硬件隔离与强制执行
本章将讨论以下几个问题:
- 如何通过 MIG(多实例 GPU)实现真正的并行 GPU 执行而非时间共享
- 为什么通过 HAMi 的软件强制执行可以在任何 GPU 上工作,而不仅仅是昂贵的 GPU
- 何时硬件隔离的成本是合理的,相较于软件替代方案
- 如何实现 MIG 和 HAMi
- 硬件分区与 API 拦截之间的运维权衡
到这一章为止,问题已经不再是“能不能让多个工作负载共用一块 GPU”,而是“当它们共享时,谁来阻止失控行为”。训练作业再次崩溃,不是因为 KAI-Scheduler 没有记录分配,也不是因为时间分片没有把 GPU 切成看似整齐的插槽,而是因为这些方案都停留在编排层:它们决定谁可以进入共享关系,却无法在运行时强制约束每个参与者。只要系统仍然建立在“请友好合作”的假设之上,多租户冲突就迟早会出现。要解决这个问题,就必须走向隔离或强制执行。本章讨论的正是两条方向截然不同的路径:一种依赖 NVIDIA 在硬件中直接构建边界,另一种则通过软件拦截 GPU API 来补上缺失的执行能力。
根本区别:并行 vs 顺序
在进入具体方案之前,先需要明确一个会影响后文所有判断的区别:并行执行与顺序执行。到目前为止已经讨论过的手动共享、时间分片和 KAI-Scheduler,本质上都仍然属于顺序执行模型:
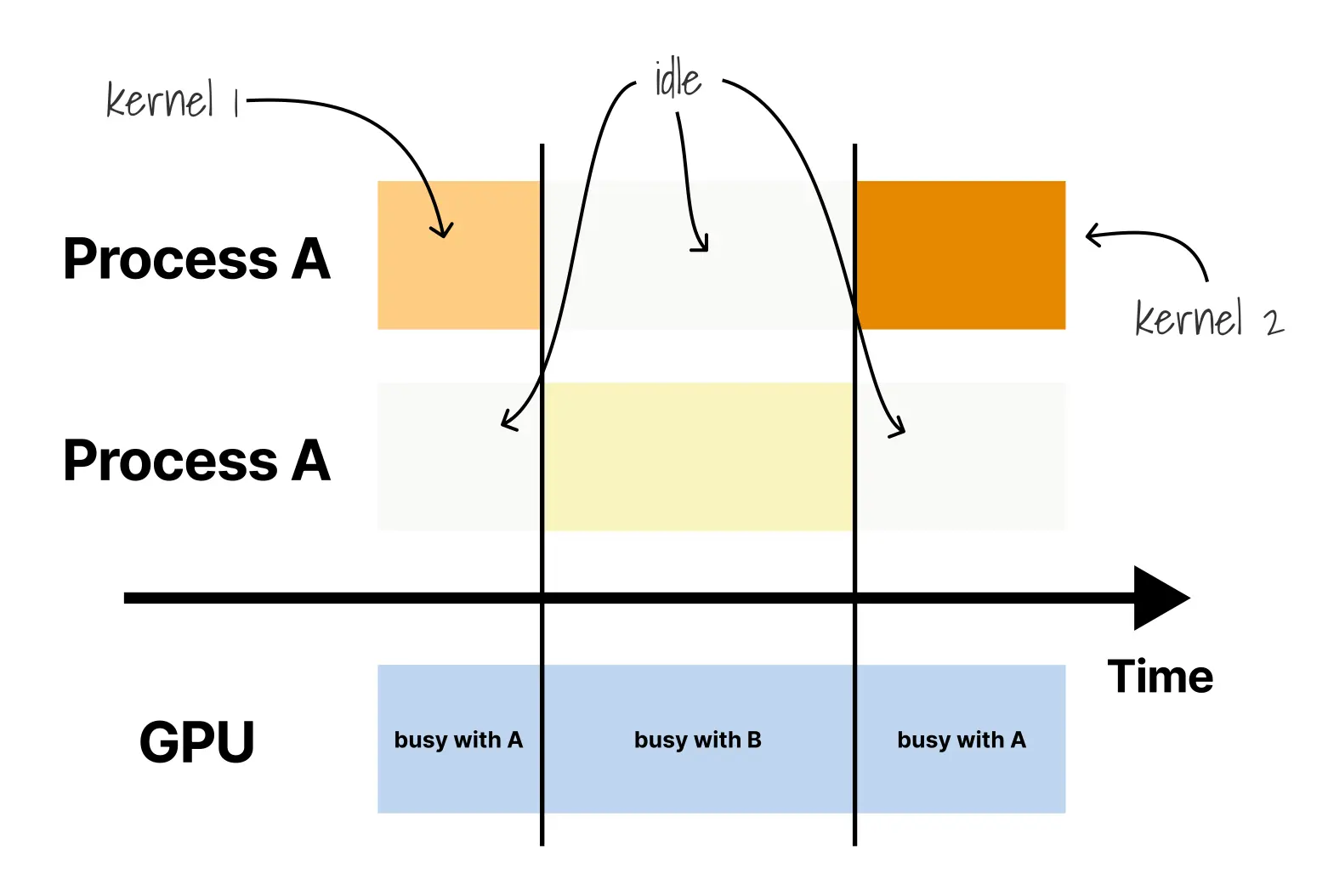
在这种模型中,Pod 并不是同时使用 GPU,而是轮流提交并等待核函数执行完成。当 Pod A 的核函数在运行时,Pod B 只能等待。这带来的根本问题是,只要有一个行为不当或工作负载特征不合适的 Pod,它就可能实质上独占 GPU。下面这个例子足以说明问题:
# Pod A 启动一个 30 秒的矩阵运算
$ kubectl logs pod-a
Starting 30-second computation
# Pod B 尝试运行推理
$ kubectl logs pod-b
Waiting for GPU...
Waiting for GPU...
Waiting for GPU...
[30 秒后终于运行]即使内存边界能够被完美隔离,Pod B 仍然会被困在等待中,因为问题出在执行顺序本身,而不是单纯的显存分配。于是,真正重要的问题变成了:能否让多个工作负载在硬件层面同时推进,而不是只是排队轮转?
MIG:NVIDIA 决定在芯片中解决这个问题
多实例 GPU(MIG)是 NVIDIA 对共享问题给出的硬件答案。它不再试图让多个工作负载顺序地共享同一块执行引擎,而是直接把一块 GPU 物理切分成若干彼此独立的处理实例。可以把时间分片想象成多个团队轮流使用同一个会议室,而 MIG 更像是在同一栋楼里竖起永久隔墙,分出多个独立办公室;这样一来,团队之间不再排队,而是并行工作。先从一个反例开始:在 Tesla T4 上,MIG 根本不可用。
$ nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-abc-123-def)
$ nvidia-smi mig -lgip
No MIG-capable GPUs found.这揭示了 MIG 的第一个现实约束:它并不是通用能力,只在少数高端、昂贵的 GPU 上可用。切换到 H100 之后,情况就完全不同了:
# On an H100-equipped node
$ nvidia-smi -L
GPU 0: NVIDIA H100 80GB HBM3 (UUID: GPU-xyz-789)
# Check MIG capability
$ nvidia-smi mig -lgip
+-----------------------------------------------------------------------------+
| GPU Instance Profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|=============================================================================|
| 0 MIG 1g.10gb 19 7/7 9.75 No 16 0 0 |
| MIG 2g.20gb 14 3/3 19.62 No 32 1 0 |
| MIG 3g.40gb 9 2/2 39.50 No 48 2 0 |
| MIG 4g.40gb 5 1/1 39.50 No 64 2 0 |
| MIG 7g.80gb 0 1/1 79.00 No 112 7 0 |
+-----------------------------------------------------------------------------+从这里可以看到,H100 支持多种不同的切分配置,而 1g.10gb 配置文件显示 7/7 个可用实例,意味着整块 GPU 最多可以被切成七个独立的切片。
为什么是七个切片?
这里的数字七并不是随意挑选出来的,它来自 GPU 内部硬件组织方式。H100 SXM5 具有 132 个流式多处理器(SM)。SM 可以理解为 GPU 内部的一个“迷你处理器簇”:它不是单个 ALU,而是一组计算单元与配套资源的集合,其中包含 CUDA 核心、共享内存、寄存器文件以及调度逻辑。第一章提到 GPU 通过大规模 ALU 获得并行能力,但这些 ALU 实际上正是按 SM 为单位组织起来的。
以 H100 SXM5 为例,每个 SM 含有 128 个用于单精度计算的 CUDA 核心,因此整块 GPU 共有 $132 \times 128 = 16{,}896$ 个 FP32 计算核心。当我们说 MIG 把 H100 分成七个切片时,本质上是在把这些 SM 及其相关资源切成七组可独立使用的硬件分区。对于最小的 1g.10gb 配置文件,在 H100 PCIe 变体上会获得 16 个 SM,也就是大约 $16 \times 128 = 2048$ 个 CUDA 核心,这仍然是一份具备相当计算能力的独立资源。NVIDIA 的硬件之所以能够把 GPU 干净地分成七个隔离单元,是因为它同时对以下资源做了分区:
- 每个实例获得专用的一部分 SM
- 每个实例获得专用的内存控制器
- 每个实例获得独立的缓存分区
换句话说,硬件不是只切开了计算核心,而是切开了一整套足以独立运行的执行域。七个基本单元随后可以按照不同配置灵活组合,只要总数不超过七即可:
H100 上的有效组合:
- 7× 1g.10gb(7 个小实例)
- 3× 2g.20gb + 1× 1g.10gb(3 个中 + 1 个小 = 7 个单元)
- 2× 3g.40gb + 1× 1g.10gb(2 个大 + 1 个小 = 7 个单元)
- 1× 7g.80gb(1 个完整 GPU = 7 个单元)
- 1× 4g.40gb + 1× 3g.40gb(4 个单元 + 3 个单元 = 7 个单元)
无效组合:
- 4× 2g.20gb(需要 8 个单元,只有 7 个可用)
每个配置文件消耗特定数量的基本单元:
- 1g.10gb = 1 个单元
- 2g.20gb = 2 个单元
- 3g.40gb = 3 个单元
- 4g.40gb = 4 个单元
- 7g.80gb = 7 个单元
把它理解为把一张披萨切成七块会比较直观:你可以任意组合这些切片,但永远不可能凭空再切出第八块。
创建 MIG 实例
在节点上启用 MIG 后,就可以把一块 H100 切成多个实例:
# 启用 MIG 模式(需要 GPU 重置)
$ nvidia-smi -mig 1
Enabled MIG Mode for GPU 00000000:00:04.0
All done.
# 创建实例:2 个小的 (1g.10gb) 和 1 个大的 (3g.40gb)
$ nvidia-smi mig -cgi 19,19,9 -C
Successfully created GPU instance ID 1 on GPU 0 using profile MIG 1g.10gb (ID 19)
Successfully created GPU instance ID 2 on GPU 0 using profile MIG 1g.10gb (ID 19)
Successfully created GPU instance ID 3 on GPU 0 using profile MIG 3g.40gb (ID 9)查看结果时,可以看到原本一块物理 GPU 已经暴露为多个独立 MIG 设备:
$ nvidia-smi -L
GPU 0: NVIDIA H100 80GB HBM3 (UUID: GPU-xyz-789)
MIG 1g.10gb Device 0: (UUID: MIG-aaa-111)
MIG 1g.10gb Device 1: (UUID: MIG-bbb-222)
MIG 3g.40gb Device 2: (UUID: MIG-ccc-333)从软件视角看,这已经不再是一块 GPU 上的多个上下文,而更像是三块独立 GPU:每个实例都有自己的 UUID、显存边界和计算资源。把工作负载分别放到不同实例上时,这种差异会非常明显:
# 终端 1:在 MIG 实例 0 上运行
$ CUDA_VISIBLE_DEVICES=MIG-aaa-111 python matrix_multiply.py
Starting matrix operations
Consistent performance: 1.20s, 1.21s, 1.20s, 1.21s
# 终端 2:同时在 MIG 实例 1 上运行
$ CUDA_VISIBLE_DEVICES=MIG-bbb-222 python inference.py
Running inference
Consistent latency: 45ms, 44ms, 46ms, 45ms
# 终端 3:在 MIG 实例 2 上运行
$ CUDA_VISIBLE_DEVICES=MIG-ccc-333 python training.py
Training model
Stable throughput: 1000 samples/sec这三个任务会同时运行,而不是排队轮转。没有额外等待,也没有因为共享执行管线而互相拖慢。再看监控输出时,这一点更加直观:
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
|=============================================================================|
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | Unc| CE ENC DEC OFA |
| | | Err| |
|=============================================================================|
| 0 1 0 0 | 3847MiB / 4864MiB | 14 0 | 0 0 0 0 |
| 0 2 0 1 | 1923MiB / 4864MiB | 14 0 | 0 0 0 0 |
| 0 3 0 2 | 15234MiB / 20096MiB | 42 0 | 2 0 2 0 |
+-----------------------------------------------------------------------------+每个实例都展示独立的显存和利用率指标,这说明这里发生的是真正的并行执行,而不是软件层面伪装出来的轮流共享。MIG 与 Kubernetes 的结合之所以相对优雅,也正是因为每个实例都可以作为独立资源被暴露出来。理论上,你可以手工在节点上完成这一切:
# 手动 MIG 设置(在节点上)
$ nvidia-smi -mig 1 # 启用 MIG 模式
$ nvidia-smi mig -cgi 19,14,9 -C # 创建配置文件
# 然后手动配置设备插件、更新节点标签等但在生产环境中,更常见的方式是借助 GPU Operator 自动化整个流程:
apiVersion: nvidia.com/v1
kind: ClusterPolicy
metadata:
name: gpu-cluster-policy
spec:
mig:
strategy: mixed # 允许每个节点使用不同的 MIG 配置文件
devicePlugin:
config:
default: default
name: device-plugin-config然后通过 ConfigMap 定义节点应采用的 MIG 配置:
apiVersion: v1
kind: ConfigMap
metadata:
name: device-plugin-config
namespace: gpu-operators
data:
default: |
version: v1
mig-strategy: none
mig-mixed: |
version: v1
mig-strategy: mixed
mig-devices:
"1g.5gb": 2
"3g.20gb": 1为节点打上对应标签后:
kubectl label node gpu-node-1 nvidia.com/mig.config=mig-mixedGPU Operator 自动:
- 启用 MIG 模式
- 创建指定的实例
- 配置设备插件以暴露它们
在 Pod 中使用 MIG 实例
MIG 的一个重大优势在于,它最终会表现为原生 Kubernetes 资源:
$ kubectl describe node gpu-node-1
Allocatable:
nvidia.com/mig-1g.5gb: 2
nvidia.com/mig-3g.20gb: 1因此,Pod 侧的使用方式也和请求其他资源一样自然:
apiVersion: v1
kind: Pod
metadata:
name: inference-pod
spec:
containers:
- name: inference
image: inference:latest
resources:
limits:
nvidia.com/mig-1g.5gb: 1这里不需要额外注解,也不需要调度器技巧;MIG 暴露出来的就是带硬件边界的原生资源。但它与 KAI-Scheduler 的差异也非常明显:
# KAI-Scheduler - 灵活但仅限软件的注解:
annotation:
gpu-memory: "3500" # 可以请求任意数量
# MIG - 硬件强制执行但配置文件固定
resources:
limits:
nvidia.com/mig-1g.5gb: 1 # 5GB 内存,14 个 SM你无法请求一个并不存在的 mig-1g.3.5gb。使用 MIG 时,资源形态由硬件预定义,调度只是从已有配置文件里做选择。想要 3.5GB 显存?那就只能在 1g.5gb 与 2g.10gb 之间二选一,而不能像软件注解那样声明一个任意值。这种不灵活正是硬件边界的代价。另一方面,它也带来了真正的强制执行能力。下面这个例子可以直接证明:
apiVersion: v1
kind: Pod
metadata:
name: memory-test
spec:
containers:
- name: test
image: cuda:latest
command: ["python"]
args: ["-c", "
import cupy as cp
print('Attempting to allocate 8GB...')
try:
x = cp.zeros((1024, 1024, 1024), dtype=np.float64) # 8GB
print('Success?!')
except Exception as e:
print(f'Failed as expected: {e}')
"]
resources:
limits:
nvidia.com/mig-1g.5gb: 1 # 获得约 5GB 限制运行该 Pod 后:
$ kubectl apply -f memory-test-pod.yaml
$ kubectl logs memory-test
Attempting to allocate 8GB
Failed as expected: cupy.cuda.memory.OutOfMemoryError: Out of memory allocating 8,589,934,592 bytes这里重要的不是日志中的错误本身,而是错误由谁触发:它不是某个软件代理“善意地”拒绝了请求,而是硬件边界直接使越界分配不可能发生。你不需要 API 拦截,也不需要假设工作负载会自觉合作。
MIG 的致命弱点:成本与架构权衡
MIG 几乎是 GPU 共享中的理想方案,但代价也同样真实。先看最直观的一点:成本。
# Azure 上的 H100 80GB(截至 2024 年)
Standard_NC40adsH100_v5: ~$6.98/小时 = ~$5,026/月
# Tesla T4 用于比较
Standard_NC4as_T4_v3: ~$0.53/小时 = ~$382/月一块 H100 的租用成本会比 T4 高出十余倍,但真正需要思考的并不仅仅是单卡价格,而是更深的架构选择:如果目标是为多个租户提供隔离资源,你究竟应该买一块支持 MIG 的 H100,还是直接购买七块 T4?对比如下:
| 方案 | 一块带 MIG 的 H100 | 七块 T4 GPU |
|---|---|---|
| 成本 | $5,026/月 | $2,674/月 |
| 总内存 | 80GB 共享 | 112GB 总计 (7×16GB) |
| Pod 放置 | 都在同一节点 | 跨 7 个节点 |
| 网络带宽 | 3.35TB/s(共享) | 各 320GB/s |
| 故障域 | 一个节点故障影响全部 | 隔离的故障 |
| 调度灵活性 | 固定在一个节点 | 可跨可用区分布 |
这个比较揭示了一个常被忽略的事实:在 H100 上启用 MIG,某种程度上就是在花高价把一张高端 GPU 变成若干更小的 GPU。它当然带来真实的硬件隔离,这是面对低信任或不可信工作负载时极具价值的特性;同时,H100 也确实具备更高的管理集中度、更适合紧耦合工作负载的高带宽互联,以及非常可观的片上带宽优势。但从系统设计角度看,七块 T4 带来的并不只是更低成本。它们还提供了更天然的故障隔离:一台 T4 节点宕机,不会像单节点 H100 那样把所有实例一起带倒;它们也提供了更高的地理分布灵活性,可以跨可用区部署,从而得到更真实的容灾能力。对于调度器来说,分布式小 GPU 还可能带来更灵活的装箱与节点选择,而单节点 H100 则天然把所有工作负载固定在同一个故障域和热点中。
还有一个不太令人愉快但必须面对的事实:MIG 只存在于 NVIDIA 最昂贵的一批 GPU 上,例如 A100、H100 以及 A30。许多组织已经拥有的是 T4,而不是这些高端型号;它们无法为 H100 的采购或租用成本找到合理性,却依然需要某种强制执行能力。正因为如此,单纯把 MIG 视为“标准答案”并不现实,软件强制执行方案才会变得重要。
HAMi:软件强制执行的革命
HAMi 走的是另一条路线:既然硬件没有提供像 MIG 那样的边界,那么就把控制点前移到软件栈中,在每一个关键 GPU API 调用进入驱动之前做检查与限制。要理解 HAMi 的工作方式,首先要回顾 CUDA 程序的调用路径。一个 CUDA 应用并不是直接与 GPU 对话,它通常会先调用用户态 CUDA 库,再通过驱动与内核和设备交互:
你的 Python 代码 → CUDA 运行时 (libcudart.so) → CUDA 驱动 (libcuda.so) → 内核驱动 → GPULinux 提供了一个极其有用的机制,叫做 LD_PRELOAD。它允许你在程序加载其他动态库之前,先插入自己的共享库。其基本过程是:
- Linux 加载你的程序
- 在加载 CUDA 库之前,它检查
LD_PRELOAD - 如果设置了,它先加载该库
- 该库可以替换(拦截)后续加载的库中的任何函数
从效果上看,当程序说“调用 cuMemAlloc”时,Linux 本来会把这次调用路由到真正的 CUDA 驱动库;HAMi 则利用 LD_PRELOAD 先行注入自己的库 libvgpu.so,从而在调用真正进入 CUDA Driver API 之前先截获它:
你的代码 → CUDA 运行时 → [HAMi 在此拦截] → CUDA 驱动 → GPU这与 cgroups 处理系统内存和 CPU 请求的方式有一种很强的类比关系:进程申请系统资源时,内核会在放行前检查 cgroup 限制;HAMi 做的事情,则是对 GPU 调用执行类似检查,只不过控制点不在内核系统调用层,而是在 CUDA 驱动 API 层。实际效果如下:
# 没有 HAMi - 直接 CUDA 访问
$ python -c "import torch; x = torch.zeros(2048, 2048, 512).cuda()" # 8GB 分配
# 成功 - 抓取了 8GB
# 使用 HAMi - 被拦截并限制
$ export LD_PRELOAD=/path/to/libvgpu.so
$ export CUDA_DEVICE_MEMORY_LIMIT=4g # 4GB 限制
$ python -c "import torch; x = torch.zeros(2048, 2048, 512).cuda()" # 8GB 分配
# RuntimeError: CUDA out of memoryHAMi 的核心作用类似一个持续记账的会计系统:它追踪每一次显存分配,并在超出预算时立即拒绝。应用程序申请显存时,大致会经历如下过程:
- 应用程序请求内存:“我需要 8GB 用于这个张量”
- HAMi 拦截:在请求到达 CUDA 驱动之前,HAMi 检查:
- 这个 Pod 的内存限制是多少?(4GB)
- 已经使用了多少?(1GB)
- 这个分配是否会超过限制?(1GB + 8GB > 4GB)
- HAMi 决定:
- 如果在限制内:将请求传递给 CUDA 驱动
- 如果超过限制:立即返回内存不足错误
- 跟踪:如果分配成功,HAMi 将其记录在表中:
- 内存地址、分配大小
- 该进程的运行总计
- 清理:当内存被释放时,HAMi 更新其记录
这正是它与 cgroups 的相似之处:系统内存由内核在 malloc() 背后做硬限制,GPU 显存则由 HAMi 在 cuMemAlloc() 之前进行检查。如果请求会超出 Pod 限制,HAMi 直接返回 OOM,而根本不把调用传给真正的 CUDA 驱动。更进一步地,对于那些会主动查询可用显存的应用程序,HAMi 还采用了一个非常关键的技巧:它会“虚构”一个受限后的设备视图。
当应用程序询问“这张 GPU 还有多少内存可用”时,HAMi 返回的不是物理 GPU 的真实答案,而是对该 Pod 而言的受限答案:
- 真实 GPU:“总共 16GB,空闲 12GB”
- HAMi 回答:“总共 4GB,空闲 3GB”(基于 Pod 的限制)
于是,行为良好的应用程序会误以为自己运行在一张更小的 GPU 上,并自然调整自身行为,从而避免连超限尝试都发生。
计算限流:令牌桶算法实战
显存限制相对直接,因为它天然是一个“允许或拒绝”的问题;计算限流则复杂得多。GPU 上的核函数一旦启动,HAMi 既不能在中途停止它,也不能在事后限制它到底占用了多少 SM。因此,当用户配置 nvidia.com/gpucores: 30 时,HAMi 实际表达的是一个目标 SM 利用率或计算吞吐比例,而不是“只允许使用固定数量的 SM”。为了逼近这个目标,HAMi 采用了类似网络限速的令牌桶算法,并把它挂接在 cuLaunchKernel 这样的核函数启动路径上。整个机制大致如下:
- 令牌计算:每次核函数启动根据网格块数量(gridDimX × gridDimY × gridDimZ)消耗令牌
- 令牌检查:在启动前,HAMi 检查是否有足够的令牌
- 阻塞等待:如果令牌不足,线程阻塞直到令牌积累
- 令牌消耗:一旦有可用令牌,扣除令牌,核函数启动
- 持续补充:后台线程根据实际 GPU 利用率补充令牌
其简化逻辑可以表示为:
// 当请求核函数启动时
function intercepted_kernel_launch(kernel, grid_dimensions, block_dimensions):
// 计算这个核函数需要多少令牌(基于网格大小)
token_cost = grid_dimensions // 实际上只是 grid,不是 grid × block
// 等待直到有足够的令牌
while (available_tokens < token_cost):
wait() // 阻塞线程
// 原子地消耗令牌(在实际实现中使用 CAS)
available_tokens = available_tokens - token_cost
// 启动实际的核函数
return real_cuda_kernel_launch(kernel, grid_dimensions, block_dimensions)
// 后台线程持续调整令牌
function token_manager():
while (true):
current_gpu_utilization = measure_gpu_utilization()
target_utilization = CUDA_DEVICE_SM_LIMIT // 例如 30%
if (current_gpu_utilization < target_utilization):
// 我们低于配额,添加更多令牌
tokens_to_add = calculate_increase(target - current)
available_tokens = available_tokens + tokens_to_add
else:
// 我们超过配额,减少令牌
tokens_to_remove = calculate_decrease(current - target)
available_tokens = max(0, available_tokens - tokens_to_remove)
sleep(interval) // 可配置的检查间隔这里真正巧妙的地方在于反馈回路。后台线程会通过 NVML(NVIDIA 管理库)持续观察实际 GPU 利用率,并动态调整令牌补充速度,从而把 Pod 的长期计算占比逐步拉向目标值。尽管如此,物理约束依然存在:如果一个核函数本身需要连续运行 30 秒,它仍然会完整运行 30 秒,HAMi 不能像 CPU 调度器那样在中途切断它。令牌桶所能做到的,是让这个 Pod 在消耗完令牌之后,必须等待令牌重新补充,才能继续提交下一批核函数。因此,它对大量短小核函数组成的工作负载更有效,对偶尔启动超长核函数的应用则效果有限。HAMi 也为此提供了几种策略选项:
- 默认策略:具有自适应补充的普通令牌桶
- 强制策略:严格将利用率限制在配置百分比以下
- 禁用策略:完全关闭计算限制
注意:如果在 HAMi 配置中
nvidia.disablecorelimit设置为 true,则无论 Pod 设置如何,计算限制都会被全局禁用。
因此,HAMi 对计算的强制执行从本质上仍然是“尽力而为”的:它不能违反 GPU 架构本身的物理规律,但它确实比简单地在核函数启动之间插入延迟要精细得多。由于 HAMi 不依赖特定高端 GPU,它的部署路径也相对直接:
# 添加 HAMi helm 仓库
$ helm repo add hami-charts https://project-hami.github.io/HAMi/
# 安装 HAMi
$ helm install hami hami-charts/hami \
--namespace kube-system \
--set scheduler.enabled=true \
--set devicePlugin.enabled=true安装后先验证组件状态:
$ kubectl get pods -n kube-system | grep hami
hami-device-plugin-ds-xvnbg 1/1 Running 0 2m
hami-scheduler-7b9d8954-kjplw 1/1 Running 0 2m安装成功后,HAMi 会向 Kubernetes 暴露新的资源类型:
apiVersion: v1
kind: Pod
metadata:
name: inference-with-limits
spec:
containers:
- name: inference
image: inference:latest
resources:
limits:
nvidia.com/gpu: 1 # 需要 GPU 访问
nvidia.com/gpumem: 4000 # 4GB 内存限制(强制执行!)
nvidia.com/gpucores: 30 # 30% 计算(尽力而为)与 KAI 的注解不同,这里已经是正式的 Kubernetes 资源模型。HAMi 对 nvidia.com/gpumem 提供真正的内存强制执行,而对 nvidia.com/gpucores 提供尽力而为的计算限流。下面这个例子展示了它如何阻止超量申请:
apiVersion: v1
kind: Pod
metadata:
name: hami-test-1
spec:
containers:
- name: memory-limited
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 2048 # 2GB 限制
command: ["python", "-c"]
args: ["
import tensorflow as tf
print('Allocated memory limit: 2048MB')
print('Attempting to allocate 3GB...')
')
try:
# Try to allocate 3GB
x = tf.random.normal([1024, 768, 1024])
print('Should not see this message!')
except Exception as e:
print(f'Blocked by HAMi: {e}')
"]
---
apiVersion: v1
kind: Pod
metadata:
name: hami-test-2
spec:
containers:
- name: compute-limited
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 4096
nvidia.com/gpucores: 20 # 20% 计算限制
command: ["python", "-c"]
args: ["
import time
import tensorflow as tf
print('Running with 20% compute limit')
start = time.time()
Heavy computation
for i in range(100):
x = tf.random.normal([2048, 2048])
y = tf.matmul(x, x)
duration = time.time() - start
print(f'Duration: {duration:.2f}s (throttle by HAMi)')
"]部署并检查:
$ kubectl apply -f hami-test.yaml
$ kubectl logs hami-test-1
Allocated memory limit: 2048MB
Attempting to allocate 3GB...
Blocked by HAMi: ResourceExhaustedError: OOM when allocating tensor
$ kubectl logs hami-test-2
Running with 20% compute limit
Duration: 45.23s (throttled by HAMi)
# 没有限流的话,这大约需要 10 秒这说明,即使在 Tesla T4 这类并不支持 MIG 的设备上,HAMi 也能实际约束显存和计算使用。
软件强制执行的现实
不过,HAMi 再强,也仍然是一种软件技巧,而不是像 MIG 那样的硬件边界。它最直接的风险之一是版本敏感性。CUDA API 会不断演进,新版本会引入新的分配函数或调用路径;一旦 HAMi 尚未适配这些变化,拦截链条就可能出现空洞。例如,在 CUDA 12.5 中出现新的内存分配函数 cuMemAllocAsync_v2 时,就可能出现如下情况:
$ nvidia-smi
Driver Version: 535.104.12 CUDA Version: 12.5
$ kubectl logs hami-device-plugin
ERROR: Unknown CUDA function cuMemAllocAsync_v2
WARNING: Cannot intercept new allocation API这意味着使用新 API 的应用有可能绕过 HAMi 的控制。更进一步地,LD_PRELOAD 本身终究只是运行时注入机制,而不是不可绕过的安全边界。具备足够知识的恶意用户理论上可以尝试绕过它:
# 恶意用户绕过 LD_PRELOAD
$ unset LD_PRELOAD
$ python gpu_memorygrab.py
# 成功抓取了所有 GPU 内存还可以使用静态链接规避动态加载器,或通过其他方式绕开预期调用路径。严格说来,拦截模型默认假设大多数工作负载是合作型的;面对蓄意规避时,它天然比硬件边界更脆弱。当然,HAMi 本身也实现了额外的 PID 跟踪和共享内存机制,使绕过不只是“取消一个环境变量”那么简单,但这并不会改变它是软件拦截层的事实。另一方面,性能开销也是必须接受的现实,因为每一次 CUDA 调用现在都要多经过一层逻辑:
# 没有 HAMi 的基准测试
Inference latency: 12.3ms
# 使用 HAMi 的基准测试
Inference latency: 14.1ms
# 拦截带来约 15% 的开销对于每秒触发成千上万次 CUDA 调用的训练任务,这种开销会积累成可感知的性能损失。但即便如此,HAMi 仍然在一个极其重要的维度上提供了价值:在没有硬件隔离可用的地方,它把“真正的强制执行”带到了现有 GPU 之上。对很多团队而言,这种现实主义的收益已经足够重要。
生产环境注意事项
无论选择 MIG 还是 HAMi,只要进入生产环境,就会暴露出概念验证阶段不明显的运维成本。对于 MIG 而言,最令人头疼的问题之一是配置文件锁定。MIG 切片配置一旦建立,后续想调整配置文件,通常需要先把节点彻底排空:
# 不能不排空节点就更改 MIG 配置文件
$ kubectl drain gpu-node-1
$ nvidia-smi mig -dci
$ nvidia-smi mig -dgi
# 用新配置文件重新创建
# 重新部署工作负载假设你现在把 H100 配置成七个 1g.10gb 实例来承载推理业务,半年后团队需要运行一个要求 3g.40gb 的更大模型时,你不能像改一个调度策略那样平滑调整,而必须驱逐运行中的工作负载,销毁现有 MIG 实例,重新创建新的切分布局,再把应用部署回来。这意味着维护窗口、工作负载迁移以及生产停机都将成为现实问题。这种刚性还会直接影响资源利用率,因为 MIG 配置必须以那七个基本单元为粒度进行组合:
# 这完美工作
mig-devices:
"1g.10gb": 7 # 使用所有 7/7 单元
# 这导致资源闲置
mig-devices:
"3g.40gb": 2 # 只使用 6/7 单元
# 你 GPU 的 1/7(H100 的 14%!)闲置着也就是说,最后那个 $1/7$ 单元可能长期闲置,而你仍然要为这部分昂贵硬件埋单。HAMi 则有另一类运维痛点。它不受固定硬件切片约束,但会把驱动升级变成一片雷区:
# 驱动更新后
$ kubectl logs hami-device-plugin
Warning: CUDA 12.5 detected, HAMi tested up to 12.2
Some interceptions may fail
# 解决方案:等待 HAMi 更新或固定驱动版本每一次 NVIDIA 驱动升级都可能让 HAMi 的拦截逻辑失效,于是团队不得不在“继续停留在旧驱动版本”与“冒着 HAMi 兼容性风险升级驱动”之间做取舍。很多团队因此会维护详细的驱动兼容性矩阵,并在每次升级前做大量验证。与此同时,监控体系也会变得复杂,因为物理 GPU 视图与 HAMi 的逻辑配额视图并不总是一致:
# nvidia-smi 显示物理使用情况
$ nvidia-smi
Memory-Usage: 15GB / 16GB # 看起来几乎满了!
# 但 HAMi 的视图不同
$ kubectl exec hami-monitor -- hami-status
Pod A: 2GB used of 4GB limit
Pod B: 3GB used of 4GB limit
Pod C: 4GB used of 4GB limit
Pod D: 6GB used of 8GB limit # 过度配置!
# 总计:已分配 15GB,但限制总和是 20GB!当 nvidia.deviceMemoryScaling > 1 时,这种“逻辑限制总和大于物理内存”的现象甚至是被故意允许的,类似于 Linux 中对内存进行过量分配。于是问题就变成:你该相信哪个监控系统?告警阈值应该基于物理显存使用量,还是基于 HAMi 的逻辑限制视图?这些已经不只是技术细节,而是需要团队培训、文档体系和运维流程共同消化的组织性问题。
GPU 共享的演进
回顾整条演进路径,可以看到 GPU 共享已经从最初“多个容器无协调地共同访问一块设备”,发展到通过 MPS、时间分片和 KAI-Scheduler 进行编排,再进一步发展到 HAMi 这种软件强制执行,以及 MIG 这种真正的硬件分区。路径的每一步都在试图回答同一个问题:共享能否被控制、被观察、被信任。但无论最终选择 MIG 的硬件隔离,还是 HAMi 的软件拦截,你都不可避免地进入同一个新的运维阶段:如何确认这些机制真的在工作?如何跨不同共享模型统一监控 GPU 利用率与显存占用?又如何在度量方式彼此不同的前提下做出合理的资源优化?这正是后续章节要继续讨论的方向。
关键要点
- 一旦编排层无法再约束共享关系,就必须引入真正的强制执行机制,否则共享只会停留在“登记了资源”而不是“控制了资源”。
- MIG 提供的是最接近理想状态的答案,因为它把并行执行、显存隔离和故障边界都落实为硬件事实。
- MIG 的代价同样明确:它只存在于少数高端 GPU 上,资源粒度固定,配置调整刚性强,成本和架构约束都不可忽视。
- HAMi 代表的是软件强制执行路线,它通过 API 拦截把类似 cgroup 的控制能力带到现有 GPU 上,因此更适合已经部署大量 T4 等设备的现实环境。
- HAMi 不如 MIG 绝对,它必须面对版本兼容、绕过风险和额外开销,但在缺少硬件隔离条件时,往往是更可落地的治理手段。
- 最终的选择不该由“哪项技术更高级”决定,而应由信任模型、成本约束、工作负载特征以及可接受的运维复杂度共同决定。