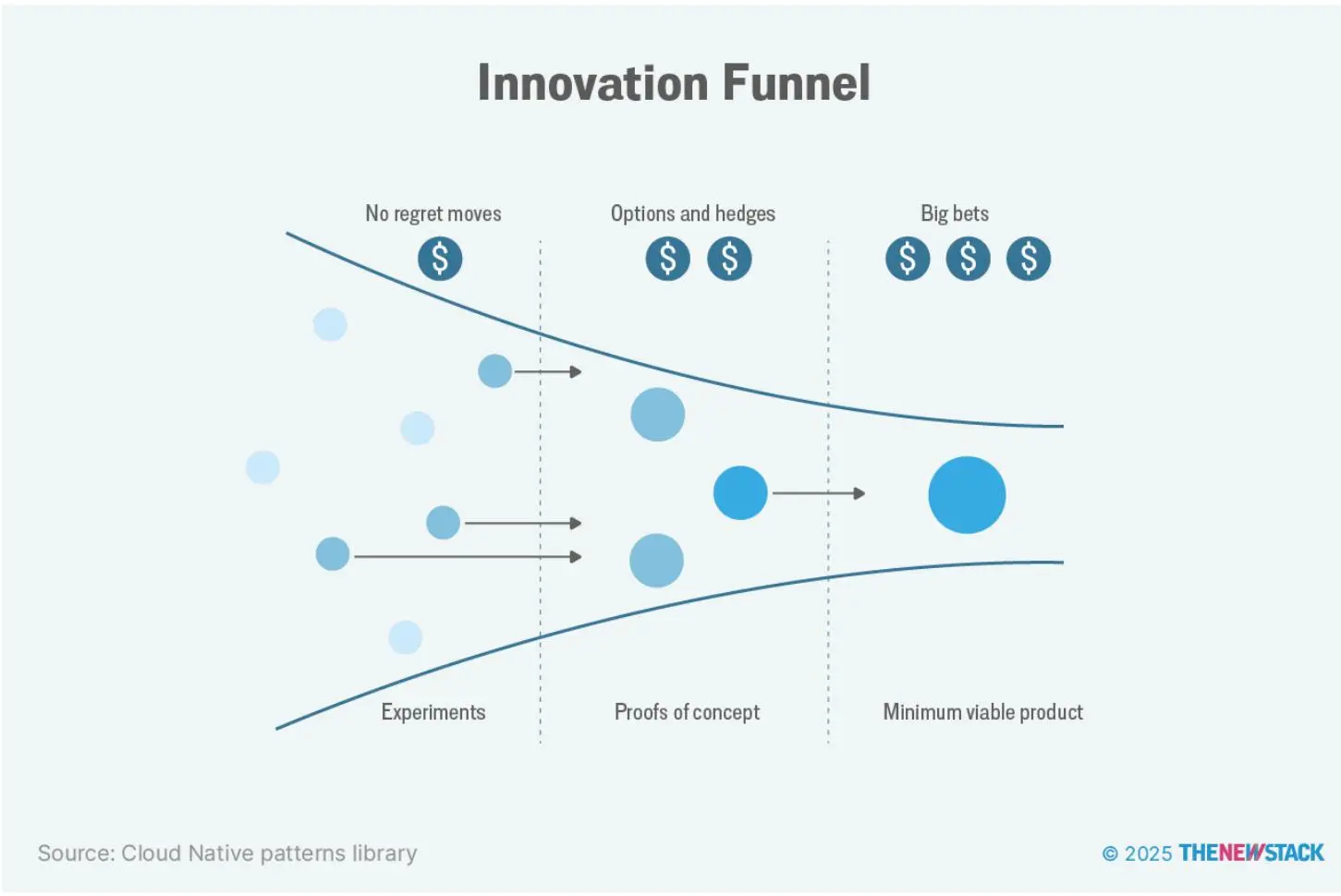
边缘计算是运维模式重大转变,组织需时间适应流程、技能和预期。渐进式方法优势明显:先用非关键负载,学习运维模式,发现问题,积累故障排查和监控经验。
新旧系统并行,便于回退、性能对比和渐进迁移,也能通过可靠性提升建立利益相关者信心。
重视 Day 2 运维
两种常见部署方式都不理想:
- 物理部署:每个应用定制资源,逐站发货,部署新应用极为繁琐,系统分散,难以统一管理。
- 虚拟化部署:通常两台虚拟主机、两台交换机和一个 SAN,比物理好,但仍是“养宠物”模式。
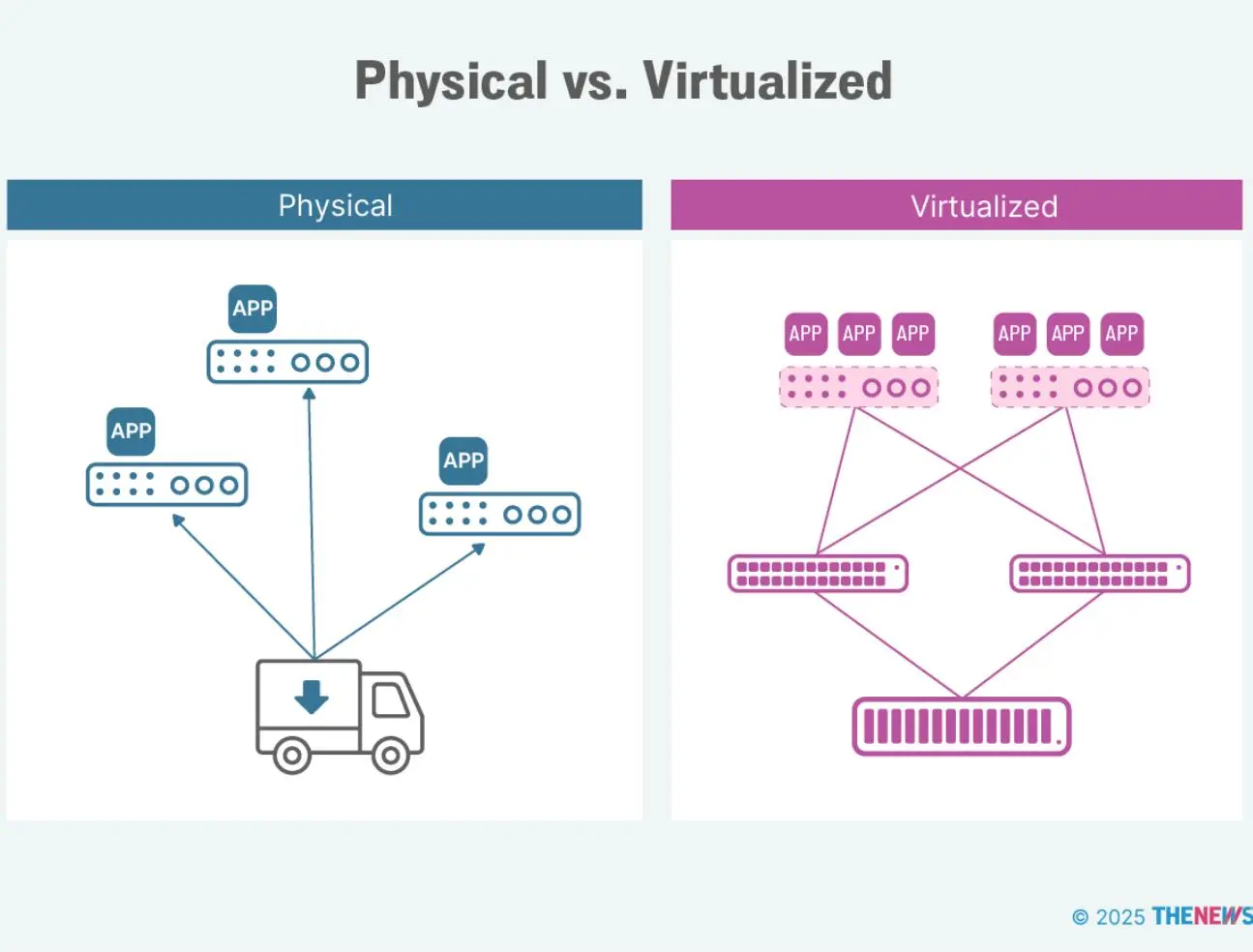
小规模尚可,但边缘项目需提前规划 Day 2 运维——集群持续管理、更新和维护。初期不可避免要部署硬件和网络,但不能让服务器因更新失败而“雪花化”。需能跨数千站点自动部署新应用,无需发货或人工操作。
自动化提升速度、敏捷性、可靠性,降低错误和成本,增强安全和可重复性。将 IaC 扩展到边缘,DevOps 团队可用自动化、版本控制的远程部署,简化配置和部署。
GitOps 是边缘 DevOps 的热门方法,以 git 仓库为应用和基础设施配置的唯一真源,结合平台可实现:
- 声明式配置:描述目标状态而非操作步骤。
- 版本控制:跟踪变更,支持回滚。
- 自动同步:确保边缘站点与目标状态一致。
- 审计追踪:记录变更和责任人。
明日边缘
选用专为边缘设计的 Kubernetes 工具可降低复杂性,专用 Linux 发行版也能规避风险。
可选发行版包括:
- Bottlerocket:亚马逊容器优化 Linux。
- Chаinguаrd OS:极简安全 Linux。
- Flatcar:轻量容器 Linux。
- Kairos:云原生边缘 Linux。
- Talos Linux:专为 Kubernetes 设计的安全极简 Linux。
这些发行版强调安全、极简和自动化,降低攻击面和运维负担。
边缘计算成功不仅需技术,还需分布式系统思维转变。组建多元团队、从低风险负载起步、全程自动化、选用专用工具,才能应对边缘挑战,释放变革潜力。边缘是价值实现的新前沿,让计算更贴近决策现场。
随着边缘设备能力提升,掌握云原生边缘实践的组织将最有能力利用实时洞察、响应本地条件、交付前所未有的能力和体验。企业计算的未来是分布式、智能、贴近客户——只要方法得当,这一未来触手可及。
结语
边缘计算带来诸多益处,包括通过联邦学习提升隐私、减少网络流量降低碳排放、免除制冷需求、通过云去迁移降低成本。但也有挑战:受限于体积、重量和功耗,算力有限,网络连接不稳定,需设计健壮、容错的软件。
容器化因轻量和不可变基础设施成为边缘部署的关键。相比传统手动配置,容器可在数千边缘站点实现可预测、可复现部署。Kubernetes 等编排平台兼顾数据中心运维模式和边缘约束。
Kubernetes 边缘计算技术日趋成熟,解决了各行业实际需求,但需专用工具和方法应对分布式、资源受限环境。
容器化、专用操作系统和集中管理平台的结合,使 JYSK、PowerFlex、RapidAI、Roche 等企业能高效大规模部署复杂应用。
新兴厂商如 Sidero 的不可变 API 管理 Talos Linux 和 Omni、Red Hat Device Edge、Spectro Cloud Palette、Scale Computing HyperCore 等,分别在不同维度解决边缘复杂性,提供集中管理能力。
切勿忽视 Day 2 运维规划——持续管理和维护分布式系统。关键策略包括从非关键负载起步、全程自动化、选用专用工具、逐步加码。
Kubernetes 边缘计算技术日趋成熟,正在解决各行业实际业务需求。
其他资源
最后推荐一些有用资源。
由于 Kubernetes 边缘变化快,相关书籍更新滞后,难以推荐。但 Hugh Taylor 的《The Edge Data Center》适合管理和运维人员,系统介绍 5G、智能设备、物联网和智慧城市,以及数据中心设计和部署模式。
Daniel Situnayake 和 Jenny Plunkett 的《AI at the Edge: Solving Real-World Problems with Embedded Machine Learning》也很棒,实用且简明,阐述为何要在边缘设备部署智能。
我在 The New Stack 的两篇文章,分别探讨联邦学习和 AI 可持续性问题,也值得一读。更广泛的可持续性介绍可参考我的电子书《The Developer’s Guide to Cloud Infrastructure, Efficiency, and Sustainability》。
最后,Liz Rice 的《Container Security》虽非专门讲边缘,但深入讲解容器攻击向量、加固措施和配置风险,第二版预计 2025 年秋出版。
作者简介
Charles Humble,IT 行业资深人士,30 年经验,现为自由顾问、作者和播客主持人。
曾任 InfoQ 主编(2014-2020)、Container Solutions 主编(2020-2023),著有《The Developer’s Guide to Cloud Infrastructure, Efficiency, and Sustainability》《Professional Skills for Software Engineers》,并为 GOTO 主持工程领导力播客。常为 The New Stack 等媒体撰稿,内容策略经验丰富,曾在 Devoxx、GOTO、QCon 等国际会议演讲。还是电子乐队 Twofish 的键盘手。
关注软件开发、可持续性与伦理、云计算、远程办公、多元与包容,以及激励新一代开发者。
声明
本文提及的 AWS、CNCF、Red Hat、VMware by Broadcom 均为 The New Stack 赞助商。
The New Stack 所有者 Insight Partners 也是 Docker 投资方。