使用 vCluster 构建多租户 GPU 平台
到前几章为止,本书已经分别讨论了 GPU 共享的基础机制、编排方式、硬件隔离与监控问题。现在需要把这些能力放进一个更真实的平台场景中:如果你不是在为单个团队配置一套 GPU 环境,而是在为整个组织设计一套能够长期服务多个 AI 团队的平台,那么你到底应该如何组织集群、分配 GPU,并在隔离与效率之间取得平衡?这一章要回答的,就是这个问题。
先从一个典型企业场景开始。假设组织拥有 5 台裸金属 GPU 节点和 5 台裸金属 CPU 节点,无论这些节点位于本地数据中心还是云环境,约束本质上都相同:硬件数量有限,但内部 AI/ML 团队对 Kubernetes 集群和 GPU 资源的需求却持续增长。这些团队可能在做基于 LLM 的智能体应用、训练模型、构建 RAG 流程或提供在线推理服务。现在,组织里有 10 个相互独立的团队,每个团队都希望获得自己的 Kubernetes 集群,以便拥有足够的自主性、隔离性与变更节奏。
如果你使用 kubeadm 之类的传统方式来创建集群,那么每个集群至少需要一个控制平面节点、一个 CPU 节点和一个 GPU 节点。只要做一个最粗略的算术,你就会立刻发现问题:
- 每个团队至少需要 3 个节点
- 10 个团队总共需要 30 个节点
- 但你手中只有 10 个节点
哪怕退一步说,每个团队只给 2 个节点,实际需求仍然远超现有容量。换句话说,问题不是“是否愿意给每个团队独立集群”,而是“在硬件总量固定的前提下,这根本做不到”。这迫使平台工程师回到一个更本质的问题:如何让多个团队共享同一个基础设施,而不牺牲他们所需要的隔离与自主性?
替代方案
在 Kubernetes 世界中,最先想到的答案通常是命名空间。命名空间是 Kubernetes 默认提供的多租户原语,它允许你在同一集群内按逻辑边界划分资源。很多 Kubernetes 原生对象,例如 Deployment、Service、ConfigMap 等,本来就是命名空间级资源。因此,一个自然的第一反应往往是:既然有 10 个团队,那就给每个团队创建一个命名空间。
从操作上看,这种方案非常直接:
- 提供一个共享 Kubernetes 集群
- 向其中加入 CPU 和 GPU 节点
- 创建 10 个命名空间,每个团队一个
为了进一步强化治理,你还可以继续叠加控制措施:
- 用
NetworkPolicy限制跨团队通信 - 用
ResourceQuota防止资源囤积 - 用
LimitRange约束默认资源声明
在一个规模较小、工作负载较简单的环境里,这看起来几乎是一个合理解法。但只要场景进入真实 AI 多租户平台,命名空间很快就会暴露出结构性不足。
首先,命名空间只能提供相对弱的租户隔离。它能把资源“分组”,却不能把控制平面真正切开。一个团队即使只是在自己的命名空间中创建了海量 Secret、ConfigMap,或者过度消耗了共享 GPU,也仍然可能对其他团队造成影响,因为所有人共享的是同一个 API 服务器、同一套控制器以及同一个宿主控制平面。这意味着命名空间多租户天然存在“吵闹邻居”问题,而且问题发生的位置并不只在数据平面,也会出现在控制平面。
其次,命名空间无法提供真正的租户自主性。团队很可能需要安装自己的 CRD、部署自定义 Operator、试验新的 GPU Operator 版本,或者使用与宿主集群不同的控制器与策略组合。但这些对象大量属于集群级别,而不是命名空间级别。结果就是,一个共享集群通常只能有一套 CRD 定义、一套 Operator 版本、一套准入控制逻辑。每个团队都不得不被约束在同一版本与同一平台假设之下,而这恰恰与 AI/ML 团队常见的实验需求相冲突。
第三,命名空间很难满足更严格的合规和监管要求。对于有审计、数据驻留、安全隔离要求的组织来说,弱隔离通常不足以过审。命名空间无法天然提供独立的审计日志、租户级 API 服务器策略、深度可分离的控制面访问模型。即使你能通过大量附加组件拼装出类似效果,其运维复杂度也会急剧上升,最终平台团队反而承担了更多脆弱的治理逻辑。
最后,命名空间并不会减少平台团队的实际负担。相反,很多集群级操作仍然只能由平台团队完成:安装 CRD、升级 Operator、调整控制器、维护集群范围策略。平台团队不仅没有从“每个团队都来提需求”的状态中解脱出来,反而成了所有变更请求的瓶颈。于是,命名空间虽然提供了最基础的逻辑隔离,却无法成为面向企业级 AI 多租户平台的最终答案。
这也是为什么仅靠命名空间通常不够,尤其是在以下条件同时成立时:
- GPU 隔离和资源公平性至关重要
- 团队需要租户特定的 CRD 或 Operator
- 自主性和运营独立性是目标之一
- 合规和审计要求不可妥协
- 平台团队不能长期充当所有集群变更的人工网关
如果命名空间不够,那么是否应该退回到另一端,即给每个团队专门配置一个独立集群?传统行业中的确常常这样做。为每个团队提供单租户集群,能把控制平面和数据平面完全隔离开来,也最容易从安全和治理角度获得清晰边界。但问题同样明显:一旦团队数量增长,平台团队就不得不维护大量独立集群,集群生命周期管理、版本升级、策略分发、监控、备份与成本控制都会迅速变成沉重负担。资源碎片化也会随之出现,尤其是 GPU 这类昂贵资源,很容易在多个小集群之间形成“每个都不够满,但谁也借不到”的局面。
平台团队于是陷入一个典型的两难:专用集群带来强隔离,却以碎片化和高运维成本为代价;命名空间共享集群带来较高利用率,却牺牲了团队自主性与隔离质量。vCluster 的意义,就在于为这两个极端之间提供一种新的中间解。
vCluster 提供的是轻量级、隔离的控制平面,而不要求你为每个团队重复创建完整宿主集群。一个虚拟集群本质上是运行在宿主集群某个命名空间内的、完整但轻量的 Kubernetes 控制平面。从租户视角看,它就是一个独立 Kubernetes 集群:有自己的 API 服务器、控制器管理器、数据存储和资源状态;从平台视角看,它只是宿主集群上的一个轻量工作负载实例。这样一来,团队获得了近似独立集群的体验,而平台团队不必为每个团队都付出一整套物理或云端集群的代价。
理解 vCluster 架构:入门指南
可以把 vCluster 理解为“在一个真实 Kubernetes 集群内部,切出多个彼此隔离的虚拟 Kubernetes 集群”。每个团队可以获得自己的虚拟集群和独立的 kubeconfig,因此他们与自己的控制平面交互,而不是直接接触宿主集群或其他团队的环境。这种模型最重要的价值,在于它把“共享底层硬件”和“隔离控制平面体验”同时保留下来。
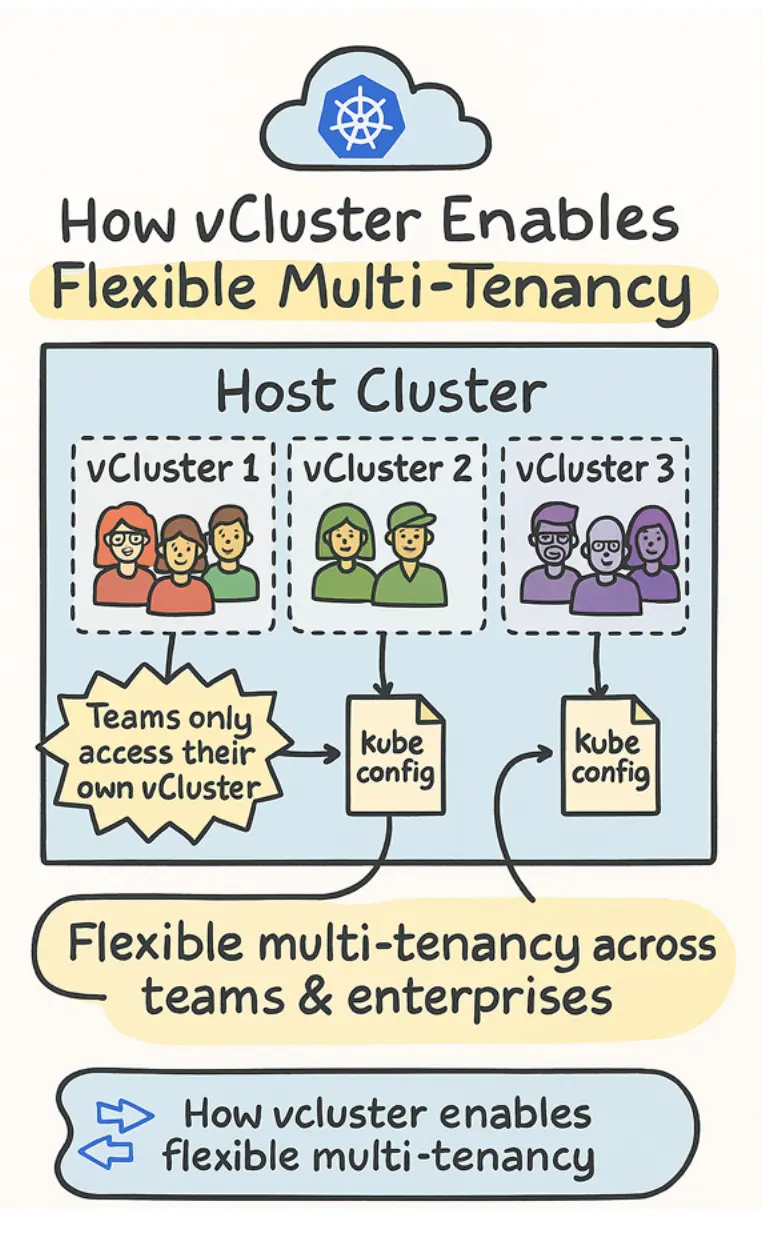
从实现上看,一个 vCluster 通常由两个核心部分构成,并以 StatefulSet 或 Deployment 的形式部署在宿主集群某个命名空间内。第一部分是虚拟控制平面。这是整个架构的中心:它包含自己的 Kubernetes API 服务器、控制器管理器和状态存储,因此租户的所有 API 请求、资源对象和 CRD 状态都首先在这里被处理。默认情况下,vCluster 使用嵌入式 SQLite 以降低资源占用;但如果需要更高可用性或更强的生产稳定性,也可以外接 etcd 或 PostgreSQL 等数据存储。
虚拟控制平面的价值,不只是“把控制器进程多跑一份”这么简单,而是它真正建立了一条租户边界。租户在其虚拟集群里安装 CRD、调整 RBAC、部署自定义 Operator,这些操作首先影响的是自己的控制平面和自己的状态数据库,而不会直接污染宿主集群或其他租户的控制面空间。这正是命名空间做不到的事情。
第二部分是 Syncer。虚拟集群本身并不拥有独立的工作节点,也不会真的创建一套新的物理网络或 kubelet 体系。Syncer 的作用,就是在虚拟控制平面和宿主集群之间建立一座桥梁:当租户在自己的 vCluster 中创建 Pod、PVC 等资源时,Syncer 会把这些对象翻译并同步到宿主集群对应的命名空间中,使真正的调度与执行发生在宿主集群的数据平面上。
这种同步不是简单复制,而是一种带转换的映射。举例来说,租户在 vCluster 中的 ai-team 命名空间里创建了一个名为 ollama 的 Pod,Syncer 在宿主集群中可能会把它转换成一个带唯一前缀或后缀的名称,如 ollama-xai-team-x-my-vcluster。这样做的目的,是在多个租户的相同命名空间名称、相同资源名称之间建立去冲突的隔离映射。
Syncer 更有价值的地方,在于它还承担着平台策略下沉的作用。在传统共享集群中,平台团队常常通过全局准入控制器、Webhook 或集群级策略组件去统一控制所有租户行为,但这种方式复杂、脆弱,而且对整个宿主集群都带来潜在风险。vCluster 则提供了更柔性的做法:平台团队可以在 vCluster 模板或同步配置中定义补丁规则,让 Syncer 在资源从虚拟集群同步到宿主集群时自动施加平台策略。例如,你可以让所有请求 GPU 的 Pod 在同步到宿主时自动附带特定的 runtimeClassName,或注入统一的节点选择、资源标签和安全配置。对租户而言,这些规则通常是透明的;对平台而言,它们则构成了一种更细粒度、更安全的治理机制。
下表概括了 vCluster 架构中的核心组件:
| 组件 | 功能 | 关键好处 |
|---|---|---|
| 虚拟控制平面 | 处理租户 API 请求并为每个 vCluster 存储独立状态。 | 提供 API 级与 CRD 级隔离,避免租户直接共享宿主控制平面。 |
| Syncer | 将 Pod 等资源从虚拟集群转换并同步到宿主集群。 | 让虚拟集群无需独立数据平面也能运行真实工作负载,并可在同步时施加策略。 |
| 数据存储 | 持久化虚拟集群的 Kubernetes 资源状态。 | 可以轻量运行,也可以外部化以支持更强的高可用和生产扩展能力。 |
| 调度器(可选) | 在虚拟集群侧为工作负载提供调度逻辑。 | 默认可复用宿主调度器节约资源,也可按需引入自定义调度策略。 |
换个角度来看,vCluster 做的不是让每个团队都拥有真正独占的硬件,而是让每个团队都拥有“看起来像独占集群”的控制平面体验,同时把真实的资源执行统一沉到一个共享宿主集群上。这样一来,多租户平台既能提升 GPU 利用率,又能把租户自主性提升到传统命名空间模型难以达到的程度。
从专用集群走向共享平台
为了更直观地理解这一点,不妨把前面讨论过的架构演化路径放到一个连续场景里。先看基础设施本身:
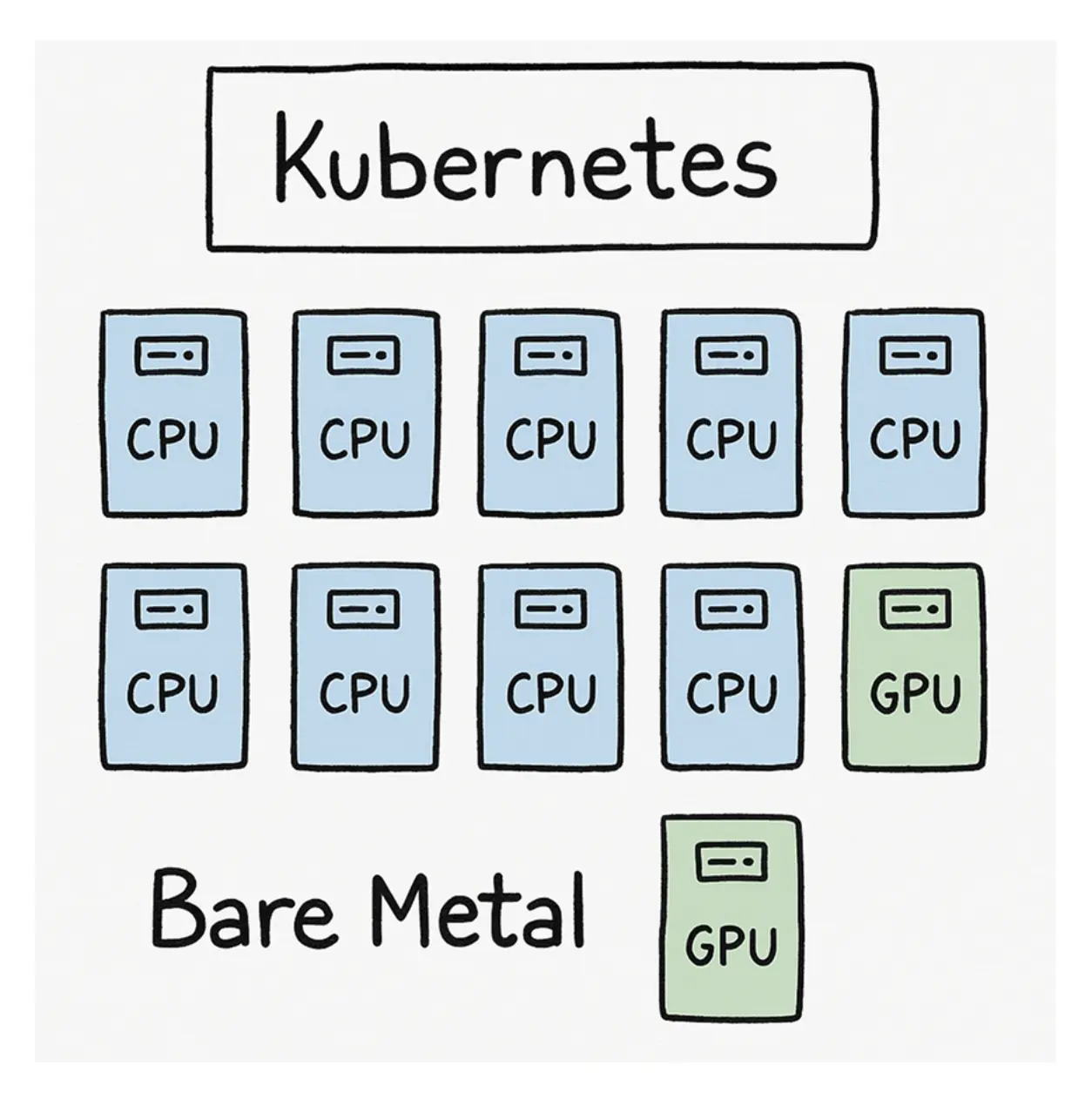
你手里只有这一批裸金属或云节点。最直觉的方案,是先为不同团队各自创建独立 Kubernetes 集群。即使在云环境里,这通常也意味着为每个团队配置单独集群,再为其附加不同节点池。看上去这最能满足团队的独立性:
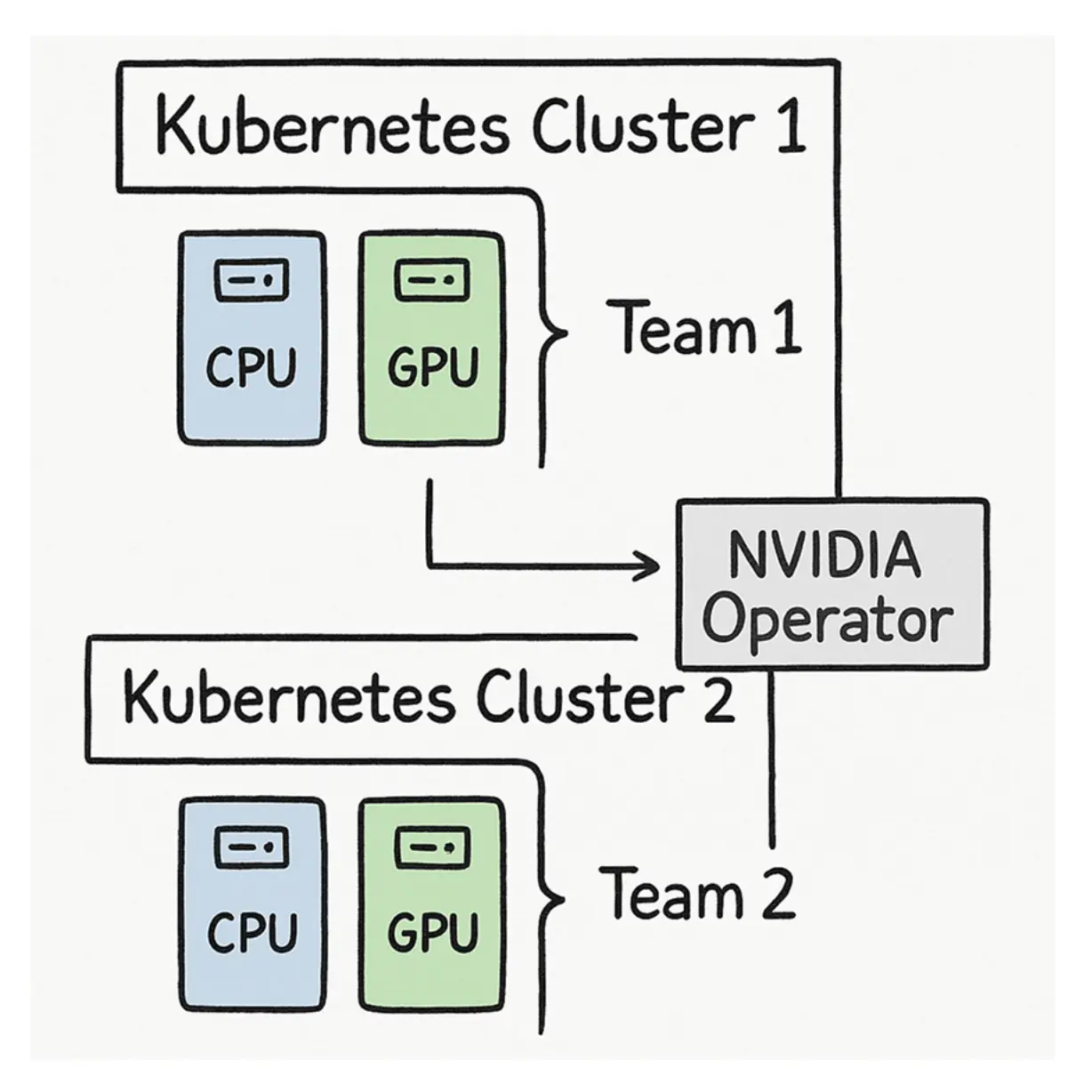
但很快你会发现,节点数量开始告急。仅为了建立一个具备基本可用性的 Kubernetes 集群,你至少就要消耗一个控制平面节点、一个 CPU 节点和一个 GPU 节点。对资源总量有限的组织来说,这种模式不可能扩展到很多团队。于是问题从“如何建集群”转向“如何分割既有基础设施”。
此时,另一个障碍也会逐渐显现:即使你成功给团队提供了集群,默认 Kubernetes 调度器也并不是为 AI/ML 工作负载设计的。AI 作业不只是“要一个 GPU”这么简单,它往往还隐含着更多要求,例如特定 GPU 型号、MIG 切片、时间分片、特定驱动与运行时、足够的显存、快速本地存储、高带宽网络,以及 Gang 调度、公平队列、检查点恢复等高级调度能力。默认调度器把 1 GPU 仅仅视作一个资源整数,而不会天然理解显存边界、拓扑位置、GPU 碎片整理、公平共享或训练作业的整体协同需求。
这就导致一系列熟悉的问题:GPU 被碎片化地占用,分布式训练作业只启动了一半就卡住,不同团队之间缺乏公平共享,数据局部性和 NUMA/PCIe 拓扑被忽略,很多 Pod 虽然声明正确却始终停留在 Pending。最终的用户体验是:队列很长,GPU 利用率却不高,工程师不断追问“为什么我的作业还没有被调度起来”。
这正是像 Kai Scheduler、HAMi 和 Kueue 这样的项目出现的背景。它们试图弥补默认调度器在 AI 工作负载上的认知不足。在本章里,我们重点使用 Kai Scheduler 作为示例,因为它更适合展示 GPU 队列、公平共享与工作负载打包的能力。
Kai Scheduler 可以被理解为默认 Kubernetes 调度器之上的专用增强层,它为 AI/ML 集群提供更丰富的调度语义,例如:
- 基于 DRF 的分层队列与公平共享机制,用于在
org/team/user等层级之间分配资源 - 面向分布式训练的 Gang 调度,确保一组 Pod 要么一起启动,要么都不启动
- GPU 分数共享与时间分片,减少小任务对整卡的浪费
- 抢占与整合能力,用于为更高优先级工作负载腾挪资源
- 对 DRA、ResourceClaim 和拓扑约束更友好的支持
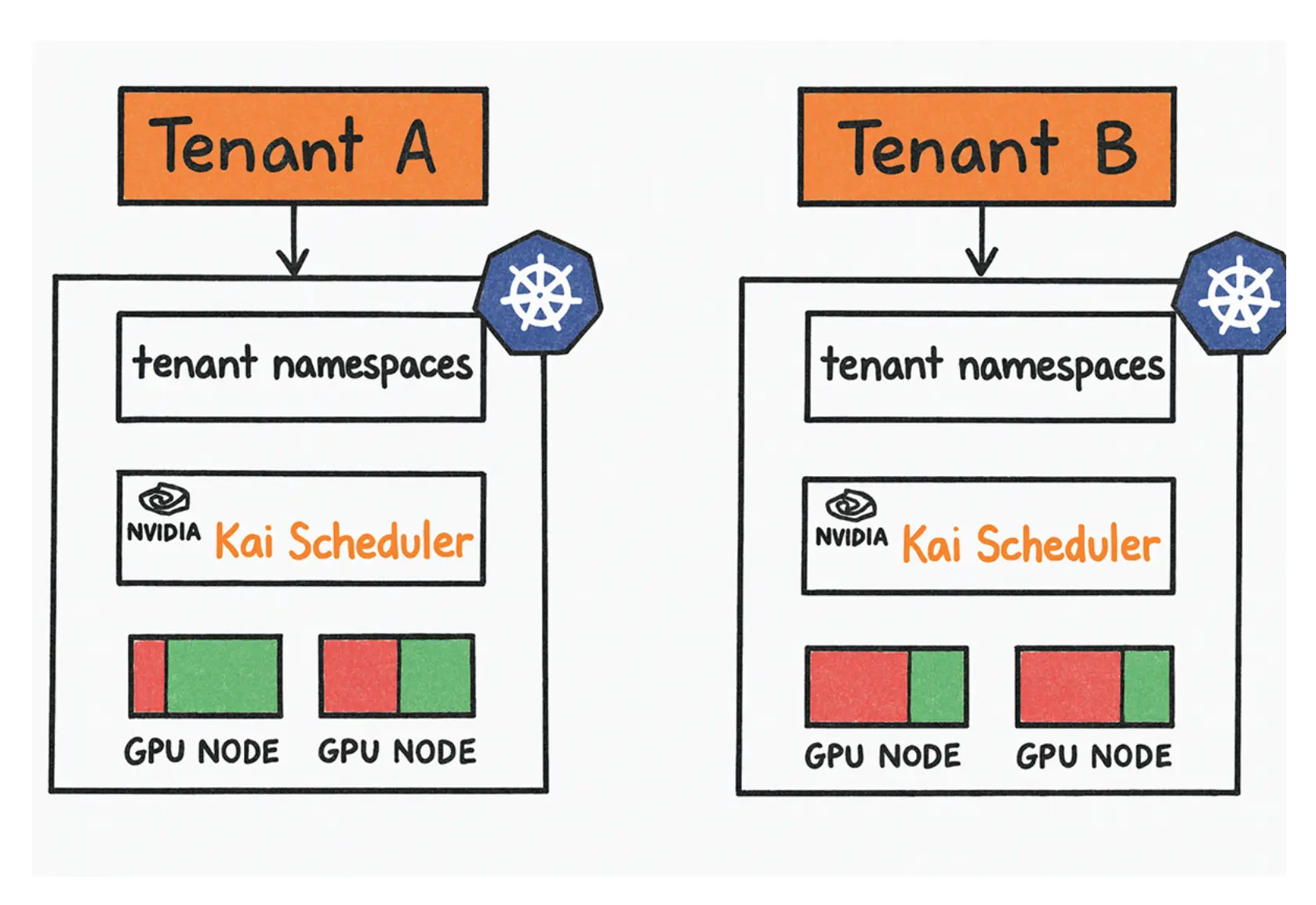
如果你在每个团队独立集群中都部署 Kai Scheduler,当然可以改善各自集群内部的 GPU 使用效率:
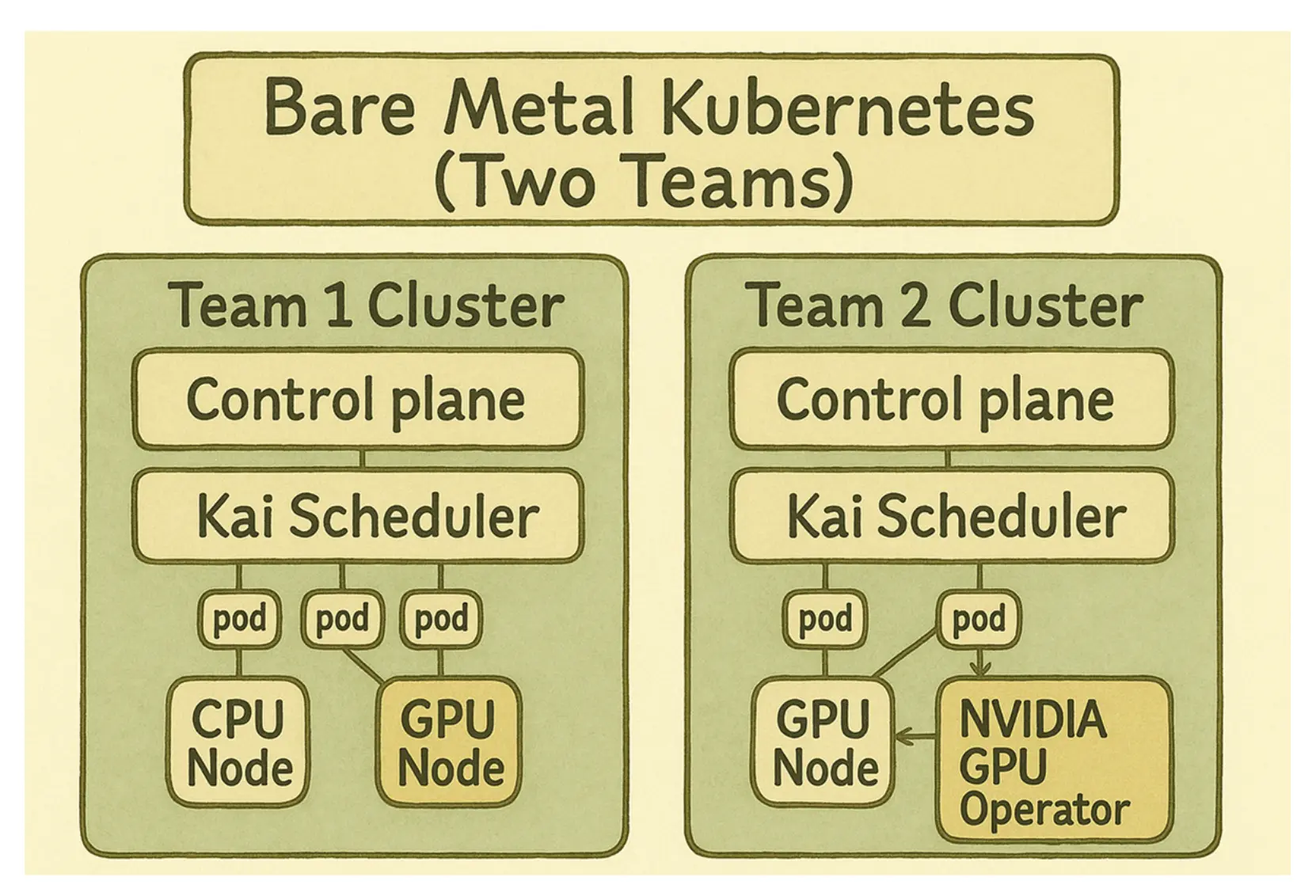
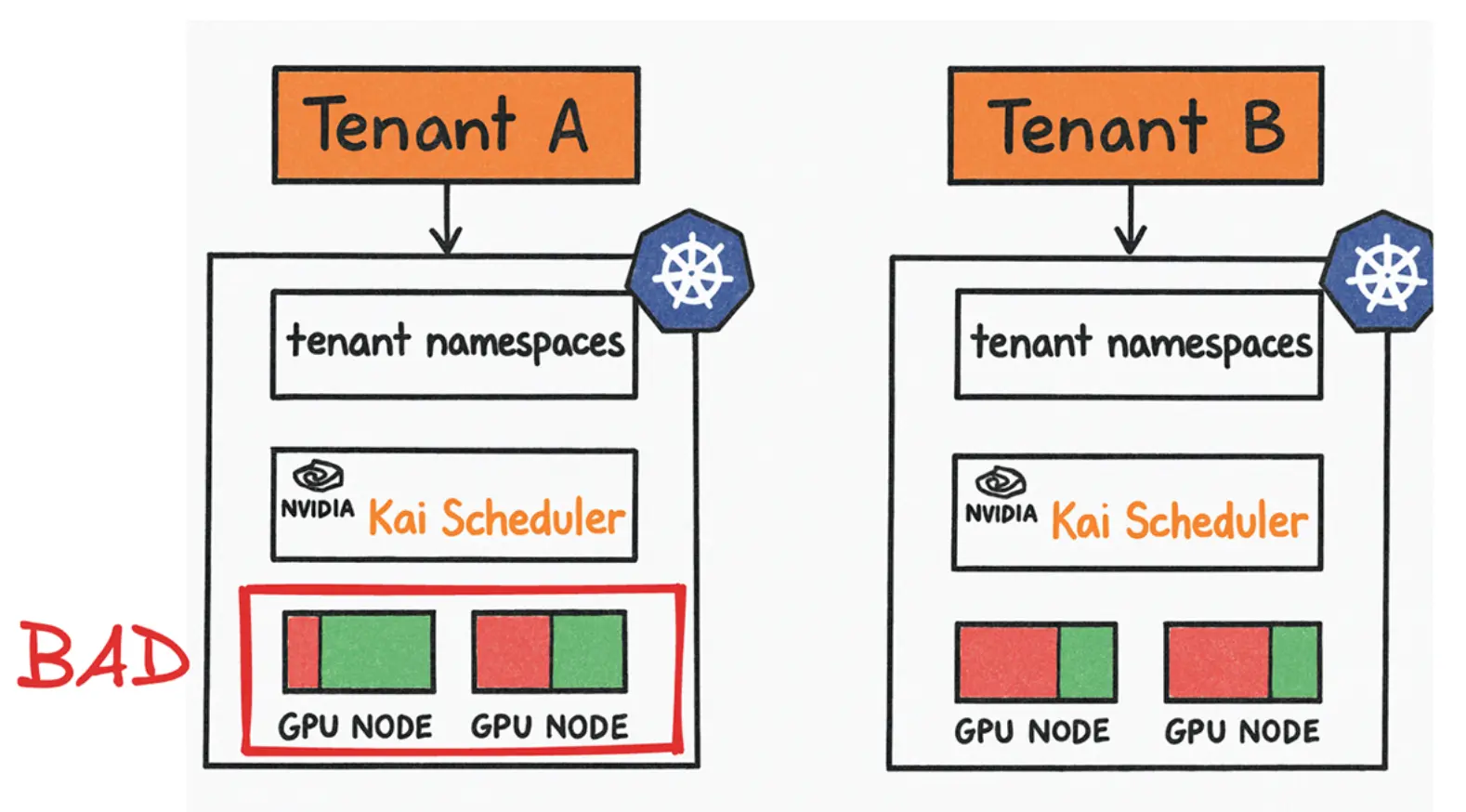
但这仍然没有解决根本矛盾:GPU 资源仍被锁在不同独立集群中,利用率依旧受碎片化影响。一个团队可能过度占用 GPU,而另一个团队的 GPU 长期空闲:
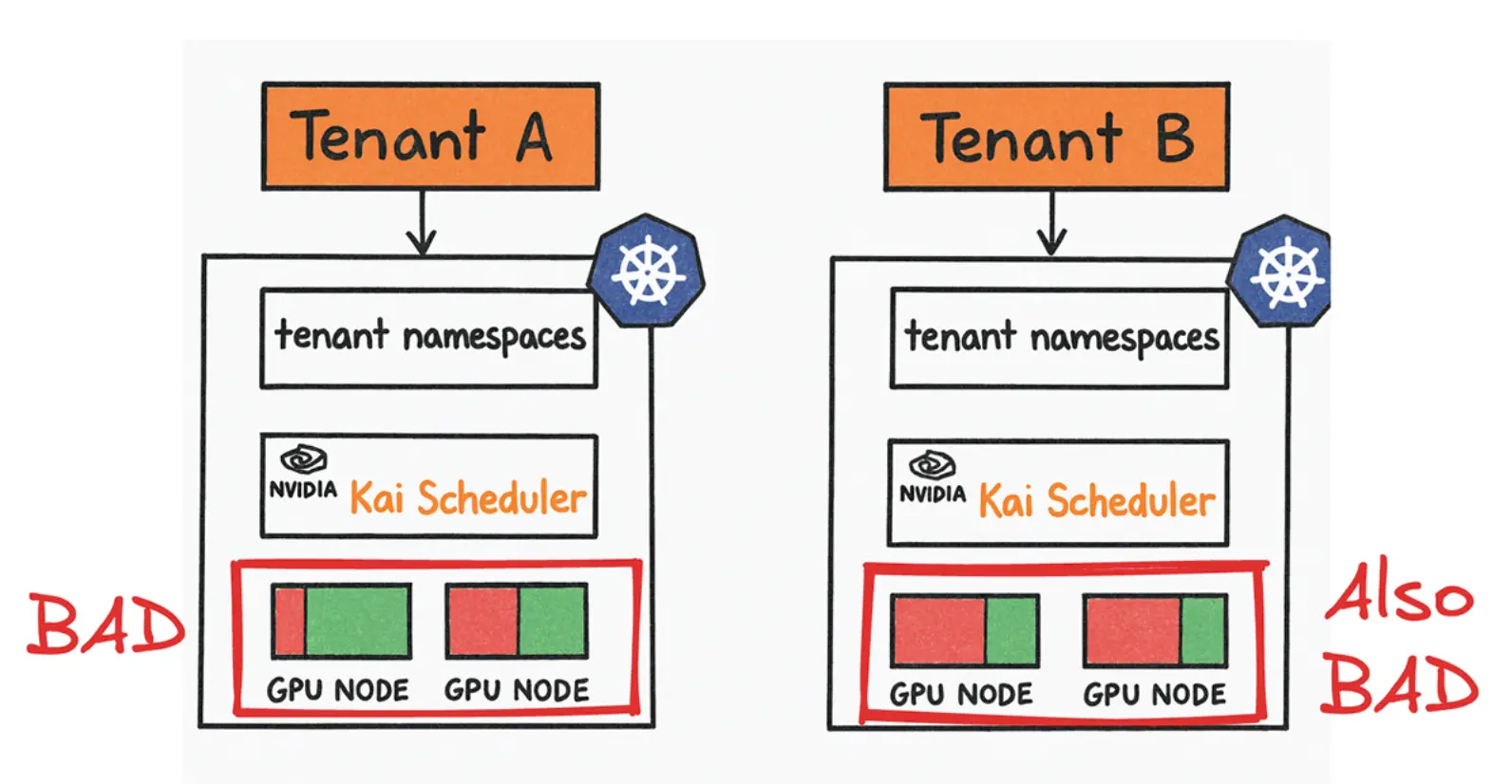
于是你又回到了那个问题:要不要退回共享集群加命名空间的方式?
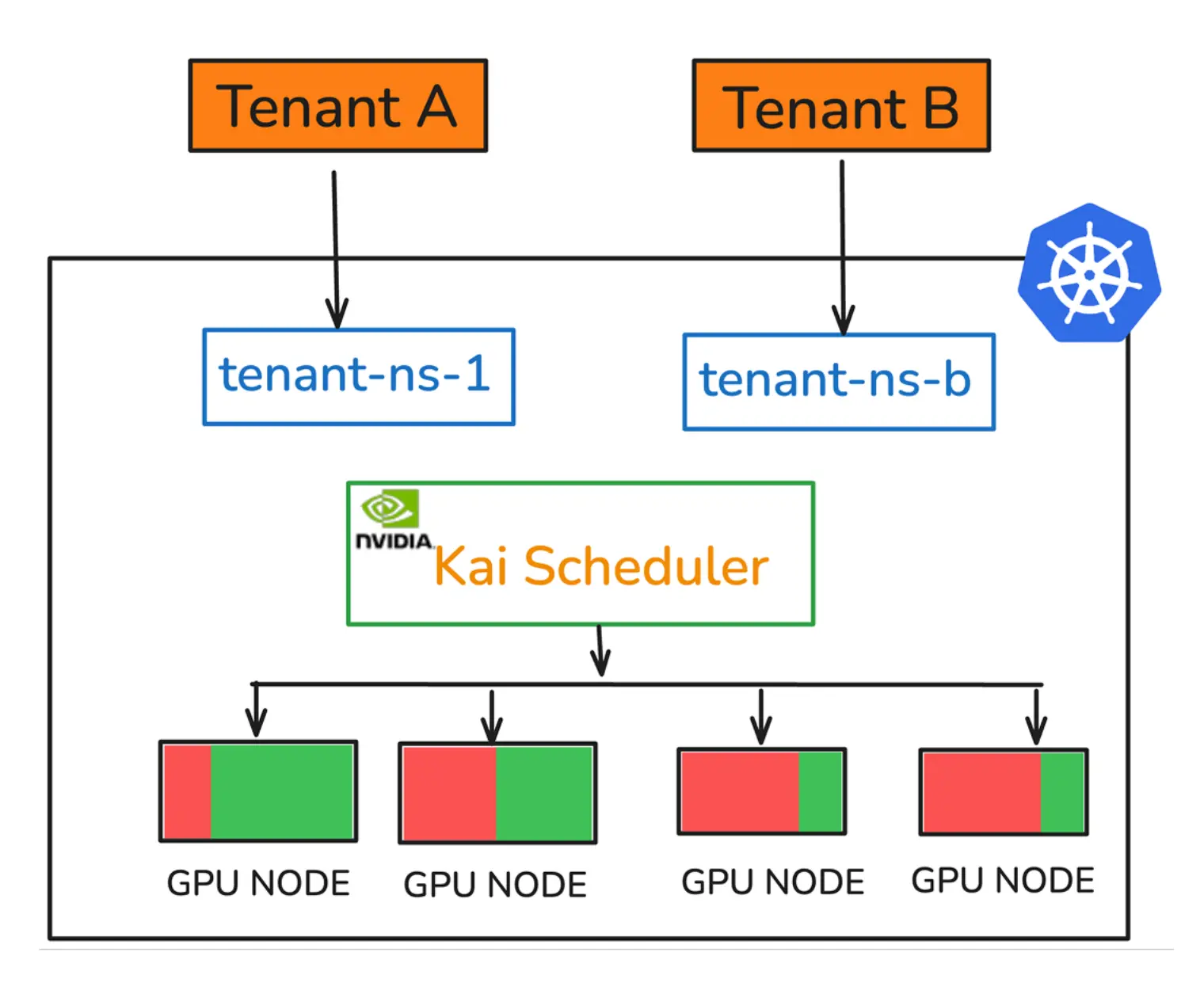
如果这样做,命名空间的那些老问题会重新出现:控制平面仍共享,租户自主性依然有限,集群级扩展和治理仍掌握在平台团队手里。于是,真正更合理的模式就浮现出来了:在一个共享的大型宿主集群上,利用 vCluster 为每个团队提供隔离的虚拟控制平面,同时让 GPU 节点池在底层被统一共享与调度。
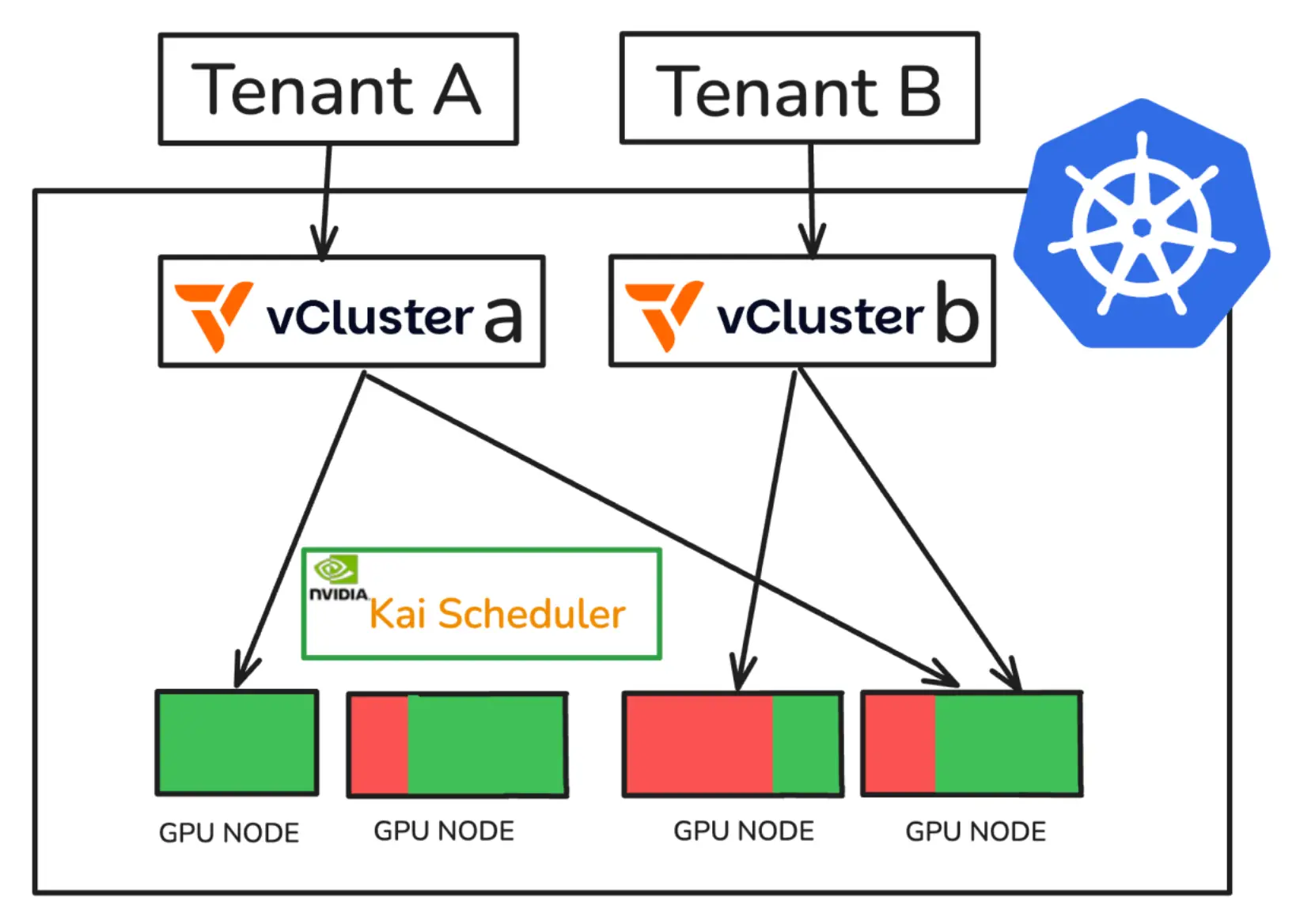
在这种模式下,平台团队只需要维护一个包含 CPU 和 GPU 节点的大型宿主 Kubernetes 集群,再为每个团队创建对应的虚拟集群。团队得到的是自己的 API 入口、自己的控制平面体验和自己的租户边界;平台得到的是统一的硬件池和统一的宿主治理面。新租户到来时,也不再需要等待新的物理集群或新的云环境交付,而只需要在现有宿主集群中创建另一个 vCluster 即可。
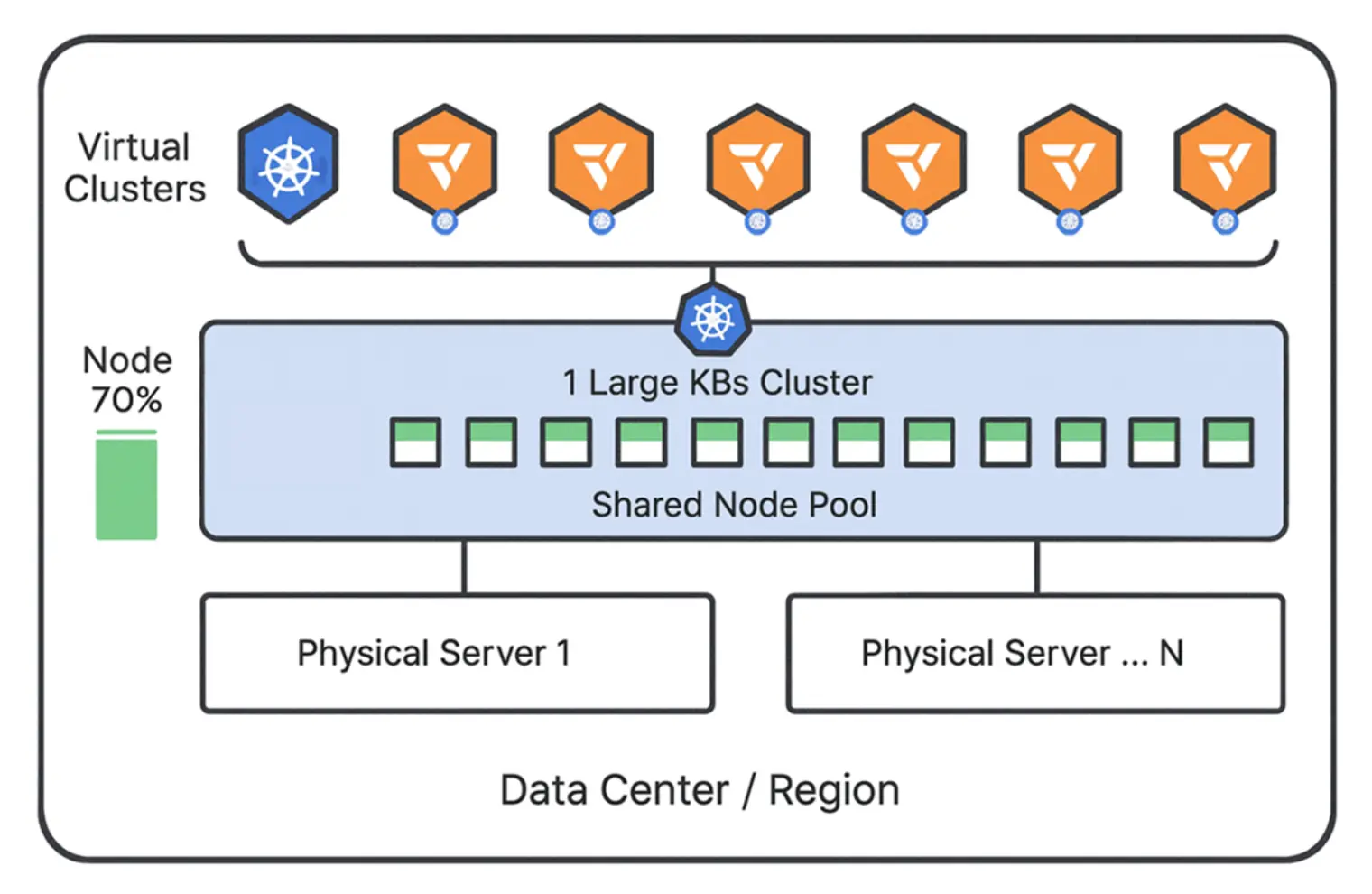
这样,数据中心或云平台最终呈现的形态就是:底层是一个大型共享宿主集群,上层是多个面向团队的虚拟 Kubernetes 集群。平台不再被“集群数量”本身拖垮,而租户也不必退回到命名空间级的弱隔离模型。
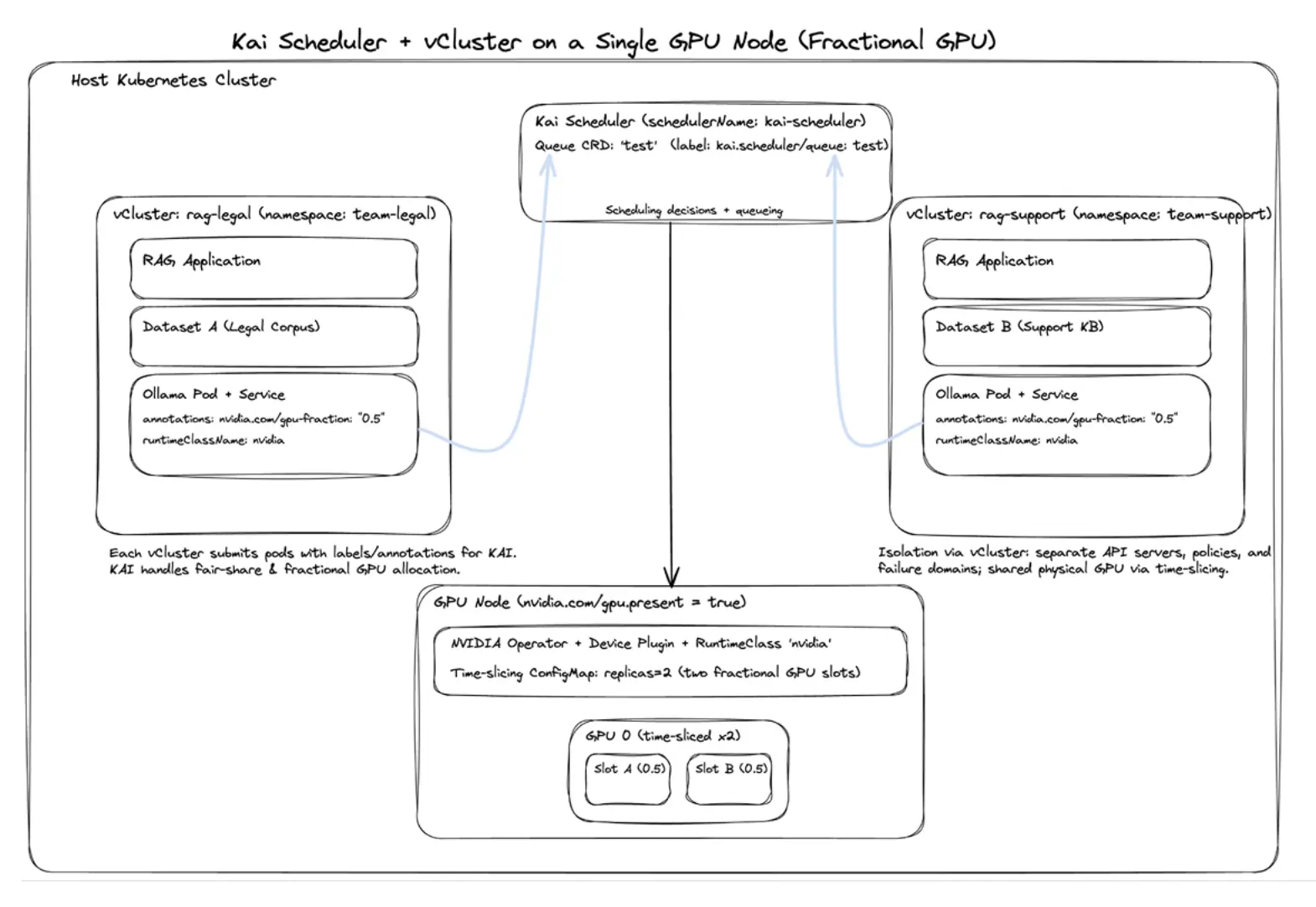
演示:使用 vCluster 和 Kai Scheduler 实现 GPU 分数共享
下面通过一个更具体的场景来说明这一模式如何落地。假设你在一个共享 GPU 环境中,需要支持不同团队使用 Ollama 部署基于 RAG 的应用。每个团队的数据集不同、模型选择不同、扩展需求不同,但它们都希望获得一定程度的自主环境和受控 GPU 使用。目标是同时实现三件事:租户隔离、公平调度和 GPU 分数共享。
前提条件
要复现实验环境,需要满足以下前提:
- 带有 NVIDIA GPU 的 Kubernetes 集群,可以是裸金属,也可以是带有 GPU 节点池的 GKE、AKS 或 EKS
- 已安装
kubectl(建议 v1.28+)并配置好上下文 - 已安装
helm(建议 v3.10+) - 已安装
vclusterCLI - 至少有一个 GPU 节点,例如
g4dn.xlarge
在本示例中,我们使用一个包含单个 GPU 节点的 EKS 集群。为了简化说明,先用 eksctl 创建一个带 GPU 节点池的集群:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: vcluster-gpu
region: us-east-2
version: '1.32'
tags:
usage: sandbox
owner: vcluster
vpc:
cidr: 10.1.0.0/16
autoAllocateIPv6: false
hostname: resource-name
clusterEndpoints:
publicAccess: true
privateAccess: true
managedNodeGroups:
- name: vcluster-gpu
amiFamily: Ubuntu2404
desiredCapacity: 1
instanceTypes:
- g4dn.xlarge
ssh:
allow: true
publicKeyName: vcluster使用以下命令创建 EKS 集群:
eksctl create cluster --config-file eks-config-gpu.yaml集群创建完成后,拉取 kubeconfig 并更新本地上下文:
aws eks update-kubeconfig --region us-east-2 --name vcluster-gpu --kubeconfig ./vcluster-kubeconfig确认集群已就绪:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-12-34.ec2.internal Ready <none> 19h v1.32.xNVIDIA GPU Operator 设置
有了 GPU 节点之后,下一步是安装 GPU Operator,并把 GPU 配置为时间分片模式,以支持分数共享。先安装 Operator:
$ helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
$ helm repo update
$ helm install gpu-operator nvidia/gpu-operator -n gpu-operator --create-namespace
NAME: gpu-operator
LAST DEPLOYED: Tue Sep 2 12:07:02 2025
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None安装完成后,确认相关组件都已正常启动:
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-svqzb 1/1 Running 0 5m
gpu-operator-5798b5b564-rw57d 1/1 Running 0 5m
gpu-operator-node-feature-discovery-gc-86f6495b55-dsvfk 1/1 Running 0 5m
gpu-operator-node-feature-discovery-master-694467d5db-cc2zj 1/1 Running 0 5m
gpu-operator-node-feature-discovery-worker-p8k7n 1/1 Running 0 5m
nvidia-container-toolkit-daemonset-s4vg4 1/1 Running 0 5m
nvidia-cuda-validator-sqfp2 0/1 Completed 0 2m
nvidia-dcgm-exporter-2bx94 1/1 Running 0 5m
nvidia-device-plugin-daemonset-tvvpr 1/1 Running 0 5m
nvidia-driver-daemonset-6wjnt 1/1 Running 0 5m
nvidia-operator-validator-s4wxv 1/1 Running 0 5m随后,在 gpu-operator 命名空间中创建时间分片配置:
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config
namespace: gpu-operator
data:
time-slicing-config.yaml: |
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 2
EOF然后重启设备插件,使配置生效:
kubectl rollout restart daemonset nvidia-device-plugin-daemonset -n gpu-operator最后确认单个物理 GPU 已暴露为两个逻辑可分配单元:
$ kubectl get nodes -o json | jq '.items[].status.capacity."nvidia.com/gpu"'
"2"这意味着底层只有一张物理 GPU,但在资源视图上,它现在可以被分成两个可共享的逻辑设备。
安装 KAI-Scheduler
接下来,在宿主 Kubernetes 集群上安装 Kai Scheduler,并打开全局 GPU 共享能力:
$ helm upgrade -i kai-scheduler \
oci://ghcr.io/nvidia/kai-scheduler/kai-scheduler \
-n kai-scheduler --create-namespace \
--version v0.8.4 \
--set gpuSharing=true确认组件已正常运行:
$ kubectl get pods -n kai-scheduler
NAME READY STATUS RESTARTS AGE
binder-5ddb78b47-75hbq 1/1 Running 0 2m
kai-admission-649bf8cbd7-gjs4t 1/1 Running 0 2m
podgroup-controller-8ff79c87f-8p7wr 1/1 Running 0 2m
podgrouper-85cfbb79b5-dgjx4 1/1 Running 0 2m
queuecontroller-658499d99c-v6wjt 1/1 Running 0 2m
scheduler-56f6f568b9-6gpgl 1/1 Running 0 2mKai Scheduler 生效后,还需要创建一个队列,让后续来自 vCluster 的工作负载能够通过 kai.scheduler/queue 标签进入该队列:
$ kubectl apply -f - <<EOF
apiVersion: scheduling.run.ai/v2
kind: Queue
metadata:
name: test
spec:
parentQueue: default
resources:
cpu:
quota: -1
limit: -1
overQuotaWeight: 1
gpu:
quota: -1
limit: -1
overQuotaWeight: 1
memory:
quota: -1
limit: -1
overQuotaWeight: 1
EOF创建完成后,可以验证队列层级:
$ kubectl get queue
NAME PRIORITY PARENT CHILDREN DISPLAYNAME
test default创建带有 Kai 集成的 vCluster
宿主侧调度能力准备就绪后,就可以为租户创建虚拟集群。首先定义一个最基本的同步配置,关闭 owner reference,并启用 runtimeClass 同步:
$ cat > values.yaml <<EOF
experimental:
syncSettings:
setOwner: false
sync:
fromHost:
runtimeClasses:
enabled: true
EOF然后安装 vcluster CLI,并在 team-legal 命名空间中创建一个名为 rag-legal 的虚拟集群:
$ curl -L -o vcluster "https://github.com/loft-sh/vcluster/releases/latest/download/vcluster-linux-amd64" \
&& sudo install -c -m 0755 vcluster /usr/local/bin \
&& rm -f vcluster
$ vcluster create rag-legal --namespace team-legal -f values.yaml
11:32:16 done Successfully created virtual cluster rag-legal in namespace team-legal
11:32:15 info Waiting for vcluster to come up...
11:34:45 done Switched active kube context to vcluster_rag-legal-team-legal_minikube确认 vCluster 已经正常运行:
$ vcluster list
NAME NAMESPACE STATUS VERSION CONNECTED AGE
rag-legal team-legal Running 0.27.0 True 3m25s这一步的含义在于:团队现在拥有了自己的 Kubernetes 入口和控制平面体验,但并没有新增任何真实 GPU 节点。租户的自主环境与宿主物理资源已经被解耦开来。
部署应用
现在可以在虚拟集群中部署一个简单的 GPU 工作负载。这个 Pod 会通过 Kai Scheduler 提交到宿主队列中,并通过注解申请半块 GPU 的分数共享。把下面的内容保存为 podkai2.yaml:
apiVersion: v1
kind: Pod
metadata:
name: gpu-sharing-pod
labels:
kai.scheduler/queue: test
annotations:
nvidia.com/gpu-fraction: "0.5"
spec:
schedulerName: kai-scheduler
runtimeClassName: nvidia
nodeSelector:
nvidia.com/gpu-present: "true"
containers:
- name: ollama-rag
image: ollama/ollama:latest
command: ["ollama", "serve"]
resources:
limits:
nvidia.com/gpu: 1将该文件应用到 vCluster:
vcluster connect rag-legal --namespace team-legal -- kubectl apply -f podkai2.yamlPod 启动后,向其拉取一个模型:
$ kubectl exec -it -n team-legal gpu-sharing-pod-x-default-x-rag-legal -- ollama pull mistral
pulling f5074b1221da: 100% ████████████████████ 4.4 GB
pulling 43070e2d4e53: 100% ████████████████████ 11 KB
pulling 1ff5b64b61b9: 100% ████████████████████ 799 B
pulling ed11eda7790d: 100% ████████████████████ 30 B
pulling 1064e17101bd: 100% ████████████████████ 487 B
verifying sha256 digest
writing manifest
success然后把端口转发到本地:
kubectl port-forward pod/gpu-sharing-pod-x-default-x-rag-legal -n team-legal 11434:11434
Forwarding from 127.0.0.1:11434 -> 11434最后发送一次测试请求:
curl -s http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "mistral",
"stream": false,
"messages": [
{"role": "user", "content": "Summarize Kubernetes in one line"}
]
}' | jq -r '.message.content'
Kubernetes is an open source platform for automating deployment, scaling, and management of containerized applications.对其他团队重复同样的流程时,你并不需要再去准备新的独立宿主集群;只要继续创建新的 vCluster 并把工作负载接入 Kai Scheduler 即可。
最终结果
完成上述配置后,你得到的并不是一个简单的共享集群,而是一套更接近内部 AI 平台的结构:
- 多个租户各自拥有独立的 vCluster,例如法律研究团队和客户支持团队
- 每个租户都能在自己的控制平面中运行隔离的 Ollama/RAG 工作负载
- 每个工作负载都可通过 Kai Scheduler 获取分数 GPU 访问,例如 0.5 GPU
- 平台团队保持对底层宿主集群、GPU Operator、策略模板和共享资源池的统一控制
- 租户获得接近独立集群的体验,而无需为每个团队单独维持完整硬件与控制面
从平台架构角度看,这个演示的价值不在于 Ollama 或 RAG 本身,而在于它展示了以下组合如何协同工作:
vCluster提供租户级控制平面隔离、自定义策略空间和 API 自主性Kai Scheduler提供公平 GPU 共享、队列治理和作业优先级控制NVIDIA GPU Operator提供 GPU 资源可见性、驱动与运行时管理,以及时间分片能力- 应用层工作负载,例如 Ollama + RAG,则验证了这套平台能够支撑真实 AI 使用场景
关键要点
- 面向多团队的 AI 平台建设,真正的约束通常不是“能不能建更多集群”,而是“在硬件数量有限时,如何同时获得隔离、自主性和高 GPU 利用率”。
- 命名空间是共享集群的必要基础,但不足以成为企业级 AI 多租户平台的最终形态,因为它无法提供强控制平面隔离、充分租户自主性和简洁的合规治理边界。
- 专用集群虽然提供最强隔离,却会带来集群数量膨胀、运维开销上升和 GPU 资源碎片化的问题,尤其不适合团队数量快速增长的环境。
- vCluster 的关键价值在于把“独立控制平面体验”与“共享宿主资源池”结合起来,使租户像拥有独立集群一样工作,而平台团队只需维护一个统一宿主集群。
- 当 vCluster 与 Kai Scheduler、NVIDIA GPU Operator 结合时,平台不仅能提供隔离,还能在共享 GPU 环境中实现分数资源调度、公平队列和更高的硬件利用率。
- 因此,vCluster 并不是单纯的多租户工具,而是一种让组织在不维护成百上千个独立集群的前提下,构建企业级 GPU 平台的现实方法。