GPU 共享编排:Kubernetes 如何管理轮转
本章将讨论以下几个问题:
- GPU 如何通过自动上下文切换始终支持多个进程
- 为什么 GPU 内存不像 CPU 内存那样在进程之间分区
- KAI-Scheduler 如何使用"预留 Pod"来欺骗 Kubernetes 实现 GPU 共享
- NVIDIA"时间分片"实际做了什么(剧透:它不是时间分片)
- 为什么两种方案都不能提供真正的隔离或公平性保证
- 编排共享与强制执行共享之间的关键区别
理解 Kubernetes 中的 GPU 共享,首先要澄清一个常见误解:GPU 并不是到了 Kubernetes 时代才开始支持“共享”,真正新出现的只是围绕这种共享建立的编排方法。
隐藏的真相:GPU 早已支持共享
GPU 从很早开始就能够被多个进程共同使用。下面是在测试机器(Tesla T4)上的一个简单演示:
$ python matrix_multiply.py
Starting matrix operations on GPU 0...
Iteration 1: 1.23s
Iteration 2: 1.21s
Iteration 3: 1.24s在它运行的同时,再打开另一个终端:
$ python vector_add.py
Starting vector addition on GPU 0...
Iteration 1: 0.89s
Iteration 2: 1.45s # 更慢 - 与矩阵乘法竞争
Iteration 3: 0.91s两个进程都在使用同一块 GPU。检查 nvidia-smi:
$ nvidia-smi
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
|=============================================================================|
| 0 N/A N/A 4521 C python matrix_multiply.py 2341MiB |
| 0 N/A N/A 4627 C python vector_add.py 1122MiB |
+-----------------------------------------------------------------------------+这里已经能看到关键事实:一块 GPU、两个进程、同时处于运行状态,而且不需要任何额外配置。这并不是 Kubernetes、MPS 或某个调度器带来的新能力,而是 CUDA 生态本来就具备的基础行为。问题不在于“能否共享”,而在于这种共享究竟以什么方式发生,以及它为什么与人们熟悉的 CPU 共享模型差异如此之大。
理解 GPU 上下文切换
当多个进程使用同一块 GPU 时,它们的执行方式并不像 CPU 上的线程调度那样“同时向前推进”。GPU 的运行模型与 CPU 根本不同:一旦某个 CUDA 核函数启动,它通常会独占相关计算资源直到执行结束,中途不能像 CPU 任务那样被任意暂停、保存状态并切换出去。因此,多个进程之所以都能“使用”同一块 GPU,并不是因为它们的核函数被精细地交错执行,而是因为它们在驱动层面轮流提交和运行工作。
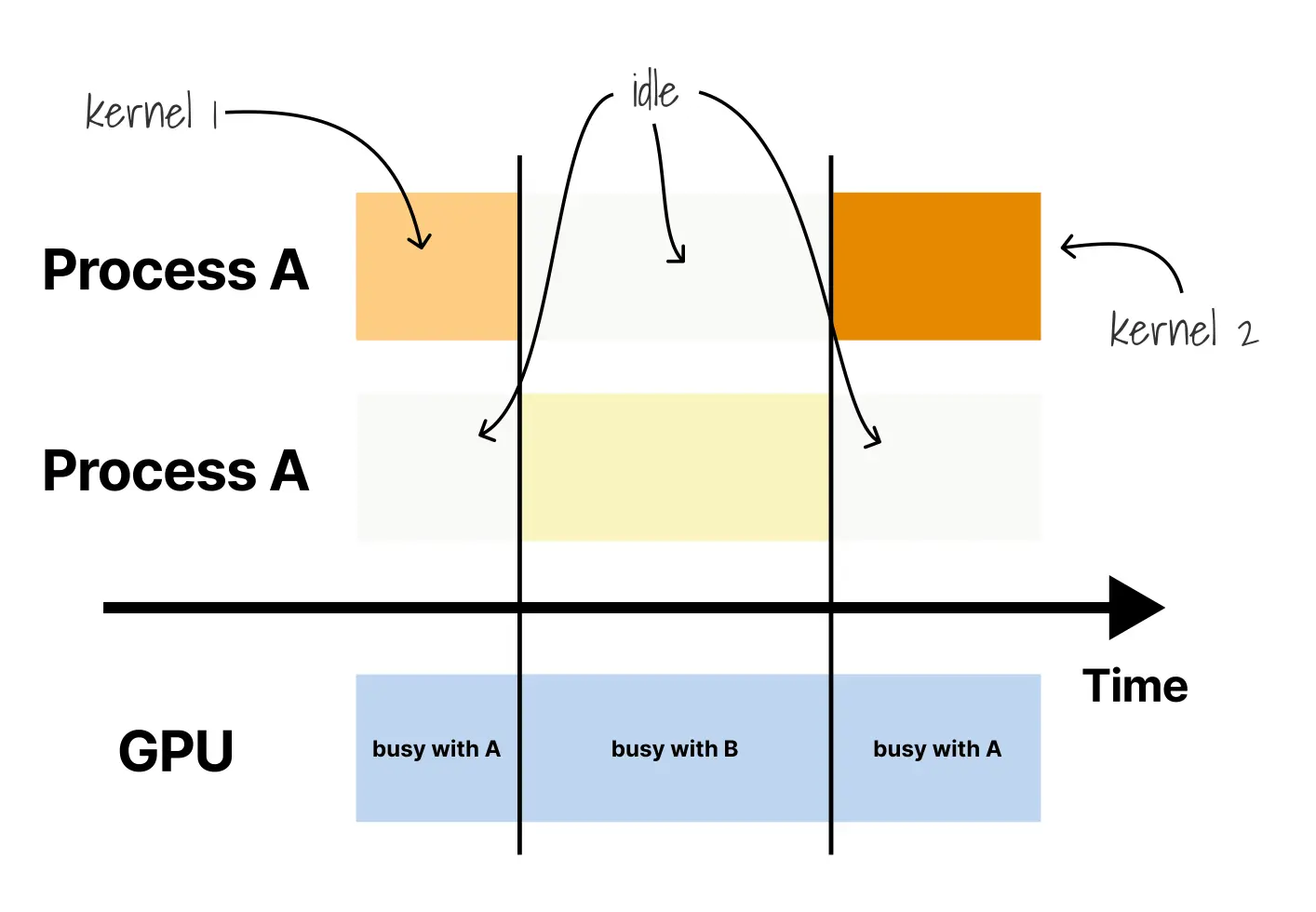
换言之,每个核函数都是运行到完成后才让出执行机会;进程 A 的核函数结束,进程 B 的核函数才能上场。NVIDIA 驱动负责维护不同进程提交的工作队列,并按自己的策略一个接一个地调度它们,这就是 GPU 世界中的驱动级上下文切换。它会自动发生,但这并不意味着 GPU 具备了 CPU 那种强抢占、公平时间片和细粒度资源配额的能力。更重要的是,这种“轮流执行”的表象很容易让人误以为内存也会像执行时间一样被干净切分,而事实恰恰相反。
内存幻觉
GPU 共享最容易误导人的地方在于显存模型。假设你有一块 24GB 的 GPU,打算同时运行:
- 需要约 16GB 的应用 A
- 需要约 8GB 的应用 B
直觉上,这看起来似乎正好可以放下,因为 $16 + 8 = 24$。但实际情况比这个算术题复杂得多:
# 启动应用 A
$ python app_a.py
Allocating 16GB of GPU memory...
Allocated successfully. GPU memory available: 8GB remaining
# 启动应用 B
$ python app_b.py
Allocating 8GB of GPU memory...
Error: CUDA out of memory. Tried to allocate 8GB (8GB free)表面上还有 8GB 空闲,为什么仍然失败?因为应用 B 需要的并不只是那 8GB 数据本身,它还要为如下部分预留空间:
- CUDA 上下文开销(约 300-500MB)
- 核函数代码
- 临时缓冲区
- 驱动分配
更重要的是,每个应用都维护着自己的 CUDA 上下文和各自的显存分配。上下文本身是分离的,但它们并不是从互不相干的私有显存池中取内存,而是共同从同一块物理显存中提取资源。当应用 A 分配了 16GB 显存后,这些显存会被保留在它的上下文里,只要上下文还活着,就不会自动回到公共池中。因此,应用 B 并不能“借用”那 16GB;它只能在剩余空间里继续申请,而这就意味着所有活动上下文的显存占用总和必须同时塞进物理 GPU 的总容量中。
这里还有一个更容易让人忽略的细节:显存占用不仅来自“长期持有”的数据,还来自核函数执行期间的临时工作空间。例如:
# 两个应用都预先分配了内存
App A: 16GB 已分配
App B: 7GB 已分配
Total: 23GB 已使用, 1GB 可用
# 核函数执行期间
Time T1: App A 核函数运行 - 需要 500MB 临时空间 (失败 - 可用空间不足)
Time T2: App B 核函数运行 - 在其 7GB 内成功运行这意味着,上下文中长期持有的显存和核函数运行时需要的临时工作区必须一起被计算在内;如果临时空间无法满足,核函数仍然会失败,即使该上下文已经拥有一大块“静态”分配的显存。为了把这个问题说得更具体,下面回到第一章中出现过的一个简单计算例子:
# 这段 Python 代码在 CPU 上运行
import cupy as cp
# 在 GPU 上创建数组 - 每个数组分配内存
x = cp.array([1, 2, 3]) # 为 x 分配内存
y = cp.array([4, 5, 6]) # 为 y 分配内存
# 这会在 GPU 上触发核函数启动
z = x + y # 核函数 1:加法核函数执行
# 这会触发另一个核函数启动
w = x - z # 核函数 2:减法核函数执行在这个例子中,显存变化过程是:
- 当我们创建 x 和 y 时,CuPy 为每个数组分配 GPU 内存
- 当我们计算 z = x + y 时,需要内存来存储结果
- 变量 z 不仅仅是一个临时计算——它是需要 GPU 内存的实际数据
- 当我们计算 w = x - z 时,需要更多内存来存储结果
如果配合显存跟踪来看,变化会更直观:
import cupy as cp
# 检查初始 GPU 内存
print(f"Initial GPU memory: {cp.cuda.MemoryPool().used_bytes()} bytes")
# 分配一些大数组
x = cp.ones((1000, 1000), dtype=cp.float32) # 4MB
print(f"After x: {cp.cuda.MemoryPool().used_bytes() / 1024**2:.2f} MB")
y = cp.ones((1000, 1000), dtype=cp.float32) # 另一个 4MB
print(f"After y: {cp.cuda.MemoryPool().used_bytes() / 1024**2:.2f} MB")
# 计算 z = x + y(需要内存存储结果)
z = x + y
print(f"After z = x + y: {cp.cuda.MemoryPool().used_bytes() / 1024**2:.2f} MB")
# 计算 w = x * z(需要更多内存)
w = x * z
print(f"After w = x * z: {cp.cuda.MemoryPool().used_bytes() / 1024**2:.2f} MB")
# Output:
# Initial GPU memory: 0 bytes
# After x: 4.00 MB
# After y: 8.00 MB
# After z = x + y: 12.00 MB
# After w = x * z: 16.00 MB这里最关键的事实是:每一个中间结果都会消耗显存,而且只要相应变量还存在,这部分显存就会保持占用。把这种模式扩展到多应用场景,问题就会迅速变得复杂:
# 应用 A 启动
App A: 分配 8GB 用于模型权重
App A: 分配 2GB 用于输入数据
App A: 需要 3GB 用于中间计算
应用 A 总计:13GB
# 应用 B 尝试在 16GB GPU 上启动
App B: 分配 2GB 用于其模型
App B: 分配 1GB 用于数据
App B: 尝试分配 2GB 用于中间结果
崩溃:内存不足 (13GB + 2GB + 1GB + 2GB = 18GB > 16GB)即使应用 B 从业务角度看“只需要”3GB 常驻显存,用于中间结果的临时空间也足以让总需求越过物理上限。这就是 GPU 显存管理比 CPU 内存直觉更难把握的原因:应用不只需要存放数据,还需要为计算过程留出生存空间;而 GPU 显存又不像 CPU 内存那样可以被内核换出、压缩或延迟回收。要么所有长期分配和临时工作区都能同时放下,要么核函数直接失败。理解了这一点,才能看懂 Kubernetes 在 GPU 编排上究竟试图解决什么问题,又为什么只能解决其中一部分。
Kubernetes 编排问题
Kubernetes 对 CPU 和系统内存的共享处理得相当优雅。例如,当你写下:
resources:
requests:
memory: "2Gi"
cpu: "500m" # 0.5 个 CPU 核心
limits:
memory: "4Gi"
cpu: "1" # 1 个 CPU 核心Kubernetes 理解分数资源,也能借助 cgroups 强制执行限制,并据此完成调度与隔离。但 GPU 完全打破了这套模型。当你写下:
resources:
limits:
nvidia.com/gpu: 1你请求的就是整块 GPU,而不是它的一部分。你不能写出类似下面这样的语义:
# 你不能这样做:
resources:
limits:
nvidia.com/gpu: 0.5 # 错误:必须是整数
nvidia.com/gpu-memory: 2Gi # 错误:没有这种资源这意味着 Kubernetes 并没有原生的 GPU 共享概念。如果你希望两个 Pod 共享同一块 GPU,就必须额外解决以下问题:
- 让两个 Pod 都调度到同一节点
- 让两个 Pod 都看到同一块物理 GPU
- 防止 Kubernetes 将该 GPU 分配给其他 Pod
- 跟踪谁在使用什么(即使你无法强制执行)
如果手工处理这些细节,几乎不可维护。因此,现实世界里通常会借助额外的编排机制自动化这一过程。下面考察两种典型方案:KAI-Scheduler 与 NVIDIA 设备插件提供的“时间分片”。
KAI-Scheduler 的预留 Pod 策略
KAI-Scheduler 解决 GPU 共享问题的方式,本质上是一个非常巧妙的变通:既然 Kubernetes 只理解整块 GPU,而用户却想请求某个“分数”或某个显存量,那么就先用一个占位对象把整块 GPU 预留下来,再在这个预留之上做内部共享。
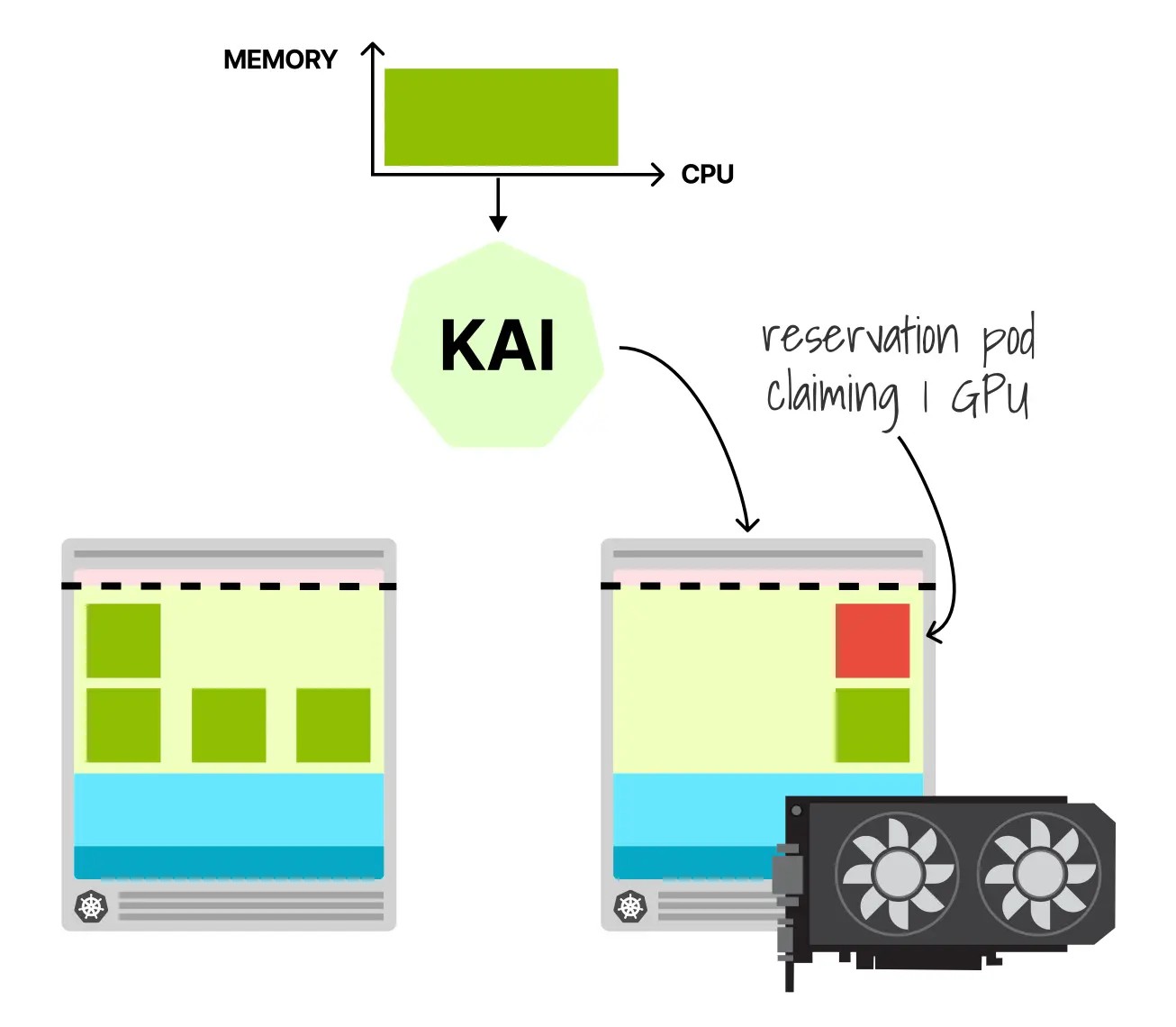
假设现在有一个只需要 2GB GPU 显存的推理服务。由于 Kubernetes 本身不理解 GPU 显存请求,KAI-Scheduler 定义了自己的注解体系:
apiVersion: v1
kind: Pod
metadata:
name: inference-service
annotations:
gpu-memory: "2000" # 以 MiB 为单位 - KAI 的自定义注解
spec:
schedulerName: kai-scheduler # 必须使用 KAI,不是默认调度器
containers:
- name: inference
image: inference:latest
# 注意:resources 中没有 nvidia.com/gpu,因为 KAI 将处理 GPU 共享这里的 `gpu-memory` 注解以 MiB 为单位,充当了 KAI 对“GPU 显存请求”这一缺失能力的补丁。当这个 Pod 被提交后,KAI-Scheduler 会先寻找一块仍有至少 2GB 可用显存的 GPU;假设它选中了 `node-1` 上的一块 Tesla T4(16GB 总显存),随后会创建一个特殊的“预留 Pod”:
apiVersion: v1
kind: Pod
metadata:
name: gpu-reservation-node1-abc123
namespace: kai-resource-reservation
labels:
runai-gpu-group: group-xyz-789 # 将此 GPU 链接到用户 Pod
spec:
nodeName: node-1 # 显式放置在 node-1 上
runtimeClassName: nvidia # KAI 要求
containers:
- name: resource-reservation
image: kai-resource-reservation:latest # KAI 的发现组件
resources:
limits:
nvidia.com/gpu: 1 # 声明整块 GPU这个预留 Pod 会向 Kubernetes 声明整块 GPU,因此在默认调度器看来,这块 GPU 已经被完全占用,不应再分配给其他普通 Pod。问题在于,KAI-Scheduler 还需要知道:这个预留 Pod 最终究竟拿到了哪一块物理 GPU。于是,当预留 Pod 启动后,kubelet 与设备插件会实际给它分配一块具体的 GPU,例如 GPU-abc-def-123,而预留 Pod 内部运行的 KAI 控制器则会主动完成发现与回写:
- 使用 NVML 发现它被分配了哪块 GPU
- 用 GPU 索引更新自己的 Pod 注解
# 在预留 Pod 的控制器内部
$ nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-abc-def-123)
# 控制器更新 Pod 注解
$ kubectl annotate pod gpu-reservation-node1-abc123 \
run.ai/reserve_for=gpu_index=GPU-abc-def-123一旦这个映射关系建立,KAI-Scheduler 就能够继续完成用户 Pod 的精细编排:
- 将你的
inference-servicePod 调度到node-1(与预留同一个节点) - 添加
runai-gpu-group标签将其链接到预留 Pod - 设置环境变量
NVIDIA_VISIBLE_DEVICES=GPU-abcdef-123,确保它看到同一块 GPU - 更新其内部跟踪:“GPU-abc-def-123 已分配 2GB,空闲 13GB”
如果随后又有一个 Pod 请求 4GB GPU 显存,例如:
metadata:
annotations:
gpu-memory: "4000" # 以 MiB 为单位那么 KAI-Scheduler 会重复同样的流程:
- 看到 GPU-abc-def-123 有 13GB 空闲
- 将这个 Pod 调度到 node-1
- 添加相同的
runai-gpu-group标签将其链接到现有预留 - 设置
NVIDIA_VISIBLE_DEVICES=GPU-abc-def-123(同一块 GPU!) - 更新跟踪:“GPU-abc-def-123 已分配 6GB,空闲 10GB”
最终,两个 Pod 都会看到同一块 GPU。
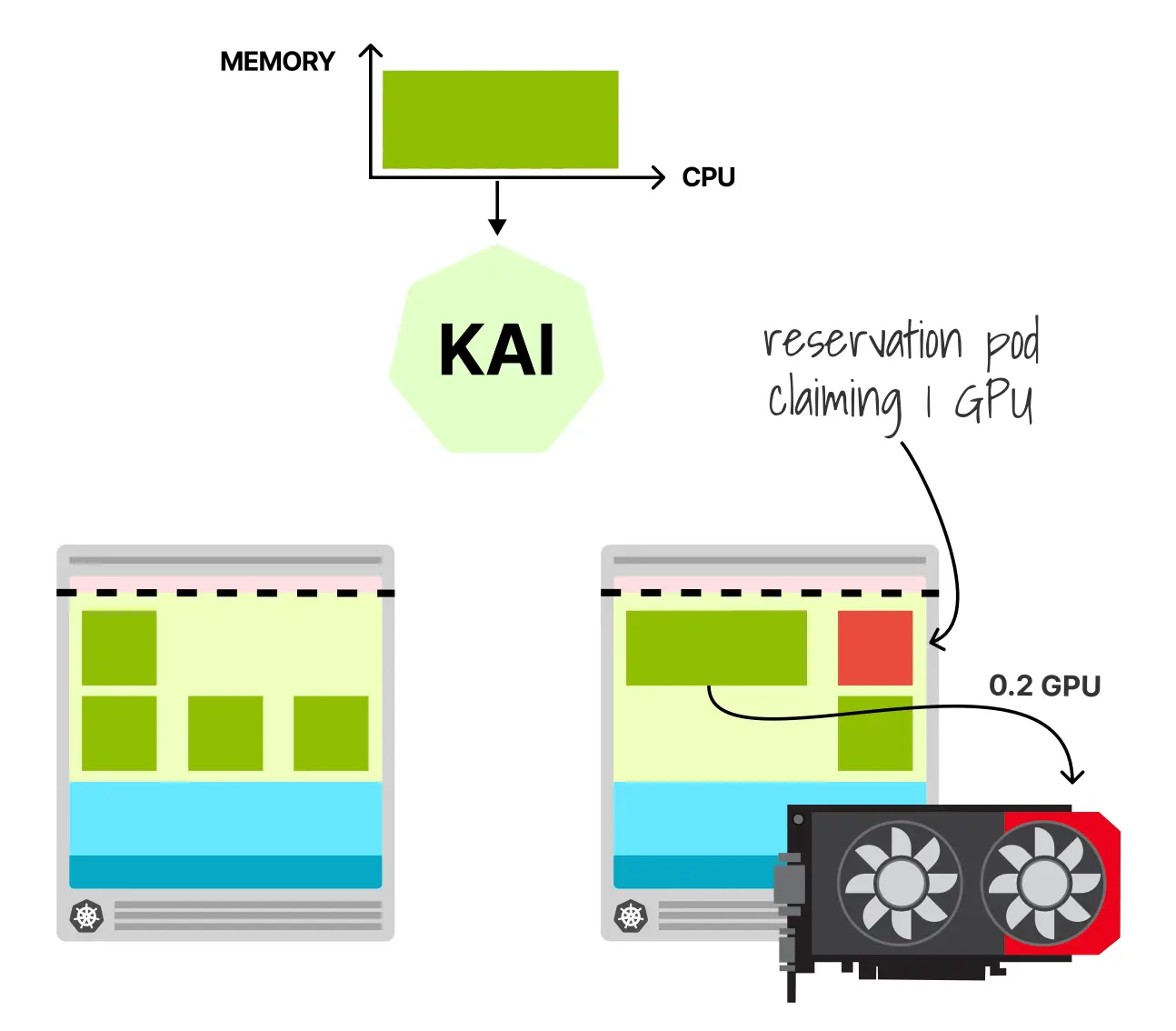
从应用视角看,它们现在都能访问同一个物理设备,并像前面的手工示例一样轮流运行核函数。也就是说,KAI-Scheduler 解决的不是 GPU 的底层共享机制,而是“如何让 Kubernetes 同意并协调这种共享”。
KAI:巧妙之处与局限性
KAI-Scheduler 的真正巧妙之处,在于它弥合了“用户真正想要表达的资源需求”和“Kubernetes 原生能理解的资源模型”之间的缺口。用户想表达的是“这个推理服务需要 2GB 显存,那个训练任务需要 8GB 显存”;Kubernetes 理解的却只有“要一整块 GPU 还是不要”。KAI 通过预留 Pod 与自定义注解,把这种差距转化为可操作的调度逻辑:它能跟踪每块 GPU 已分配了多少显存,根据剩余容量决定把新 Pod 放到哪里,也能把多个小型推理任务打包进同一块 GPU,或者把大多数资源留给大型训练作业。
但理解 KAI 的价值时,必须同样清楚它没有做什么。首先,它没有显存强制执行能力。一个声称自己只需要 2GB 的 Pod,如果实际申请了 15GB 显存,KAI 无法阻止它;KAI 可以记录“这个 Pod 本该只拿 2GB”,却无法阻止它在运行时把所有可用显存都吞掉。其次,它也没有计算隔离能力。一个 Pod 完全可以启动一个持续 30 秒的长核函数,从而阻塞其他 Pod 的执行;KAI 既不能中断这个核函数,也不能确保公平轮转。进一步说,它甚至没有真正的公平性保证。GPU 时间最终仍由底层驱动和核函数提交模式决定,谁先提交、谁更频繁提交、谁的核函数更长,都会影响其他工作负载的体验。因此,KAI-Scheduler 做的是“编排共享”,而不是“强制执行共享”。即便它还支持 gpufraction: "0.5" 这类更细粒度的表达,或者通过其他注解请求多个分数 GPU,底层现实依旧没有改变:它协调了共享,但没有创造出新的硬件隔离机制。
NVIDIA “时间分片”:误导性的名称
NVIDIA 的设备插件还提供了一个名为“时间分片”的能力。这个名字非常具有诱导性,因为它会让人自然联想到 CPU 时间片模型:好像 GPU 会像 CPU 一样,把执行时间公平地切成若干小片,轮流分发给不同 Pod。然而,这种理解是错误的。先看配置方式:
configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: nvidia-device-plugin-config
namespace: kube-system
data:
config.yaml: |
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4 # 让 1 块 GPU 看起来像 4 块应用这段配置并重启设备插件后,节点上展示出来的资源会变成:
$ kubectl describe node node-1
Capacity:
nvidia.com/gpu: 4 # 原来是 1,现在报告 4!
Allocatable:
nvidia.com/gpu: 4也就是说,一块物理 GPU 现在在 Kubernetes 看起来像四块 GPU。这里真正发生的事情并不是 GPU 被物理切开,而是设备插件向 Kubernetes 报告了一个“放大后的资源视图”。换句话说,物理上仍然只有一块 GPU,但 Kubernetes 被告知这里有四个可调度单元。于是,当你部署四个 Pod、每个都请求 nvidia.com/gpu: 1 时:
# Pod 1
resources:
limits:
nvidia.com/gpu: 1 # 认为自己获得了整块 GPU
---
# Pod 2
resources:
limits:
nvidia.com/gpu: 1 # 也认为自己获得了整块 GPU
# Pod 3 和 4:同样如此Kubernetes 会理直气壮地把这四个 Pod 都调度到同一节点上,而且每个 Pod 都会认为自己得到了“一个完整的 GPU”。然而,真正进入容器内部之后,看到的却是同一个物理设备:
$ kubectl exec pod-1 -- nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-abc-def-123)
$ kubectl exec pod-2 -- nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-abc-def-123) # 同一块 GPU!
$ kubectl exec pod-3 -- nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-abc-def-123) # 同一块 GPU!
$ kubectl exec pod-4 -- nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-abc-def-123) # 同一块 GPU!因此,这四个 Pod 看到的其实是同一块 Tesla T4,它们仍然只能像前面手工运行 matrix_multiply.py 与 vector_add.py 那样,依靠底层驱动轮流执行核函数。所谓“时间分片”在这里并没有创造新的执行机制,它只是改变了 Kubernetes 对资源数量的认知。
为什么"时间分片"具有误导性
“时间分片”这个名字之所以危险,是因为它会制造关于公平性和隔离性的虚假预期。在 CPU 调度中,时间分片具有非常明确的技术含义:每个进程获得固定时长的运行窗口,时间一到,内核就强制暂停它并切换到下一个进程。正因为内核能够强制中断和切换,CPU 时间片才真正构成了公平性机制。GPU 的所谓“时间分片”完全没有这些性质。你也许会以为,当副本数为 4 时,每个 Pod 会按照轮询方式获得大致相等的执行窗口,例如每次 250ms;但实际情况并非如此,GPU 上的轮转依旧发生在核函数自然结束之后,而不是由某个更高层的调度器强制切换。
因此,它既没有真正的公平调度,也没有真正的抢占能力。如果 Pod A 启动了一个持续 5 秒的长核函数,那么 Pod B、C、D 只能等它完整跑完;Pod A 不会因为“已经用完自己的公平时间”而被强制让出 GPU,它完全可以通过不断提交长核函数来主导整块设备。这不是设备插件实现不够好,而是 GPU 架构本身的限制:核函数一旦启动,就通常只能运行到完成,软件层无法把它像 CPU 任务那样中途剥离。 从这个意义上说,NVIDIA 所谓的“时间分片”更准确的名字应该是“GPU 副本模式”或“GPU 多路复用视图”。它做的事情是让一块 GPU 在 Kubernetes 看起来像多块 GPU,而不是对时间进行真正的切片与管理。
时间分片的关键局限性
这就引出了时间分片最关键的局限性。首先,它依然不允许你请求具体数量的显存:
# 你不能这样做:
annotations:
gpu-memory: "4000" # 时间分片不支持这个
# 你只能做:
resources:
limits:
nvidia.com/gpu: 1 # 仍然是"一块 GPU"(实际上是 1/4)虽然在概念上每个 Pod 似乎拿到了一个 1/N 的份额,但从运行时视角看,它们依然都看见完整的 GPU。更严重的问题是,时间分片完全没有显存跟踪能力。相比之下,KAI-Scheduler 至少还维护了某种内部状态,知道某块 GPU 已经“分配了多少显存、还剩多少”,并据此避免把明显放不下的工作负载继续塞进去;运维人员也可以从这些状态中获得一些容量规划线索。时间分片则没有任何这类智能。它既不知道某个 Pod 实际需要 100MB 还是 10GB 显存,也不会记录当前每个 Pod 实际消耗了多少显存。你无法询问“Pod A 现在用了多少显存”,因为系统根本没有跟踪这些信息。你所知道的只是:这块 GPU 看起来有 4 个插槽,其中 4 个都被占满了。除此之外,几乎一无所知。这种缺乏显存核算和观测能力的特征,使时间分片在生产环境中特别危险,因为你几乎是在盲飞,直到工作负载开始因 OOM 而崩溃,问题才会显性化。
比较两种方案:相同的现实,不同的技巧
从这个角度看,KAI-Scheduler 与 NVIDIA“时间分片”虽然表面形式不同,但底层现实非常接近。它们的差异可以概括为:
| 方面 | KAI-Scheduler | NVIDIA “时间分片” |
|---|---|---|
| 如何欺骗 Kubernetes | 预留 Pod 声明整块 GPU | 设备插件报告 N 个虚假 GPU |
| 节点放置 | 自动(KAI 处理) | 手动(你确保 Pod 共置) |
| 内存感知 | 有(通过注解跟踪) | 无(固定插槽) |
| 灵活打包 | 有(2GB + 4GB + 8GB 的 Pod) | 无(N 个相等插槽) |
| 实际 GPU 行为 | 上下文切换 | 上下文切换 |
| 内存隔离 | 无 | 无 |
| 计算隔离 | 无 | 无 |
| 公平调度 | 无 | 无 |
这张表最值得注意的地方,不是它们在哪些方面不同,而是它们在哪些关键方面完全相同:两种方案最终都只是让多个进程在一块 GPU 上轮流执行;两者都不提供真正的内存隔离、计算隔离或公平调度。换言之,它们只是两种不同的编排技巧,而不是两种不同的强制执行机制。
实际示例:调度器对决
为了更具体地看出差异,设想下面这个实际场景。你有一块 Tesla T4(16GB 显存),需要同时运行:
- 2 个推理服务(每个 2GB)
- 1 个训练作业(8GB)
- 1 个数据预处理作业(3GB)
按纸面数字计算,总请求正好是 16GB,看起来似乎可以完美放下。先看 KAI-Scheduler 会如何处理。假设我们用内存注解(MiB)提交这四个 Pod:
$ kubectl apply -f inference-1.yaml # gpu-memory: "2000"
$ kubectl apply -f inference-2.yaml # gpu-memory: "2000"
$ kubectl apply -f training.yaml # gpu-memory: "8000"
$ kubectl apply -f preprocessing.yaml # gpu-memory: "3000"
$ kubectl get pods
NAME READY STATUS NODE
inference-1 1/1 Running node
inference-2 1/1 Running node
training 1/1 Running node
preprocessing 1/1 Running nodeKAI 会把它们全部调度到同一节点,并通过同一个预留 Pod 共享一块 GPU。就编排层面而言,它成功了:内存请求被记录下来,资源看起来也被高效打包了。但真正进入运行时之后,情况可能是:
$ kubectl logs training
Epoch 1: Training: Allocated 11GB for gradients
# 使用了超过"请求"的 8GB!
$ kubectl logs preprocessing
ERROR: CUDA out of memory
# 因为训练使用了额外的内存而崩溃这里的问题很清楚:KAI 编排了共享,却无法强制执行声明时写下的显存上限。现在再用时间分片重复同样的实验:
# 在 node-1 上配置了四个副本的时间分片
# 每个 Pod 请求一个"GPU"
$ kubectl apply -f inference-1.yaml # nvidia.com/gpu: 1
$ kubectl apply -f inference-2.yaml # nvidia.com/gpu: 1
$ kubectl apply -f training.yaml # nvidia.com/gpu: 1
$ kubectl apply -f preprocessing.yaml # nvidia.com/gpu: 1
$ kubectl get pods -o wide
NAME READY STATUS NODE
inference-1 1/1 Running node-1
inference-2 1/1 Running node-1
training 1/1 Running node-1
preprocessing 1/1 Running node-1所有 Pod 同样会顺利调度到 node-1,因为时间分片已经让节点对外宣称自己拥有 4 块 GPU。区别在于,这里连 KAI 那种最起码的内存感知都没有。系统不会理解每个 Pod 希望使用多少显存,也不会据此做出更保守的摆放决策。每个 Pod 都认为自己获得了一块完整 GPU,于是训练作业完全可能直接申请 12GB 甚至 15GB 显存,并把其他工作负载顶爆:
$ kubectl logs training
Loading model... Allocated 12GB for weights and gradients
Training epoch 1/100...
$ kubectl logs preprocessing
ERROR: CUDA out of memory
Crashed because training consumed most of the GPU memory编排共享总结
到这里,可以对这两类方案下一个清晰结论:它们都是编排层能力,而不是隔离机制。它们试图回答的问题是“如何让 Kubernetes 接受多个 Pod 共享同一块 GPU”,却没有真正回答“当这些 Pod 真正共享 GPU 时,如何保证它们和谐共处”。因此,这两种方案最适合用于高信任环境,也就是下列条件大体成立的场景:
- 应用程序行为良好
- 开发人员协调资源使用
- 内存需求可预测
- 核函数执行时间合理
一旦进入对抗性更强的多租户环境,仅仅编排共享就不够了,你需要真正的强制执行能力。这也正是 HAMi 这类通过 CUDA API 拦截实现控制的方案,或 MIG 这种通过硬件分区提供边界的方案开始变得重要的原因。不过,这已经超出了本章范围。
关键要点
- 理解 Kubernetes 中的 GPU 共享,必须把“编排谁共享”与“运行时如何执行”明确区分开来。
- 多个工作负载共享一块 GPU 并不新鲜,驱动层早就能通过上下文切换实现;真正困难的是显存和执行管线并不会因此自然分区。
- KAI-Scheduler 和 NVIDIA 所谓的“时间分片”本质上都在做编排,而不是创造新的隔离机制;它们解决的是资源声明与调度表达,不是运行时强制执行。
- 在这些方案下,底层仍然是多个上下文在同一块 GPU 上轮流执行,因此既没有可靠的内存边界,也没有真正的公平性保证。
- “时间分片”这类名称很容易误导判断,因为它并不真正切开物理 GPU,只是改变了 Kubernetes 所看到的资源数量和调度表象。
- 所以问题从来不是“能不能共享”,而是“能不能在共享时仍然做到安全、可控且公平”,这正是下一步必须进入强制执行层的原因。