GPU 调度的未来,不在于谁的实现更“黑盒”,而在于谁能把资源契约标准化到可治理。

引言
你是否想过:为什么 GPU 这么贵,但整体利用率却经常只有 10%–20%?
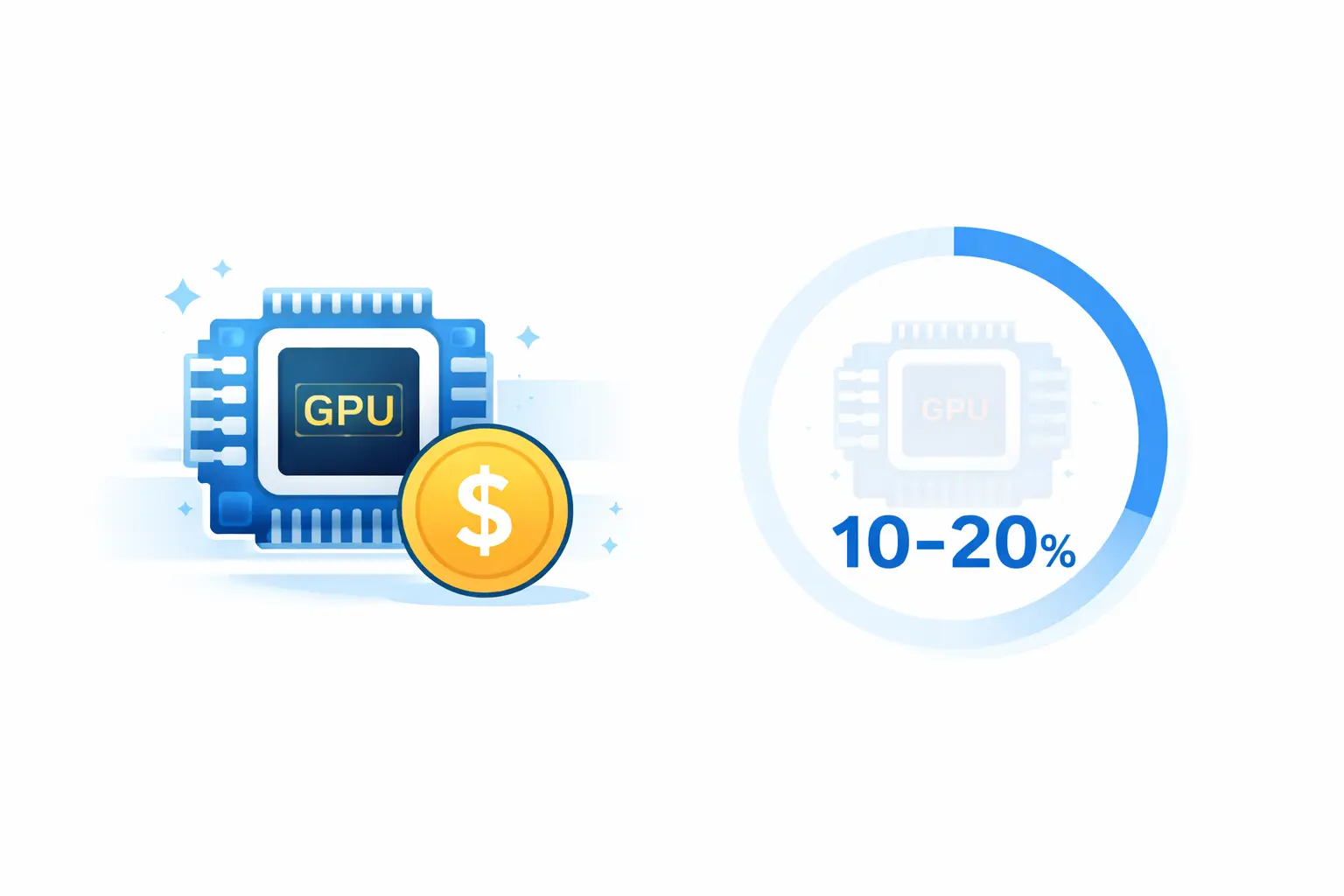
这不是一个"优化算法"能解决的问题,而是一个结构性问题——GPU 调度正在经历一场从"私有实现"到"开放调度"的转变,类似当年网络走向 CNI、存储走向 CSI 的标准化路径。
在 HAMi 2025 年度回顾 中提到:“2025 的 HAMi 已经不再只是一个 GPU 共享工具箱,而是一个更结构性的信号:GPU 正在走向开放调度。”
2025 年,这个转变的信号已经清晰可见:Kubernetes DRA(Dynamic Resource Allocation)进入 GA 并默认启用,NVIDIA GPU Operator 开始默认使用 CDI(Container Device Interface)开放规范,而 HAMi 在 CNCF 的生产级案例正在把"GPU 共享"从实验能力推向运营能力。
本文将从 AI Native Infrastructure 的视角,深入解析这场结构性转变的驱动力、证据链以及对「Dynamia 密瓜智能」和整个行业的战略意义。
为什么“开放调度”很重要
在多云/混合云环境下,GPU 型号多样性会显著放大运维成本。以某大型互联网公司为例,其平台覆盖 H200/H100/A100/V100/4090 等多型号 GPU,跨 5 个集群。如果只能“整卡分配”,资源错配几乎不可避免。
“开放调度”不是一句口号,而是一组正在被主流栈固化的工程契约。
资源表达的标准化
过去,GPU 作为扩展资源(extended resources),调度器无法识别其显存、算力或设备类型等属性。
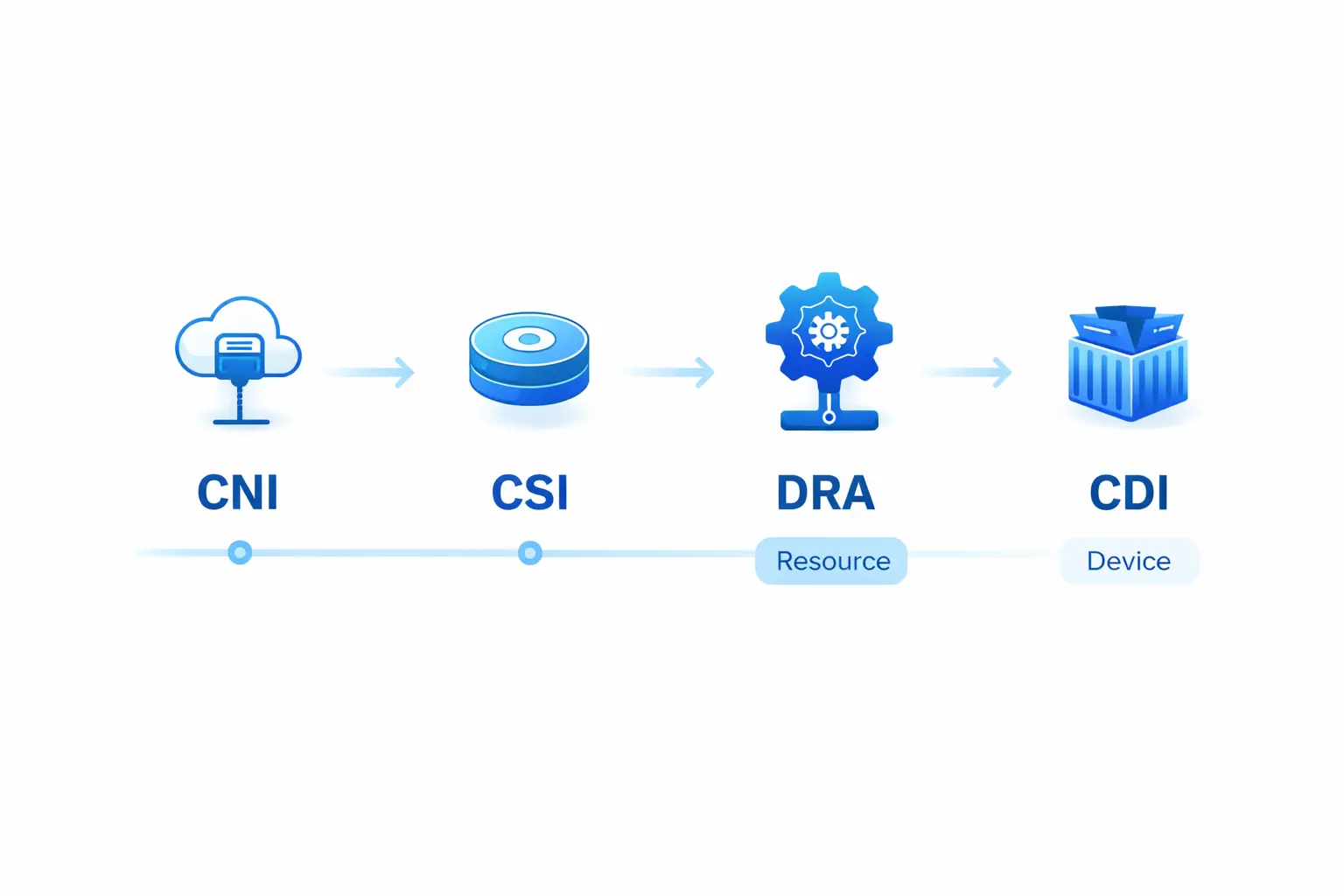
现在,Kubernetes DRA 通过 DeviceClass、ResourceClaim、ResourceSlice 等对象,让驱动和集群管理员可以定义设备类别与选择条件(支持 CEL 选择器)。Kubernetes 在调度时完成“匹配设备 → 绑定声明 → 把 Pod 放到可访问节点”的完整流程。
更重要的是,Kubernetes 1.34 明确承诺:resource.k8s.io 组的核心 API 进入 GA,DRA 变得稳定且默认启用,后续不会再有破坏性变更。这意味着生态可以以“标准 API”为锚点开始规模化投资。
设备注入的标准化
过去,设备注入容器依赖 vendor-specific 的 hooks 和 runtime class 模式。
现在,CDI 将设备注入语义抽象成开放规范。NVIDIA Container Toolkit 明确将其描述为面向 container runtime 的开放规范,NVIDIA GPU Operator 25.10.0 在安装/升级时默认启用 CDI,直接利用 containerd/CRI-O 等 runtime 的 CDI 支持进行注入。
这意味着“设备进入容器”这一步也在走向可替换、可标准化接口。
HAMi:从“共享工具”到“可治理数据平面”
在标准化通路上,HAMi 的角色需要重新定义:它不是要替代 Kubernetes,而是把 GPU 虚拟化与切分做成可声明、可调度、可治理的数据平面。
数据平面视角
HAMi 的核心是将“整卡整数”的资源单位扩展为 core/memory 等份额,形成完整的分配链路:
- 设备发现:识别可用 GPU 设备和型号。
- 调度落位:通过 Scheduler Extender 让原生调度器“看懂”vGPU 资源模型(Filter/Score/Bind 三段式)。
- 容器内兑现:把份额约束注入容器运行时。
- 指标导出:提供可观测的利用率、隔离度等指标。
这种方式让“共享”不再是容器里自觉的经验主义,而是可以被 YAML 声明、被策略调度、被指标验收的工程能力。
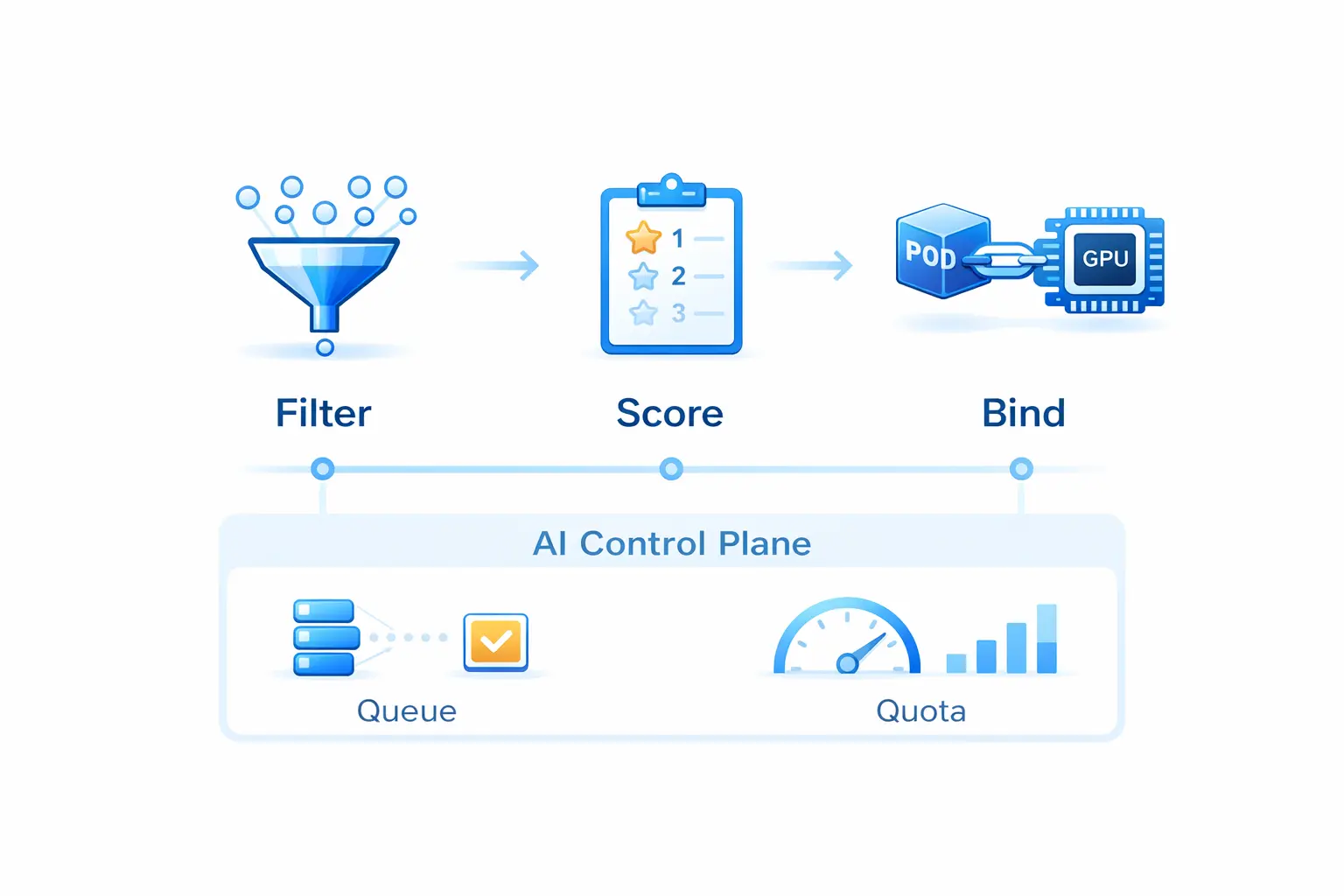
调度机制:不是替换,而是增强
HAMi 的调度并非替换 Kubernetes,而是用 Scheduler Extender 让原生调度器“看懂”vGPU 资源模型:
- Filter:根据显存、算力、设备类型、拓扑等约束过滤节点。
- Score:提供 binpack、spread、topology-aware 等可配置策略。
- Bind:完成设备与 Pod 的最终绑定。
因此,HAMi 天然适合作为“AI 控制面(队列/配额/优先级)”之下的执行层,与 Volcano、Kueue、Koordinator 等形成职责分工。
生产证据:从“能不能共享”到“能不能运营”
CNCF 的公开案例为 GPU 虚拟化的生产级能力提供了直观证据:
在一个跨公有云与私有云的多集群平台中,Kubernetes + HAMi 支撑 10,000+ Pod 并发,把 GPU 利用率从 13% 提升到 37%(近 3 倍)。

以下是 CNCF 生产案例的实证数据:
| 案例 | 场景/项目 | 核心成果 | 特色 |
|---|---|---|---|
| 贝壳找房 | 跨 5 集群平台 H200/H100/A100/V100/4090 等多型号训练整卡池 vs 推理 vGPU 池 | 整体 GPU 利用率 13% → 37%(近 3 倍)10,000+ Pod 并发 | 多型号异构调度 |
| DaoCloud | 硬约束:云原生、vendor-agnostic、CNCF 工具链 | 平均 GPU 利用率 80%+ 运营成本下降 20–30% 10+ 数据中心、10,000+ GPU 卡 | 统一抽象层跨 NVIDIA + 国产 GPU |
| Prep EDU | 异构 RTX 4070/4090 集群 | 资源隔离失败 → GPU 虚拟化调度提升利用率 | 与 GPU Operator、RKE2 生产集成 |
| 顺丰科技 | 大模型推理、测试、语音识别国产 AI 硬件适配(华为昇腾、百度昆仑等) | GPU 节省 57%(生产 + 测试集群)大模型推理 65 服务/28 GPU 测试 19 服务/6 GPU | 跨节点协同调度、优先级抢占内存超售技术 |
这些案例证明,GPU 虚拟化成为经济上有意义的能力,前提是它参与到一个可治理的契约——利用率、隔离度、策略可以被表达、被测量、被持续改进。
国产芯片的崛起:智谱 GLM-5 的实践
一个更具信号意义的案例来自智谱 AI:GLM-5 在上线后不久即完成与华为昇腾、摩尔线程、寒武纪、昆仑芯、沐曦、燧原、海光等国产算力平台的深度推理适配,通过底层算子优化与硬件加速,在国产芯片集群上实现高吞吐、低延迟的稳定运行。详见 GLM-5 开源:从代码到工程,Agentic Engineering 时代最好的开源模型
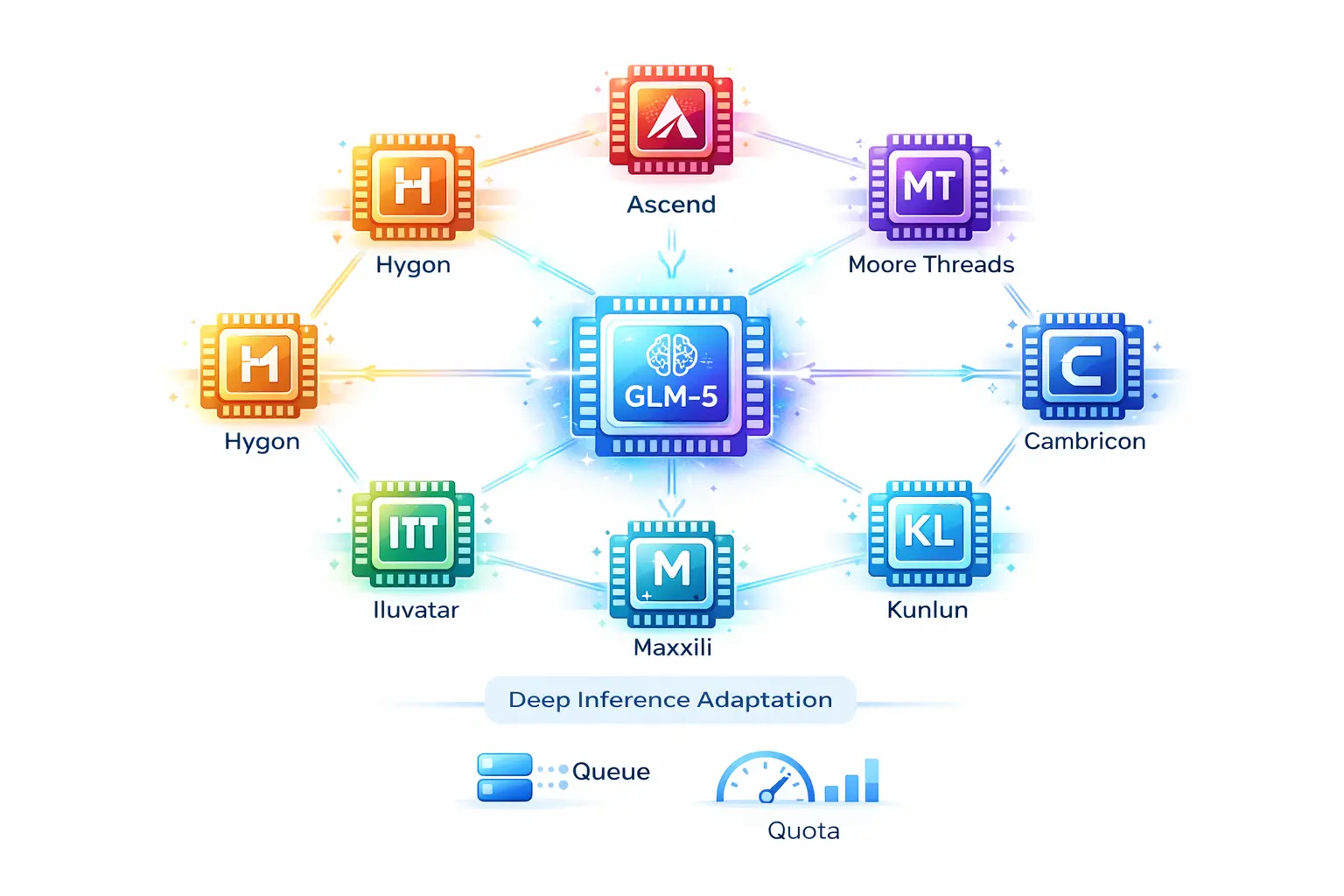
这个案例的重要性在于:它不是"试验性适配",而是承载全球爆量生产流的真实部署。GLM 系列模型在全球权威的 Artificial Analysis 榜单中位居开源第一,GLM-5 更是在全球开发者社区中引发爆量采用——在这样的规模下,“能否在多型号、多厂商的国产 GPU 集群上稳定服务"不再是技术验证问题,而是业务连续性问题。
从开放调度的视角看:
- 硬件层面的异构性正在成为常态:国产芯片从"可用"走向"可规模化部署”,意味着调度系统必须真正具备跨厂商、跨型号的资源抽象与治理能力
- “适配"不再是单点工程,而是需要可声明的契约:GLM-5 能在多个国产 GPU 平台上实现"底层算子优化与硬件加速”,恰恰证明了当资源表达、设备注入、调度约束都成为可声明的工程能力时,上层应用才有空间做深度优化
- 开放调度是国产芯片生态化的前提:当硬件层走向多元化,“能不能在多种芯片上跑"会变成"能不能以可预测的运维成本和治理水平在多种芯片上跑”——这需要标准化接口作为基础
对密瓜智能的战略意义
从密瓜智能的视角,HAMi 的结构性价值更加清晰:
双层机制:开源 vs 商业
- HAMi(CNCF 开源项目):负责“采用与信任”,聚焦 GPU 虚拟化与算力优化。
- 密瓜智能企业产品与服务:负责“落地与规模化运行”,基于 HAMi 提供商业发行版。
这种边界是长期信任的底线——项目与公司产品分离,商业发行版与企业服务基于开源项目。
商业化的正确落点
DaoCloud 的案例已将 vendor-agnostic 与兼容 CNCF 工具链设为硬约束,并把“减少 vendor dependency”写进收益清单。Project-HAMi 的官方文档也将“避免 vendor lock”列为主打价值之一。
在此基础上,商业化更合理的落点不是“把调度闭源”,而是围绕企业真实复杂度提供产品化能力:
- 更系统化的兼容矩阵
- SLO/尾延迟治理
- 可计费计量
- RBAC/配额/多集群治理
- 升级与回滚安全
- 对 DRA/CDI 等规范化路径的更快落地与工程化整合
前瞻判断:接下来的 2–3 年
我个人判断,未来 2–3 年,GPU 调度的竞争重点会从“谁的实现更黑盒”转向“谁的契约更开放”。
原因如下:
硬件形态和供应链正在变得更复杂
- OpenAI 2026-02-12 发布的“GPT‑5.3‑Codex‑Spark”强调超低时延 serving,包括持久 WebSocket 和 Cerebras 硬件上的专用 serving tier。
- 大规模 GPU 资产融资(用于泛欧部署)显示了加速器舰队的基础设施规模和金融工程。
这些信号表明,异构性会持续增长——混合加速器、混合云、混合工作负载类型。
低时延推理 tier 会逼迫资源调度体系化
低时延推理 tier(不仅限于 GPU)会推动资源调度走向“多加速器、多层缓存、多类节点”的体系化设计,调度必须面向异构。
开放调度不是理想主义,而是风险管理
在这样的世界里,“开放调度”不是理想主义,而是风险管理。围绕 DRA/CDI 这样不断被固化的开放接口,把调度做成可插拔、多租户可治理、且能被生态共同演进的“控制平面/数据平面组合”,更像是 AI Native Infrastructure 真正可持续的路径。
下一个主战场不是“谁的调度更聪明”,而是“谁能把设备资源契约标准化到可治理”。
总结
当你把 2025 的 HAMi 放回更大的 AI Native Infrastructure 语境里看,它已经不再是“GPU 共享工具箱”的一年,而是一个更结构性的信号:GPU 正在走向开放调度。
这场转变的驱动力来自两端:
- 上游:DRA/CDI 等标准不断固化。
- 下游:规模化与多样化(多云、多型号、甚至 GPU 之外的加速器形态)。
对密瓜智能而言,HAMi 的意义已经超出一个“GPU 共享工具”:它把 GPU 虚拟化与切分变成可声明、可调度、可计量的数据平面,让队列/配额/优先级/多租户等控制面治理真正闭环。
