为什么 GPU 多租户如此困难
本章将讨论以下几个问题:
- 传统 Kubernetes 隔离机制(命名空间、cgroups、RBAC)如何工作以及为什么它们对 GPU 失效
- 跨租户共享 GPU 时出现的具体安全漏洞
- 如何根据你的信任模型评估不同的 GPU 共享方案(MPS、时间分片、MIG、vGPU)
- 一个实用的决策框架,用于为你的组织选择合适的 GPU 共享策略
为了理解 GPU 多租户为什么困难,首先需要回到一个更基础的问题:在不涉及 GPU 的情况下,Kubernetes 是如何实现多租户的。
传统 Kubernetes 隔离:行之有效的基础
在典型的 Kubernetes 集群中,工作负载往往来自不同的团队、部门,甚至不同客户,它们需要共享同一批物理节点,却又不能彼此干扰。Kubernetes 之所以能够支撑这种模式,依赖的是三类相互配合的隔离机制:命名空间负责逻辑划分,cgroups 在 Linux 内核层面强制执行物理资源边界,RBAC 控制谁可以通过 API 访问和操作哪些对象。三者组合起来,形成了一个相当稳固的多租户模型:工作负载可以并行运行,但在可见性、可消耗资源以及可操作范围上彼此隔离。
命名空间:控制面分离
命名空间将 Kubernetes 资源划分为逻辑域。每个租户——无论是团队、部门还是客户——都有自己的命名空间。
$ kubectl get ns
NAME STATUS
fraud-detection Active
data-analytics Active
marketing Active
engineering Active从表面上看,这像是一种强隔离;但命名空间本质上只存在于 Kubernetes API 这一层。它规定的是谁可以通过控制面查看、列举或管理资源,而不是谁在内核或硬件层面真正与谁隔离。
下面用一个简单的例子说明这一点:
$ kubectl get pods -A -o wide
NAMESPACE NAME STATUS NODE
fraud-detection fraud-inference Running minikube
data-analytics analytics-job Running minikube
marketing campaign-analysis Running minikube
engineering model-training Running minikube虽然这些 Pod 分属不同命名空间,但它们实际上运行在同一个物理节点上。fraud-detection 命名空间中的 Pod 无法通过 API 列出 data-analytics 中的 Pod,不过只要它知道对方的 IP 地址,依然可以直接通过网络访问它们,除非集群额外配置了网络策略。换句话说,命名空间并不隔离 CPU、内存或设备,它只是一个控制面上的 API 构造。因此,真正阻止工作负载相互干扰的并不是命名空间本身,而是更底层的机制。
Cgroups:内核始终掌控一切
真正的物理强制执行来自 Linux cgroups。当你在 Pod 中声明资源限制时:
resources:
limits:
cpu: 500m
memory: 1Gikubelet 将这些值写入内核:
$ minikube ssh
$ cd /sys/fs/cgroup/kubepods.slice
$ cat ../cpu.max
50000 100000 # 每 100ms 中 50ms 的 CPU 时间
$ cat ../memory.max
1073741824 # 1 GiB这些限制不是建议值,而是由内核直接执行的硬边界。如果进程试图突破 CPU 配额,内核会对其进行限速;如果它试图分配超过 1 GiB 的内存,OOM killer 会直接终止该进程。对于 CPU 周期和内存页而言,内核拥有完整可见性,因此也能在租户之间强制执行公平性。这正是 Kubernetes 可以安全地把多个工作负载打包到同一节点上的关键前提。
RBAC:访问控制边界
命名空间定义逻辑边界,RBAC 则定义谁可以操作这些边界中的资源。
例如,可以先在 tenant-a 中创建一个服务账号:
kubectl create sa tenant-a-user -n tenant-a然后测试它对另一个命名空间的访问能力:
$ kubectl auth can-i get pods --namespace=tenant-b --as=system:serviceaccount:tenant-a:tenant-a-user
no
$ kubectl auth can-i list secrets --namespace=tenant-b --as=system:serviceaccount:tenant-a:tenant-a-user
noRBAC 的确阻止了通过 API 进行跨命名空间操作,但这种限制只覆盖控制面交互,并不会自动转化为运行时网络隔离。举例来说,只要知道 IP 地址,tenant-a 中的 Pod 仍然可以直接联系 tenant-b 中的 Pod:
# 首先,在 tenant-b 中创建一个简单的 Web 服务
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: web-service
namespace: tenant-b
spec:
containers:
- name: web
image: nginx:alpine
ports:
- containerPort: 80
EOF# 获取 Pod 的 IP 地址
$ kubectl get pod web-service -n tenant-b -o jsonpath='{.status.podIP}'
10.244.0.15# 现在从 tenant-a 中的一个 Pod,我们可以直接访问 tenant-b 的服务
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: client
namespace: tenant-a
spec:
containers:
- name: client
image: curlimages/curl:latest
command: ["sh", "-c", "curl http://10.244.0.15 && sleep 3600"]
EOF# 检查日志 - 连接成功
$ kubectl logs client -n tenant-a
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
…
</html>连接是成功的。
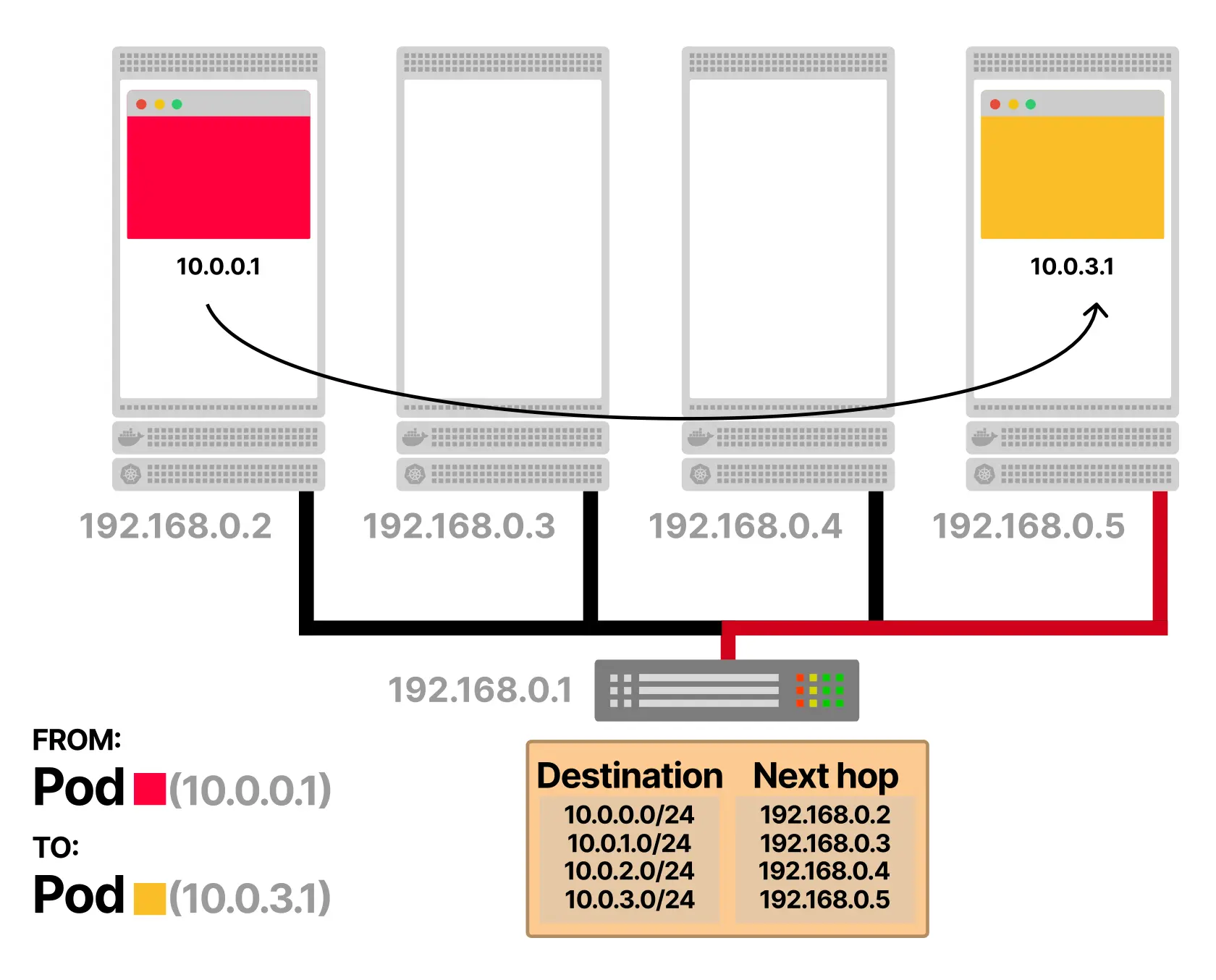
这说明了一个根本限制:命名空间和 RBAC 保护的是 API,cgroups 保护的是 CPU 和内存,而网络流量则需要额外的网络策略来约束。即便如此,凭借这三层配合,Kubernetes 依然为 CPU 和内存建立起了有效的多租户模型。其根本原因在于,真正决定资源边界的内核始终处于控制环路之中。
为什么这种多租户模型有效
这种多租户模型之所以成立,是因为 Linux 内核对 CPU 和系统内存拥有完整的可见性与执行能力。每个进程都属于某个 cgroup,内核直接维护这种关系;当 tenant-a 的进程请求 CPU 时间或分配内存时,内核会检查相应计数器,并据此决定是否允许、限速或终止。租户超过 CPU 配额时,调度器会限制它;超过内存边界时,OOM killer 会介入。关键不在于 Kubernetes 声明了什么,而在于内核能看到每一条指令和每一个字节,并能立刻执行限制。问题在于,一旦共享对象从 CPU 和系统内存变成 GPU,这套模型就开始失效,因为在 GPU 场景中,内核在许多关键环节上是“盲”的。
为什么这个模型对 GPU 失效
第一个断裂点出现在 GPU 内存上。分配系统内存时,内核会逐页跟踪变化,cgroups 也会立刻反映并强制执行限制;但分配 GPU 内存时,请求通常不会进入内核的常规内存管理路径,而是在用户空间的 NVIDIA 驱动内部被处理。下面这个 Pod 同时分配系统 RAM 与 GPU RAM,可以清楚展示这种差异:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: gpu-memory-test
spec:
containers:
- name: tester
image: pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime
command: ["python", "-c"]
args:
- |
import torch, os
def cgroup_mem():
try:
with open("/sys/fs/cgroup/memory.current") as f:
return int(f.read().strip()) / 1024**2
except:
return -1
print("System memory before:", cgroup_mem(), "MB")
system_data = bytearray(100 * 1024 * 1024)
print("System memory after 100MB allocation:", cgroup_mem(), "MB")
print("GPU memory before:", torch.cuda.memory_allocated() / 1024**2, "MB")
gpu_data = torch.zeros(25 * 1024 * 1024, device="CUDA") # ~100MB
print("GPU memory after 100MB allocation:", torch.cuda.memory_allocated() / 1024**2, "MB")
print("System memory after GPU allocation:", cgroup_mem(), "MB")
EOF运行这个 Pod 时,你会看到 cgroup 计数器在分配 100MB 系统内存后增加,但在分配 100MB GPU 内存后保持不变;与此同时,torch.cuda.memory_allocated() 却明确表明 GPU 显存已经被消耗。也就是说,GPU 内存确实发生了变化,但内核对此没有可见性。这个问题不仅影响计量,也直接延伸到调度与公平性控制。
GPU 调度发生在内核之外
在 CPU 上,Linux 内核可以在几微秒内抢占进程、保存状态并恢复执行,因此能够在租户之间实施公平共享;而在 GPU 上,核函数通常通过 NVIDIA 驱动启动,一旦执行便会运行到结束,Linux 内核既无法中断它,也无法像 CPU 一样对其实施细粒度时间分片。结果是,当两个租户共享同一块 GPU 时,其中一个可以持续占用显存、提交长时间运行的核函数,从而在另一个租户几乎无法察觉的情况下让后者资源饥饿。适用于 CPU 和系统内存的那套强制执行模型,在这里已不再成立。下面这个 Pod 同时执行 CPU 与 GPU 任务,可以直观看到差异:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: scheduler-demo
spec:
containers:
- name: tasks
image: pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime
command: ["python", "-c"]
args:
- |
import torch, threading, time
def cpu_task():
print("Starting CPU task...")
start = time.time()
sum(i*i for i in range(30_000_000))
print(f"CPU task finished in {time.time() - start:.2f}s")
def gpu_task():
print("Starting GPU task...")
start = time.time()
x = torch.rand(2000, 2000, device="CUDA")
for _ in range(50):
torch.matmul(x, x.T)
torch.cuda.synchronize()
print(f"GPU task finished in {time.time() - start:.2f}s")
t1 = threading.Thread(target=cpu_task)
t2 = threading.Thread(target=gpu_task)
t1.start(); t2.start()
t1.join(); t2.join()
resources:
limits:
cpu: "200m"
memory: "512Mi"
nvidia.com/gpu: 1
restartPolicy: Never
EOF检查日志时,通常会观察到如下现象:
- CPU 任务在内核控制下运行。因为容器被限制为 200m(一个核心的 20%),任务需要几秒钟才能完成。内核完全按配置限制它。
- GPU 任务不到一秒就完成了,不受 CPU 配额或内存限制的影响。
原因并不神秘:GPU 调度发生在另一个几乎独立于 Linux 资源控制平面的世界里。
CUDA 上下文跨越容器
第三个断裂点来自 CUDA 上下文本身的工作方式。CUDA 上下文是驱动为单个进程建立的私有执行环境,其中包含该进程已经分配的显存、已加载的核函数以及执行流。每个使用 CUDA 的进程都会创建自己的上下文,而驱动负责在这些上下文之间切换。当容器请求 nvidia.com/gpu: 1 时,Kubernetes 的实际动作是把整块 GPU 设备挂载到 Pod 中;进入 Pod 之后,CUDA、PyTorch 或 TensorFlow 等框架便直接与 GPU 驱动通信。驱动才是与物理设备交互、创建上下文并管理执行状态的真正组件。
在 Linux 中,安装 NVIDIA 驱动后,GPU 会以 /dev/ 下的设备文件形式暴露出来,其中最关键的入口点之一是 /dev/nvidia0。从内核角度看,它只是一个可被进程打开的文件;而当 PyTorch 或 TensorFlow 开始使用 CUDA 时,它做的事情也不过是像打开普通文件一样获取一个文件描述符。如果两个容器都能访问 /dev/nvidia0,它们就都能建立 CUDA 上下文。之后的显存分配、核函数加载和执行调度,都发生在 NVIDIA 驱动内部。下面这个 Pod 展示了两个容器如何在同一物理设备上分别建立自己的 CUDA 上下文:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: context-demo
spec:
containers:
- name: container-a
image: pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime
command: ["python", "-c"]
args:
- |
import torch, os
print(f"Container A PID: {os.getpid()}")
a = torch.full((1000, 1000), 1.0, device="CUDA")
print(f"Container A allocated {torch.cuda.memory_allocated()} bytes of GPU memory")
- name: container-b
image: pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime
command: ["python", "-c"]
args:
- |
import torch, os
print(f"Container B PID: {os.getpid()}")
b = torch.full((1000, 1000), 2.0, device="CUDA")
print(f"Container B allocated {torch.cuda.memory_allocated()} bytes of GPU memory")
restartPolicy: Never
EOF从驱动视角看,这不过是两个打开了 /dev/nvidia0 的进程,它并不知道,也并不关心它们是否处于不同的容器中。也就是说,容器边界并没有自然延伸到 CUDA 上下文这一层。
Kubernetes 仅在 API 层面强制调度
因此,当你在 Kubernetes 中请求 GPU 时,系统并不是像管理 CPU 那样直接管理底层硬件;它主要做的是调度与记账。对一个 nvidia.com/gpu: 1 的请求而言,实际发生的过程大致如下:
- 调度器将
nvidia.com/gpu视为一个数字。 - 它找到一个公告至少一个可用 GPU 的节点。
- 它使用正常的打分规则将 Pod 分配到该节点。
- 该节点上的 kubelet 接收 Pod 规格。
- kubelet 调用 NVIDIA 设备插件,因为这不是原生资源。
- 插件选择一块 GPU 并返回要挂载的设备文件。
- kubelet 将这些文件挂载到容器中,并将 GPU 标记为已占用。
这里最重要的是注意那些“没有发生”的事情:Kubernetes 从未直接检查 GPU 硬件,也没有真正理解 GPU 的内部状态;对调度器来说,nvidia.com/gpu: 1 与 example.com/device: 1 本质上没有区别。真实的设备选择发生在节点侧,并且由设备插件而不是 Linux 内核完成。Kubernetes 随后做的,是更新自己的内部计数器,以阻止其他 Pod 再来请求同一个逻辑上的 GPU。换句话说,Kubernetes 真正执行的是“一块 GPU 只分配给一个 Pod”这条控制面规则,而不是对物理硬件本身建立不可绕过的执行边界。在硬件层面,GPU 仍然是共享设备;任何能够打开 /dev/nvidia0 的进程,理论上都可以与其交互。控制面规则与硬件实际能力之间的落差,也正是安全和性能问题出现的起点。
实际威胁场景
上述架构缺陷并不是抽象概念,它们会直接演化为传统 Kubernetes 边界无法阻止的安全和可用性问题。下面用三个典型场景说明这一点。第一个场景是最直观的资源饥饿:在共享 GPU 环境中,一个租户很容易压垮另一个租户。假设 tenant-a 先启动了一个稳定的训练工作负载:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: stable-training
namespace: tenant-a
spec:
containers:
- name: training
image: nvidia/cuda:11.0-base
command: ["python3", "-c"]
args:
- |
import time
for epoch in range(100):
print(f"Epoch {epoch+1}/100: loss=0.{234-epoch*2}, memory=2.1GB")
print("Training stable at 45ms per batch")
time.sleep(2)
resources:
limits:
nvidia.com/gpu: 1
EOF训练运行顺利:
$ kubectl logs -f stable-training -n tenant-a
Epoch 1/100: loss=0.234, memory=2.1GB
Training stable at 45ms per batch
Epoch 2/100: loss=0.232, memory=2.1GB
Training stable at 45ms per batch此时训练运行正常,但 tenant-b 随后部署一个显存吞噬者:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: memory-hog
namespace: tenant-b
spec:
containers:
- name: hog
image: nvidia/cuda:11.0-base
command: ["python3", "-c"]
args:
- |
print("Allocating 8GB GPU memory...")
# 实际上,这会分配大量 GPU 数组
print("Allocation complete. Holding memory.")
import time
time.sleep(3600)
resources:
limits:
nvidia.com/gpu: 1
EOF如果这两个 Pod 最终在物理上共享同一块 GPU,那么 tenant-a 的训练进程可能会直接因为显存耗尽而失败:
CUDA out of memory error: tried to allocate 2.10GB
# Training failed.命名空间和 RBAC 都无法阻止这种情况,因为问题根本不发生在它们能够施加约束的层面。更严重的是,这种风险并不只停留在资源争夺上。当 GPU 内存没有在进程退出后被充分清理时,敏感数据甚至可能跨租户泄露。设想一家金融服务公司在 GPU 上处理专有模型与敏感数据:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: financial-model
namespace: tenant-a
spec:
containers:
- name: model
image: pytorch/pytorch
command: ["python3", "-c"]
args:
- |
import torch
import os
# 将敏感数据加载到 GPU
secret_weights = torch.tensor([0.7234, -0.3456, 0.8891], device='CUDA')
customer_ssn = torch.tensor([123456789, 987654321], device='CUDA')
print("Processing sensitive financial data...")
# 模拟崩溃 - 没有清理!
os._exit(139) # Segmentation fault
# 这段代码永远不会运行:
# torch.cuda.empty_cache()
resources:
limits:
nvidia.com/gpu: 1
EOF这个 Pod 因段错误崩溃,没有执行任何显存清理逻辑。随后,另一个租户可能启动一个“数据扫描器”,尝试从未初始化的 GPU 内存中读取残留内容:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: data-scanner
namespace: tenant-b
spec:
containers:
- name: scanner
image: python/pytorch
command: ["python3", "-c"]
args:
- |
import torch
import numpy as np
# 分配内存但不初始化
# torch.empty() 不会将内存清零(不像 torch.zeros())
dirty_memory = torch.empty(1000000, dtype=torch.float32, device='CUDA')
# 检查这些"空"内存中有什么
cpu_copy = dirty_memory.cpu().numpy()
non_zero = cpu_copy[cpu_copy != 0]
if len(non_zero) > 0:
print(f"Found {len(non_zero)} non-zero values in 'empty' memory!")
EOF 扫描器运行在完全不同的命名空间中,但仍可能恢复到前一个租户遗留在显存中的数据。第三个场景则是服务质量问题:长时间运行的核函数或批处理作业,会直接拖垮时间敏感型工作负载。假设有一个批处理作业先占住 GPU:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: batch-processor
namespace: engineering
spec:
containers:
- name: batch
image: nvidia/cuda:11.0-base
command: ["python3", "-c"]
args:
- |
import time
print("Starting 60-minute matrix computation...")
for i in range(60):
print(f"Progress: {i+1}/60 minutes completed")
time.sleep(60)
resources:
limits:
nvidia.com/gpu: 1
EOF随后,一个需要低延迟响应的实时推理服务尝试启动:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: realtime-inference
namespace: marketing
spec:
containers:
- name: inference
image: nvidia/cuda:11.0-base
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 1
EOF
$ kubectl get pods -A | grep -E "batch|realtime"
engineering batch-processor 1/1 Running 0 10m
marketing realtime-inference 0/1 Pending 0 5m结果是,推理服务可能整整一小时都处于 Pending 状态。对于需要 SLA 保证的系统而言,这种行为意味着既无法承诺启动时延,也无法承诺吞吐稳定性。资源隔离失败在这里不再只是“公平性变差”,而是直接演变为业务层面的不可用。
GPU 共享选项:寻找合适的平衡
既然问题无法靠传统 Kubernetes 隔离机制自然解决,那么接下来的关键问题就是:应当如何共享 GPU,以及在什么条件下共享才是可接受的。NVIDIA 提供了几种常见方案,但它们本质上都在利用率、隔离性和复杂度之间做不同权衡。最直接的一种方式是多进程服务(MPS)。它在 Kubernetes 中几乎不需要额外资源模型,只要在 GPU 节点上启用,多个进程就可以同时使用同一块 GPU。
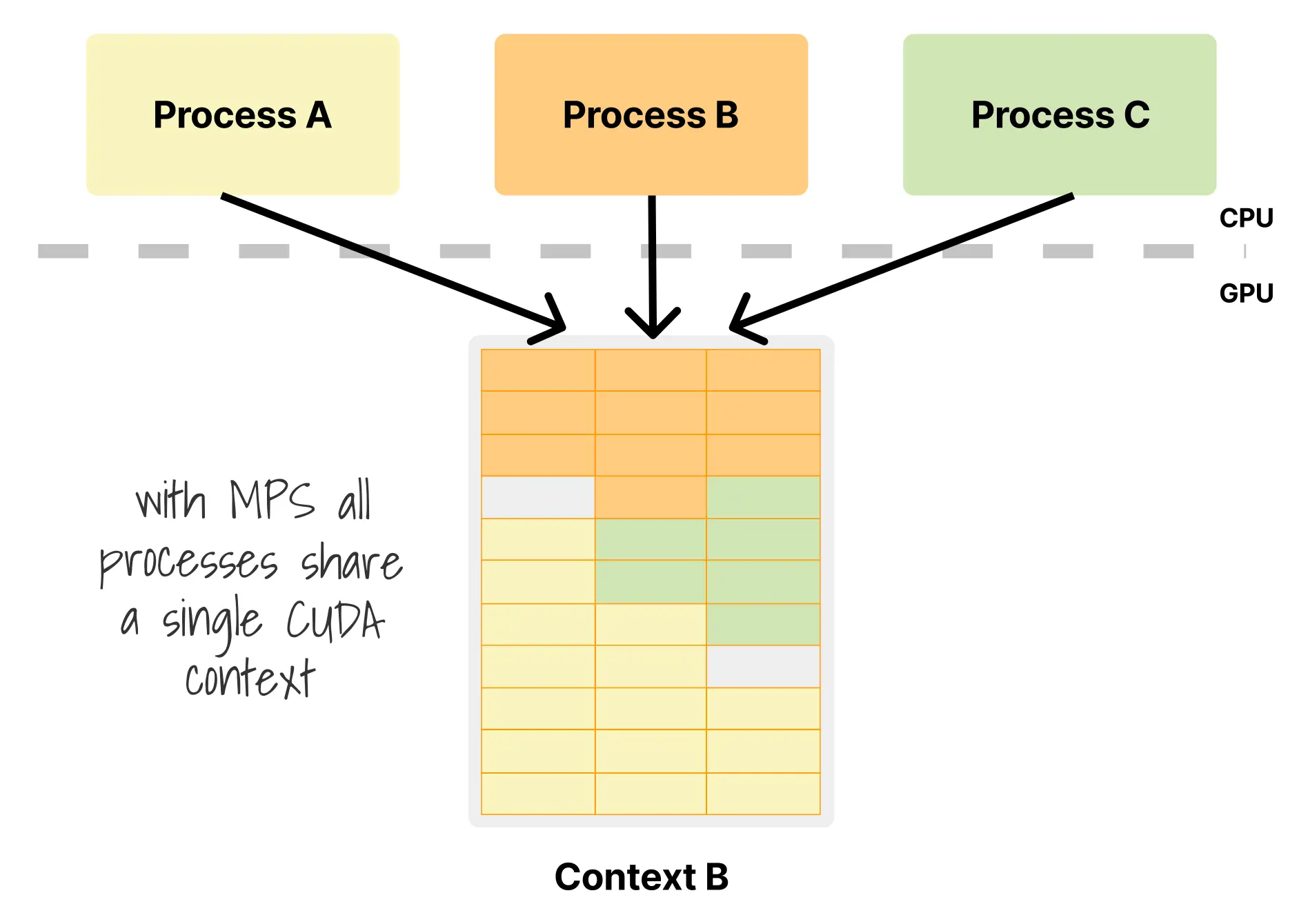
MPS 的核心思路是让多个进程共享同一个 CUDA 上下文。通常情况下,每个 CUDA 进程都会创建自己的上下文,其中包含私有的显存分配、已加载的核函数和执行状态;驱动必须像操作系统切换进程那样,在这些上下文之间不断切换,而每一次切换都会带来额外开销。MPS 通过引入一个共享的 MPS 服务器进程,把多个进程提交的工作收敛到同一个上下文中,从而基本消除了这部分切换成本,因此经常带来明显的性能收益:
# 不使用 MPS - 高方差,因上下文切换而较慢
App1 Average: 0.0847s
App1 StdDev: 0.0234s # 上下文切换导致的高方差
App2 Average: 0.0891s
App2 StdDev: 0.0267s # 同样高方差当你启用 MPS 时,性能显著提升:
# 启用 MPS
$ nvidia-smi -c EXCLUSIVE_PROCESS
$ nvidia-cuda-mps-control -d# 使用 MPS - 稳定,更快
App1 Average: 0.0623s # 快 26%
App1 StdDev: 0.0031s # 方差减少 87%
App2 Average: 0.0629s # 快 29%
App2 StdDev: 0.0028s # 方差减少 90%不过,性能收益并不意味着 MPS 适合多租户环境。它的第一个问题是缺乏内存跟踪与强制执行能力:多个进程共享同一个上下文时,所有显存都来自同一个池,系统无法精确回答“是谁用了多少”。如果进程 A 已经分配了 8GB,而进程 B 又试图在一块 16GB GPU 上分配 10GB,进程 B 只会收到 OOM 错误,却无法明确指出进程 A 就是原因。第二个问题是可观测性差。nvidia-smi 等工具看到的往往只是聚合后的 GPU 使用情况,而不是每个进程的清晰明细,这让调试和容量规划都变得非常困难。第三个问题也是最关键的:所有进程处于同一内存空间语义之下,安全边界极其薄弱。例如:
# 一个恶意行为者影响所有人
$ kubectl logs memory-corruption-test
Process A: Running normally...
Process B: Corrupting shared memory...
Process A: Segmentation fault
Process B: Segmentation fault
MPS Server: Fatal error, restarting...一个进程的崩溃或内存损坏,可能连带影响同一块 GPU 上的所有其他进程。因此,MPS 更适合同一团队内部的可信工作负载,在这种场景下,性能和吞吐往往比隔离更重要;但如果你至少希望 Kubernetes 能够在一定程度上记录“哪些 Pod 正在使用 GPU”,那么就需要另一种机制,即时间分片。
时间分片:GPU 数量倍增
时间分片是共享 GPU 时更进一步的一种做法。与 MPS 让多个进程共享同一个上下文不同,时间分片的目标是让一块物理 GPU 在 Kubernetes 中表现为多个逻辑 GPU,从而允许多个 Pod 被同时调度上来。
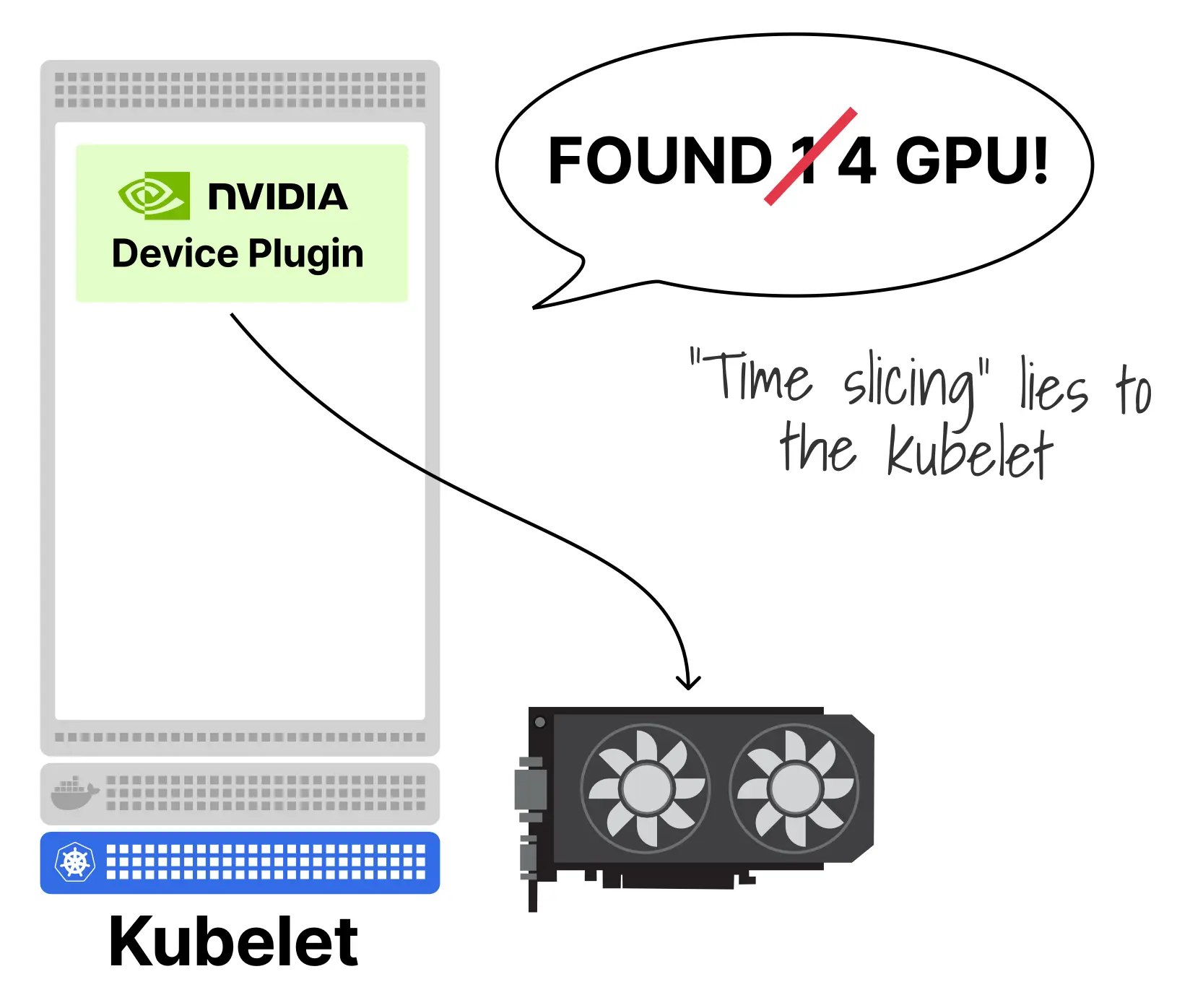
做法是在 NVIDIA 设备插件中配置多个副本:
apiVersion: v1
kind: ConfigMap
metadata:
name: nvidia-device-plugin-config
data:
config.yaml: |
version: v1
sharing:
timeSlicing:
replicas: 4 # 一块 GPU 变成四块应用此配置后:
$ kubectl describe node minikube | grep nvidia.com/gpu
nvidia.com/gpu: 4
nvidia.com/gpu: 4这样,一块 Tesla T4 在 Kubernetes 看起来就像四块可调度的 GPU,因而可以让多个 Pod 同时进入 Running 状态:
$ kubectl get pods
NAME READY STATUS GPU-REQUEST
workload-1 1/1 Running nvidia.com/gpu: 1
workload-2 1/1 Running nvidia.com/gpu: 1
workload-3 1/1 Running nvidia.com/gpu: 1
workload-4 1/1 Running nvidia.com/gpu: 1在这种模式下,每个 Pod 都拥有自己的 CUDA 上下文,而 GPU 驱动则负责在这些上下文之间轮流切换。这里最关键的一点是:这些上下文属于仍在运行的进程,它们在 Kubernetes 里会同时处于 Running 状态。也就是说,当 workload-1 启动后,它会建立自己的 CUDA 上下文并可能分配大量显存;workload-2 随后启动时,也会创建自己的上下文。虽然任意时刻通常只有一个上下文真正占用 GPU 执行,但多个 Pod 却是同时活着、同时持有状态和显存的。
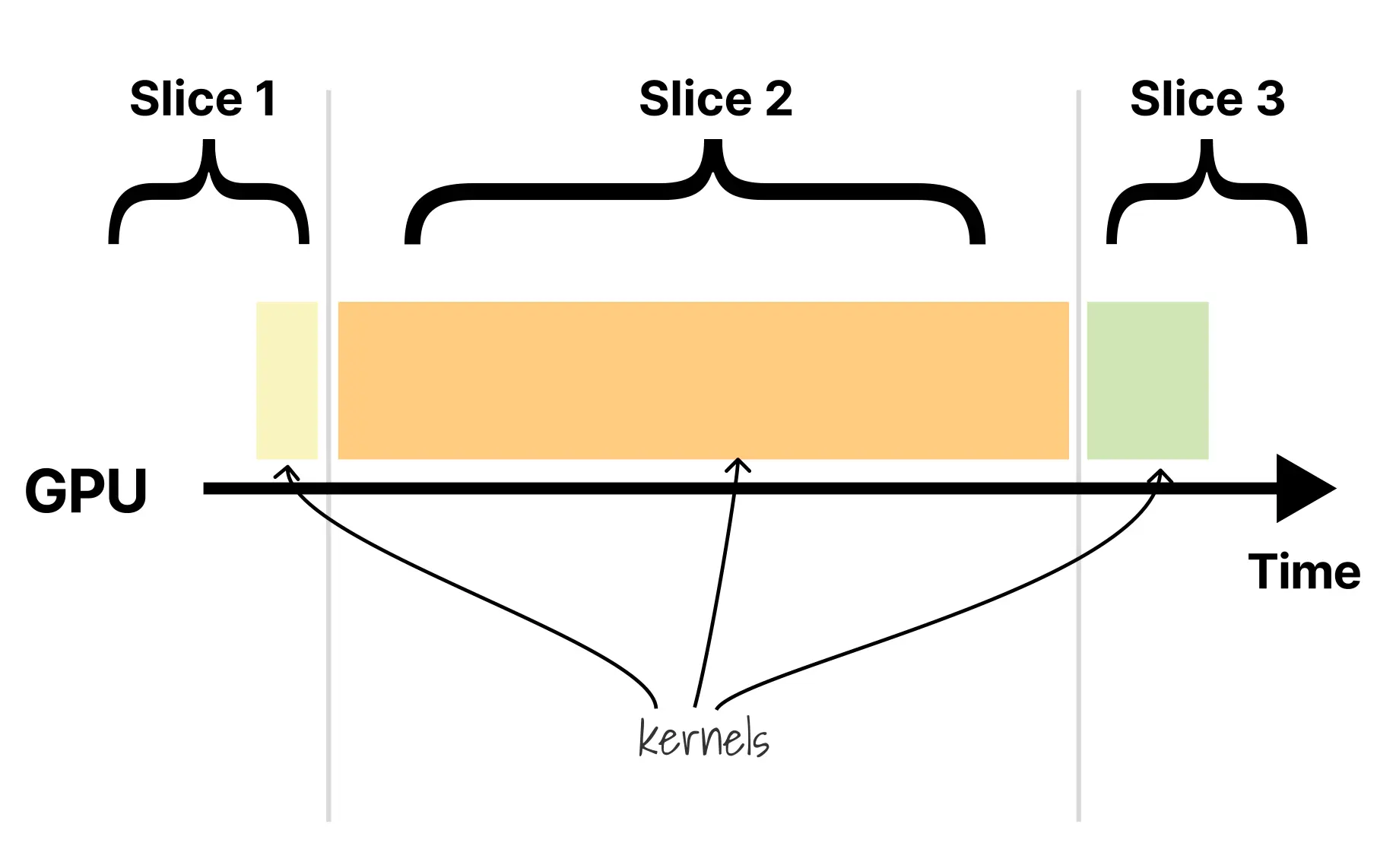
GPU 驱动通过时间分片给每个上下文轮流执行核函数的机会,但上下文本身并不会随着时间片结束而消失,因为对应进程仍然存活。
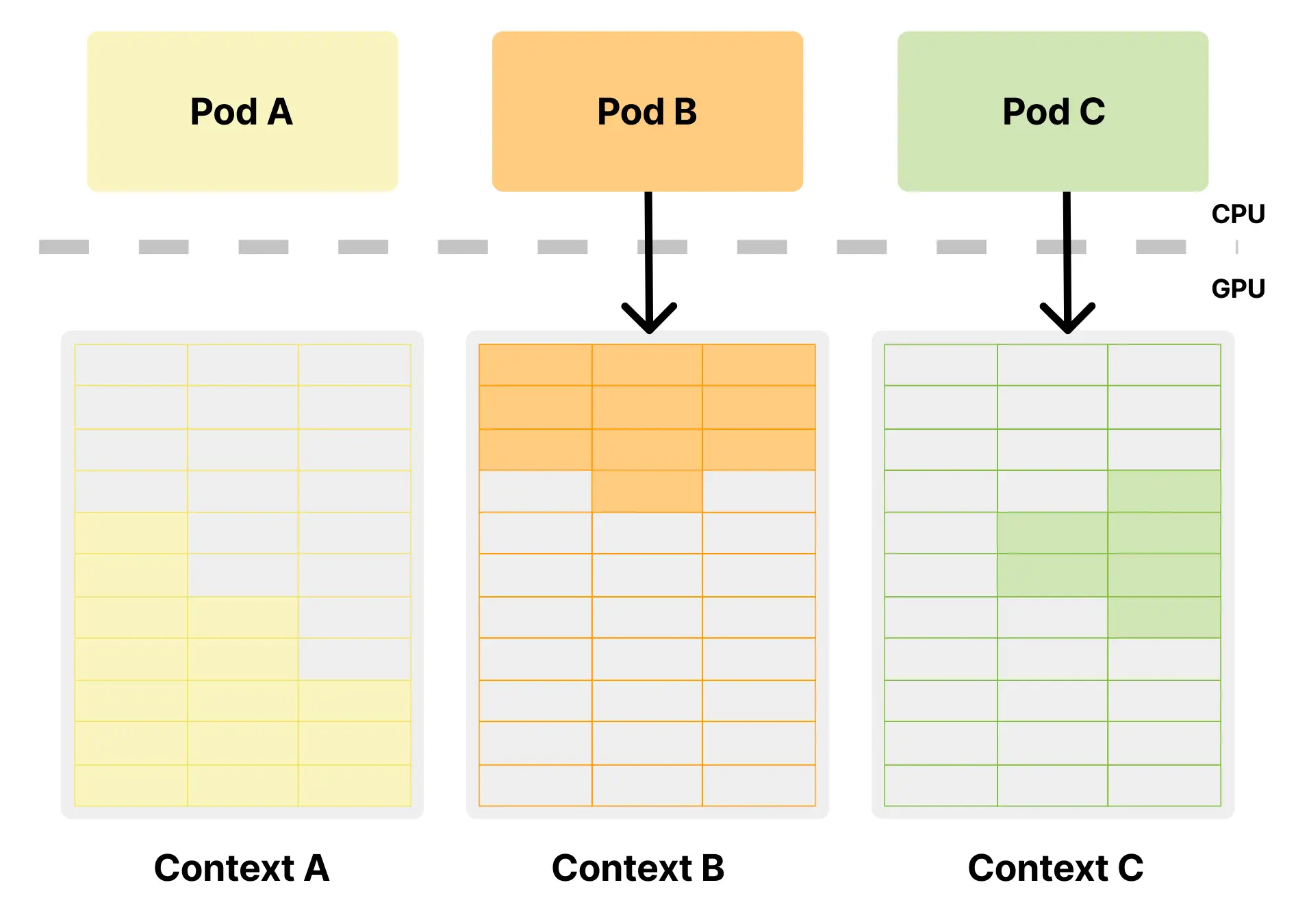
当轮到上下文 B 执行时,上下文 A 不是被卸载,而只是暂停;它已经分配的显存依然保留,因为对应进程预期下一次获得时间片时还能继续使用这些数据。与 MPS 相比,时间分片的关键改进在于上下文彼此分离:上下文 A 分配的内存不会被上下文 B 直接读取或写入,因此至少建立了一个基础的数据隔离边界。但这种隔离并不意味着资源互不影响,因为多个上下文仍然竞争同一个物理显存池。如果 workload-1 已经为模型分配了 12GB 显存,那么只要它还活着,这 12GB 就会一直被占用,剩下的工作负载只能共享其余 4GB,并可能因此失败。
MIG:硬件分区
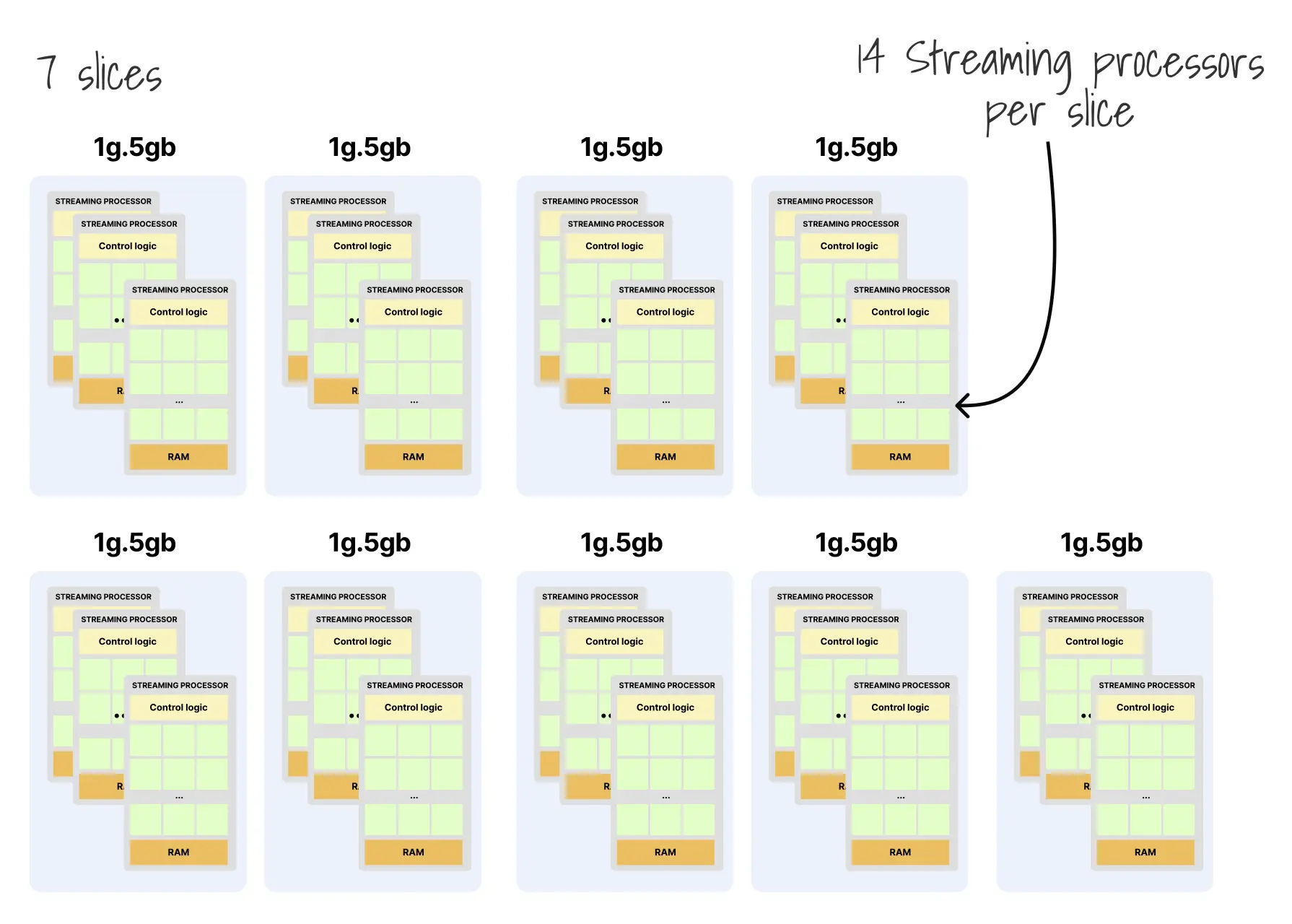
多实例 GPU(MIG)提供的是更强的硬件级隔离,不过它只适用于 A100 和 H100 这类支持 MIG 的 GPU。MIG 的核心做法不是在软件层轮转时间片,而是直接把一块 GPU 物理切成多个彼此隔离的实例:
# 在 A100 上:
$ nvidia-smi mig -cgi 1g.5gb,2g.10gb,3g.20gb
$ nvidia-smi -L
GPU 0: NVIDIA A100-SXM4-40GB (UUID: GPU-0DCF3380)
MIG 3g.20gb Device 0: (UUID: MIG-fb9af708)
MIG 2g.10gb Device 1: (UUID: MIG-a0d4e8e4)
MIG 1g.5gb Device 2: (UUID: MIG-52a84557)每个 MIG 实例都具有自己独占的一组资源:
- 专用的计算单元(SM)
- 隔离的内存(5GB、10GB 或 20GB)
- 独立的内存带宽
- 独立的故障域
在 Kubernetes 中,这些实例会被视为不同类型的 GPU 资源:
$ kubectl describe node | grep nvidia.com/mig
nvidia.com/mig-1g.5gb: 1
nvidia.com/mig-2g.10gb: 1
nvidia.com/mig-3g.20gb: 1Pod 请求特定的切片:
resources:
limits:
nvidia.com/mig-2g.10gb: 1MIG 的优势在于它提供了真正的硬件边界:一个切片既不能访问另一个切片的显存,也不能直接干扰其计算资源。不过,它的代价也同样明确:你必须拥有支持 MIG 的 A100/H100 级别硬件,而且单卡切片数量上限有限,通常最多只有七个实例。
vGPU:企业级方案
虚拟 GPU(vGPU)则把共享进一步提升到虚拟机监控器层面,试图提供与传统虚拟化环境相近的隔离保证。不同于 MPS 在进程层共享、时间分片在调度层共享,vGPU 的基本思路是为每个租户提供一个虚拟机,而每个虚拟机都“以为”自己拥有一块专用 GPU;真正的时间与内存分配,则由虚拟机监控器根据预设配置文件完成。
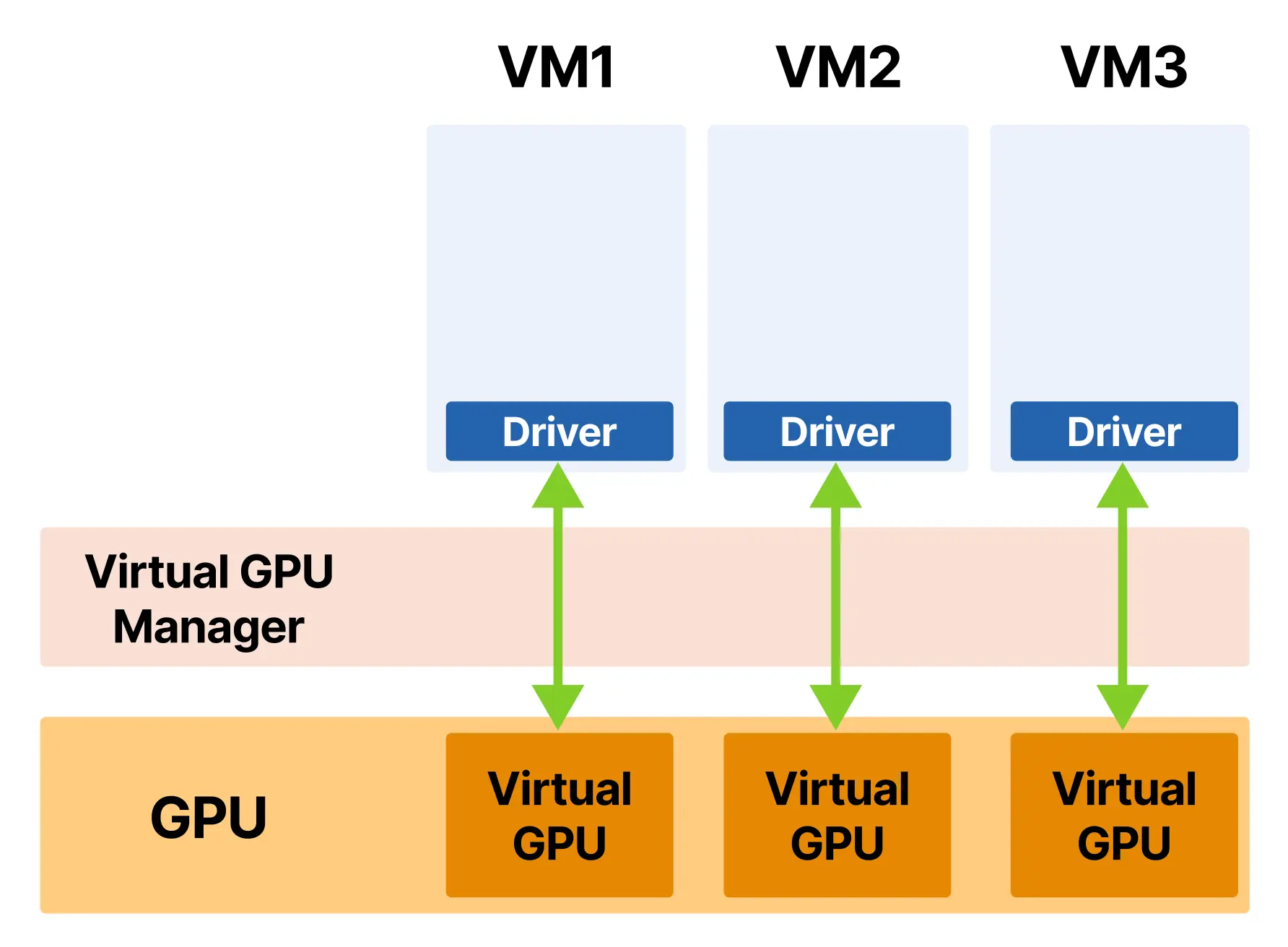
这种方案的代价是显著的基础设施投入。你需要 NVIDIA vGPU 软件许可证,它通常按 GPU 每年收费,成本可能接近硬件本身;你还需要受支持并带有相应补丁的虚拟机监控器,例如 VMware vSphere、Citrix XenServer 或 KVM。此外,并非所有 GPU 都支持 vGPU,通常需要 A40、A100 等数据中心级产品。
一旦部署完成,每个虚拟机看到的都是一块具有固定显存容量的标准 NVIDIA 设备。应用程序可以在其中安装驱动、运行 CUDA 程序、使用 nvidia-smi 等工具,而不必知道自己实际运行在共享硬件上。虚拟机监控器会在虚拟机之间强制执行严格边界:如果某个虚拟机试图分配超过配额的 GPU 内存,它会收到 OOM 错误;如果某个虚拟机内部的 GPU 驱动崩溃,其他虚拟机仍可继续运行。这种隔离是在操作系统之下执行的,因此比容器级共享更强。vGPU 还启用了许多裸金属 GPU 难以提供的运维能力:
- 你可以在主机之间实时迁移虚拟机而不中断 GPU 工作负载
- 你可以快照 GPU 状态用于备份和恢复
- 你可以根据工作负载需求动态调整 GPU 配置文件。
对于运行关键业务负载的企业而言,这些运维收益往往可以抵消复杂性带来的负担;但这种隔离并非没有代价。虚拟机监控器会引入额外开销,与裸金属相比通常会损失 20% 到 30% 的性能;许可证模型本身也较为复杂,不同用途可能对应不同许可证。再加上共享存储、vCenter 或同类管理工具,以及熟悉虚拟化与 GPU 技术的运维团队,vGPU 更像是一套企业级平台方案,而不是轻量级共享技巧。
信任层级:选择你的策略
GPU 共享只有在信任边界被明确识别之后,才可能设计得合理。原则很简单:信任越弱,隔离就必须越强。如果所有用户都属于同一团队,目标一致,能够通过人工方式协调资源,那么时间分片或 MPS 通常已经足够;在这种高信任环境中,人们往往愿意容忍偶发干扰,以换取更高利用率。相反,如果集群服务的是不同部门,且它们有彼此竞争的优先级,那么没有硬件边界时,意外干扰就很容易发生,这类场景往往更适合 MIG 或专用 GPU。再往下,如果面对的是需要明确 SLA 的付费客户,那么虚拟机级隔离甚至专用节点才更接近合理选择,因为客户预期的是可保证的资源与完整的隔离。对于受监管行业或带有对抗性质的工作负载,最保守也往往最现实的答案,是根本不共享:每个租户使用专用物理 GPU,从根源上避免交叉污染。
比较所有方案
以上几种机制的差异,可以用下表概括:
| 方案 | 隔离性 | 性能 | 复杂度 | 硬件要求 |
|---|---|---|---|---|
| MPS | 无 | 优秀 | 低 | 任何 GPU |
| 时间分片 | 无 | 良好 | 低 | 任何 GPU |
| MIG | 硬件级 | 良好 | 中 | 仅 A100/H100 |
| vGPU | 虚拟机级 | 一般(70-80%) | 高 | 许可证 + 特定 GPU |
| 专用 | 完全 | 完美 | 低 | 任何 GPU |
关键要点
- GPU 多租户困难的根源,不是 Kubernetes 缺少资源对象,而是 GPU 资源管理本身不服从内核主导的控制模型。
- 对 CPU 和系统内存有效的命名空间、cgroups 和 RBAC,在 GPU 上都失去了关键前提:内核既看不全状态,也无法细粒度强制执行。
- 没有 GPU cgroups、没有可靠的内核级可见性、没有细粒度可抢占执行,意味着很多控制权实际落在驱动和厂商运行时内部。
- 因而 GPU 共享从来不只是一个技术选型问题,而是一个由信任模型驱动的架构问题:信任越低,越需要硬件边界或更强隔离。
- 时间分片、MPS、MIG、vGPU 和专用 GPU 都只是不同约束下的折中方案,没有任何一种机制可以脱离信任等级、成本和性能目标单独成立。