- 发布于 :2017/07/11
- Kubernetes
- 3 分钟
- 最后更新于 :2024/04/25
点击查看目录
数据落盘问题的由来
这本质上是数据持久化问题,对于有些应用依赖持久化数据,比如应用自身产生的日志需要持久化存储的情况,需要保证容器里的数据不丢失,在 Pod 挂掉后,其他应用依然可以访问到这些数据,因此我们需要将数据持久化存储起来。
数据落盘问题解决方案
下面以一个应用的日志收集为例,该日志需要持久化收集到 ElasticSearch 集群中,如果不考虑数据丢失的情形,可以直接使用kubernetes-handbook 中【应用日志收集】一节中的方法,但考虑到 Pod 挂掉时 logstash(或 filebeat)并没有收集完该 pod 内日志的情形,我们想到了如下这种解决方案,示意图如下:
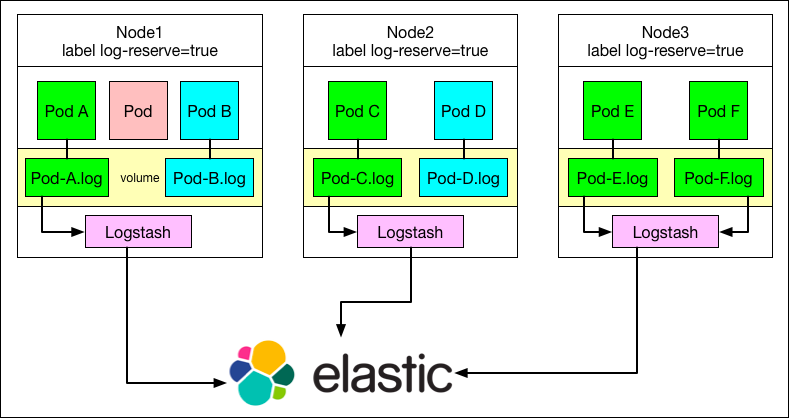
- 首先需要给数据落盘的应用划分 node,即这些应用只调用到若干台主机上
- 给这若干台主机增加 label
- 使用
deamonset方式在这若干台主机上启动 logstash 的 Pod(使用 nodeSelector 来限定在这几台主机上,我们在边缘节点启动的treafik也是这种模式) - 将应用的数据通过 volume 挂载到宿主机上
- Logstash(或者 filebeat)收集宿主机上的数据,数据持久化不会丢失
Side-effect
- 首先 kubernetes 本身就提供了数据持久化的解决方案 statefulset,不过需要用到公有云的存储货其他分布式存储,这一点在我们的私有云环境里被否定了。
- 需要管理主机的 label,增加运维复杂度,但是具体问题具体对待
- 必须保证应用启动顺序,需要先启动 logstash
- 为主机打 label 使用 nodeSelector 的方式限制了资源调度的范围
本文已归档到kubernetes-handbook 中的【最佳实践—运维管理】章节中,一切内容以 kubernetes-handbook 为准。