HAMi 不只在集群里省卡了,它开始在桌面上决定一台 AI 工作站好不好用。
一个老朋友提到一个名字
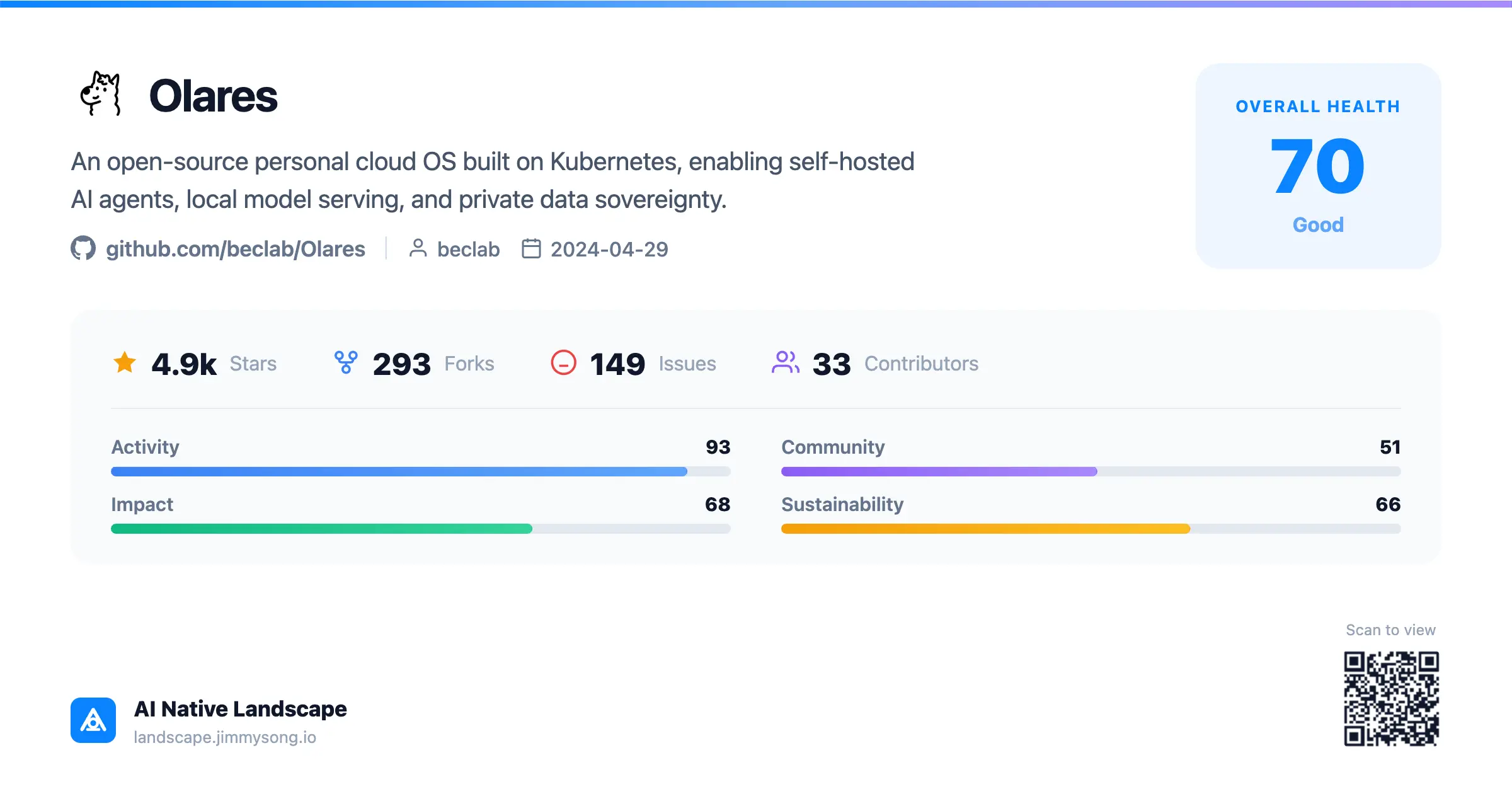
前几天一位老朋友来找我聊天。我们以前一起张罗国内的云原生社区活动,算是老搭档了。她最近去了一家叫 Olares 的公司,聊着聊着提到一句:他们项目集成了 HAMi。
我平时就在运营 HAMi 社区,听到别人拿它做什么,总会想多看一眼。结果真去翻了翻 Olares 的仓库和官网,第一反应是,哎,这个有点意思。
这不就是我惦记了很久、却一直没舍得下手的那种本地 AI 工作站吗?我之前在《我的 Personal AI Stack》里聊过,对我这种主要靠脑子干活的人来说,订阅模型比养一张高端显卡实在。但“一台机器跑全套 AI”到底能做到什么程度、谁真把它做出来了,我一直想亲眼看一看。
这东西到底是个啥
Olares 不是那种“带块 GPU 的 NAS”,也不是“装了 Ollama 的小主机”。它更像一台拿 Kubernetes 当底的个人云:本地模型、应用、身份、远程访问、开发环境、存储,连 GPU 治理都打包进一台机器,做成一个端侧的云操作系统。
HAMi 在这里不是凑数的。它是把“一张卡”变成“一个能共享、能隔离、能调度的资源池”的那一层。
跟一堆 AI 小主机的区别
市面上喊着 AI 工作站的东西不少,大多是台性能强点的小主机。Olares 不太一样,它是真按一个云来设计的。
官方直接把这台机器定位成 7×24 小时跑的 personal AI cloud,不是让你坐在前面用的 PC。就这一个定位,后面的事基本都说通了:为什么非得用 Kubernetes,为什么那么在意网络穿透和远程访问,为什么 GPU 治理在这里突然变得要紧。
还有俩细节挺能说明问题:它支持 Thunderbolt 5 外接 eGPU,还能两台机器组集群。也就是说,它从一开始就不是个封闭盒子,是单机起步、能往上长的东西。
把一整个云的运行时塞进单机
架构上看,Olares 干的就是把一整套云的运行时压进单机:认证授权、应用生命周期、各种隧道穿透、密钥、可观测中间件,一层都没落下。
这不是“预装几个 AI 应用”,是一个完整的 cloud runtime 被塞进了桌面设备。
下面这张图是我照着它的公开文档重新梳理的分层,特意把 HAMi 那一层单拎出来,因为它是整篇的重点。

一个挺有意思的细节
我翻的时候注意到一件事:Olares 的文档,有点跟不上它自己的产品。
它 2025 年的架构页面还写着 nvshare,注明 GPU 只支持每节点一张卡。可翻开版本说明,1.12 就已经集成 HAMi 调度器了,独占、时间切片、显存切片三种模式都有;1.12.2 上多 GPU;1.12.5 直接支持 DGX Spark,还把自动调度铺到全部三种模式。
产品比文档跑得快。这本身就说明点东西:它正从“个人云 OS”往“本地 AI 云 OS”挪。这也是我想专门写一篇的原因。
HAMi 在里面到底干了啥
HAMi 是个 CNCF Sandbox 项目,定位是异构 AI 计算虚拟化中间件。链路上有 Webhook、调度器、Device Plugin,还有负责容器内资源控制的 HAMi-core。我之前在《Kubernetes 正在成为 AI 时代的 GPU Control Plane》里写过一句话概括它:把 GPU 切分从“硬件能力”变成“控制面的能力”。
放到 Olares 上,这就是设置里那个 GPU 模式开关背后真正的东西。表面是个 UI 选项,底下是资源平面的策略切换。
最关键的一环大概率是 HAMi-core,玩法一句话:在容器里拦住 CUDA 调用,做显存虚拟化、算力限流、利用率监控。不靠硬件切,靠软件管。
下面这张图把这条注入链路和三种 GPU 模式放一块了。

证据也对得上。Olares 的 GitHub issue 里能直接看到 HAMi 的 libvgpu.so 在 WSL2 下崩过,讨论里也有人提到它通过 /etc/ld.so.preload 注进每个进程,Olares 团队自己也说这套实现从 HAMi 项目“获得了重要启发”。
不过有件事得说清楚:Olares 到底是直接用上游的 HAMi-core,还是自己改了一版,公开资料里没有个统一说法。这地方我就不替它脑补了。
三种模式顺着就懂。整卡独占给重负载;时间切片让轻量服务轮着用,Olares 还会把不活跃的模型先换到内存里,切换大概就 5% 开销;显存切片把显存切成固定配额,让多个应用一起跑。到了 DGX Spark 那种 CPU 和 GPU 共享内存的架构,它就默认走显存切片,因为压根没有传统那种显存换入换出。
为啥我觉得这事对 HAMi 挺重要
HAMi 以前主要在大集群里转:多租户、推理服务、训练推理混部、异构卡。NIO 拿它在 80 个节点、600 张卡上做共享,就是典型。这条线已经很熟了。
Olares 让我觉得新鲜的地方是,它把同一个问题搬到了一台机器上。

你在 Olares 上真会同时跑的东西,从来不止一个 Ollama:一个本地模型,一个聊天界面,一个研究 agent,一条图像或视频链路,再加一堆 OCR、语音转写、自动化工具。这种场景要是没有 GPU 调度层,GPU 最后一定退化成“谁先起来谁占住”。
所以对 HAMi 来说,这事挺关键。它从“给平台工程师省卡的工具”,变成了“直接决定普通用户用得爽不爽”的东西。在集群里它管的是利用率和成本,在 Olares 上它管的是并发体验、模型切换、和这台机器到底好不好用。HAMi 不再只跟平台工程师打交道了。
端侧 AI 会往哪走
我的感觉是,端侧 AI 最后不会停在“一个更强的本地模型盒子”,而是会长成“控制平面加模型平面加应用平面”一整套。
NVIDIA 把 DGX Spark、RTX Spark 往桌面上推,故事已经从“本地跑模型”升级到“本地跑 agent”。Olares 这种 CUDA 加 x86 是一条路,DGX Spark 那种统一内存是一条,再往下还有 DIY 小主机加 eGPU 自己拼的。有意思的是 Olares 自己就把 eGPU 和双节点列成了支持路径,appliance 跟 DIY 之间没那么泾渭分明。
不过最后能跑出来的,我猜不是参数最猛的那家,而是能把资源治理、开发体验、应用生态、安全、远程访问捏成一整个闭环的那家。端侧 AI 工作站这个品类要是真能立住,最后拼的不是 GPU 和内存,是控制平面。
顺手把 Olares 收进了我自己维护的 AI Native Landscape,往后好接着看它怎么长。
总结
一句话:Olares 是一台以 Kubernetes 为内核的端侧 AI 操作系统,HAMi 是它把单机 GPU 变成可共享、可隔离、可调度资源池的那一层。
从集群到桌面,HAMi 的故事正从“省卡”往“让端侧 AI 好用”扩。端侧 AI 工作站要是真成一个品类,最后拼的是控制平面,不是单卡性能。
