Netflix 的计算与性能工程团队定期调查我们多租户环境中的性能问题。首先是确定问题是源自应用程序还是底层基础设施。一个经常复杂化这一过程的问题是“噪声邻居”问题。在我们的多租户计算平台 Titus ,“噪声邻居”指的是大量使用服务器资源的容器或系统服务,导致相邻容器的性能下降。我们通常关注 CPU 利用率,因为它是我们工作负载中噪声邻居问题的最常见来源。
检测噪声邻居的影响是复杂的。传统的性能分析工具如 perf 可能会引入显著的开销,从而加剧性能下降。此外,这些工具通常在事后部署,对有效调查来说已经太迟了。另一个挑战是,调试噪声邻居问题需要相当的底层专业知识和专门的工具。在这篇博客文章中,我们将展示我们如何利用 eBPF 实现 Linux 调度器的持续、低开销的检测,有效地自助监控噪声邻居问题。你将学习到 Linux 内核检测如何改善你的基础设施可观测性,并带来更深入的洞察和增强的监控。
持续检测 Linux 调度器
为了确保我们依赖低延迟响应的工作负载的可靠性,我们对每个容器的 run queue 延迟进行了检测,这个指标衡量进程在调度队列中等待被派发到 CPU 的时间。在此队列中的长时间等待可能是性能问题的征兆,尤其是当容器没有使用其全部 CPU 分配时。持续的检测对于抓住这类问题至关重要,而 eBPF 通过最小的开销进入 Linux 调度器,使我们能够有效地监控 run queue 延迟。
为了发出 run queue 延迟指标,我们利用了三个 eBPF 钩子:sched_wakeup、sched_wakeup_new 和 sched_switch。
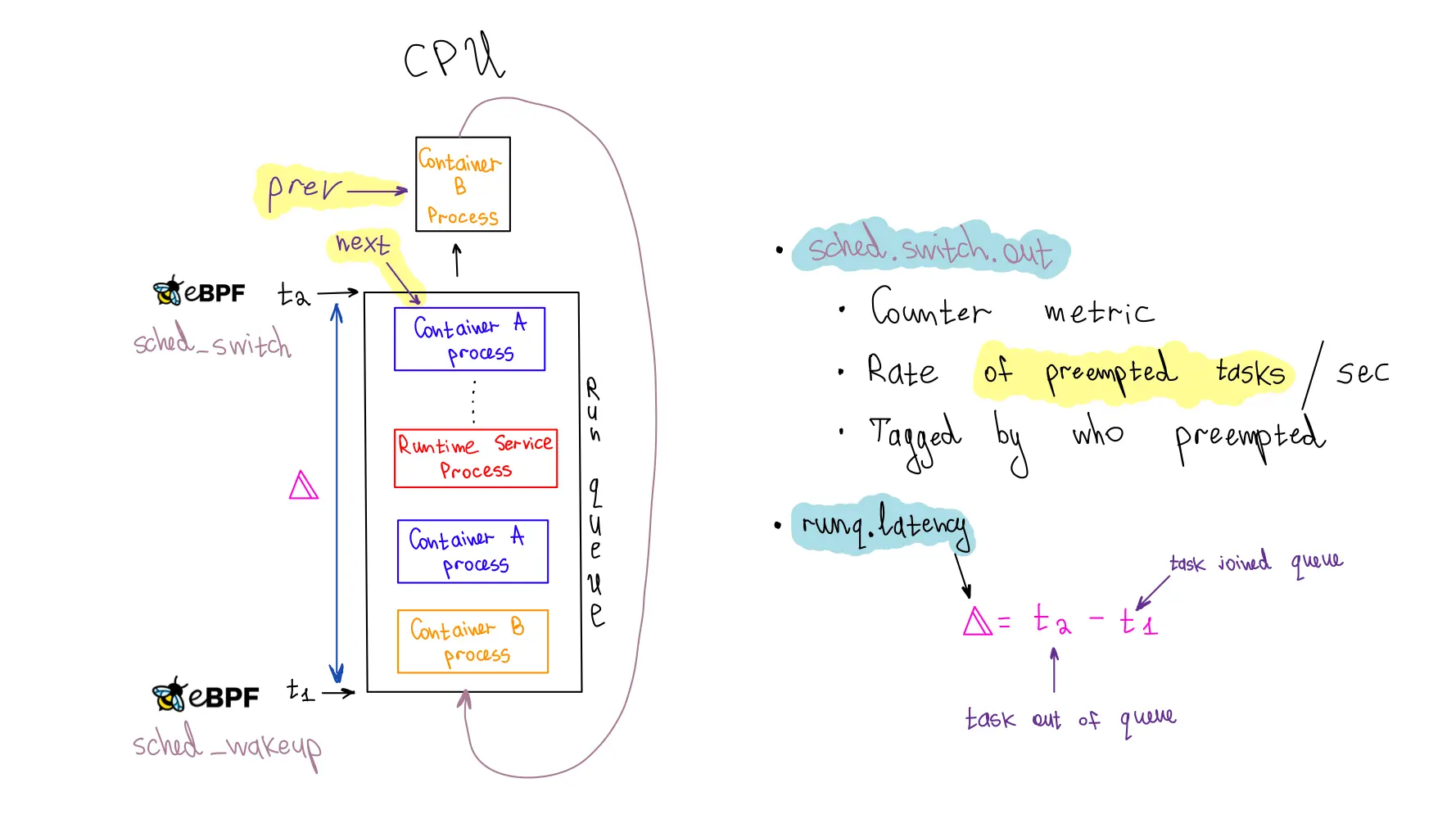
sched_wakeup 和 sched_wakeup_new 钩子在进程状态从“睡眠”变为“可运行”时调用。它们让我们识别出进程准备运行并等待 CPU 时间的时刻。在此事件中,我们生成一个时间戳,并使用进程 ID 作为键,将其存储在 eBPF 哈希图中。
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, MAX_TASK_ENTRIES);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u64));
} runq_enqueued SEC(".maps");
SEC("tp_btf/sched_wakeup")
int tp_sched_wakeup(u64 *ctx)
{
struct task_struct *task = (void *)ctx[0];
u32 pid = task->pid;
u64 ts = bpf_ktime_get_ns();
bpf_map_update_elem(&runq_enqueued, &pid, &ts, BPF_NOEXIST);
return 0;
}
相反,sched_switch 钩子在 CPU 在进程间切换时触发。这个钩子提供了当前利用 CPU 的进程和即将接管的进程的指针。我们使用即将执行任务的进程 ID (PID) 来获取之前存储的时间戳。然后,我们通过简单地减去时间戳来计算 run queue 延迟。
SEC("tp_btf/sched_switch")
int tp_sched_switch(u64 *ctx)
{
struct task_struct *prev = (struct task_struct *)ctx[1];
struct task_struct *next = (struct task_struct *)ctx[2];
u32 prev_pid = prev->pid;
u32 next_pid = next->pid;
// 获取下一个任务入队的时间戳
u64 *tsp = bpf_map_lookup_elem(&runq_enqueued, &next_pid);
if (tsp == NULL) {
return 0; // 未记录入队
}
// 在删除存储的时间戳前计算 runq 延迟
u64 now = bpf_ktime_get_ns();
u64 runq_lat = now - *tsp;
// 从 enqueued 图中删除 PID
bpf_map_delete_elem(&runq_enqueued, &next_pid);
....
eBPF 的一个优势是它能提供指向实际内核数据结构的指针,这些结构代表进程或线程,也称为内核术语中的任务。这一特性使得我们能够访问关于进程存储的大量信息。我们需要进程的 cgroup ID 以将其与容器关联,但是进程结构中的 cgroup 信息受到 RCU (Read Copy Update) 锁 的保护。
为了安全地访问这些受 RCU 保护的信息,我们可以利用 eBPF 中的 kfuncs 。kfuncs 是可以从 eBPF 程序调用的内核函数。这些函数确保我们的 eBPF 程序在检索任务结构中的 cgroup ID 时保持安全和高效。
void bpf_rcu_read_lock(void) __ksym;
void bpf_rcu_read_unlock(void) __ksym;
u64 get_task_cgroup_id(struct task_struct *task)
{
struct css_set *cgroups;
u64 cgroup_id;
bpf_rcu_read_lock();
cgroups = task->cgroups;
cgroup_id = cgroups->dfl_cgrp->kn->id;
bpf_rcu_read_unlock();
return cgroup_id;
}
数据准备好后,我们必须将其打包并发送到用户空间。为此,我们选择了 eBPF 环形缓冲区 。它既高效又高性能,且用户友好。它可以处理变长数据记录,并允许数据读取而无需额外的内存复制或系统调用。然而,大量数据点使得用户空间程序的 CPU 使用过多,所以我们在 eBPF 中实施了速率限制以采样数据。
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, RINGBUF_SIZE_BYTES);
} events SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_HASH);
__uint(max_entries, MAX_TASK_ENTRIES);
__uint(key_size, sizeof(u64));
__uint(value_size, sizeof(u64));
} cgroup_id_to_last_event_ts SEC(".maps");
struct
runq_event {
u64 prev_cgroup_id;
u64 cgroup_id;
u64 runq_lat;
u64 ts;
};
SEC("tp_btf/sched_switch")
int tp_sched_switch(u64 *ctx)
{
// ....
// 上述代码
// ....
u64 prev_cgroup_id = get_task_cgroup_id(prev);
u64 cgroup_id = get_task_cgroup_id(next);
// 按每个 cgroup ID 每个 CPU 进行速率限制
// 平衡可观测性与性能开销
u64 *last_ts =
bpf_map_lookup_elem(&cgroup_id_to_last_event_ts, &cgroup_id);
u64 last_ts_val = last_ts == NULL ? 0 : *last_ts;
// 在进行更多工作之前检查考虑中的 cgroup ID 的速率限制
if (now - last_ts_val < RATE_LIMIT_NS) {
// 速率限制超出,丢弃事件
return 0;
}
struct runq_event *event;
event = bpf_ringbuf_reserve(&events, sizeof(*event), 0);
if (event) {
event->prev_cgroup_id = prev_cgroup_id;
event->cgroup_id = cgroup_id;
event->runq_lat = runq_lat;
event->ts = now;
bpf_ringbuf_submit(event, 0);
// 更新当前 cgroup ID 的最后一个事件时间戳
bpf_map_update_elem(&cgroup_id_to_last_event_ts, &cgroup_id,
&now, BPF_ANY);
}
return 0;
}
我们在 Go 开发的用户空间应用程序处理环形缓冲区中的事件,以向我们的度量后端
Atlas
发出度量。每个事件包含一个带有 cgroup ID 的 run queue 延迟样本,我们将其与主机上运行的容器关联。如果没有发现这种关联,我们会将其分类为系统服务。当 cgroup ID 与容器关联时,我们会为该容器发出百分位计时器 Atlas 度量(runq.latency)。我们还增加了一个计数器度量(sched.switch.out)来监控容器进程的抢占情况。通过访问被抢占进程的 prev_cgroup_id,我们可以为度量标记抢占的原因,无论是同一容器(或 cgroup)内的进程、另一个容器的进程还是系统服务的进程。
值得强调的是,runq.latency 度量和 sched.switch.out 度量都需要确定容器是否受到噪声邻居的影响,这是我们旨在实现的目标。单独依赖 runq.latency 度量可能会导致误解。例如,如果容器处于或超过其 cgroup CPU 限制,调度器将对其进行限制,导致队列中的延迟明显增加。如果我们只考虑这个度量,我们可能错误地将性能下降归咎于噪声邻居,而实际上是因为容器触及了其 CPU 配额。然而,当两个度量同时出现尖峰,尤其是当原因是不同容器或系统进程时,明显表明了噪声邻居问题。
噪声邻居的故事
以下是一台运行单个容器的服务器的 runq.latency 度量,该容器拥有充足的 CPU 容量。99 百分位平均为 83.4 微秒(微秒),作为我们的基准。尽管有些尖峰达到 400 微秒,但延迟仍在可接受的参数范围内。
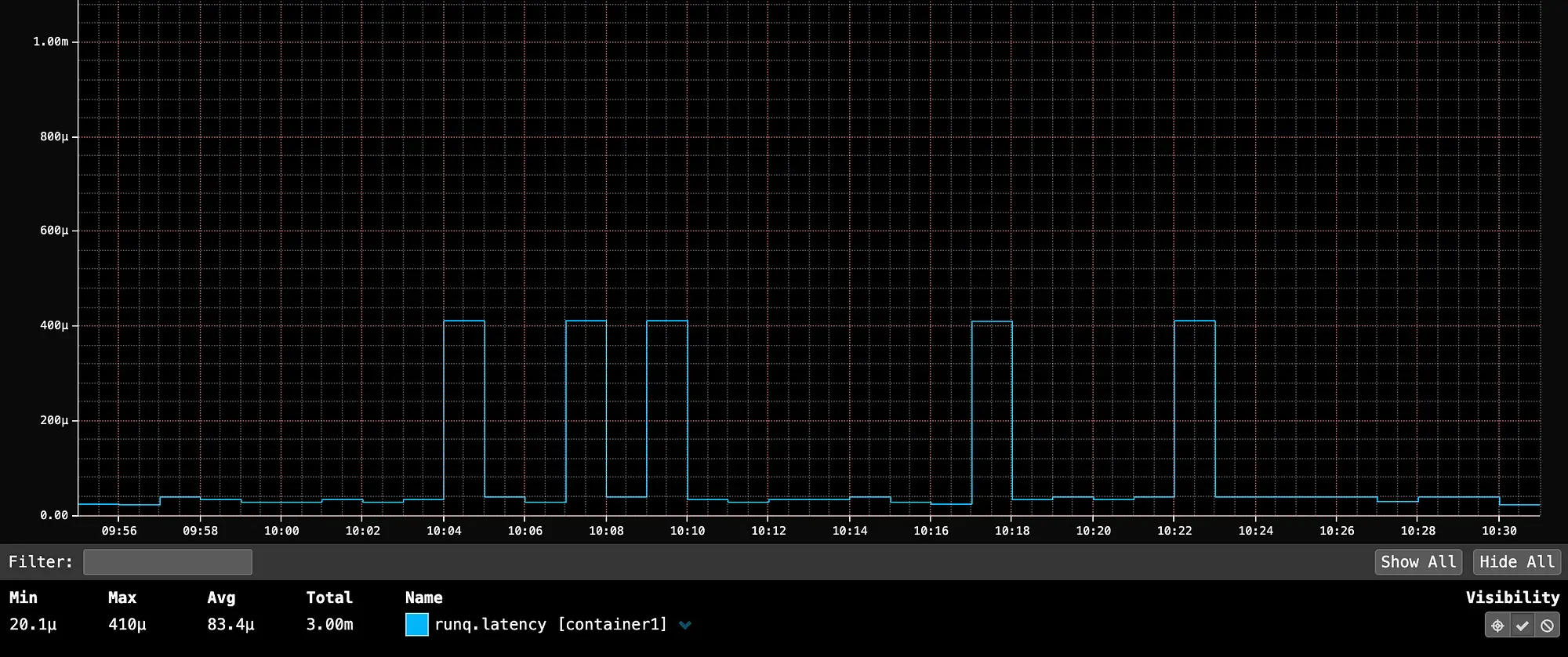
container1 的 99 百分位 runq.latency 平均为 83 微秒(微秒),尖峰可达 400 微秒,没有相邻容器。这作为一个容器在主机上未争夺 CPU 的基准。
在 10:35,启动 container2,它充分利用了主机上的所有 CPU,导致 container1 的 P99 run queue 延迟出现了 131 毫秒的尖峰(131,000 微秒)。如果用户空间应用程序正在服务 HTTP 流量,则这一尖峰将在用户空间应用程序中可见。如果用户空间应用程序所有者报告了无法解释的延迟尖峰,我们可以通过 run queue 延迟度量迅速识别噪声邻居问题。
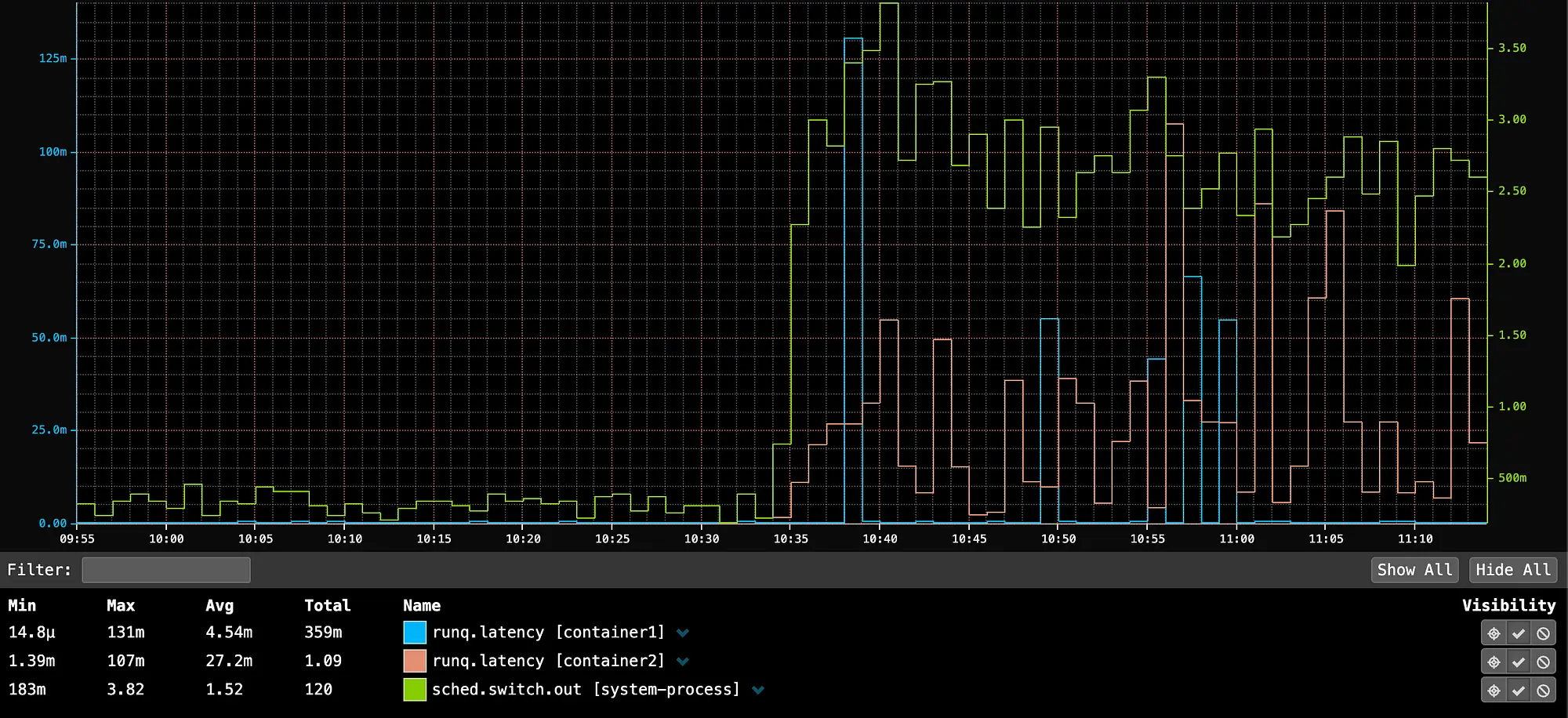
在 10:35 启动的 container2 充分利用了主机上的所有 CPU,导致 container1 的 P99 run queue 延迟出现了 131 毫秒的尖峰,因为系统进程的抢占增加。这表明存在一个噪声邻居问题,即系统服务与容器竞争 CPU 时间。我们的度量显示,噪声邻居实际上是系统进程,可能是由 container2 消耗所有可用 CPU 容量触发的。
优化 eBPF 代码
我们开发了一个名为
bpftop
的开源 eBPF 进程监控工具,用来测量此内核热路径中 eBPF 代码的开销。我们使用 bpftop 进行的性能分析显示,检测仪增加的开销不到每个 sched_* 钩子 600 纳秒。我们对在容器中运行的 Java 服务进行了性能分析,发现检测代码未引入显著开销。开启与关闭 run queue 检测代码的性能差异在毫秒级不可测。
在我们对内核中如何测量 eBPF 统计信息的研究中,我们发现了一个改进计算的机会。我们提交了这个 patch ,并包括在 Linux 内核 6.10 版本中。
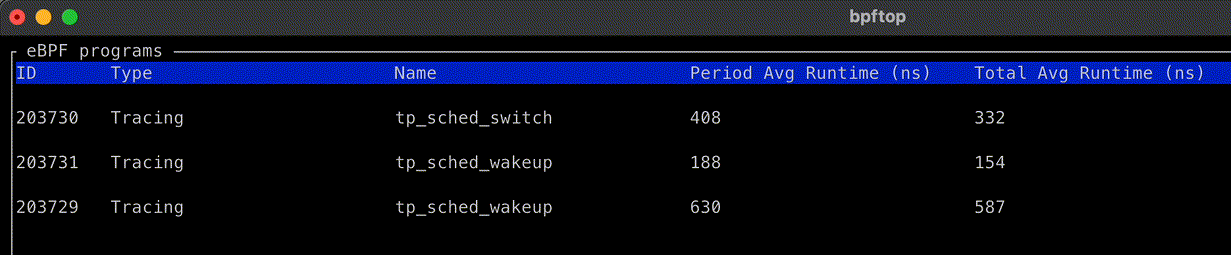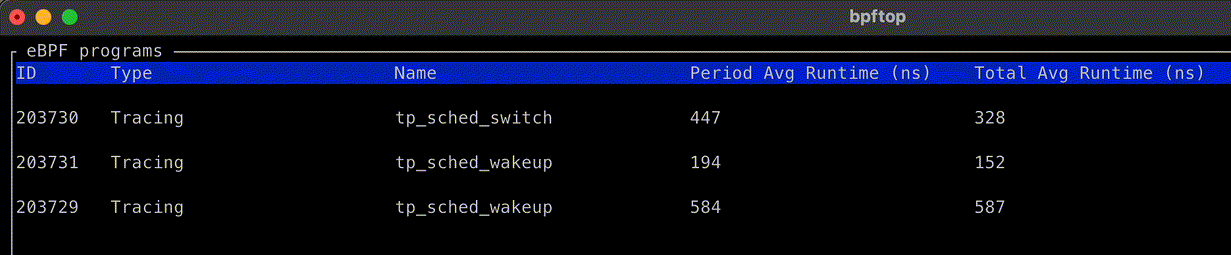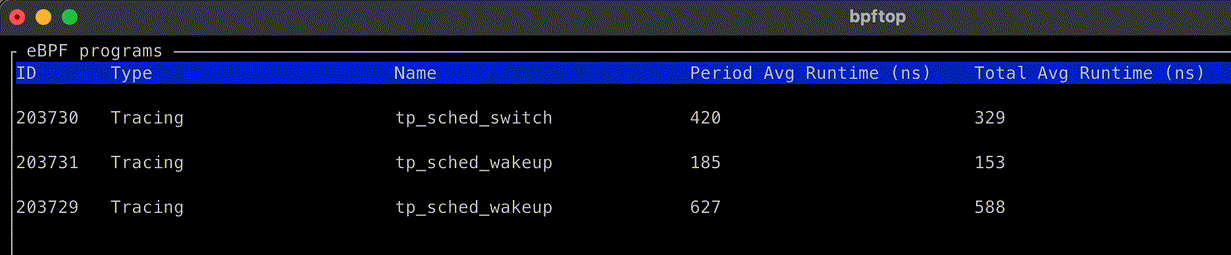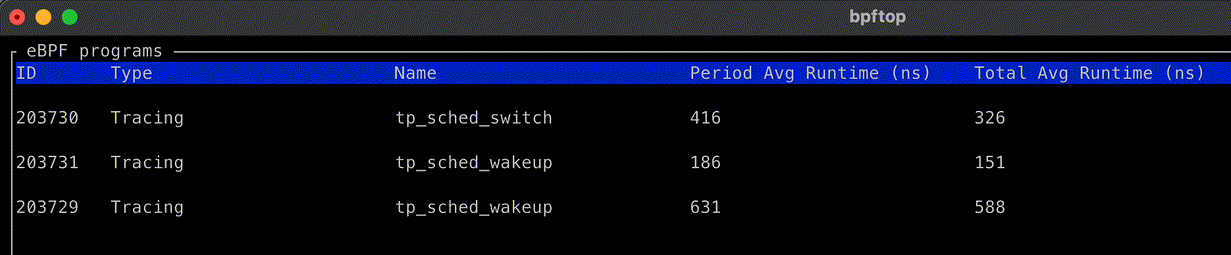
通过试错和使用 bpftop,我们确定了几种优化,帮助保持了我们 eBPF 代码的低开销:
- 我们发现
BPF_MAP_TYPE_HASH存储入队时间戳时最为高效。使用BPF_MAP_TYPE_TASK_STORAGE会导致性能下降近一倍。BPF_MAP_TYPE_PERCPU_HASH的性能略低于BPF_MAP_TYPE_HASH,这是意料之外的,需要进一步调查。 BPF_MAP_TYPE_LRU_HASH映射的操作比常规哈希映射慢 40-50 纳秒。由于 PID 流失引起的空间问题,我们最初使用了它们来存储入队时间戳。最终,我们选择了增大尺寸的BPF_MAP_TYPE_HASH,以降低这一风险。BPF_CORE_READ帮助每次调用增加 20-30 纳秒。在特别是那些“BTF 启用”的原始跟踪点(tp_btf/*)的情况下,直接访问任务结构成员是安全且更高效的。Andrii Nakryiko 在这篇 博客文章 中推荐了这种方法。sched_switch、sched_wakeup和sched_wakeup_new都会因内核任务触发,这些任务的 PID 为 0。我们发现监控这些任务是不必要的,因此我们实施了几种提前退出条件和条件逻辑,以防在处理内核任务时执行代价高昂的操作,如访问 BPF 映射。值得注意的是,内核任务就像任何常规进程一样通过调度队列操作。
结论
我们的发现突出了使用 eBPF 对 Linux 内核进行低开销持续检测的价值。我们已将这些度量整合到客户仪表板中,使其能够提供可操作的洞察,并指导多租户性能讨论。我们现在也可以使用这些度量来完善 CPU 隔离策略,以最小化噪声邻居的影响。此外,这些度量使我们深入了解了 Linux 调度器。
这项工作还加深了我们对 eBPF 技术的理解,并强调了像 bpftop 这样的工具对优化 eBPF 代码的重要性。随着 eBPF 的采用增加,我们预见更多的基础设施可观测性和业务逻辑将转向使用它。在这方面有一个前景广阔的项目是
sched_ext
,它有潜力革新调度决策的制定方式,并根据特定工作负载需求进行定制。