基础:GPU 如何与 Kubernetes 结合
本章将讨论以下几个问题:
- 容器如何通过系统调用、cgroups 和命名空间工作
- 为什么 GPU 打破了容器资源隔离中的若干基本假设
- 设备插件如何将 GPU 接入 Kubernetes
- 整数资源问题及其影响
理解这些问题,需要先回到 Linux 内核提供容器隔离能力的基本机制。
系统调用:内核的 API 接口
在 Linux 中,用户空间应用程序无法直接与硬件交互,所有访问都必须经过 Linux 内核,而系统调用就是这条路径上唯一合法的入口。系统调用本质上是内核对外暴露的一组预定义接口:应用程序请求文件、网络、进程或内存服务时,最终都要通过这些入口点进入内核。例如,当 Java 应用访问文件系统中的文件时,它实际发起的就是一次系统调用。
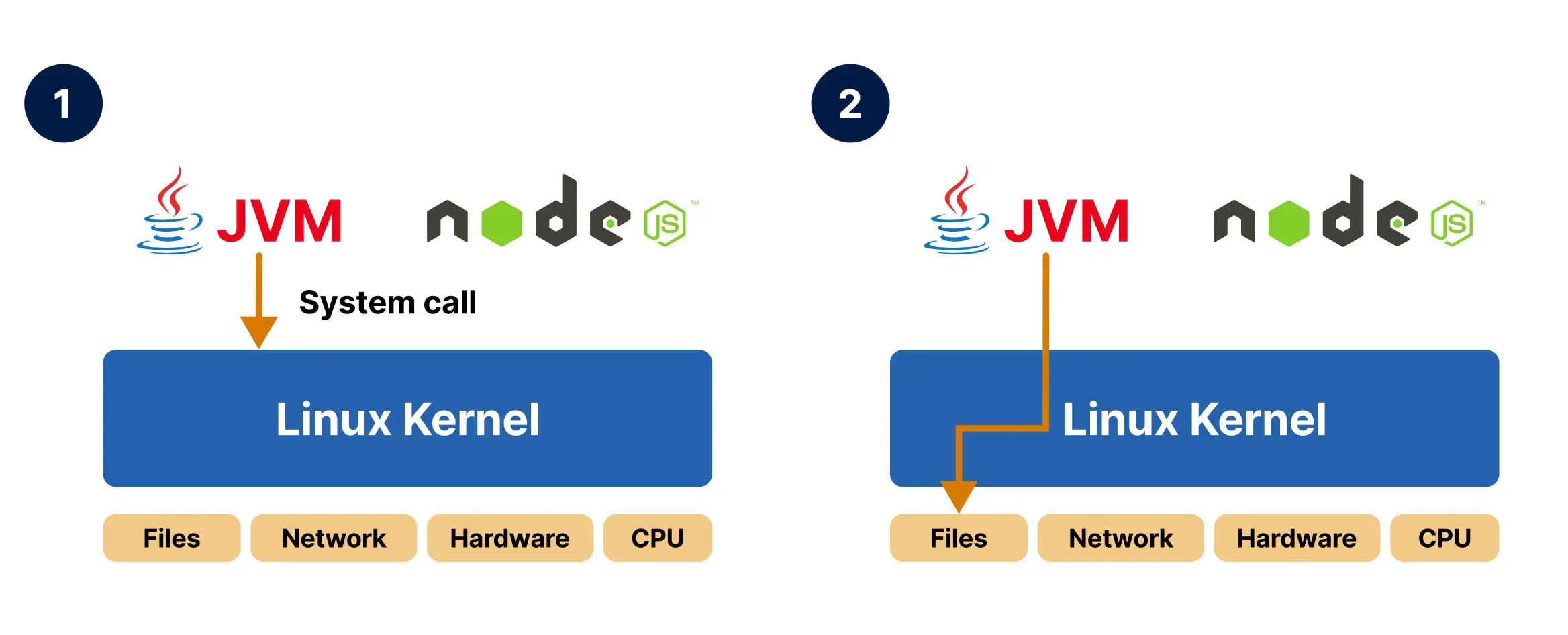
- 内核作为应用程序和硬件之间的中介。当你的 Java 应用程序访问文件系统上的文件时,它向 Linux 内核发起一个系统调用。
- 内核知道如何访问底层存储,并让你的应用程序检索文件。你可以把系统调用看作 API 调用。
同样,Node.js 应用要发起网络连接,也必须通过系统调用进入内核,由内核代表它访问网络硬件。无论语言和运行时如何变化,真正与硬件交互的始终是内核,而不是用户空间中的应用代码。
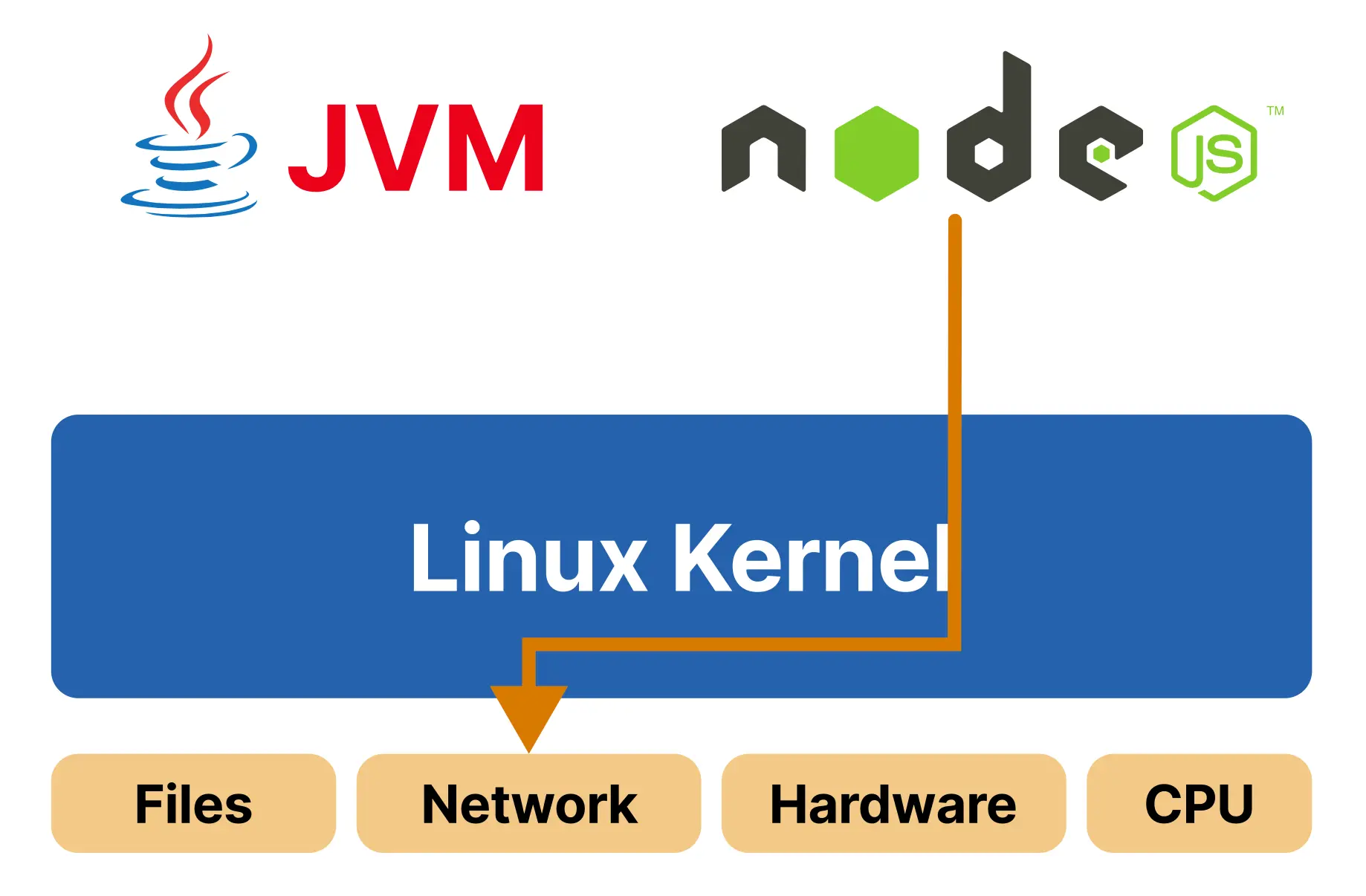
从抽象上看,系统调用可以视为 Linux 内核的 API:它包含 300 多个按功能分组的入口点,有的用于文件操作,有的用于进程管理,也有的处理网络和内存。每个系统调用都有唯一的编号和明确的参数约定,因此即使是高级语言中的简单操作,例如 Node.js 里的一次网络请求,底层也会落到具体的 socket 系统调用上。正因为用户空间可以借助系统调用触达如此广泛的内核能力,系统调用既是功能入口,也是攻击面来源;尤其当操作涉及特权能力时,内核必须进一步约束应用能够消耗和影响的资源范围,这就引出了控制组,即 cgroups。
控制组(cgroups):强制执行资源限制
控制组是内核级机制,用于限制单个进程或一组进程可以消耗的 CPU、内存、I/O 等资源。假设一台机器上同时运行一个 JVM 应用和一个 Node.js 应用,你可以把它们分别放入不同的 cgroup 中,并为前者设置 256MB 内存上限和单核 CPU 配额,为后者设置另一组独立约束。每个 cgroup 都对应一个明确的资源边界,而边界的执行由内核负责。
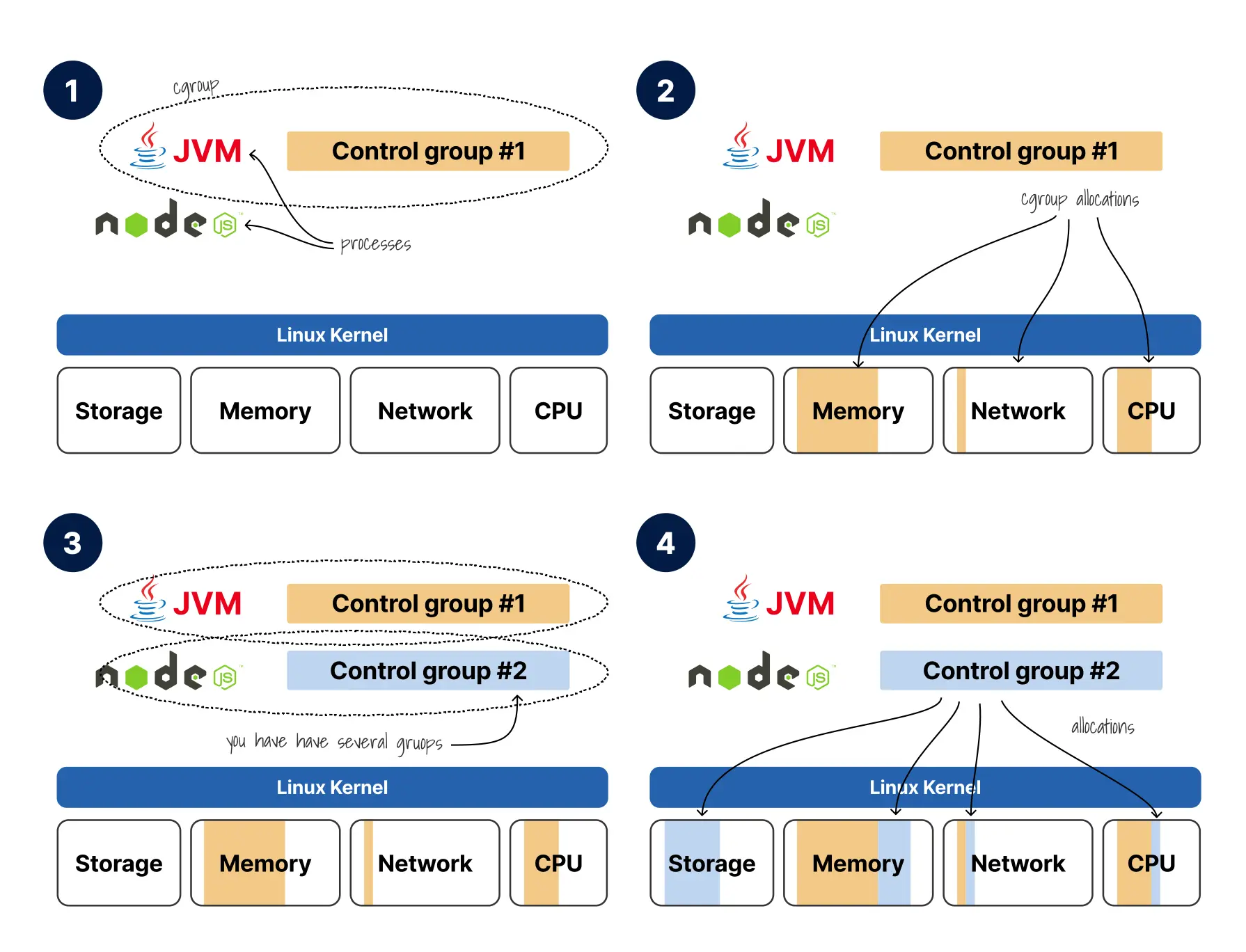
- 在这个例子中,我为 JVM 创建了一个控制组。
- 我可以创建一个控制组,限制对 CPU、内存、网络带宽等的访问。
- 每个进程都可以有自己的控制组。我可以为 Node.js 应用创建第二个控制组。
- 我可以微调新控制组的设置,进一步限制该进程可用的资源。
这意味着资源限制不是建议值,而是物理上被强制执行的边界。下面的配置展示了 cgroups 如何限制 CPU 与内存:
# CPU 限制 - 一个核心的 50%
$ echo 50000 > /sys/fs/cgroup/cpu/myapp/cpu.cfs_quota_us
$ echo 100000 > /sys/fs/cgroup/cpu/myapp/cpu.cfs_period_us
# 内存限制 - 256MB
$ echo 268435456 > /sys/fs/cgroup/memory/myapp/memory_limit_in_bytes借助这些限制,工作负载可以在资源层面被硬性隔离。不过,cgroups 解决的是“能用多少”的问题,而不是“能看到什么、能接触什么”的问题;后者依赖的则是另一类内核原语,即命名空间。
命名空间:隔离进程的可见性
cgroups 控制进程可以消耗多少资源,命名空间则控制进程能看到什么。命名空间决定了一个进程认为自己处于系统中的哪个位置。例如,在网络命名空间下,进程只能看到自己的网络接口和流量,看不到命名空间之外的套接字或数据包;在挂载命名空间下,进程看到的是一个私有文件系统视图,它可能以为自己访问的是 /etc、/var 和 /home,但实际接触到的只是容器专属的 overlay 文件系统。
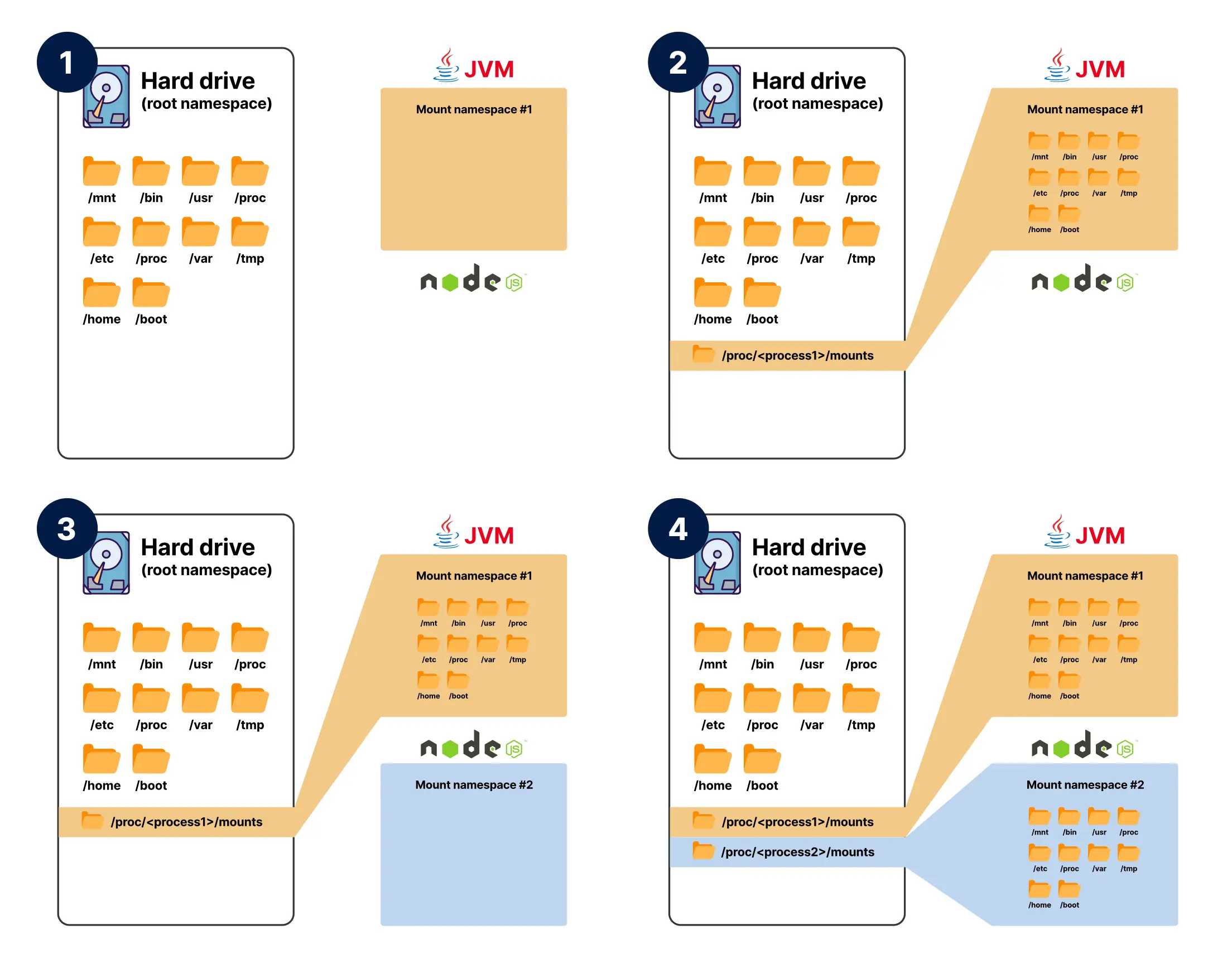
- 自内核版本 5.6 起,有八种命名空间,挂载命名空间(mount namespace)就是其中之一。
- 通过挂载命名空间,你可以让进程以为自己可以访问主机上的所有目录,但实际上并非如此。
- 挂载命名空间用于隔离资源——在这个例子中是文件系统。
- 每个进程可以看到相同的文件系统,但仍然与其他进程相互隔离。
从 Linux 内核 5.6 开始,系统一共有八类命名空间,每一类隔离系统标识的一个维度。这样一来,同一台机器上的多个进程既可以拥有各自的资源限制,也可以拥有各自的系统视图,并在主观上“以为”自己独占整台机器。cgroups 与命名空间共同构成了容器隔离的基础,只是手工配置这些原语既繁琐又容易出错,这也是 Docker 等工具存在的原因。
从内核原语到 Docker
Docker 提供了一种更适合开发者使用的容器管理方式:你不必手工编排系统调用、cgroups 和命名空间,只需定义镜像并启动容器,运行时便会在后台完成隔离环境的建立。当然,Docker 并不是唯一选择,Podman 和 CRI-O 等工具也在抽象这些内核能力。无论具体实现如何变化,这些平台的本质都是构建在系统调用、控制组和命名空间之上的编排层,而这些内核原语共同构成了容器轻量、隔离且安全的运行环境。在进入 GPU 主题之前,还需要先回顾内核如何管理 CPU 和内存,因为后文的对比正建立在这一点上。
CPU 抢占式多任务处理
Linux 内核通过抢占式多任务处理来管理 CPU 调度。它快速中断正在运行的程序,以公平地分配执行时间并保持系统的响应性。
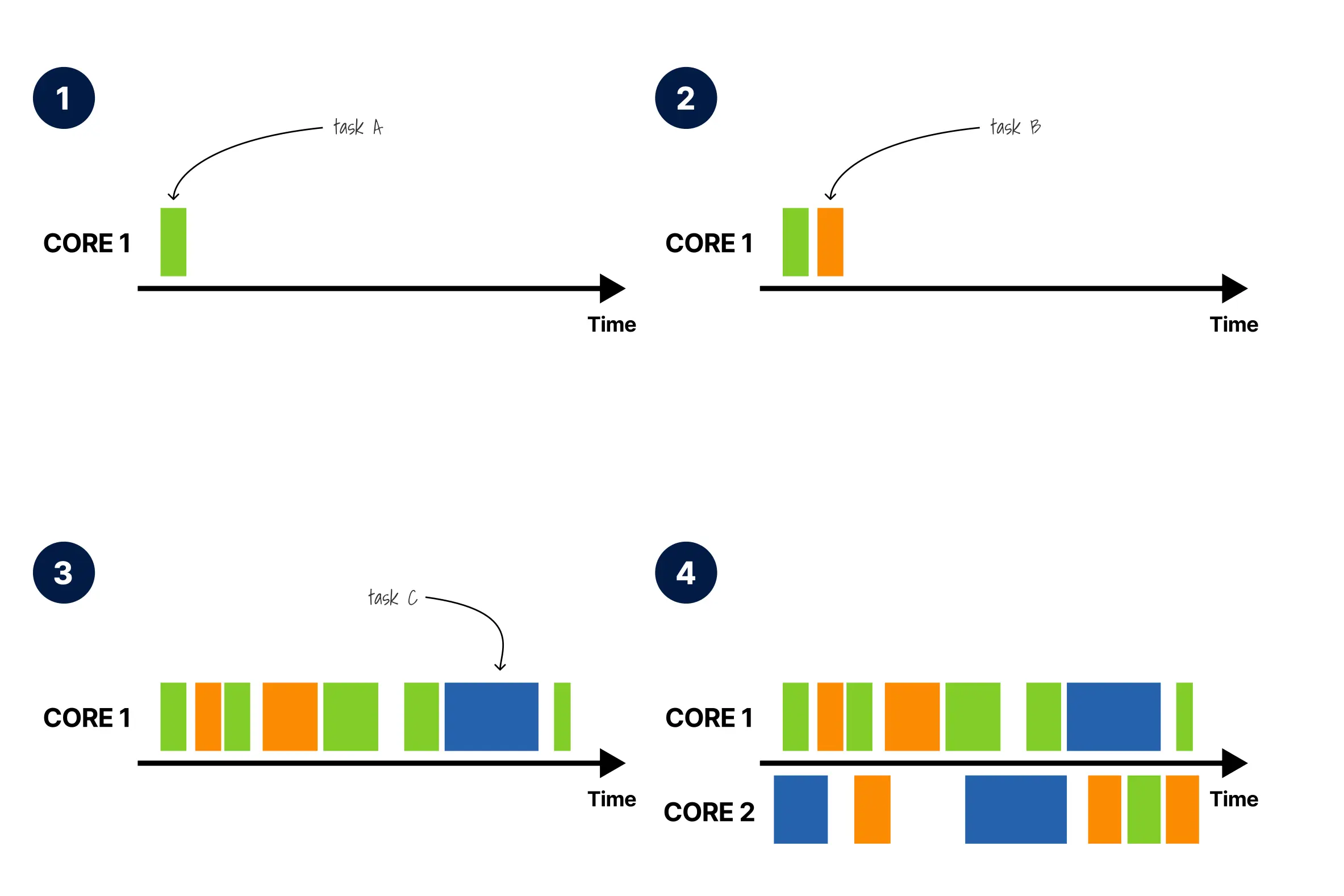
- 在单核抢占式多任务处理中,CPU 一次执行一个任务。
- 调度器抢占任务 A 并切换上下文到任务 B(橙色)。每个任务获得一个 CPU 时间片。
- 随着更多任务的加入,调度器继续在它们之间轮转。任务 C(蓝色)现在加入了队列。
- 有了多核处理器,真正的并行执行成为可能。任务可以在不同的核心上同时运行。
当内核在任务之间切换时,会进行一次上下文切换:
- 它保存正在运行的程序的完整状态,包括其寄存器、栈和内存映射,以便稍后可以从上次中断的地方精确恢复。
- 然后,它加载下一个程序的已保存状态,并恢复执行,就像它从未暂停过一样。
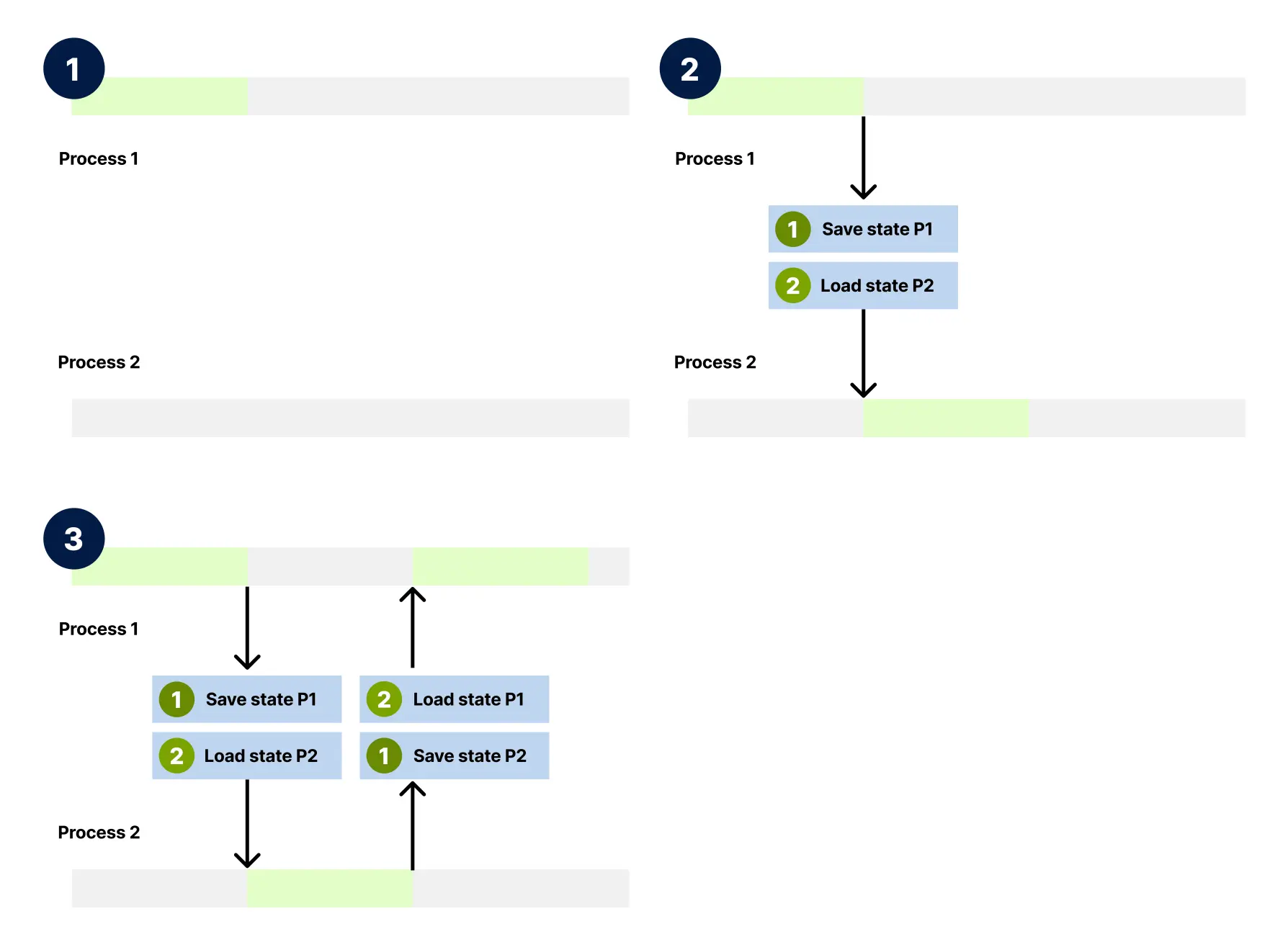
- 进程 1(上方)正在主动执行,而进程 2(下方)处于空闲状态,等待轮到自己执行。
- 进程 1 保存其当前状态(步骤 1),然后进程 2 加载其之前保存的状态(步骤 2)以恢复执行。
- 进程 2 先保存其状态(步骤 1),然后进程 1 加载其保存的状态(步骤 2)以从上次中断的地方继续。
这套机制在 CPU 上既快速又可靠,因为 CPU 的硬件结构就是围绕可中断、可恢复、可调度而设计的。典型的支持能力包括:
- 中断控制器来暂停执行
- 用于保存/恢复状态的硬件支持
- 用于调度的复杂控制逻辑
- 用于加速切换的精密缓存
正因如此,现代 CPU 上的上下文切换通常只需几微秒,足以让多个进程表现出近似同时运行的效果。
内存:按页分配
内存分配则通过内核与内存管理单元(MMU)协同完成。当进程请求一段内存时:
void *ptr = malloc(1024); // 请求 1KB
Linux 内核会执行如下步骤:
- 在物理内存中找到空闲页
- 将它们映射到进程的虚拟地址空间
- 返回一个指向虚拟地址的指针
- 在页表中跟踪每一次分配
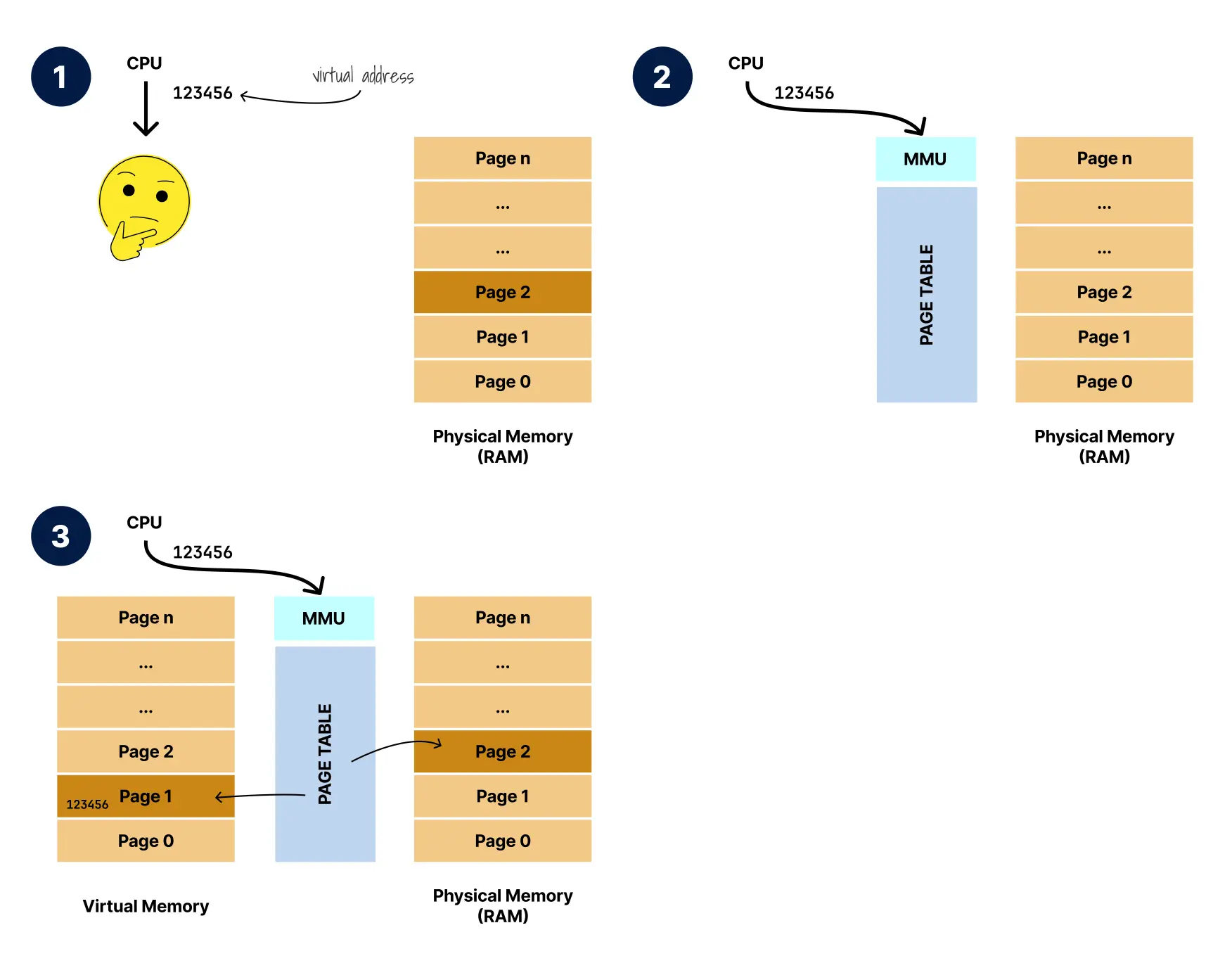
- CPU 尝试访问虚拟地址 123456,但如果没有 MMU,它不知道如何在物理内存中定位数据。
- CPU 将虚拟地址 123456 发送到 MMU,MMU 包含用于地址转换的页表。
- MMU 使用页表成功将虚拟地址 123456 转换为物理地址。
对进程而言,它拿到的是一段连续的虚拟内存;在物理 RAM 中,这些页却可能是离散分布的。内核跟踪每一页的映射关系,负责回收未使用页面、换出到磁盘,并借助 cgroups 强制执行内存限制。如果某个进程超过了自己的内存 cgroup 配额:
echo 104857600 > /sys/fs/cgroup/memory/myapp/memory.limit_in_bytes # 100MB 限制内核的 OOM killer 会立即终止该进程。到这里为止,我们实际上回顾了容器所依赖的那套经典内核控制模型:
- 系统调用提供了对内核功能的受控访问
- cgroups 在内核的支持下强制执行硬性资源限制
- 命名空间为进程可见的内容创建了隔离边界
- CPU 上下文切换在微秒级别完成,实现了公平的时间共享
- 内存按页分配,具有完整的内核可见性和控制能力
这套模型之所以有效,是因为 Linux 内核既看得见,也管得住,还能在资源越界时直接强制执行限制。问题在于,GPU 的工作方式并不遵循这套假设,而后续所有困难几乎都源于这一差异。
CUDA 基础:理解上下文、核函数和内存
GPU 应用并不是一开始就运行在 GPU 上;它首先仍是普通的 CPU 进程,只是在需要执行大规模并行计算时,才通过 CUDA 与 GPU 通信。而这类通信需要管理一整套状态信息:
- 使用哪块 GPU(如果有多块的话)
- GPU 上的内存分配
- 已编译的 GPU 代码(核函数)
- CPU 与 GPU 之间的同步
- 配置和设置
这些状态被 CUDA 打包为“上下文”。一个进程想要使用 GPU 时,首先要创建自己的 CUDA 上下文;这个上下文可以理解为进程与 GPU 之间建立的一次会话,其中包含:
- 该进程特有的内存分配
- 已加载的核函数代码(GPU 程序)
- GPU 状态(配置、设置)
- 执行流和事件
GPU 只能处理已经位于其设备内存中的数据,因此数据必须显式地从主机内存复制到与该上下文关联的 GPU 内存中;这一点与 CPU 直接访问系统内存的习惯完全不同。
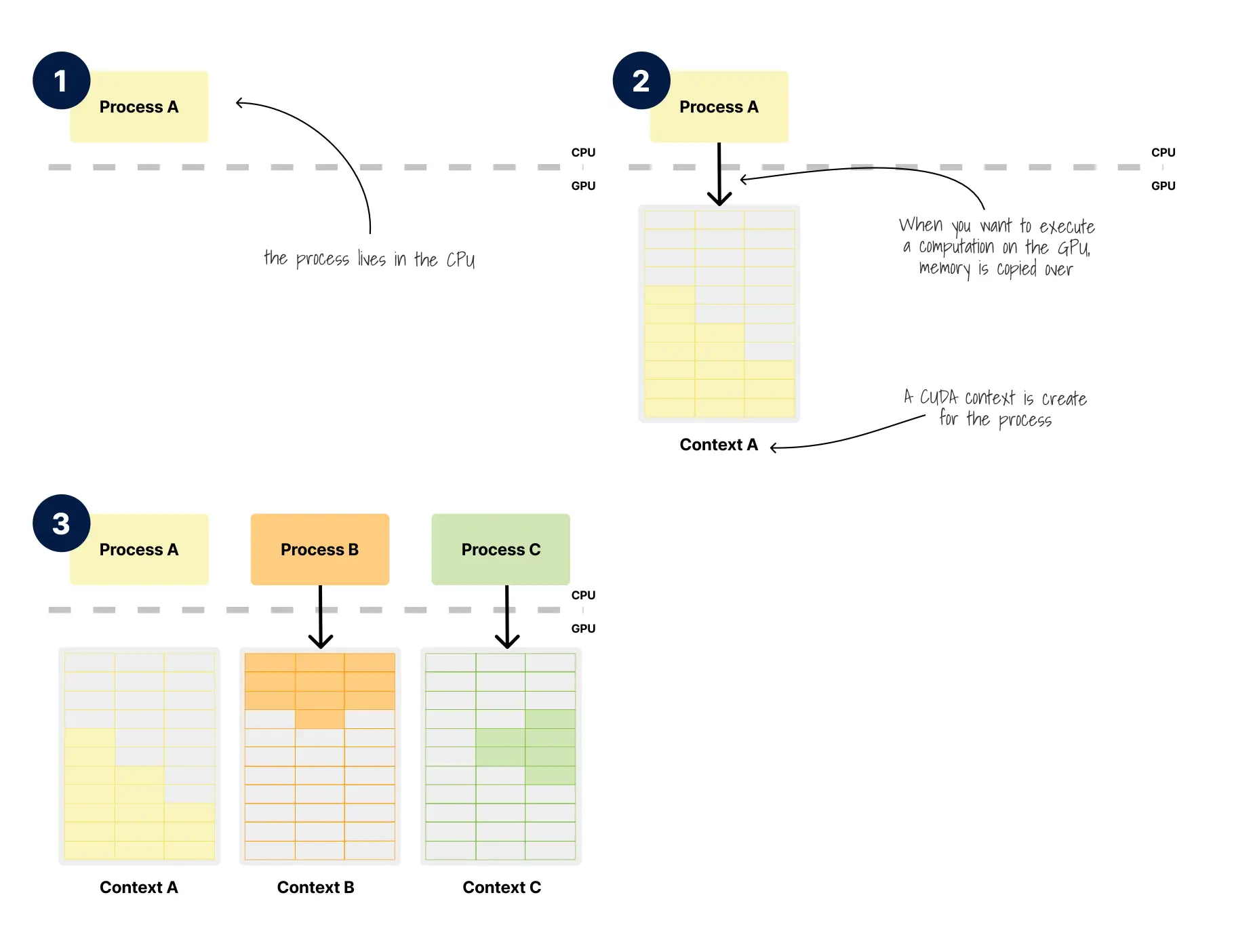
- 在 CPU 上运行的进程 A 需要在 GPU 上执行计算。进程存在于 CPU 域中,但需要 GPU 资源进行并行处理。
- 当进程 A 想在 GPU 上执行时,内存被复制过去,并为该进程创建了一个 GPU 上下文(Context A)。
- GPU 可以管理多个上下文,允许不同的进程通过上下文切换来利用 GPU 资源。
下面的例子展示了数据在 CPU 与 GPU 之间如何显式移动:
import cupy as cp
# 这些数据存在于系统内存中
cpu_data = [1, 2, 3, 4, 5]
# 这将数据复制到 GPU 内存中
gpu_data = cp.array(cpu_data) # 数据传输在此发生
# 现在 GPU 可以处理它了
result = gpu_data * 2 # 计算在 GPU 上进行
# 要获取结果,需要再次复制
cpu_result = result.get() # 传回系统内存每一次 CPU 与 GPU 之间的数据移动都需要穿过两者之间的物理互连,因此会带来额外延迟。这也是 GPU 编程普遍强调“减少数据搬运”的原因:很多时候,真正昂贵的不是计算本身,而是把数据送到 GPU 和再取回来的过程。
CUDA 核函数:GPU 程序
“核函数”(kernel)这个词在这里很容易与 Linux 内核混淆,但在 GPU 语境中,它指的是运行在 GPU 上的函数。比如下面这段代码:
# 这段 Python 代码在 CPU 上运行
import cupy as cp
x = cp.array([1, 2, 3])
y = cp.array([4, 5, 6])
# 这会在 GPU 上触发一个核函数启动
z = x + y # 加法操作通过核函数在 GPU 上执行这里的加法操作会触发一个预先实现好的 GPU 核函数,它通常经历以下过程:
- 从上下文的核函数缓存中加载
- 在数千个 GPU 核心上并行执行
- 运行到完成,不会被中断
- 将结果返回给 CPU
如果同一个上下文中连续发起多个操作,情况如下:
# 这段 Python 代码在 CPU 上运行
import cupy as cp
x = cp.array([1, 2, 3])
y = cp.array([4, 5, 6])
# 这会在 GPU 上触发一个核函数启动
z = x + y # 核函数 1:加法核函数执行
# 这会触发另一个核函数启动
w = x - y # 核函数 2:减法核函数执行每个操作(+、-、* 等)都会触发一个独立的 CUDA 核函数,而这些核函数通常在同一个 CUDA 上下文中依次执行。这个上下文在 Python 进程的生命周期内持续存在,并保存如下状态:
- 你所有的 GPU 内存分配(x、y、z、w 数组)
- 已编译的核函数(加法、减法)
- 执行状态
与 CPU 不同的是,一旦某个核函数被提交到 GPU 执行,它通常会一直运行到结束,在此期间不会像 CPU 线程那样被轻易中断。
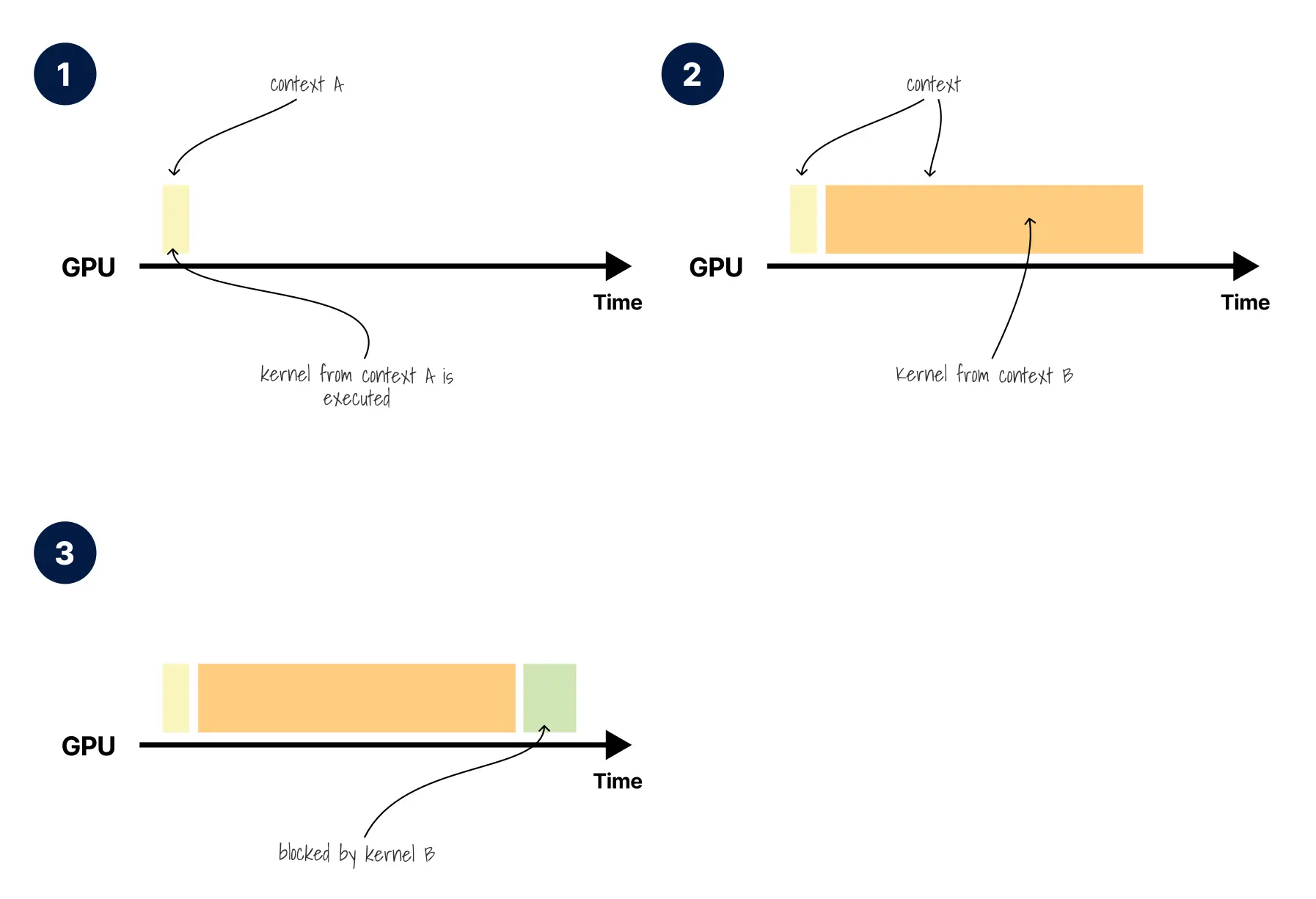
- 上下文 A 正在 GPU 上主动执行一个核函数。
- 上下文切换发生:上下文 A 继续执行,然后来自上下文 B(橙色)的核函数被调度并执行。
- 上下文 A(黄色)、上下文 B(橙色)和上下文 C(绿色)轮流执行它们的核函数。
如果习惯了 CPU 调度模型,这一点会显得反直觉,因为 CPU 可以通过时间片在单核上“并发”运行大量进程:内核快速轮转它们,给每个进程分配几毫秒执行窗口。
通过时间片机制,操作系统可以在一个 CPU 核心上并发运行数百个进程。内核会快速在这些进程之间切换,给每个进程分配几毫秒的执行时间,从而让它们看起来像是在同时运行。
在单核 CPU 上,任意时刻实际上只有一个进程正在执行;所谓“同时运行”,本质上是内核通过抢占式调度和上下文切换实现的时间复用(time-sharing)。
但在 GPU 上,来自不同进程的核函数通常不能同时执行,至少默认情况下如此;这是上下文级别的串行化。每个进程会创建自己的 CUDA 上下文,而同一时刻通常只有一个上下文处于活动状态,因此不同上下文中的核函数并不真正并行。另一方面,在单个 CUDA 上下文内部,可以创建多个流(stream)作为独立的 GPU 操作队列,例如:
import cupy as cp
# 不使用流 - 顺序执行
A = cp.random.random((4096, 4096))
B = cp.random.random((4096, 4096))
C = cp.random.random((4096, 4096))
D = cp.random.random((4096, 4096))
# 这些操作一个接一个执行
result1 = A + B # 核函数 1 执行
result2 = C + D # 核函数 2 等待核函数 1 完成
# 使用流 - 并发执行
stream1 = cp.cuda.Stream()
stream2 = cp.cuda.Stream()
with stream1:
result1 = A + B # 核函数 1 在 stream1 中
with stream2:
result2 = C + D # 核函数 2 在 stream2 中 - 与核函数 1 并发运行!这种并发执行依赖于 Hyper-Q,它为现代 GPU 提供多个硬件工作队列;在 Kepler 及以后的架构上,通常有 32 个队列。没有 Hyper-Q 时,即使处于不同流中的核函数,也常因底层硬件队列受限而被串行化。即便如此,流和 MPS 也没有改变一个根本事实:单个核函数仍然通常不可抢占。要理解原因,需要回到 GPU 的硬件架构本身。
为什么 GPU 不支持核函数抢占
为什么 GPU 不能像 CPU 一样随时暂停和恢复执行,核心原因在于硬件设计目标不同。理解这一点,需要先看 ALU(算术逻辑单元):它负责执行加法、乘法和比较等数学运算。CPU 和 GPU 都依赖 ALU 计算,但两者为这些 ALU 配套的控制逻辑差异极大。CPU 要运行浏览器、数据库、操作系统和其他高度通用的程序,这些程序包含大量分支、不可预测的内存访问以及复杂依赖,因此即便只是让 2 到 4 个 ALU 持续忙碌,也需要非常复杂的控制逻辑来:
- 预测代码将走哪个分支
- 重新排序指令以避免停顿
- 处理数据未就绪时的缓存未命中
- 管理中断和上下文切换
这也是 CPU 不能简单堆叠更多 ALU 的原因。要让大量 ALU 在通用代码上保持高利用率,就必须配套成倍增加分支预测、指令缓冲、缓存管理和乱序执行能力,而这些控制逻辑本身会迅速膨胀。即使在只有 2 到 4 个 ALU 的情况下,CPU 也已经把大量晶体管花在分支预测器、指令解码器、重排序缓冲区和缓存上;如果继续扩展到 8 个 ALU,相关控制复杂度也会同步上升。GPU 的设计前提则完全不同:它主要处理可预测的并行计算,例如矩阵乘法或像素处理,在这些场景中,大量数据执行的是同一种操作,分支和不可预测内存访问都大幅减少。正因如此,一个 GPU 流式多处理器中的 64 到 128 个 ALU 可以共享较少的控制逻辑,由单一控制单元把同一条指令广播给所有 ALU。
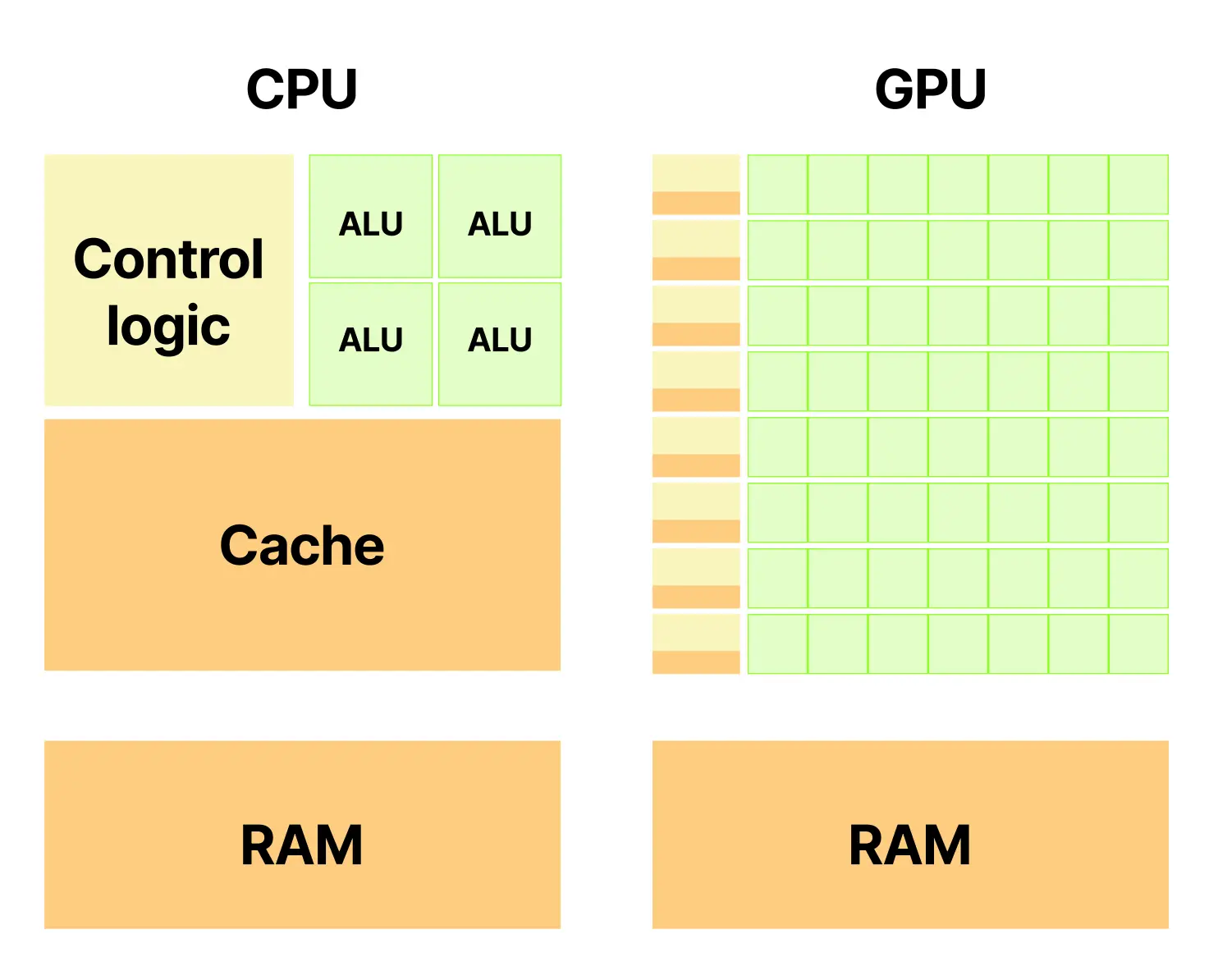
这就是为什么 CPU 核心往往只有 2 到 4 个 ALU,而 GPU 的流式多处理器却可以拥有 64 到 128 个。GPU 把更多晶体管预算投入计算单元而不是控制单元,代价则是缺少 CPU 那样成熟的中断、抢占和暂停恢复能力。换句话说,GPU 之所以能够塞入如此多的 ALU,恰恰是因为它放弃了支持通用抢占所需的大量控制逻辑。
GPU 内存:完全不同的模型
如果说 GPU 的执行模型已经偏离了 CPU 的直觉,那么 GPU 的内存模型则进一步打破了系统管理员对“内存管理”的既有理解。首先,物理 GPU 内存就是显卡上的 VRAM,例如 Tesla T4 提供 16GB,A100 则可能是 40GB 或 80GB,这与服务器中的 RAM 一样构成绝对容量上限。不同之处在于,系统内存由 Linux 内核逐页跟踪,而 GPU 内存管理主要发生在 NVIDIA 驱动内部,对 Linux 内核几乎不可见。进程一旦创建 CUDA 上下文并开始分配显存,每个上下文都会看到整块 GPU 的总内存空间,例如 T4 的 16GB,但它实际上只能访问自己分配到的那一部分。
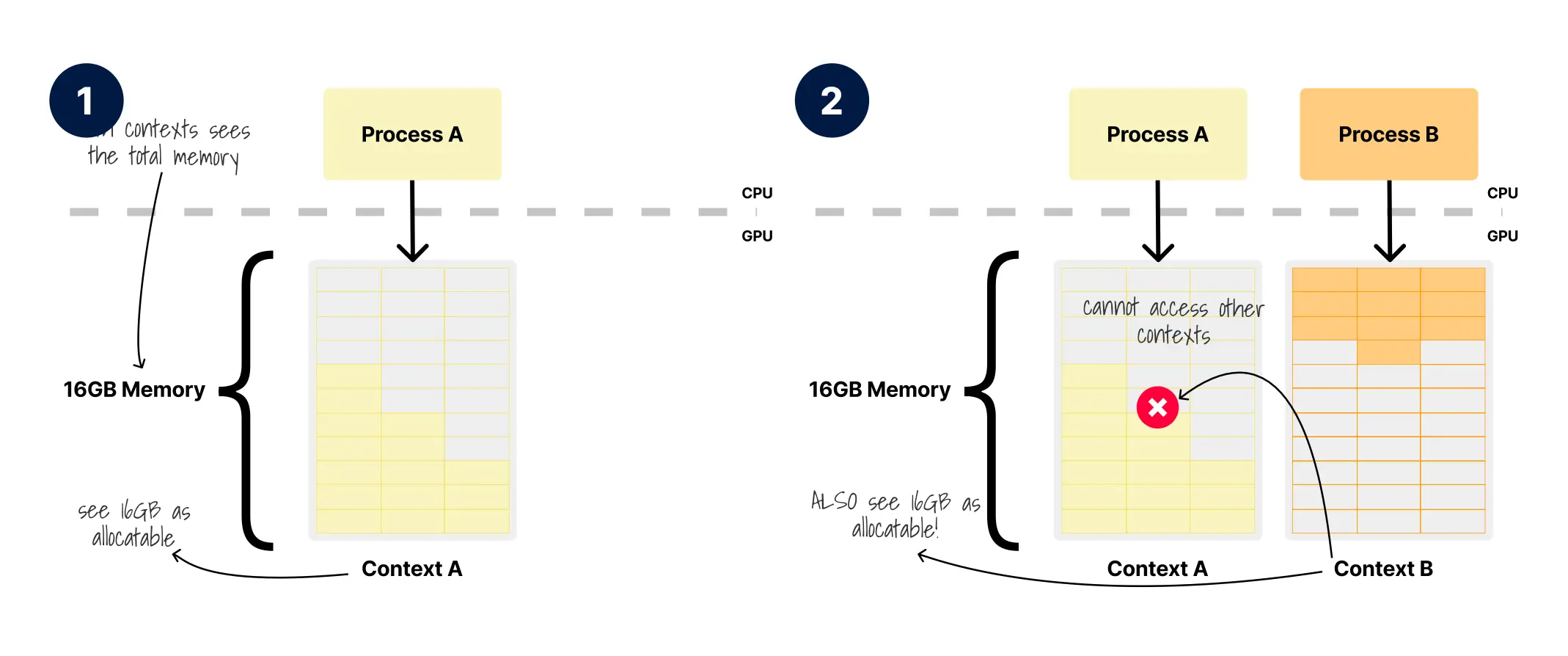
- 进程 A 在 GPU 上创建上下文 A,16GB 总内存可用。上下文看到全部 16GB 都可分配。
- 进程 B 尝试在上下文 A 仍在驻留时创建上下文 B。虽然两个上下文都看到 16GB 可分配,但它们无法访问其他上下文的内存。
假设有两个进程先后启动:
进程 A 启动,创建上下文 A:
- 看到:16GB 总 GPU 内存
- 分配:4GB 用于神经网络权重
- 可访问:仅它自己的 4GB
进程 B 启动,创建上下文 B:
- 看到:16GB 总 GPU 内存(与 A 相同的视图!)
- 分配:2GB 用于图像处理
- 可访问:仅它自己的 2GB
此时真实状态是:总共用了 7GB,剩余 9GB,但两个进程都“以为”自己面对的是完整的 16GB 地址空间。对于 Linux 内核而言,这部分状态并不存在于标准内存管理视图中,没有 GPU 版的 /proc/meminfo,没有对应的 cgroup 统计,也没有可以直接强制执行的内存上限。更进一步地,CUDA 的分配方式还不是“按请求精确分配”,而是为了性能使用池化分配器:
import cupy as cp
# 第一次分配 - 你请求 8KB
arr1 = cp.zeros(1000) # 1000 个浮点数 x 8 字节 = 8KB
# 但 CUDA 实际上从 GPU 预留了一个 2MB 的池
# nvidia-smi 现在显示使用了 2MB,而不是 8KB
# 第二次分配
arr2 = cp.zeros(1000) # 另一个 8KB
# 这使用了现有的池 - 没有新的 GPU 分配
# nvidia-smi 仍然显示使用了 2MB
# 很久以后...
huge_array = cp.zeros(10_000_000) # 需要 80MB
# 现在 CUDA 预留了另一个大块,可能是 128MB
# nvidia-smi 显示使用了 130MB(2MB + 128MB)这种池化策略从性能角度看完全合理,因为 GPU 内存分配本身开销很高,驱动倾向于先拿到较大的内存块,再在内部复用。
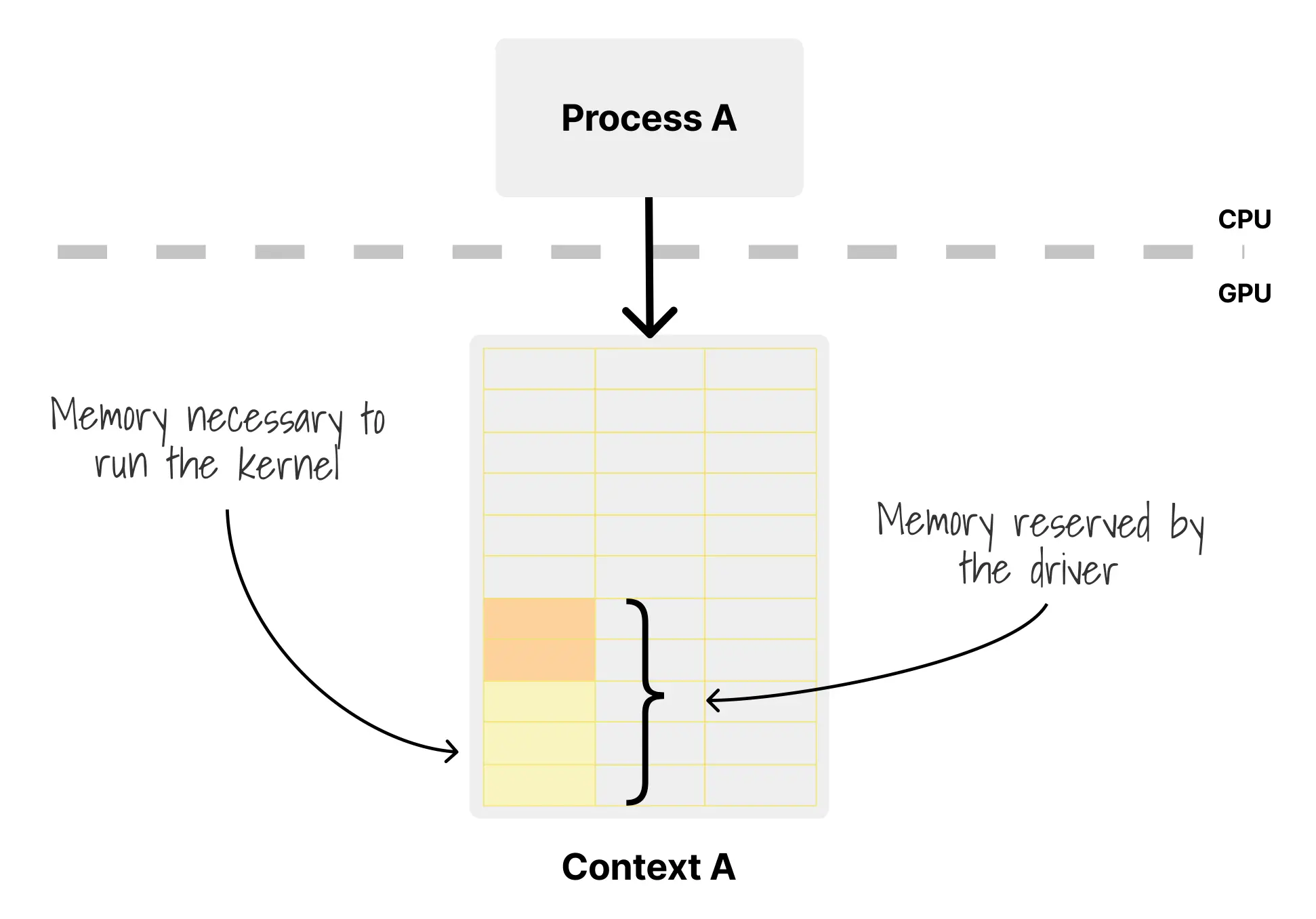
但对监控和容量规划而言,这会造成严重偏差:你可能在 nvidia-smi 中看到 2GB 已分配,而应用真实持有的有效数据只有 100MB。也就是说,GPU 内存的“可见使用量”与“逻辑有效载荷”之间,天然存在一个由驱动和分配器引入的落差。
关键差异
到这里,可以更清楚地对比 CPU/内核模型与 GPU/驱动模型之间的差异。
当你的 CPU 代码运行时:
- 每个操作都通过系统调用传递给 Linux 内核
- Linux 内核可以在任何微秒抢占你的进程
- 进程之间的上下文切换只需几微秒
- Linux 内核能看到每一条指令、每一次内存访问
当你的 GPU 代码运行时:
- CUDA API 调用传递给 NVIDIA 驱动(专有的、闭源的)
- 核函数运行到完成,无法被抢占
- 上下文切换需要几毫秒(比 CPU 慢 1000 倍)
- Linux 内核对 GPU 上发生的事情完全不可见
当 Linux 内核管理系统内存时:
- 按页分配(通常 4KB 的页)
- 每次分配都在页表中跟踪
- cgroups 可以强制执行硬性限制
- 可以换出到磁盘、压缩、回收
相比之下,GPU 内存由驱动管理:
- 以大池分配(一次数兆字节)
- 驱动跟踪分配,Linux 内核看不到它们
- 不可能有 cgroup 强制执行
- 内存不能被换出或回收
也正因为如此,容器赖以成立的许多内核原语,在 GPU 上都没有直接对应物:
没有 GPU cgroups:
# 这个不存在
echo 4G > /sys/fs/cgroup/gpu/myapp/gpu-memory_limitLinux 内核之所以无法限制 GPU 内存,是因为它根本看不到这些分配。同样,也没有 GPU 命名空间可言,/dev/nvidia0 对所有能访问该设备文件的进程都是同一个对象,内核无法为不同进程构造独立的虚拟 GPU 视图。当进程发起 CUDA 调用时,Linux 内核能观察到的往往只有对 NVIDIA 驱动的系统调用,例如 ioctl();进入驱动内部之后,GPU 的调度、内存与执行状态都变得不透明。于是,Linux 内核无法像管理 CPU 和内存那样跟踪 GPU 利用率、显存占用、资源公平性或服务质量。这正是问题的根部:容器依赖的是一套在 GPU 上并不存在的内核控制原语,而 Kubernetes 中的许多限制也都由此而来。
Kubernetes 与容器运行时接口
有了这些背景,再看 Kubernetes 中的容器运行路径就会更清晰。当你部署一个 Pod 时,真正负责在节点上把它跑起来的是 kubelet,但 kubelet 并不直接创建容器,而是通过容器运行时接口(CRI)与 containerd、CRI-O 等运行时通信。
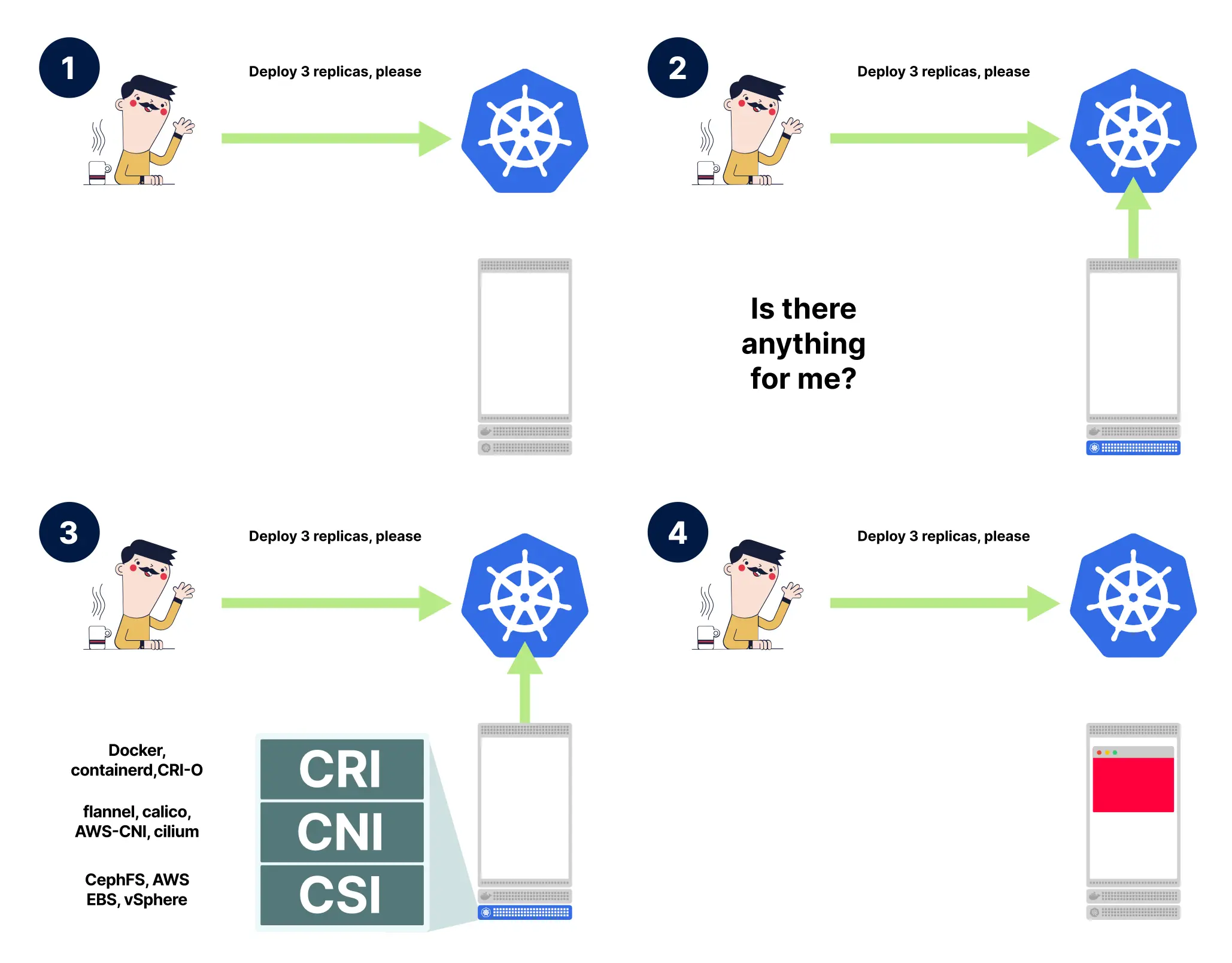
- 部署请求被发送到 Kubernetes API(由船舵图标表示),一个空节点准备好接收工作负载。
- 节点上的 kubelet 轮询 Kubernetes API。API 服务器响应该节点上需要调度的 Pod 规格。
- kubelet 接收 Pod 规格并与 CRI/CSI/CNI 交互。
- 容器(以粉红/红色显示)现在运行在节点上。
当一个 Pod 被调度到节点后,kubelet 会从 API 服务器读取其规格,并把这个抽象描述转化为真实的容器环境。它先调用 CRI 创建 Pod sandbox,为同一个 Pod 下的多个容器建立共享环境,包括共享的网络命名空间、主机名和卷。然后,kubelet 针对 Pod 中的每个容器依次完成镜像检查、镜像拉取、层解压和文件系统准备,并把资源请求翻译成实际的 cgroup 配置。例如,当 Pod 规格包含如下限制时:
resources:
limits:
cpu: '500m' # 半个 CPU 核心
memory: '256Mi' # 256 MiB 内存CRI 创建相应的 cgroups:
# CPU cgroup - 限制为一个核心的 50%
/sys/fs/cgroup/cpu/kubepods/pod-UUID/container-id/cpu.cfs_quota_us: 50000
/sys/fs/cgroup/cpu/kubepods/pod-UUID/container-id/cpu.cfs_period_us: 100000
# Memory cgroup - 限制为 256MiB
/sys/fs/cgroup/memory/kubepods/pod-UUID/container-id/memory_limit_in_bytes: 268435456CRI 会进一步通过命名空间建立隔离:每个容器拥有自己的挂载命名空间和 PID 命名空间,同时加入所属 Pod 的共享网络命名空间。最后,运行时执行容器入口点,进程开始运行,而内核在整个生命周期中持续强制执行前面建立好的 cgroup 与命名空间边界。换言之,CRI 的职责就是把 Kubernetes 中的 Pod 规格翻译成 Linux 内核真正能够理解和执行的原语。
Kubernetes 中的 GPU 问题
GPU 的情况则不同,它在 Kubernetes 中带来两个根本问题:
- 调度器需要知道哪些节点有可用的 GPU。但 Kubernetes 不知道什么是 GPU,因为它原生只理解 CPU 和内存。
- 即使我们将 Pod 调度到 GPU 节点,容器也是被隔离的。它看不到
/dev/nvidia0或其他 GPU 设备文件。
因此,系统必须同时解决三个问题:
- 使 GPU 设备文件在容器内可见
- 加载正确的库来与 GPU 通信
- 设置 CUDA 上下文
从实现角度看,GPU 集成可以视为一个四层结构,每一层都解决一个明确问题,同时也引入新的复杂性。
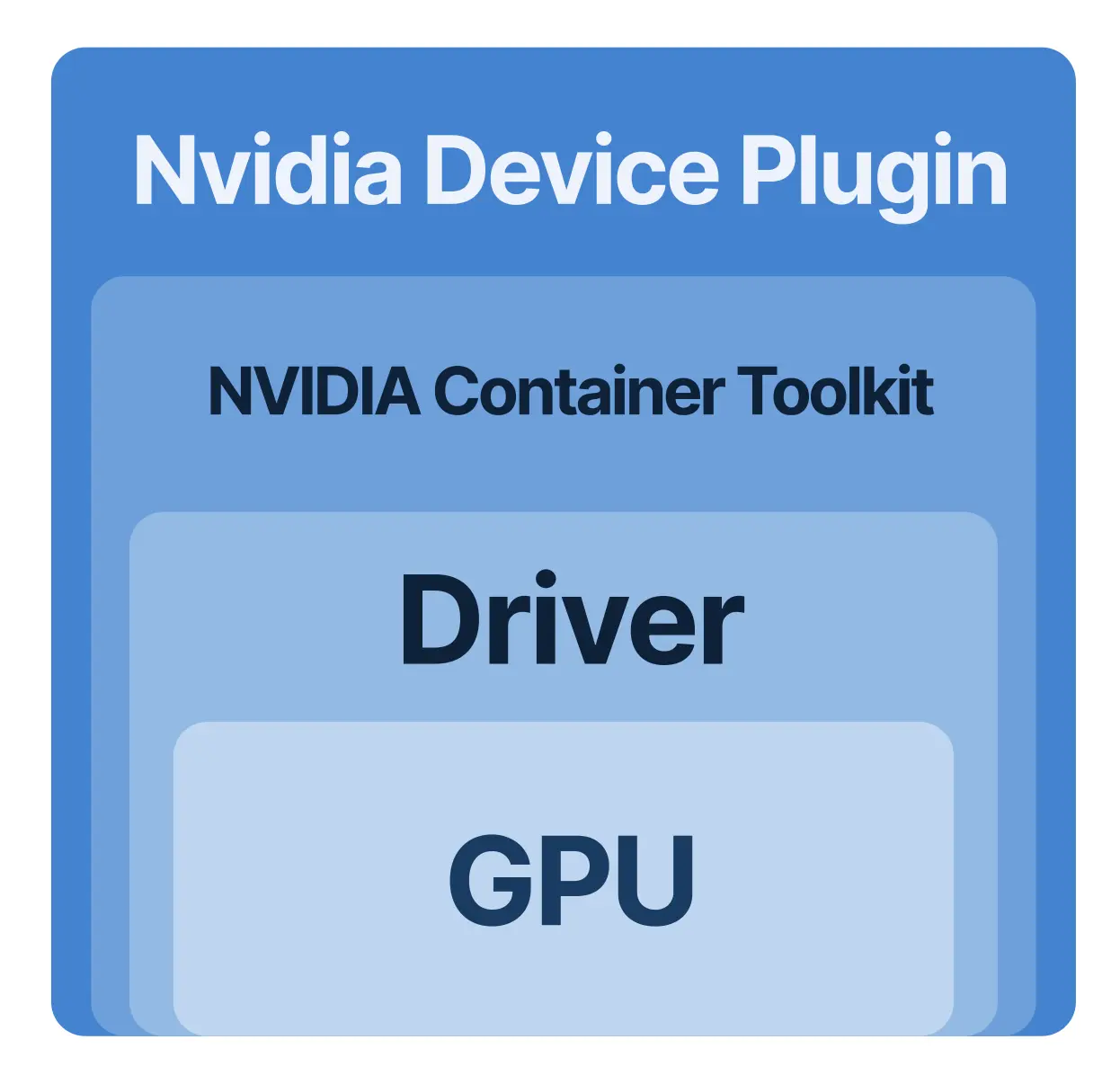
最底层是 GPU 硬件及其驱动。以下是本书所使用的 minikube 环境中的实际硬件与运行时信息:
$ minikube ssh
$ nvidia-smi
Mon Aug 4 12:35:11 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------------------------------------------|
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=============================================================================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 37C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
+-----------------------------------------------------------------------------+
| | | N/A |
+---------------------------------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
$ nvidia-container-runtime --version
NVIDIA Container Runtime version 1.13.5
commit: 6b8589dcb4dead72ab64f14a5912886e6165c079
spec: 1.1.0-rc.2
runc version 1.1.5+ds1
commit: 1.1.5+ds1-1+deb12u1
spec: 1.0.2-dev
go: go1.19.8
libseccomp: 2.5.4可以看到,节点上有一块 Tesla T4,并且 NVIDIA 驱动、容器运行时工具链都已经就绪。NVIDIA 驱动在这里承担的是桥梁角色:它把 GPU 硬件暴露为 Linux 能够处理的设备接口。
$ ls -la /dev/nvidia*
crw-rw-rw- 1 root root 195, 254 Aug 4 11:56 /dev/nvidia-modeset
crw-rw-rw- 1 root root 241, 0 Aug 4 11:40 /dev/nvidia-uvm
crw-rw-rw- 1 root root 241, 1 Aug 4 11:40 /dev/nvidia-uvm-tools
crw-rw-rw- 1 root root 195, 0 Aug 4 11:40 /dev/nvidia0
crw-rw-rw- 1 root root 195, 255 Aug 4 11:40 /dev/nvidiactl
/dev/nvidia-caps:
total 0
drwxr-xr-x 2 root root 80 Aug 4 11:40 .
drwxr-xr-x 15 root root 3240 Aug 4 11:56 ..
cr-------- 1 root root 244, 1 Aug 4 11:40 nvidia-cap1
cr--r--r-- 1 root root 244, 2 Aug 4 11:40 nvidia-cap2其中,/dev/nvidia0 对应 Tesla T4 设备本身,/dev/nvidiactl 负责跨 GPU 的控制操作。CUDA Driver API 正是通过这些设备接口与驱动协同工作,从而把 GPU 计算能力提供给应用程序。
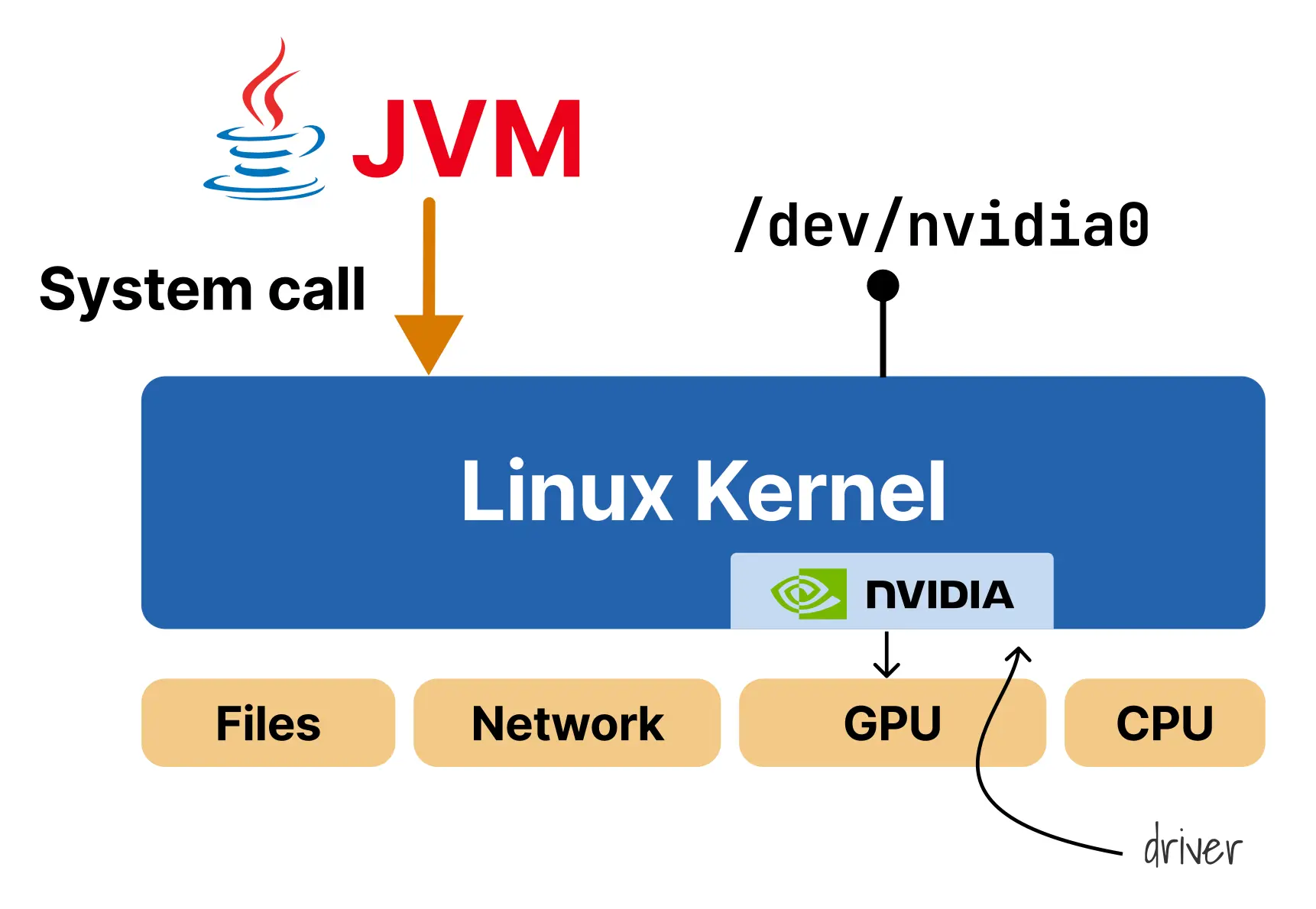
问题在于,这些设备文件只存在于主机上,而容器运行时本身并不理解 GPU,也不会主动把它们暴露给容器。为了解决这一点,需要 NVIDIA Container Toolkit 介入。GPU 工作负载的特殊性在于:容器本应与主机隔离,但 GPU 使用又要求一定程度的直接硬件访问。NVIDIA Container Toolkit 通过拦截容器创建流程,并有选择地把 /dev/nvidia0 之类的设备文件、驱动库以及 NVIDIA_VISIBLE_DEVICES 等环境变量挂载或注入到容器中,来完成这种“受控突破”。
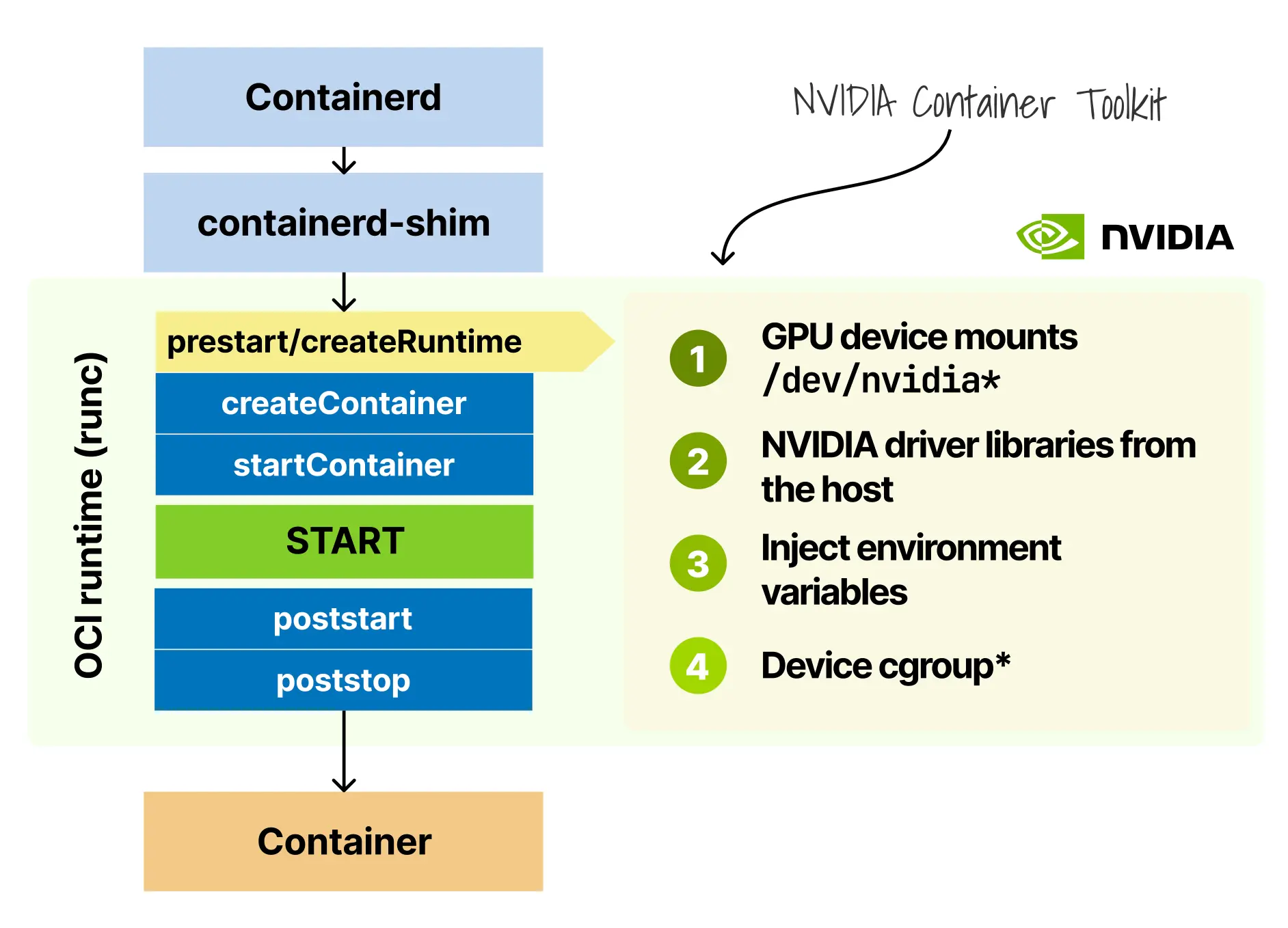
这样一来,应用代码本身无需修改,却能够在容器中直接使用主机上的 Tesla T4。不过,容器运行时只解决了“如何访问 GPU”的问题,Kubernetes 仍然需要先知道“GPU 存不存在、该把 Pod 调度到哪里”。这正是设备插件框架的职责。设备插件是 Kubernetes 处理非原生硬件资源的标准方式,而集群中的 NVIDIA 设备插件对外实现的是一个简单的 gRPC 接口:
// 设备插件 gRPC 服务
service DevicePlugin {
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse);
rpc Allocate(AllocateRequest) returns (AllocateResponse);
}这个插件充当 Tesla T4 硬件与 Kubernetes 资源模型之间的翻译层。它通过 NVML 发现节点上的 GPU,再把这些设备公告为可调度资源;注册完成后,插件通过 ListAndWatch 流持续向 kubelet 报告设备状态。
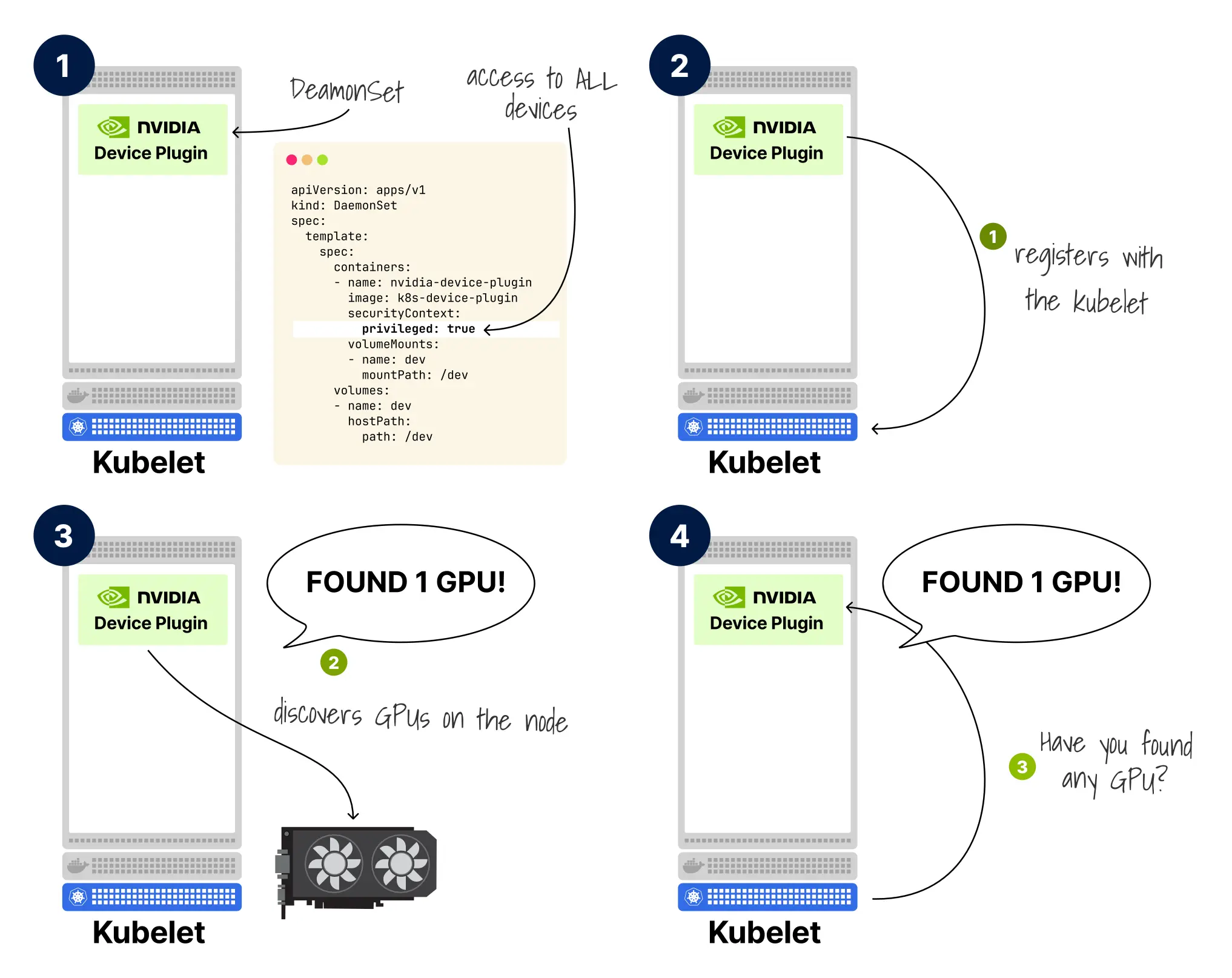
- DaemonSet 将 NVIDIA Device Plugin 部署到所有有 GPU 资源的节点。
- 注册过程建立设备插件与 kubelet 之间的通信以管理 GPU 资源。
- 设备插件发现节点上的 GPU,但不会立即报告给 kubelet。
- kubelet 从设备插件查询 GPU。
kubelet 接收到这些信息后,会相应更新节点容量和可分配资源:
status:
capacity:
nvidia.com/gpu: '1'
allocatable:
nvidia.com/gpu: '1'于是,原本物理存在的一块 Tesla T4,就在 Kubernetes 里被表示为 nvidia.com/gpu: 1。设备完成注册后,Pod 便可以像请求其他资源一样请求它:
resources:
limits:
nvidia.com/gpu: 1从此以后,Kubernetes 就可以把 GPU 当作一种扩展资源来调度。不过,与 CPU 和内存不同,GPU 在默认语义下不是可细粒度共享的资源,而是整数资源;一个 Pod 要么拿到 1,要么拿不到。这种设计也让设备插件获得了比普通资源控制更大的权力:在 CPU 和内存场景下,最终裁决权在 Linux 内核和 cgroups 手中;而在 GPU 场景下,插件本身成为硬件分配的核心权威。它负责资源发现,通过 ListAndWatch 持续上报健康状态;它负责分配决策,通过 Allocate 精确构造容器所需的设备、挂载和环境变量。例如,当 Pod 请求 nvidia.com/gpu: 1 时,Allocate 返回的并不只是一个“分配成功”标记,而是类似下面这样的具体配置:
// Allocate 响应示例
&AllocateResponse{
ContainerResponses: []*ContainerAllocateResponse{
Devices: []*DeviceSpec{
{ContainerPath: "/dev/nvidia0", HostPath: "/dev/nvidia0"},
{ContainerPath: "/dev/nvidiactl", HostPath: "/dev/nvidiactl"},
},
Envs: map[string]string{"NVIDIA_VISIBLE_DEVICES": "0"},
},
}这种控制并不止于分配本身,还延伸到资源生命周期的清理阶段。与 Linux 内核管理 CPU 时间片不同,设备插件需要自行编排整个 GPU 使用过程:挂载设备、设置环境变量、退出时清理状态。它的局限性也同样明显:Kubernetes 核心组件,例如调度器、kubelet 与资源配额控制器,看到的只有 nvidia.com/gpu: 1 这样的抽象数量,而无法理解显存使用量、无法设置服务质量策略、无法做真正的抢占与公平共享,也无法直接观测 GPU 的真实利用率。
运行 GPU Pod:端到端
有了前面的组件背景,现在可以顺着一次实际部署过程,把 GPU Pod 从创建到真正访问 GPU 的路径完整串起来。下面是一个最小测试 Pod:
apiVersion: v1
kind: Pod
metadata:
name: gpu-test
spec:
containers:
- name: cuda-container
image: nvidia/cuda:11.0-base
command: ['nvidia-smi']
resources:
limits:
nvidia.com/gpu: 1当这个 Pod 被提交到集群后,Kubernetes 调度器会立即开始工作。
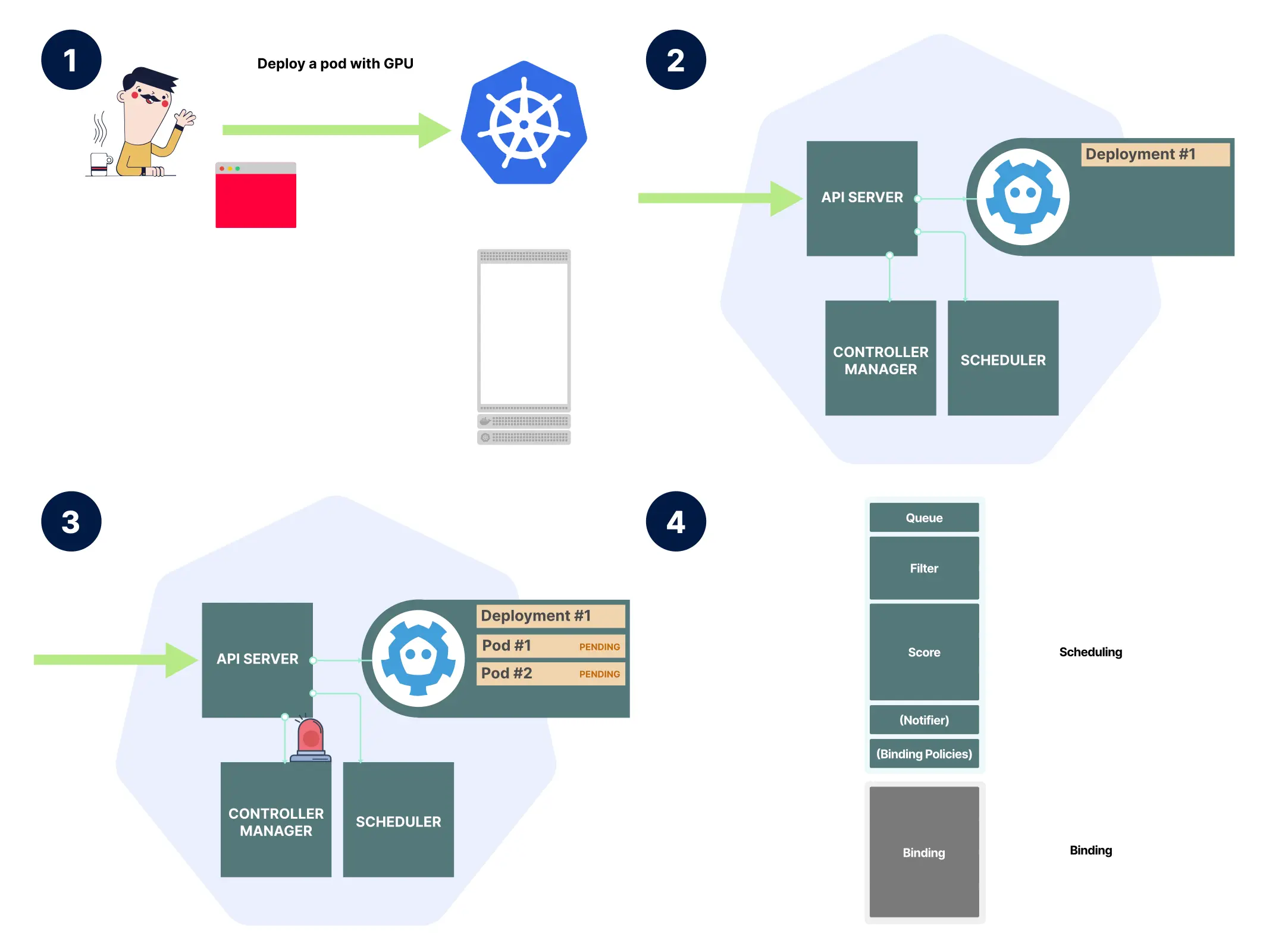
- 部署请求被发送到 Kubernetes API 服务器。
- API 服务器接收部署请求,并将资源存储在 etcd 中。
- 控制器管理器继续创建 ReplicaSet 和 Pod。Pod 处于待定状态并被添加到调度器的队列中。
- 调度器经过两个阶段:过滤谓词来决定将节点分配到哪里。
调度器看到 Pod 请求 nvidia.com/gpu: 1,便把它当作扩展资源进行过滤和匹配:它遍历节点的可分配资源,寻找至少有 1 个可用 nvidia.com/gpu 的节点,最终发现 minikube 节点满足条件,并通过 API 服务器把该 Pod 绑定到这个节点。节点上的 kubelet 监视到新的绑定事件后,会读取 Pod 规格,并注意到该 Pod 请求了一个并非原生的资源,于是转而向设备插件发起 Allocate 请求:
AllocateRequest{
ContainerRequests: []*ContainerAllocateRequest{
DevicesIDs: ["GPU-abc123"], // 特定的 GPU 标识符
},
}NVIDIA 设备插件收到请求后,会返回一组足以让容器访问 GPU 的精确指令:
&AllocateResponse{
ContainerResponses: []*ContainerAllocateResponse{
Devices: []*DeviceSpec{
// 挂载 GPU 设备文件
{ContainerPath: "/dev/nvidia0", HostPath: "/dev/nvidia0"},
// 挂载控制接口
{ContainerPath: "/dev/nvidiactl", HostPath: "/dev/nvidiactl"},
// 挂载统一内存接口
{ContainerPath: "/dev/nvidia-uvm", HostPath: "/dev/nvidia-uvm"},
},
Envs: map[string]string{
// 告诉 NVIDIA 运行时使用哪块 GPU
"NVIDIA_VISIBLE_DEVICES": "0",
// 启用 CUDA 支持
"NVIDIA_DRIVER_CAPABILITIES": "compute,utility",
},
},
}kubelet 随后把这些分配结果连同原始 Pod 规格一起交给 CRI。容器运行时此时需要创建一个既满足标准隔离要求、又具备 GPU 访问能力的容器环境:先建立 CPU 和内存 cgroups,再设置文件系统与进程命名空间,然后把主机上的 GPU 设备文件挂载到容器中,并写入相关环境变量,告诉 NVIDIA 运行时这个容器应当使用哪块 GPU。到了容器即将启动的时刻,另一个关键组件开始工作,即 NVIDIA 容器运行时钩子。它位于 containerd 与容器之间,会在启动阶段自动执行。
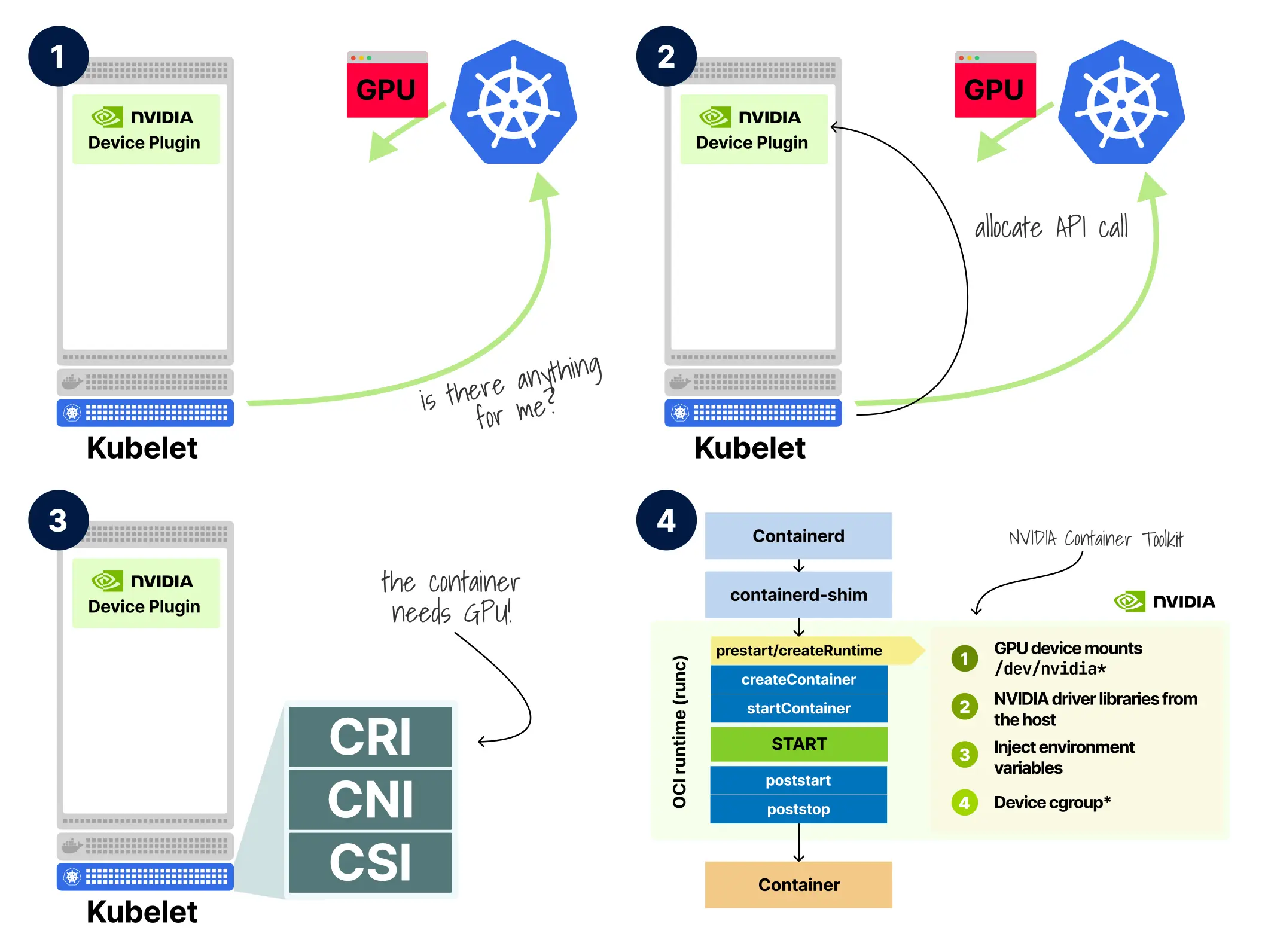
- kubelet 轮询需要 GPU 资源的新 Pod 分配。
- 节点上的 NVIDIA Device Plugin 准备为传入的 Pod 处理 GPU 资源分配。
- kubelet 通过 CRI 创建容器
- 工具包为容器启用 GPU 设备挂载、NVIDIA 驱动库、环境变量注入和设备 cgroups 管理。
这个运行时钩子在容器启动前会完成如下工作:
- 检查
NVIDIA_VISIBLE_DEVICES环境变量。如果不存在,它什么都不做,让容器正常启动 - 如果变量存在,它会查询主机上安装的 GPU 库,确定与当前驱动匹配的 CUDA 库版本,并修改容器规格以添加挂载
- 将必要的库注入容器。
- 配置库路径,使容器能够找到它们。
如果没有这一步,容器即使已经拥有 /dev/nvidia0 设备文件,也依然缺少实际调用 GPU 所需的 CUDA 库,效果相当于“看得见显卡,却没有驱动”。这一机制利用的是运行时规范中的 prestart OCI(开放容器倡议) 钩子,即在容器创建完成但应用尚未启动之前插入逻辑。NVIDIA 正是借助这个标准扩展点,在最后一刻把 GPU 支持注入到一个原本并不包含任何 NVIDIA 组件的标准镜像中。下面是 containerd 启用相关集成的一个示例:
[plugins."io/containerd.grpc.v1.cri"]
enable_cdi = true
cdi_specdirs = ["/etc/cdi", "/var/run/cdi"]在 Kubernetes 环境中,这些组件通常由 NVIDIA 提供的 DaemonSet 一并安装和配置。经过前述步骤之后,容器中的应用终于可以真正访问 GPU;例如,当它执行 nvidia-smi 时,就能够观察到设备,并进一步执行以下操作:
- 创建 CUDA 上下文(200-300ms 初始化)
- 分配 GPU 内存(以大池为单位)
- 启动核函数(不可抢占的执行)
- 在数千个核心上处理数据
但这里的关键限制也随之显现:这个 Pod 拿到的是整块 GPU,而不是其中一小部分。即使应用只消耗了部分算力或少量显存,Kubernetes 视角下它仍然独占了这块设备。
共享挑战
到这里,我们已经完成了 GPU 工作负载在 Kubernetes 中的基本运行路径,但代价也很清楚:每个 Pod 默认获得的是整块 GPU。无论是 Tesla T4 还是更昂贵的 H100,都可能被单个只使用了 10% 算力或 1GB 显存的 Pod 独占。只要你开始考虑跨团队或跨工作负载共享 GPU,新的问题就会立刻出现:
- 如何防止一个工作负载独占 GPU?
- 当多个 Pod 尝试使用相同的 GPU 内存时会发生什么?
- 如何在没有内核支持的情况下确保公平调度?
- 不同团队的工作负载之间的安全边界怎么办?
这些问题将我们引向 GPU 共享机制及其产生的根本信任问题,这正是下一章的主题。
关键要点
- 容器之所以成立,前提是内核既提供系统调用接口,也能通过 cgroups 和命名空间观察并强制执行资源边界。
- GPU 运行在这套内核控制模型之外:CUDA 上下文替代了进程视角,核函数不可抢占,显存通过内存池管理,很多关键状态对内核不可见。
- 设备插件只是把 GPU 接入 Kubernetes 资源模型:它们能发现设备、暴露资源、配置容器访问,但不能复制 CPU 和系统内存那种细粒度控制能力。
- 现有 Kubernetes GPU 集成是可用的,但能力边界非常明确:Pod 可以申请并使用 GPU,却仍然只能按整卡或整数资源单元消费,缺少原生共享、显存配额和服务质量保障。
- 一旦进入多工作负载共享场景,问题就会从“如何接入 GPU”转向“谁来控制 GPU”,这也是后续章节要继续展开的核心矛盾。